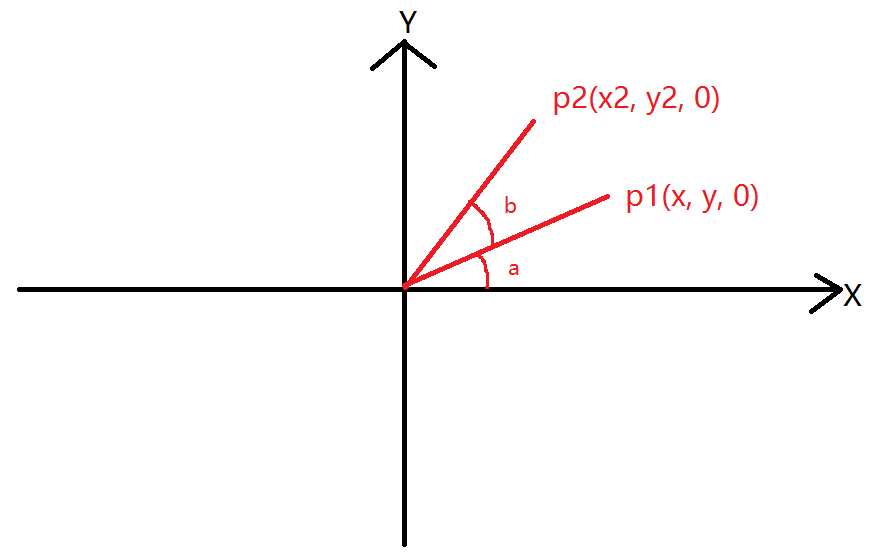
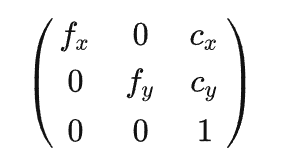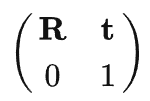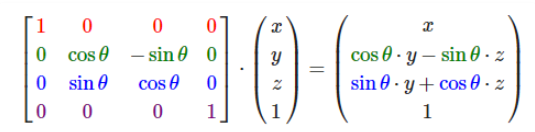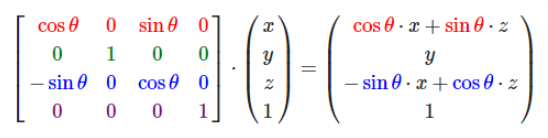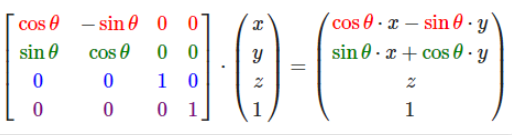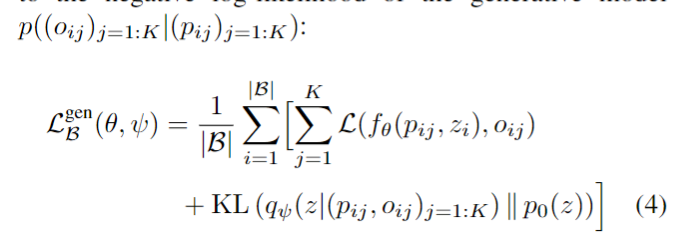3D机器学习相关合集:https://github.com/timzhang642/3D-Machine-Learning
A paper list of 3D photography and cinemagraph.
This list is non-exhaustive. Feel free to pull requests or create issues to add papers.
Following this repo, I use some icons to (imprecisely) differentiate the 3D representations:
- 🍃 Layered Depth Image
- 💎 Mesh
- ✈️ Multiplane Images
- 🚕 Nerf
- ☁️ Point Cloud
- 👾 Voxel
3D Photography from a Single Image
Here I include the papers for novel view synthesis with a single input image based on 3D geometry.
