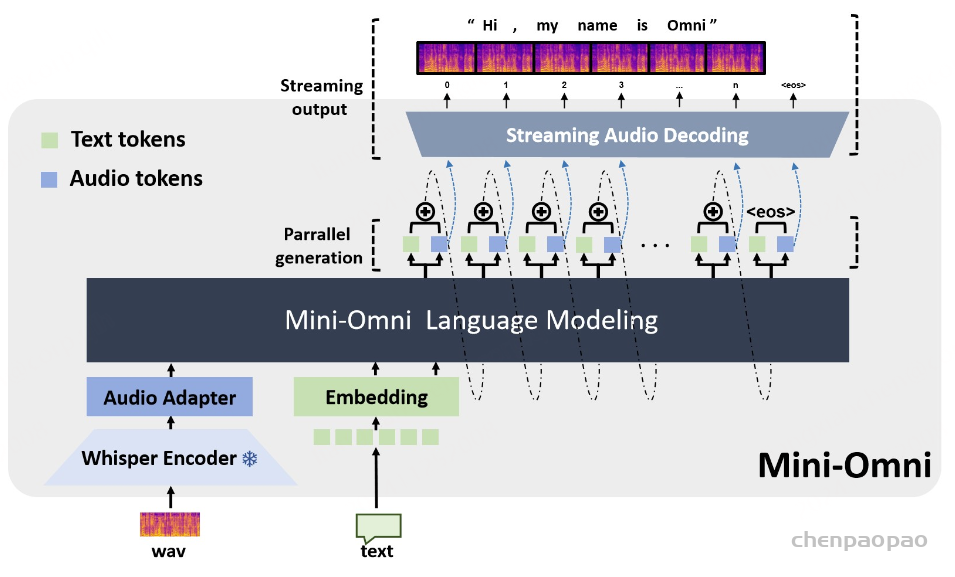
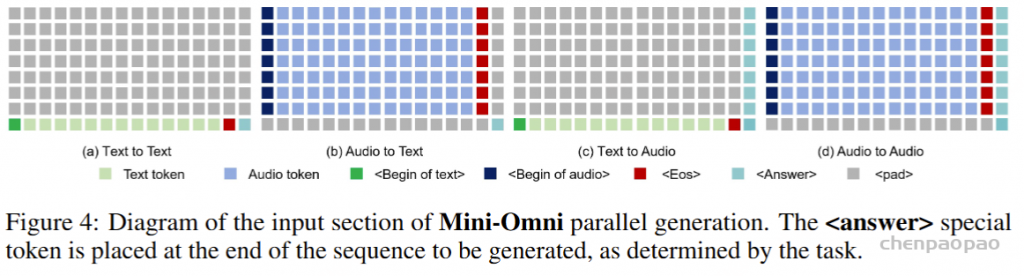
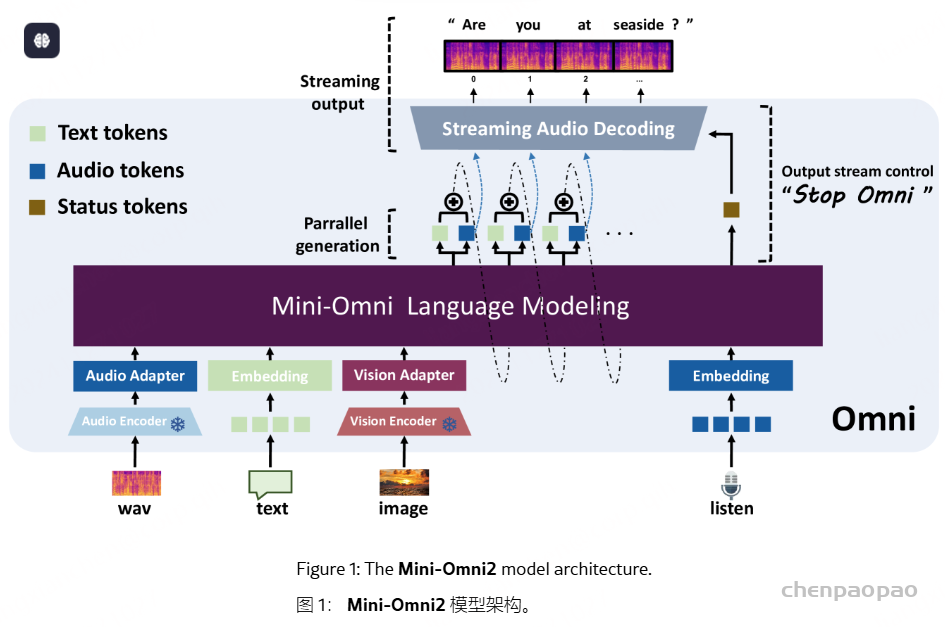
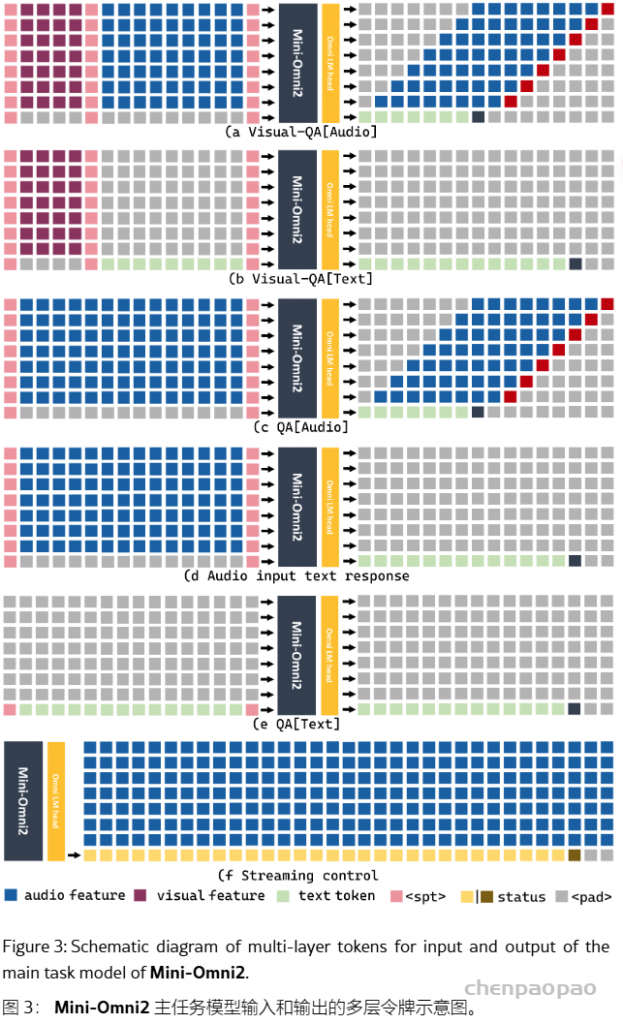
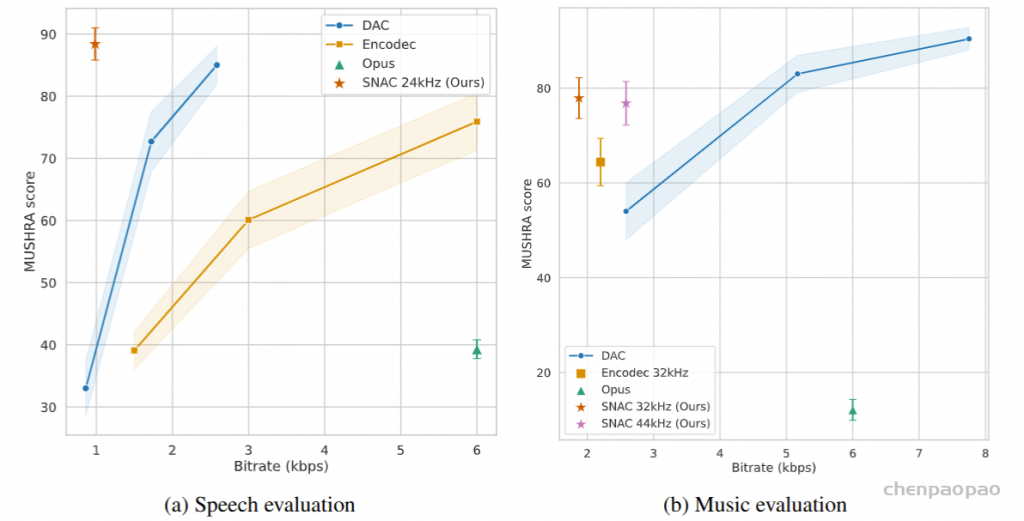
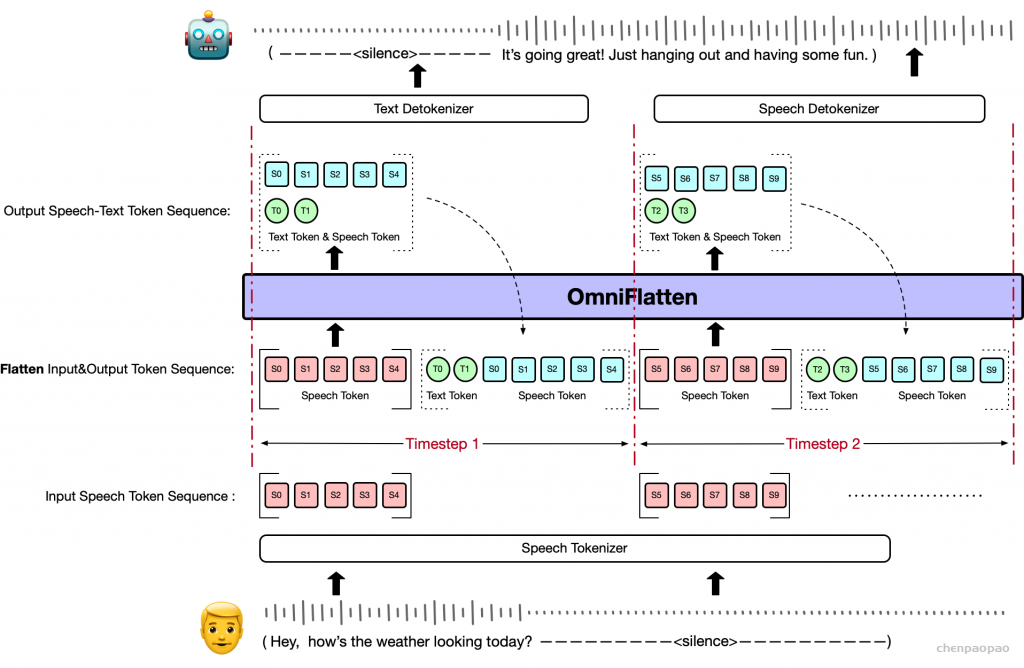
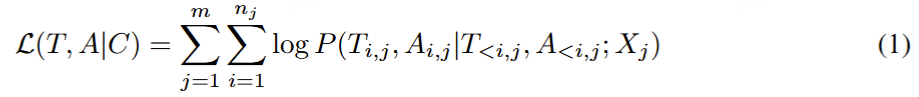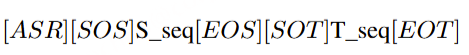生成音频token时以对应文本token为条件,类似在线语音合成系统,且生成音频前用 N 个pad token填充,确保先产生文本token。
模型可依据说话者和风格的embedding,控制说话者特征和风格元素。
Introduction
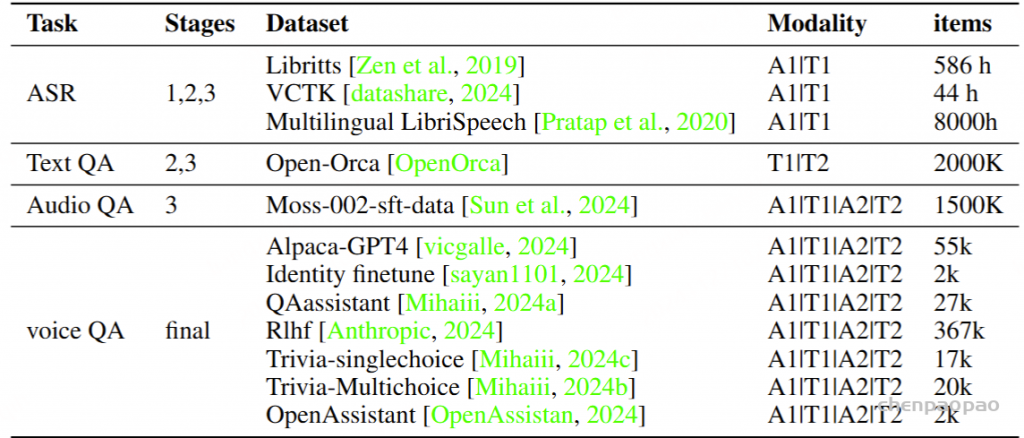
Mini-Omni,这是一种基于音频的端到端对话模型,能够进行实时语音交互。为了实现这种能力,提出了一种文本指导的语音生成方法,以及推理过程中的批处理并行策略,以进一步提高性能。该方法还有助于以最小的退化保留原始模型的语言能力,使其他工作能够建立实时交互能力。我们将这种训练方法称为 “Any Model Can Talk”。我们还引入了 VoiceAssistant-400K数据集,以微调针对语音输出优化的模型。据我们所知,Mini-Omni是第一个用于实时语音交互的完全端到端的开源模型,为未来的研究提供了宝贵的潜力。
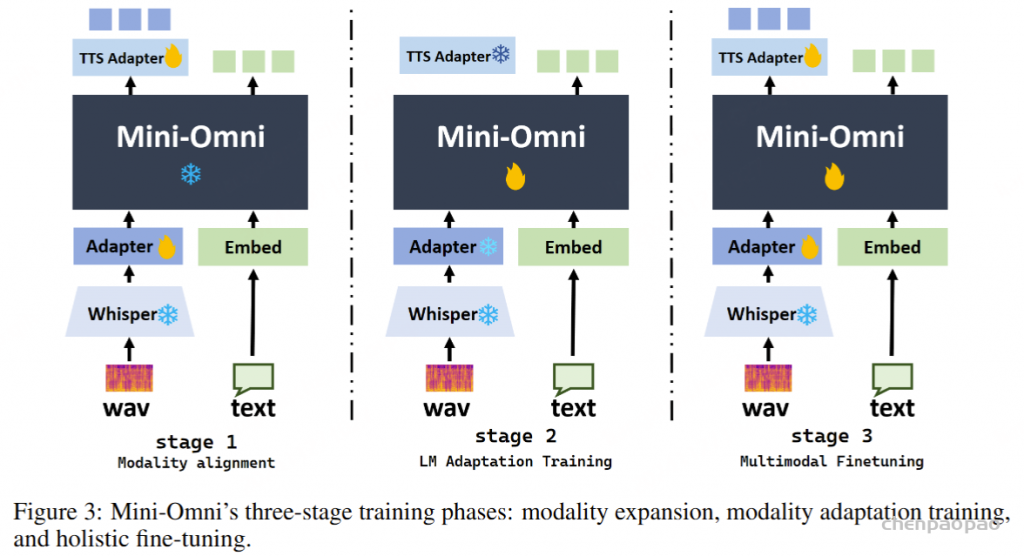
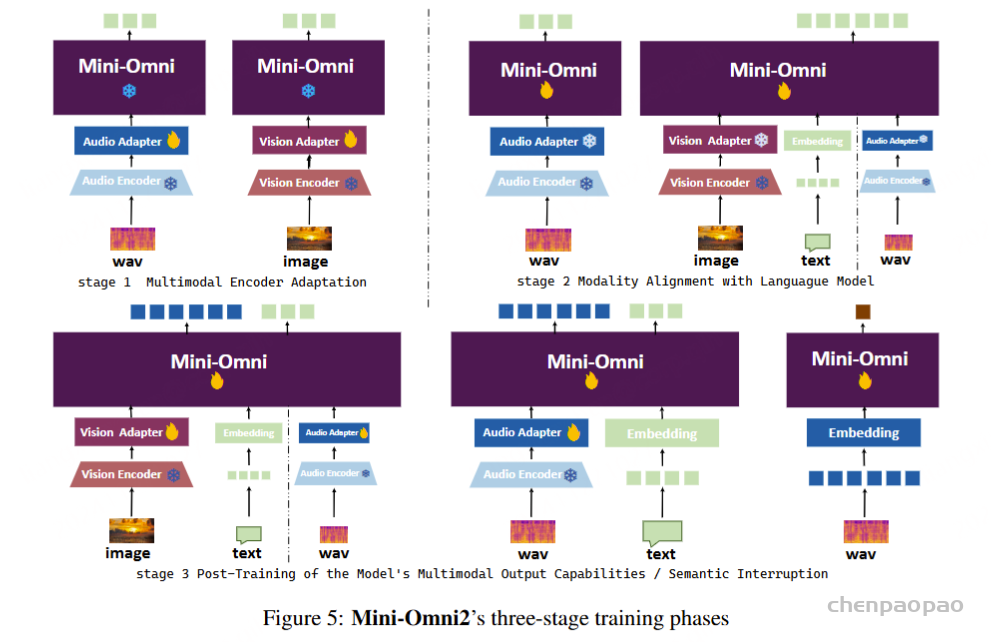
我们还提出了一种方法,该方法只要对原始模型进行最少的训练和修改,使其他工作能够快速发展自己的语音能力。我们将这种方法称为 “Any Model Can Talk”,旨在使用有限数量的附加数据实现语音输出。该方法通过额外的适配器和预先训练的模型来扩展语音功能,并使用少量合成数据进行微调。这与上述并行建模方法相结合,可以在新模态中启用流式输出,同时保留原始模型的推理能力。
提出了一种同时生成文本和音频的新方法。这种方法假设文本输出具有更高的信息密度,因此可以通过更少的标记实现相同的响应。在生成音频标记的过程中,模型能够高效地基于对应的文本标记进行条件生成,类似于在线 TTS 系统。为确保在生成音频标记之前先生成对应的文本标记,我们在模型中引入了以 N 个标记进行填充的机制,该值可作为超参数进行调整。此外,模型还能够基于说话人嵌入和风格嵌入进行条件生成,从而实现对说话人特征和风格元素的控制。
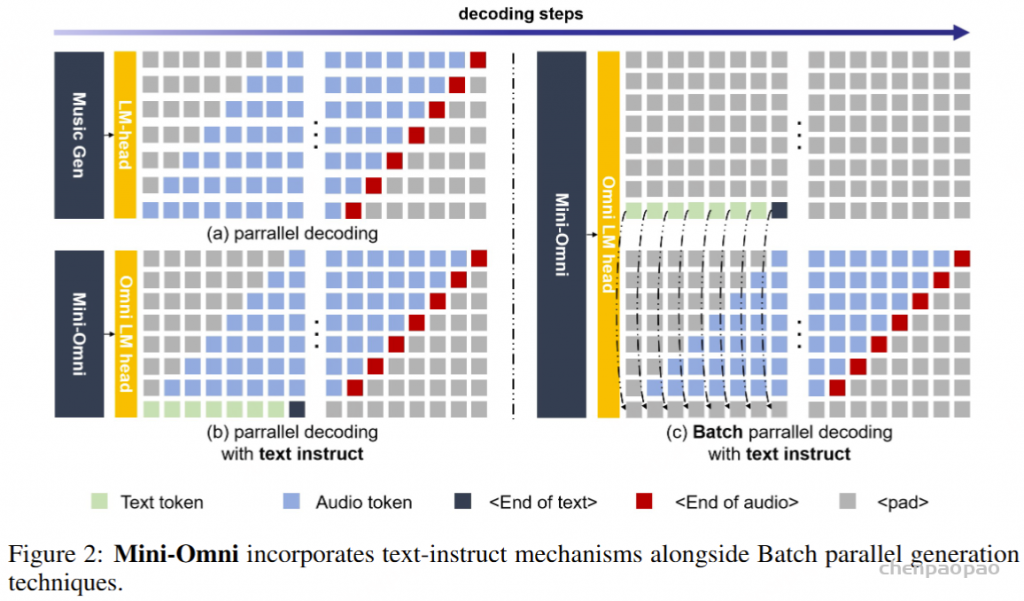
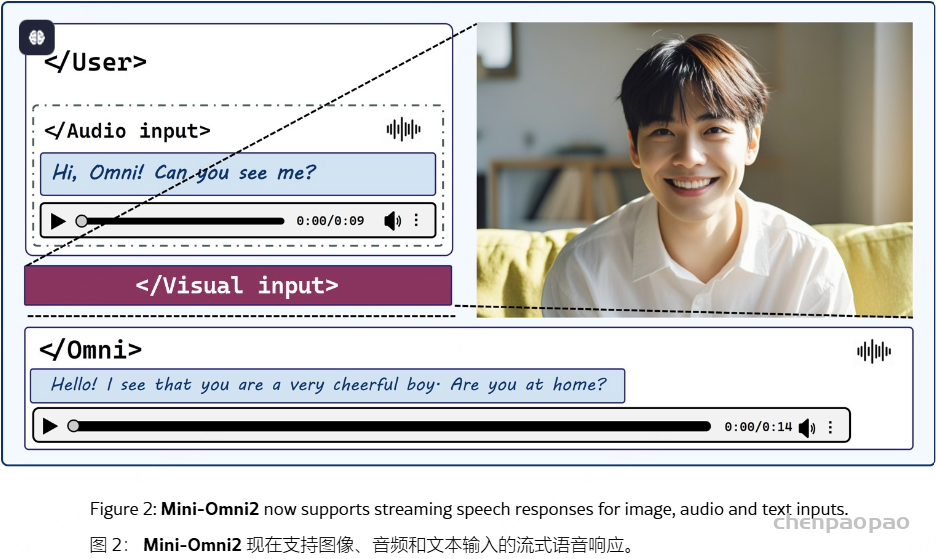
Mini-Omni,这是第一个具有直接语音转语音功能的多模态模型。在以前使用文本引导语音生成的方法的基础上,我们提出了一种并行文本和音频生成方法,该方法利用最少的额外数据和模块将语言模型的文本功能快速传输到音频模态,支持具有高模型和数据效率的流式输出交互。我们探索了文本指令流式并行生成和批量并行生成,进一步增强了模型的推理能力和效率。我们的方法使用只有 5 亿个参数的模型成功地解决了具有挑战性的实时对话任务。我们开发了基于前适配器和后适配器设计的 Any Model Can Talk 方法,以最少的额外训练促进其他模型的快速语音适应。此外,我们还发布了 VoiceAssistant-400K 数据集,用于微调语音输出,旨在最大限度地减少代码符号的生成,并以类似语音助手的方式帮助人类。我们所有的数据、推理和训练代码都将在 https://github.com/gpt-omni/mini-omni 逐步开源。
深度可分离卷积最初被引入是为了在视觉应用中构建更轻量的模型。通过对每个输入通道应用单个滤波器,该方法显著减少了计算量和模型大小。建议在生成器中使用深度卷积,不仅可以减少参数数量,还能稳定训练过程。基于 GAN 的声码器(vocoders)以其训练的不稳定性而闻名,通常在早期训练阶段会出现梯度发散,导致训练不稳定甚至模型崩溃。
HierSpeech++: Bridging the Gap between Semantic and Acoustic Representation of Speech by Hierarchical Variational Inference for Zero-shot Speech Synthesis
This dataset list includes all the raw datasets we have found up to now. You may also find their Data Type* as well as their status*. 此数据集列表包括我们迄今为止找到的所有原始数据集。您还可以找到他们的数据类型* 以及他们的状态*。
Most datasets are made public, hence downloadable through the URL in the list. You may find download scripts for some of them in audio-dataset/utils/. For those datasets who do not have any link in the list, they are purchased by LAION hence we can not make it public due to license issue. Do please contact us if you want to process them. 大多数数据集都是公开的,因此可以通过列表中的 URL 下载。您可以在 audio-dataset/utils/ 中找到其中一些的下载脚本。对于那些列表中没有任何链接的数据集,它们是由 LAION 购买的,因此由于许可证问题,我们无法公开。如果您想处理它们,请联系我们。
For using the excat processed dataset for training your models, please contact LAION. 如需使用 excat 处理的数据集来训练您的模型,请联系 LAION。
*Data Type Terminology Explanation *数据类型术语解释
Caption: A natural language sentence describing the content of the audio 字幕:描述音频内容的自然语言句子Example: A wooden door creaks open and closed multiple times 示例:木门吱吱作响地打开和关闭多次
Class label: Labels that are often manually annotated for classification in curated datasets. Each audio clip can be assigned with one or several class label. 类标签:通常在特选数据集中手动注释以进行分类的标签。可以为每个音频剪辑分配一个或多个类标签。Example: Cat, Dog, Water 示例:猫、狗、水
