
- 论文:Contextual Biasing for LLM-based ASR with Hotword Retrieval and Reinforcement Learning
- 作者:阿里巴巴通义实验室
- 论文链接:https://arxiv.org/abs/2512.21828
- GLCLAP: A Novel Contrastive Learning Pre-trained Model for Contextual Biasing in ASR: https://www.isca-archive.org/interspeech_2025/kong25_interspeech.pdf
在真实业务里,如果你做过语音识别落地,大概率会遇到类似的崩溃瞬间:
- 在医疗场景,医生口述一长串药品名、病理名,模型能把普通口语识得很好,一到专业名词就开始「编」,还经常把词表里没出现的药名硬说出来;
- 影视媒体、短视频领域,剧名、角色名、艺人名每天都在更新,热词词表轻轻松松几十万条,模型一旦“认不住、认不准”,用户搜不出东西。
即使对于LLM-ASR这种强大的语音识别模型,在落地过程中也绕不开热词这个话题。
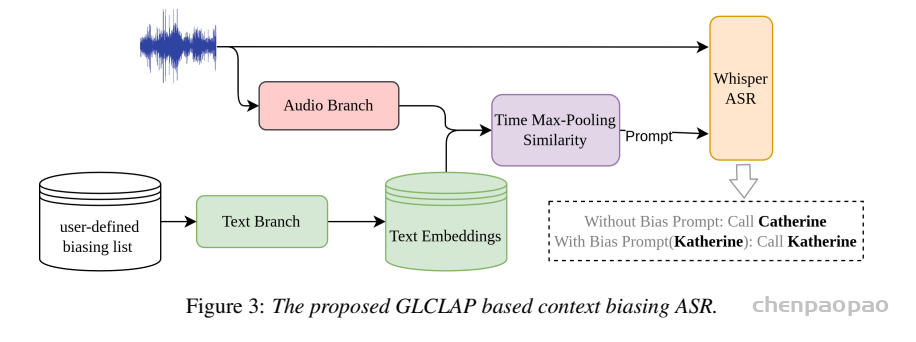
通义最新工作中提出了一个面向 LLM-ASR 的可扩展上下文偏置框架,把“热词检索 + LLM 自适应 + 强化学习”串成一套系统,在大规模热词场景(近 10 万规模词表)下显著提升了热词识别能力,同时提升了整体识别效果。具体来说,首先,扩展了 Global–Local Contrastive Language–Audio Pre-trained(GLCLAP)模型,通过具备鲁棒性的数据增强与模糊匹配机制,从大规模词表中检索出一个紧凑的 top-k 热词候选集合。其次,将检索到的候选热词以文本提示的形式注入到 LLM-ASR 模型中,并采用GRPO进行强化微调,使用任务驱动的奖励函数同时优化热词识别性能和整体转写准确率。
总体框架:检索 + 强化学习,两阶段协同
- 热词检索(Hotword Retrieval):
从大词表中,为当前语音检索出一小撮最相关的 top-k 热词; - 热词感知 ASR 适配(Hotword-aware ASR Adaptation):
把检索出的热词以 prompt 形式喂给 LLM-ASR,并用强化学习优化其使用策略。
