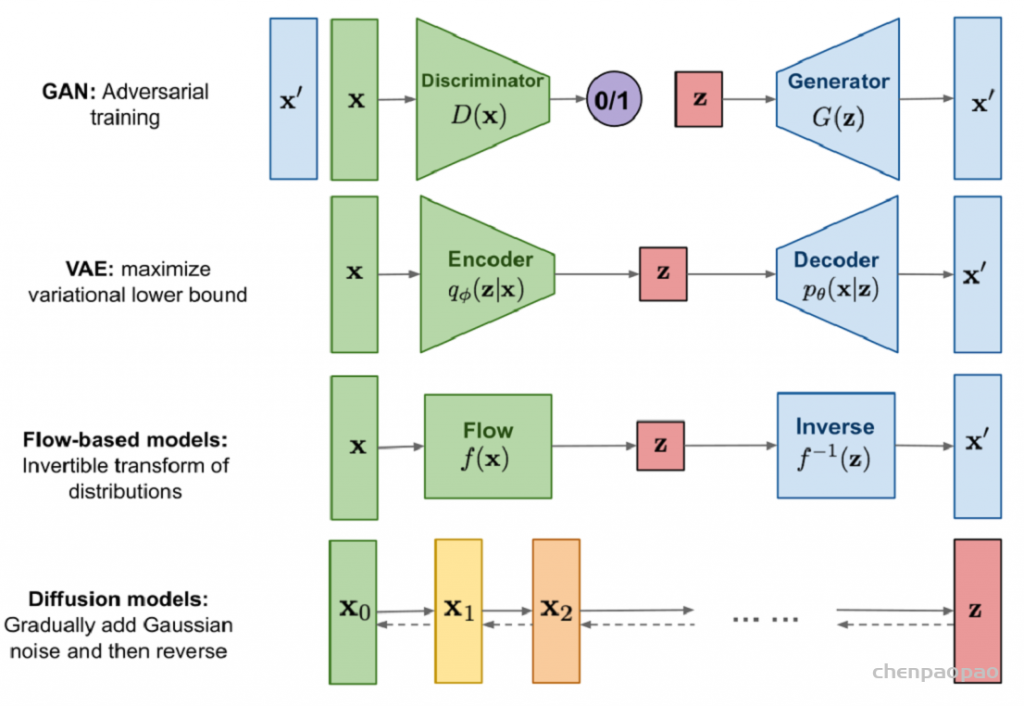
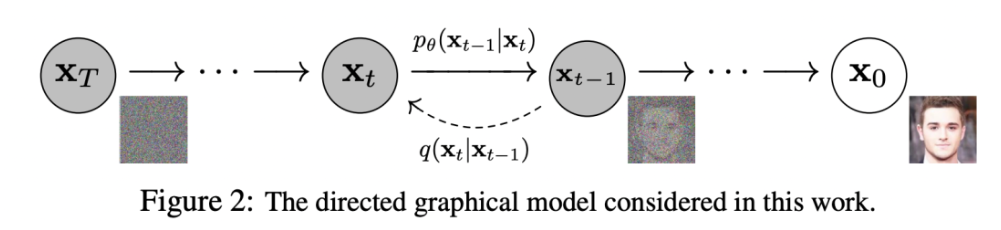
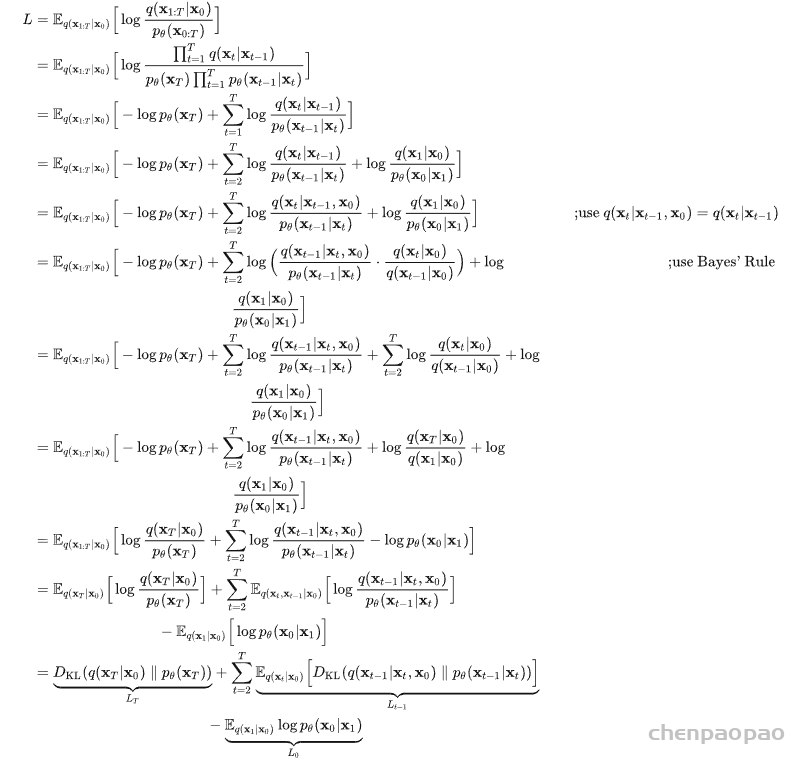
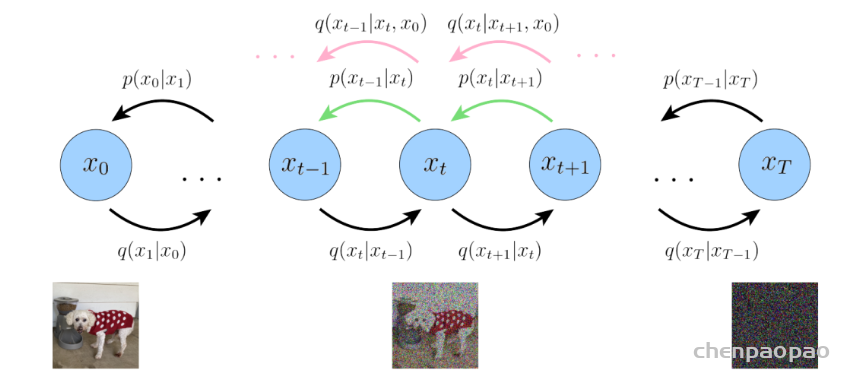
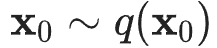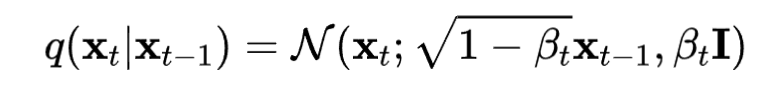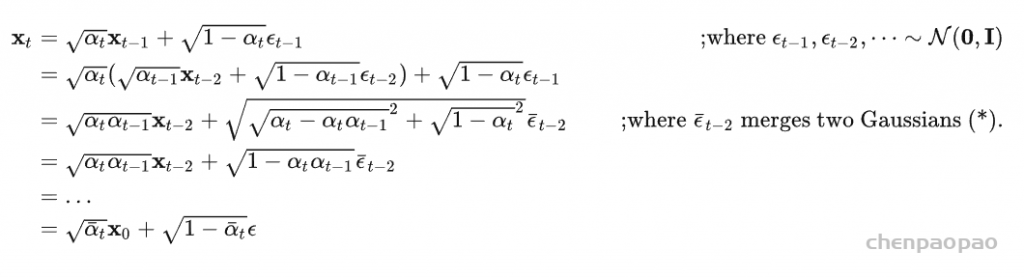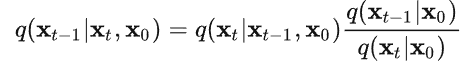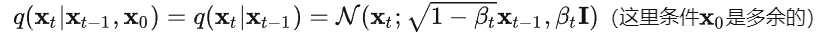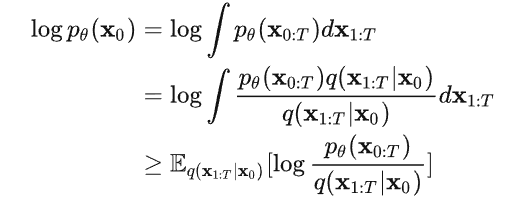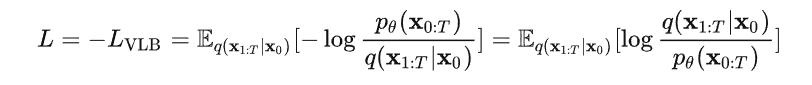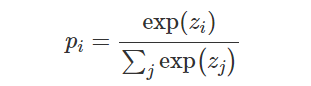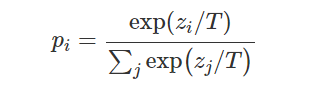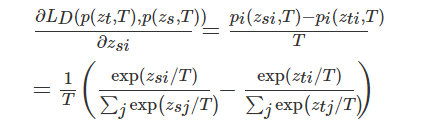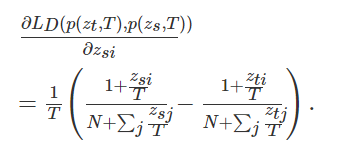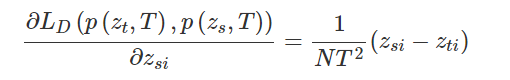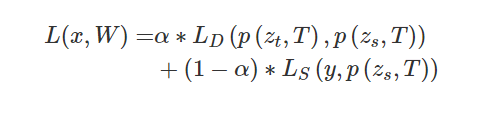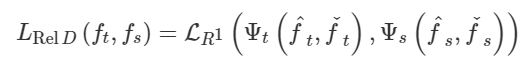摘自:MFEI
Abstract
- 深度学习已经广泛的应用于医疗影像分割领域,大量的论文记录了深度学习在该领域的成功
- 本文中提出了关于深度学习医疗影像分割的综合专题调查
- 本文主要有两项贡献
- 与传统文献做对比
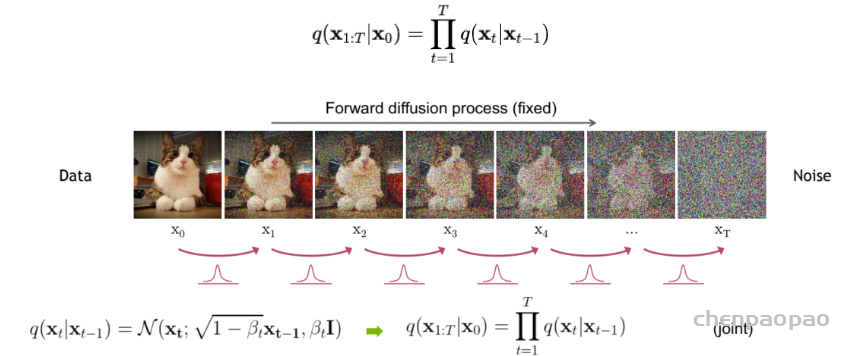
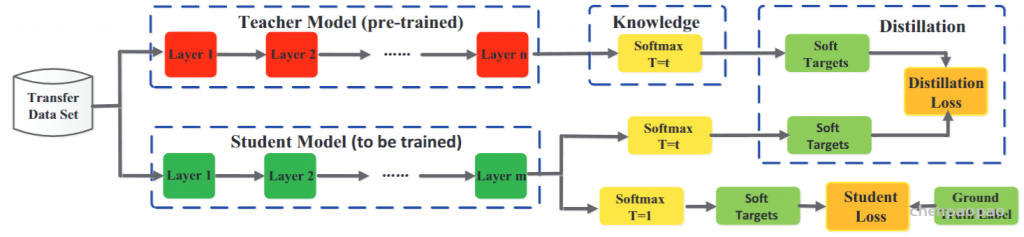
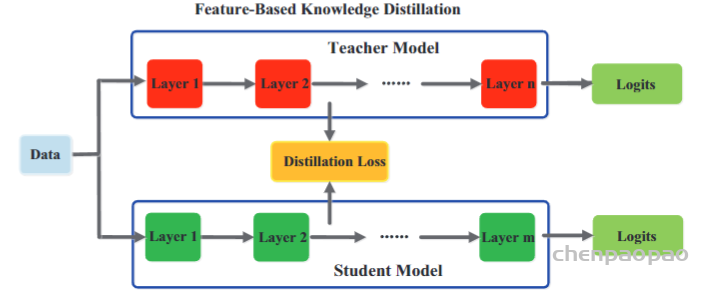
- 本文关注的是监督和弱监督学习方法,不包括无监督方法。对于监督学习方法,我们从三个方面分析了文献:骨干网络的选择、网络块的设计和损失函数的改进。对于弱监督学习方法,我们分别根据数据增强、迁移学习和交互式分割来研究文献。