Tag: Tags of the audio that are commenly associated with data in website. A audio clip may be associated to several tags 标签:与网站中的数据相关的音频标签。一个音频剪辑可能与多个标签相关联Example: phone recording, city, sound effect 示例:电话录音、城市、音效
Relative text: Any text about the audio. May be comments on the audio, or other metadata. Can be very long. 相对文本:有关音频的任何文本。可能是对音频的评论或其他元数据。可以很长。Exmaple: An impact sound that I would hear over an action scene, with some cinematic drums for more tension and a high pitched preexplosion sound followed by the impact of the explosion. Please rate only if you like it, haha. Thanks! 示例:我在动作场景中会听到的撞击声,一些电影鼓声更加紧张,爆炸前发出高亢的音调,然后是爆炸的冲击声。请只评价你喜欢的,哈哈。谢谢!
Transcription: Transcription of human speech. Only used for Speech Datasets. 转录:人类语音的转录。仅用于语音数据集。
Translation: Transcription in an other language of what the speaker uses. 翻译:说话人使用的其他语言的转录。
*Status Terminology Explanation *状态术语解释
processed: Dataset already converted to webdataset format. processed:数据集已转换为 webdataset 格式。
processing: Dataset already downloaded and the processing going on. processing:数据集已下载,处理正在进行中。
meatadata downloaded: We have already scraped the dataset website, wheras the dataset itself is not yet downloaded. meatadata downloaded:我们已经抓取了数据集网站,但数据集本身尚未下载。
assigned: Someone have begun the work on the dataset. assigned:有人已开始处理数据集。
General Sound Dataset General Sound 数据集
Name 名字
Description 描述
URL
Data Type 数据类型
Total Duration 总持续时间
Total Audio Number 音频总数
Status 地位
AudioSet 音频集
The AudioSet dataset is a large-scale collection of human-labeled 10-second sound clips drawn from YouTube videos. To collect all our data we worked with human annotators who verified the presence of sounds they heard within YouTube segments. To nominate segments for annotation, we relied on YouTube metadata and content-based search. The sound events in the dataset consist of a subset of the AudioSet ontology. You can learn more about the dataset construction in our ICASSP 2017 paper. Explore the dataset annotations by sound class below. There are 2,084,320 YouTube videos containing 527 labels AudioSet 数据集是从 YouTube 视频中提取的人工标记的 10 秒声音剪辑的大规模集合。为了收集我们的所有数据,我们与人工注释者合作,他们验证了他们在 YouTube 片段中听到的声音是否存在。为了提名要注释的片段,我们依靠 YouTube 元数据和基于内容的搜索。数据集中的声音事件由 AudioSet 本体的子集组成。您可以在我们的 ICASSP 2017 论文中了解有关数据集构建的更多信息。探索下面的 sound 类数据集注释。有 2,084,320 个 YouTube 视频,包含 527 个标签
33066 sound effects with text description. Type: mostly environmental sound. Each audio has a natural text description. (need to see check the license) 33066 个带有文本描述的音效。类型:主要是环境声音。每个音频都有一个自然的文本描述。(需要查看 检查许可证)
40 000 audio clips of 10 seconds, organized in three splits; a training slipt, a validation slipt, and a testing slipt. Type: environmental sound. 40 000 个 10 秒的音频剪辑,分为三个部分;训练滑道、验证滑道和测试滑道。类型:环境声音。
3700 audio clips from “Hospital” scene and around 3600 audio clips from the “Car” scene. Every audio clip is 10 seconds long and is annotated with five captions. Type: environmental sound. 来自 “Hospital” 场景的 3700 个音频剪辑和来自 “Car” 场景的大约 3600 个音频剪辑。每个音频剪辑时长 10 秒,并带有 5 个字幕。类型:环境声音。
Clotho consists of 6974 audio samples, and each audio sample has five captions (a total of 34 870 captions). Audio samples are of 15 to 30 s duration and captions are eight to 20 words long. Type: environmental sound. Clotho 由 6974 个音频样本组成,每个音频样本有 5 个字幕(总共 34870 个字幕)。音频样本的持续时间为 15 到 30 秒,字幕的长度为 8 到 20 个单词。类型:环境声音。
VGG-Sound is an audio-visual correspondent dataset consisting of short clips of audio sounds, extracted from videos uploaded to YouTube VGG-Sound 是一个视听通讯员数据集,由从上传到 YouTube 的视频中提取的音频短片组成
The Free Universal Sound Separation (FUSS) dataset is a database of arbitrary sound mixtures and source-level references, for use in experiments on arbitrary sound separation. FUSS is based on FSD50K corpus. Free Universal Sound Separation (FUSS) 数据集是一个包含任意混声和源级参考的数据库,用于任意声分离的实验。FUSS 基于 FSD50K 语料库。
YFCC100M is a that dataset contains a total of 100 million media objects, of which approximately 99.2 million are photos and 0.8 million are videos, all of which carry a Creative Commons license, including 8081 hours of audio. YFCC100M 是一个 THAT 数据集,总共包含 1 亿个媒体对象,其中大约 9920 万个是照片,80 万个是视频,所有这些对象都带有 Creative Commons 许可证,包括 8081 小时的音频。
100M video clips with audio, each 10 sec, with automatic AudioSet, Kinetics400 and Imagenet labels. -> Noisy, but LARGE. 100M 带音频的视频剪辑,每段 10 秒,带有自动 AudioSet、Kinetics400 和 Imagenet 标签。-> 吵闹,但很大。
This is a dataset containing audio captions and corresponding audio tags for a number of 3930 audio files of the TAU Urban Acoustic Scenes 2019 development dataset (airport, public square, and park). The files were annotated using a web-based tool. Each file is annotated by multiple annotators that provided tags and a one-sentence description of the audio content. The data also includes annotator competence estimated using MACE (Multi-Annotator Competence Estimation). 这是一个数据集,其中包含 TAU Urban Acoustic Scenes 2019 开发数据集(机场、公共广场和公园)的 3930 个音频文件的字幕和相应的音频标签。这些文件使用基于 Web 的工具进行注释。每个文件都由多个注释器进行注释,这些注释器提供音频内容的标记和一句话描述。数据还包括使用 MACE(多注释者能力估计)估计的注释者能力。
Dataset contains thousands of vocal imitations of a large set of diverse sounds.The dataset also contains data on hundreds of people’s ability to correctly label these vocal imitations, collected via Amazon’s Mechanical Turk Dataset 包含大量不同声音的数千个人声模仿。该数据集还包含数百人正确标记这些人声模仿的能力数据,这些数据是通过亚马逊的 Mechanical Turk 收集的
VimSketch Dataset combines two publicly available datasets(VocalSketch + Vocal Imitation, but Vimsketch delete some parts of the previous two datasets), VimSketch 数据集结合了两个公开可用的数据集(VocalSketch + Vocal Imitation,但 Vimsketch 删除了前两个数据集的部分),
OtoMobile dataset is a collection of recordings of failing car components, created by the Interactive Audio Lab at Northwestern University. OtoMobile consists of 65 recordings of vehicles with failing components, along with annotations. OtoMobile 数据集是由西北大学交互式音频实验室创建的故障汽车部件的录音集合。OtoMobile 由 65 条组件出现故障的车辆的录音以及注释组成。
Knocking Sound Effects With Emotional Intentions 带有情感意图的 Knocking Sound Effects
A dataset of knocking sound effects with emotional intention recorded at a professional foley studio. Five type of emotions to be portrayed in the dataset: anger, fear, happiness, neutral and sadness. 在专业拟音工作室录制的带有情感意图的敲击音效数据集。数据集中要描绘的五种情绪:愤怒、恐惧、快乐、中立和悲伤。
60K hours of unlabelled speech from audiobooks in English and a small labelled dataset (10h, 1h, and 10 min) plus metrics, trainable baseline models, and pretrained models that use these datasets. 来自英语有声读物的 60K 小时未标记语音和一个小型标记数据集(10 小时、1 小时和 10 分钟)以及使用这些数据集的指标、可训练基线模型和预训练模型。
A Multilingual Speech Translation Corpus, that contains paired audio-text samples for Speech Translation, constructed using the debates carried out in the European Parliament in the period between 2008 and 2012. 多语言语音翻译语料库,包含用于语音翻译的成对音频文本样本,使用 2008 年至 2012 年期间在欧洲议会进行的辩论构建。
A large-scale multilingual ST corpus based on Common Voice, to foster ST research with the largest ever open dataset. Its latest version covers translations from English into 15 languages—Arabic, Catalan, Welsh, German, Estonian, Persian, Indonesian, Japanese, Latvian, Mongolian, Slovenian, Swedish, Tamil, Turkish, Chinese—and from 21 languages into English, including the 15 target languages as well as Spanish, French, Italian, Dutch, Portuguese, Russian. It has total 2,880 hours of speech and is diversified with 78K speakers. 基于 Common Voice 的大规模多语言 ST 语料库,以有史以来最大的开放数据集促进 ST 研究。其最新版本涵盖从英语翻译成 15 种语言—阿拉伯语、加泰罗尼亚语、威尔士语、德语、爱沙尼亚语、波斯语、印度尼西亚语、日语、拉脱维亚语、蒙古语、斯洛文尼亚语、瑞典语、泰米尔语、土耳其语、中文—以及从 21 种语言翻译成英语,包括 15 种目标语言以及西班牙语、法语、意大利语、荷兰语、葡萄牙语、俄语。它总共有 2,880 小时的语音,并拥有 78K 扬声器。
An evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. 一个不断发展的多域英语语音识别语料库,具有 10000 小时的高质量标记音频(适用于监督训练)和 40000 小时的总音频(适用于半监督和无监督训练)。
This is a public domain speech dataset consisting of 13,100 short audio clips of a single speaker reading passages from 7 non-fiction books. A transcription is provided for each clip. Clips vary in length from 1 to 10 seconds and have a total length of approximately 24 hours. 这是一个公共领域的语音数据集,由 13,100 个简短的音频剪辑组成,其中单个说话人朗读了 7 本非小说类书籍的段落。为每个剪辑提供转录。剪辑的长度从 1 秒到 10 秒不等,总长度约为 24 小时。
This dataset consists of 100,000 episodes from different podcast shows on Spotify. The dataset is available for research purposes. We are releasing this dataset more widely to facilitate research on podcasts through the lens of speech and audio technology, natural language processing, information retrieval, and linguistics. The dataset contains about 50,000 hours of audio, and over 600 million transcribed words. The episodes span a variety of lengths, topics, styles, and qualities. Only non-commercial research is permitted on this dataset 该数据集包含来自 Spotify 上不同播客节目的 100,000 集。该数据集可用于研究目的。我们正在更广泛地发布此数据集,以便通过语音和音频技术、自然语言处理、信息检索和语言学的视角来促进对播客的研究。该数据集包含大约 50000 小时的音频和超过 6 亿个转录单词。这些剧集跨越各种长度、主题、风格和质量。此数据集只允许进行非商业研究
The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) 瑞尔森情感语音和歌曲视听数据库 (RAVDESS)
The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) contains 7356 files (total size: 24.8 GB). The database contains 24 professional actors (12 female, 12 male), vocalizing two lexically-matched statements in a neutral North American accent. Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) 包含 7356 个文件(总大小:24.8 GB)。该数据库包含 24 名专业演员(12 名女性,12 名男性),以中性的北美口音发音两个词汇匹配的陈述。
CREMA-D is a data set of 7,442 original clips from 91 actors. These clips were from 48 male and 43 female actors between the ages of 20 and 74 coming from a variety of races and ethnicities (African America, Asian, Caucasian, Hispanic, and Unspecified). Actors spoke from a selection of 12 sentences. The sentences were presented using one of six different emotions (Anger, Disgust, Fear, Happy, Neutral and Sad) and four different emotion levels (Low, Medium, High and Unspecified). CREMA-D 是一个包含来自 91 位演员的 7,442 个原始剪辑的数据集。这些剪辑来自 48 名男性演员和 43 名女性演员,年龄在 20 至 74 岁之间,来自不同种族和民族(非裔美国人、亚洲人、高加索人、西班牙裔和未指定人)。演员们从精选的 12 句话中发言。这些句子使用六种不同的情绪(愤怒、厌恶、恐惧、快乐、中立和悲伤)中的一种和四种不同的情绪级别(低、中、高和未指定)来呈现。