整体结构可以类比为语音版的 RAG(Retrieval-Augmented Generation):
- 检索侧:基于改进版 GLCLAP(Global–Local Contrastive Language–Audio Pre-trained Model)做音频 ↔ 热词文本的匹配;
- 识别侧:把检索到的热词放到 LLM-ASR的文本 prompt 中,用 GRPO(Generative Rejection-based Policy Optimization)做 RL 微调,让模型学会:
- 对真正出现的热词要“认得准”;
- 对没出现的热词不要“瞎猜”;
- 兼顾整体转写的 WER / 句子准确率。
增强版 GLCLAP 热词检索
GLCLAP 检索器以音频信号 x 及候选偏置词集合 G={g1,g2,…,gN}作为输入,其中 N 表示候选词表的规模。该检索器由两个组件构成:音频编码器(A-enc)和文本编码器(T-enc)。对于输入音频,A-enc 提取一个固定维度的音频嵌入表示,记为 haudio。同时,候选集合中的每一个偏置词 gi∈G 通过 T-enc 编码为对应的语义向量 ei,从而得到文本嵌入集合 E={e1,e2,…,eN}。随后,我们计算 haudio 与集合 E 中所有文本嵌入之间的相似度得分,并选取得分最高的 top-k 个偏置词,构成子集 G′。这些被选中的偏置词随后被拼接到偏置提示(bias prompt)中,以引导模型进行上下文感知的转写。
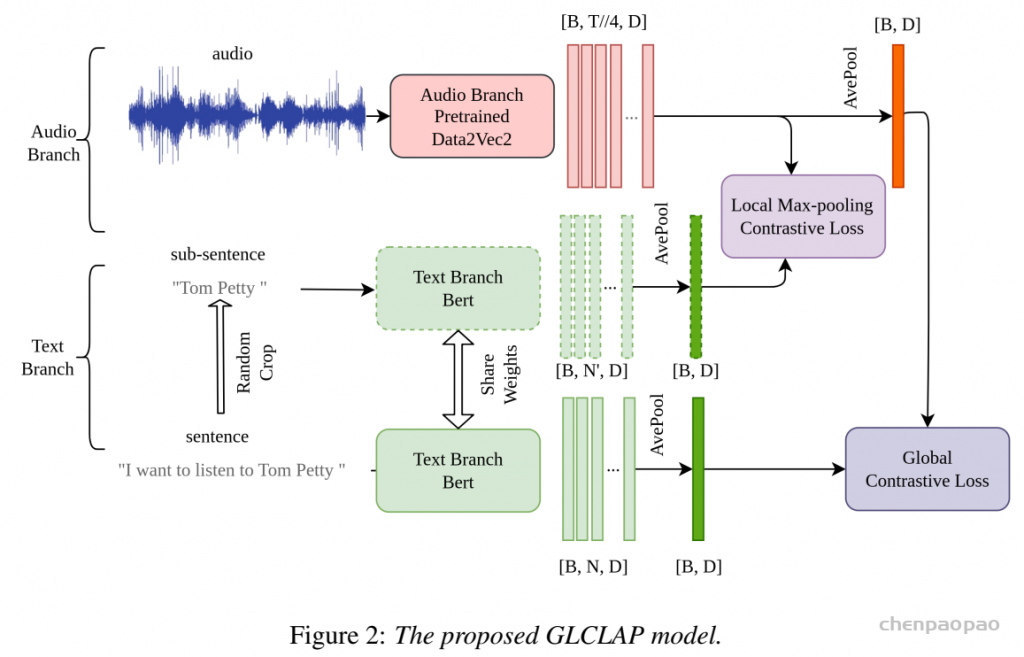
本文对 GLCLAP 又做了两方面增强。
Robustness-Aware Data Augmentation(RADA)。
为缓解热词规模扩大会导致召回率下降及干扰项增多的问题,我们构建了一套鲁棒性感知数据增强(RADA)流程,用于缩减热词词表规模。初始热词词表通过网络爬取领域相关的热词构建得到。对于候选集合 G 中的每一个偏置词 gi,我们首先利用TTS系统合成对应语音(在必要时由大语言模型生成上下文文本),随后使用现有的 ASR 系统对合成语音进行解码,以检测原始 LLM-ASR 是否已具备对该热词的稳定识别能力。若该热词能够被可靠识别,则将其从热词词表中移除;反之,则保留该词作为后续偏置建模的目标。通过该流程,模型训练与推理阶段仅需关注真正具有识别难度的热词,从而提升整体检索与偏置效果。结果:词表规模从 60 万缩减到约 9.8 万。
