
视频: https://www.zhihu.com/zvideo/1566362268736200704?playTime=194.2
讲解: https://zhuanlan.zhihu.com/p/572057070
今年Tesla FSD部分,感知网络从去年的Bev感知(Hydranet)的基础上,更近一步,提出了occupancy network.
1. 为什么是occupancy network?
在基于 LiDAR 的系统中,可以根据检测到的反射强度来确定对象的存在,但在相机系统中,必须首先使用神经网络检测对象。如果看到不属于数据集的对象怎么办?比如侧翻的大卡车。仅此一项,就引发了很多事故。

可行驶区域的一些问题
rv、bev (Birds Eye View) 空间下可行驶区域会有一定问题:
- 地平线的深度不一致,只有2个左右的像素决定了一个大区域的深度。
- 无法看穿遮挡物,也无法行驶。
- 提供的结构是 2D的,但世界是 3D 的。
- 高度方向可能只有一个障碍物(悬垂的检测不到),目前是每类对象设置固定的矩形。
- 存在未知物体,例如,如果看到不属于数据集的对象。
所以希望有种通用的方式来解决该问题,首先能想到的是bev下的可行驶区域,但相对来说在高度维会比较受限,索性一步到位变成3d空间预测、重建。
2. Occupancy Network
2022 CVPR中,tesla FSD新负责人 Ashok Elluswamy 推出了Occupancy Network。借鉴了机器人领域常用的思想,基于occupancy grid mapping,是一种简单形式的在线3d重建。将世界划分为一系列网格单元,然后定义哪个单元被占用,哪个单元是空闲的。通过预测3d空间中的占据概率来获得一种简单的3维空间表示。关键词是3D、使用占据概率而非检测、多视角。

Occupancy Network
这里输出的并非是对象的确切形状,而是一个近似值,可以理解为因为算力和内存有限,导致轮廓不够sharp,但也够用。另外还可以在静态和动态对象之间进行预测,以超过 100 FPS 的速度运行(或者是相机可以产生的 3 倍以上)。
2020 AI day中的Hydranet算法中有三个核心词汇:鸟瞰图(BEV)空间、固定矩形、物体检测。而occupancy network针对这三点有哪些优化,可以看:
第一是鸟瞰图。在 2020 年特斯拉 AI 日上,Andrej Karpathy 介绍了特斯拉的鸟瞰网络。该网络展示了如何将检测到的物体、可驾驶空间和其他物体放入 2D 鸟瞰视图中。occupancy则是计算占据空间的概率。
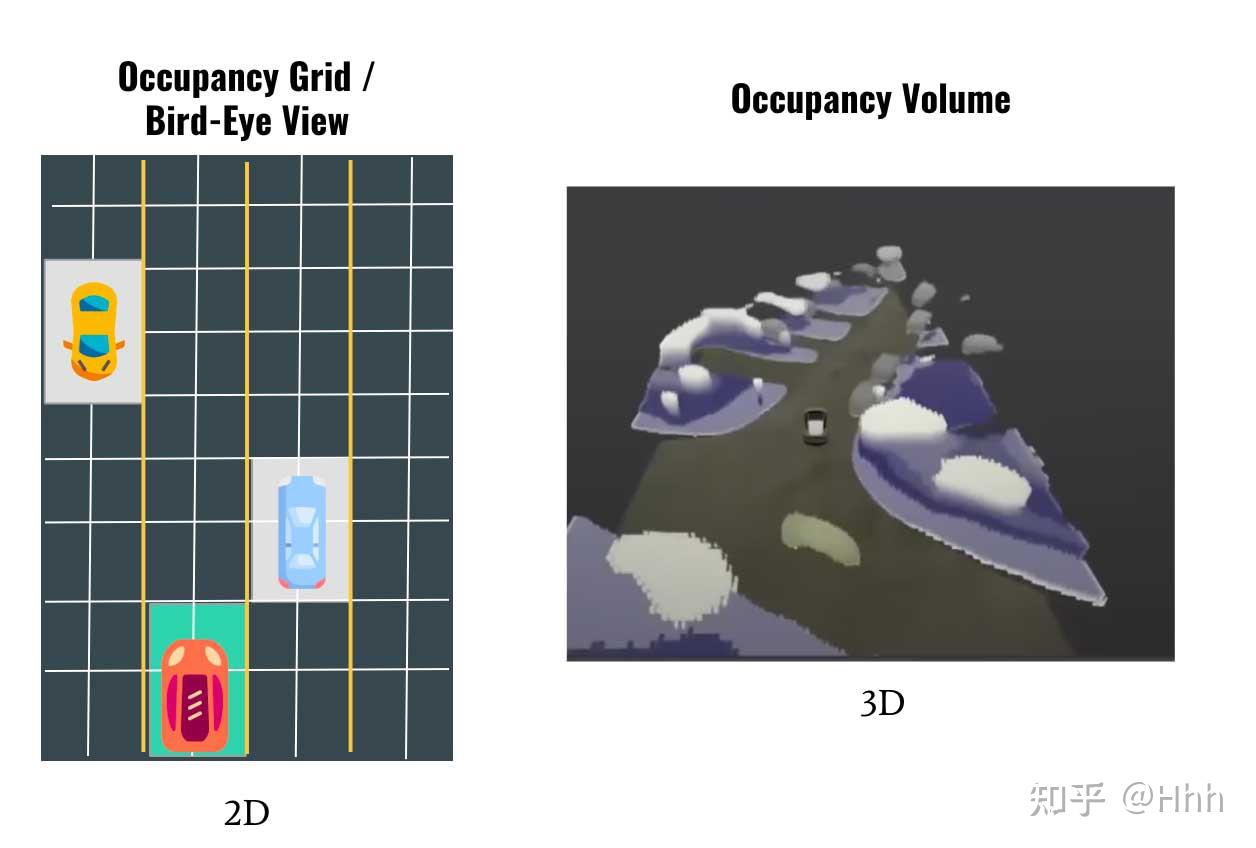
BEV vs Volume Occupancy
最主要的区别就是,前者是 2D表示,而后者是3D表示。
