
同时定位与地图构建(英语:Simultaneous localization and mapping,一般直接称SLAM)是一种概念:希望机器人从未知环境的未知地点出发,在运动过程中通过重复观测到的地图特征(比如,墙角,柱子等)定位自身位置和姿态,再根据自身位置增量式的构建地图,从而达到同时定位和地图构建的目的。
一、SLAM的典型应用领域
机器人定位导航领域:地图建模。SLAM可以辅助机器人执行路径规划、自主探索、导航等任务。国内的科沃斯、塔米以及最新面世的岚豹扫地机器人都可以通过用SLAM算法结合激光雷达或者摄像头的方法,让扫地机高效绘制室内地图,智能分析和规划扫地环境,从而成功让自己步入了智能导航的阵列。国内思岚科技(SLAMTEC)为这方面技术的主要提供商,SLAMTEC的命名就是取自SLAM的谐音,其主要业务就是研究服务机器人自主定位导航的解决方案。目前思岚科技已经让关键的二维激光雷达部件售价降至百元,这在一定程度上无疑进一步拓展了SLAM技术的应用前景。
VR/AR方面:辅助增强视觉效果。SLAM技术能够构建视觉效果更为真实的地图,从而针对当前视角渲染虚拟物体的叠加效果,使之更真实没有违和感。VR/AR代表性产品中微软Hololens、谷歌ProjectTango以及MagicLeap都应用了SLAM作为视觉增强手段。
无人机领域:地图建模。SLAM可以快速构建局部3D地图,并与地理信息系统(GIS)、视觉对象识别技术相结合,可以辅助无人机识别路障并自动避障规划路径,曾经刷爆美国朋友圈的Hovercamera无人机,就应用到了SLAM技术。
无人驾驶领域:视觉里程计。SLAM技术可以提供视觉里程计功能,并与GPS等其他定位方式相融合,从而满足无人驾驶精准定位的需求。例如,应用了基于激光雷达技术Google无人驾驶车以及牛津大学MobileRoboticsGroup11年改装的无人驾驶汽车野猫(Wildcat)均已成功路测。
二、SLAM框架
SLAM系统框架如图所示,一般分为五个模块,包括传感器数据、视觉里程计、后端、建图及回环检测。
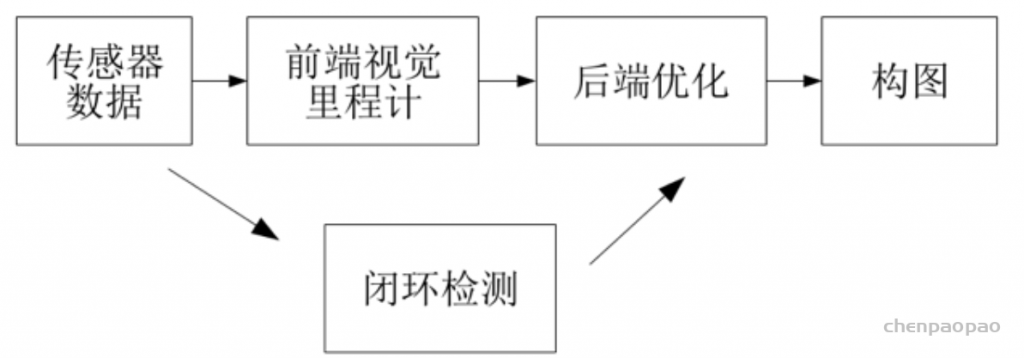
传感器数据:主要用于采集实际环境中的各类型原始数据。包括激光扫描数据、视频图像数据、点云数据等。
视觉里程计:主要用于不同时刻间移动目标相对位置的估算。包括特征匹配、直接配准等算法的应用。
后端:主要用于优化视觉里程计带来的累计误差。包括滤波器、图优化等算法应用。
建图:用于三维地图构建。
回环检测:主要用于空间累积误差消除
其工作流程大致为:
传感器读取数据后,视觉里程计估计两个时刻的相对运动(Ego-motion),后端处理视觉里程计估计结果的累积误差,建图则根据前端与后端得到的运动轨迹来建立地图,回环检测考虑了同一场景不同时刻的图像,提供了空间上约束来消除累积误差。
三、SLAM分类(基于传感器的SLAM分类)
目前用在SLAM上的传感器主要分为这两类,一种是基于激光雷达的激光SLAM(Lidar SLAM)和基于视觉的VSLAM(Visual SLAM)。
1.激光SLAM
激光SLAM采用2D或3D激光雷达(也叫单线或多线激光雷达),2D激光雷达一般用于室内机器人上(如扫地机器人),而3D激光雷达一般使用于无人驾驶领域。激光雷达的出现和普及使得测量更快更准,信息更丰富。激光雷达采集到的物体信息呈现出一系列分散的、具有准确角度和距离信息的点,被称为点云。通常,激光SLAM系统通过对不同时刻两片点云的匹配与比对,计算激光雷达相对运动的距离和姿态的改变,也就完成了对机器人自身的定位。
激光雷达测距比较准确,误差模型简单,在强光直射以外的环境中运行稳定,点云的处理也比较容易。同时,点云信息本身包含直接的几何关系,使得机器人的路径规划和导航变得直观。激光SLAM理论研究也相对成熟,落地产品更丰富。
