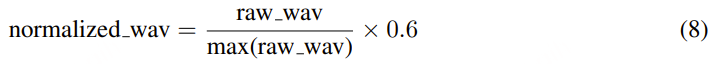- 流式TTS:https://kyutai.org/next/tts
- 流式STT:https://kyutai.org/next/stt
- STT+LLM+TTS demo:https://unmute.sh/
- https://kyutai.org/next/unmute
- Github:https://github.com/kyutai-labs/delayed-streams-modeling
- 论文:paper is coming soon
关于Kyutai:Kyutai 是一家位于法国巴黎的非营利性人工智能研究实验室,成立于 2023 年 11 月。该实验室致力于推动人工智能的开放研究,特别关注多模态大模型的开发与创新算法的研究,旨在提升 AI 的能力、可靠性和效率,并促进其民主化。
延迟流建模 (DSM) :一种用于解决多种流式 X 到 Y 任务的技术(其中 X 和 Y 可以是语音或文本),它将我们在 Moshi 和 Hibiki 中采用的方法形式化了。
Kyutai STT
Kyutai STT 是一种流式语音转文本模型架构,在延迟与准确率之间实现了无与伦比的平衡,非常适合交互式应用。它支持批处理,可在单个 GPU 上处理数百条并发对话。发布了两个模型:
- kyutai/stt-1b-en_fr:一个低延迟模型,支持英语和法语,并内置语义级语音活动检测器。
- kyutai/stt-2.6b-en:一个更大的仅支持英语的模型,经过优化以实现尽可能高的准确率。
Streaming and accurate: 在英文测评集上的WER指标
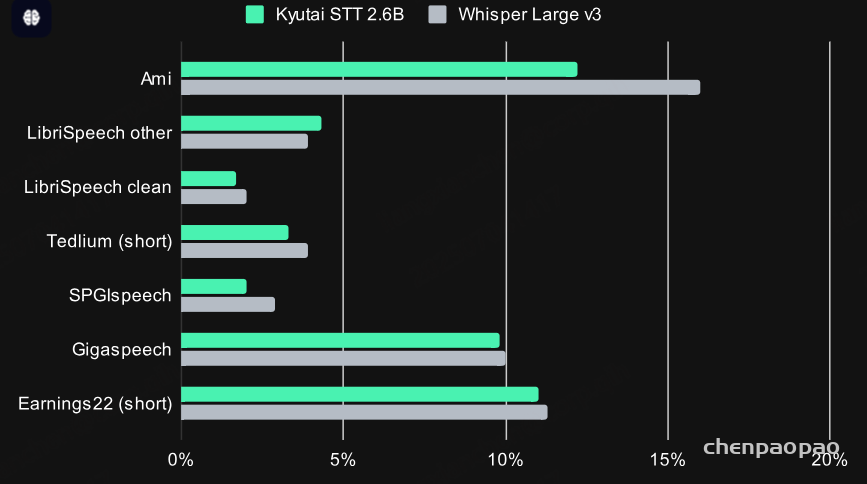
Kyutai STT 是一个流式模型,这意味着它在接收音频的同时实时转录,而不是假设音频在开始处理前已全部可用。这使其非常适合诸如 Unmute [Make any LLM listen and speak using Kyutai’s speech-to-text and text-to-speech.] 之类的实时应用。
它输出格式良好的转录文本,包含标点符号,同时还提供词级时间戳。
在准确性方面,它的表现仍可与那些能够一次性访问完整音频的最先进非流式模型相媲美。
语义语音活动检测器
