
- 论文标题: Explore the Reinforcement Learning for the LLM based ASR and TTS system
- 论文链接: https://arxiv.org/pdf/2509.18569v1
在语音技术领域,ASR(语音识别)和 TTS(语音合成)早已进入 LLM 时代,但 “能用” 和 “好用” 之间,还隔着一道难以逾越的鸿沟:ASR 会出现幻觉、漏检关键词;TTS 发音虽准,却缺自然韵律,甚至越优化语速越慢。
问题的核心在于:LLM 的 “文本 RL” 经验,没法直接套用到音频领域。音频是连续信号,既要处理声学特征,又要对齐语义,传统 RL 框架又笨重又低效。
阿里通义实验室的论文《Explore the Reinforcement Learning for the LLM based ASR and TTS system》,给出了一套 “轻量、高效、通用” 的解决方案。它不仅设计了适配音频大模型的 RL 框架,还在 ASR 和 TTS 任务上做了深度探索:ASR 用 GRPO + 规则奖励,WER 相对下降 5.3%;TTS 把 GRPO 和 DiffRO 结合,既提升发音准确率,又保住自然度,彻底解决了 “顾此失彼” 的问题。实验结果表明,即使在训练数据有限且优化步骤较少的情况下,RL 也能显著提升 ASR 和 TTS 系统的性能。
相关概念
- GRPO(组相对策略优化):轻量化 RL 算法,对一组(G 个)模型输出打分,通过组内奖励归一化计算优势函数,无需单独训练 Critic 网络。降低计算成本,适配音频大模型的多输出评估。ASR、TTS 均适用
- DiffRO(可微分奖励优化):直接对 TTS 生成的声学 token 打分,通过 Gumbel-Softmax 采样实现梯度回传,无需合成完整音频即可优化。奖励函数:Token2Text 模型(类 ASR)训练一个Token2Text 模型(输入语音 token,输出文本概率分布),作为核心奖励器。以WER(词错误率) 为核心奖励信号:Token2Text 预测文本与目标文本的差异,转化为可微分奖励。解决 argmax 不可导问题:用Gumbel Softmax对 token 分布采样,实现端到端梯度回传。
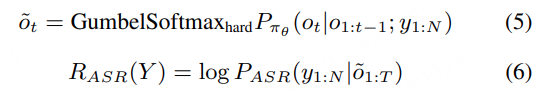
| 对比维度 | GRPO | DiffRO |
|---|---|---|
| 核心逻辑 | 组内对比打分,优化 “相对优势” | 单样本 token 级打分,优化 “绝对奖励” |
| 奖励来源 | 规则函数(如 WER、关键词准确率)或简单奖励模型 | 可微分模型(如 token 级 ASR) |
| 依赖数据 | 少量标注数据 + 硬样本(如 ASR 的 hallucination 样本) | 无需大量配对音频 – 文本数据 |
| 优势 | 适配主观体验优化(如韵律、多样性) | 发音准确率提升明显,训练稳定 |
