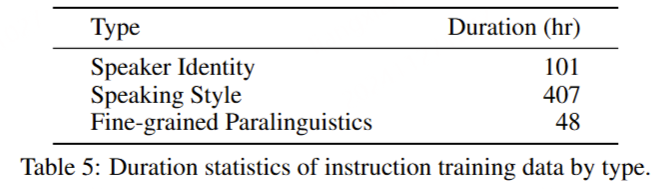
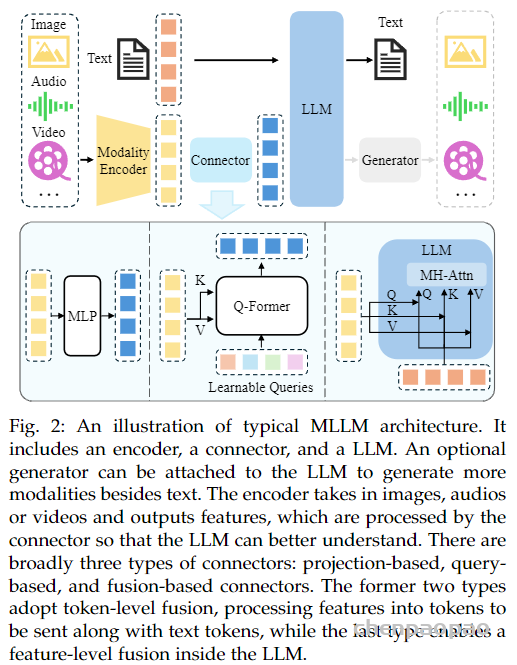
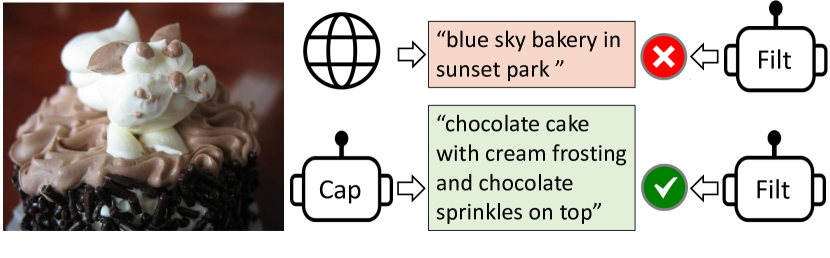
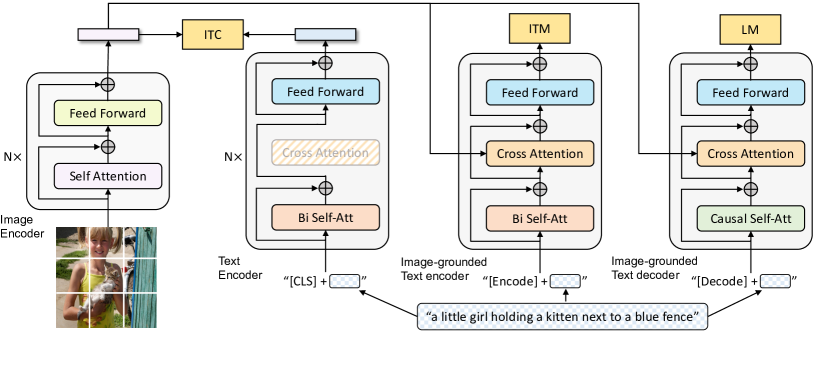
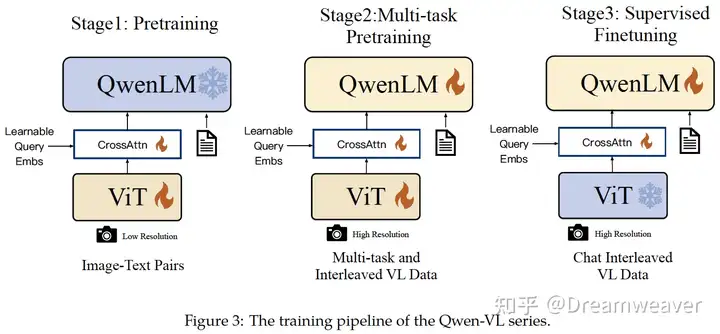
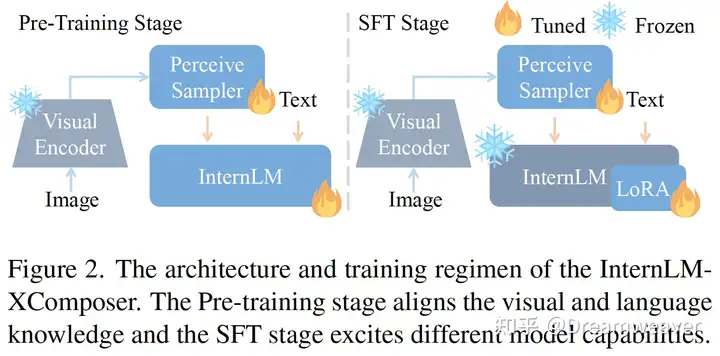
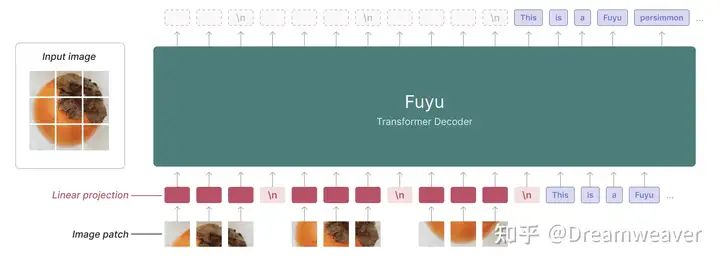
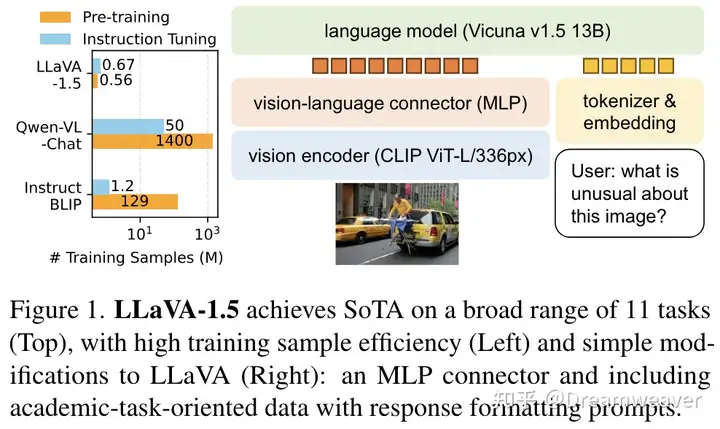
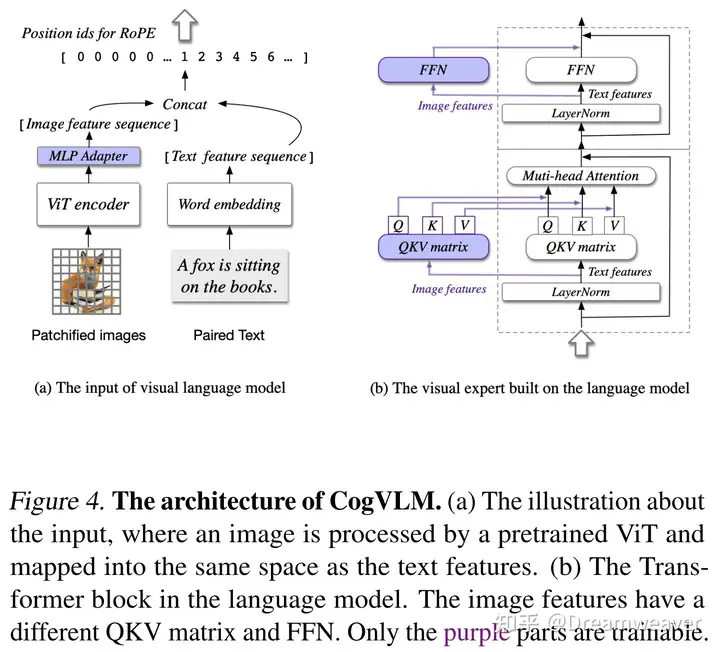
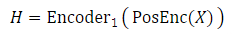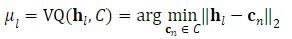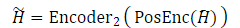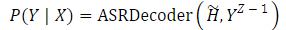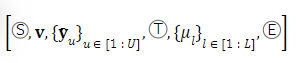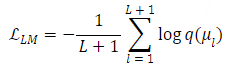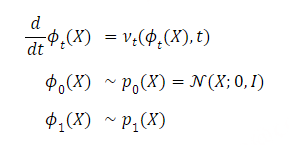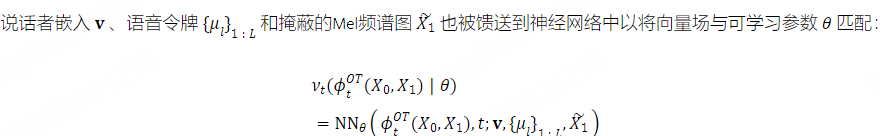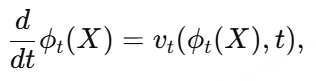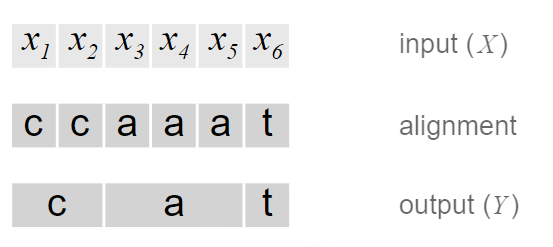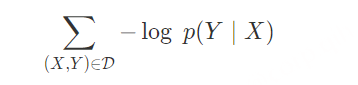###################################
# Sample a speaker from Gaussian.
rand_spk = chat.sample_random_speaker()
print(rand_spk) # save it for later timbre recovery
params_infer_code = ChatTTS.Chat.InferCodeParams(
spk_emb = rand_spk, # add sampled speaker
temperature = .3, # using custom temperature
top_P = 0.7, # top P decode
top_K = 20, # top K decode
)
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = ChatTTS.Chat.RefineTextParams(
prompt='[oral_2][laugh_0][break_6]',
)
wavs = chat.infer(
texts,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code,
)
