
论文:https://arxiv.org/pdf/2509.20410
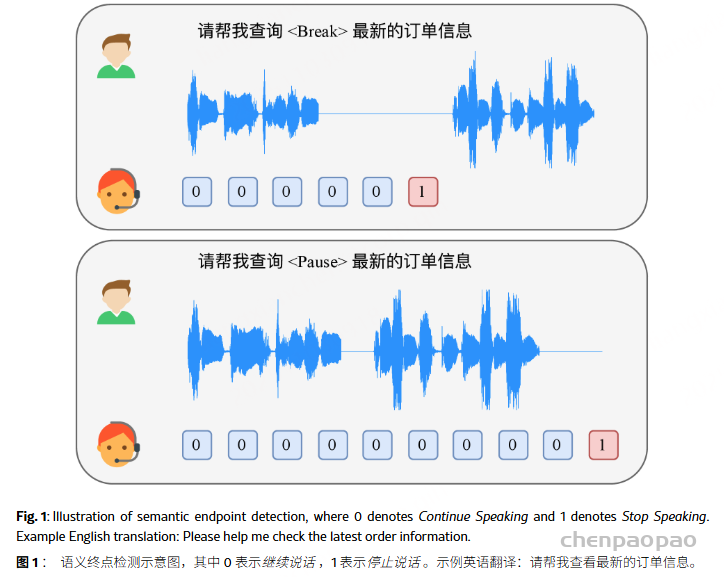
口语对话模型在智能人机交互方面取得了显著进展,但仍缺乏一种可即插即用的全双工语义端点检测模块,从而限制了音频交互的无缝体验。本文提出了一种基于大语言模型(LLM)的流式语义端点检测模型——Phoenix-VAD。Phoenix-VAD 利用大语言模型的语义理解能力,并结合滑动窗口训练策略,实现了在流式推理场景下的可靠语义端点检测。实验证明,在语义完整与语义不完整的语音场景中,Phoenix-VAD 均取得了优异且具竞争力的性能。
现有方法在这一方面存在明显局限。传统的VAD仅依赖声学特征判断“是否存在人声”,无法理解语义层面的意图,因而难以实现自然的语义对齐。语义VAD虽在一定程度上引入了语义判断,但通常依赖外部自动语音识别(ASR)模块,导致系统延迟增加,并可能损失语音中的细粒度语义信息。至于如 RTTL-DG、Moshi 等端到端方案,虽具备一定的语义理解能力,但模型高度耦合,难以在不同对话系统中直接复用,每次更换对话模型都需重新训练或微调,部署成本较高。
Phoenix-VAD ——一种基于大语言模型的语义端点检测框架,旨在实现模块化、低延迟、可流式推理的全双工语音交互。
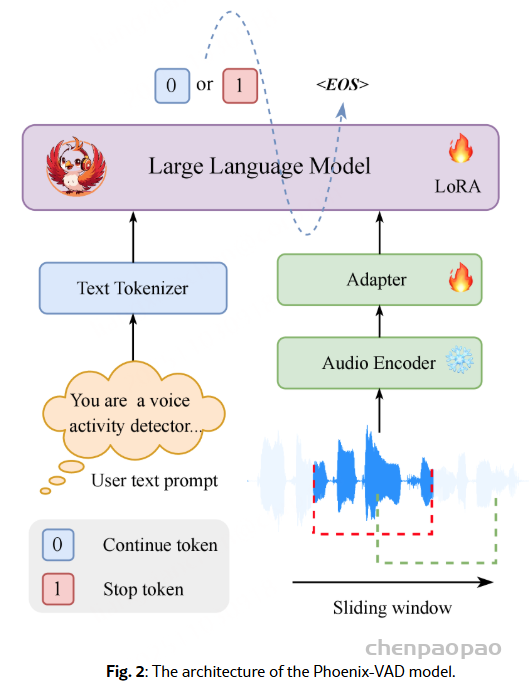
音频编码器:用的是150M参数的Zipformer,之前还在10万多组内部ASR数据上训练过,能把原始语音波形转换成25Hz的“帧级特征”——简单说就是先把语音里的关键信息抽出来,方便后续处理。
适配器:就是两个线性层加个ReLU激活函数,专门解决“音频特征和文本特征对不上”的问题。它先把编码器输出的音频特征,按几帧拼一块做下采样,再转成LLM能“看懂”的文本embedding,最后输出适配好的特征。
LLM:用的是Qwen2.5-0.5B-Instruct,给它喂两样东西:一是适配器处理好的音频特征,二是文本提示(比如告诉它“你是个VAD,要判断用户是不是还在说”),最后让它输出两个结果:要么是“Continue Speaking”(用户还在说),要么是“Stop Speaking”(用户说完了)。
Sliding Window:
滑动窗口策略仅使用每个窗口内的音频进行预测,从而降低了对整个输入序列的依赖。与处理整个序列相比,它能够进行增量式的分块预测,在延迟方面具有潜在优势。同时,该模型可以利用每个窗口内的信息,为语义推理提供足够的局部上下文,并支持流式推理。
针对100Hz的语音特征序列,窗口设成256帧(对应2560ms),每次往前挪32帧(320ms);训练的时候,只盯着每个窗口“最后一个chunk”做监督——不用等整段语音,就能一块一块增量预测,既保留了局部的语义上下文,又能减少延迟,刚好满足实时交互的需求。
