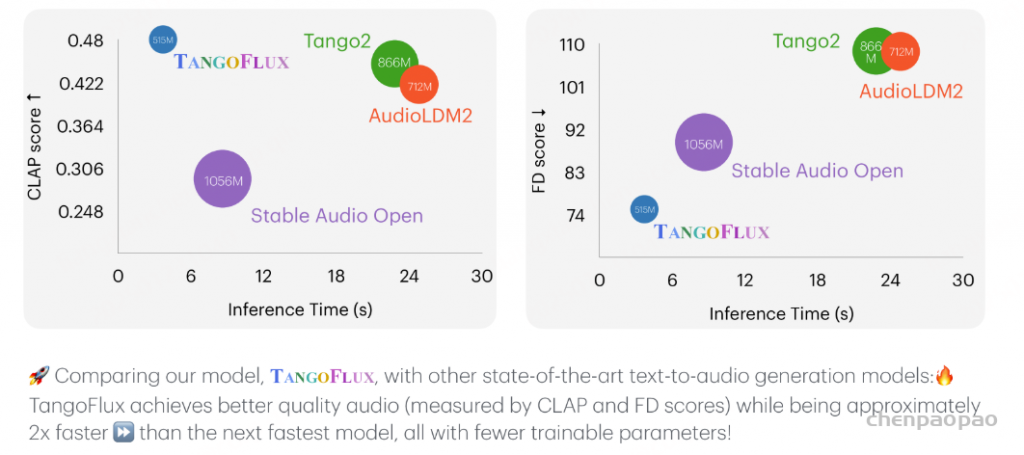
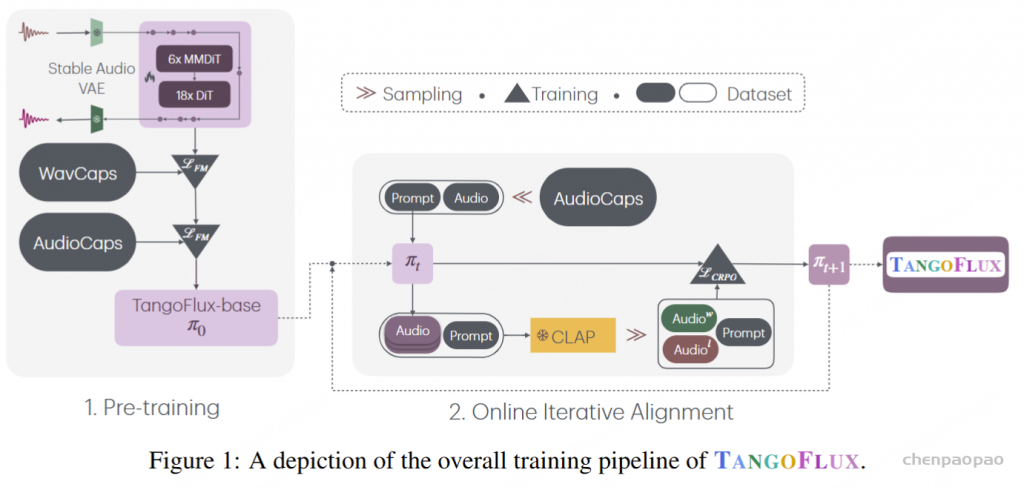
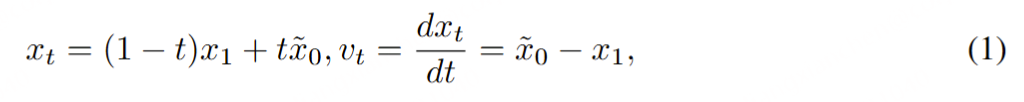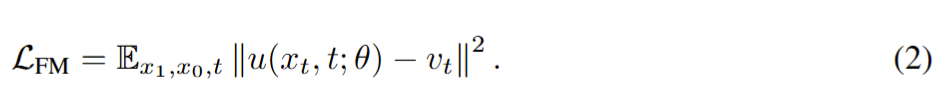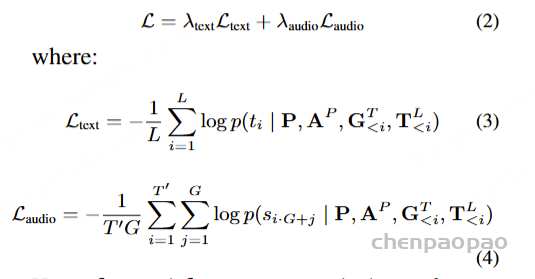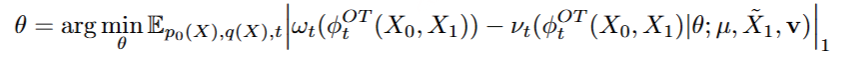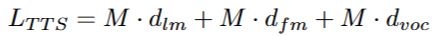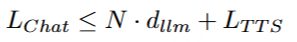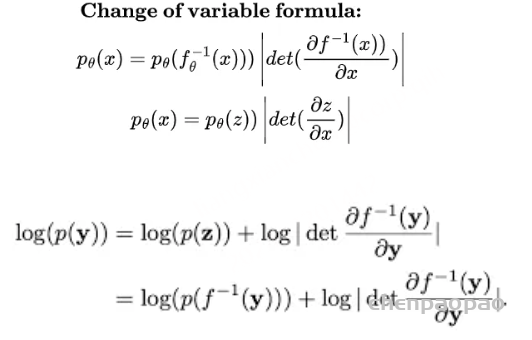# 1️⃣ Install dependencies silently
!git lfs install
!git clone https://huggingface.co/hexgrad/Kokoro-82M
%cd Kokoro-82M
!apt-get -qq -y install espeak-ng > /dev/null 2>&1
!pip install -q phonemizer torch transformers scipy munch
# 2️⃣ Build the model and load the default voicepack
from models import build_model
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
MODEL = build_model('kokoro-v0_19.pth', device)
VOICE_NAME = [
'af', # Default voice is a 50-50 mix of Bella & Sarah
'af_bella', 'af_sarah', 'am_adam', 'am_michael',
'bf_emma', 'bf_isabella', 'bm_george', 'bm_lewis',
'af_nicole', 'af_sky',
][0]
VOICEPACK = torch.load(f'voices/{VOICE_NAME}.pt', weights_only=True).to(device)
print(f'Loaded voice: {VOICE_NAME}')
# 3️⃣ Call generate, which returns 24khz audio and the phonemes used
from kokoro import generate
text = "How could I know? It's an unanswerable question. Like asking an unborn child if they'll lead a good life. They haven't even been born."