###################################
# For word level manual control.
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wavs = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
torchaudio.save("output2.wav", torch.from_numpy(wavs[0]), 24000)
Model Implementations for Inference(MII)是一个开源的存储库,通过减轻应用复杂系统优化技术的需求,使所有数据科学家都可以访问低延迟和高吞吐量的推理。开箱即用,MII为数千种广泛使用的DL模型提供支持,使用DeepSpeed-Inference进行优化,可以使用几行代码进行部署,同时与其香草开源版本相比,实现了显着的延迟减少。
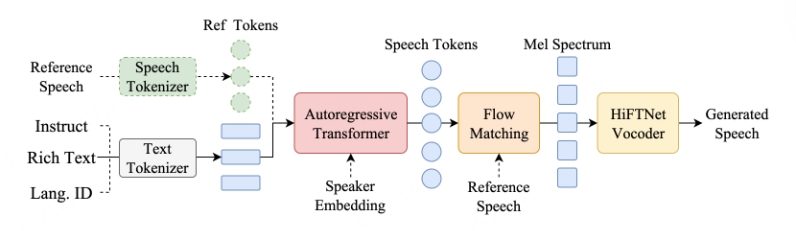
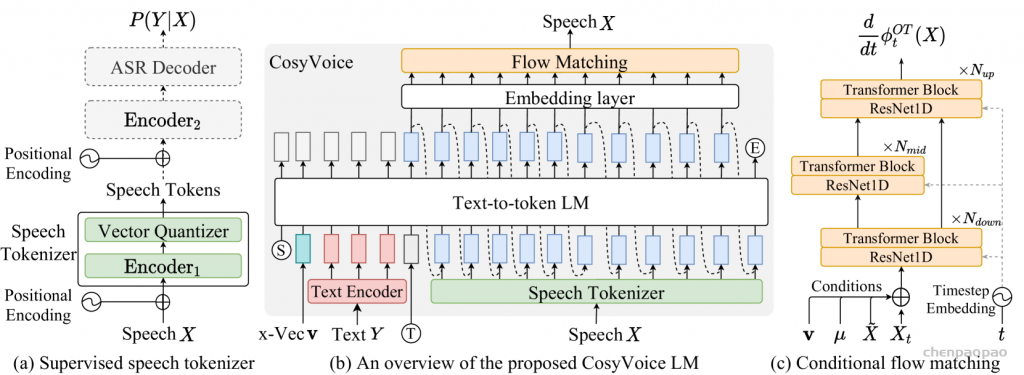
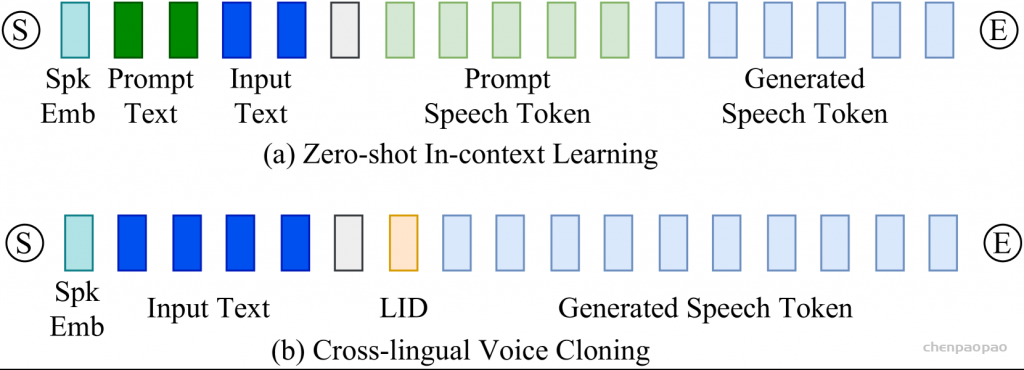
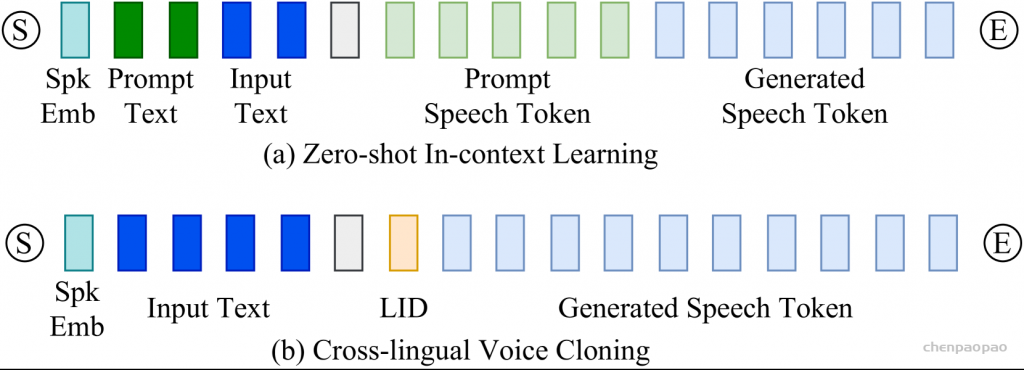
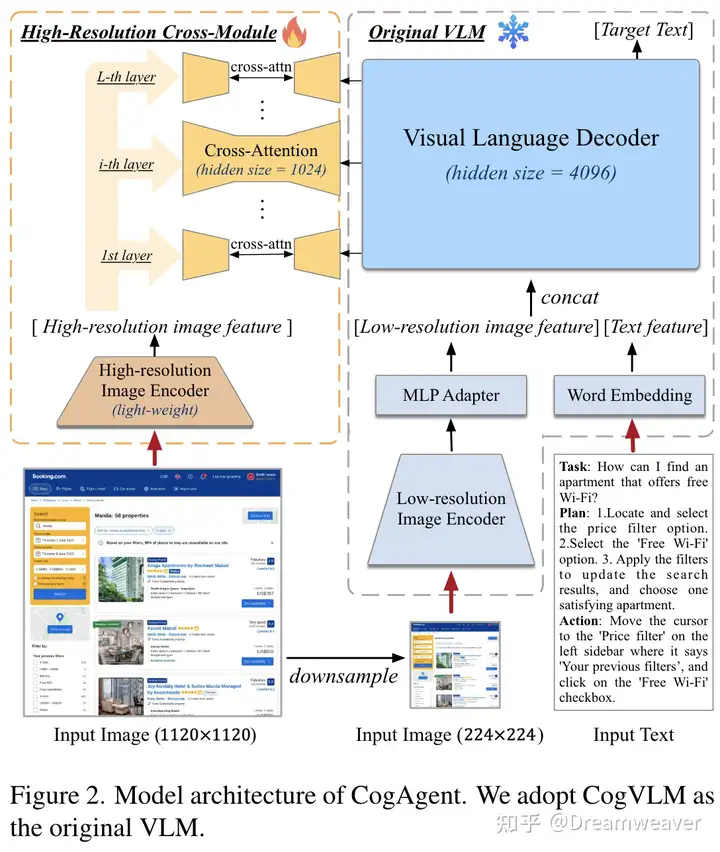
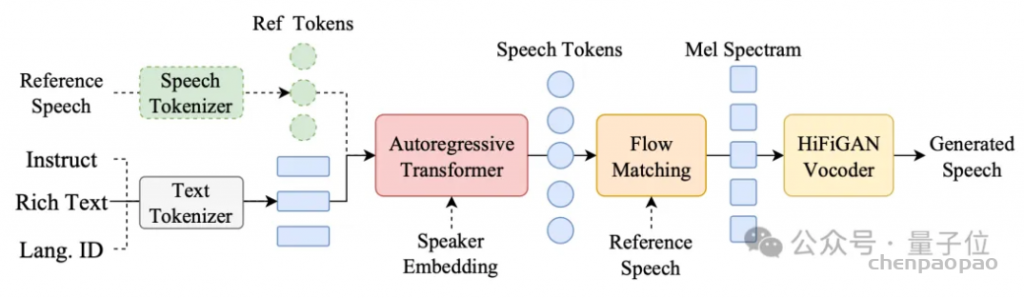
图1:所提出的CosyVoice模型的概述。(a)演示了 𝒮3 标记器,其中虚线模块仅在训练阶段使用。(b)是CosyVoice的示意图,由文本到令牌LLM和令牌到语音流匹配模型组成。 S、E和T表示“start of sequence”、“end of sequence”和“turn of speech”标记。虚线表示推理阶段的自回归解码。(c)提供了我们的流匹配模型的放大视图,该模型以概率密度路径上的时间步长 t处的说话者嵌入 𝐯、语义标记 μ、掩蔽语音特征 X~和中间状态 Xt为条件。图2:(a)零触发上下文学习和(B)跨语言语音克隆的序列构建。LID表示目标语言标识符。
S and E denote the start and end of sequence, respectively.T is “turn of speech” tokens. 𝐯 is a speaker embedding vector extracted from the speech X with a pre-trained voice-print model2. The text encodings Y¯={𝐲¯u}u∈[1:U] is obtained by passing the text through a Byte Pair Encoded (BPE) tokenizer and text encoder:
System:
You are a translator proficient in English and {language}. Your task is to translate the following English text into {language}, focusing on a natural and fluent result that avoids “translationese.” Please consider these points:
1. Keep proper nouns, brands, and geographical names in English.
2. Retain technical terms or jargon in English, but feel free to explain in {language} if necessary.
3. Use {language} idiomatic expressions for English idioms or proverbs to ensure cultural relevance.
4. Ensure quotes or direct speech sound natural in {language}, maintaining the original’s tone.
5. For acronyms, provide the full form in {language} with the English acronym in parentheses.
User:
Text for translation: {text}
Assistant:
{translation results}
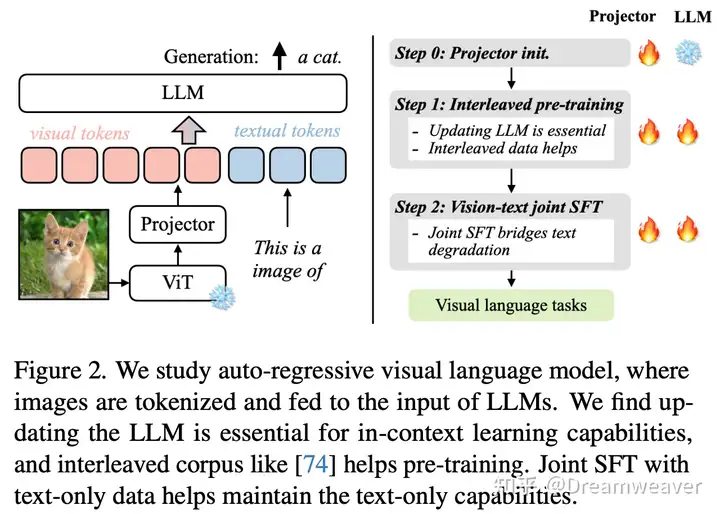
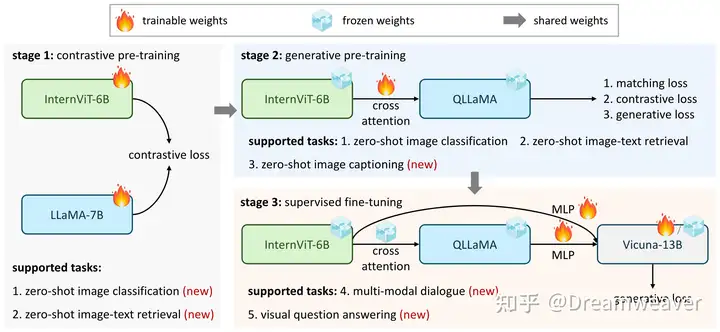
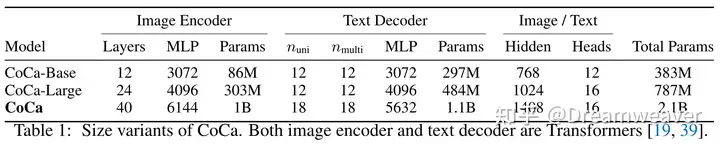
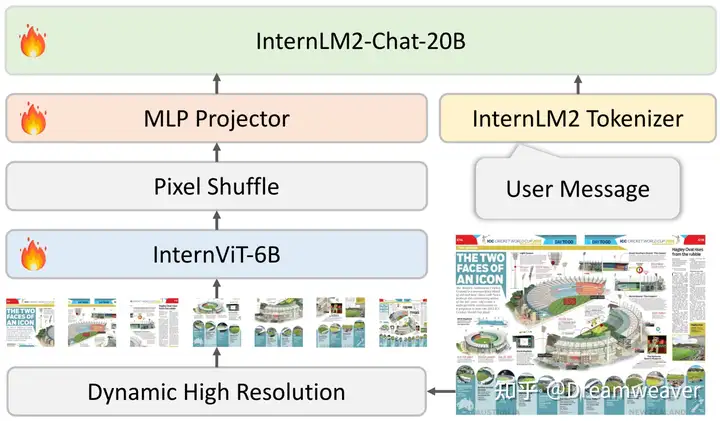
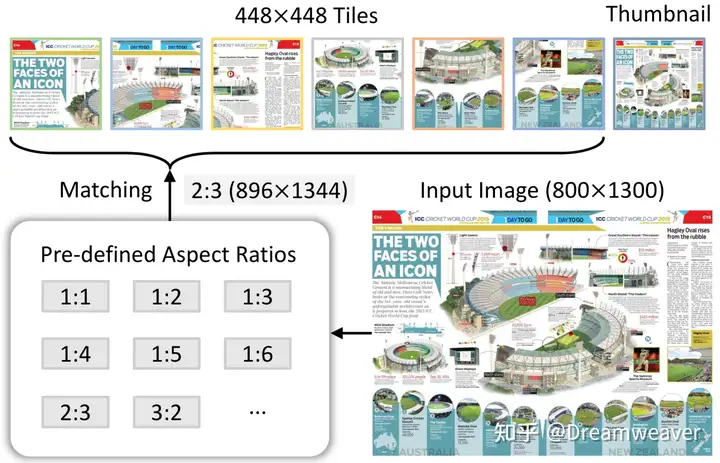
24年6月,LeCun&谢赛宁团队发布Cambrian-1,关注以视觉为中心的多模态LLM,开源了8B/13B/34B的模型。当前多模态LLM仍存在较大的视觉缺陷,需要增强视觉表征以更好地和语言模态交互,赋予模型在真实场景更强的感知定位能力。这项研究的一大意义在于影响多模态LLM的工作开始重视视觉表征质量的提升,而非一直scale up LLM。
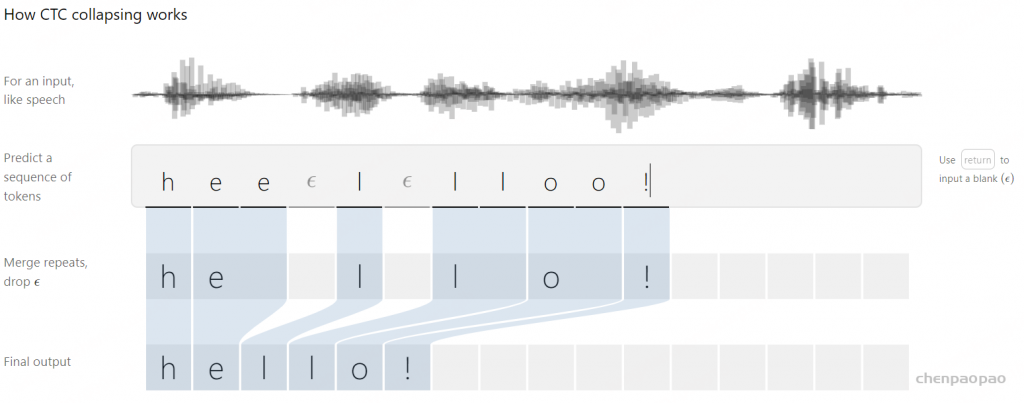
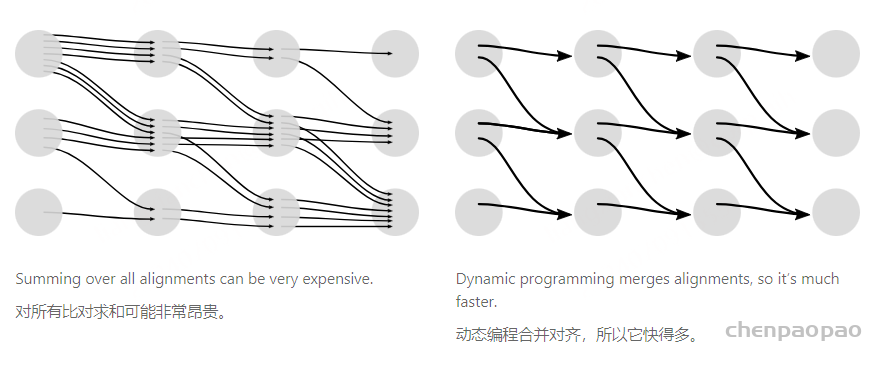
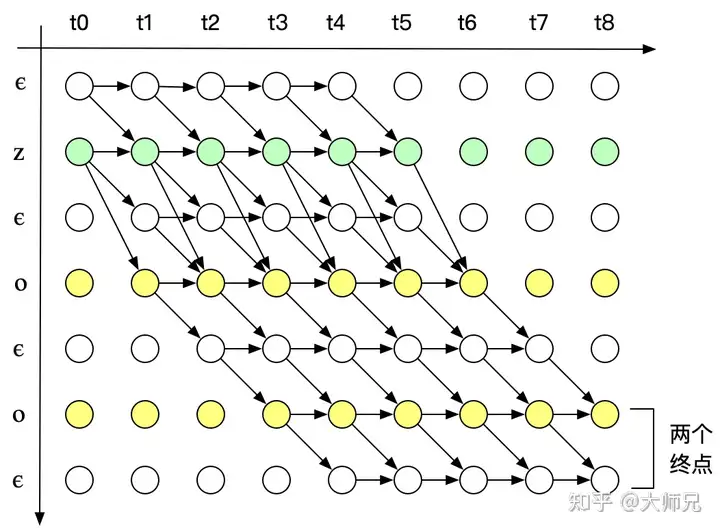
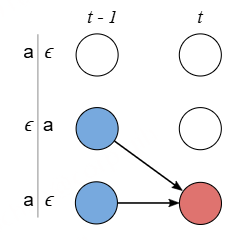