| 劣势 | 训练步数过多易退化 | 难以优化主观体验指标 |
- 强化学习的训练框架 TRL 提供了简单的强化学习实现方案,但效率较低;它在训练和推理阶段均直接依赖 PyTorch,并采用手动资源管理方式。 相比之下,VeRL 和 OpenRLHF 等更先进的工业级框架利用 Ray 灵活的分布式计算原语,简化了分布式操作与部署流程。这些框架进一步集成了 VLLM、SGLang 等高效推演引擎用于响应生成,并采用搭载 ZeRO 策略的 Deepspeed/FSDP 进行策略优化。
轻量音频 RL 框架设计
音频领域 RL 的 3 大核心难题,这也是其技术方案的出发点:
- 模态复杂:音频大模型既要处理连续声学嵌入,又要生成离散文本 /token,比纯文本 LLM 的 RL 复杂得多;
- 框架笨重:传统 RL 框架(如 TRL)需要同时维护 Actor、Critic、Reward Model 等多个模块,GPU 资源冲突严重,训练效率低;
- 奖励难设计:ASR 的幻觉、TTS 的韵律自然度等痛点,没法用单一指标(如 WER)衡量,复杂奖励模型又难以训练。
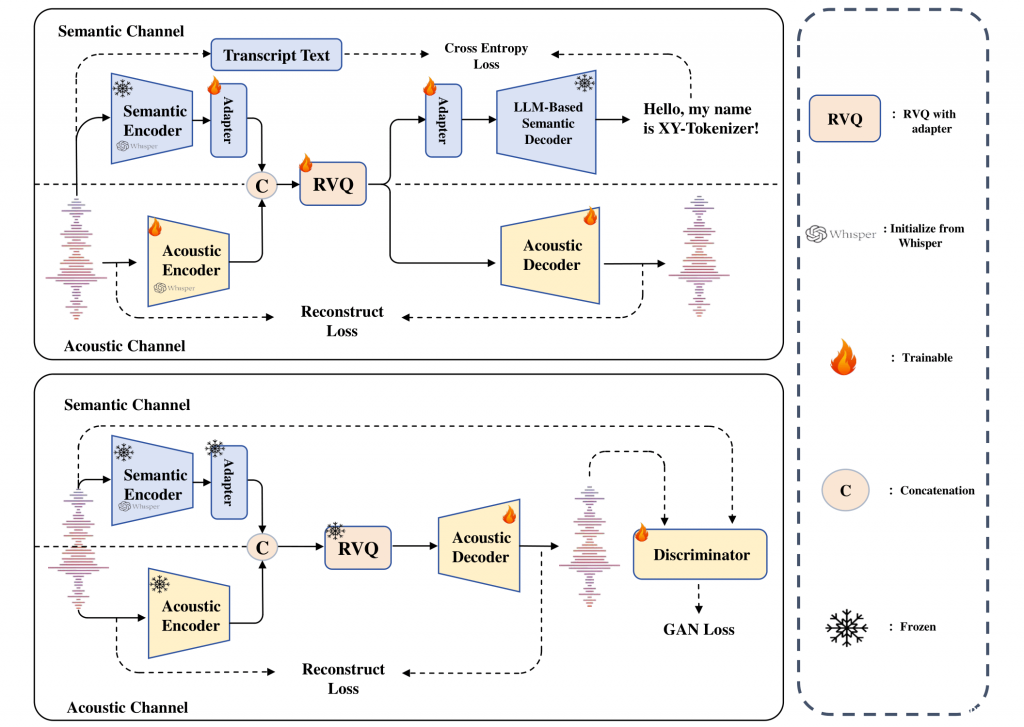
为了简化计算资源的管理,设计了一个强化学习(RL)训练框架,该框架可以交替地在不同的组件之间分配 GPU 资源。整个框架如图1 所示。
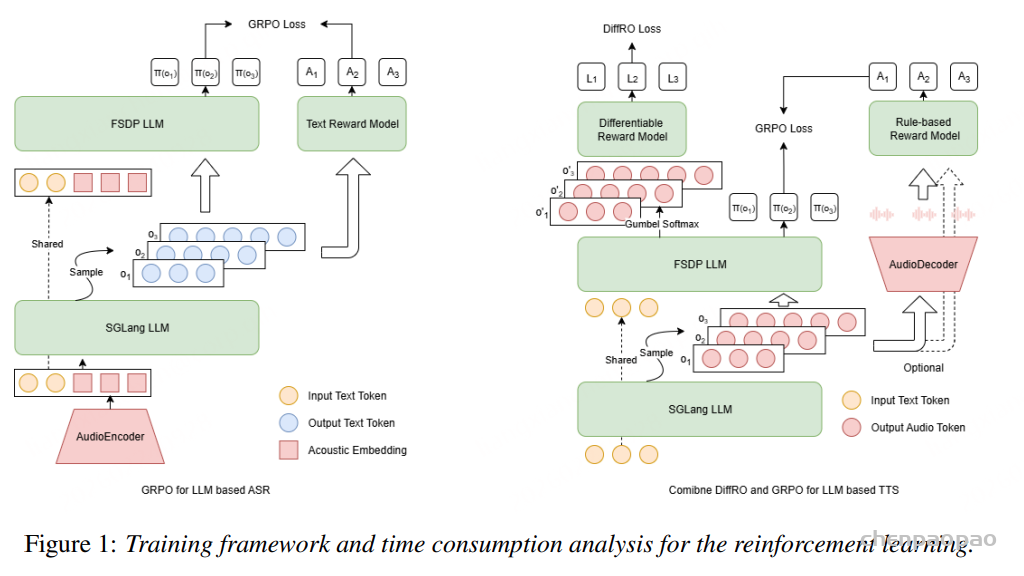
轻量音频 RL 框架 —— 交替调度 GPU,效率翻倍。核心思路是:按训练步骤交替分配 GPU 资源,避免多模块抢占,具体流程如下:
1)框架核心设计
| 训练阶段 | 占用 GPU 的模块 | 核心任务 | 资源释放逻辑 |
|---|---|---|---|
| 阶段 1:特征处理 | PyTorch-based 音频编码器(ASR)/ 解码器(TTS) | ASR:将音频转为嵌入;TTS:将文本转为声学 token | 处理完后释放 GPU,嵌入 /token 存入主存 |
| 阶段 2:生成候选输出 | SGLang-based LLM 生成引擎 | 基于特征生成多组候选(ASR 生成文本,TTS 生成声学 token) | 生成完成后释放 GPU |
| 阶段 3:奖励计算 | PyTorch-based 奖励模型 / 规则函数 | 对候选输出打分(如 ASR 的 WER、TTS 的 ASR 准确率) | 打分完成后释放 GPU |
| 阶段 4:策略优化 | FSDP-based LLM 策略模型 | 用 GRPO/DiffRO 更新模型参数,同步回生成引擎 | 一轮更新后进入下循环 |
(2)关键优势
- 效率高:8 张 A100 GPU 上,ASR 单步训练仅需 54.6 秒,TTS 仅 16.73 秒,远超 VeRL 等开源框架;
- 通用性强:一套框架适配 ASR 和 TTS,无需为不同任务单独搭建;
- 资源省:避免多模块同时占用 GPU,显存消耗降低 30% 以上。
