
- Demo Page:
https://soulx-duplug.sjtuxlance.com/ - Technical Report: 技术报告:
https://arxiv.org/pdf/2603.14877 - Source Code:
https://github.com/Soul-AILab/SoulX-Duplug - HuggingFace:
https://huggingface.co/Soul-AILab/SoulX-Duplug-0.6B - SoulX-Duplug-Eval:
https://huggingface.co/datasets/Soul-AILab/SoulX-Duplug-Eval - 基于SoulX-Duplug的双工对话系统:
https://github.com/Soul-AILab/SoulX-Duplug/tree/dialogue-system
SoulX-Duplug —— 一款面向 全双工语音对话系统的即插即用流式状态预测模块。SoulX-Duplug 旨在解决当前语音对话系统中 实时交互能力不足、系统响应延迟高、模块耦合严重 等问题。通过将 语音活动检测(VAD)、语音识别(ASR)与对话轮次判断(Turn Detection)统一建模,SoulX-Duplug 可以帮助传统的半双工语音系统在 无需修改原有模型架构的情况下,快速获得 全双工语音交互能力。 项目还开源了 SoulX-Duplug-Eval,一个面向全双工语音对话系统的 双语评测基准,以促进该领域更标准化和可比较的研究。
Introduction
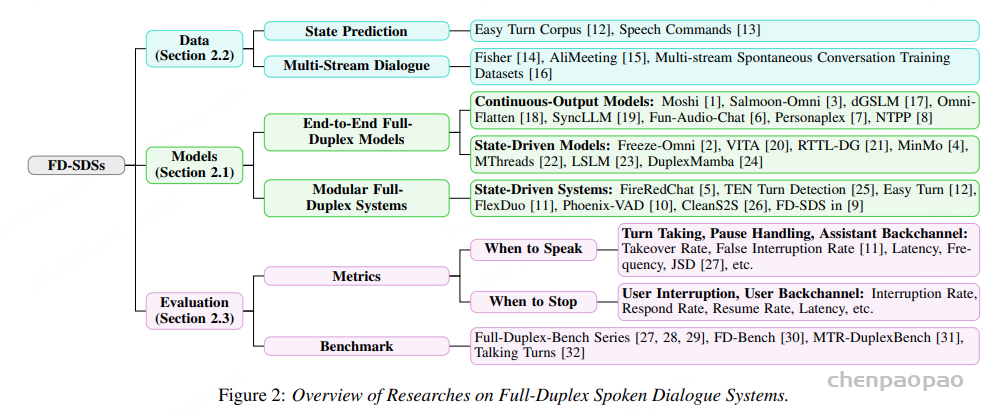
传统语音对话系统通常采用 半双工(Half-Duplex)交互模式:系统在用户说话时只能“听”,而在系统回答时用户则无法打断。这种严格分离的听说流程,使得交互节奏显得机械,也限制了真实对话中常见的打断(interruption)、停顿(pause)、附和(backchannel)等行为。 相比之下,全双工语音对话系统允许系统在生成回复的同时持续监听用户输入,从而支持更加自然的实时互动体验。
近年来,一些端到端全双工语音模型开始出现,但这类方法通常将 语言生成与交互控制强耦合 在同一个模型中,带来了新的挑战:
- 模型训练难度高
- 数据需求巨大
- 交互策略难以控制
- 系统扩展性受限
在实际工业系统中,更常见的方案是通过 VAD + ASR + Turn Detection 等模块组成级联流水线,为半双工系统提供基本的全双工能力。然而,这种方式也存在明显问题:
- 传统 VAD 仅依赖声学特征,缺乏语义理解
- 非流式 ASR 会带来额外延迟
- 多模块级联导致系统响应速度下降