对于像 Unmute [Make any LLM listen and speak using Kyutai’s speech-to-text and text-to-speech.] 这样基于串联式语音对话的应用程序,需要一种方式来判断用户是否已经说完,以便生成回应。最常见的方法是使用一个独立的语音活动检测(VAD)模型,判断用户是否在说话,并在用户说完之后等待一个固定的时间。但在实际应用中,不可能找到一个适用于所有情况的等待时间。人们在说话时经常会出现长时间停顿,这会导致这种朴素方法出现误判。
为了解决这个问题,Kyutai STT 不仅预测文本,还预测用户是否已经说完话的概率。对于停顿的判断延迟会根据用户说话的内容和语调自适应调整。
低延迟
kyutai/stt-1b-en_fr 的延迟设定为 500 毫秒,也就是说,每个词会在说出后约 500 毫秒被转录。而 kyutai/stt-2.6b-en 的延迟为 2.5 秒。
在 Unmute [Make any LLM listen and speak using Kyutai’s speech-to-text and text-to-speech.]中,我们使用一种称为 “flush trick”(刷新技巧)的方法来进一步降低响应延迟。当语音活动检测器预测用户已经说完时,我们还需再等 500 毫秒(即 STT 模型的延迟),以确保不会截断转录的结尾部分。
为了减少这段延迟,我们利用了语音转文本服务器“比实时更快”的处理能力。当检测到说话结束时,我们请求 STT 服务器尽可能快地处理此前已发送的音频。服务器的运行速度约为实时的 4 倍,因此可以在大约 125 毫秒内处理这段 500 毫秒的音频(即 500ms ÷ 4 = 125ms)。通过这种方式,我们“扭曲时间”,只需等待这 125 毫秒,即可确保所有内容已被转录。
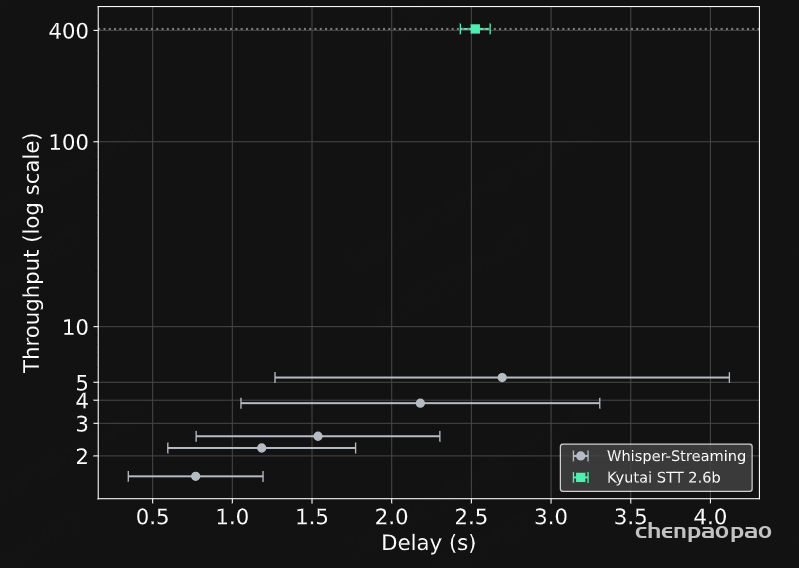
高吞吐量
Kyutai STT 非常适合在生产环境中部署:在一块 H100 GPU 上,它可以同时转录 400 路实时音频流。这得益于其采用的延迟流建模架构(见下文),该架构允许我们在无需任何额外“粘合代码”的情况下,以大批量运行模型,并实现流式处理。
相比之下,将 Whisper 改造成流式模型需要一个完全独立的研究项目——Whisper-Streaming。该系统会反复在最近几秒的音频上运行 Whisper,并将重叠的转录结果拼接在一起。