- 检索难度显著降低;
- 减少大量“干扰”的词,后面 LLM-ASR也不会被这些词干扰。
模糊匹配策略(Fuzzy Matching Strategy):
在实际应用场景中,热词往往难以通过严格的词面匹配进行约束,否则将导致热词词表规模急剧膨胀,进而降低系统的可扩展性。然而,在 GLCLAP 的训练过程中,热词通常通过严格的词汇级匹配进行约束,这与真实部署环境存在不一致性。在真实场景中,用户可能会使用目标热词的不同形态(如屈折变化)、语义改写(paraphrases)或仅部分提及目标术语。为弥合训练与部署之间的差异,我们在 GLCLAP 训练阶段引入模糊匹配策略,使模型能够学习到更具语义与发音鲁棒性的热词表示,从而提升在复杂真实场景下的检索与上下文偏置能力。
真实场景中,用户说的热词常常不是词表里的标准形式,比如:
- 说一个药品名,可能有胶囊、颗粒、口服液等。
- 说一个影片名,可能有第二部、续、新xxx等。
如果训练中的监督只允许严格的字面匹配,检索模型就会对这些变体缺乏鲁棒性。因此,本文引入了 fuzzy matching(模糊匹配策略),在训练阶段引入了由生成式上下文句子嵌入以及经过刻意扰动的偏置词变体所构成的数据增强。
- 在训练数据中增加多种变体:人为扰动词形,如Tongyi → Tongyi abc等;
这样做的效果:
- 更贴合真实业务中“词形变动、说法多样”的场景;
- 检索模型对热词的语义及形态变体更鲁棒。
LLM-ASR
LLM-ASR 网络由音频编码器、适配器以及LLM三部分组成。本文选用 Qwen2.5-7B 作为 LLM 主体。在音频编码器方面,将原始的 Conformer 编码器扩展为 Conformer-MoE 编码器,具体做法是在每一层 Conformer 中,将第二个前馈网络(FFN)模块替换为混合专家(MoE)结构。我们定义了 KC个候选专家,并通过router从中选择 KS个专家进行加权聚合,同时保留一个专用的共享专家以提供通用建模能力。
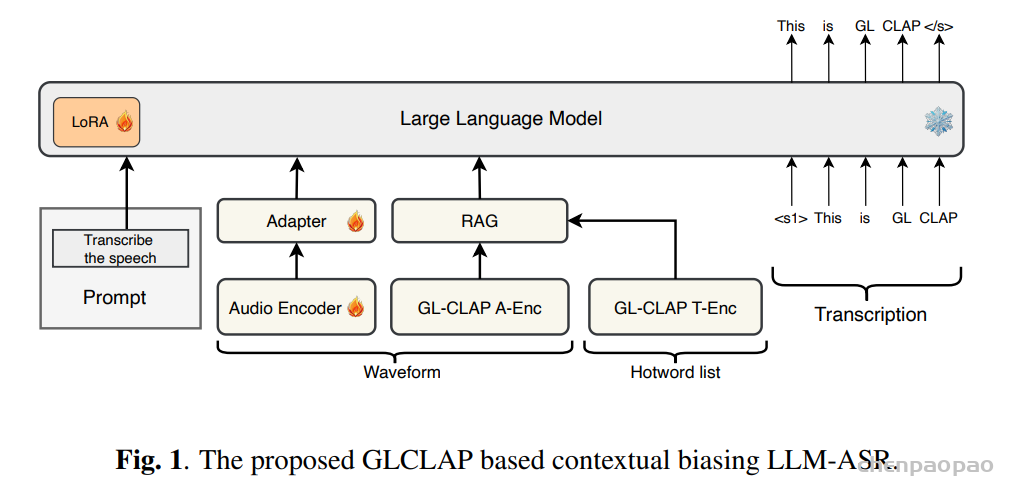
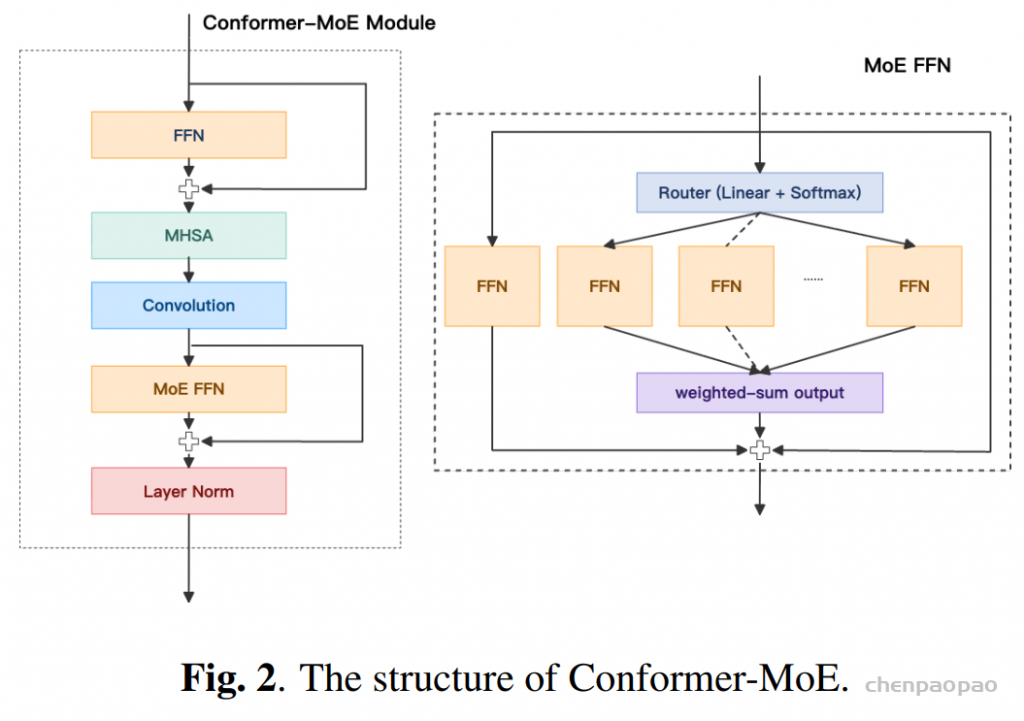