[ECCV 2022]InfiniteNature-Zero: Learning Perpetual View Generation of Natural Scenes from Single Images [paper] [project page][SIGGRAPH 2022]Single-View View Synthesis in the Wild with Learned Adaptive Multiplane Images [paper] [code] [project page] ✈️[CVPR 2022]Efficient Geometry-aware 3D Generative Adversarial Networks [paper] [code] [project page][CVPRW 2022]Artistic Style Novel View Synthesis Based on A Single Image [paper] [code] [project page] ☁️[CVPR 2022]3D Photo Stylization: Learning to Generate Stylized Novel Views from a Single Image [paper] [code] [project page] ☁️[ICCV 2021]Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image [paper] [code] [project page] 💎[ICCV 2021]MINE: Towards Continuous Depth MPI with NeRF for Novel View Synthesis [paper] [code] [project page] ✈️ 🚕[ICCV 2021]PixelSynth: Generating a 3D-Consistent Experience from a Single Image [paper] [code] [project page] ☁️[ICCV 2021]SLIDE: Single Image 3D Photography with Soft Layering and Depth-aware Inpainting [paper] [project page] 💎[ICCV 2021]Video Autoencoder: self-supervised disentanglement of static 3D structure and motion [paper] [code] [project page] 👾[ICCV 2021]Worldsheet: Wrapping the World in a 3D Sheet for View Synthesis from a Single Image [paper] [code] [project page] 💎[CVPR 2021]Layout-Guided Novel View Synthesis from a Single Indoor Panorama [paper] [dataset][WACV 2021]Adaptive Multiplane Image Generation from a Single Internet Picture [paper] ✈️[CVPR 2020]Single-View View Synthesis with Multiplane Images [paper] [code] [project page] ✈️[CVPR 2020]SynSin: End-to-end View Synthesis from a Single Image [paper] [code] [project page] ☁️[CVPR 2020]3D Photography using Context-aware Layered Depth Inpainting [paper] [code] [project page] 🍃[Trans. Graph. 2020]One Shot 3D Photography [paper] [code] [project page] 🍃 💎[Trans. Graph. 2019]3D Ken Burns Effect from a Single Image [paper] [code] ☁️[ICCV 2019]Monocular Neural Image-based Rendering with Continuous View Control [paper] [code][ECCV 2018]Layer-structured 3D Scene Inference via View Synthesis [paper] [code] [project page] 🍃[SIGGRAPH Posters 2011]Layered Photo Pop-Up [poster] [abstract] [project page]
Binocular-Input Novel View Synthesis
Not a complete list.
[CVPR 2022]3D Moments from Near-Duplicate Photos [paper] [code] [project page] 🍃☁️[CVPR 2022]Stereo Magnification with Multi-Layer Images [paper] [code] [project page] ✈️💎[ICCV 2019]Extreme View Synthesis [paper] [code][CVPR 2019]Pushing the Boundaries of View Extrapolation with Multiplane Images [paper] ✈️[SIGGRAPH 2018]Stereo Magnification: Learning View Synthesis using Multiplane Images [paper] [code] [project page] ✈️
Landscape Animation
Animating landscape: running water, moving clouds, etc.
[SA 2022]Water Simulation and Rendering from a Still Photograph [paper] [project page][arXiv 2022]DiffDreamer: Consistent Single-view Perpetual View Generation with Conditional Diffusion Models [paper] [project page][arXiv 2022]Towards Smooth Video Composition [paper] [project page][arXiv 2022]Simulating Fluids in Real-World Still Images [paper] [code] [project page][CVPR 2022]Controllable Animation of Fluid Elements in Still Images [paper] [project page][CVPR 2022]StyleGAN-V: A Continuous Video Generator with the Price, Image Quality and Perks of StyleGAN2 [paper] [code] [project page][CVPR 2021]Animating Pictures with Eulerian Motion Fields [paper] [project page][MultiMedia 2021]Learning Fine-Grained Motion Embedding for Landscape Animation [paper][ECCV 2020]DeepLandscape: Adversarial Modeling of Landscape Videos [paper] [code] [project page][ECCV 2020]DTVNet: Dynamic Time-lapse Video Generation via Single Still Image [paper] [code][SIGGRAPH Asia 2019]Animating Landscape: Self-Supervised Learning of Decoupled Motion and Appearance for Single-Image Video Synthesis [paper] [code] [project page][CVPR 2018]Learning to Generate Time-lapse Videos Using Multi-stage Dynamic Generative Adversarial Networks [paper] [code] [project page]
Some Other Papers
Some other interesting papers for novel view synthesis or cinemagraph.
[arXiv 2022]Make-A-Video: Text-to-Video Generation without Text-Video Data [paper] [project page][ECCV 2022]SinNeRF: Training Neural Radiance Fields on Complex Scenes from a Single Image [paper] [code] [project page] 🚕[CVPR 2022]Look Outside the Room: Synthesizing A Consistent Long-Term 3D Scene Video from A Single Image [paper] [code] [project page][ICCV 2021]Geometry-Free View Synthesis: Transformers and no 3D Priors [paper] [code] [project page][ICCV 2021]iPOKE: Poking a Still Image for Controlled Stochastic Video Synthesis [paper] [code] [project page][ICCV 2021]Learning to Stylize Novel Views [paper] [code] [project page] ☁️[ICCV 2021]Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis [paper] [code] [project page] 🚕[CVPR 2021]Stochastic Image-to-Video Synthesis Using cINNs [paper] [code] [project page][CVPR 2021]Understanding Object Dynamics for Interactive Image-to-Video Synthesis [paper] [code] [project page][SIGGRAPH 2021]Endless Loops: Detecting and Animating Periodic Patterns in Still Images [paper] [project page][ECCV 2018]Flow-Grounded Spatial-Temporal Video Prediction from Still Images [paper] [code][CVPR 2018]Controllable Video Generation with Sparse Trajectories [paper] [code] [project page][CVPR 2018]MoCoGAN: Decomposing Motion and Content for Video Generation [paper] [code][ICCV 2017]Personalized Cinemagraphs using Semantic Understanding and Collaborative Learning [paper]