1 INTRODUCTION

图1 An overview of deep learning methods on medical image segmentation
- 早期的医学图像分割方法往往依赖于边缘检测、模板匹配技术、统计形状模型、主动轮廓和机器学习等,虽然有大量的方法被报道并在某些情况下取得了成功,但由于特征表示和困难,图像分割仍然是计算机视觉领域中最具挑战性的课题之一,特别是从医学图像中提取鉴别特征比正常RGB图像更困难,因为普通RGB图像往往存在模糊、噪声、低对比度等问题。
- 由于深度学习的快速发展,医学图像分割不再需要手工制作的特征,卷积神经网络成功的实现了图像的分层和特征表示,从而成为图像处理和计算机视觉中最热门的研究课题。由于用于特征学习的cnn对图像噪声、模糊、对比度等不敏感,它们为医学图像提供了良好的分割结果。
- 目前图像分割任务有两类,语义分割和实例分割。语义分割是一种像素级分类,它为图像中的每个像素分配一个相应的类别。与语义分割相比,实例分割不仅需要实现像素级的分类,还需要根据特定的类别来区分实例。
- 很少有应用于医疗影像分割的实力分割,因为每个器官和组织是很不同的。本文综述了深度学习技术在医疗图像分割方面的研究进展。
- 监督学习的优点是可以基于精心标记的数据来训练模型,但很难获得大量的医学图像标记数据。无监督学习不需要标记数据,但学习的难度增加了。弱监督学习是在监督学习和无监督学习之间,因为它只需要一小部分标记的数据,大多数数据是未标记的。
- 通过对以上调查的研究,研究者可以学习医学图像分割的最新技术,然后为计算机辅助诊断和智能医疗做出更重要的贡献。然而这些调查存在两个问题。
- 1)大多按时间顺序总结了医学图像分割的发展,因此忽略了医学图像分割深度学习的技术分支。
- 2)这些调查只介绍了相关的技术发展,而没有关注医学图像分割的任务特征,如少镜头学习、不平衡学习等,这限制了基于任务驱动的医学图像分割的改进。
为了解决这两个问题我们提出了一个新的Survey,在这项工作中我们的主要贡献如下:
- 深度学习医疗影像分割技术从粗到细的分支,如图1所示
- 对于监督学习的方法,我们从三个方面分析了文献:
- 骨干网络的选择
- 网络块的设计
- 损失函数的改进
回顾了来自处理少镜头数据或类不平衡数据的三个方面的文献:数据增强、迁移学习和交互分割。
- 收集了目前常见的公共医学图像分割数据集,最后我们讨论了这一领域的未来研究趋势和发展方向
2 SUPERVISED LEARNING