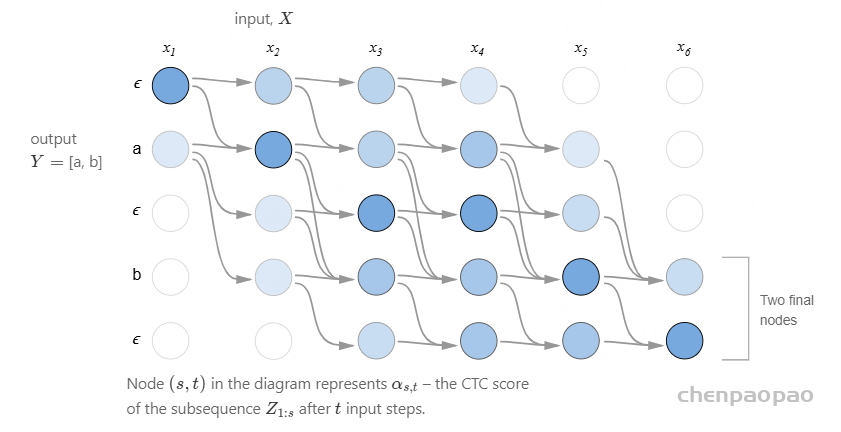
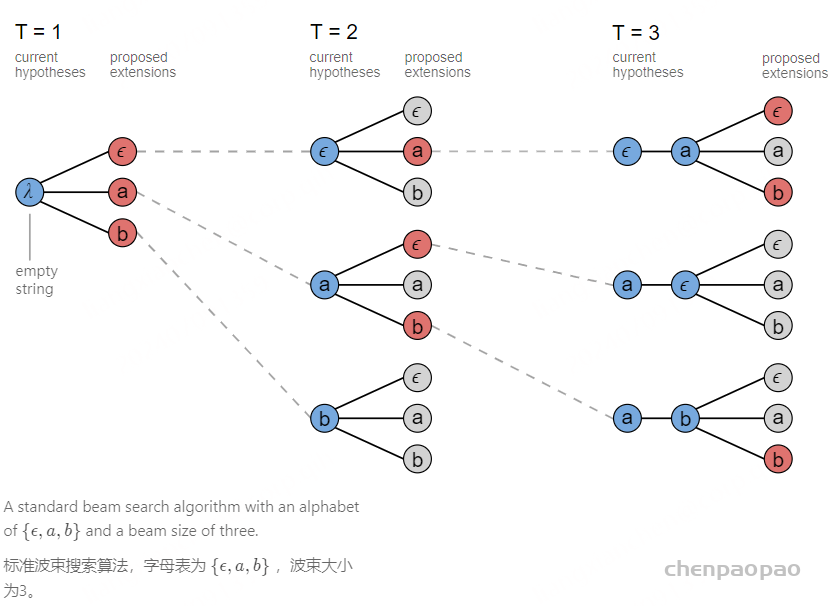
在语音识别中,我们的数据集是音频文件和其对应的文本,不幸的是,音频文件和文本很难在单词的单位上对齐。除了语言识别,在OCR,机器翻译中,都存在类似的Sequence to Sequence结构,同样也需要在预处理操作时进行对齐,但是这种对齐有时候是非常困难的。如果不使用对齐而直接训练模型时,由于人的语速的不同,或者字符间距离的不同,导致模型很难收敛。
当我们主要关注文本和语音模态时,GPT-4o其实就是一个语音语言模型(speech language model, SLM)。该SLM同时具备语音理解能力和语音合成能力,输入端和输出端均支持文本和语音的混合多模态。那么,这一SLM应该如何实现呢?在大语言模型(large language model, LLM)滥觞的今日,不难想到这样一种方法:将连续的语音数据离散化成如同单词(或者称token,词元)一样的表示,并入到LLM的词表中,再走一遍训练LLM的老路。
audio & text tokenizer的实现应该是语音离散化部分所用的技术,例如SoundStream、Encodec、SpeechTokenizer,或者是MEL+VQ最后配合声码器来解码;参考zero-shot TTS、AudioLM/AudioPaLM、SpeechGPT-Gen等工作的结果,LLM中语音token的解码应该是要走层次化或者多步的方法,先解码语义特征,再解码声学特征,或者是先解码MEL,再加一个HIFIGAN这样的声码器。另外,如果做audio/speech/music这样的通用声合成的话,可能也能通过prompt来控制。AudioLDM2虽然做了这方面的工作,但audio/music和speech的参数其实是不一样的,说到底还不是同一个模型。
[1] Baevski A, Zhou Y, Mohamed A, et al. wav2vec 2.0: A framework for self-supervised learning of speech representations[J]. Advances in neural information processing systems, 2020, 33: 12449-12460.
[2] Hsu W N, Bolte B, Tsai Y H H, et al. Hubert: Self-supervised speech representation learning by masked prediction of hidden units[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3451-3460.