领域内目前仍缺乏开源的流式 semantic VAD 方案。SoulX-Duplug 正是在这样的背景下提出的一种独立、可扩展的解决方案。通过将语音交互中的双工控制能力从对话模型中解耦为独立模块并进行开源,SoulX-Duplug 旨在缓解全双工模型在数据规模与系统扩展性方面的挑战,使语音对话模型的优化能够更多聚焦于记忆能力、推理能力与共情能力等核心智能能力,而不必始终受到全双工交互机制的复杂约束。与此同时,通过引入文本引导的流式状态预测机制,SoulX-Duplug 能够更准确地理解用户语义意图,并在模块化架构下尽可能降低系统延迟,从而实现更自然、高效的实时语音交互体验。

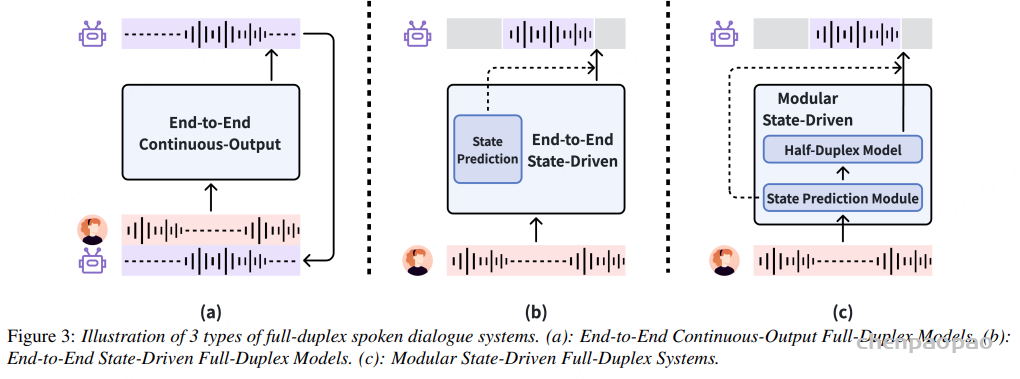
SoulX-Duplug
Overview
SoulX-Duplug 是一个面向实时语音交互场景设计的 统一流式状态预测模块。与传统基于多模块级联的全双工语音系统不同,SoulX-Duplug 在单一模型框架中同时完成:
- 语音活动检测(VAD)
- 流式语音识别(ASR)
- 对话状态预测(Dialogue State Prediction)
通过统一建模这些任务,SoulX-Duplug 能够在持续音频输入的情况下实时理解用户语音内容,并动态预测对话交互状态,从而实现更自然的全双工语音互动。总体架构上,SoulX-Duplug 采用 GLM-4-Voice speech tokenizer 以12.5Hz 的频率提取离散语音 token,取 160ms (2 token) 的处理窗口流式交替生成语音识别文本与对话状态 token。这种设计使模型能够通过语音识别理解语义并判断当前对话状态,从而实现低延迟的交互控制。
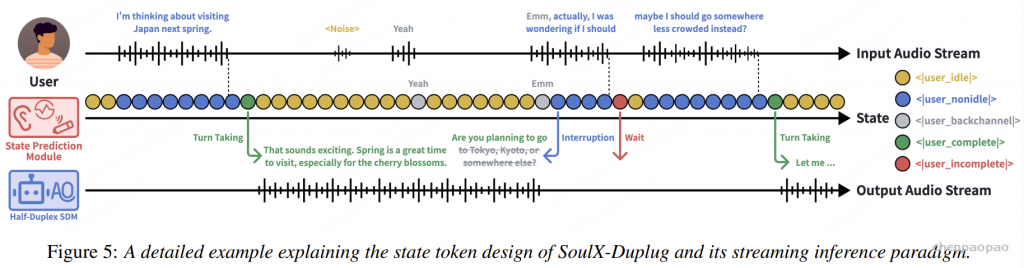
State Token Design
为了刻画全双工语音对话中的交互动态,SoulX-Duplug 定义了五种核心状态 token:
- user_idle 表示当前音频片段不包含语义信息,例如静音或背景噪声。
- user_nonidle 表示用户正在进行具有语义内容的语音输入。
- user_backchannel 表示用户“嗯”“对”等 backchannel 行为。
- user_complete 表示用户当前语句在语义上已经完成,系统可以接管对话轮次并进行回复。
- user_incomplete 表示用户虽然暂时停顿,但语句在语义上仍未结束,系统需要继续等待用户输入。 通过这种定义方式对对话状态进行了清晰、结构化的建模。
Speech Input Modeling
采用 GLM-4-Voice tokenizer,以 12.5 Hz 的频率提取音频 token:
Ad=[ad,1,ad,2,…,ad,N]