第二是固定矩形,在设计感知系统时,经常会将检测与固定输出尺寸联系起来,矩形无法表示一些异形的车辆或者障碍物。如果您看到一辆卡车,将在featuremap上放置一个 7×3 的矩形,如果看到一个行人,则使用一个 1×1 的矩形。问题是,这样无法预测悬垂的障碍物。如果汽车顶部有梯子,卡车有侧拖车或手臂;那么这种固定的矩形可能无法检测到目标。而使用Occupancy Network的话,看到下图中,是可以精细的预测到这些情况的。

固定矩形 vs Volume Occupancy
后者的工作方式如下:
- 将世界划分为微小(或超微小)的立方体或体素
- 预测每个体素是空闲还是被占用
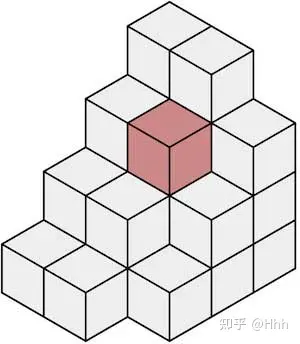
这里意味着两种方法的思维方式完全不一样,前者是为一个对象分配一个固定大小的矩形,而后者是简单地说“这个小立方体中有一个对象吗? ”。
第三点,物体检测。
目前有很多新提出来的物体检测算法,但大多面向的是固定的数据集,只检测属于数据集的部分或全部对象,一旦有没有标注的物体出现,比如侧翻的白色大卡车,垃圾桶出现的路中,这是没法检测到的。而当思考和训练一个模型来预测“这个空间是空闲的还是被占用的,不管对象的类别是什么?”,正可以避免这种问题。
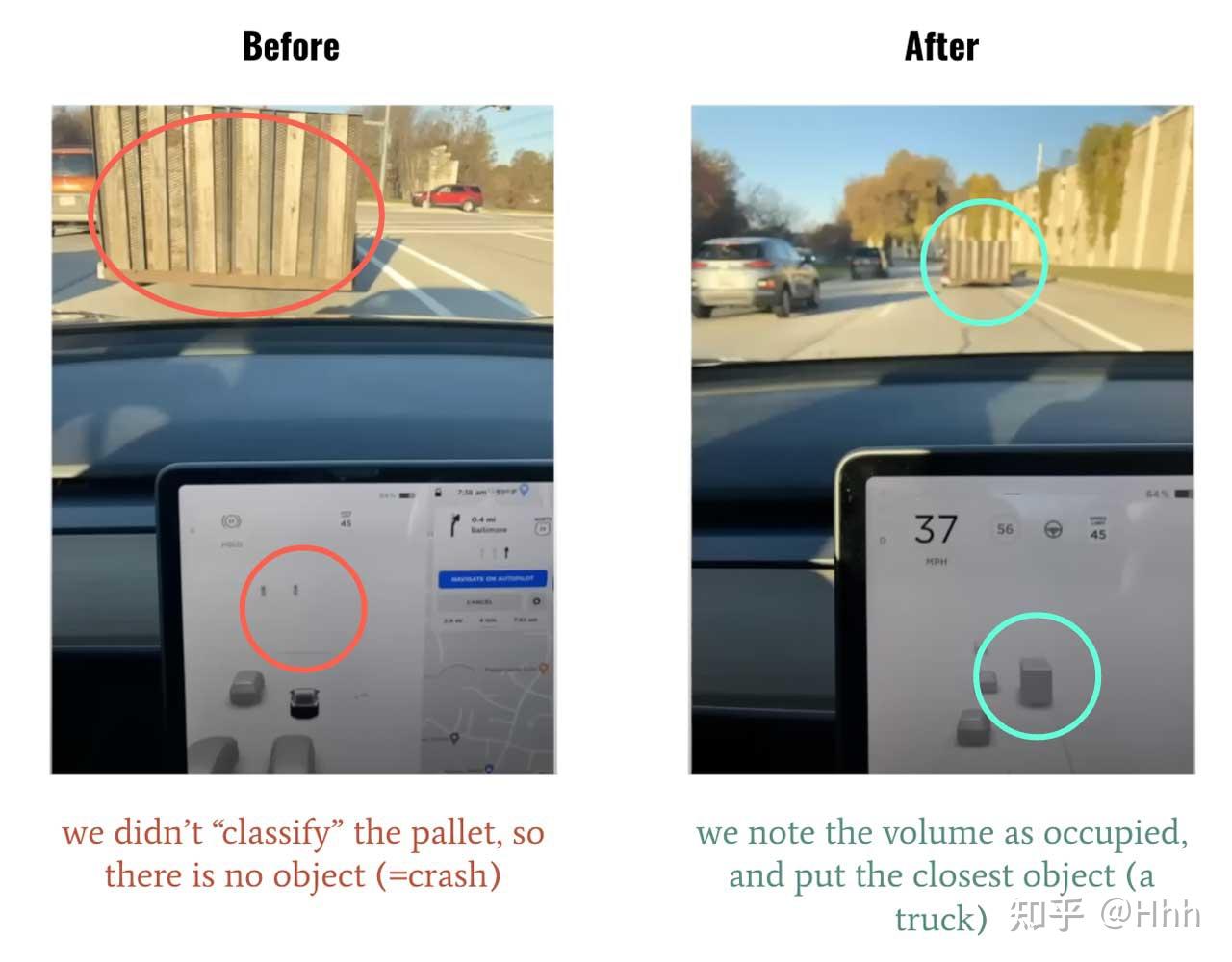
对象检测 vs Occupancy Network
基于视觉的系统有 5 个主要缺陷:地平线深度不一致、物体形状固定、静态和移动物体、遮挡和本体裂缝。特斯拉旨在创建一种算法来解决这些问题。
新的占用网络通过实施 3 个核心思想解决了这些问题:体积鸟瞰图、占用检测和体素分类。这些网络可以以超过 100 FPS 的速度运行,可以理解移动对象和静态对象,并且具有超强的内存效率。