Whisper-Streaming 在技术上令人印象深刻,但它不支持批处理,这导致吞吐量大大降低。若目标延迟更低,其吞吐量会进一步下降,因为需要更频繁地重新运行 Whisper。
延迟流建模
Kyutai STT 的主要创新是一种在 Kyutai 开发的技术,称为延迟流建模(delayed streams modeling),最早在 Moshi 项目中率先使用了这一方法。
传统的语音转文本方法通常是将整段音频一次性输入模型,并由模型逐步(自回归地)生成文本。例如,Whisper 就是这样做的,它使用的是编码器-解码器结构的 Transformer 模型。

在 Kyutai STT 中,将数据表示为时间对齐的文本流和音频流。本质上,音频和文本是“并列”存在的,而不是一个接着另一个。文本流会进行填充,以确保文本的时间与音频对齐。只是将文本流延迟了几个帧,以便语音转文本模型能够进行一定程度的前瞻。
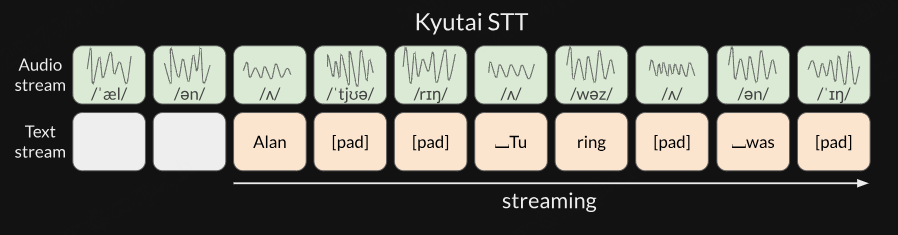
使用这种表示方式的文本-音频数据来训练 Kyutai STT,教它同时建模音频流和文本流。在推理阶段,我们保持音频流固定,实时输入接收到的音频,利用模型预测文本流。
这种方法的另一个巧妙之处在于其对称性。我们可以通过延迟音频流而非文本流,并保持文本固定(教师强制),来实现文本到语音的转换,进而预测音频。为使模型能够预测填充符号以对齐文本流和音频流的时间,需要一些技巧。
Kyutai TTS
Kyutai 文本到语音(TTS)最初是我们在 Moshi 开发过程中使用的内部工具。作为我们对开放科学的承诺的一部分,我们现在向公众发布了改进版的 TTS:kyutai/tts-1.6b-en_fr,一个拥有 16 亿参数的模型。该模型包含多项创新,使其特别适合实时使用。
State of the art
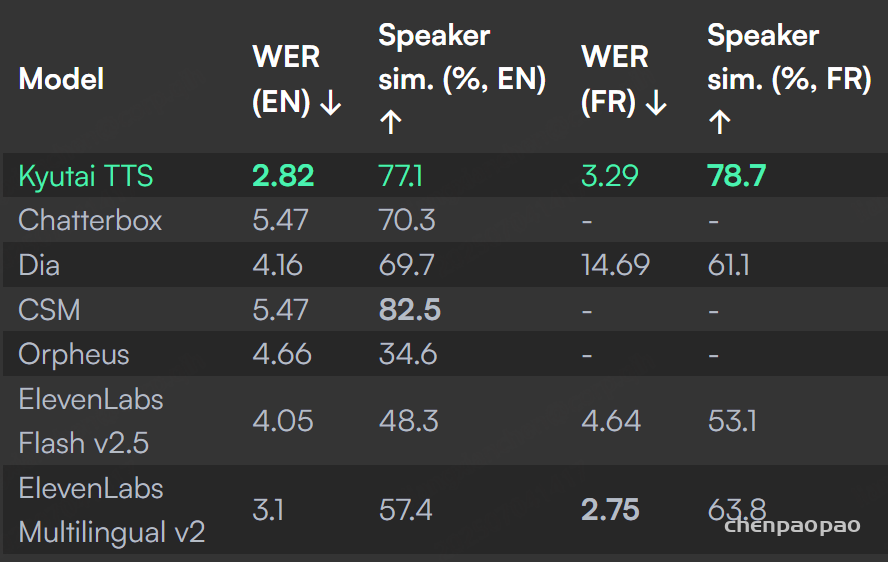
Kyutai TTS 在文本到语音领域树立了新的技术水平。词错误率(WER)衡量 TTS 未能准确遵循文本脚本的频率。说话人相似度则是评估在语音克隆时生成音频与原始样本声音相似程度的指标。我们在 NTREX 数据集中,选取了 15 篇英文和 15 篇法文新闻文章,对 Kyutai TTS 与其他模型进行了对比。除 Kyutai TTS 和 ElevenLabs 外,所有模型均按句子逐句生成,因为我们观察到这样能获得最佳效果。
适合大语言模型(LLM)
Kyutai TTS 无需提前获取完整文本,从接收到第一个文本标记到生成第一段音频的延迟为 220 毫秒。在 Unmute.sh 部署环境中,我们通过批处理同时处理最多 32 个请求,使用 L40S GPU 测得的延迟约为 350 毫秒。
其他被描述为流式的 TTS 模型仅在音频上实现流式处理,仍然需要提前知道完整文本。
Kyutai TTS 是首个同时支持文本流式处理的文本到语音模型。你可以边由大语言模型生成文本边输入,Kyutai TTS 会即时开始处理,从而实现超低延迟。这在大语言模型生成耗时较长的情况下尤为有用,比如资源受限环境或生成长文本段落时。
文本流式处理得益于下文详细介绍的延迟流建模技术。
语音克隆
为了指定语音,我们使用一段 10 秒的音频样本。TTS 能够匹配源音频的声音、语调、说话习惯和录音质量。
长时段生成
大多数基于 Transformer 的 TTS 模型针对生成少于 30 秒的音频进行了优化,通常不支持更长时间的生成,或者在处理较长音频时表现不佳。Kyutai TTS 在生成更长时段音频方面没有任何问题。
词级时间戳
除了音频本身,Kyutai TTS 还会输出生成词语的精确时间戳。这对于为 TTS 提供实时字幕非常有用。
延迟流建模
Kyutai TTS 独特的能力,如文本流式处理、批处理和时间戳功能,均得益于 Kyutai 开发的一项技术——延迟流建模,该技术最早由我们在 Moshi 项目中开创。
传统使用语言模型进行文本到语音转换的方法,是基于输入文本与音频的分词输出拼接在一起进行训练:

这意味着这些模型是流式的,但仅限于音频:在已知完整文本的情况下,它们开始生成音频,并允许你在生成过程中访问部分结果。然而,完整文本仍需提前获知。
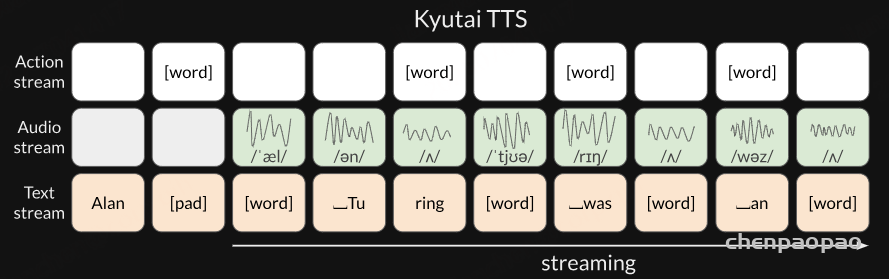
而在 Kyutai TTS 中,我们将问题建模为时间对齐的文本流和音频流。本质上,音频和文本是“并列”存在的,而不是一个接着另一个。我们只是将音频流延迟了几个帧,以便文本到语音模型能够进行一定程度的前瞻:
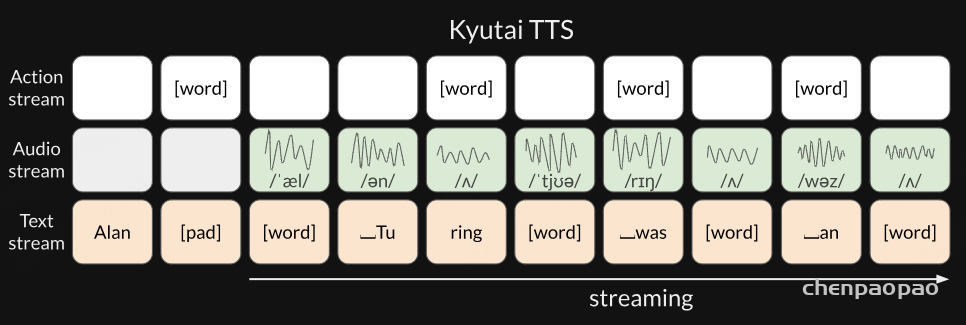
这意味着一旦知道了前几个文本标记,无论最终文本多长,我们都可以开始流式输出音频。
在输入端,我们接收到一个没有时间信息的词语流,但模型需要使用填充符使文本流与音频对齐。这就是动作流(action stream)的作用:当它预测到 [word] 时,表示“我已完成当前词的发音,请给我下一个词”,此时我们将下一个词输入到文本流中。