2 An overview of network architectures based on supervised learning.
A. Backbone Networks
研究人员提出了编码器-解码器架构,这是最流行的端到端体系结构之一,如FCN,U-Net,Deeplab等。这些结构中编码器通常用于提取图像特征,而解码器通常用于将提取的特征恢复到原始图像大小,并输出最终的分割结果。虽然端到端结构对于医学图像分割是实用的,但它降低了模型的可解释性。
- U-Net

图3 U-Net architecture
U-Net解决了一般的CNN网络用于医学影响分割的问题,因为它采用了完美的对称结构和跳过连接。与普通的图像分割不同,医学图像通常包含噪声,边界模糊。因此仅依靠图像的低级特征,很难检测到医学图像中的物体或识别物体。同时,由于缺乏图像的细节信息,仅依靠图像的语义特征也不可能获得准确的边界。而U-Net通过跳跃连接结合低分辨率和高分辨率的特征图,有效地融合了低层次和高级层次的图像特征,是医学图像分割任务的完美解决方案。
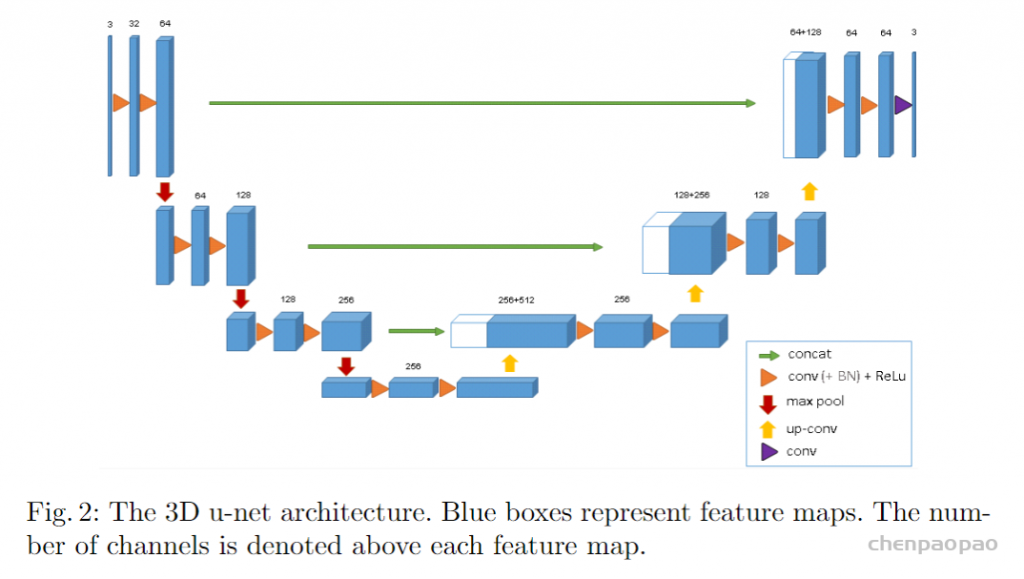
- 3D Net
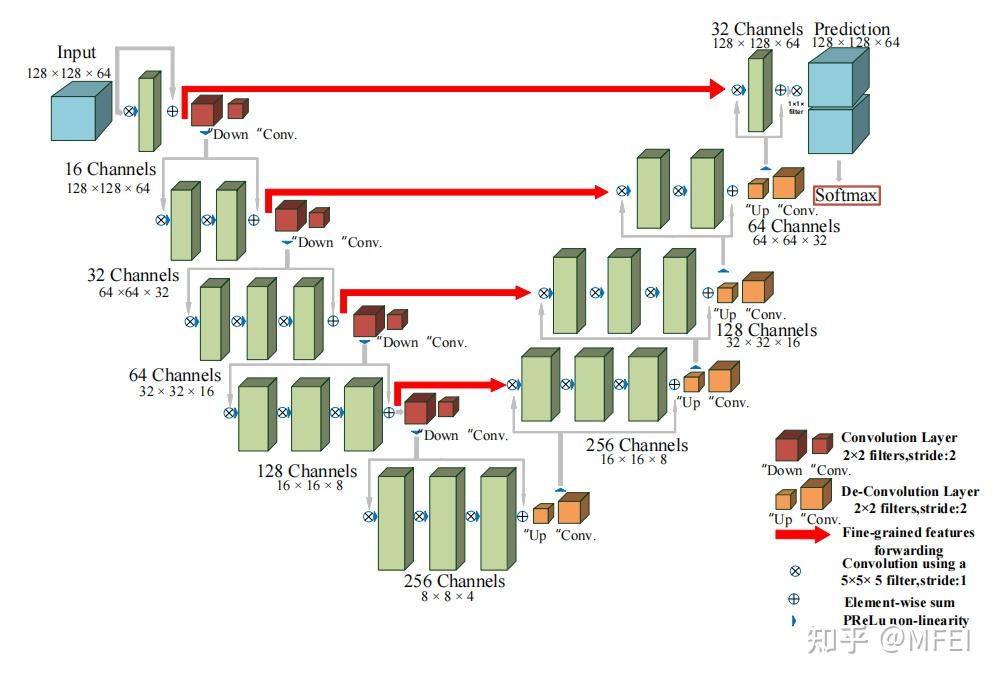
图4 V-Net architecture
在实践中,由于CT和MRI图像等大多数医学数据都以三维体积数据的形式存在,因此使用三维卷积核可以更好地挖掘数据的高维空间相关性。基于这一想法,C¸ ic¸ek等人[34]将U-Net架构扩展到3D数据的应用中,并提出了直接处理3D医疗数据的3DU-Net。由于计算资源的限制,三维U-Net只包含3个下采样,不能有效地提取深层图像特征,导致对医学图像的分割精度有限。
此外,米列塔利等人提出了类似的结构,V-Net,如图4所示。众所周知,残差连接可以避免梯度的消失,加速网络的收敛速度,很容易设计出更深层次的网络结构,可以提供更好的特征表示。与3DU-Net相比,V-Net采用残差连接设计跟深层次的网络(4次下采样)从而获得更好的性能。
然而,由于大量的参数,这些3D网络也遇到了高计算成本和GPU内存使用的问题。
- Recurrent Neural Network (RNN)
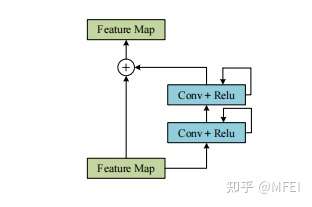
图5 Recurrent residual convolution unit
RNN最初被设计用于处理序列问题。长短期记忆(LSTM)网络[39]是最流行的rnn之一。通过引入自循环,它可以长时间保持梯度流动。在医学图像分割中,RNN已经被用来建模图像序列的时间依赖性。Alom等人[40]提出了一种结合ResUNet与RNN的医学图像分割方法。该方法实现了递归残差卷积层的特征积累,改进了图像分割任务的特征表示。图5为递归残差卷积单元。
显然,RNN可以通过考虑上下文信息关系来捕获图像的局部和全局空间特征。然而,在医学图像分割中,获取完整和有效的时间信息需要良好的医学图像质量(例如,较小的切片厚度和像素间距)。因此,RNN的设计对于提高医学图像分割的性能并不常见。
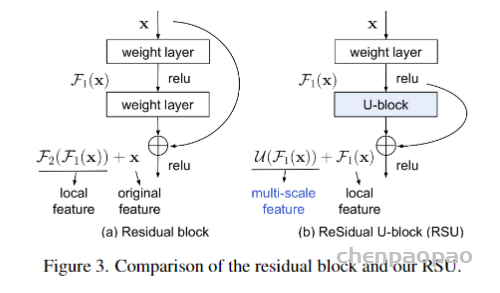
- Skip Connection
虽然skip connection可以融合低分辨率和高分辨率的信息,从而提高特征表示能力,但由于低分辨率和高分辨率特征之间的语义差距较大,导致特征映射模糊。为了改进skip connection,Ibtehaz等人[43]提出了包含Residual Path(ResPath)的MultiResUNet,这使得编码器特征在与解码器中的相应特征融合之前执行一些额外的卷积操作。Seo等人[44]提出mUNet,Chen等[45]提出FED-Net。mU-Net和FED-Net都在跳跃连接中添加了卷积操作,以提高医学图像分割的性能。 - Cascade of 2D and 3D
对于图像分割任务,级联模型通常训练两个或两个以上的模型来提高分割精度。该方法在医学图像分割中尤为流行。级联模型大致可分为三种框架类型- 粗-细分割
- 它使用两个二维网络的级联进行分割,其中第一个网络进行粗分割,然后使用另一个网络模型基于之前的粗分割结果实现精细分割。
- 粗-细分割
- 检测分割
- 首先使用R-CNN或者YOLO等网络模型进行目标位置识别,然后使用另一个网络基于之前的粗糙分割结果进行进一步的分割
- 混合分割
- 由于大多数医学图像是三维数据,二维卷积神经网络不能学习三维时间信息,而三维卷积神经网络往往需要较高的计算成本。所以一些伪三维的分割方法被提出。Oda等[58]提出了一种三平面的方法,从医学CT体积中有效地分割腹动脉区域。Vu等人[59]将相邻切片的叠加作为中心切片预测的输入,然后将得到的二维特征图输入标准的二维网络进行模型训练。虽然这些伪三维方法可以从三维体数据中分割对象,但由于利用了局部时间信息,它们只能获得有限的精度提高。