模型结构:
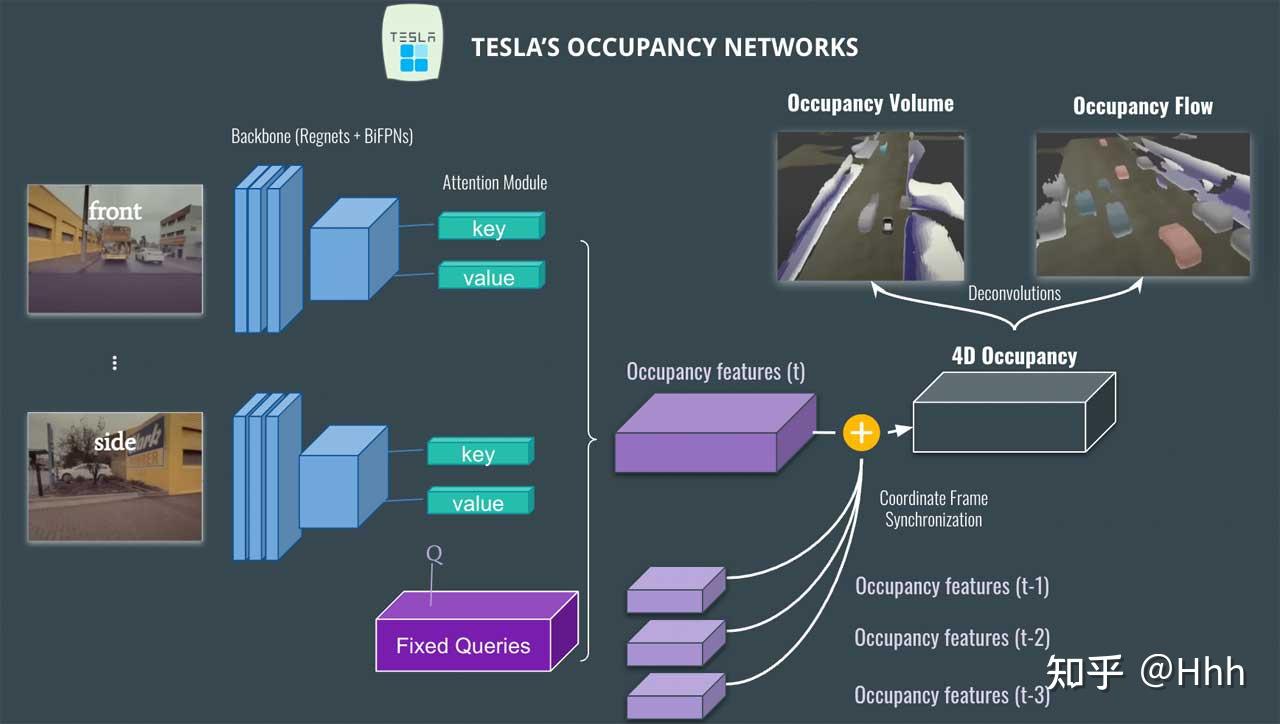
cvpr 时的网络结构
- 输入为不同视角的图像(总共 8 个:正面、侧面、背面等……)。
- 图像由Regnet和BiFPN等网络提取特征
- 接着transformer模块,使用注意力模块,采用位置图像编码加上QKV获得特征,以此来产生占用Occupancy。
- 这会产生一个Occupancy feature,然后将其与之前的体积(t-1、t-2 等)融合,以获得4D Occupancy feature。
- 最后,我们使用反卷积来检索原始大小并获得两个输出:Occupancy volume和Occupancy flow。
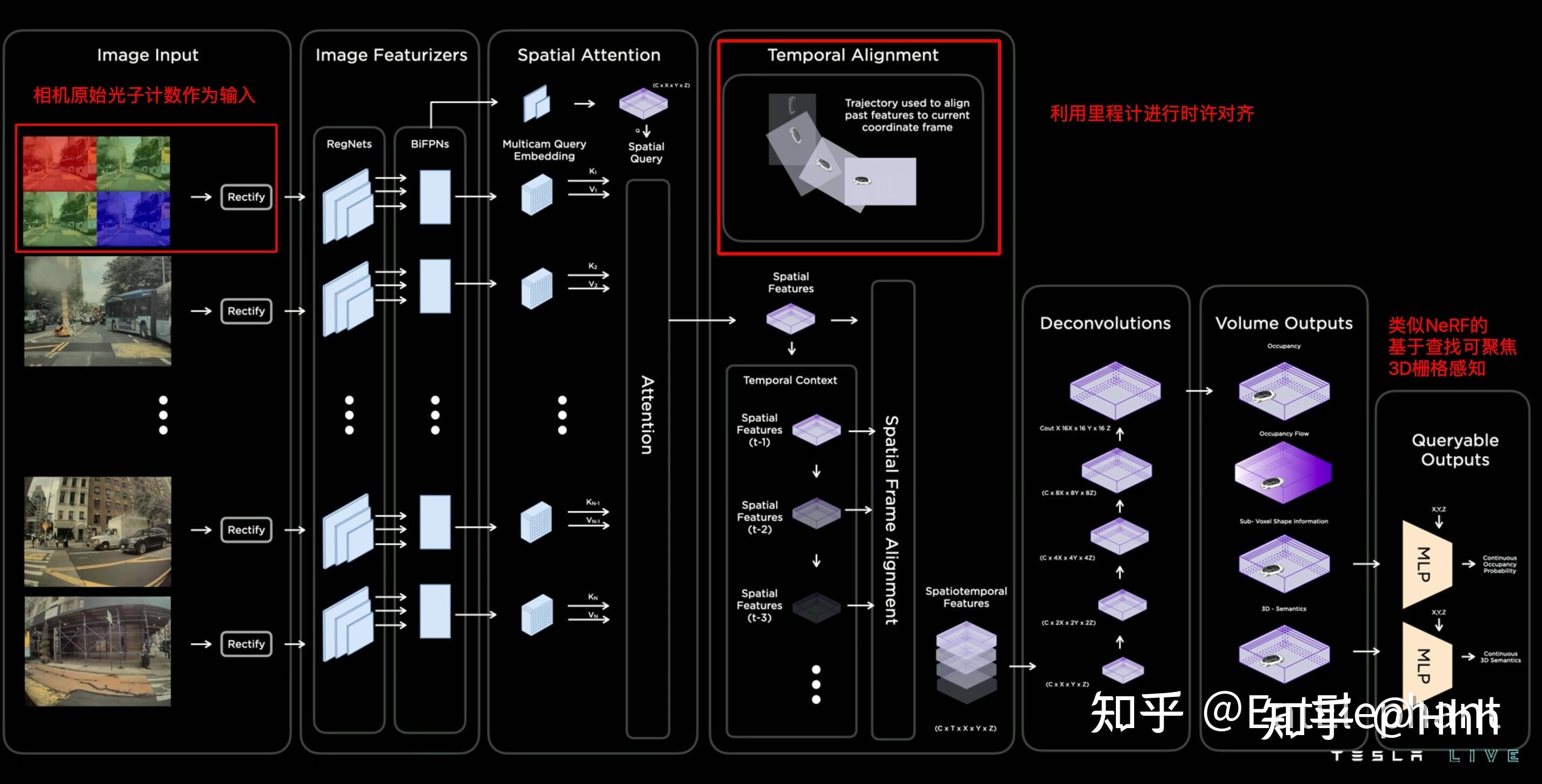
AI day时的网络结构
相比cvpr时,AI day上的分享更加详细,主要有三点更新:
- 最左侧是基于photon count的传感器图像作为模型输入(虽然鼓吹的很高大上,其实就是ISP处理前的raw数据),这里的好处是可以在低光照、可见度低等情况下,感知的动态范围更好。
- temporal alignment利用里程计信息,对前面时刻的occupancy features进行时序上的加权融合,不同的时间的特征有着不同的权重,然后时序信息似乎实在Channel维度进行拼接的?组合后的特征进入deconv模块提高分辨率。这样看来时序融合上,更倾向于使用类似transformer或者时间维度作为一个channel的时序cnn进行并行的处理,而非spatial RNN方案。
