
Q-Former 最开始被设计用于跨模态任务(如视觉-语言建模)的 transformer 模型。它由 BLIP-2(Bootstrapping Language-Image Pre-training 2)提出,目的是在视觉特征和语言模型之间建立高效的桥梁,从而提高大规模预训练语言模型在多模态任务中的表现。
后续也逐渐用于语音-文本模态的对齐任务中,比如: DeSTA2.5-Audio
BLIP-2 提出了一个通用且高效的预训练策略,能够从已存在的冻结图像编码器和大型语言模型中引导出强大的视觉-语言模型。核心思想是引入一个轻量级的Querying Transformer(Q-Former),在冻结的图像编码器和语言模型之间架起桥梁。Q-Former 被设计为一个信息瓶颈,负责从图像编码器中提取对文本生成最有用的视觉特征,并将其传递给大型语言模型。
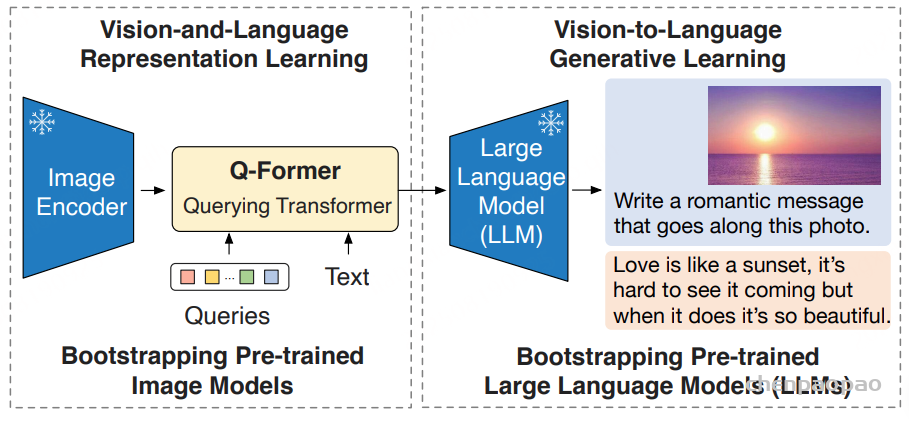
Querying Transformer(Q-Former):
Q-Former 是一个轻量级的 Transformer 模型,包含一组可学习的查询向量(queries)。其架构由两个共享自注意力层的 Transformer 子模块组成:
- 图像 Transformer:与冻结的图像编码器交互,提取视觉特征。
- 文本 Transformer:同时可以作为文本编码器和解码器。
这些查询向量通过交叉注意力层与图像特征进行交互,提取出固定数量且对文本生成最有用的视觉特征。Q-Former 的输出是这些查询向量的表示,记为Z 。
由于 Q-Former 的输出维度比图像编码器的输出特征要小很多(例如,32×768 vs. 257×1024),因此它起到了信息瓶颈的作用,只保留了对后续文本生成最有用的视觉信息。这种设计减轻了大型语言模型在冻结参数的情况下与视觉特征进行对齐的负担。
两阶段预训练策略:
BLIP-2 的预训练分为两个阶段,每个阶段都有特定的训练目标,以逐步引导模型实现视觉和语言的有效结合。
第一阶段:从冻结的图像编码器中引导视觉-语言表示学习
在第一阶段,将 Q-Former 与冻结的图像编码器连接,通过图像-文本对进行预训练。目标是训练 Q-Former,使其能够提取与文本最相关的视觉表示。
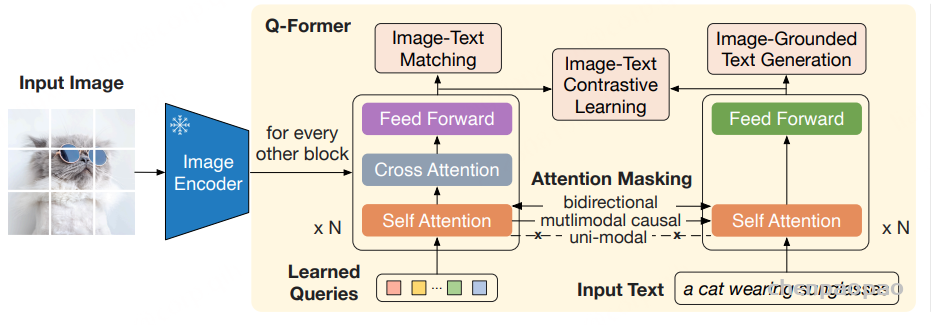
第二阶段:从冻结的大型语言模型中引导视觉到语言的生成学习
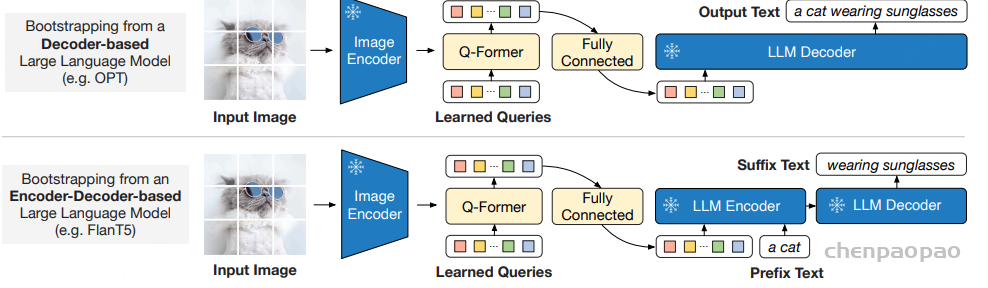
在第二阶段,将 Q-Former 输出的视觉表示连接到冻结的 LLM 上,训练 Q-Former 使其输出的视觉特征能够被 LLM 解释和利用。根据 LLM 的类型(解码器或编码器-解码器),采用不同的策略:
对于解码器类型的 LLM:利用语言模型的自回归特性,采用语言建模损失,让 LLM 在给定视觉特征的情况下生成文本。
对于编码器-解码器类型的 LLM:将视觉特征和前缀文本输入到 LLM 的编码器中,然后让解码器生成后续的文本,使用前缀语言模型损失进行训练。
在这一阶段,Q-Former 被训练使其输出的视觉特征能够被 LLM 有效地理解和利用,从而实现视觉到语言的高效生成。