- 与伪三维网络相比,混合级联二维三维网络更受欢迎。Li等人[60]提出了一种混合密集连接的U-Net(H-DenseUNet)用于肝脏和肝肿瘤的分割。该方法首先采用一个简单的Resnet获得一个粗糙的肝脏分割结果,利用二维DenseUNet有效地提取二维图像特征,然后利用三维数据集提取三维图像特征,最后设计一个混合特征融合层,共同优化二维和三维特征。
- Others
- GAN已经广泛应用于计算机视觉的多个领域。生成对抗的思想也被用于图像分割。但由于医学图像通常显示低对比度,不同组织之间或组织之间的边界和病变模糊,医学图像数据标签稀疏。Luc等[65]首先将生成对抗网络应用于图像分割,将生成网络用于分割模型,将对抗网络训练为分类器。
- 结合有关器官形状和位置的先验知识可能对提高医学图像分割效果至关重要,在医学图像分割效果中,由于成像技术的限制,图像被损坏,因此包含了伪影。然而,关于如何将先验知识整合到CNN模型中的工作很少。Oktay等人[68]提出了一种新的通用方法,将形状和标签结构的先验知识结合到解剖约束神经网络(ACNN)中,用于医学图像分析任务。通过这种方式,神经网络的训练过程可以被约束和引导,以做出更解剖学和有意义的预测,特别是在输入图像数据信息不足或足够一致的情况下(例如,缺少对象边界)。上述研究表明由于在神经网络的训练过程中采用了先验知识约束,改进后的模型具有更高的分割精度,且具有更强的鲁棒性。
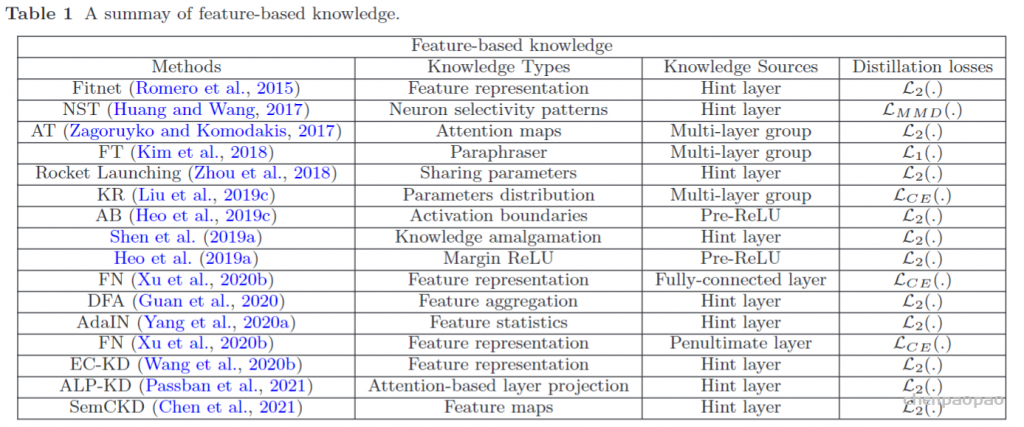
B. Network Function Block
- Dense Connection
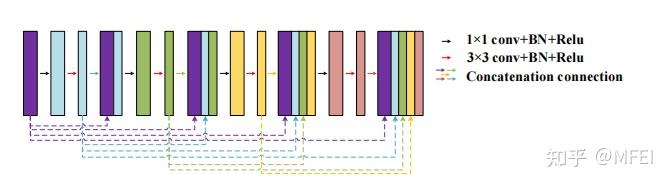
图6 Dense connection architecture
密集连接通常用于构造一种特殊的卷积神经网络。对于密集连接网络,每一层的输入来自前向传播过程中所有层的输出。受密集连接的启发,Guan等[70]提出了一种改进的U-Net,将它的每个子块替换为密集连接形式,如图6所示。虽然密集的连接有助于获得更丰富的图像特征,但它往往在一定程度上降低了特征表示的鲁棒性,增加了参数的数量。
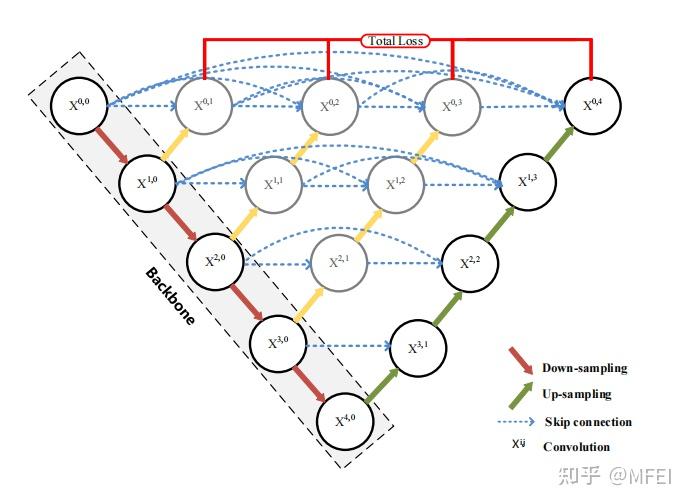
图7 UNet++
Zhou等人[71]将所有U-Net层(从1层到4层)连接在一起,如图7所示。这种结构的优点是,它允许网络自动学习不同层的特征的重要性。并且对跳跃连接进行了重新设计,可以将具有不同语义尺度的特征聚合在解码器中,从而形成了一个高度灵活的特征融合方案。缺点是由于密集连接的使用,参数的数量增加了。因此,将一种剪枝方法集成到模型优化中,以减少参数的数量。
- Inception

图8 Inception architecture
对于CNNs来说,深层网络往往比浅层网络具有更好的性能,但也会有梯度消失、难收敛、内存使用要求大等问题。Inception结构克服了这些问题,它在不增加网络深度的情况下并行合并卷积核,具有更好的性能。该结构能够利用多尺度卷积核提取更丰富的图像特征,并进行特征融合以获得更好的特征表示。
图8显示了inception的架构,它包含四个级联分支,随着无卷积次数的逐渐增加,从1到1、3和5,每个分支的接受域分别为3、7、9和19。因此,该网络可以从不同的尺度中提取特征。由于该架构比较复杂,导致模型修改困难
- Depth Separability
为了提高网络模型的泛化能力,减少对内存使用的需求,许多研究者将重点研究了复杂医学三维体数据的轻量级网络。
Howard et.al[76]提出了移动网络将普通卷积分解为深度可分卷积和点态卷积。普通卷积运算的数量通常为DK×DK×M×N,其中M为输入特征映射的维数,N为输出特征映射的维数,DK为卷积核的大小。然而,信道卷积操作的次数为DK×DK×1×M,点卷积为1×1×M×N。与普通卷积相比,深度可分离卷积的计算代价是普通卷积的计算代价(1/N+1/D2K)倍。
深度可分卷积是减少模型参数数量的一种有效方法,但它可能会导致医学图像分割精度的损失,因此需要采用其他方法(如深度监督)[78]来提高分割精度。
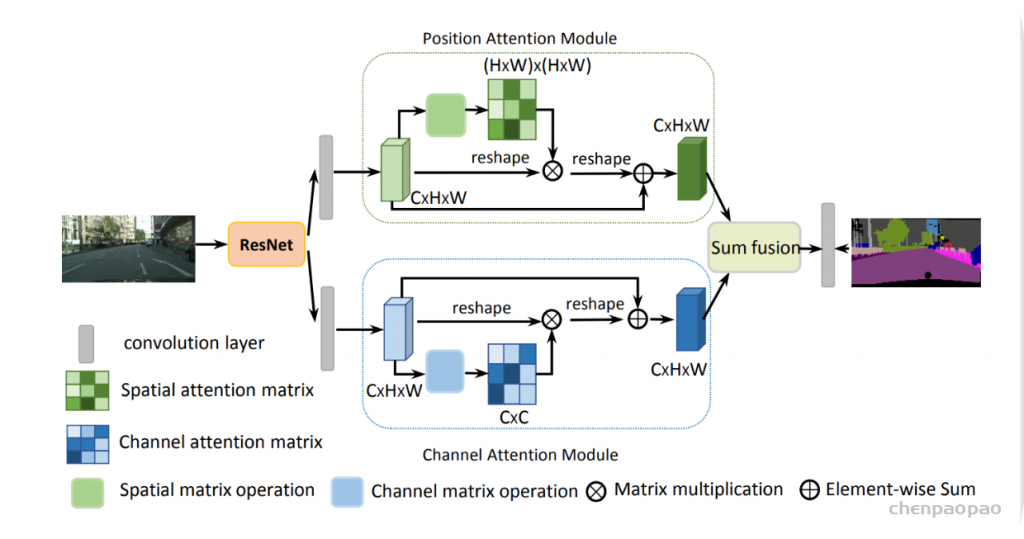
- Attention Mechanism
对于神经网络,attention block可以根据不同的重要性选择性地改变输入或给输入变量分配不同的权值。近年来,大多数结合深度学习和视觉注意机制的研究都集中在利用mask形成注意机制上。mask的原理是设计一个新的层,通过训练和学习从图像中识别出关键特征,然后让网络只关注图像中的有趣区域。- Local Spatial Attention
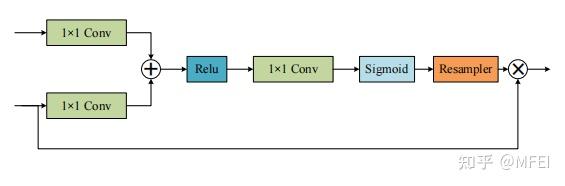
图9 The attention block in the attention U-Net