The emotional Voice Database. This dataset is built for the purpose of emotional speech synthesis. It includes recordings for four speakers- two males and two females. The emotional styles are neutral, sleepiness, anger, disgust and amused. 情感语音数据库。此数据集是为情感语音合成而构建的。它包括四个扬声器的录音 – 两个男性和两个女性。情绪风格是中性、困倦、愤怒、厌恶和逗乐。
The databases consist of around 1150 utterances carefully selected from out-of-copyright texts from Project Gutenberg. The databses include US English male (bdl) and female (slt) speakers (both experinced voice talent) as well as other accented speakers. 这些数据库包含大约 1150 条话语,这些话语是从 Project Gutenberg 的版权外文本中精心挑选出来的。数据库包括美国英语男性 (bdl) 和女性 (slt) 说话人(均为经验丰富的配音人才)以及其他带口音的说话人。
The Interactive Emotional Dyadic Motion Capture (IEMOCAP) database is an acted, multimodal and multispeaker database. It contains approximately 12 hours of audiovisual data, including video, speech, motion capture of face, text transcriptions. 交互式情感二元动作捕捉 (IEMOCAP) 数据库是一个行动、多模态和多说话人数据库。它包含大约 12 小时的视听数据,包括视频、语音、面部动作捕捉、文本转录。
We introduce the Free Music Archive (FMA), an open and easily accessible dataset suitable for evaluating several tasks in MIR, a field concerned with browsing, searching, and organizing large music collections. The community’s growing interest in feature and end-to-end learning is however restrained by the limited availability of large audio datasets. The FMA aims to overcome this hurdle by providing 917 GiB and 343 days of Creative Commons-licensed audio from 106,574 tracks from 16,341 artists and 14,854 albums, arranged in a hierarchical taxonomy of 161 genres. It provides full-length and high-quality audio, pre-computed features, together with track- and user-level metadata, tags, and free-form text such as biographies. We here describe the dataset and how it was created, propose a train/validation/test split and three subsets, discuss some suitable MIR tasks, and evaluate some baselines for genre recognition. Code, data, and usage examples are available at https://github.com/mdeff/fma. 我们介绍了免费音乐档案 (FMA),这是一个开放且易于访问的数据集,适用于评估 MIR 中的多项任务,MIR 是一个与浏览、搜索和组织大型音乐收藏有关的领域。然而,社区对功能和端到端学习的兴趣日益浓厚,但由于大型音频数据集的可用性有限,这限制了他们。FMA 旨在通过提供来自 16,341 位艺术家和 14,854 张专辑的 106,574 首曲目的 917 GiB 和 343 天的知识共享许可音频来克服这一障碍,这些音频按照 161 种流派的分层分类法排列。它提供全长和高质量的音频、预计算功能,以及轨道和用户级元数据、标签和自由格式的文本,例如传记。我们在这里描述了数据集及其创建方式,提出了一个训练/验证/测试拆分和三个子集,讨论了一些合适的 MIR 任务,并评估了一些流派识别的基线。代码、数据和用法示例可在 https://github.com/mdeff/fma 中找到。
MusicNet is a collection of 330 freely-licensed classical music recordings, together with over 1 million annotated labels indicating the precise time of each note in every recording, the instrument that plays each note, and the note’s position in the metrical structure of the composition. The labels are acquired from musical scores aligned to recordings by dynamic time warping. The labels are verified by trained musicians; we estimate a labeling error rate of 4%. We offer the MusicNet labels to the machine learning and music communities as a resource for training models and a common benchmark for comparing results. URL: https://homes.cs.washington.edu/~thickstn/musicnet.html MusicNet 是 330 张免费授权的古典音乐录音的集合,以及超过 100 万个带注释的标签,这些标签指示了每个录音中每个音符的精确时间、演奏每个音符的乐器以及音符在乐曲的度量结构中的位置。标签是通过动态时间扭曲从与录音对齐的乐谱中获得的。唱片公司由训练有素的音乐家进行验证;我们估计标记错误率为 4%。我们为机器学习和音乐社区提供 MusicNet 标签,作为训练模型的资源和比较结果的通用基准。网址:https://homes.cs.washington.edu/~thickstn/musicnet.html