该 tokenizer 是一种 block-causal(块因果)语音 tokenizer,在大规模语音数据上预训练,可作为双语语音理解的基础编码器
在流式推理中:
- 使用 block size = 12 进行音频 token 生成
- 每一步处理:
- 目标窗口(target window):160 ms
- 左上下文(look-back):960 ms
- 右上下文(look-ahead):40 ms
因此总感受野(receptive field)为: 1160 ms,共提取 15 个 token。目标区域对应的 token 与 block 中的倒数第二和倒数第三个 token 对齐。随后,通过一个线性 encoder projector,将 Ad 的 embedding 映射为特征 A,以匹配 LLM 的 embedding 维度:
A=MLP(Ad)
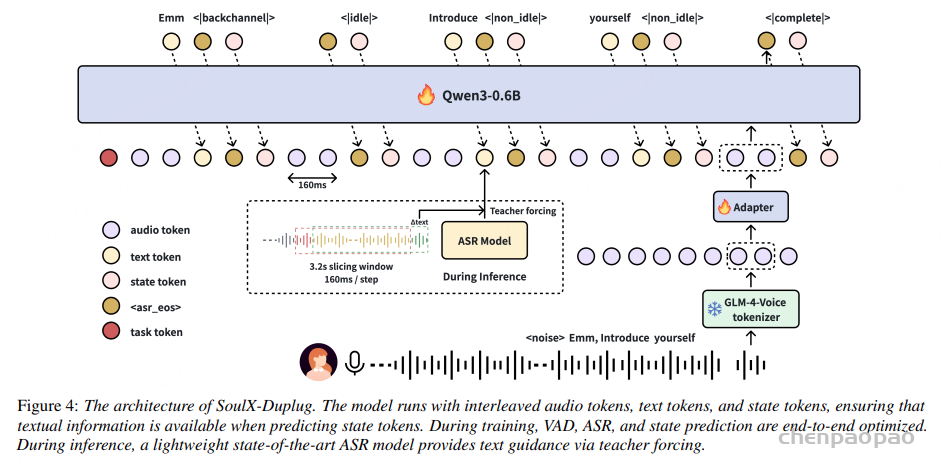
文本引导的流式状态预测
为了在流式状态预测中显式引入语义信息,我们创新性地引入了联合 ASR 目标,并设计了交错预测范式(interleaved prediction):
{A1,T1,S1,A2,T2,S2,…,AT,TT,ST}
每个 160 ms 音频块对应两个音频 token:
At=[at,1,at,2]
在历史上下文 Ht−1条件下,模型首先预测当前块的 ASR token 序列:
Tt∼P(Tt∣A≤t,T<t,S<t)
其中Tt:与第 t 个音频块对齐的流式 ASR 输出,在生成 Tt 之后,模型进一步预测对话状态 token:
St∼P(St∣A≤t,T≤t,S<t)
- St:当前音频块对应的全双工对话状态
这种交错式设计在保持流式推理能力的同时,使状态预测能够获得显式的语义引导。
Training Objective
由于不同类型的 token(例如文本 token、<asr_eos> 以及各种状态 token)在长序列中的出现频率差异较大,我们采用加权的 token 级训练目标。
设:
- Y:完整的目标 token 序列
- yj:第j 个 token
整体损失定义为:
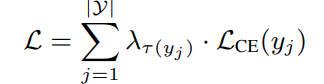
其中:
- LCE(yj):预测 token yj 的交叉熵损失
- τ(yj):将 token 映射到其所属类型(如 ASR token / state token)
- λτ(yj):针对不同 token 类型设置的权重系数,用于在不同类别之间进行训练平衡
三阶段混合训练+ Teacher-Forced 推理
设计了三个顺序训练阶段:
- 非流式 ASR 预训练。目标:学习基础语音识别能力