普通的pooling相当于信息合并,这很容易导致关键信息丢失。针对这个问题,设计了一个称为spatial transformer的块,通过执行空间变换来提取图像的关键信息。受此启发,Oktay等人[83]提出了attention U-Net。改进后的U-Net在融合来自编码器和相应的解码器的特征之前,使用一个注意块来改变编码器的输出。注意块输出门控信号来控制不同空间位置的像素的特征重要性。图9显示了该体系结构。这个块通过1×1卷积结合Relu和sigmoid函数,生成一个权重映射,通过与编码器的特征相乘来进行修正。
- Channel Attention

图10 The channel attention in the SE-Net
通道注意力模块可以实现特征重新校准,利用学习到的全局信息,选择性地强调有用特征,抑制无用特征。
Hu等人[84]提出了SE-Net,将通道关注引入了图像分析领域,该方法通过三个步骤实现了对信道的注意力加权;图10显示了该体系结构。首先是压缩操作,对输入特征进行全局平均池化,得到1×1×通道特征图。第二种是激励操作,将信道特征相互作用以减少信道数,然后将减少后的信道特征重构回信道数。最后利用sigmoid函数生成[0,1]的特征权值映射,将尺度放回原始输入特征。
- Mixture Attention
空间注意机制和通道注意机制是改进特征表示的两种常用策略。然而,空间注意忽略了不同通道信息的差异,并平等地对待每个通道。相反,通道注意力直接汇集全局信息,而忽略每个通道中的局部信息,这是一个相对粗糙的操作。因此,结合两种注意机制的优势,研究者设计了许多基于mixed domain attention block的模型。
Wang等人[86]在U-Net的收缩路径和扩展路径之间的中心瓶颈中嵌入了一个注意块,并提出了网格网。此外,他们还比较了通道注意、空间注意和两种注意的不同组合在医学图像分割中的表现。他们的结论是,以通道为中心的注意力是提高图像分割性能的最有效的方法。
虽然上述的注意机制提高了最终的分割性能,但它们只执行局部卷积的操作。该操作侧重于相邻卷积核的区域,但忽略了全局信息。此外,降采样的操作会导致空间信息的丢失,这尤其不利于医学图像的分割。 - Non-local Attention
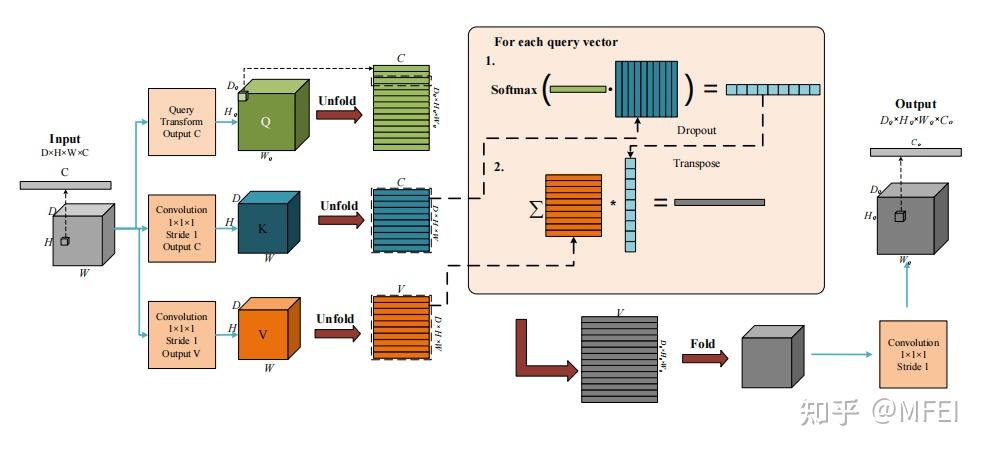
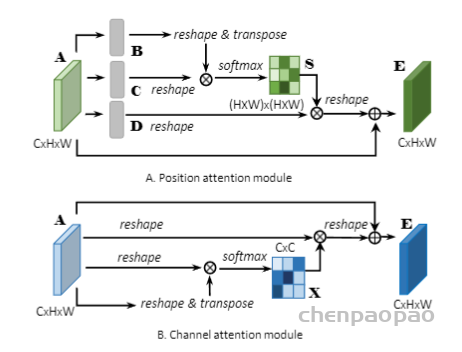
图11 The global aggregation block in the Non-Local U-Net
最近,Wang等人[87]提出了一种Non-local U-Net来克服局部卷积的缺点。Non-local U-Net在上采样和下采样部分均采用自注意机制和全局聚合块提取全图像信息,提高最终分割精度,图11显示了global aggregation block 。Non-local block是一种通用块,可以很容易地嵌入到不同的卷积神经网络中,以提高其性能。
该注意机制对提高图像分割精度是有效的。事实上,空间注意寻找有趣的目标区域,而通道注意寻找有趣的特征。混合注意机制可以同时利用空间和渠道。然而,与非局部注意相比,传统的注意机制缺乏利用不同目标与特征之间关联的能力,因此基于非局部注意的cnn在图像分割任务中通常比正常的cnn具有更好的性能。
- Multi-scale Information Fusion
物体之间的大尺度范围是医学图像分割的挑战之一。例如,中晚期的肿瘤可能比早期的肿瘤要大得多。感知场的大小大致决定了我们可以使用多少上下文信息。一般的卷积或池化只使用单个内核,例如,一个3×3内核用于卷积,一个2×2内核用于池化。- Pyramid Pooling:多尺度池化的并行操作可以有效地改善网络的上下文信息,从而提取出更丰富的语义信息。He et al.[88]首先提出了spatial pyramid pooling(SPP)来实现多尺度特征提取。SPP将图像从细空间划分为粗空间,然后收集局部特征,提取多尺度特征。受SPP的启发,设计了一个多尺度信息提取块,并将其命名为multi-kernel pooling(RMP)[75],它使用四个不同大小的池内核对全局上下文信息进行编码。然而,RMP中的上采样操作不能由于池化而恢复细节信息的丢失,这通常会扩大接受域,但降低了图像的分辨率。
- Atrous Spatial Pyramid Pooling:为了减少池化操作造成的详细信息损失,研究人员提出了atrous convolution而不是池化操作。与普通卷积相比,atrous convolution可以在不增加参数数量的情况下有效地扩大接受域。

图12 The gridding effect (the way of treating images as a chessboard causes the loss of information continuity).