- 相比CVPR的方案,除了输出3D occupancy特征和occupancy flow(速度,加速度)以外,还增加了基于x,y,z坐标的query思路(借鉴了Nerf),可以给occupancy network提供基于query的亚像素、变分辨率的几何和语义输出。
因为nerf只能离线重建,输出的occupancy 猜想可以通过提前训好的的nerf生成GT来监督?
光流估计和Occupancy flow
特斯拉在这里实际上做的是预测光流。在计算机视觉中,光流是像素从一帧到另一帧的移动量。输出通常是flow map 。
在这种情况下,可以有每一个体素的流动,因此每辆车的运动都可以知道;这对于遮挡非常有帮助,但对于预测、规划等其他问题也很有帮助

Occupancy Flow(来源)
Occupancy flow实际上显示了每个对象的方向:红色:向前 — 蓝色:向后 — 灰色:静止等……(实际上有一个色轮代表每个可能的方向)
Nerf

特斯拉的 NeRF(来源)
神经辐射场,或 Nerf,最近席卷了3D 重建;特斯拉也是其忠实粉丝。它最初的想法是从多视图图像中重建场景(详见3D 重建课程)。
这与occupancy network 非常相似,但这里的不同之处在于也是从多个位置执行此操作的。在建筑物周围行驶,并重建建筑物。这可以使用一辆汽车或特斯拉车队在城镇周围行驶来完成。