- 流式 ASR 适配。目标:让模型适应 streaming 场景
- 全双工状态预测微调。目标:强化实时对话管理能力(state prediction)
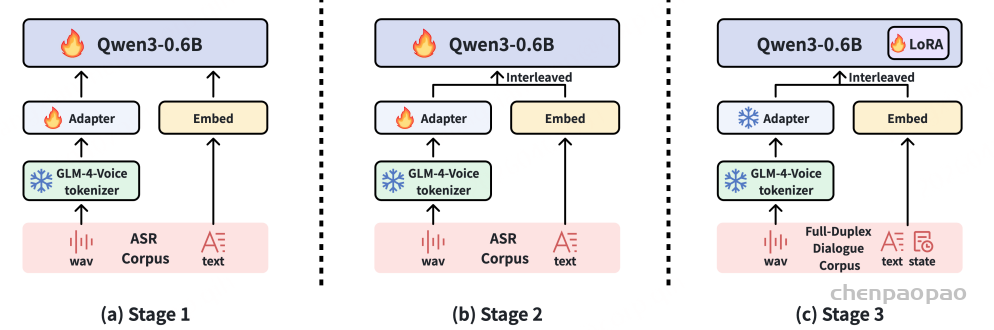
Hybrid 训练-推理策略。SoulX-Duplug 采用训练与推理不完全一致(hybrid)的策略:
训练阶段(第 3 阶段):
- 端到端联合优化:
- VAD + ASR + 状态预测
推理阶段:
- 使用一个轻量级外部 ASR 模型(如 SenseVoice Small)
- 为每个 chunk 提供:
- teacher-forced 的流式 ASR 输出
这个设计的本质:
训练时学“联合建模能力”,推理时用更强/更稳的 ASR 来“喂语义”,提升稳定性和效率。
算法延迟
- 每个 audio chunk = 160 ms
- 用户语音在 chunk tit_iti 内结束
由于模型是流式的:
必须等到下一个 chunk ti+1 才能确认“后面没有语音”
在处理ti+1 时:
- 检测到没有语音(VAD = silent)
- 判定
<|user_nonidle|>结束 - 决策:
<|user_complete|>(语义完成)- 或
<|user_incomplete|>(语义未完成)
由于语音结束点在 chunk 内均匀分布:
- 平均等待时间:80 ms(= 160 / 2)
- 再加一个 chunk:160 ms
最终:
Latencyavg=80 ms+160 ms=240 ms
SoulX-Duplug-Eval
为了解决现有全双工语音对话基准中跨语言评测资源不足的问题,我们构建了补充性的测试集,用于提升不同模型之间的可比性,并在对话状态预测与系统级全双工对话两种评测设置下,实现标准化与公平比较。
提出 Easy Turn testset-En,作为原始 Easy Turn testset 的英文对应版本。
该数据集主要用于全双工状态预测(duplex state prediction),包含两类数据:
Complete(完整句)
- 共 318 条样本
- 内容为语义完整的 utterance
- 由 ChatGPT 生成,并使用 ChatTTS2 [36] 合成
Incomplete(不完整句)
- 共 299 条样本
- 内容为语义不完整的 utterance
- 同样由 ChatGPT 生成并通过 ChatTTS2 合成
为了支持中文场景下的系统级评测,我们构建了 Full-Duplex-Bench-Zh,作为 Full-Duplex-Bench的中文版本。
该数据集覆盖四种具有代表性的交互场景,所有文本均由 ChatGPT 生成,并通过最先进的 TTS 系统合成。
包括:
- Turn-Taking 子集(轮次切换):用户连续说话数秒随后 15 秒静音,评估是否正确判断用户说完
- Pause Handling 子集(停顿处理):单条 utterance 中插入多个停顿,区分自然停顿和语义未结束
- User Backchannel 子集(用户附和):短 backchannel(如“嗯”“对”),防止模型误抢话
- User Interruption 子集(用户中断/续说):是否识别“用户未说完”,是否正确预测
<|user_incomplete|>
实验
训练设置
中文数据总计约 47,000 小时。英文数据共计约 31,000小时。
在流式 ASR 训练中:
- 首先获取 字符级或词级对齐(alignment)【使用 Paraformer3 /WhisperX 生成时间戳】
- 将数据重组为 基于 chunk 的交错格式(interleaved chunk-based format)
状态预测训练阶段(State Prediction Stage):
英文数据:
- 使用 Fisher 数据集 [14]
- 规模:千小时级
中文数据:
- 使用内部构建的约 万小时级语料
- 构造方式与 Fisher 保持一致
数据标注与清洗流程:
- 先进行对齐(alignment)
- 中文数据:
- 使用 双 ASR 一致性过滤
- 数据增强:
- 全局添加 Musan 噪声
- 在静音片段加入 ESC-50 噪声
- 状态标签:
- 使用 Qwen2.5-72B-Instruct进行自动标注
SoulX-Duplug 模型:
- 语音编码器:预训练 GLM-4-Voice tokenizer
- LLM backbone:Qwen3-0.6B [48]
- speech tokenizer:全程冻结(frozen)
训练策略
- ASR 预训练 LLM:全量微调 adapter:全量微调
- 状态预测阶段对 LLM 使用 LoRA ,rank = 32,训练数据:双语 trainsets
推理设置
使用 teacher-forcing ASR 提供更准确文本引导 【中文:Paraformer,英文SenseVoice Small】
为了评估 SoulX-Duplug 的对话状态控制能力:Qwen2.5-7B-Instruct + IndexTTS-1.5
评测指标(Metrics)
- Takeover Rate (TOR)
- Response Latency (RL)
- Resume Rate (RsR)
- Respond Rate (RpR)
- Stop Latency (SL)
结果