LLM-ASR 模型总参数规模为 10.5B,其中推理阶段的有效激活参数量为 8.7B。整体架构由一个 3.5B 参数规模的音频编码器和一个 LLM 解码器组成。编码器采用 CNN 前端并接入 20 层 Conformer-MoE 结构。CNN 前端首先对输入特征进行 4× 的时间维下采样,随后将得到的特征送入 Conformer-MoE 堆叠模块。每一层 MoE 采用 3-of-8 的专家路由策略,隐藏层维度为 3584。
编码器的输出进一步经过一次 2× 的帧级下采样与特征拼接操作,随后通过一个两层线性适配器(adapter),最终作为输入送入 LLM 解码器。在基础训练阶段,仅对 LLM 部分施加 LoRA微调,其中 LoRA 的秩(rank)设置为 64,缩放系数(alpha)为 32。在上下文偏置训练阶段,学习率设为 1×10−5,并联合更新音频编码器、适配器以及 LLM 的 LoRA 参数。在 GRPO 训练阶段,继续使用相同的学习率(1×10−5),但冻结编码器和适配器,仅更新 LLM 的 LoRA 参数。此外,我们将 KL 散度正则项的权重设置为 0.04,并在每个训练步骤中生成 6 个候选响应用于策略优化。
基于强化学习引导判别的上下文 ASR
为抑制由上下文偏置引入的误检(false positives),我们充分利用 ASR 模型在解码阶段对偏置词进行判别的能力。模型采用结构化提示(structured prompt)进行训练,形式如下:
“<Audio> 请将音频转写为文本。可使用的偏置词包括:<g₁> <g₂> … <gₖ>”。
其中,提供的偏置词列表刻意包含与当前语音无关的词项或干扰词,以避免模型过度依赖偏置词并提升其判别能力。
除上述数据层面的增强策略外,我们在 LLM-ASR 训练过程中进一步引入生成式拒绝式策略优化(Generative Rejection-Based Policy Optimization,GRPO) 这一强化学习方法,以增强模型对偏置词的区分能力。所设计的奖励函数联合优化多个目标,具体包括:
- 匹配奖励(match reward):若某候选偏置词同时出现在模型输出与参考标注中,或同时未出现在二者中,则奖励值为 1;否则奖励值为 0;
- 基于 WER 的奖励(WER-based reward):奖励定义为 1−WER,以保证整体转写准确率。