这些 NeRF 是如何使用的?
由于Occupancy network产生 3D volume,可以将这些 3D volume与 3D-reconstruction volume(Nerf离线训练得到)进行比较,从而比较预测的 3D 场景是否与“地图”匹配(NeRF 产生 3D重建)。
在这些重建过程中也可能出现问题是图像模糊、雨、雾等……为了解决这个问题,他们使用车队平均(每次车辆看到场景,它都会更新全局 3D 重建场景)和描述符而不是纯像素。

使用Nerf的descriptor
这就是获得最终输出的方式!特斯拉还宣布了一种名为隐式网络的新型网络,其主要思想是相似的:通过判断视图是否被占用来避免冲突
总结来说:
- 当前仅基于视觉的系统的算法存在问题:它们不连续,在遮挡方面做得不好,无法判断物体是移动还是静止,并且它们依赖于物体检测。 因此,特斯拉决定发明“Occupancy network”,它可以判断 3D 空间中的一个单元格是否被占用。
- 这些网络改进了 3 个主要方面:鸟瞰图、物体类别和固定大小的矩形。
- occupancy network分 4 个步骤工作:特征提取、注意和occupancy检测、多帧对齐和反卷积,从而预测光流估计和占用估计。
- 生成 3D 体积后,使用 NeRF(神经辐射场)将输出与经过训练的 3D 重建场景进行比较。
- 车队平均采集数据用于解决遮挡、模糊、天气等场景
reference: