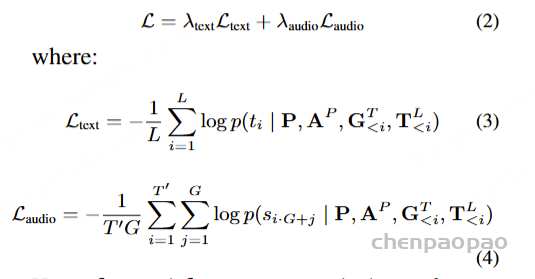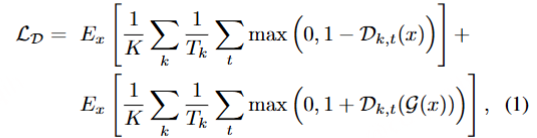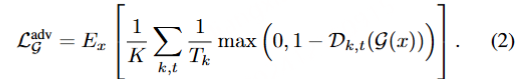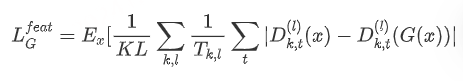# 1️⃣ Install dependencies silently
!git lfs install
!git clone https://huggingface.co/hexgrad/Kokoro-82M
%cd Kokoro-82M
!apt-get -qq -y install espeak-ng > /dev/null 2>&1
!pip install -q phonemizer torch transformers scipy munch