ASR 的 RL 优化 —— GRPO + 规则奖励
ASR 的核心痛点是 “基础准确率(WER)达标,但幻觉、关键词漏检影响实际使用”,因此奖励函数聚焦 “准确率 + 抗幻觉 + 关键词保障” 三大目标,采用 “基础奖励 + 惩罚性奖励 + 强化奖励” 的组合逻辑:
(1)奖励函数设计:3 条规则,精准打击幻觉与关键词漏检
基础奖励 R1:ASR 识别准确率(核心基础)
- 设计逻辑:以 “词错误率(WER)” 为核心指标,奖励与准确率正相关,确保模型优先优化基础识别能力。
- 计算公式:1 − WER(y∗, y), 其中 y∗:音频对应的真实标注文本,y:ASR 模型的输出文本,WER:词错误率(插入、删除、替换错误的综合指标,范围 0~1)。
- 数值范围:0~1(WER=0 时R1=1,完全错误时R1=0)。
- 核心作用:保证 RL 训练不偏离 “提升基础识别准确率” 的核心目标,避免为了优化其他指标而牺牲 WER。
- 惩罚性奖励 R2:幻觉检测(优先级最高)
- 设计逻辑:ASR 的幻觉(无中生有、重复生成、翻译错误)对用户体验伤害极大,因此采用 “一票否决” 式惩罚,检测到幻觉直接将奖励设为 – 1,强制模型规避该行为。
- 幻觉判定规则:
- 无中生有:生成文本中包含音频中不存在的词(如音频说 “苹果”,ASR 输出 “苹果手机”);
- 重复生成:连续重复相同短语(如 “今天今天今天天气好”);
- 翻译错误:将一种语言误译为另一种(如英文音频被识别为中文)。
- 奖励逻辑:若检测到上述任意一种幻觉 →R2 = -1 ;无幻觉 →R2 = 0 (不额外加分,仅避免惩罚)。
- 核心作用:针对性解决长音频、噪声环境下的 ASR 幻觉问题,实验中长音频插入错误率(Ins)从 2.72 降至 0.86。
- 强化奖励R3 :关键词准确率与召回率(工业场景关键)
- 设计逻辑:人名、品牌名、专业术语等关键词的识别准确率,直接影响 ASR 的工业实用性(如智能客服、语音助手),因此单独强化该维度。
- 数值范围:0~1(关键词完全命中时R3 = 1 ,完全漏检 / 误检时 R3 = 0)。
- 核心作用:保证基础准确率的同时,重点强化关键信息的识别能力,提升模型的工业落地价值。
- ASR 最终奖励聚合
- 聚合逻辑:惩罚性奖励优先级最高,其次是基础奖励和强化奖励的加权求和(论文未明确权重,实验中采用等权求和)。
- 最终公式:1) 若存在幻觉 → RASR = R2 = -1;2) 无幻觉 → RASR = (R1+R3) / 2 (范围 0~1)。
- 设计巧思:通过 “惩罚优先” 避免模型 “为了加分而牺牲关键词 / 抗幻觉”,平衡基础性能与工业需求。
(2)训练数据构建:专挑 “硬骨头”,少而精 RL 训练不用海量数据,重点在于 “针对性”。论文构建了 4 类训练集,每类 2 万条,精准命中 ASR 的失败模式:
| 数据集 | 数据来源 | 训练目标 |
|---|---|---|
| D0:随机样本 | 普通语音数据 | 作为对照,保证基础性能 |
| D1:难样本 | 不同 ASR 系统输出不一致的音频(如歧义句、噪声环境) | 提升复杂场景鲁棒性 |
| D2:长音频样本 | 时长 > 20 秒的音频 | 解决长语音的幻觉、漏检问题 |
| D3:关键词样本 | 含人名、品牌名、专业术语的音频 | 强化关键词识别能力 |
(3)训练配置与实验结果
- 核心参数:batch size=32,组大小 G=12,学习率 = 1e-5,KL 系数 = 0.1,训练 1 天即可收敛;
- 评估指标:WER(词错误率)、Ins(插入错误率)、Del(删除错误率);
- 关键结果:
- 短音频(<10 秒):最优配置(全奖励 + 全数据集)WER 从 10.25 降至 9.71,相对下降 5.3%;
- 长音频(>20 秒):Ins 错误率从 2.72 降至 0.86,幻觉问题大幅缓解;
- 结论:硬样本 + 关键词奖励是提升 ASR 性能的关键,单纯增加长音频样本效果有限。
TTS 的 RL 优化 —— GRPO+DiffRO 融合,发音与自然度双提升
TTS 的核心痛点是 “发音准确率与自然度失衡”(如 DiffRO 提升发音但牺牲语速,GRPO 优化自然度但易发音不准),因此奖励函数聚焦 “发音准确率 + 语速控制 + 韵律多样性”,覆盖客观指标与主观体验:
(1)单一算法对比:各有优劣
先分别用 GRPO 和 DiffRO 做实验,结果如下:
| 方法 | 核心优势 | 核心劣势 | 中文 WER | 中文 SS(说话人相似度) |
|---|---|---|---|---|
| 基线(无 RL) | – | – | 4.280 | 77.64 |
| DiffRO | 发音最准(WER 最低) | SS 下降最多(77.00) | 3.418 | 77.00 |
| GRPO | SS 下降少(77.26) | 发音提升有限 | 3.710 | 77.26 |
(2)GRPO 的奖励扩展:3 条规则,兼顾准确率与自然度
- 核心奖励 R1:ASR 识别准确率(保证发音准确)
- 设计逻辑:TTS 合成音频的 “可懂性” 是基础,通过 ASR 模型反向验证发音准确率,ASR 能准确识别的音频,说明发音无明显错误。
- 两种计算方式(适配不同场景):
- 方式 1(音频级):用标准 ASR 模型识别 TTS 合成的完整音频,计算识别准确率(同 ASR 的R1);
- 方式 2(token 级):直接用 DiffRO 的 token-based ASR 模型,对 TTS 生成的声学 token 打分,无需合成完整音频(效率更高)。
- 数值范围:0~1(ASR 完全识别正确时R1=1,完全无法识别时 R1= 0)。
- 核心作用:锚定 TTS 的发音准确性,避免 RL 优化过程中出现 “自然但听不懂” 的问题。
- 约束奖励 R2:音频时长控制(防止语速变慢)
- 设计逻辑:论文发现 “TTS 为提升 ASR 识别率,会主动放慢语速”,导致语音不自然,因此通过时长约束强制模型保持合理语速。