We introduce the MetaMIDI Dataset (MMD), a large scale collection of 436,631 MIDI files and metadata. In addition to the MIDI files, we provide artist, title and genre metadata that was collected during the scraping process when available. MIDIs in (MMD) were matched against a collection of 32,000,000 30-second audio clips retrieved from Spotify, resulting in over 10,796,557 audio-MIDI matches. In addition, we linked 600,142 Spotify tracks with 1,094,901 MusicBrainz recordings to produce a set of 168,032 MIDI files that are matched to MusicBrainz database. These links augment many files in the dataset with the extensive metadata available via the Spotify API and the MusicBrainz database. We anticipate that this collection of data will be of great use to MIR researchers addressing a variety of research topics. 我们介绍 MetaMIDI 数据集 (MMD),这是一个包含 436,631 个 MIDI 文件和元数据的大型集合。除了 MIDI 文件之外,我们还提供在抓取过程中收集的艺术家、标题和流派元数据(如果可用)。(MMD) 中的 MIDI 与从 Spotify 检索的 32,000,000 个 30 秒音频剪辑集合进行匹配,从而产生超过 10,796,557 个音频-MIDI 匹配。此外,我们将 600,142 个 Spotify 曲目与 1,094,901 个 MusicBrainz 录音链接起来,生成了一组与 MusicBrainz 数据库匹配的 168,032 个 MIDI 文件。这些链接通过通过 Spotify API 和 MusicBrainz 数据库提供的大量元数据来扩充数据集中的许多文件。我们预计这些数据收集将对处理各种研究主题的 MIR 研究人员非常有用。
MUSDB18 consists of a total of 150 full-track songs of different styles and includes both the stereo mixtures and the original sources, divided between a training subset and a test subset. MUSDB18 由总共 150 首不同风格的全轨歌曲组成,包括立体声混音和原始源,分为训练子集和测试子集。
Here’s a list of multitrack projects which can be freely downloaded for mixing practice purposes. All these projects are presented as ZIP archives containing uncompressed WAV files (24-bit or 16-bit resolution and 44.1kHz sample rate). 以下是可以免费下载用于混音练习目的的多轨项目列表。所有这些项目都以 ZIP 档案的形式呈现,其中包含未压缩的 WAV 文件(24 位或 16 位分辨率和 44.1kHz 采样率)。
The Tunebot project is an online Query By Humming system. Users sing a song to Tunebot and it returns a ranked list of song candidates available on Apple’s iTunes website. The database that Tunebot compares to sung queries is crowdsourced from users as well. Users contribute new songs to Tunebot by singing them on the Tunebot website. The more songs people contribute, the better Tunebot works. Tunebot is no longer online but the dataset lives on. Tunebot 项目是一个在线 Query By Humming 系统。用户向 Tunebot 唱歌,它会返回 Apple iTunes 网站上可用的候选歌曲的排名列表。Tunebot 与唱歌查询进行比较的数据库也是从用户那里众包的。用户通过在 Tunebot 网站上演唱新歌来向 Tunebot 贡献新歌。人们贡献的歌曲越多,Tunebot 的效果就越好。Tunebot 不再在线,但数据集仍然存在。
pertinent text (long paragraphs), audio 相关文本(长段落)、音频
Genius
Music lyrics website Music 歌词网站
pertinent text (long paragraphs), audio 相关文本(长段落)、音频
assigned(@marianna13#7139) 已分配(@marianna13#7139)
IDMT-SMT-Audio-Effects
The IDMT-SMT-Audio-Effects database is a large database for automatic detection of audio effects in recordings of electric guitar and bass and related signal processing. IDMT-SMT-Audio-Effects 数据库是一个大型数据库,用于自动检测电吉他和贝斯录音中的音频效果以及相关的信号处理。
72222 hours of general music as 30 second clips, one million different songs.