在推理阶段,为进一步提升性能,我们采用联合束搜索(joint beam search)策略,同时解码无上下文约束(context-free)与上下文条件化(context-conditioned)的候选假设。在保留检索增强生成(Retrieval-Augmented Generation,RAG)优势的同时,该策略有效降低了由无关偏置词引发的幻觉问题。
数据集和效果
Context-Biasing Training Datasets
LLM-ASR 系统在总计数百万小时的语音数据上进行训练。本文重点关注上下文偏置相关的数据设置。在完成基础 LLM-ASR 训练之后,进一步使用约 200 万条与热词和/或上下文历史相关的语句对模型进行微调,这些语句主要通过 RADA 流程生成。在训练数据构成上,包含热词/上下文的语句与不包含热词/上下文的语句按 1:8 的比例进行混合,其中非偏置数据占主导,以避免模型对上下文偏置的过度依赖。对于包含热词的语句,每条语句包含 1–10 个热词,其中约一半语句包含正确的目标热词,另一半不包含目标热词,从而在正、负热词样本之间形成 1:1 的比例平衡。
GLCLAP微调数据
在大规模通用 ASR 数据上对模型进行训练,其中文本标注通过从完整转写中随机裁剪短语的方式获得。随后,在第二阶段对 GLCLAP 检索器进行微调时,我们构建了一个面向特定领域的音频–文本数据集,规模约为 25 万对,以更好地使检索结果与偏置词所属领域对齐。
热词词表(Hotword Vocabulary)
热词词表通过网络数据构建,主要覆盖医疗和媒体(影视)两个领域。在得到初始词表后,进一步采用 RADA 策略进行过滤。经过基于 RADA 的筛选,热词词表规模由约 60 万条缩减至 9.8 万条,有效降低了词表规模并提升了可用性。
评测设置(Evaluation)
构建了两个面向特定领域的测试集:Media 和 Medical,每个测试集包含 240 条语句,主要来源于实际系统中的错误案例(bad cases)。每条语句均由人工标注其真实偏置词,并将这些偏置词加入偏置词列表中。此外,我们还构建了一个回归测试集 General Task,包含约 5,000 条标准 ASR 语句,用于评估通用识别性能。
ASR 评测中,我们采用两项指标:(i)句级识别准确率(Sentence-level Accuracy,SACC),以及(ii)关键词错误率(Keyword Error Rate,KER)。
结果
在 Media 和 Medical 测试集上评估基于 GLCLAP 的热词检索性能。如表 1 和表 2 所示,鲁棒性感知数据增强(RADA)与模糊匹配策略均对整体性能产生了正向贡献。具体而言,原始热词词表约包含 60 万条词项,在应用 RADA 筛选后缩减至 9.8 万条。模糊匹配不仅更契合我们的评测指标,同时也更真实地反映了实际应用场景中的偏置词使用情况。此外,结果显示,随着 top-kkk 值的增大,召回率呈持续上升趋势。
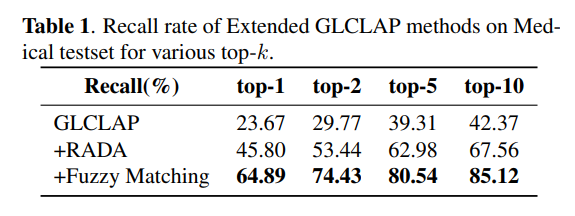
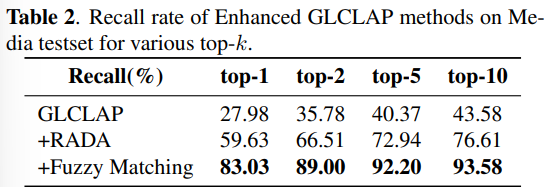
将 GLCLAP 与 LLM-ASR 模型结合,并以句级识别准确率(SACC)和关键词错误率(KER)报告最终识别性能。Base 列显示了在不使用任何偏置提示(bias prompt)的情况下,经过上下文感知微调的 LLM-ASR 模型的结果。
召回率随着 top-k 的增加持续上升,但在热词测试集上的 KER 和 SACC 并未呈单调改善。这是因为较大的 top-k 会向 LLM-ASR 模型引入更多干扰候选词,从而增加识别干扰。
在 General Task 测试集上,大多数结果略低于未使用热词的基线表现。综合两个热词测试集的结果,我们认为 top-2 是更为合适的选择。
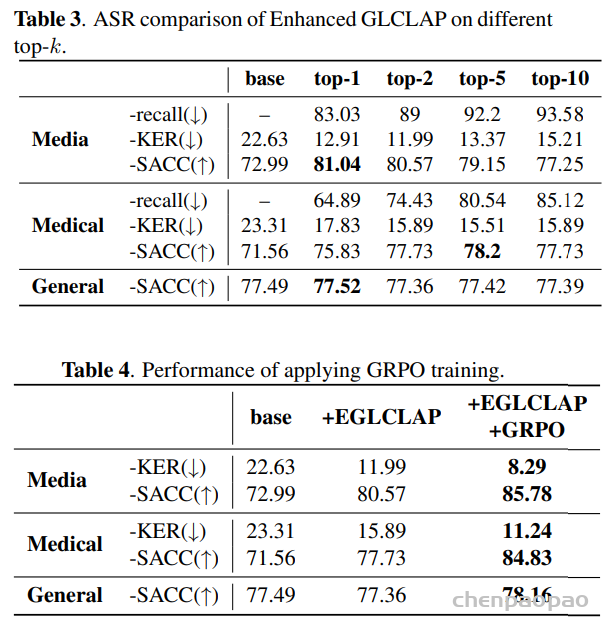
GRPO 训练的结果表 4,引入 GRPO 可以在媒体和医疗设备上的 KER 中产生明显的性能提升。 此外,得益于GRPO中使用的基于准确性的奖励,通用任务的句子准确性也得到了显着提高。
工程与落地视角的一些启发
从工程落地的角度,这篇工作有几个特别值得实践参考的点:
- 不要盲信“全量热词表”:
- 用 RADA 先筛一遍“模型已熟练掌握”的词,再做偏置,能大幅降低复杂度与干扰;
- 检索与解码要协同设计:
- 仅有高召回的检索还不够,要与 LLM 的使用策略共设计,否则容易“给了武器但不会用”;
- RL 对 ASR 也非常有用:
- 传统 ASR 多用 CE/CTC/Transducer 等损失,很难直接对接任务级指标;
- 引入类似 GRPO 这样的 RL 方法,可以在“热词识别 + 句子准确”这样的组合目标上做更直接的优化;
-
top-k 是个关键的“工程超参”:
- k 太小,召回不足;
- k 太大,干扰过多;
- 最优点依赖业务场景、词表质量与 LLM 容量,需要通过系统性实验来选。