- 计算公式:
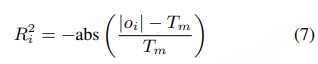
- 其中|oi|:第 i 个 TTS 候选输出的音频时长;Tm同组候选输出的音频时长中位数;abs:绝对值函数。
- 数值范围:-1~0(时长与中位数完全一致时=0,偏差越大越接近 – 1)。
- 核心作用:惩罚语速过快 / 过慢的输出,实验中成功避免 TTS “为准确率牺牲语速”,说话人相似度(SS)也同步提升。
- 增强奖励 R3:token 与音调多样性(提升韵律自然度)
- 设计逻辑:TTS 的 “机械感” 源于韵律单一,因此奖励模型生成多样化的声学 token 和音调变化,模拟人类自然 speech 的韵律波动。
- 计算公式(双维度加权求和):
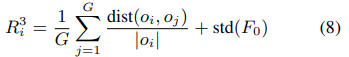
- 第一部分(token 多样性):
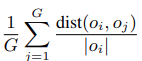
- 其中G:GRPO 的组大小(实验中 G=8),:第 i 个与第 j 个候选输出的声学 token 编辑距离;dist(oi,oj):第 i 个候选的 token 长度;组内候选的 token 差异越大,得分越高。
- 第二部分(音调多样性):std(F0),其中F0:归一化后的基频(音调);std:标准差函数;音调波动越大(标准差越高),韵律越丰富,得分越高。
- 数值范围:0~+∞(无上限,多样性越高得分越高)。
- 核心作用:提升 TTS 的主观自然度,实验中该奖励虽未优化客观 WER,但人类主观评估中 “韵律自然度” 得分最高。
- TTS 最终奖励聚合
- 聚合逻辑:核心奖励(R1)保证基础发音,约束奖励(R2)控制语速,增强奖励(R3)优化韵律,三者加权求和(论文实验中采用等权)。
- 最终公式:Rtts = R1+R2+R3
- 设计巧思:通过 “核心 + 约束 + 增强” 的组合,平衡客观准确率与主观体验,为 GRPO 与 DiffRO 的融合奠定基础。
实验验证
训练效率:新框架碾压开源方案
在 8 张 A100 GPU 上,论文提出的交替调度框架,训练速度远超基于 VeRL 的开源方案:
- ASR 单步训练时间:54.6 秒(RTF=0.015),是开源方案的 2.3 倍快;
- TTS 单步训练时间:16.73 秒(batch size=128),是开源方案的 1.8 倍快;
- 关键原因:避免了多模块 GPU 资源冲突,SGLang 和 FSDP 的并行优化大幅提升效率。
ASR 关键结论
- 奖励设计比数据量更重要:仅用R1(WER)效果有限,加入R2(幻觉惩罚)和R3(关键词奖励)后,性能大幅提升;
- 长音频训练需针对性数据:单纯增加长音频样本(D2)无法解决幻觉,需结合困难样本(D1)和关键词样本(D3);
- 工业场景优先选 “全奖励 + 全数据集” 配置,WER 和抗幻觉能力均最优。
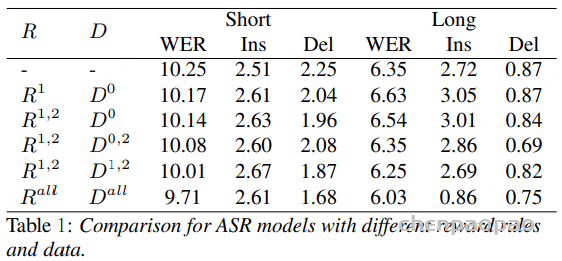