Temporarily not available
tags, artist names, song titles, audio
synth1B1
One million hours of audio: one billion 4-second synthesized sounds. The corpus is multi-modal: Each sound includes its corresponding synthesis parameters. Since it is faster to render synth1B1 in-situ than to download it, torchsynth includes a replicable script for generating synth1B1 within the GPU.
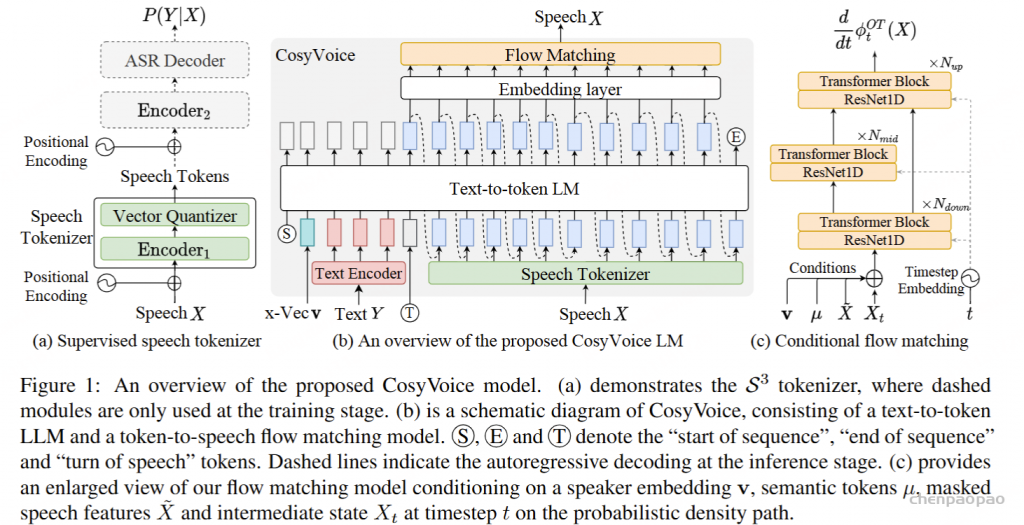
在将离散的语音Token重新转换回音频时,作者同样使用了与CosyVoice中相同的Optimal Transport Conditional Flow Matching模型(OTCFM)。OTCFM将语音Token序列转化为Mel频谱图,然后使用HifiGAN语音生成器生成最终的音频输出。先前的研究表明,相比于更简单的梯度扩散概率模型(DPM),OTCFM在训练更容易且生成更快方面表现更优。