[3] Chung Y A, Zhang Y, Han W, et al. W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training[C]//2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021: 244-250.
[4] Van Den Oord A, Vinyals O. Neural discrete representation learning[J]. Advances in neural information processing systems, 2017, 30.
[5] Zeghidour N, Luebs A, Omran A, et al. Soundstream: An end-to-end neural audio codec[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 30: 495-507.
[6] Défossez A, Copet J, Synnaeve G, et al. High fidelity neural audio compression[J]. arXiv preprint arXiv:2210.13438, 2022.
[7] Zhang X, Zhang D, Li S, et al. Speechtokenizer: Unified speech tokenizer for speech large language models[J]. arXiv preprint arXiv:2308.16692, 2023.
[8] Borsos Z, Marinier R, Vincent D, et al. Audiolm: a language modeling approach to audio generation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023.
[9] Rubenstein P K, Asawaroengchai C, Nguyen D D, et al. Audiopalm: A large language model that can speak and listen[J]. arXiv preprint arXiv:2306.12925, 2023.
[10] Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Chao Zhang. SALMONN: Towards Generic Hearing Abilities for Large Language Models
[11] Zhang D, Li S, Zhang X, et al. Speechgpt: Empowering large language models with intrinsic cross-modal conversational abilities[J]. arXiv preprint arXiv:2305.11000, 2023.