audio, out_ps = generate(MODEL, text, VOICEPACK, lang=VOICE_NAME[0])
# Language is determined by the first letter of the VOICE_NAME:
# 'a' => American English => en-us
# 'b' => British English => en-gb
# 4️⃣ Display the 24khz audio and print the output phonemes
from IPython.display import display, Audio
display(Audio(data=audio, rate=24000, autoplay=True))
print(out_ps)
本项目是一个围绕开源大模型、针对国内初学者、基于 Linux 平台的中国宝宝专属大模型教程,针对各类开源大模型提供包括环境配置、本地部署、高效微调等技能在内的全流程指导,简化开源大模型的部署、使用和应用流程,让更多的普通学生、研究者更好地使用开源大模型,帮助开源、自由的大模型更快融入到普通学习者的生活中。
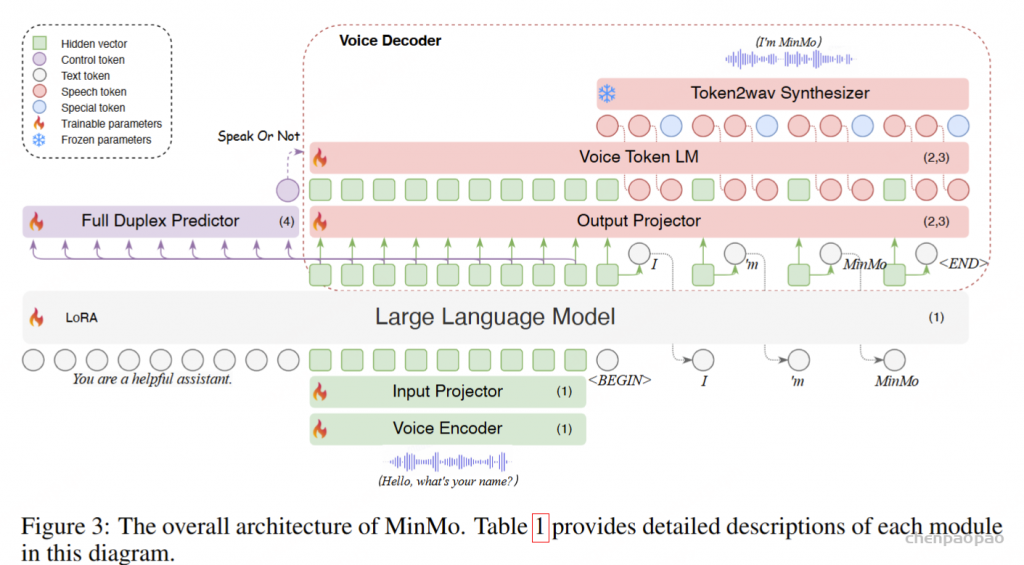
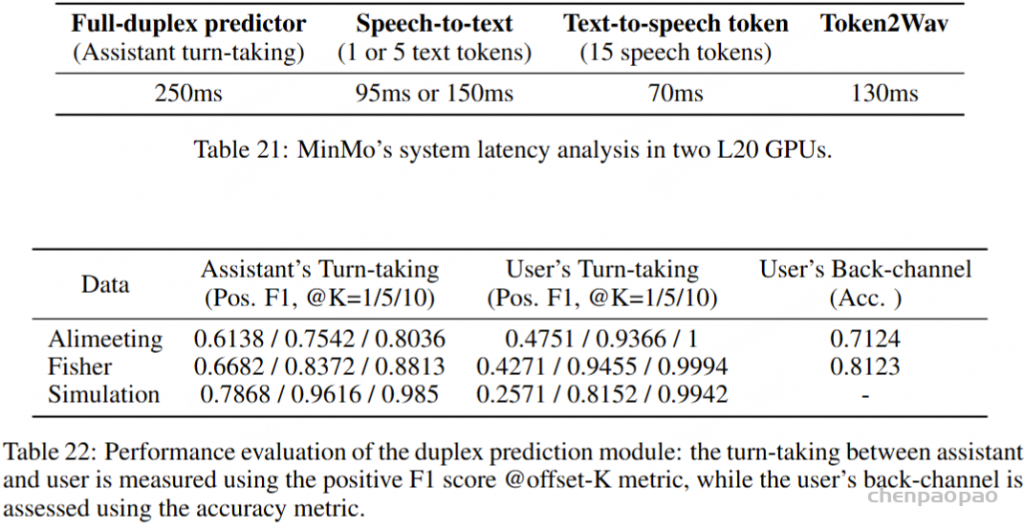
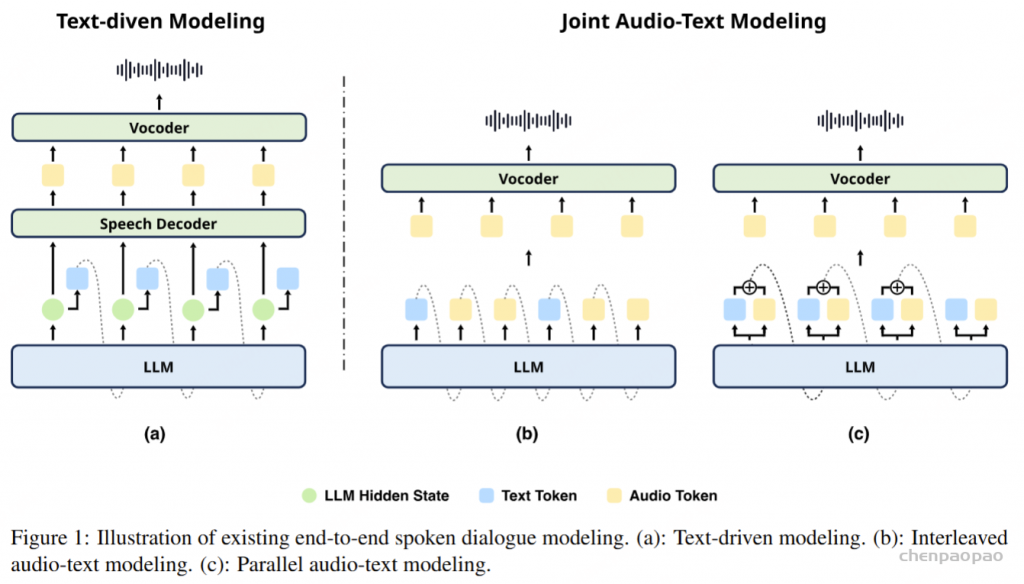
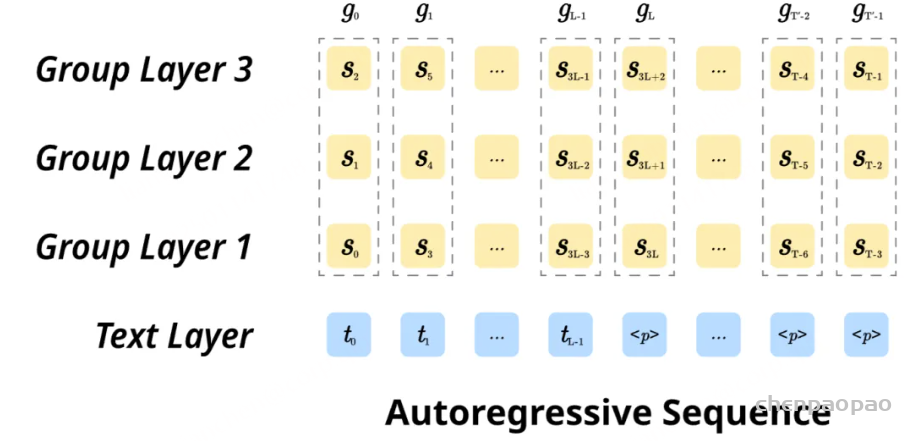
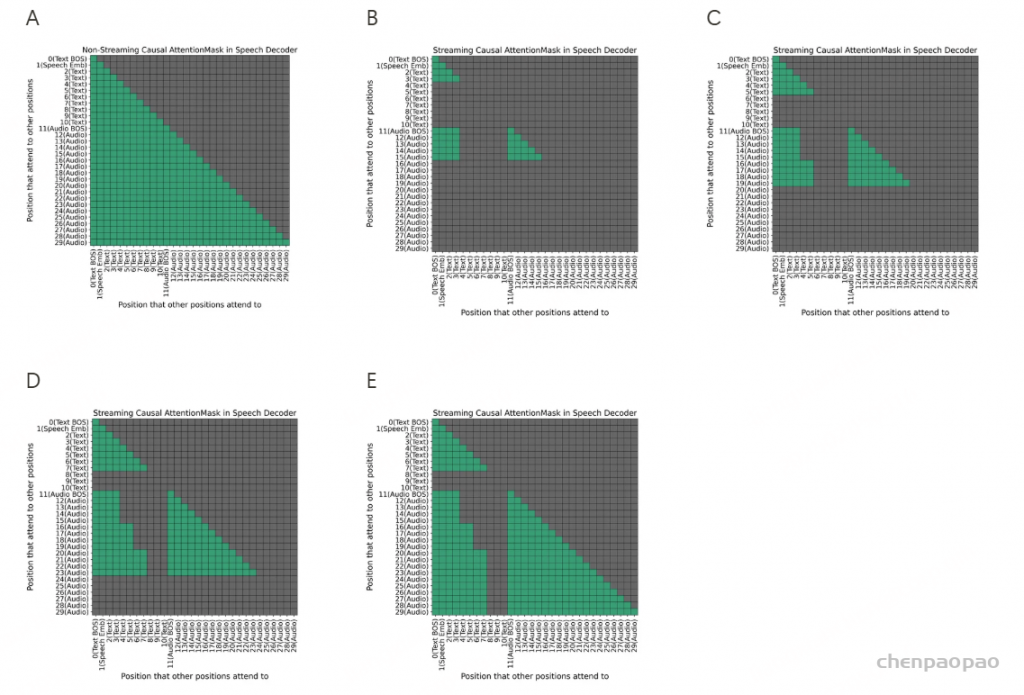
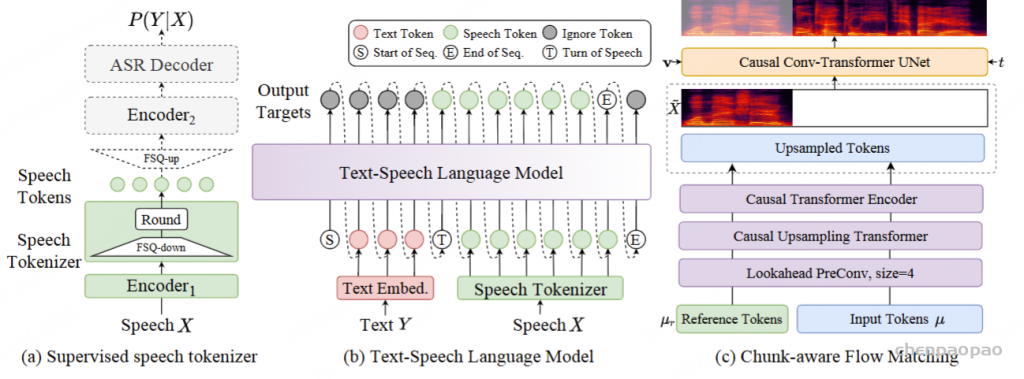
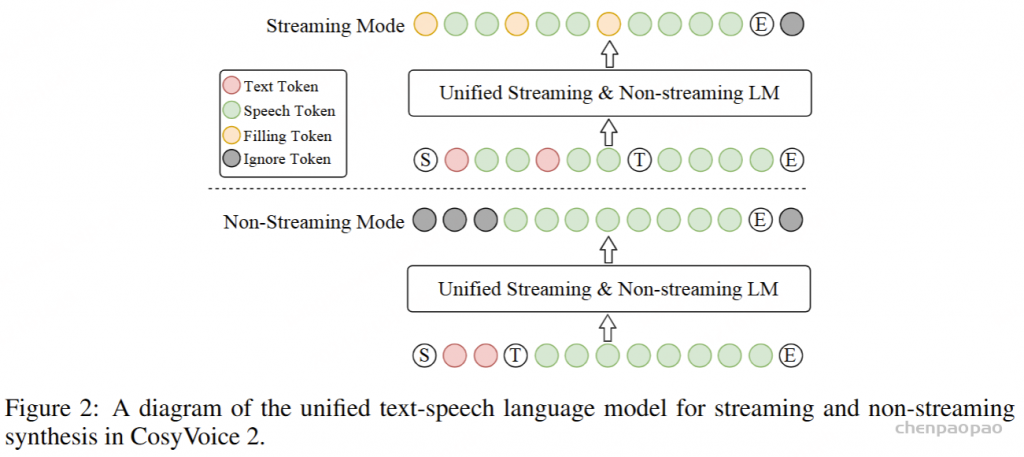
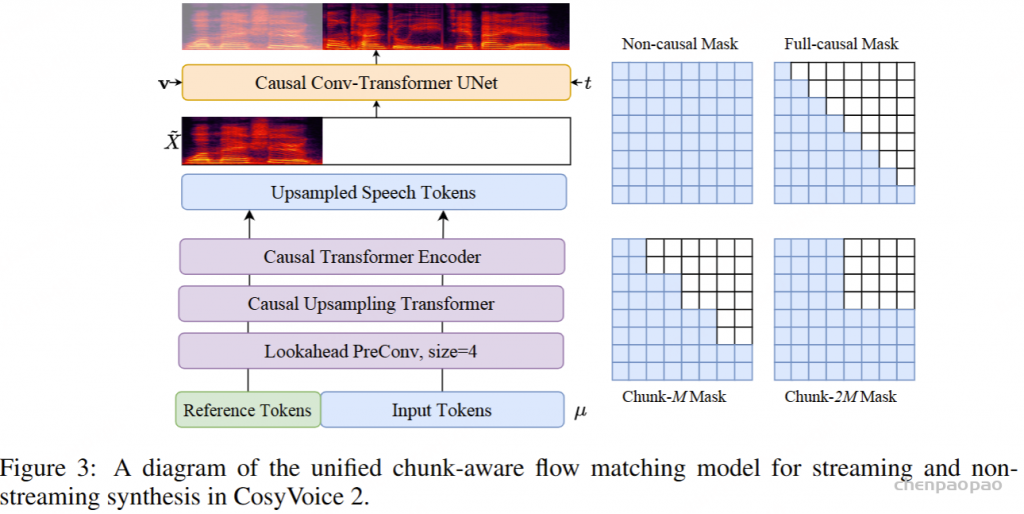
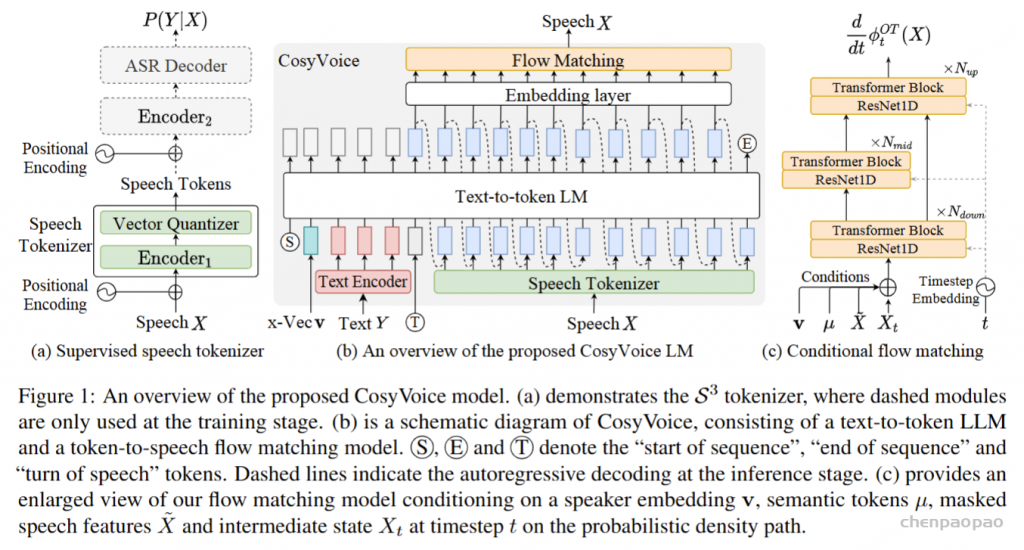
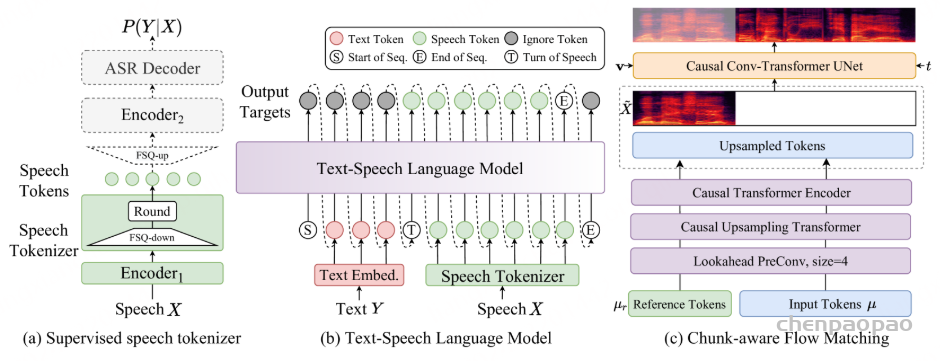
在训练过程中,采用教师强制策略,并引入一个特殊标记,用于指示下一个语义向量应被连接。当 LLM 的文本响应完成且语义向量耗尽时,我们插入一个“语音轮次”(turn of speech)标记,提示语音标记语言模型接下来的标记应完全为语音标记。当生成“语音结束”(end of speech)标记时,语音合成过程结束。
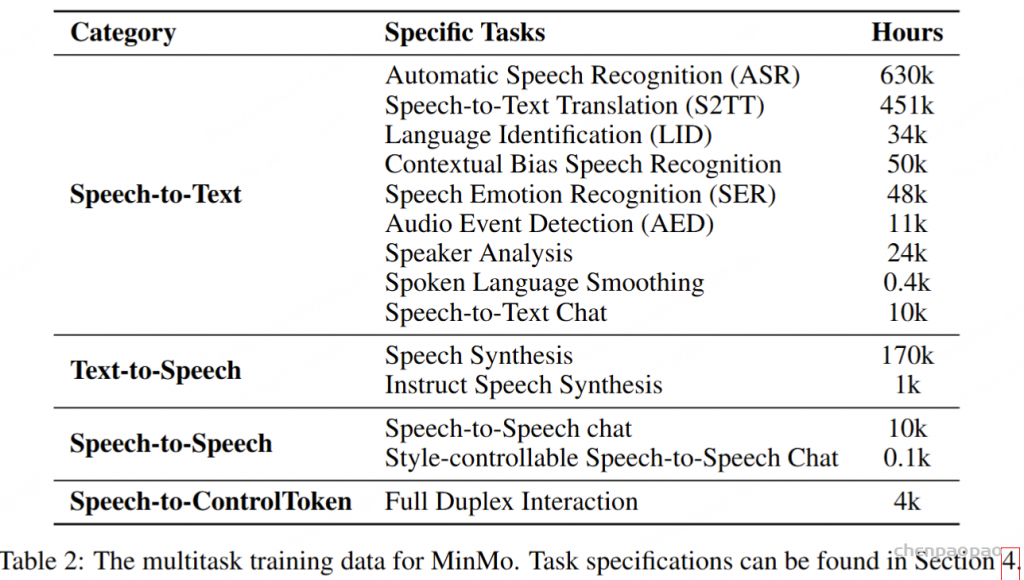
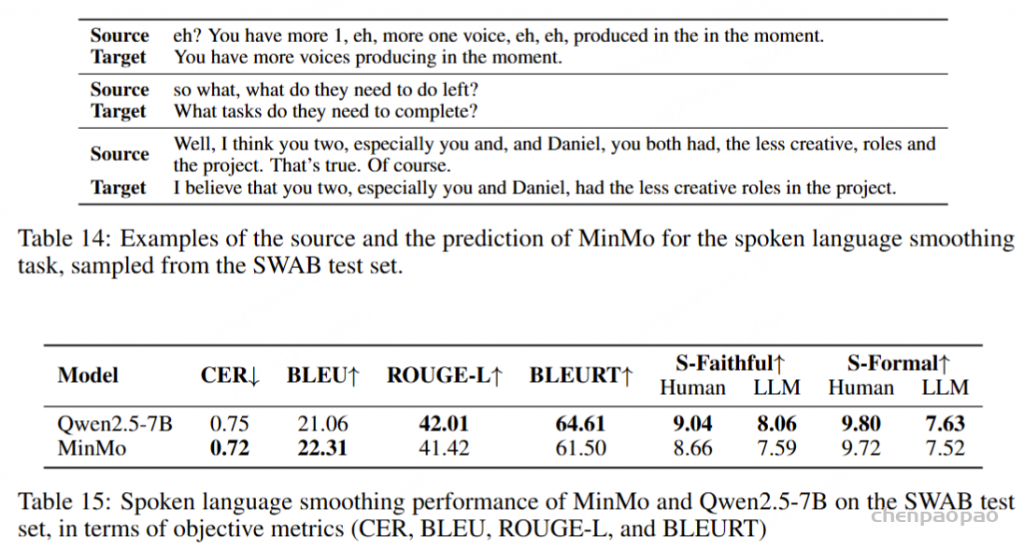
口语语言平滑任务以口语ASR(自动语音识别)转录文本为输入,输出正式风格的书面文本。表14展示了口语语言平滑的一些示例。为该任务,我们通过扩展为ASR转录文本的口语到书面转换而创建的SWAB数据集(Liu et al., 2025),构建了一个多领域数据集用于训练和评估。SWAB数据集源自中文和英文的会议、播客及讲座。
在客观指标评估中,我们使用BLEU(Papineni et al., 2002)、ROUGE(Lin, 2004)和BLEURT(Sellam et al., 2020),以人工目标为参考。然而,我们注意到口语语言平滑任务具有显著的主观性和多样性,因此基于词汇匹配的客观指标可能无法充分反映模型性能。因此,我们采用人工和LLM注释来提供信实性(S-Faithful,即对原始内容的信实性)和正式性(S-Formal)的排名评估。自动化LLM评分的提示见附录A.1。
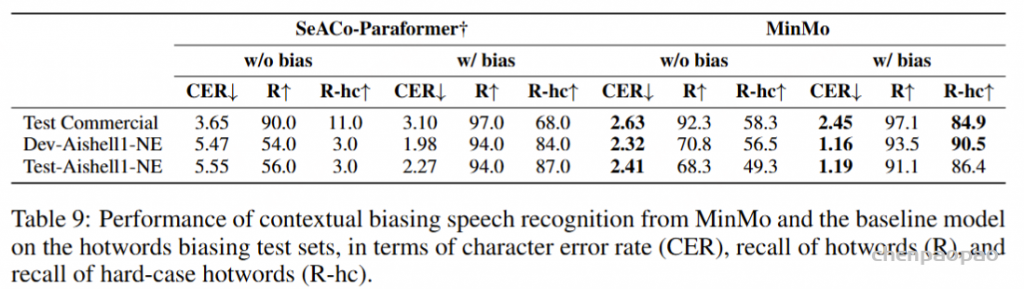
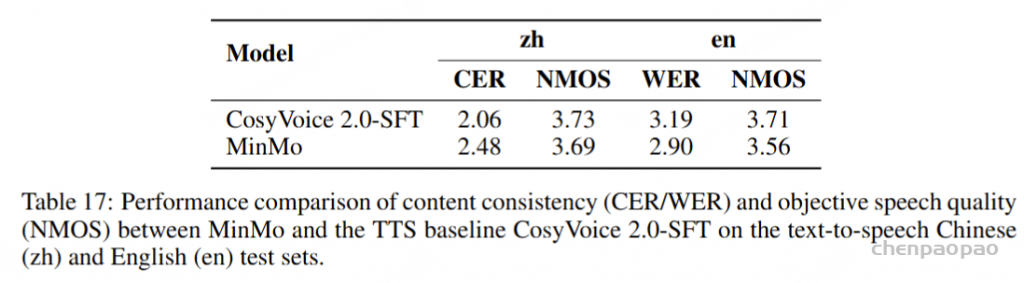
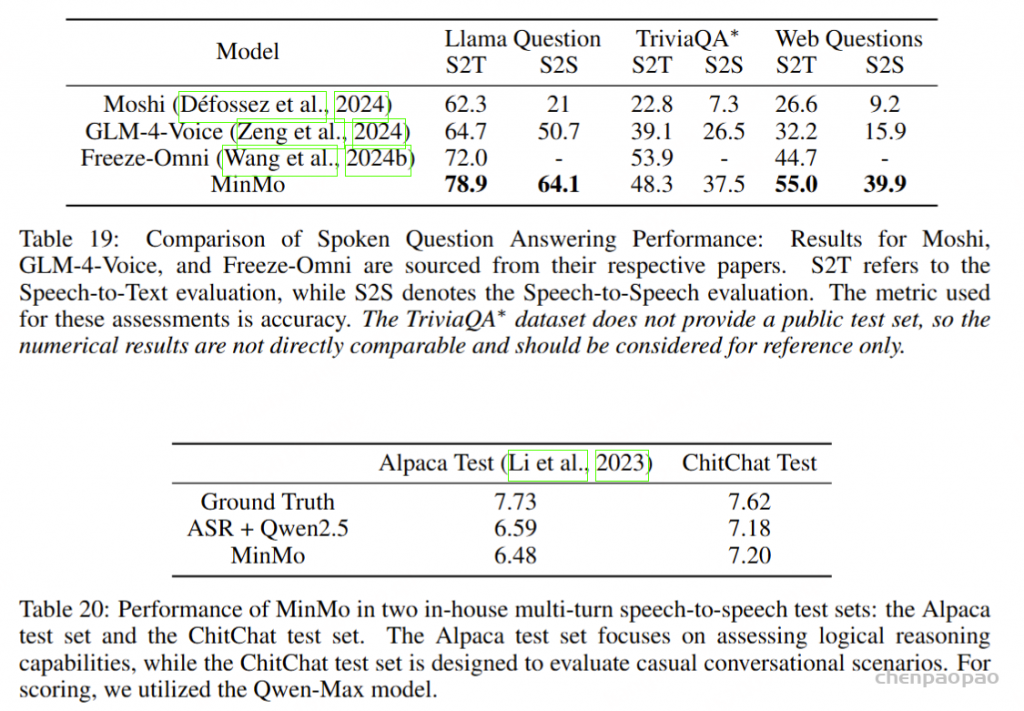
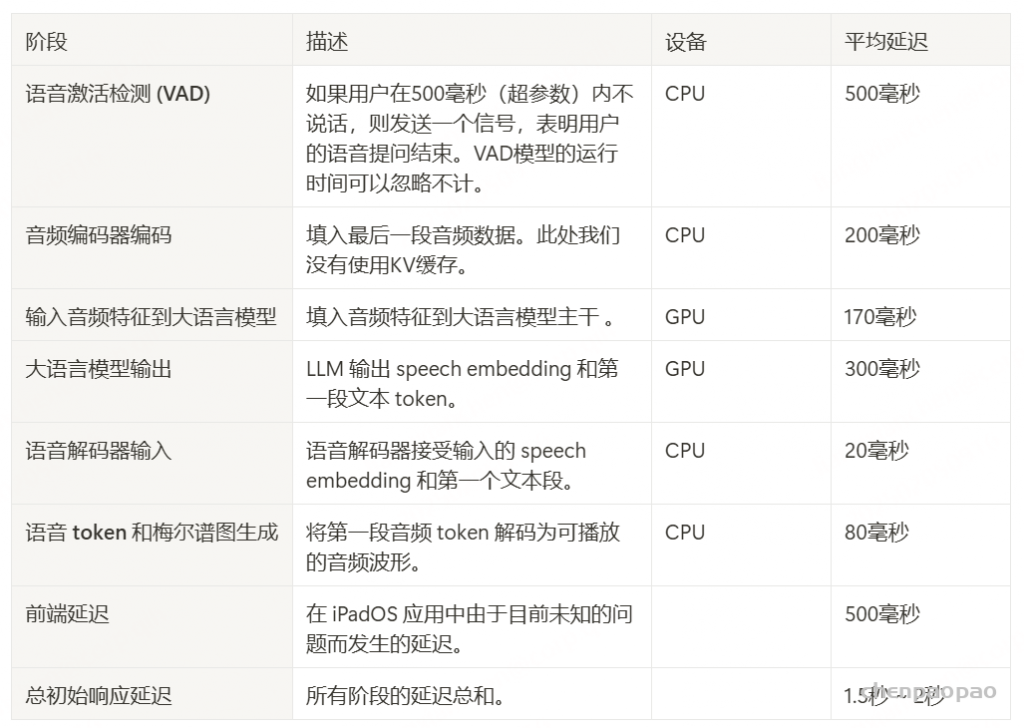
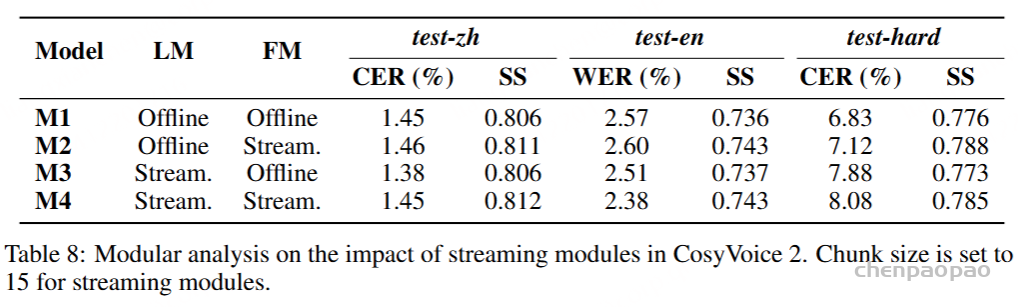
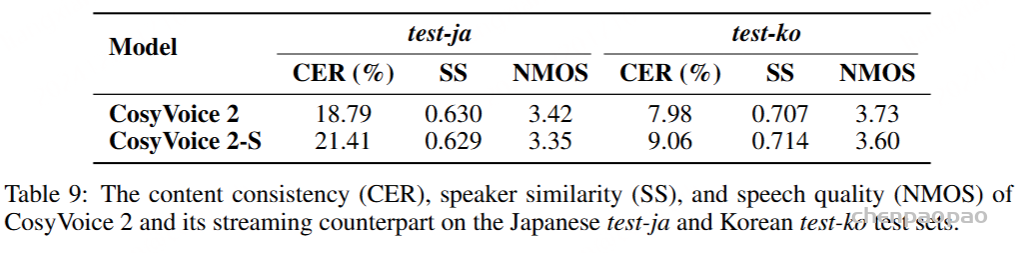
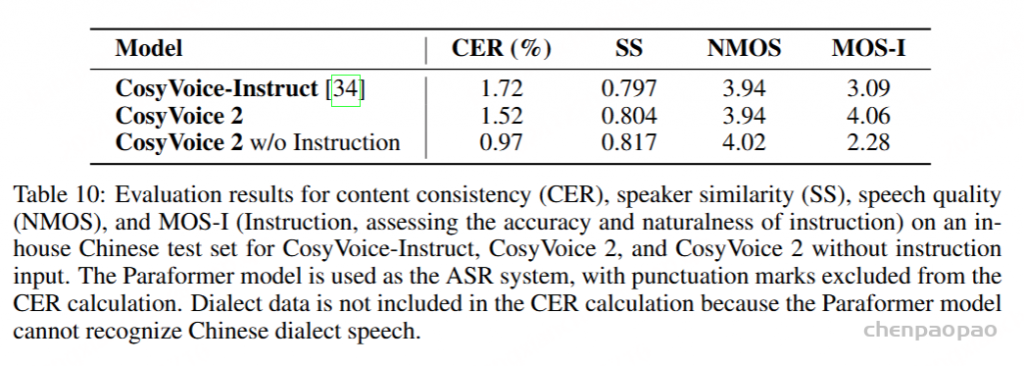
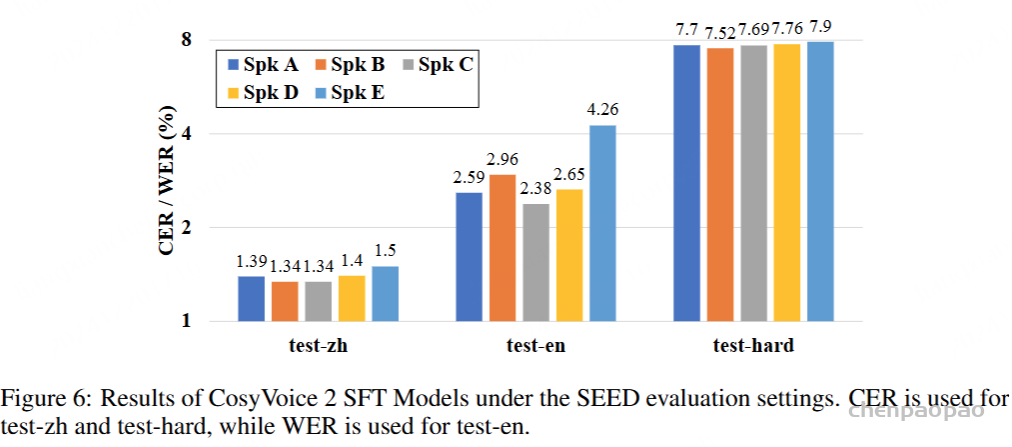
为了评估我们语音解码器的合成准确性,我们将最新的SEED测试集(Anastassiou et al., 2024)转换为ChatLM格式。在该格式中,文本以用户内容的形式呈现,并以“Copy:”命令为前缀,LLM预计会复制该文本。测试集包括2,020个中文案例和1,088个英文案例。对于中文案例,我们使用了Paraformer-zh模型(Gao et al., 2022),而英文案例则使用了Whisper-large V3(Radford et al., 2023)。鉴于LLM存在的指令跟随问题,我们在推理过程中应用了教师强制方案,以最小化输入和输出文本之间的差异。语音解码器的内容一致性通过中文的CER(字符错误率)和英文的WER(词错误率)进行评估。
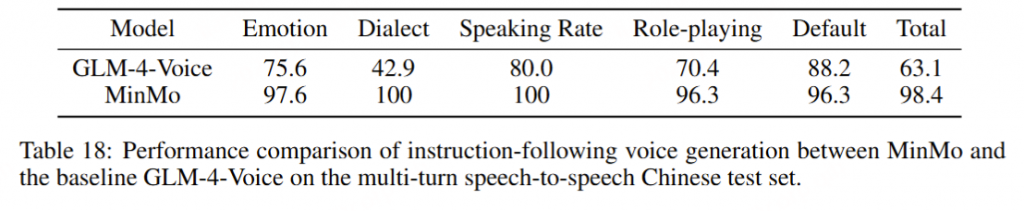
我们的发现表明,即使在应用了教师强制方案的情况下,只有大约20%的测试案例的输入和输出文本与LLM完全一致。由于不一致的输入和输出可能导致语音解码器的隐藏状态混乱,因此仅包括输入和输出文本一致的测试案例来计算错误率。结果如表17所示。我们观察到,与TTS基线模型CosyVoice 2.0-SFT(Du et al., 2024b)相比,MinMo在中文测试集上表现出稍微较低的内容一致性和语音质量。在英文测试集上,MinMo在内容一致性上表现相似,但NMOS(语音质量评分)稍低。这个下降可以归因于微调的说话人不同的声学特性,这影响了识别模型和NMOS评分器。然而,这种下降不会显著影响人类的理解。因此,主观评估可能更适合语音到语音的语音聊天模型,我们将在未来的工作中进一步探讨这一点。
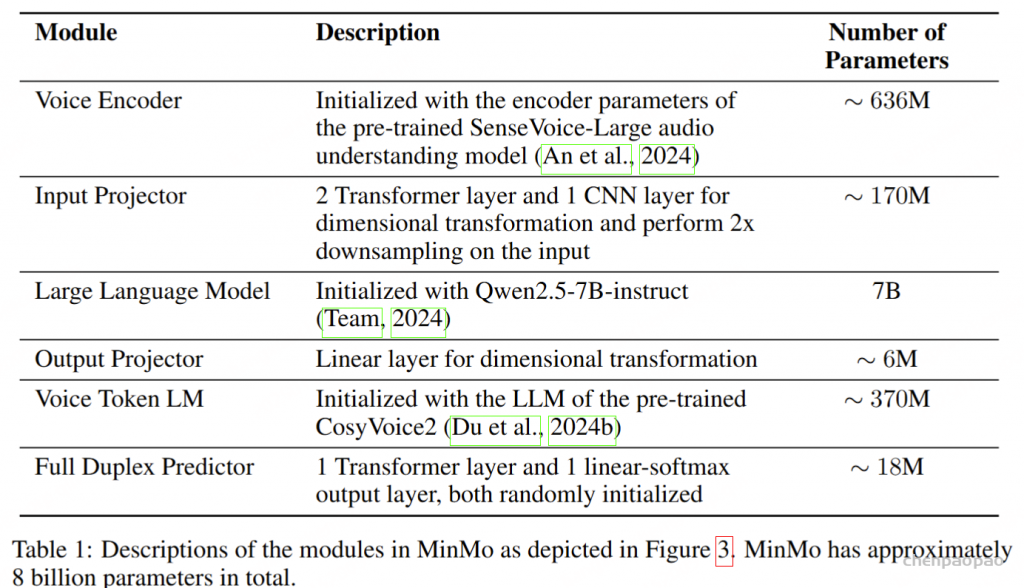
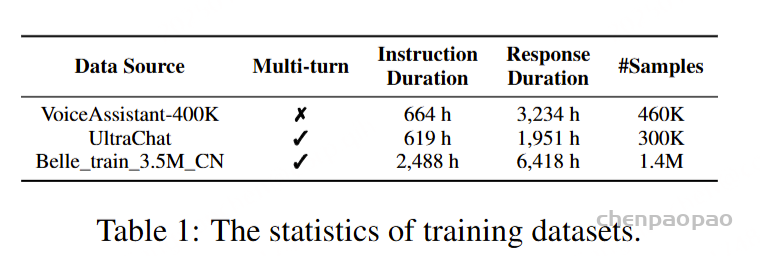
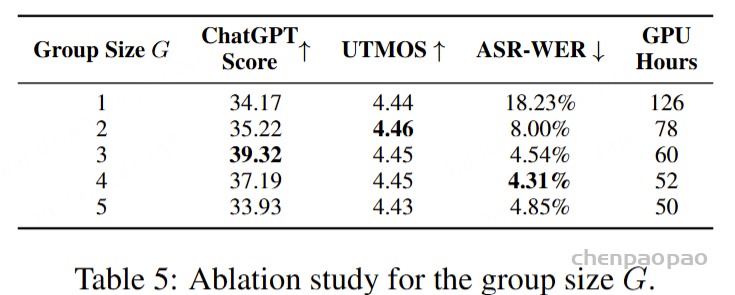
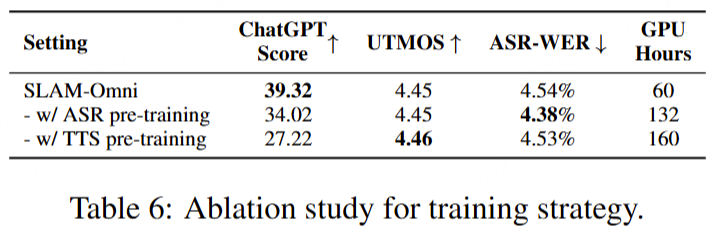
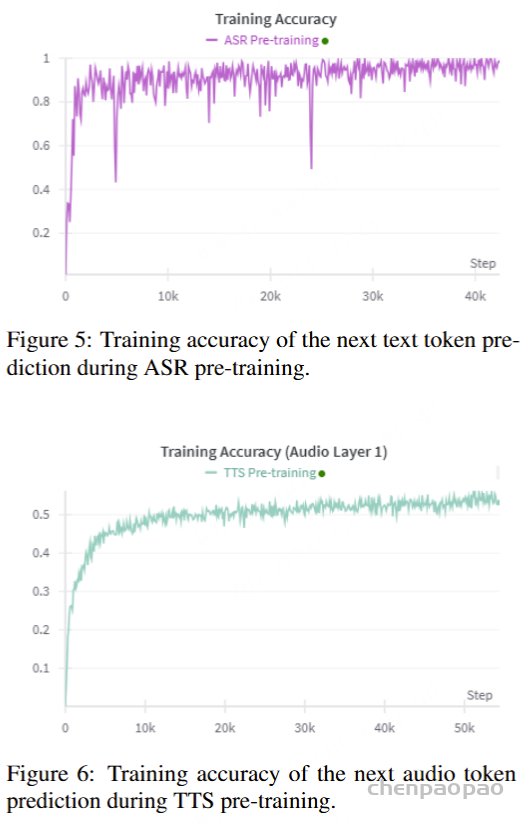
对于ASR和TTS预训练,专门使用VoiceAssistant-400K数据集来确保一致性并避免引入外部数据。在 ASR 预训练期间,提供语音指令作为输入,其相应的转录文本作为目标输出。相反,对于 TTS 预训练,语音响应的转录被用作输入文本,而相应的语义token被设置为预测目标。优化和学习策略与微调期间采用的策略一致,值得注意的是,在 ASR 预训练期间仅计算文本层损失,而 TTS 预训练专门关注多层音频损失作为训练目标。
This is a curated list of open speech datasets for speech-related research (mainly for Automatic Speech Recognition).
Over 110 speech datasets are collected in this repository, and more than 70 datasets can be downloaded directly without further application or registration.
Notice:
This repository does not show corresponding License of each dataset. Basically it’s OK to use these datasets for research purpose only. Please make sure the License is suitable before using for commercial purpose.
Some small-scale speech corpora are not shown here for concision.
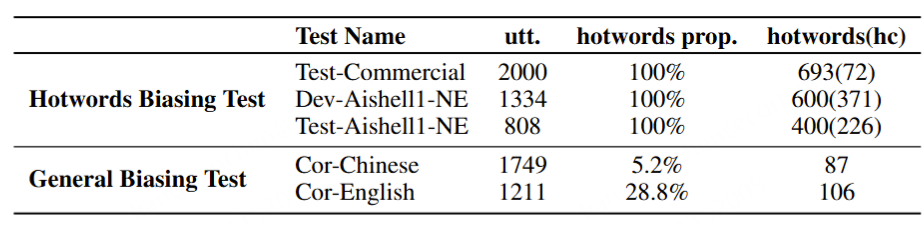
1. Data Overview
Dataset Acquisition
Sup/Unsup
All Languages (Hours)
Mandarin (Hours)
English (Hours)
download directly
supervised
199k +
2110 +
34k +
download directly
unsupervised
530k +
1360 +
68k +
download directly
total
729k +
3470 +
102k +
need application
supervised
53k +
16740 +
50k +
need application
unsupervised
60k +
12400 +
57k +
need application
total
113k +
29140 +
107k +
total
supervised
252k +
18850 +
84k +
total
unsupervised
590k +
13760 +
125k +
total
total
842k +
32610 +
209k +
Mandarin here includes Mandarin-English CS corpora.
Sup means supervised speech corpus with high-quality transcription.
Unsup means unsupervised or weakly-supervised speech corpus.
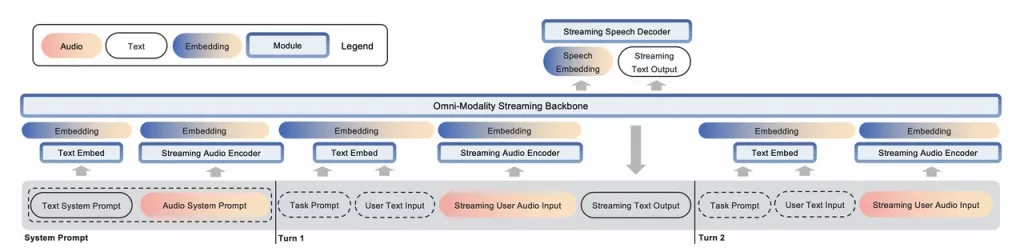
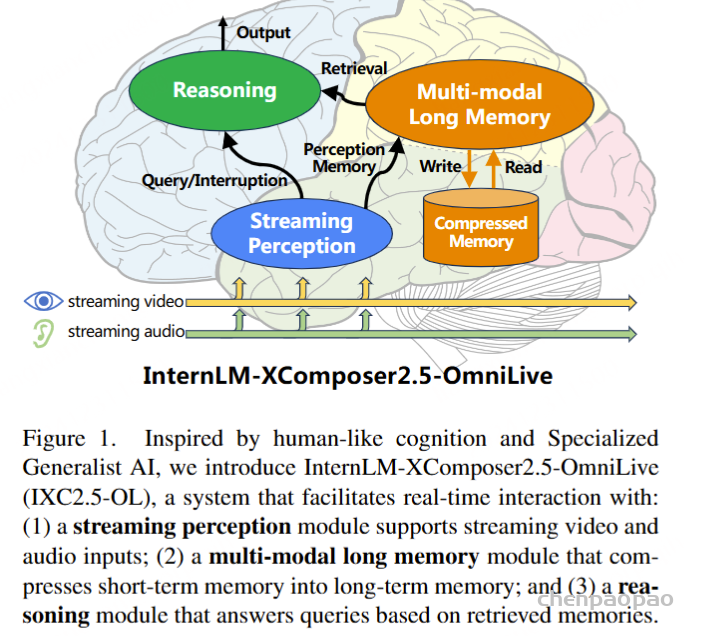
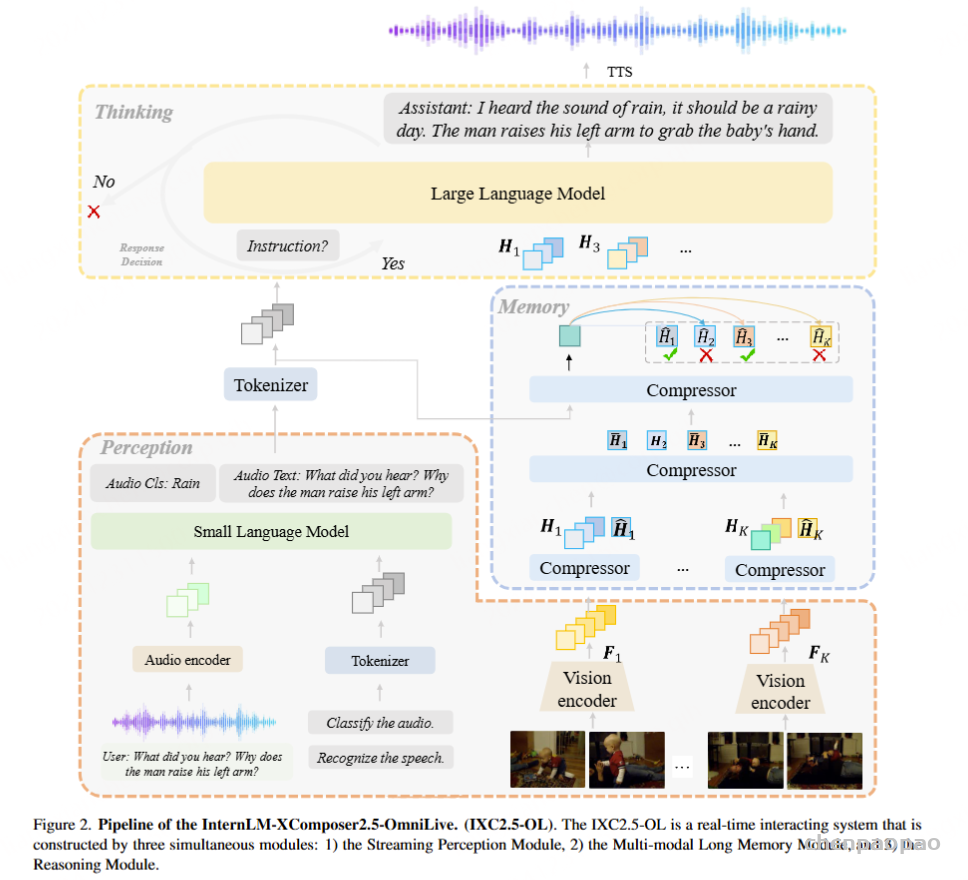
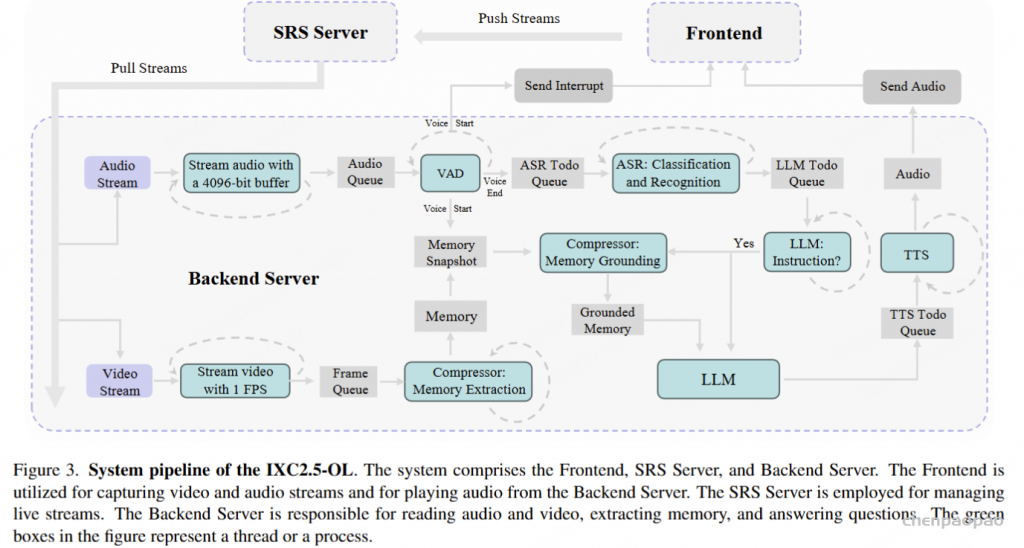
随着人工智能的发展,构建能够实时感知环境、进行复杂推理并记忆的系统,已成为研究者们追求的目标。这不仅要求 AI 系统能处理音频、视频和文本等多模态数据,还需在动态环境中模拟人类感知、推理与记忆的协同能力。然而,现有多模态大语言模型(MLLMs)在这方面仍存在诸多限制,尤其是在同时处理任务时的效率和可扩展性。
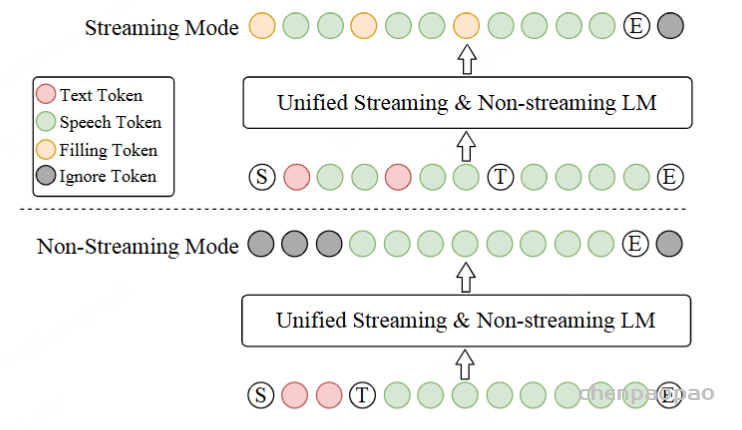
ICL,非流式:在 ICL 中,LM 需要来自参考音频的提示文本和语音标记,以模仿重音、韵律、情感和风格。在非流式处理模式下,提示和要合成的文本标记连接为整个实体,提示语音标记被视为预先生成的结果并固定:“S 、 prompt_text、 text 、T、 prompt_speech”。LM 的自回归生成从此类序列开始,直到检测到 “End of sequence” 标记。
ICL,流式处理:在此方案中,我们假设要生成的文本是已知的,并且语音令牌应以流式处理方式生成。同样,我们将 prompt 和 to-generate 文本视为一个整体。然后,我们将其与提示语音标记混合,比例为 N : M : “S, mixed_text_speech,T,remaining_speech”。如果文本长度大于提示语音 Token 的长度,LM 将生成 “filling token”。在这种情况下,我们手动填充 N个文本标记。如果文本令牌用完,将添加“Turn of speech” T 令牌。在流式处理模式下,我们为每个 M 令牌返回生成结果,直到检测到 E为止。
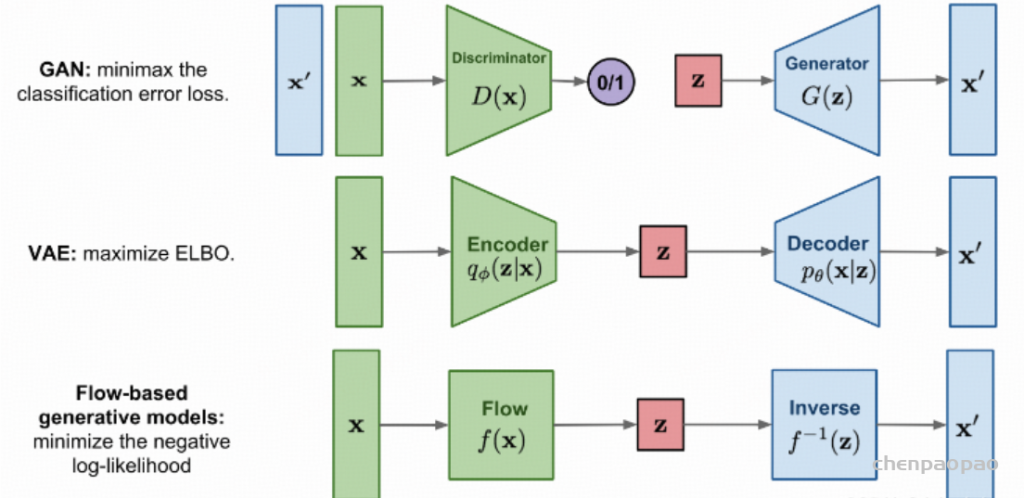
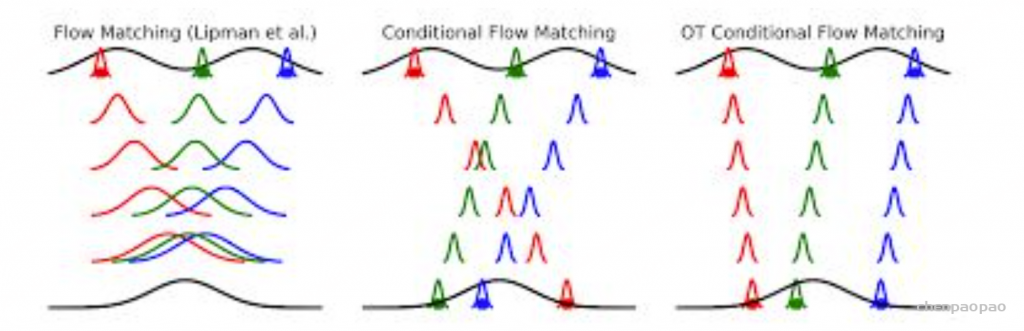
每个生成模型(generative model)理想情况下都是密度估计(density estimaor);因此模拟概率密度,最终是 JPD,具有两个预期特征,即采样和压缩,压缩基本上是将数据推送到信息空间,这似乎是较低维的,而采样是从任何特征分布(z)开始生成 P(x|z) 的能力,可以是正态分布(如 VAE 的情况),因此,在非常高的层次上,我们试图找到将 z 映射到 x 以及将 x 映射到 z(采样和压缩)的映射/函数。