为了验证 SoulX-Duplug 在真实系统中的效果,团队以 SoulX-Duplug 作为对话状态控制模块构建了一个完整的全双工语音对话系统,并在中英双语的 Full-Duplex-Bench 基准上对系统进行了全面评测,该 benchmark 涵盖了:Turn Taking(轮次切换)、Pause Handling(停顿处理)、User Backchannel(用户附和)、User Interruption(用户打断)等多种全双工对话关键场景。
实验结果表明,基于 SoulX-Duplug 构建的系统在多个评测维度上取得了稳定且均衡的整体表现。在整体的 turn management 能力上优于现有模型,并在总体响应延迟指标上同样表现优异。这一结果充分验证了 SoulX-Duplug 的对话状态控制能力以及在系统构建中的实用价值。
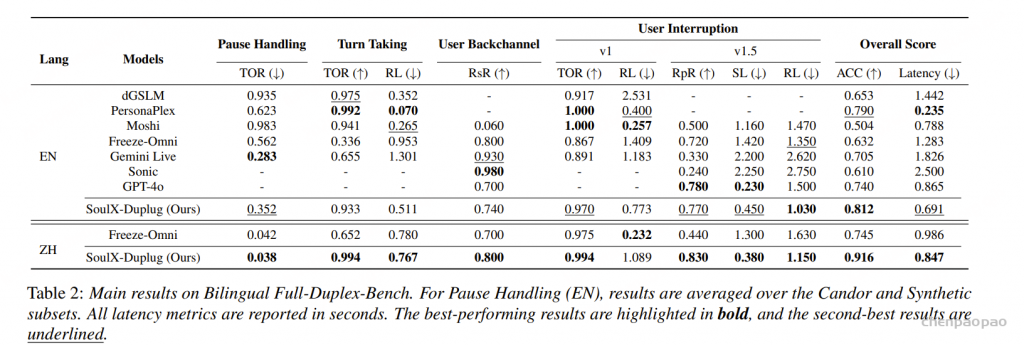
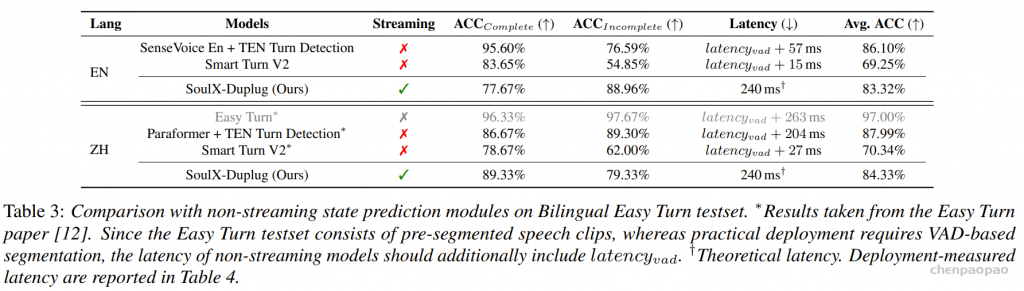
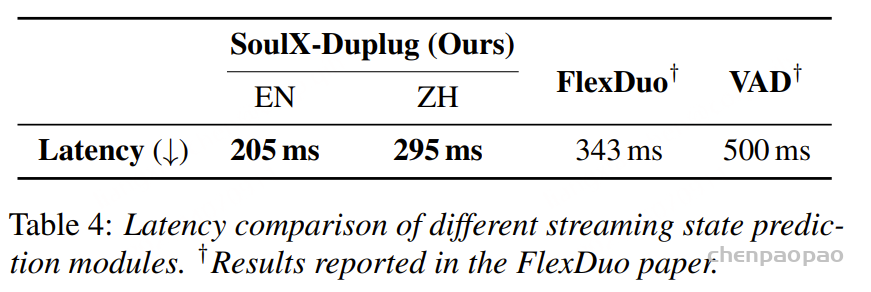
同时,实际部署环境中 SoulX-Duplug 的独立模块的平均延迟约为 250ms,接近其理论延迟 240ms。这一结果显著优于传统基于 VAD 的方案(约 500ms),也低于近期提出的 FlexDuo 模块(约 343ms)。
Further Discussion
围绕全双工语音对话系统(FD-SDS)的设计与部署形成了若干观察与思考:
1、小 chunk 流式 ASR 识别效果较差
采用非常小的 chunk size 进行流式 ASR 在本质上仍然具有较大挑战。当 chunk 时长较短时,声学片段经常会跨越音素、音节或词边界被切分。这一问题在英语中尤为明显,因为单词很容易被切分到相邻的多个 chunk 中,从而导致识别不稳定以及瞬时错误。因此,在严格低延迟约束下,预测波动在一定程度上是不可避免的。此外,在实时流式场景中,基于 LLM 的方法虽然具有较强的上下文建模能力,但其上下文仍受限于增量解码(incremental decoding)以及有限的未来信息。因此,基于 LLM 的 ASR 模型在“解码速度与识别准确率的综合权衡”方面,并不一定优于传统结构(如 RNN-T)。
2、模块化系统 vs 端到端系统
尽管近年来端到端全双工语音对话模型(FD-SDMs)在经验表现上取得了较强效果,并展现出较大潜力,但它们通常需要大规模训练数据与较高计算资源。相比之下,模块化系统更易于实现与维护。当系统出现性能问题时,可以在不重新训练整个系统的情况下,对单个模块进行调整或替换。这种灵活性使得模块化设计在实际部署中可能更具优势
最后,目前的研究工作对实时应用的支持仍然相对有限。仍然需要更加成熟且易用的开源流式语音编码器与 ASR 模型。持续推进这一方向的发展,将有助于真正实现可落地的全双工语音对话系统(FD-SDSs)。