
- GLCLAP: A Novel Contrastive Learning Pre-trained Model for Contextual Biasing in ASR
- https://www.isca-archive.org/interspeech_2025/kong25_interspeech.pdf
小米团队提出了一个叫GLCLAP的预训练模型,专门解决ASR(自动语音识别)里的“上下文偏向”问题——简单说就是让ASR更准地识别那些领域特定词汇(比如人名、地名),还不用微调原ASR模型。
传统的上下文偏置 ASR 解决方案中,主要存在两种范式。第一种依赖发音词典,例如基于加权有限状态转换器(WFST)的相关方法。这类系统利用预先定义的发音信息来提升特定术语的识别准确率。第二种范式是将偏置机制直接融入 ASR 模型结构中,通过与 ASR 模型进行联合训练来实现 ,典型代表包括 SeAco-Paraformer。
然而,这两类系统都不利于在支持 prompt 的 ASR 场景中处理偏置词。对于基于 WFST 的系统而言,获取少数语言或方言的发音词典往往十分困难;而端到端的上下文偏置方法通常需要修改 ASR 模型结构并进行联合训练,这在 prompt 支持的大模型范式下缺乏灵活性,难以快速更新和迭代。同时,大模型训练本身需要大量时间和计算资源,成本较高。
大语言模型(LLMs)中引入的提示机制与检索增强生成(Retrieval-Augmented Generation,RAG)为此提供了重要启示。RAG 通过优化提示来获得期望输出,而无需修改 LLM 的网络结构或进行微调。受这一范式的启发,偏置提示的生成可以作为一个独立模块,与识别过程进行解耦。这样,模型既不需要依赖发音词典,也不必在训练阶段依赖 ASR 模型本身。该方法与当前的大模型框架高度契合,能够利用 RAG 思路实现大规模的上下文偏置增强。
之前常用的多模态预训练模型CLAP(对比语言-音频预训练),只能做“句子级”的音频-文本匹配——但偏向词往往只是音频里的一小段(比如句子里的“Taylor Swift”),CLAP抓不住这种局部信息。所以就搞了GLCLAP,同时抓“全局”(整句语义)和“局部”(偏向词细节)的信息,专门适配偏向prompt生成。
本文的主要贡献如下:
- 利用音频-语言预训练模型生成用户自定义的偏置提示;