假设两个 Normalizing Flows,一个表示为 z(潜在或可处理分布),另一个表示为 X(数据分布),因为我们想要找到一个可以将 z 映射到 x 的函数,我们会得到 X 和 Z 密度之间的关系,这必然指出假设 X 和 Z 是共轭分布(变换前后同一家族 z 的分布),X 和 Z 的变化应该是相对的,因此,X 的变化是 Z 的某个函数,反之亦然。但是,按某个量缩放。这个量由雅可比矩阵给出的 z 和 x 之间每个维度的变化表示,在非常简单的尺度上,它基本上是 Z 和 X 之间变量的变化。但是,它不是那么简单,因为 X 和 Z 实际上并不共轭,因此,我们只剩下迭代采样和近似方法,比如最佳传输或吉布斯采样(用于 RBM)。鉴于这些限制,大多数方法都绕道去模拟分布并近似非精确映射,而像 Normalizing flow 这样的方法则做出简化假设,使计算和公式易于处理,形式为 p(x)dx = p(z)dz,可以将其重新表述为两个项,第一个是 MLE 项,第二个是雅可比行列式。
要解决这个问题,我们需要假设 z 和 X 之间的状态依赖性,使得它是双射的并且行列式可以有效计算,有三种主要方法
1. 耦合块:基本上你将 z 分成两块,只有最后 k 值预测 X 的最后 k 值(通过基于均值/方差的采样),X 的其他部分基本上是 z 的直接复制,这有何帮助?由于这种方法,雅可比矩阵变成了对角矩阵,左上角(<k)部分是恒等矩阵,右下角(>=k)变成元素乘积,右上角变成 0,因为 z(<k)和 x(>=k)之间没有依赖关系,因此,雅可比行列式的计算是有效的。
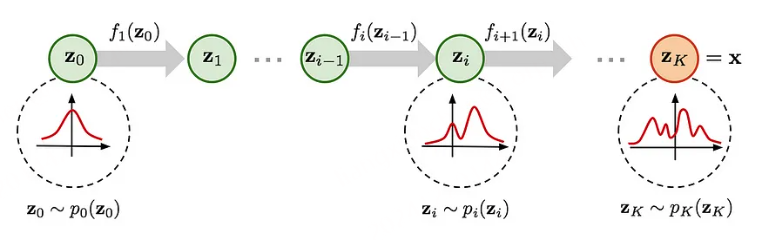
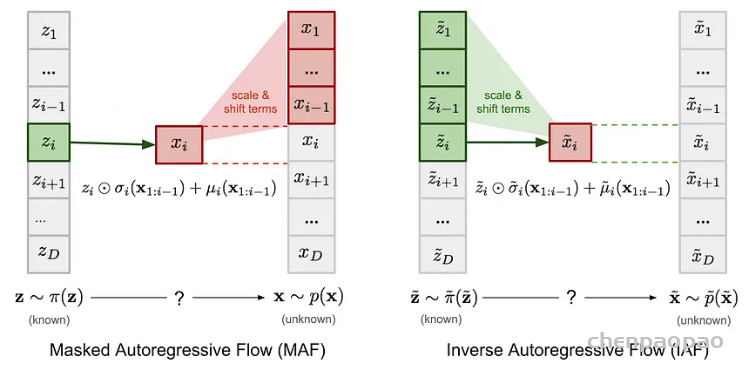
2. AR 流或自回归流是下一个合乎逻辑的扩展,与其制作大 k 块,为什么不将每个状态/特征视为马尔可夫链的一部分,从而消除额外的依赖关系,这会导致雅可比矩阵的下三角矩阵,这也很容易计算。但是,这种方法保留了更多的特征,并且不易受到我们在耦合层中为保留特征而进行的置换操作的影响。
图 MAF 和 IAF 的比较。具有已知密度的变量为绿色,而未知的变量为红色。
3. 最后,残差流,我们保留整个特征空间,而不牺牲计算。这个想法很简单,但却有非常复杂的数学支持。公式是残差形式 x = z + f(z),但这不是双射,因为 f 是一个神经网络。有趣的是,多亏了 Banach 和他的收缩映射,在理想情况下,存在一个唯一的 z*,它总是映射到相同的 x(稳定状态 z),因此,它也变成了双射,形式为 x = z* + f(z*),其中 f 是一个收缩映射(函数受 Lipschitz 小于 1 的限制,因此,z 的变化受 X 的变化的限制),该形式还为我们提供了一种在给定先前 z(k) 的情况下表示 z(k+1) 的方法,这有助于迭代近似 X,而不是单次框架。我们可以通过相同的公式从 z(0) 转到 z(t),也可以恢复回来,听起来很熟悉,这大致就是扩散。那么行列式呢,迭代变换导致雅可比矩阵迹的无穷项之和,这对于满秩雅可比矩阵来说是可怕的,但可以通过类似的矩阵公式使用哈钦森方法进行迹估计来简单地计算。
Fig. 4. Three substeps in one step of flow in Glow.