然而,ASPP在图像分割方面存在两个严重的问题。第一个问题是局部信息的丢失,如图12所示,其中我们假设卷积核为3×3,三次迭代的膨胀率为2。第二个问题是,这些信息在很大的距离上可能是无关的。
- Non-local and ASPP:
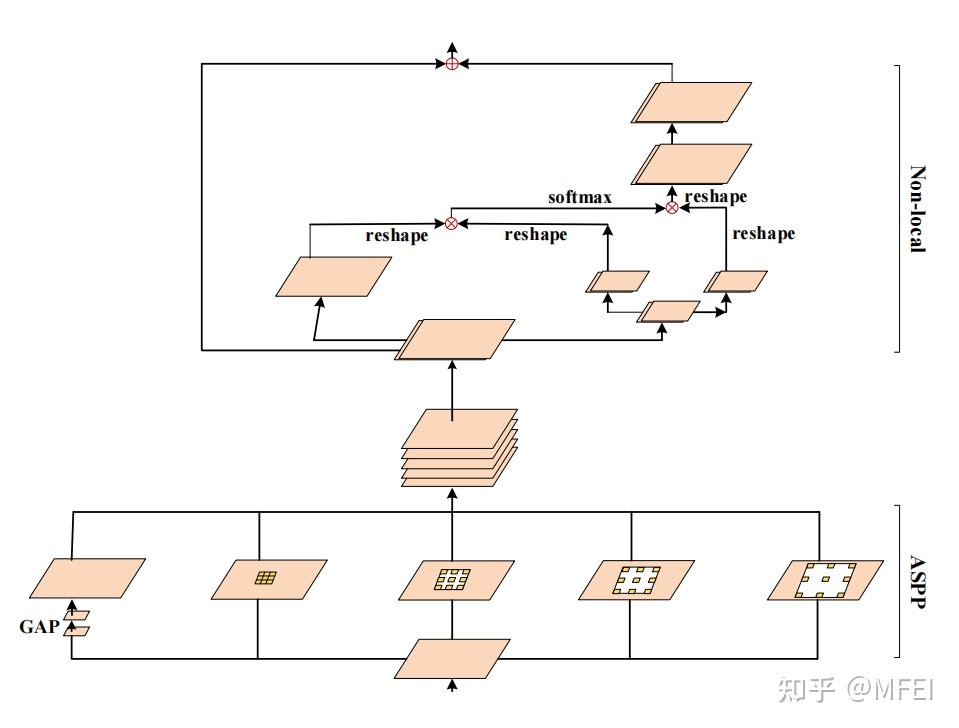
图13 The combination of ASPP and Non-local architecture
atrous convolution可以有效地扩大接受域,收集更丰富的语义信息,但由于网格效应,导致了细节信息的丢失。因此,有必要添加约束或建立像素关联来提高无效卷积性能。最近,Yang等人提出了[92]的ASPP和非局部组合块用于人体部位的分割,如图13所示。ASPP使用多个不同规模的并行无性卷积来捕获更丰富的信息,而非本地操作捕获了广泛的依赖关系。该组合具有ASPP和非局部化的优点,在医学图像分割方面具有良好的应用前景。
C. Loss Function
除了通过设计网络主干和函数块来提高分割速度和精度外,设计新的损失函数也可以改进分割精度
- Cross Entropy Loss
对于图像分割任务,交叉熵是最流行的损失函数之一。该函数将预测的类别向量和实际的分割结果向量进行像素级的比较。
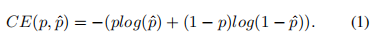
- Weighted Cross Entropy Loss
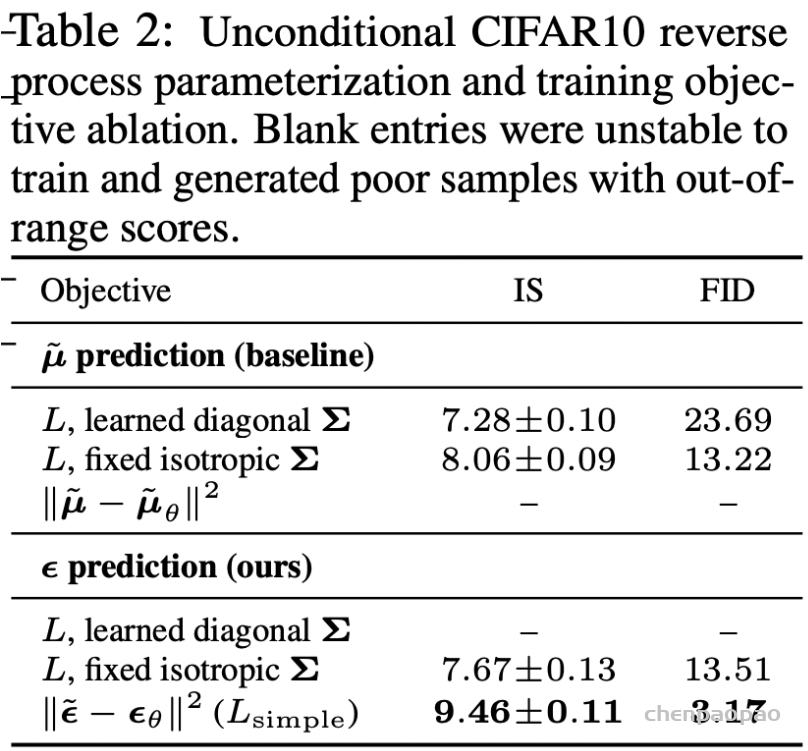
交叉熵损失对图像平均处理每个像素,输出一个平均值,忽略类不平衡,导致损失函数依赖于包含最大像素数的类的问题。因此,交叉熵损失在小目标分割中的性能往往较低。为了解决类的不平衡的问题,Long等人[32]提出了加权交叉熵损失(WCE)来抵消类的不平衡。对于二值分割的情况,将加权交叉熵损失定义为
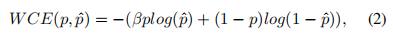
其中,β用于调整正样本和负样本的比例,它是一个经验值。如果是β>1,则假阴性的数量将会减少;事实上,交叉熵是加权交叉熵的一个特例,当β=1时,假阳性的数量就会减少。当β=1时。为了同时调整阳性和阴性样本的权重 的权重,我们可以使用平衡交叉熵 (BCE)损失函数,其定义为
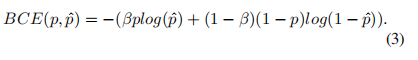
- Dice Loss
Dice是一个流行的医学影像分割性能评价指标。这个指标本质上是分割结果与相应的真实值之间重叠的度量。Dice的值为0-1之间,计算公式为
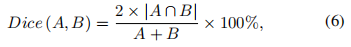
其中A为预测分割结果,B为真实分割结果。
- Tversky Loss
Dice loss的正则化版本,以控制假阳性和假阴性对损失函数的贡献,TL被定义为
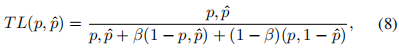
其中,p∈0, 1和0≤pˆ≤1。p和pˆ分别为地面真实值和预测分割。如果β=为0.5,则TL相当于Dice
- Generalized Dice Loss
Dice loss虽然一定程度上解决了分类失衡的问题,但却不利于严重的分类不平衡。例如小目标存在一些像素的预测误差,这很容易导致Dice的值发生很大的变化。Sudre等人提出了Generalized Dice Loss (GDL)
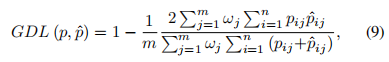
GDL优于Dice损失,因为不同的区域对损失有相似的贡献,并且GDL在训练过程中更稳定和鲁棒。
- Boundary Loss
为了解决类别不平衡的问题,Kervadec等人[95]提出了一种新的用于脑损伤分割的边界损失。该损失函数旨在最小化分割边界和标记边界之间的距离。作者在两个没有标签的不平衡数据集上进行了实验。结果表明,Dice los和Boundary los的组合优于单一组合。复合损失的定义为
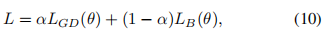
其中第一部分是一个标准的Dice los,它被定义为
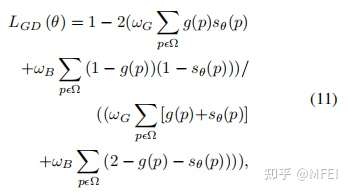
第二部分是Boundary los,它被定义为
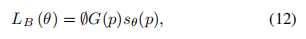
- Exponential Logarithmic Loss
在(9)中,加权Dice los实际上是得到的Dice值除以每个标签的和,对不同尺度的对象达到平衡。因此,Wong等人结合focal loss [96] 和dice loss,提出了用于脑分割的指数对数损失(EXP损失),以解决严重的类不平衡问题。通过引入指数形式,可以进一步控制损失函数的非线性,以提高分割精度。EXP损失函数的定义为
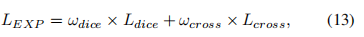
其中,两个新的参数权重分别用ωdice和ωcross表示。Ldice是指数对数骰子损失,而交叉损失是交叉熵损失
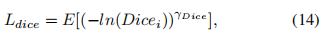
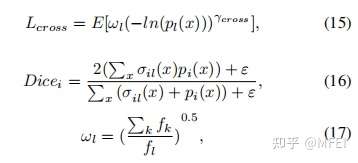
其中x是像素位置,i是标签,l是位置x处的地面真值。pi(x)是从softmax输出的概率值。
在(17)中,fk是标签k出现的频率,该参数可以减少更频繁出现的标签的影响。γDice和γcross都用于增强损失函数的非线性。
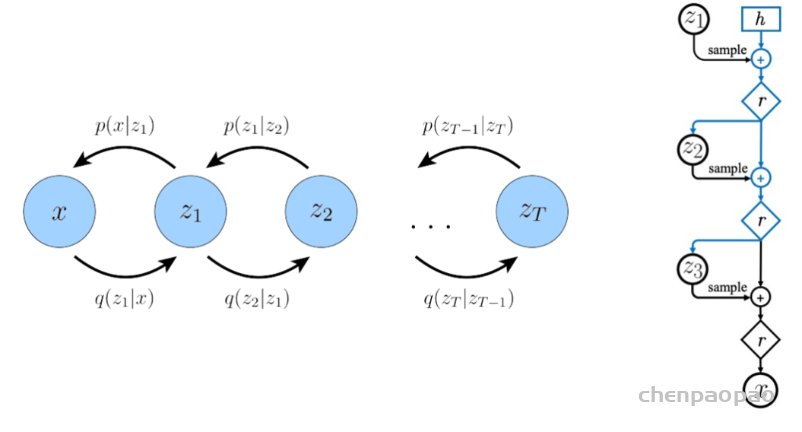
3 WEAKLY SUPERVISED LEARNING
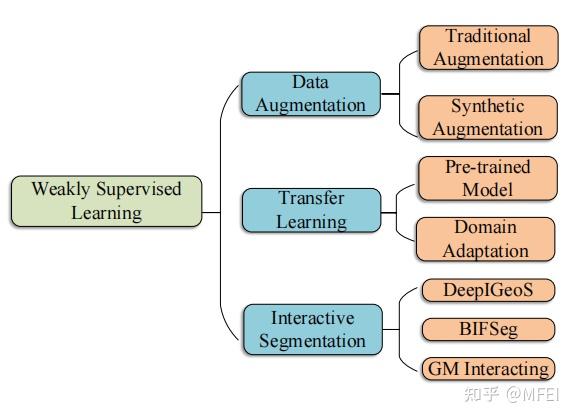
图14 The weakly supervised learning methods for medical image segmentation.