- 提出全局-局部对比式语言-音频预训练模型(GLCLAP),能够在不同尺度上提取音频信息,显著提升句内偏置提示的准确性;
- 将基于 GLCLAP 的偏置提示生成组件集成到 ASR 模型中,在无需微调的情况下对解码结果进行纠正。
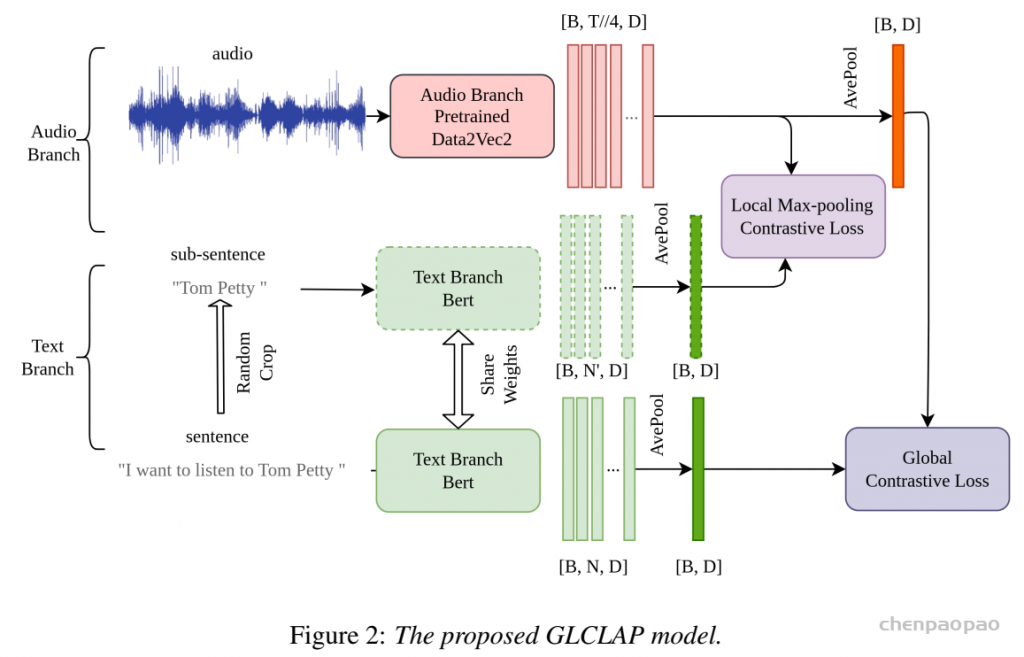
Proposed Method
Local Subtext Extraction for CLAP
主要目标是将音频嵌入与从用户定义的偏向列表生成的嵌入进行对齐。通过计算这些嵌入之间的相似度,可以确定提供最佳匹配的偏向。如图1所示,原始的CLAP模型旨在捕捉整个音频和文本输入的语义信息。然而,它与偏向词检索任务并不完全兼容,因为偏向词通常是整个句子的一部分。为了克服这一限制,对训练过程进行了修改。具体来说,从原始文本注释中随机提取子文本。这种方法有助于增强模型对句子中短语境的表示能力。
全局-局部对比学习模型(GLCLAP)
文本分支:在文本处理方面,除了原始的处理方法(称为全局分支),还添加了一个局部分支来处理子文本。设ft(.)为文本编码器。局部分支和全局分支共享相同的权重,其后均连接一个平均池化层p(.)以降低词维度。全局分支从完整文本Xt ∈ RB×N 中捕获嵌入Et,而局部分支专注于为子文本Xt′∈ RB×N′提取嵌入Et’,其中N表示文本标记N’ ≤N的数量 :
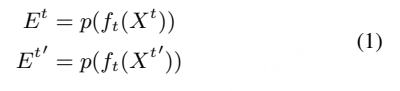
音频分支:音频输入是“梅尔频谱”(Mel spectrogram),用Data2Vec2.0-large当编码器(Transformer结构,自监督预训练过,支持中英)。这里有个巧思:在平均池化前后都做对比学习——因为音频的局部信息是“时序相关”的,直接池化会丢信息。
- 局部音频embedding(Ea’)包含时序(局部信息):编码器输出的原始结果,形状[B, T//4, D](T是音频帧数,//4表示编码器做了4倍下采样);
- 全局音频embedding(Ea)包含全局信息:对Ea’做“时间维度平均池化”,形状[B,D]。

分别对文本和音频的局部表示与全局表示计算对比损失。音频与文本嵌入之间的全局对比损失 Lg定义为:
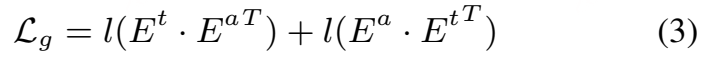
局部 最大池化损失:
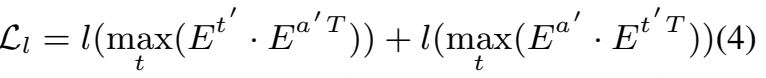
其中,maxt 表示沿时间维度取最大值。
l(⋅)=−B1∑log(diag(softmax(⋅))),其中, diag 表示在对矩阵应用 softmax 函数之后,取其对角元素。该函数用于度量预测分布与目标分布之间的相似性。
GLCLAP for Contextual Biasing ASR
GLCLAP 模型能够检索出与音频最匹配的偏置词,并将其作为提示(prompt)输入 ASR 模型,从而帮助 ASR 更准确地识别那些容易被误识别的低频词。
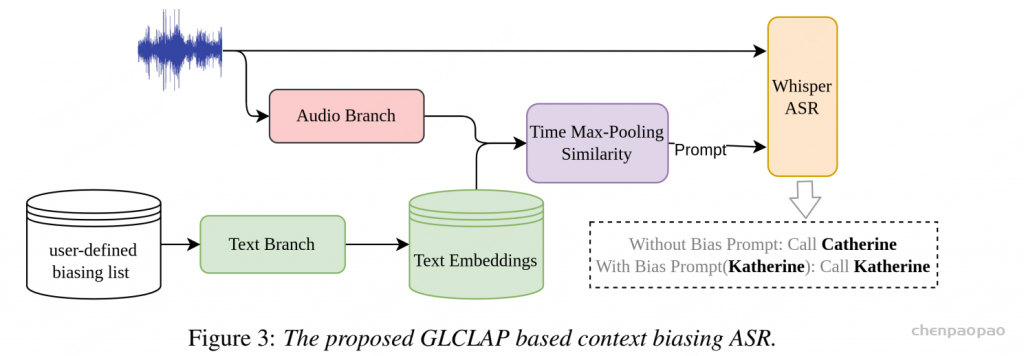
- 先准备“用户定义的偏向词列表”(比如[“Catherine”, “Katherine”]),把这些词输入GLCLAP的文本分支,生成文本embedding(形状[K,C],K是列表长度);
- 把要识别的音频输入GLCLAP的音频分支(不做平均池化,保留时序信息),得到局部音频embedding(E^a’,形状[T,D]);
- 算“相似度矩阵”(Sim = 文本embedding × 音频embedding转置),形状[K,T]——每个元素代表“第k个偏向词”和“第t帧音频”的相似度;
- 对相似度矩阵做“时间维度max池化”,得到一个[K]的向量——每个值是“某个偏向词和整段音频的最大相似度”;
- 把超过“预设阈值”的偏向词挑出来当prompt,和原音频一起喂给ASR(比如Whisper),最后得到更准的识别结果。
实验
关键参数
- 学习率:5e-4;
- batch size:64;
- 训练轮次:100轮(早停防过拟合);
- 对比模型:Base ASR(Conformer架构,1.3亿参数,训过4个训练集)、Base CLAP、Subtext CLAP(只加了子文本提取的CLAP)、LCLAP(只算局部损失)。
音频编码器(Audio Encoder)
我们采用与 Data2Vec2.0-large 相同的网络结构和预训练方式。具体而言,使用的是 Data2VecAudioModel,这是一种基于 Transformer 的架构,专门用于语音表示的自监督学习。该模型在一个私有数据集上进行了预训练,数据集同时包含英文和中文语音数据。
文本编码器(Text Encoder)