在训练过程中,音频编码器被冻结,仅训练适配器和 LLM。LLM 骨干网络使用 LoRa 进行微调,以增强其多模态推理能力。训练目标使用标准交叉熵损失进行优化
Data:
造文本:结合内部的文本资源和ChatGPT API,生成两种文本:一种是“语义完整”的(比如“帮我查一下最新的订单信息”),一种是“语义不完整”的(比如“帮我查<停顿>最新的订单信息”);
合成音频:用Index-TTS工具把文本合成语音,为了模拟不同人的声音,还从库里随机选了1007个英语、1010个中文说话人的声音模板;另外还故意插点静音段,还原真实聊天里的“犹豫、中断”场景;
标标签:用Paraformer工具给每个字标上时间戳,再根据“用户停止说话”的时间点,标两种训练标签:“Continue”(还在说)和“Stop”(说完了)。还特别设置了不同的超时阈值:语义完整的话,等400毫秒就判断“说完了”;不完整的话,等1000毫秒,避免提前打断用户。
Experiments:
用40万条音频(总共570小时)训练,然后拿2000条“语义完整”+2000条“语义不完整”的音频做测试:
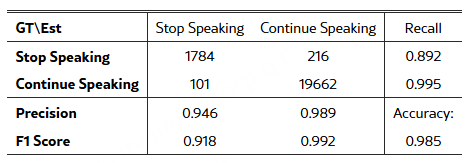
语义不完整的场景里,准确率98.5%,“说完了”的F1分数0.918,“还在说”的F1分数0.992
语义完整的场景更稳,准确率98.6%,“说完了”F1 0.905,“还在说”F1 0.993
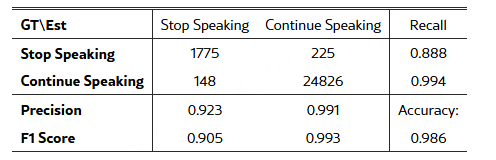
简单说就是,判断“用户还在说”几乎不会错,判断“说完了”也很靠谱。
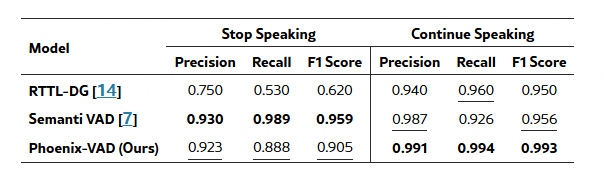
对比其他开源VAD:
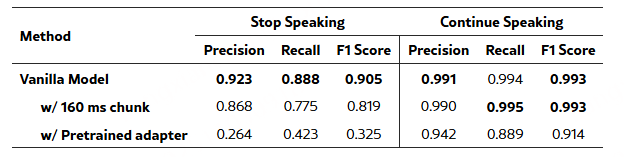
消融实验:
如果把滑动窗口的步长从320毫秒缩到160毫秒(更细的粒度),性能会下降——因为太细的粒度会让判断更犹豫,还会放大时间戳标注的误差;如果适配器只在ASR数据上训练,也不如“联合训练”效果好,因为ASR数据只关注“语音转文字对不对”,缺了“判断说话边界”需要的时间线索。
Phoenix-VAD最核心的价值就是:靠LLM的语义理解能力,加上滑动窗口的实时 trick,弄出了一个“靠谱、实时、能随便用”的语义端点检测模块,刚好补上了全双工语音交互的短板。以后优化方向:一是让模型能过滤“没用的声音”(比如背景噪音、无意义的嘟囔);二是用真实场景的录音再训练,让它在实际聊天里更好用;最后打算把它装到端到端的对话系统里,让整个交互更顺畅。