A. Data Augmentation
在缺乏大量标记数据集的情况下,数据增强是解决这一问题的有效解决方案,然而一般的数据扩展方法产生的图像与原始图像高度相关。与常用的数据增强方法相比,GAN是目前最流行的数据增强策略,因为GAN克服了对原始数据的依赖问题。
- Traditional Methods
一般的数据增强方法包括提高图像质量,如噪声抑制,亮度、饱和度、对比度等图像强度的变化,以及旋转、失真、缩放等图像布局的变化。传统数据增强中最常用的方法是参数变换(旋转、平移、剪切、位移、翻转等)。由于这种转换是虚拟的,没有计算成本,并且对医学图像的标注很困难,所以总是在每次训练之前进行。 - Conditional Generative Adversarial Nets(cGAN)
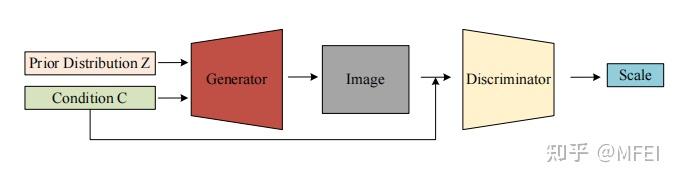
图15 The cGAN architecture
原始GAN生成器可以学习数据的分布,但生成的图片是随机的,这意味着生成器的生成过程是一种非引导的状态。相比之下,cGAN在原始GAN中添加了一个条件,以指导G的生成过程。图15显示了cGAN的体系结构。
Guibas等人[107]提出了一个由GAN和cGAN组成的网络架构。将随机变量输入GAN,生成眼底血管标签的合成图像,然后将生成的标签图输入条件GAN,生成真实的视网膜眼底图像。最后,作者通过检查分类器是否能够区分合成图像和真实图像来验证合成图像的真实性
虽然cGAN生成的图像存在许多缺陷,如边界模糊和低分辨率,但cGAN为后来用于图像样式转换的CycleGAN和StarGAN提供了一个基本的思路。
B. Transfer Learning
通过利用模型的训练参数来初始化一个新的模型,迁移学习可以实现对有限标签数据的快速模型训练。一种方法是在ImageNet上微调预先训练好的模型,而另一种方法是对跨领域的数据进行迁移训练。
- Pre-trained Model
转移学习通常用于解决数据有限的问题在医学图像分析,一些研究人员发现,使用预先训练的网络自然图像如ImageNet编码器在U-Net-like网络,然后对医疗数据进行微调可以进一步提高医学图像的分割效果。
在ImageNet上进行预训练的模型可以学习到医学图像和自然图像都需要的一些共同的基础特征,因此再训练过程是不必要的,而执行微调对训练模型是有用的。然而,当将预训练好的自然场景图像模型应用于医学图像分析任务时,领域自适应可能是一个问题。此外,由于预先训练好的模型往往依赖于二维图像数据集,因此流行的迁移学习方法很难适用于三维医学图像分析。如果带有注释的医疗数据集的数量足够大,那么就有可能这样做 - Domain Adaptation

图16 The Cycle GAN architecture
如果训练目标域的标签不可用,而我们只能访问其他域的标签,那么流行的方法是将源域上训练好的分类器转移到没有标记数据的目标域。CycleGAN是一种循环结构,主要由两个生成器和两个鉴别器组成。图16为CycleGAN的体系结构。
C. Interactive Segmentation
手工绘制医学图像分割标签通常是繁琐而耗时的,特别是对于绘制三维体数据。交互式分割允许临床医生交互式地纠正由模型生成的初始分割图像,以获得更准确的分割。有效的交互式分割的关键是,临床医生可以使用交互式方法,如鼠标点击和轮廓框,来改进来自模型的初始分割结果。然后,该模型可以更新参数,生成新的分割图像,从临床医生那里获得新的反馈。
例:Wang等人[121]提出了利用两个神经网络级联的DeepIGeoS,对二维和三维医学图像进行交互分割。第一个CNN被称为P-Net,它输出一个粗糙的分割结果。在此基础上,用户提供交互点或短线来标记错误的分割区域,然后使用它们作为第二个CNNR-Net的输入,获得校正的结果。对二维胎儿MRI图像和三维脑肿瘤图像进行了实验,实验结果表明,与传统的图形切割、随机游走、ITK-Snap等交互式分割方法相比,DeepIGeoS大大减少了用户交互的需求,减少了用户时间。
D. Others Works
半监督学习可以使用一小部分已标记数据和任意数量的未标记数据来训练模型,它的损失函数通常由两个损失函数的和组成。第一个是仅与标记数据相关的监督损失函数。第二个是无监督损失函数或正则化项,与标记和未标记数据相关。
弱监督分割方法从边框或图像级标签或少量标注的图像数据中学习图像分割,而不是使用大量的像素级标注,以获得高质量的分割结果。事实上,少量的注释数据和大量的未注释数据更符合真实的临床情况。然而,在实践中,弱监督学习的性能很少能为医学图像分割任务提供可接受的结果,特别是对三维医学图像。因此,这是一个值得在未来探索的方向。
4 CURRENTLY POPULAR DIRECTION
A. Network Architecture Search
到目前为止,NAS[130]在提高图像分类精度方面取得了重大进展。NAS可以被认为是自动机器学习的一个子域,与超参数优化和元学习有很强的重叠。
大多数深度学习医疗影像分割依赖于U-Net网络,并根据不同的任务对网络结构进行一些改变,但在实际应用中,非网络结构因素可能对提高分割效果也有重要意义。
Isensee等人[136]认为,对网络结构进行过多的人工调整会导致对给定数据集的过拟合,因此提出了一种医学图像分割框架no-new-unet(nnU-Net),以适应任何新的数据集。nnUnet会根据给定数据集的属性自动调整所有超参数,而不需要手动干预。因此,nnU-Net只依赖于普通的2DUNet、3DUNet、UNet级联和一个鲁棒的训练方案。它侧重于预处理(重采样和归一化)、训练(损失、优化器设置、数据增强)、推理(基于补丁的策略、测试时间增强集成、模型集成等)的阶段,以及后处理(例如,增强的单通域)。在实际应用中,网络结构设计的改进通常依赖于没有足够的可解释性理论支持的经验,此外,更复杂的网络模型表明过拟合的风险更高。