[16] Wang C, Chen S, Wu Y, et al. Neural codec language models are zero-shot text to speech synthesizers[J]. arXiv preprint arXiv:2301.02111, 2023.
[17] Anil R, Dai A M, Firat O, et al. Palm 2 technical report[J]. arXiv preprint arXiv:2305.10403, 2023.
[18] Lee Y, Yeon I, Nam J, et al. VoiceLDM: Text-to-Speech with Environmental Context[C]//ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024: 12566-12571.
[19] Lyth D, King S. Natural language guidance of high-fidelity text-to-speech with synthetic annotations[J]. arXiv preprint arXiv:2402.01912, 2024.
[20] Betker J. Better speech synthesis through scaling[J]. arXiv preprint arXiv:2305.07243, 2023.
[21] Xin D, Tan X, Shen K, et al. RALL-E: Robust Codec Language Modeling with Chain-of-Thought Prompting for Text-to-Speech Synthesis[J]. arXiv preprint arXiv:2404.03204, 2024.
[22] Wang C, Zeng C, Zhang B, et al. HAM-TTS: Hierarchical Acoustic Modeling for Token-Based Zero-Shot Text-to-Speech with Model and Data Scaling[J]. arXiv preprint arXiv:2403.05989, 2024.
[23] Ren Y, Hu C, Tan X, et al. Fastspeech 2: Fast and high-quality end-to-end text to speech[J]. arXiv preprint arXiv:2006.04558, 2020.
[24] Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 10684-10695.
[25] Shen K, Ju Z, Tan X, et al. Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers[J]. arXiv preprint arXiv:2304.09116, 2023.
[26] Ju Z, Wang Y, Shen K, et al. NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models[J]. arXiv preprint arXiv:2403.03100, 2024.
[27] Liu H, Tian Q, Yuan Y, et al. AudioLDM 2: Learning holistic audio generation with self-supervised pretraining[J]. arXiv preprint arXiv:2308.05734, 2023.
[28] Jiang Z, Ren Y, Ye Z, et al. Mega-tts: Zero-shot text-to-speech at scale with intrinsic inductive bias[J]. arXiv preprint arXiv:2306.03509, 2023.
[29] Jiang Z, Liu J, Ren Y, et al. Mega-tts 2: Zero-shot text-to-speech with arbitrary length speech prompts[J]. arXiv preprint arXiv:2307.07218, 2023.
[30] Łajszczak M, Cámbara G, Li Y, et al. BASE TTS: Lessons from building a billion-parameter text-to-speech model on 100K hours of data[J]. arXiv preprint arXiv:2402.08093, 2024.
[31] Li Y A, Han C, Mesgarani N. Styletts: A style-based generative model for natural and diverse text-to-speech synthesis[J]. arXiv preprint arXiv:2205.15439, 2022.
[32] Li Y A, Han C, Raghavan V, et al. Styletts 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models[J]. Advances in Neural Information Processing Systems, 2024, 36.
[33] Guo Z, Leng Y, Wu Y, et al. Prompttts: Controllable text-to-speech with text descriptions[C]//ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023: 1-5.
[34] Yang D, Liu S, Huang R, et al. Instructtts: Modelling expressive TTS in discrete latent space with natural language style prompt[J]. arXiv preprint arXiv:2301.13662, 2023.
[35] Vyas A, Shi B, Le M, et al. Audiobox: Unified audio generation with natural language prompts[J]. arXiv preprint arXiv:2312.15821, 2023.
[36] Lee S H, Choi H Y, Kim S B, et al. HierSpeech++: Bridging the Gap between Semantic and Acoustic Representation of Speech by Hierarchical Variational Inference for Zero-shot Speech Synthesis[J]. arXiv preprint arXiv:2311.12454, 2023.
[37] Yang D, Tian J, Tan X, et al. Uniaudio: An audio foundation model toward universal audio generation[J]. arXiv preprint arXiv:2310.00704, 2023.
[38] Huang R, Zhang C, Wang Y, et al. Make-a-voice: Unified voice synthesis with discrete representation[J]. arXiv preprint arXiv:2305.19269, 2023.