TTS 关键结论
- 发音准确率:DiffRO > 融合方案 > GRPO > 基线;
- 说话人相似度:GRPO > 融合方案 > 基线 > DiffRO;
- 稳定性:DiffRO > 融合方案 > GRPO;
- 落地推荐:优先选择 “样本过滤 +R1+R2” 融合方案,兼顾准确率、自然度和稳定性。
研究价值与未来展望
核心价值
- 技术层面:首次提出适配音频大模型的轻量 RL 框架,解决了模态复杂、资源冲突的核心难题;同时探索了 GRPO 与 DiffRO 的融合方案,为 TTS 的 “准确率 + 自然度” 双优化提供了可落地的范式;
- 工业层面:规则型奖励 + 困难样本训练的思路,无需标注海量偏好数据,降低了 RL 在 ASR/TTS 中的落地成本;实验结果可直接复用,加速工业产品迭代。
未来展望
- 多语言扩展:当前实验主要基于中英双语,未来可扩展至低资源语言,优化小语种 ASR/TTS 的性能;
- 奖励模型融合:将规则奖励与训练后的奖励模型结合,进一步提升奖励的精准度;
- 多模态扩展:将框架适配到语音翻译、语音情感合成等更复杂的音频任务;
- 轻量化部署:在保证性能的前提下,优化框架的显存占用,适配边缘设备训练。
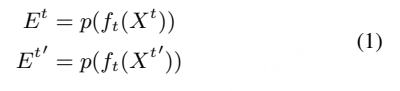

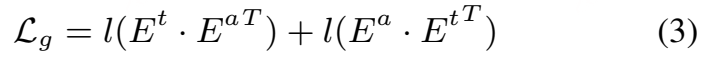
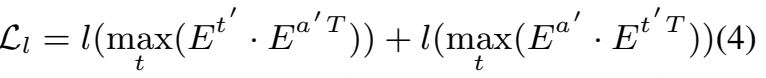






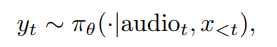
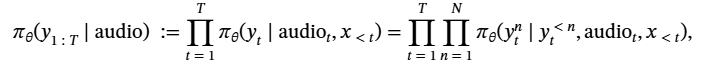
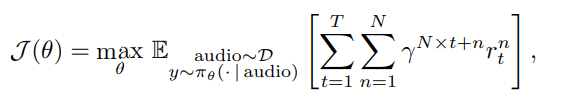
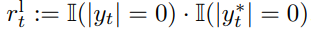
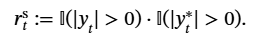
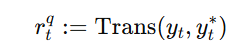
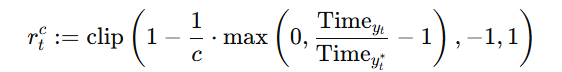
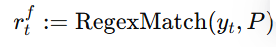
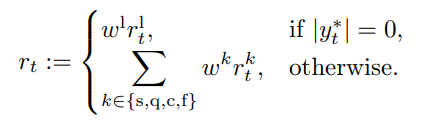
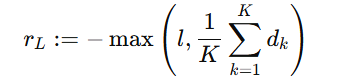
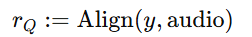
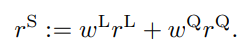
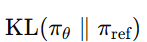
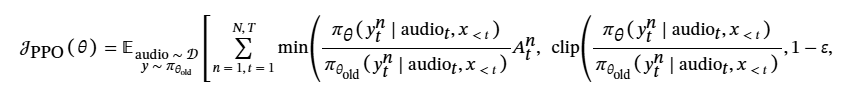
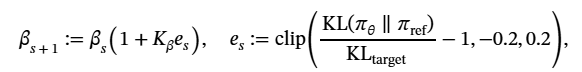
{kind=link}