# 2️⃣ Build the model and load the default voicepack
from models import build_model
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
MODEL = build_model('kokoro-v0_19.pth', device)
VOICE_NAME = [
'af', # Default voice is a 50-50 mix of Bella & Sarah
'af_bella', 'af_sarah', 'am_adam', 'am_michael',
'bf_emma', 'bf_isabella', 'bm_george', 'bm_lewis',
'af_nicole', 'af_sky',
][0]
VOICEPACK = torch.load(f'voices/{VOICE_NAME}.pt', weights_only=True).to(device)
print(f'Loaded voice: {VOICE_NAME}')
# 3️⃣ Call generate, which returns 24khz audio and the phonemes used
from kokoro import generate
text = "How could I know? It's an unanswerable question. Like asking an unborn child if they'll lead a good life. They haven't even been born."
audio, out_ps = generate(MODEL, text, VOICEPACK, lang=VOICE_NAME[0])
# Language is determined by the first letter of the VOICE_NAME:
# 'a' => American English => en-us
# 'b' => British English => en-gb
# 4️⃣ Display the 24khz audio and print the output phonemes
from IPython.display import display, Audio
display(Audio(data=audio, rate=24000, autoplay=True))
print(out_ps)
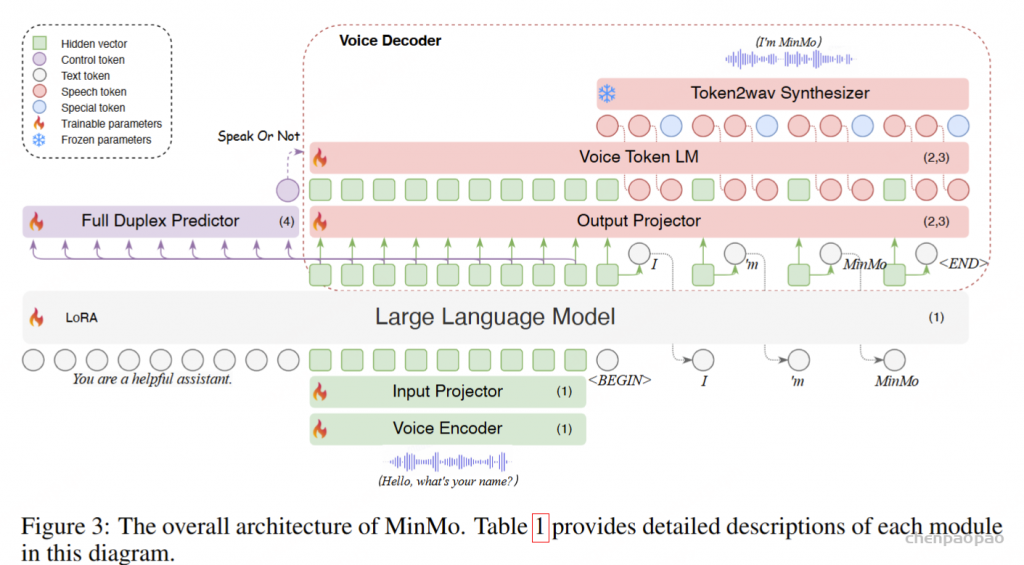