文本编码器初始化为 bert-base-multilingual-uncased。该模型由 12 层 Transformer 组成,能够有效地捕获文本中的上下文信息 。
评估指标
- 偏向词检索:用“Top-1召回率”(找对最匹配的偏向词的比例)和“F1分数”;
- ASR性能:用“词错误率(WER)”——越低越好。
(1)偏向词检索效果(表1)对比不同模型的Top-1召回率(%)
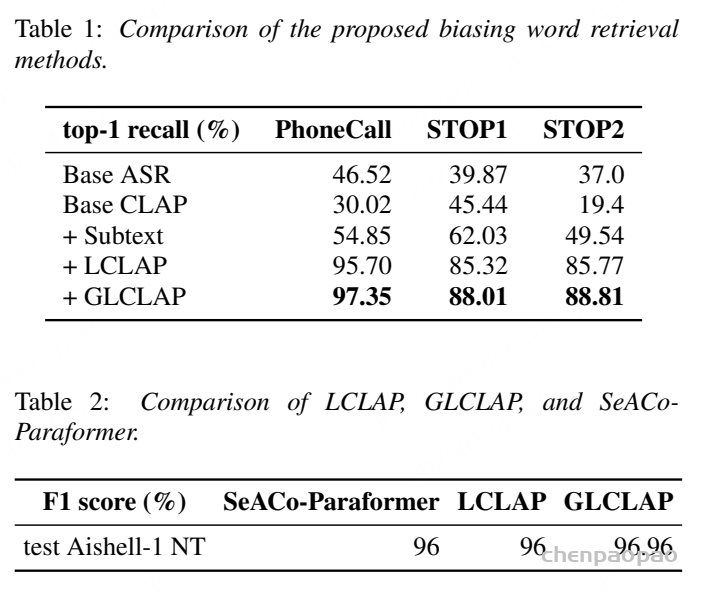
- Base ASR和Base CLAP效果都差,尤其是Base CLAP在STOP2上才19.4%;
- 加了“子文本提取”后明显提升,说明局部信息有用;
- LCLAP已经比Base好很多,再加上“全局分支”的GLCLAP,直接冲到97%左右,不管是人名还是地名场景都稳赢。
还有表2(Aishell-1 test NT的F1):
- SeACo-Paraformer(传统偏向模型):96%;
- LCLAP:96%(打平);
- GLCLAP:96.96%(+0.96%)——比传统模型还强一点。
多模态对齐效果(图4):局部匹配很准
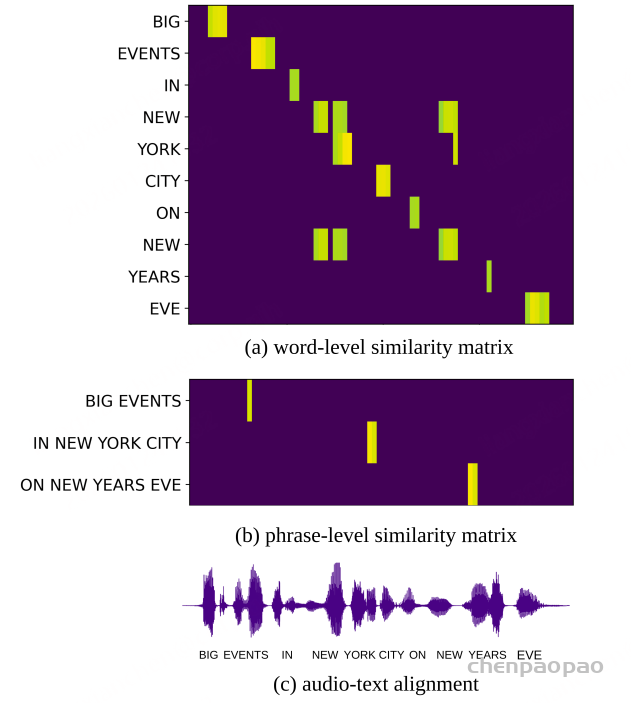
- 图4a(词级):每个词(比如“NEW”“YORK”)都能和音频里对应的时序片段对齐,相似度高的地方很集中;
- 图4b(短语级):“NEW YORK CITY”这种短语也能准确匹配音频片段,不会跟其他部分混;
- 图4c(音频-文本对齐):即使文本有小错误(比如“EVETS”“YOR”),音频还是能和正确的文本片段对齐——说明GLCLAP的局部匹配能力很稳,不会因为文本小错跑偏。
对比Whisper Small加不同prompt模块的WER(%):
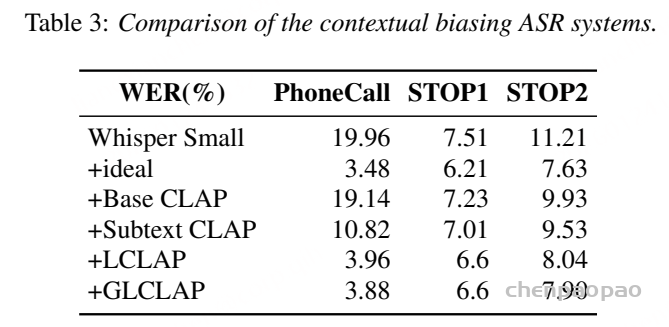
这篇论文最核心的贡献是:用“全局+局部对比学习”解决了ASR上下文偏向的“prompt匹配”问题
- 不用依赖发音词典,也不用改ASR模型、做微调,直接加个独立的GLCLAP模块就行,灵活又省资源;
- 不管是中文还是英文,不管是人名还是地名,GLCLAP的偏向词检索 accuracy都很高,还能实实在在降低ASR的WER;
- 给大模型时代的ASR个性化提供了新思路:用多模态预训练做检索增强,比传统方法更高效。