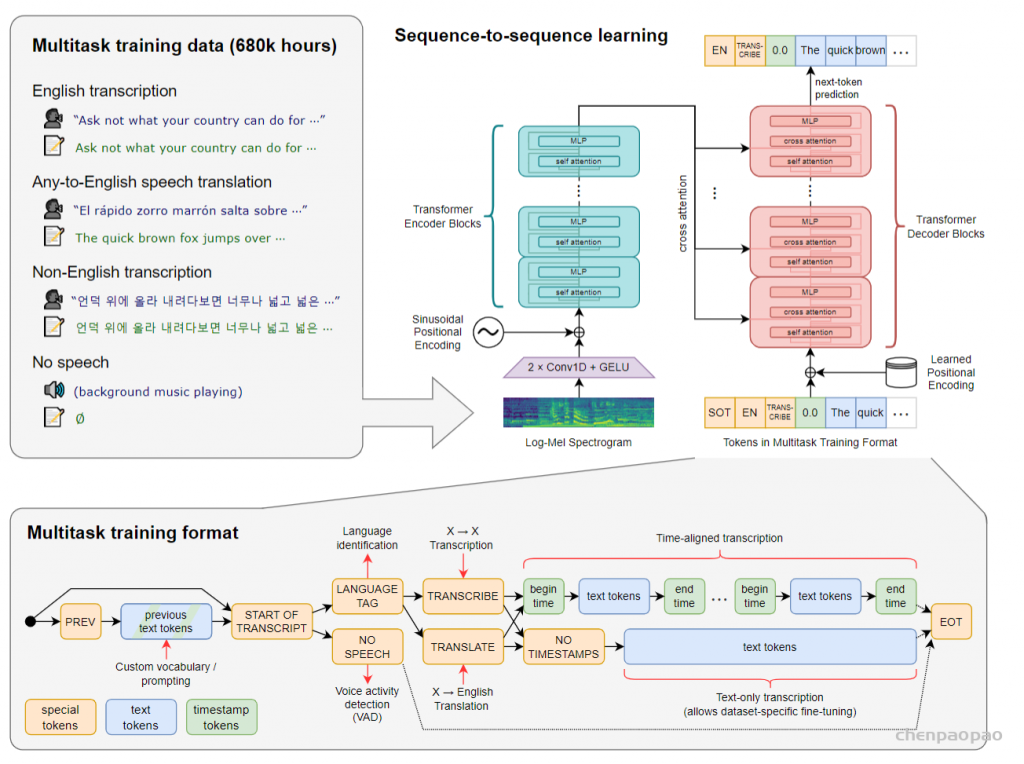
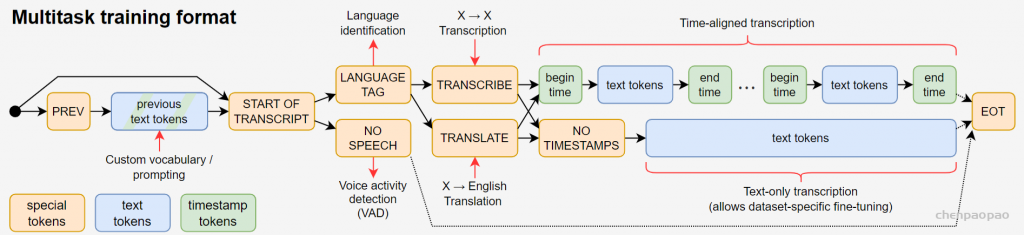
Overview of our approach. A sequence-to-sequence Transformer model is trained on many different speech processing tasks, including multilingual speech recognition, speech translation, spoken language identification, and voice activity detection
目前主流的语音识别方法是先进行大规模的无监督预训练(Wav2Vec 2.0),比如, Wav2Vec 采集了1000000h的无标签训练数据,先用这些数据进行预训练一个编码器(使用对比学习 or 字训练),encoder能够对语音数据做一个很好的编码,然后在面向下游任务时,可以在标准训练集中做微调(只需要几十小时的数据就可),这样比只在标准数据集上训练的结果好很多。
这些预训练好的语音编码器能够学习到语音的一个高质量表示,但是用无监督方法训练的编码器仍然需要训练一个解码器,需要用带标签的数据来微调,微调是一个很复杂的过程,如果不需要微调就好了,这也是本文要做的工作。此外,过去的工作缺乏一个很好的解码器,这是一个巨大的缺陷,而语音识别系统就是应该是“out of box”,也就是拿来即用。
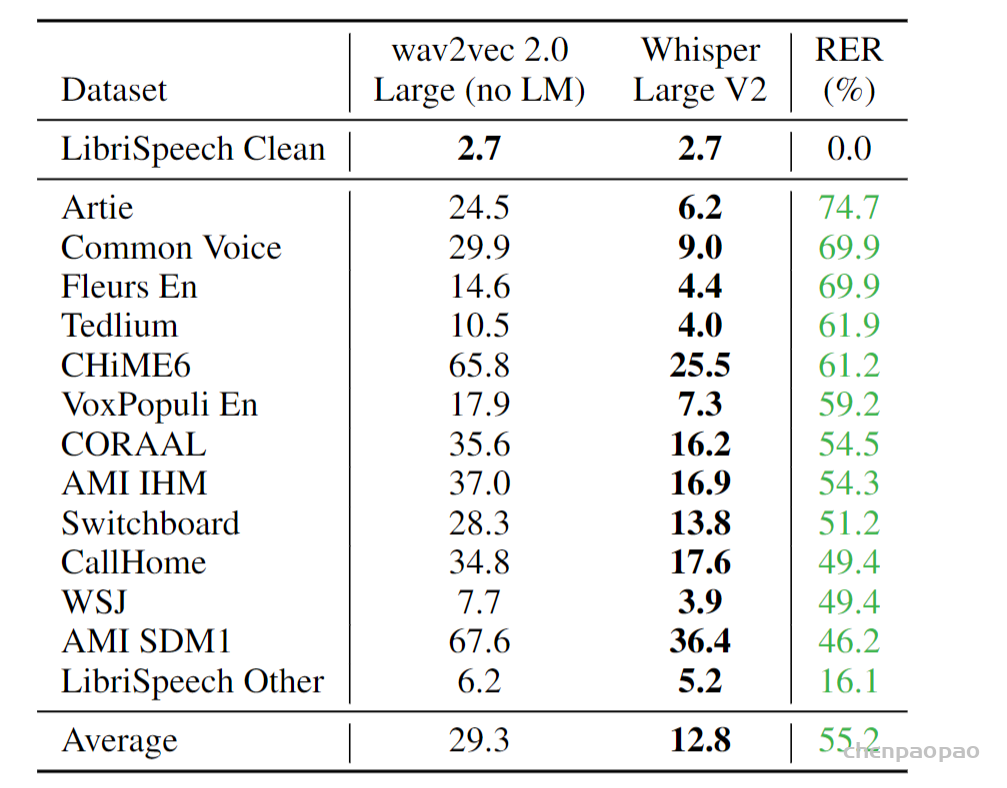
数据部分是本文最核心的贡献。由于数据够多,模型够强,本文模型直接预测原始文本,而不经过任何标准化(standardization)。从而模型的输出就是最终识别结果,而无需经过反向的文本归一化(inverse text normalization)后处理。所谓文本归一化包括如将所有单词变小写,所有简写展开,所有标点去掉等操作,而反向文本归一化就是上述操作的反过程。在 Whisper 中,这些操作统统不用,因为数据足够多,可以覆盖所有的情况。