为了对高分辨率的二维图像(如CT、MRI和组织病理学图像)进行实时图像分割,压缩神经网络模型的研究已成为医学图像分割的一个流行方向。NAS的应用可以有效地减少模型参数的数量,实现了较高的分割性能。尽管NAS的性能令人惊叹,但我们无法解释为什么特定架构的性能良好。因此,更好地理解对性能有重要影响的机制,以及探索这些特性是否可以推广到不同的任务,对于未来的研究也很重要。
B. Graph Convolutional Neural Network
GCN是研究非欧几里得域的强大工具之一。图是一种由节点和边组成的数据结构。早期的图神经网络(GNNs)主要处理严格的图形问题,如分子结构的分类。在实践中,欧几里得空间(如图像)或序列(如文本),以及许多常见的场景可以转换为图,可以使用GCN技术建模。
Gao等人设计了一种新的基于GCN的图池(gUnPool)和图解池(gUnpool)操作,并提出了一种编码-解码器模型,即graph U-Net。graph U-Net通过添加少量的参数,比流行的unet获得了更好的性能。与传统的深度卷积神经网络相比,当深度值超过4时,增加网络的深度并不能提高graph U-Net的性能。然而,当深度值小于或等于4时,图U-Net比流行的U-Net表现出更强的特征编码能力。
基于GCN的方法比传统的和最近的基于深度学习的方法提供了更好的性能和更强的鲁棒性。由于图结构具有较高的数据表示效率和较强的特征编码能力,因此其在医学图像分割中的结果很有前景。
C. Interpretable Shape Attentive Neural Network
目前,许多深度学习算法倾向于通过使用近似适合输入数据的“记忆”模型来做出判断。因此,这些算法不能被充分地解释,并为每个具体的预测提供令人信服的证据。因此,研究深度神经网络的可解释性是目前的一个热点。
Sun等人[142]提出了SAU-Net,重点关注模型的可解释性和鲁棒性。该架构试图通过使用二次形状流来解决医学图像中边缘分割精度较差的问题。特别是,形状流和规则的纹理流可以并行地捕获丰富的与形状相关的信息。此外,解码器还使用了空间注意机制和通道注意机制来解释模型在U-Net各分辨率下的学习能力。最后,通过提取学习到的形状和空间注意图,我们可以用15个方法来解释每个解码器块的高度激活区域。学习到的形状图可以用来推断由模型学习到的有趣类别的正确形状。SAU-Net能够通过门控形状流学习对象的鲁棒形状特征,并且通过使用注意力的内置显着性映射比以前的工作更容易解释。
Wickstrøm等人[143]探索了卷积神经网络中结直肠息肉语义分割的不确定性和可解释性,作者开发了用于解释网络梯度的引导反向传播[144]的中心思想。通过反向传播,得到输入中每个像素对应的梯度,使网络所考虑的特征能够可视化。在反向传播过程中,由于图像中梯度值大且正的像素需要得到高度的重视,而应抑制梯度值大且梯度值负的像素。如果这些负梯度包含在重要像素的可视化中,它们可能会导致描述性特征的噪声可视化。为了避免产生有噪声的可视化,引导反向传播过程改变了神经网络的反向传播,使每一层的负梯度设置为零,从而只允许正梯度向后流过网络并突出这些像素。
目前,医学图像分析的解释主要是采用注意力和类激活图(CAM)等可视化方法。因此,对医学图像分割深度学习可解释性的研究将是未来的热门方向。
D. Multi-modality Data Fusion
多模态数据融合可以提供更丰富的目标特征,有助于提高目标检测和分割结果,因此在医学图像分析中得到了广泛的应用。
虽然众所周知,多模态融合网络通常显示更好的性能比单模式网络分割任务,多模型融合导致一些新的问题,如如何设计多模式网络有效地结合不同的模式,如何利用不同模式之间的潜在关系,如何将多个信息集成到分割网络提高分割性能等。此外,将多模态数据融合集成到一个有效的单参数网络中,有助于简化部署,提高临床实践中模型的可用性。
5 DISCUSSION AND OUTLOOK
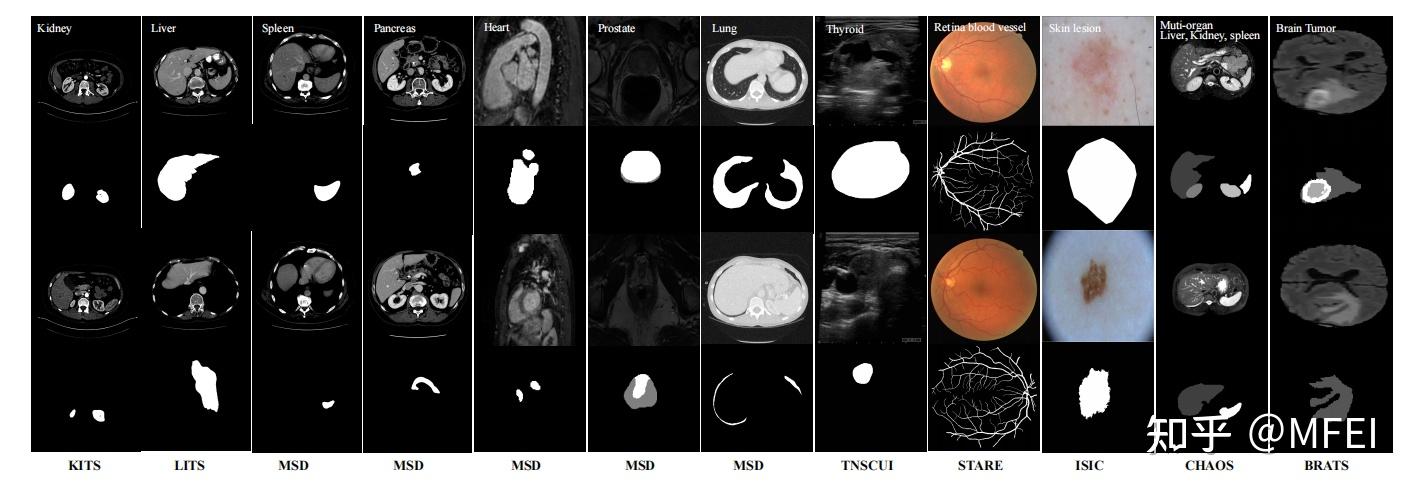
A. Medical Image Segmentation Datasets
B. Popular evaluation metrics
为了有效地衡量医学图像分割模型的性能,人们提出了大量的指标来评价分割的有效性。对图像分割性能的评价依赖于像素质量、区域质量和表面距离质量。
目前比较流行的指标有像素质量指标包括像素精度(PA)。区域质量指标包括Dice score、体积重叠误差(VOE)和相对体积差(RVD)。表面距离质量度量包括平均对称表面距离(ASD)和最大对称表面距离(MSD)。
- PA
像素精度只是找到正确分类的像素的比率,除以像素总数。对于K个+1类(K个前景类和背景),像素精度定义为:
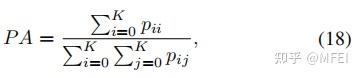
其中,pij是第i类预测为属于第j类的像素数。
- Dice score
它是一种常用的图像分割度量方法(在医学图像分析中更常用),它可以定义为预测地图和地面真实地图重叠面积的两倍,除以两幅图像的像素总数。对Dice score的定义为:
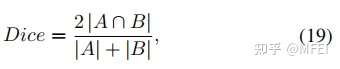
- VOE
它是Jaccard index的补充,其定义为:
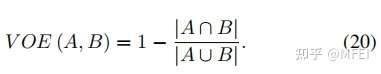
- RVD
它是一种非对称度量,定义为:
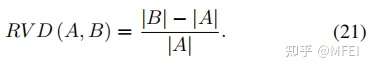
- ASD
表面距离度量是参考和预测病变的表面距离的相关度量。
设S(A)表示a的表面体素集合。任意体素v到S(A)的最短距离定义为:
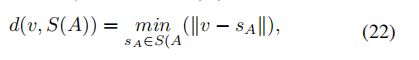
ASD is defined as:
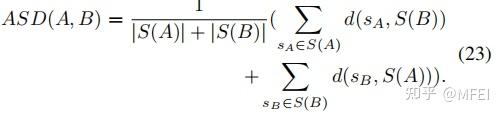
- MSD
它也被称为对称豪斯多夫距离,与ASD相似,但取的最大距离而不是平均值:
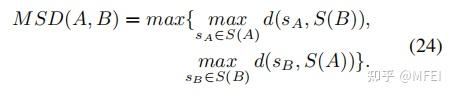
本文所有图片公式均来自论文原文