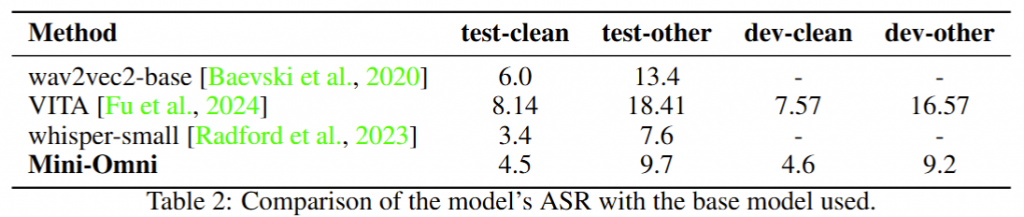
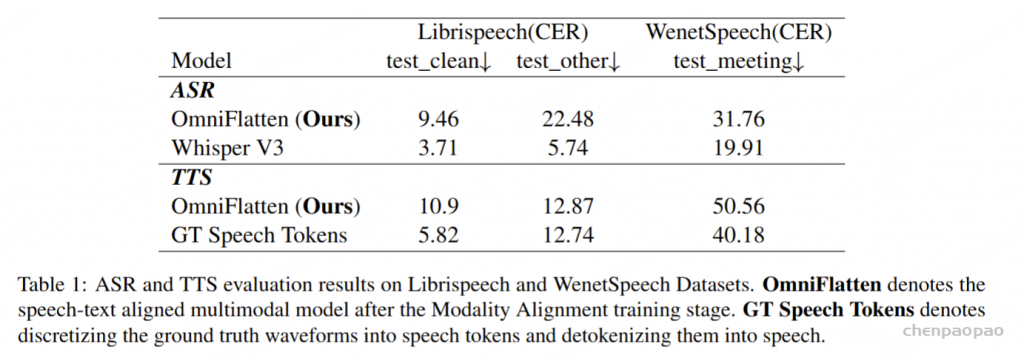
对于TTS评估,作者基于输入文本生成语音Token,然后使用CosyVoice的随机英语女性声音合成为音频。合成的音频随后使用Whisper Large V3模型进行识别,ASR的输出则与输入文本进行对比评分。ASR和TTS评估均在公开可用的LibriSpeech和VoNet Speech数据集上进行,采用字符错误率(CER)作为评估指标。
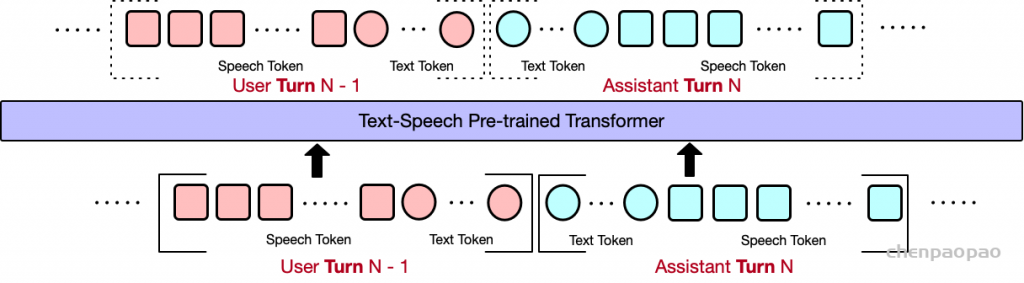
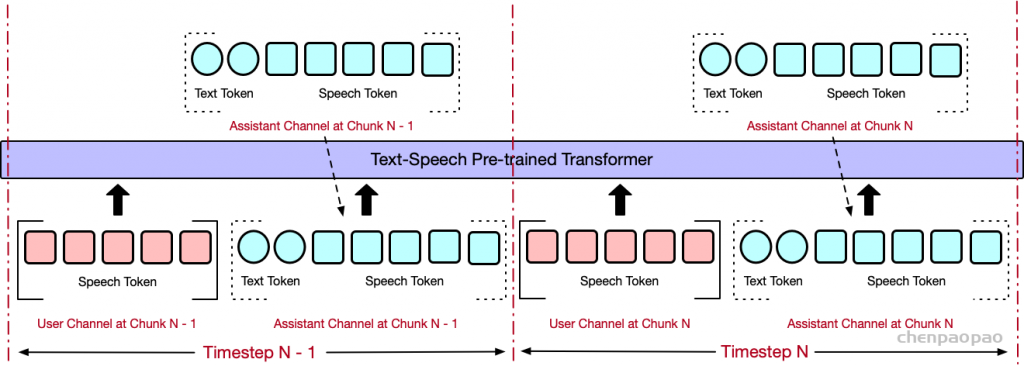
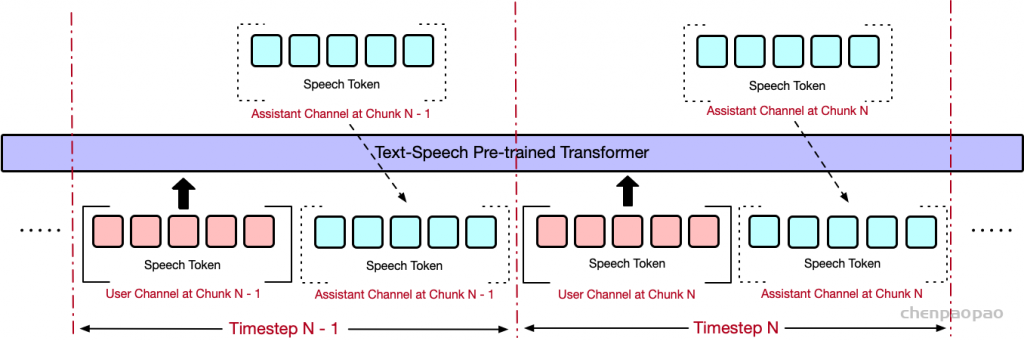
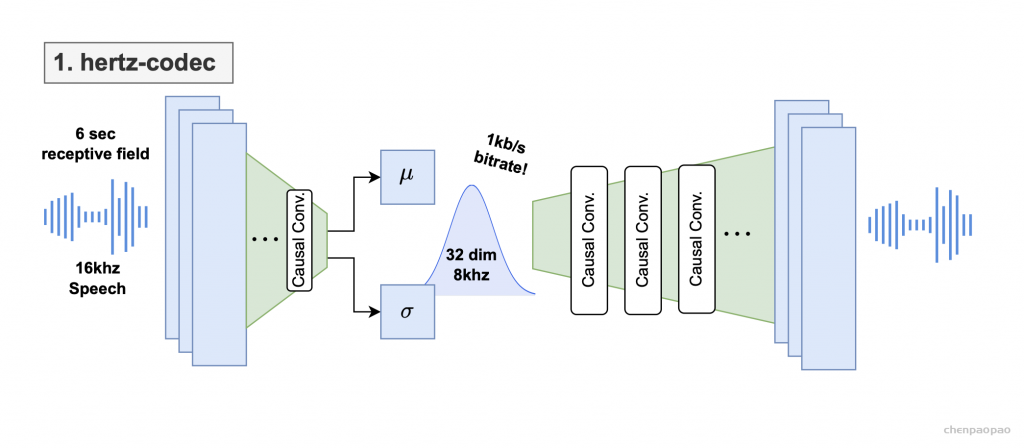
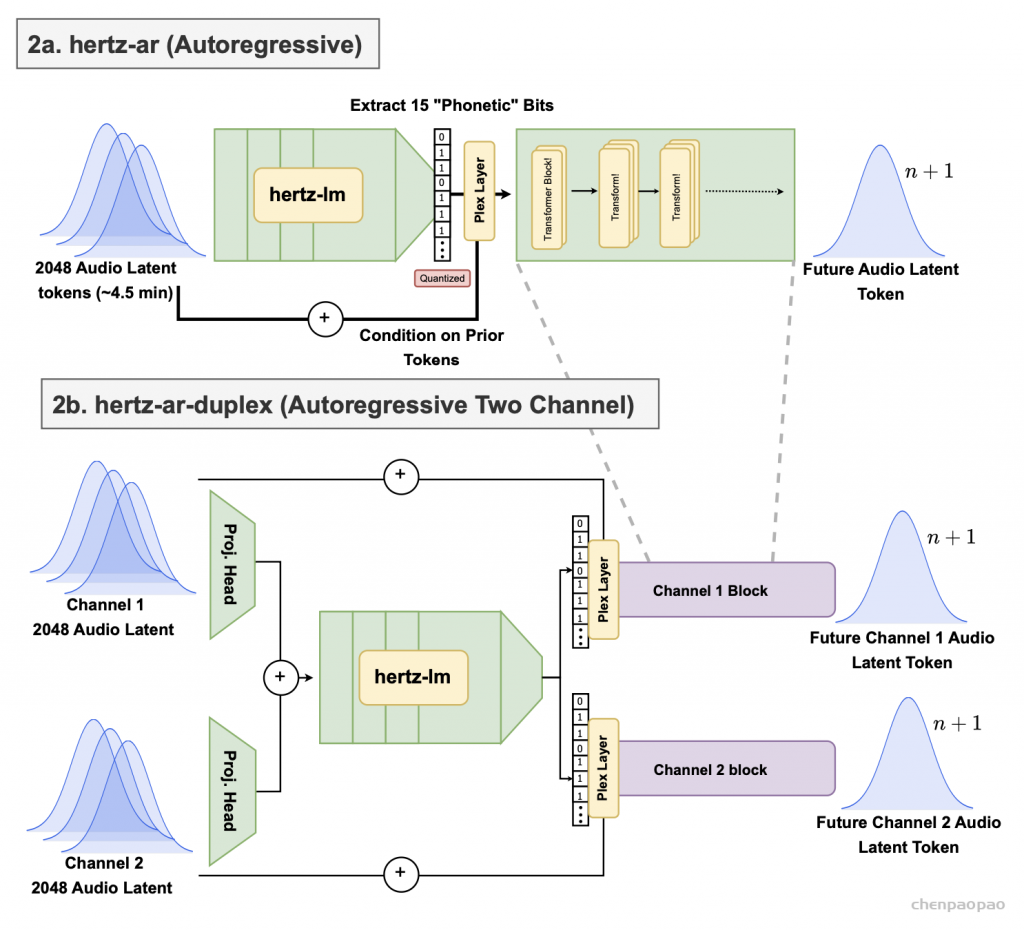
Figure 1: hertz-codec architecture diagram for our VAE. The input is 6s 16kHz mono audio and the output is a 32-dim latent.图 2:我们模型的自回归部分的 hertz-ar 架构图。(2a) 是单通道自回归潜在预测,(2b) 是双工自回归潜在预测。