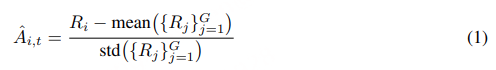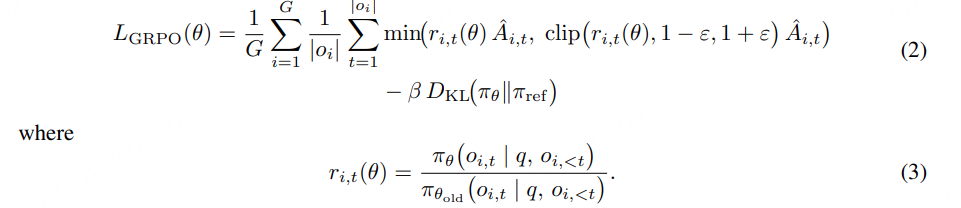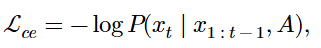个人一些看法:1、关于语种混淆问题 ,目前的语音识别大模型确实存在较为严重的语种混淆,一般可以通过指定语种缓解该问题。 FunAudioLLM 提出的将CTC 的第一遍解码结果作为 Prompt 输入给 LLM,可以有效缓解该问题,这个后面可以尝试下,但个人感觉CTC能力可能不会很强,技术报告中说的CTC本身发生串语种的概率极低,这个个人表示存疑。另外关于语种混淆,感觉跟LLM本身翻译能力可能无关,应该是部分语种某些发音以及说话人发音不规范导致语种识别错误。2、对于“幻觉”问题 ,可以通过加入纯噪声/纯背景声进行训练。3、热词 这块结合RAG,确实是个好的办法,毕竟直接注入上千的热词势必会对模型的识别产生不可控的影响,通过检索增强生成,只将少量相关性高的热词进行注入,可以避免无关信息干扰,但关键是如何利用ctc的粗解码结果检索出相关的热词,做到不漏检。4、ASR性能提升的核心还是数据 ,论文中无论是优化抗噪能力/幻觉问题/热词能力/混合中英语言 等,基本上都依靠设计生成对应的高质量的数据!!!5、 关于语音编码器的训练范式和数据量:自监督+监督学习,上千万小时的训练数据。
阿里巴巴通义实验室推出了FunAudio-ASR端到端语音识别大模型 。这款模型通过创新的Context模块,针对性优化了“幻觉”、“串语种”等关键问题,在高噪声的场景下,幻觉率从78.5%下降至10.7%,下降幅度接近70%。 FunAudio-ASR使用了数千万小时的音频数据 ,融合了大语言模型的语义理解能力,从而提升语音识别的上下文一致性与跨语言切换能力。
Abstract FunAudio-ASR,一个结合大规模数据、超大模型、LLM整合和强化学习的先进ASR系统。该系统不仅在复杂语音场景中实现了最先进的识别性能,还通过针对实际部署的优化增强了流式处理、噪声鲁棒性、混合语言 【中英】、和热词自定义能力,验证了其在真实应用环境中的高效性和可靠性。
Introduction
数据规模扩展 、模型规模扩展 以及与大型语言模型(LLM) 共同推动ASR系统的能力提升:
数据规模扩展 被证明是ASR提升的基础驱动力;模型规模扩展 ,尤其是模型参数数量的增加,进一步放大了数据规模扩展的优势;与LLM的深度整合 代表了ASR方法论的一次范式转变,不再将ASR视为独立任务,而是利用LLM丰富的语言知识和上下文理解能力来增强语音识别,例如,Seed-ASR和FireRedASR展示了引入LLM可以显著提升ASR性能,尤其在解决语义歧义和生成更连贯、上下文更合理的转录结果方面表现突出 。这些模型有效地弥合了语音理解与文本理解之间的鸿沟。FunAudio-ASR ,这是一个基于 LLM 的大规模 ASR 系统,可在大规模数据上进行训练。FunAudio-ASR 具有以下关键特性:
规模化与创新性LLM整合。 最先进的语音识别准确率。通过在数据规模、模型规模以及与LLM的创新架构整合方面的协同进展,FunAudio-ASR在多语言和多声学领域实现了前所未有的识别准确率,确立了ASR系统的新一代最先进水平。 面向实际生产的优化 。经过精心设计,以满足真实部署场景的复杂需求:高效流式ASR架构 :FunAudio-ASR采用高度高效的流式识别架构,支持低延迟实时处理,可无缝集成到视频会议、实时字幕和语音控制设备等应用中。噪声鲁棒性增强 :通过多阶段方法,显著提升系统在嘈杂环境下的识别能力。先进的混合语言处理能力 :能够在同一句话中无缝处理中英文切换 ,这对于全球商业环境中的多语言用户至关重要。 可定制的热词识别 :允许用户定义特定领域的术语或短语,以提高识别准确率 。该功能在医疗、企业及汽车技术等专业领域尤为有价值。Model Architecture
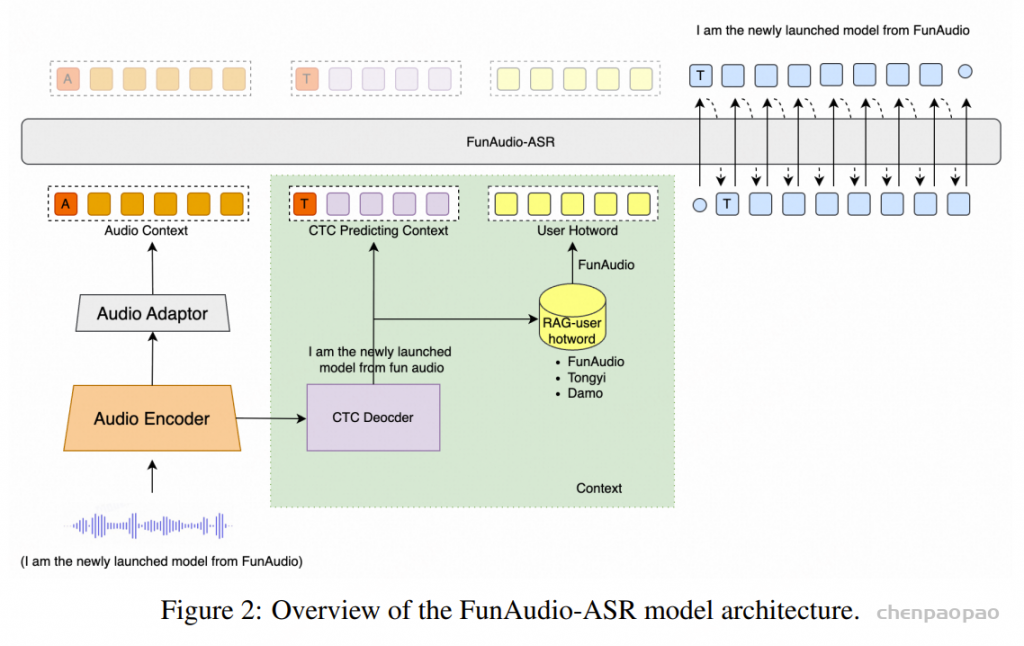
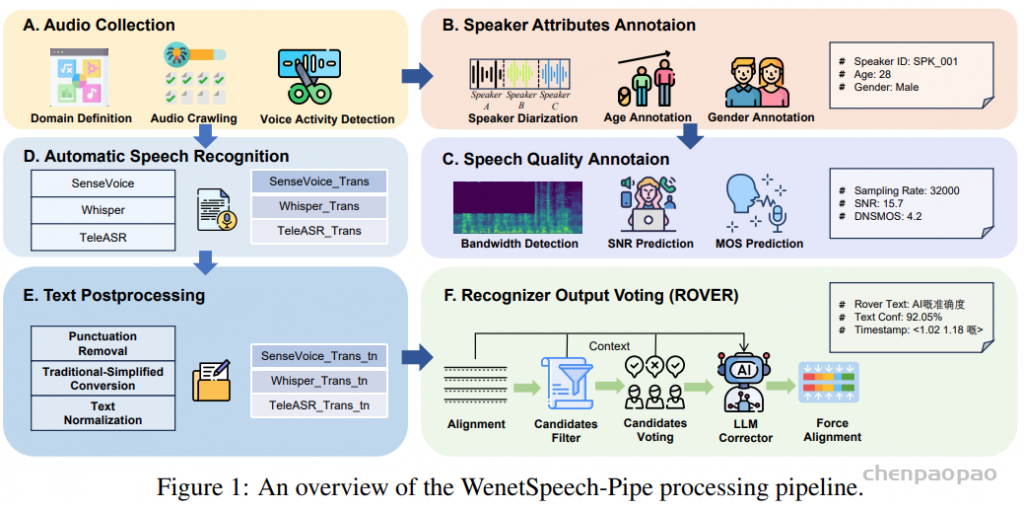
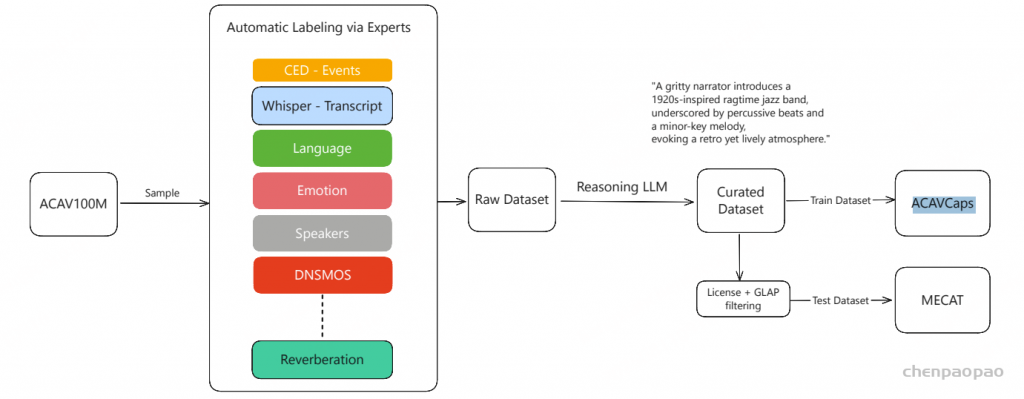
FunAudio-ASR 由四个关键组件组成:
音频编码器(Audio Encoder) :用于从输入语音中提取特征表示,采用多层Transformer编码器实现。音频适配器(Audio Adaptor) :用于将音频编码器的输出与LLM连接,采用两层Transformer编码器实现。CTC解码器(CTC Decoder) :基于音频编码器构建,用于生成初步识别参考,该参考将用于热词自定义。基于LLM的解码器(LLM-based Decoder) :在音频条件和CTC预测的基础上生成最终输出。提出了两种不同规模的模型:FunAudio-ASR [0.7B参数的编码器 和 7B参数的LLM解码器 ]和 FunAudio-ASR-nano[0.2B参数的编码器 和 0.6B参数的LLM解码器 ] ,用以满足不同的计算资源约束和推理效率需求
Data【核心】
Pre-taining Data
预训练数据集 包括约数千万小时的音频数据,涵盖无标注音频和带标注的音频-文本数据。无标注音频覆盖了人工智能、生物技术、电子商务、教育、娱乐、金融、交通等领域的广泛真实场景。对于带标注的数据,采用了完整的数据处理流程,包括:
语音活动检测(VAD) ,识别语音片段;多系统伪标签生成 ,利用多种ASR系统(如 Paraformer-V2、Whisper 和 SenseVoice生成伪标签;逆文本正则化(ITN) ,将文本恢复为标准化格式。 带标注数据的主要语言为中文和英文。
Supervised Fine-tuning Data
有监督微调(SFT)数据 规模约为数百万小时,具体包括以下几类:
人工转写数据 :由人工标注的高质量语音转写。伪标签数据 :由ASR系统自动生成的标注数据。环境噪声数据 :覆盖各种真实噪声场景。CosyVoice3生成的TTS数据 :由TTS合成的补充语音数据。流式模拟数据 :用于优化实时流式识别能力。噪声增强数据 :通过数据增强方法引入不同类型的噪声。热词定制数据 :支持特定领域和应用场景的热词识别。Training
Pre-training of Audio Encoder
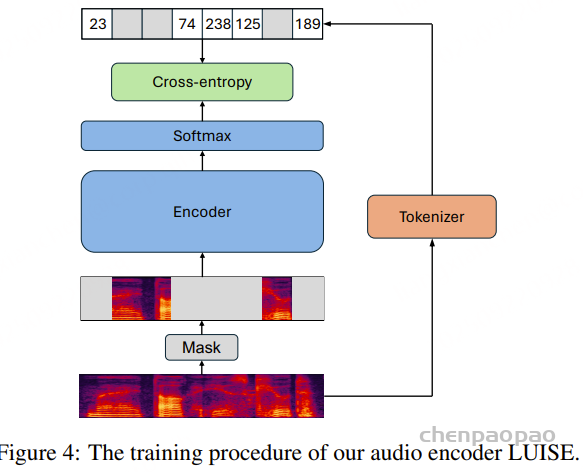
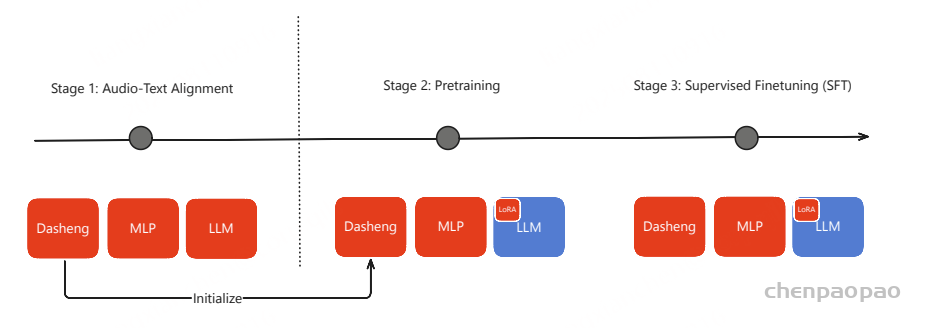
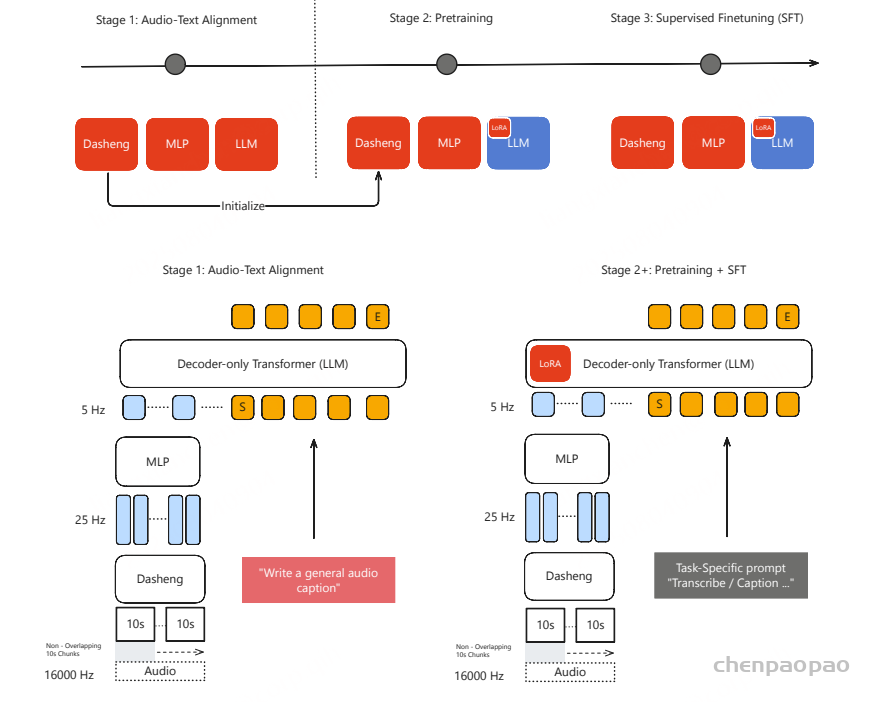
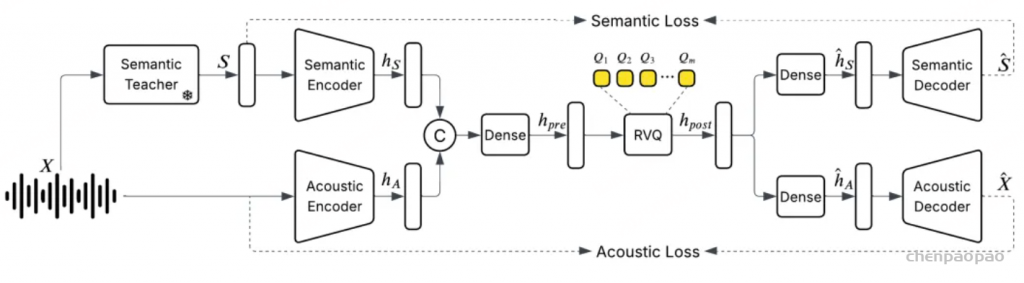
为了开发一个强大而有效的音频编码器,以便集成到基于 LLM 的 ASR (LLM-ASR) 系统中, 采用了自监督+监督学习结合的方法 ,如上图所示,通过利用自监督学习和监督学习范式来生成高质量的语音表示,并使其能够与 LLM 中的语言知识有效匹配。
Stage 1: 基于Best-RQ
Best-RQ是一种先进的语音表示学习方法,它通过对语音单元进行掩码和重建,并利用量化模块将连续表示离散化,从而在不依赖标注数据的情况下学习通用语音表示,使其能够大规模扩展到海量无标注音频数据。
创新点 在于 初始化策略 :发现预训练文本LLM的层可有效用于ASR系统编码器的初始化。使用 Qwen3模型 的部分层参数来初始化Best-RQ编码器。该跨模态初始化策略的假设是:LLM中蕴含的深层语言与语义知识能够为语音表示学习提供有益的归纳偏置 。实验表明,与随机初始化相比,采用预训练文本LLM进行初始化可以显著加快训练收敛速度,并提升所学习语音表示的质量。
补充关于语音encoder的训练:
SeedASR也使用自监督学习进行预训练,特点是contrastive-loss[对比损失]和 codebook-diversity-loss去训练模型的speech representation和codebook。
Seed-ASR endoer training Best-RQ 离散的随机量化器来近似的表示连续的语音信号 。这个随机的量化器训练阶段是固定不变的 ,这样就不用再像wav2vec 2.0中使用contrastive-loss[对比损失]和 codebook-diversity-loss去训练模型的speech representation和codebook。
主要特点在于:不在使用contrastive loss去学习音频表征(无contrastive-loss),极大简化了SSL训练的过程,并且因为量化器是随机初始化并固定的,因此codebook和训练的encoder模型解耦了。
BEST-RQ 训练范式 Stage 2: 基于encoder-decoder (AED) 进行 Supervised pre-training
参考SenseVoice-Large的训练方法,编码器在大规模标注的 ASR 数据集上进行端到端训练,使用标准的序列到序列学习目标。目标是获得一个从转录语音数据中学习到丰富的声学和语言特征的编码器,训练好的该编码器将用于初始化下游 LLM-ASR 系统中的音频编码器。
通过上述预训练阶段,减少了从头开始进行大量低级特征学习的需要,从而加速了训练收敛。
Supervised Fine-tuning
监督微调(SFT)包括四个连续的阶段:
阶段 1 :保持预训练的音频编码器和 LLM 参数冻结,仅训练适配器模块 ,使音频编码器的输出表征能够与 LLM 的语义空间对齐。本阶段的训练数据约为 20 万小时 。
阶段 2 :依然冻结 LLM 参数,同时训练音频编码器和适配器模块,以学习更好的语义表征 。本阶段使用约 1000 万小时的低成本 ASR 训练数据 ,并训练 1 个 epoch 。
阶段 3 :冻结音频编码器和适配器模块 ,仅使用 LoRA(低秩适配) 来更新 LLM 参数 。LoRA 微调的目的是在保持模型文本生成能力的同时,缓解对预训练知识的灾难性遗忘 。本阶段使用 2 万小时的 ASR 数据 。
阶段 4 :对音频编码器和适配器进行全参数微调,同时对 LLM 采用 LoRA 进行微调 。在此阶段,仅使用 高质量数据 (约 300 万小时语音 )。这些转录数据由 Whisper-Large-V3、FireRed-ASR 和 SenseVoice 三个不同的 ASR 模型进行评估 。
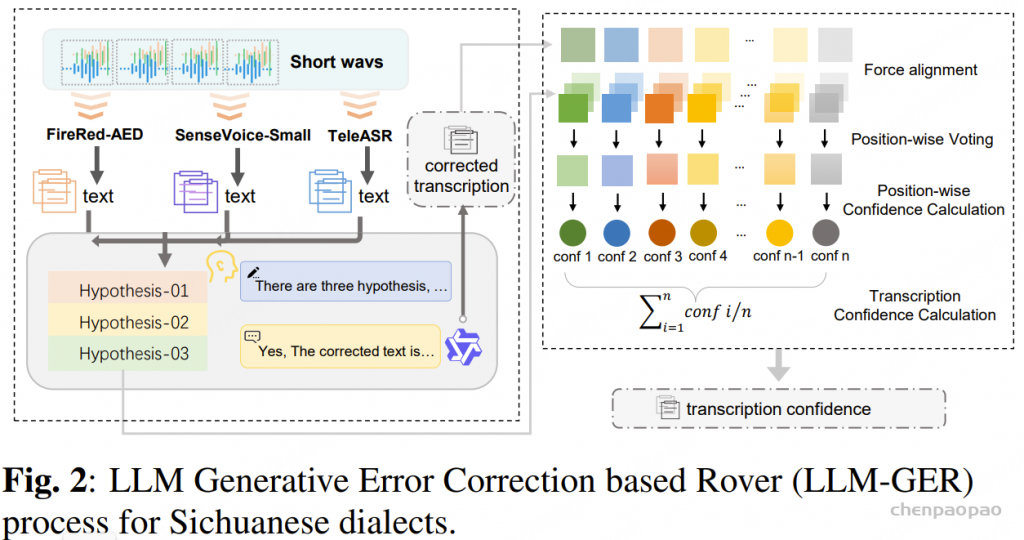
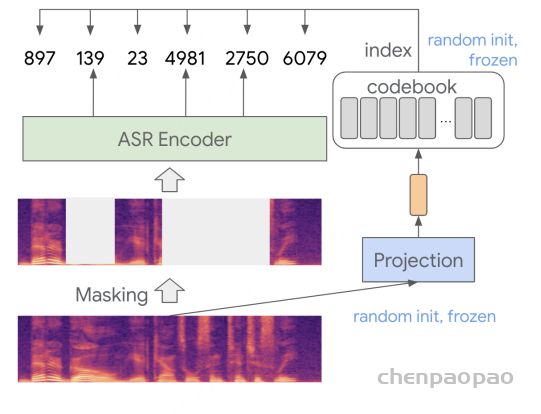
阶段 5 :如图 2 所示,我们在音频编码器之上添加了一个 CTC 解码器 。在该训练阶段,音频编码器保持冻结,仅训练 CTC 解码器 。该 CTC 解码器通过 贪心搜索 (greedy search)生成初始识别假设 。随后,这个一次性解码结果被用于 检索增强生成(RAG) ,以获取上下文信息。
此外,通义实验室发现,给语音大模提供必要的上下文 ,可以减少 文本生产时候的幻觉 现象。为此,设计了 Context 增强模块 :该模块通过 CTC 解码器快速生成第一遍解码文本,并将该结果作为上下文信息输入 LLM,辅助其理解音频内容 。由于 CTC 结构轻量且为非自回归模型,几乎不增加额外推理耗时。此外,观察到幻觉问题在高噪声场景中更易发生,因此在训练数据中加入了大量仿真数据。我们构建了一个包含 28 条易触发幻觉音频的测试集,经优化后,幻觉率从78.5% 下降至 10.7% 。
上下文监督微调
作为 内容先验 (content prior),上下文信息可以有效帮助模型在 ASR 任务中 :
识别关键文本内容 ,从易混淆的发音中消除歧义 ;提高长时连续语音识别的准确性 ,尤其在复杂场景下表现显著 。因此,在完成 SFT 训练后,我们进一步在 具有上下文信息和长时语音 的数据上训练 FunAudio-ASR,以增强其 上下文建模能力 。
音频样本的时长可达 5 分钟 。 对于较长的样本,我们将其进行切分,并将前一段的转录文本添加到当前音频段的前面,作为提示(prompt)。 由于高质量上下文音频数据严重匮乏,通过以下步骤构建了 超过 5 万小时的带上下文内容的 SFT 数据 :
步骤 1:关键词提取 。为了生成与当前对话内容相关的上下文信息,我们首先使用 Qwen3-32B 从转录文本中提取关键词。关键词通常包括实体、专业术语以及特定时间段等,这些是 ASR 系统容易识别错误或遗漏的词汇。
步骤 2:相关上下文生成 。利用 Qwen3-32B 模型生成上下文内容:
给定当前对话内容和提取出的关键词,提示 Qwen3-32B 合成多个、多样化的上下文内容,这些内容应与口语对话特征相符。 对合成的上下文内容,通过 关键词匹配 筛选,剔除未包含指定关键词的片段 。 如果在第一步中未提取到任何关键词,则仅根据当前对话内容提示 LLM 合成上下文 。步骤 3:无关上下文混合 。为了防止模型对上下文过度依赖,从数据集中为每条对话随机抽取 五条无关上下文片段 ,并与生成的相关上下文混合,形成最终的上下文 SFT 训练数据。
Reinforcement Learning
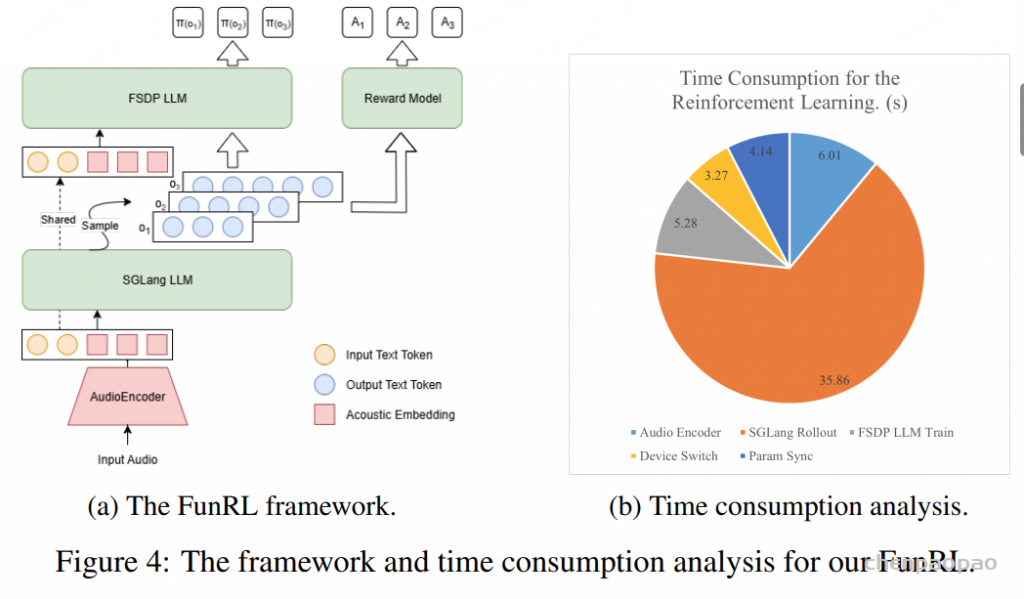
设计了 FunRL ,一个专为 大规模音频-语言模型(LALMs) 定制的高效强化学习(RL)框架。与文本 LLM 不同,作为 LALM 的 FunAudio-ASR 包含一个音频编码器,用于将语音转换为嵌入向量,而现有的 RL 框架或 Trl原生并不支持这一组件。
如图 4(a) 所示,FunRL 使用 Ray 协调音频编码器、rollout 和策略模块,使它们能够交替使用 GPU 资源:
音频编码器推理阶段 将所有输入音频批量处理,通过基于 Torch 的编码器提取音频嵌入。 提取的嵌入从 GPU 转移到 CPU。 SGLang LLM Rollout GPU 控制权转交给 SGLang Rollout 模块,根据音频嵌入和指令文本 token 生成多个假设序列。 每个假设根据预定义规则分配奖励(奖励规则将在后文详细说明)。 FSDP LLM 策略优化 利用音频嵌入和生成的假设序列计算输出概率,并通过 RL 进行策略优化。 每次更新后,将优化后的策略同步回 Rollout 模块,保证 RL 过程保持 on-policy 。 我们在 8 块 A100 GPU 上评估了 FunRL 的训练效率(如图 4(b)):
对大约 1 小时输入音频 ,每个训练步骤约需 54.6 秒 ,对应实时因子(RTF)约为 0.015 。 如图 4(b) 所示,SGLang Rollout 阶段占据了大部分计算时间,而设备切换开销仅占总时间的不到 6%。 这表明 FunRL 的交替 GPU 利用策略 非常高效,使其成为 大规模音频-语言模型 RL 训练的可扩展且有效的解决方案 。
GRPO-based RL for ASR
基于 FunRL 框架,对 FunAudio-ASR 的 GRPO(Generalized Reinforced Policy Optimization) 强化学习算法进行了增强。
策略优化采用 裁剪目标(clipped objective) 并直接施加 KL 惩罚项(KL penalty term) 。
我们观察到,当 WER(词错误率) 被用作值函数时,GRPO 与 最小词错误率(MWER, Minimum Word Error Rate) 方法非常相似 ,MWER 是 ASR 社区广泛采用的优化标准。在本文中,我们进一步设计了一组新的值函数 {Rk (yi ∗ ,yi )}k=1 K ,以同时提升 ASR 性能和用户体验:
ASR 准确率(R1 i ) 为直接优化识别质量,我们以 1−WER(y∗,y) 作为基础值函数,其取值范围为 [0,1]。 关键词准确率与召回率(R2 i ) 由于关键词对用户体验影响显著,我们将 关键词召回率 作为奖励组件。每条语音的关键词可通过人工标注或 LLM 自动识别获得。 仅使用召回率可能会增加插入错误,因此我们同时加入 关键词准确率 ,以平衡精度与召回。 噪声鲁棒性与幻觉抑制(R3 i ) 在 LLM ASR 系统中,幻觉(hallucination)是常见问题,尤其在嘈杂环境下。 为缓解这一问题,通过正则表达式匹配检测幻觉内容,并按幻觉片段长度施加惩罚。 语言一致性(R4i ) 某些情况下,模型可能错误生成语音翻译而非转录。 为保证语言一致性,如果输出语言与源语言不匹配,则最终奖励设为 −1 。 除 R4 i 外,所有函数结果会求和得到最终的 Ri 。虽然 R2 i 到 R4 i 的效果在一定程度上可由 ASR 准确率反映,但实验结果表明,加入这些规则能显著改善用户体验,并在困难样本上降低 WER。
构建 RL 训练数据
针对应用场景中的实际问题,我们采用以下方法构建一个小但高质量的 RL 训练数据。
困难样本(Hardcase Samples)
收集大量未标注语音,并使用 FunAudio-ASR(上下文 SFT 后) 以及其他三个独立 ASR 系统(Whisper、FireRed-ASR、SenseVoice)进行转录。 当三个外部系统输出一致(WER < 5%),但与 FunAudio-ASR 差异显著(WER > 10%)时,将该样本识别为 困难样本 ,并纳入 RL 训练集。 长时语音样本(Long-duration Samples)
选择时长超过 20 秒 的音频片段,以提升模型对长语音输入的识别能力。 现实应用中长语音常见,但训练数据中比例不足(<10%)。 幻觉相关样本(Hallucination-related Samples)
特别包括基础模型出现幻觉的语料,例如输出明显长于真实文本或出现重复片段 。 同时加入参考转录中存在长重复词或短语的语句 ,这类样本与幻觉类似,但是真实存在,用于帮助模型区分 真实模式 与 虚假模式 。 关键词与热词样本(Keyword and Hotword Samples)
对于没有预设热词的语句,使用 Qwen-2.5 7B 识别显著关键词。 热词特定训练中,将参考转录中的热词作为目标关键词。 常规 ASR 数据(Regular ASR Data)
包含部分标准 ASR 数据,以缓解 灾难性遗忘 ,并在 RL 训练中保持通用识别性能。 面向生产的优化
Streaming Ability
为了增强大规模音频语言模型 FunAudio-ASR 的 流式识别能力 ,我们构建了 流式训练数据 ,显式模拟流式解码过程,从而减少训练与推理之间的不匹配。
具体方法如下:
从离线训练语料中抽取一个子集。 将训练语料转化为 增量分块输入(incremental, chunked inputs),每个块仅暴露过去的上下文信息。 将这种模拟流式训练数据与原离线训练数据结合进行微调,从而提升模型在流式解码场景下的性能。 Noise Robust Training
鉴于现实部署场景的多样性,FunAudio-ASR 必须在 复杂声学环境 (如餐厅、火车站、商场等)下保持可靠性能,且不出现显著性能下降。然而,要构建一个能完整覆盖真实噪声环境复杂性和多样性的语料库几乎不可能。
为应对这一挑战,我们采用了 大规模噪声数据增强策略 :
从内部语料库中选择约 11 万小时低噪语音 和 1 万小时噪声样本 。 将它们组合生成约 11 万小时离线模拟噪声语音 ,平均信噪比(SNR)为 10 dB,标准差为 5 dB。 为进一步提升数据多样性,随机选择 30% 训练语音 进行 在线数据增强 ,在训练过程中混入环境噪声。 通过这种综合性的噪声鲁棒性训练策略,在复杂噪声评估集上平均实现了约 13% 的相对性能提升 。
多语言 ASR
不同语言的训练数据可用性差异显著。资源丰富的语言,如 中文(普通话) 和 英语 ,数据充足;而 越南语 和 泰语 等语言的数据相对有限。
FunAudio-ASR 的主模型为中文-英语模型。为提升多语种 ASR 性能,我们训练了额外的 多语种 FunAudio-ASR 模型(FunAudio-ASR-ML) ,支持以下语言:
训练策略如下:
对中文和英语数据进行 下采样 ,减少过度占比。 对越南语、泰语和印尼语数据进行 上采样 ,平衡数据分布。 多语种数据集总量约 50 万小时音频 。 训练方法与中文-英语 FunAudio-ASR 模型相同。 混合语音(code-switched)
混合语(code-switched)语音的识别一直是 ASR 的挑战。为优化 中文-英语混合语 的 ASR 性能,我们通过以下步骤合成混合语训练数据:
收集关键字 收集超过 4 万条英语关键词或短语 ,覆盖技术、教育、金融、体育等常见领域。 生成混合语文本 使用 Qwen3 模型,根据从上述池中随机选择的关键词,生成中文-英语混合语文本。 合成语音 利用 文本转语音(TTS)模型 ,为 LLM 生成的混合语文本合成多种声音的语音数据,从而得到最终的 混合语训练语料 。 热词定制
在 FunAudio-ASR 中,我们实现了基于 RAG(Retrieval-Augmented Generation) 的 热词定制机制 。具体方法如下:
构建热词词表 每个预设热词通过预定义词典被转换为 音素序列 (中文)或 子词序列 (其他语言)。 热词检索 推理阶段,根据 CTC 假设输出 与热词词表条目的 音素级或子词级编辑距离 ,检索热词候选。 生成定制输出 将检索到的热词候选、音频输入和 CTC 预测结果一起作为 LLM 的输入 (如图 2 所示),生成热词定制的最终输出。 定制化识别通过提高特定词汇(如人名、术语等)的识别优先级,来提升它们的召回率,同时不影响整体准确度。
传统方法直接将用户词表输入大模型,虽然简单,但词量增多时干扰增强,效果下降。为解决这一问题,通义实验室采用RAG(检索增强生成)机制:
(1)构建知识库:将用户配置的定制词构建成专属RAG库; (2)动态检索:依据CTC第一遍解码结果,从RAG库中抽取相关词汇; (3)精准注入:仅将相关词汇注入大语言模型的提示词中,避免无关信息干扰。 该方法可在不增加计算负担的前提下,支持上千定制词,并保持高识别效果。
缓解幻觉
尽管通过训练将声学特征对齐到文本特征空间,由于声学特征 Embedding 与真实的文本 Embedding 仍然存在这一定的差距,这会导致LLM在生成文本时发生幻觉的现象。
在 ASR 中,幻觉(hallucination) 指模型生成的文本并未出现在输入音频中。这一问题在 静音段、说话者突然打断 或 噪声环境 下尤为严重,模型可能在没有语音的情况下产生虚假转录。
为缓解幻觉问题,FunAudio-ASR 采用以下策略:
数据增强阶段引入零填充(zero-padding) 在向音频信号添加噪声前,先在音频中插入零填充,从而生成 纯噪声前缀片段 。 模型学习纯噪声识别 该策略迫使模型学会识别仅含噪声的输入,并将输出与实际音频对齐,从而降低幻觉文本生成的概率。 实验表明,这种方法显著提升了 FunAudio-ASR 在多样声学条件下的 鲁棒性、准确性和稳定性 。
此外,通义实验室发现,给语音大模提供必要的上下文 ,可以减少 文本生产时候的幻觉 现象。为此,设计了 Context 增强模块 :该模块通过 CTC 解码器快速生成第一遍解码文本,并将该结果作为上下文信息输入 LLM,辅助其理解音频内容 。
由于 CTC 结构轻量且为非自回归模型,几乎不增加额外推理耗时。此外,观察到幻觉问题在高噪声场景中更易发生,因此在训练数据中加入了大量仿真数据。我们构建了一个包含 28 条易触发幻觉音频的测试集,经优化后,幻觉率从78.5% 下降至 10.7% 。
测试结果:
错误识别结果:你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你你我说不尽的春风吹又生 ours 大模型识别结果:离离原上草一岁一枯荣 FunAudio-ASR识别结果:是我说不尽的中国味。 豆包大模型识别结果:别急别慌。我说不见的。 “串语种”问题 “串语种” 是语音大模型落地中的另一类典型问题。具体表现为:输入音频内容为英文,模型输出却为中文文本。这是因为文本 LLM 本身具备翻译能力,在声学特征映射不够精确时,模型可能在推理过程中“自动启动”翻译功能,从而影响语音识别的准确性。
在 FunAudio-ASR 的 Context 增强模块 中,CTC 解码器经过高质量数据训练,本身发生串语种的概率极低。通过将 CTC 的第一遍解码结果作为 Prompt 输入给 LLM,可有效引导模型聚焦于语音识别任务,缓解“翻译”行为的发生。
Evaluation
我们在开源 ASR 基准数据集和真实工业评测集上对 FunAudio-ASR 和 FunAudio-ASR-ML 进行了评测。2025年6月30日之后 在 YouTube 与 Bilibili 新上传的视频,并进行人工转写,构建了一个独立的测试集。
在噪声鲁棒性评测方面,我们使用了真实环境下采集的音频,覆盖多种场景:食堂、餐厅、会议室、办公室、户外、公园、商店、街道、地铁、超市和步行街。这些数据进一步按声学条件和话题进行分类,以更全面地评估系统在复杂多样场景下的表现。
Overall results
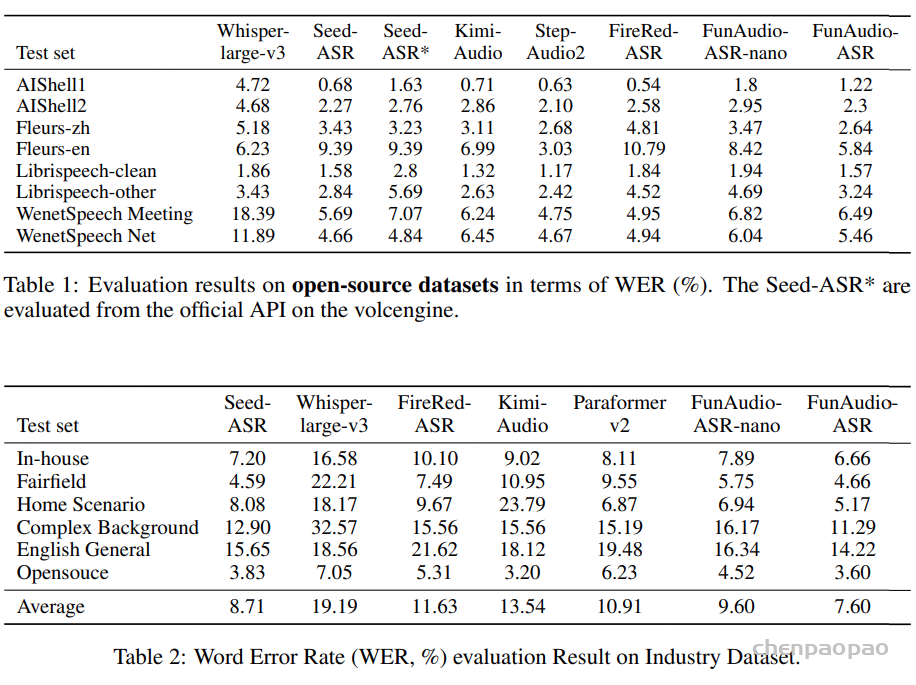
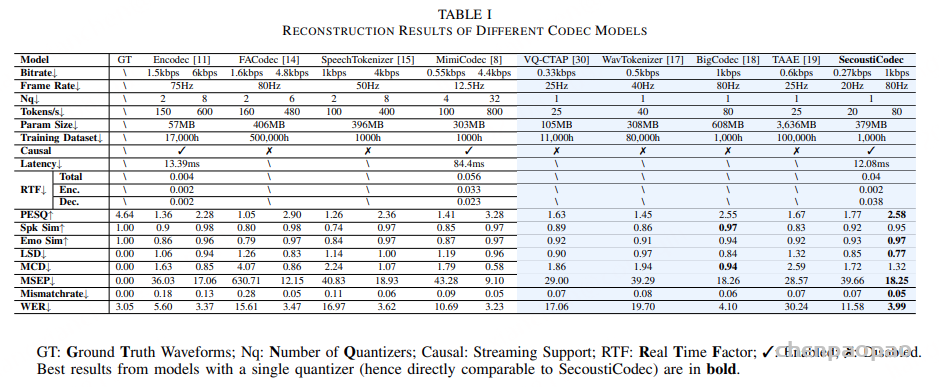
我们首先在开源基准上评测了近期发布的 ASR 系统,结果如表 1 所示。在这些数据集上,所有模型的 WER(词错误率)都非常低 ,甚至有一些开源模型在 Librispeech 和 AIShell 数据集上的表现超越了商业 API。在真实的工业评测集上,Seed-ASR-API 在多数场景,尤其是噪声环境下,表现出明显优势 。这表明 在开源测试集上的表现并不能可靠反映真实世界的 ASR 能力 ,因此需要定期更新评测集以避免数据泄漏。
相比开源模型与商业 API,我们的 FunAudio-ASR 在开源基准(表 1)和工业数据集(表 2)上均取得了 SOTA(最优)性能 。2025年6月30日之前 收集,确保了评测过程中 无数据泄漏 ,使得结果可信且可复现。值得注意的是,FunAudio-ASR-nano (仅 0.8B)也超越了开源模型,并且在性能上接近 Seed-ASR 。
Streaming ASR Performance
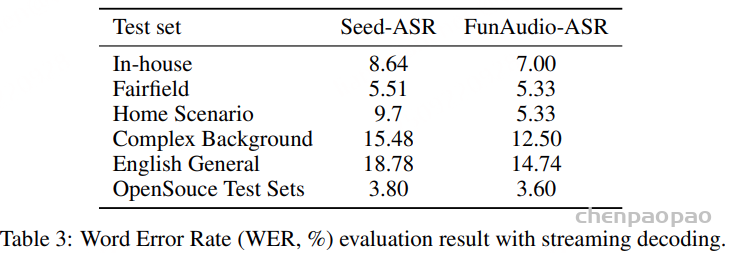
为了评估 FunAudio-ASR 模型的流式识别能力,我们在与离线语音识别相同的测试集上进行了实验,结果如表 3 所示。与 Seed-ASR 相比,我们的 FunAudio-ASR 模型在不同测试集和不同场景下都表现出更优异的性能。
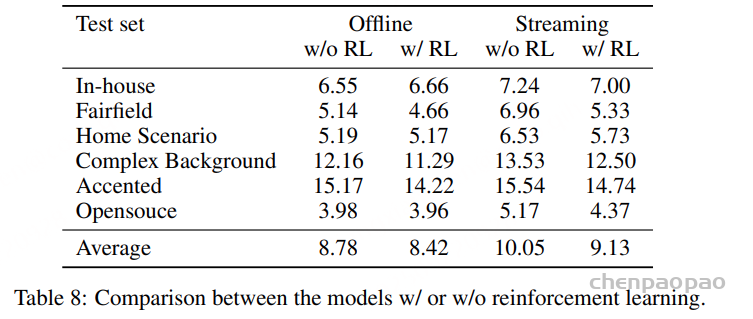
Evaluation on Noise Robustness
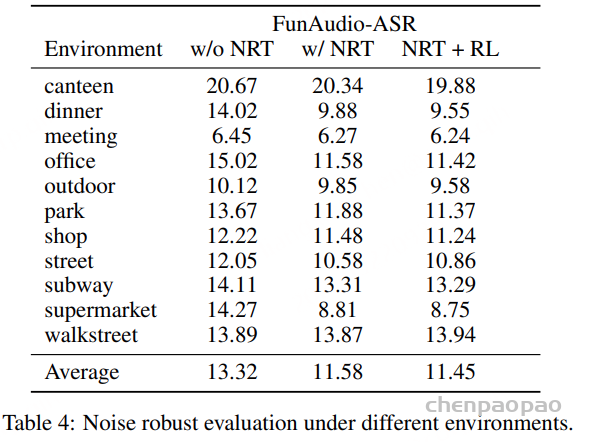
表 4 中展示了 噪声鲁棒性评估 。结果表明,噪声鲁棒训练(NRT) 对于工业应用至关重要。在餐厅、超市等复杂环境中,NRT 能带来超过 30% 的相对提升 ,这是因为基于大模型的 ASR 系统在此类声学条件下容易生成幻觉式输出。此外,强化学习(RL) 进一步增强了模型的噪声鲁棒性。
Code-switching Evaluation
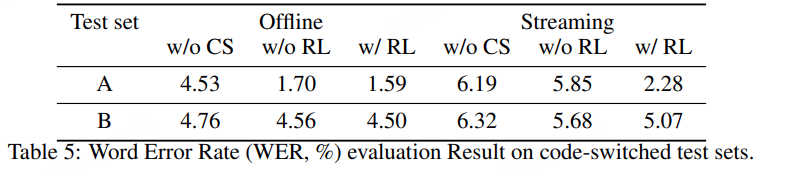
用两个测试集 A 和 B 来评估构建的语码转换训练数据的有效性:
热门词汇定制评估
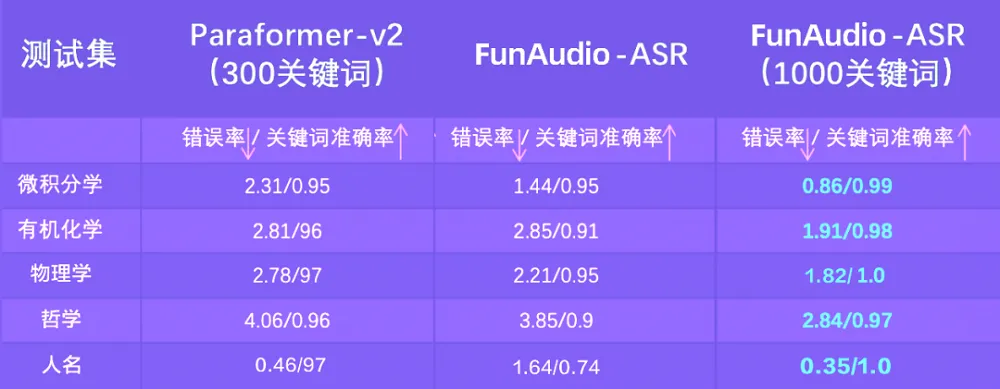
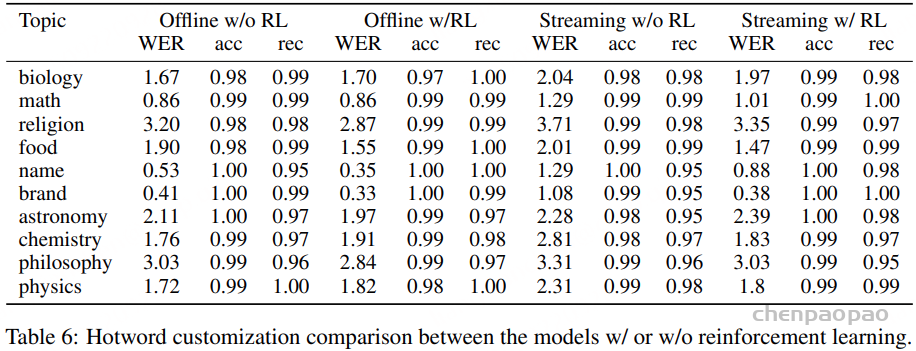
在 热词评测 中,我们选择了一些带有特殊主题的音频 ,包括 生物、数学、宗教、食品、姓名、天文学、化学、哲学和物理 ,因为技术术语的识别对大多数 ASR 系统来说仍然是关键但具有挑战性的任务。表 6 的结果表明,FunAudio-ASR 可以从热词定制中显著受益 。在大多数主题上,FunAudio-ASR 的 召回率(recall)可以提升到 0.97 以上 。在 姓名 主题上,召回率甚至可以从 0.75 提升到 1.0 。这表明 热词定制不仅仅是提供上下文信息,而是真正激发并强化了目标关键词的识别 。
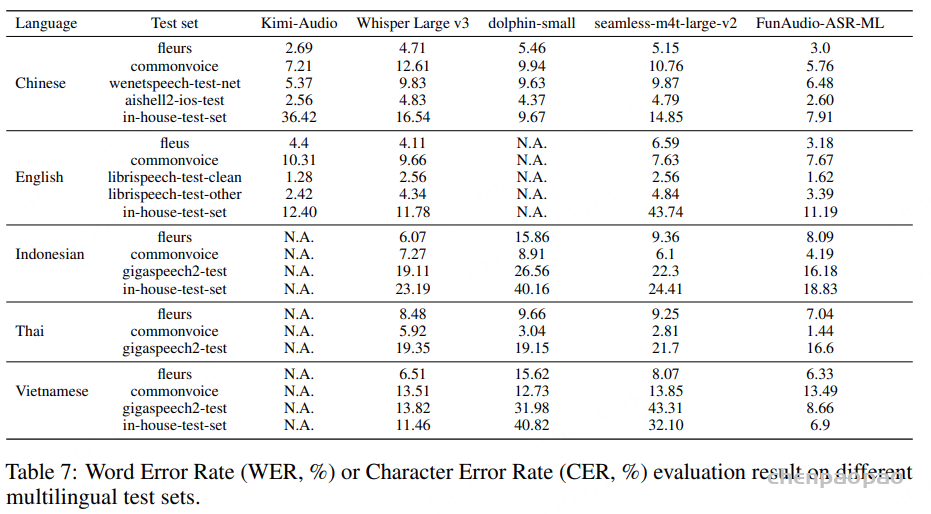
Multilingual ASR Results
我们还在多个开源测试集和内部行业测试集上评估了我们的多语种 ASR 模型 FunAudio-ASR-ML 。表 7 给出了测试结果。由表 7 可见,在 中文和英文的开源测试集及内部行业测试集 上,我们的多语种 ASR 模型 FunAudio-ASR-ML 相较于 Kimi-Audio 具有更优或相当的效果。我们还将该模型与其他多语种 ASR 模型进行了比较,例如 Whisper large v3 、dolphin-small和 seamless-m4t large v2 。与这些模型相比,我们的 FunAudio-ASR-ML 同样能够获得 SOTA 性能 。
Effect of Reinforcement Learning
表 8 显示,RL 在 FunAudio-ASR 训练中发挥了关键作用 ,在离线和流式条件下分别带来了约 4.1% 和 9.2% 的相对提升 。对于离线 ASR,相较于干净或开源数据,在嘈杂和复杂环境下的音频上性能提升更为显著 。值得注意的是,在流式 ASR 设置中,改进幅度更大。RL 有助于抑制插入和删除错误,这些错误往往源于模型在完整发音尚未结束前的过早终止或预测。
如表 6 所示,RL 还能 有效增强热词集成 ,在大多数测试集上都提升了准确率和召回率。在某些领域(如哲学和宗教),RL 模型的准确率或召回率可能略低于基线模型;然而,整体 WER 仍然降低 。这是因为在 RL 训练过程中,关键词的选择基于实际转录而非输入提示,从而使 FunAudio-ASR 能够更好地识别领域特定术语——即便这些专业词汇未被显式包含在热词列表中。
Limitations and Future Plans
尽管我们的 FunAudio-ASR 模型在多项评估中都取得了优异的成绩,但仍存在一些局限性。首先,它主要针对中文和英文进行优化,尤其是在流媒体性能和启动词自定义方面,因此对其他语言的支持仍然有限。其次,有效上下文窗口受限;如果没有外部语音活动检测 (VAD) 模块,系统难以稳健地处理长时间录音。第三,当前版本不支持远场或多声道音频。我们计划在未来的工作中解决这些局限性。