对比相机、ToF 和其他传感器,激光可以使精确度大大提高,常用于自动驾驶汽车和无人机等高速移动运载设备的相关应用。激光传感器的输出值一般是二维 (x, y) 或三维 (x, y, z) 点云数据。激光传感器点云提供了高精确度距离测度数据,特别适用于 SLAM 建图。一般来说,首先通过点云匹配来连续估计移动。然后,使用计算得出的移动数据(移动距离)进行车辆定位。对于激光点云匹配,会使用迭代最近点 (ICP) 和正态分布变换 (NDT) 等配准算法。二维或三维点云地图可以用栅格地图或体素地图表示。
但就密度而言,点云不及图像精细,因此并不总能提供充足的特征来进行匹配。例如,在障碍物较少的地方,将难以进行点云匹配,因此可能导致跟丢车辆。此外,点云匹配通常需要高处理能力,因此必须优化流程来提高速度。鉴于存在这些挑战,自动驾驶汽车定位可能需要融合轮式测距、全球导航卫星系统 (GNSS) 和 IMU 数据等其他测量结果。仓储机器人等应用场景通常采用二维激光雷达 SLAM,而三维激光雷达点云 SLAM 则可用于无人机和自动驾驶。
2.视觉SLAM
眼睛是人类获取外界信息的主要来源。视觉SLAM也具有类似特点,它可以从环境中获取海量的、富于冗余的纹理信息,拥有超强的场景辨识能力。早期的视觉SLAM基于滤波理论,其非线性的误差模型和巨大的计算量成为了它实用落地的障碍。近年来,随着具有稀疏性的非线性优化理论(Bundle Adjustment)以及相机技术、计算性能的进步,实时运行的视觉SLAM已经不再是梦想。
视觉SLAM的优点是它所利用的丰富纹理信息。例如两块尺寸相同内容却不同的广告牌,基于点云的激光SLAM算法无法区别他们,而视觉则可以轻易分辨。这带来了重定位、场景分类上无可比拟的巨大优势。同时,视觉信息可以较为容易的被用来跟踪和预测场景中的动态目标,如行人、车辆等,对于在复杂动态场景中的应用这是至关重要的。
通过对比我们发现,激光SLAM和视觉SLAM各擅胜场,单独使用都有其局限性,而融合使用则可能具有巨大的取长补短的潜力。例如,视觉在纹理丰富的动态环境中稳定工作,并能为激光SLAM提供非常准确的点云匹配,而激光雷达提供的精确方向和距离信息在正确匹配的点云上会发挥更大的威力。而在光照严重不足或纹理缺失的环境中,激光SLAM的定位工作使得视觉可以借助不多的信息进行场景记录。
近年来,SLAM导航技术已取得了很大的发展,它将赋予机器人和其他智能体前所未有的行动能力,而激光SLAM与视觉SLAM必将在相互竞争和融合中发展,使机器人从实验室和展厅中走出来,做到真正的服务于人类。
顾名思义,视觉 SLAM(又称 vSLAM)使用从相机和其他图像传感器采集的图像。视觉 SLAM 可以使用普通相机(广角、鱼眼和球形相机)、复眼相机(立体相机和多相机)和 RGB-D 相机(深度相机和 ToF 相机)。
视觉 SLAM 所需的相机价格相对低廉,因此实现成本较低。此外,相机可以提供大量信息,因此还可以用来检测路标(即之前测量过的位置)。路标检测还可以与基于图的优化结合使用,这有助于灵活实现 SLAM。
使用单个相机作为唯一传感器的 vSLAM 称为单目 SLAM,此时难以定义深度。这个问题可以通过以下方式解决:检测待定位图像中的 AR 标记、棋盘格或其他已知目标,或者将相机信息与其他传感器信息融合,例如测量速度和方向等物理量的惯性测量单元 (IMU) 信息。vSLAM 相关的技术包括运动重建 (SfM)、视觉测距和捆绑调整。
视觉 SLAM 算法可以大致分为两类。稀疏方法:匹配图像的特征点并使用 PTAM 和 ORB-SLAM 等算法。稠密方法:使用图像的总体亮度以及 DTAM、LSD-SLAM、DSO 和 SVO 等算法。