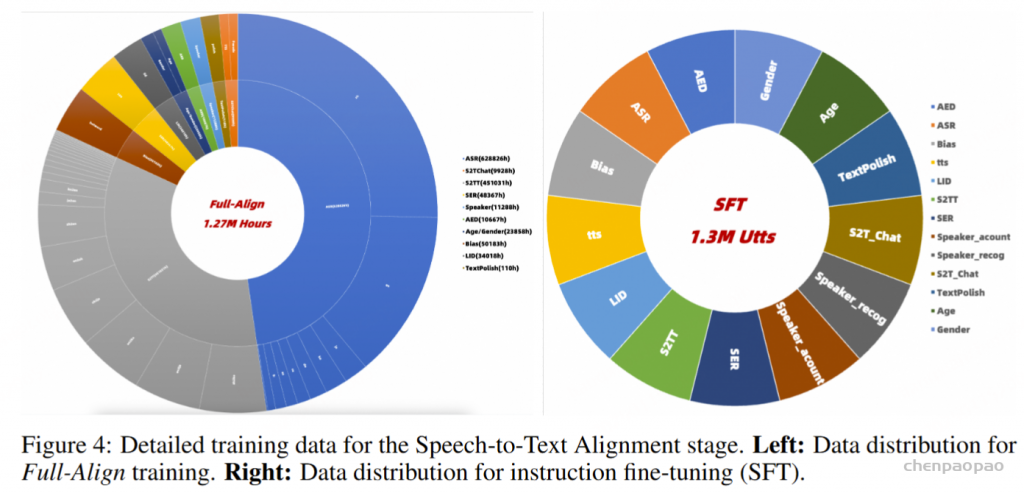
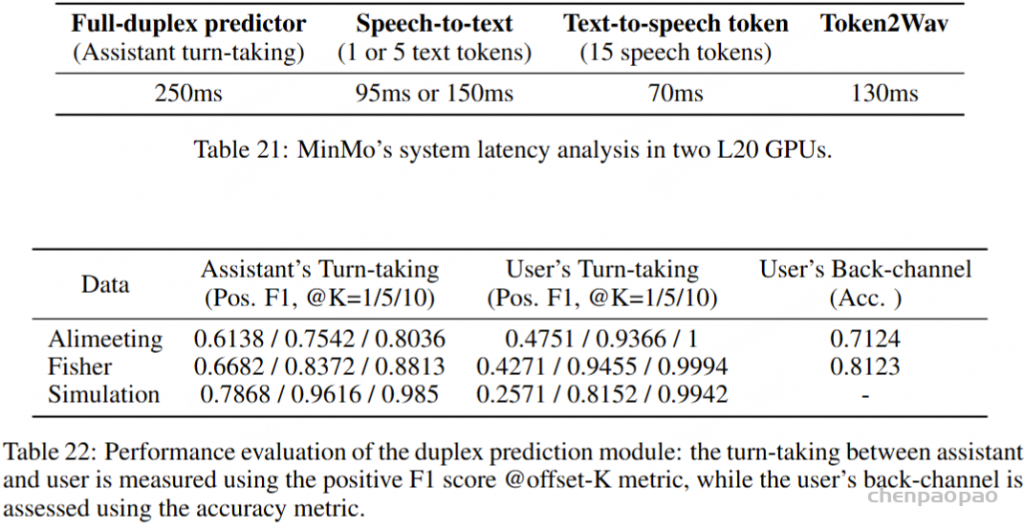
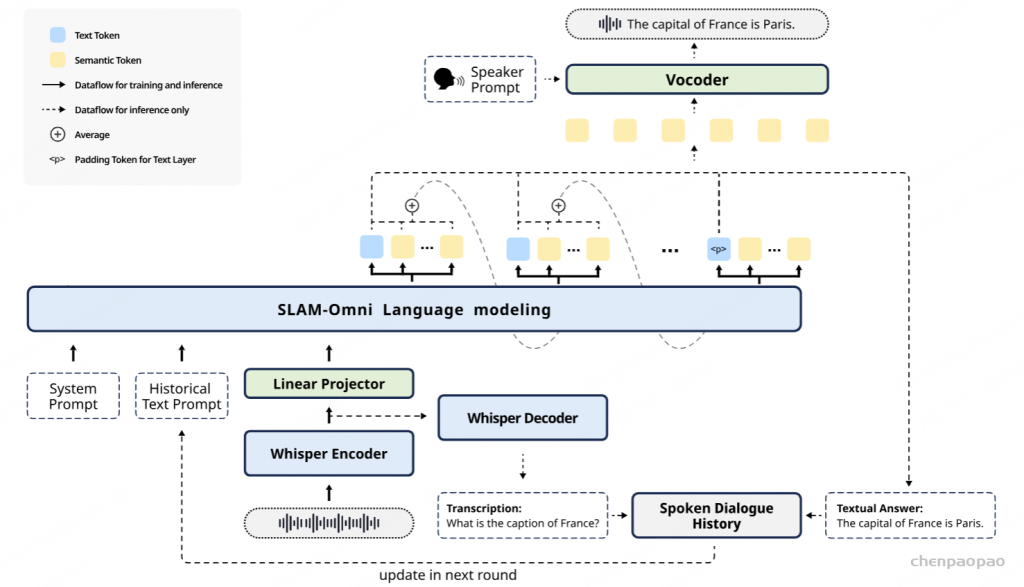
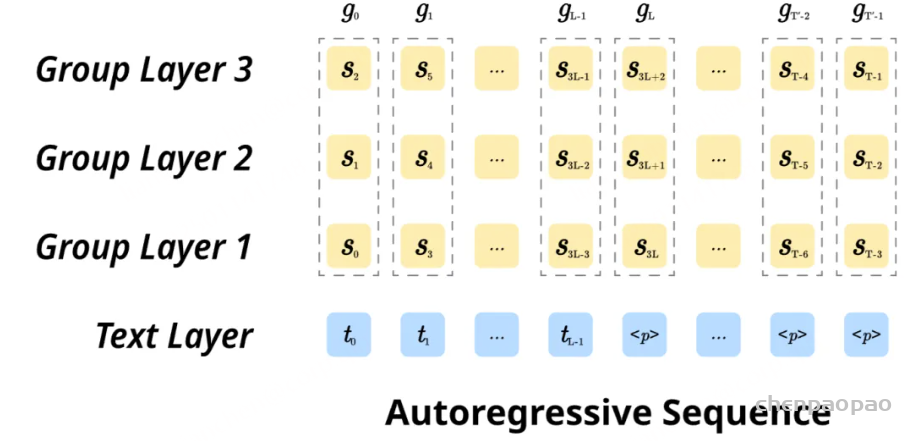
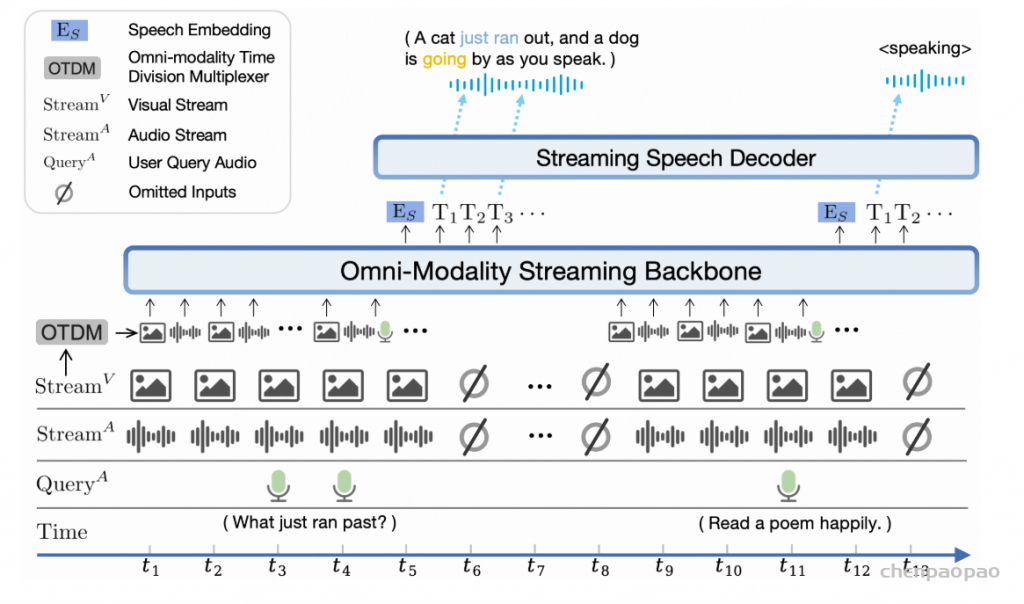
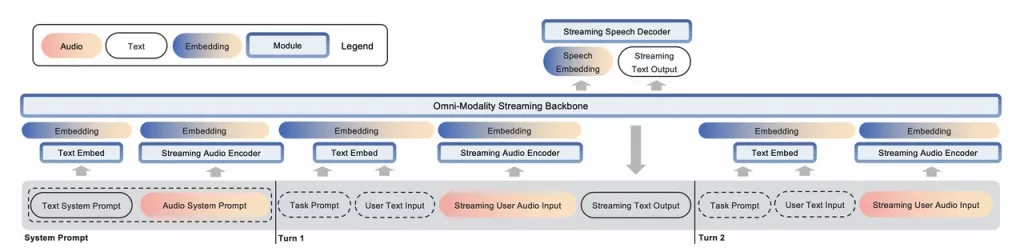
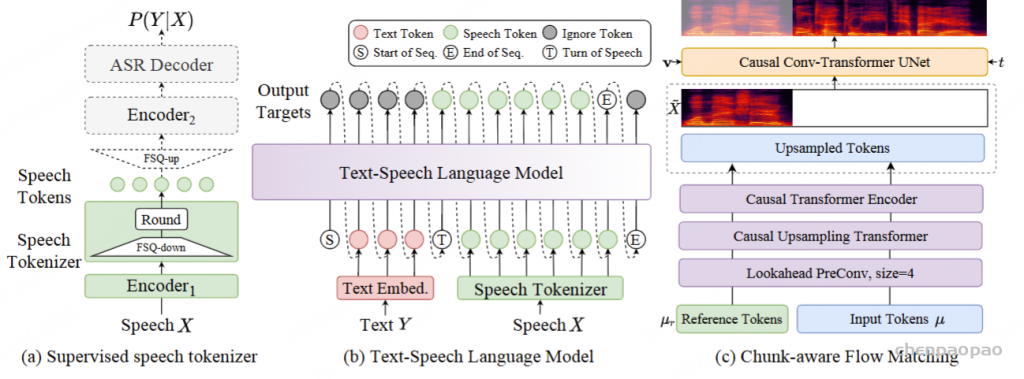
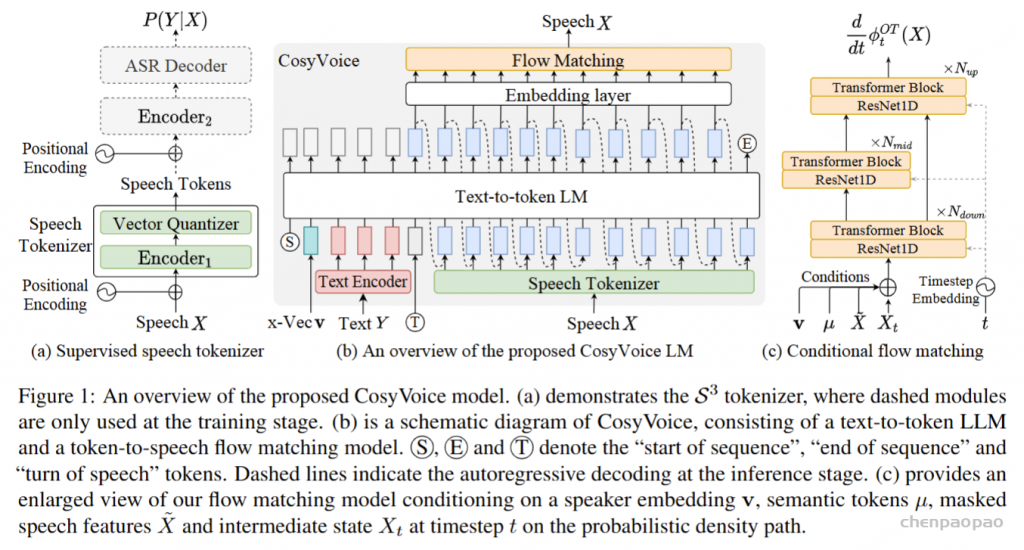
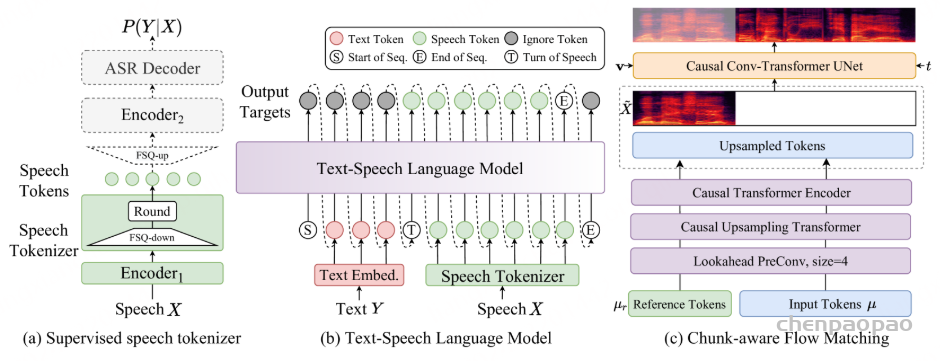
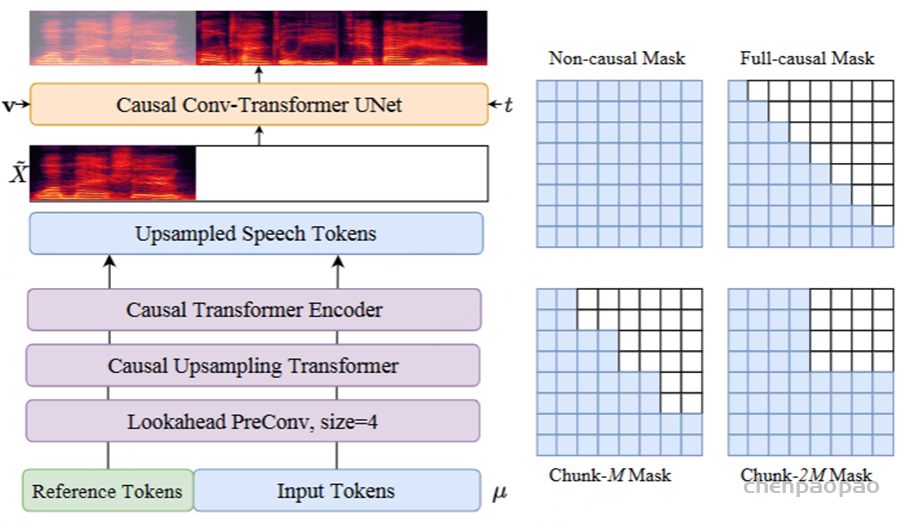
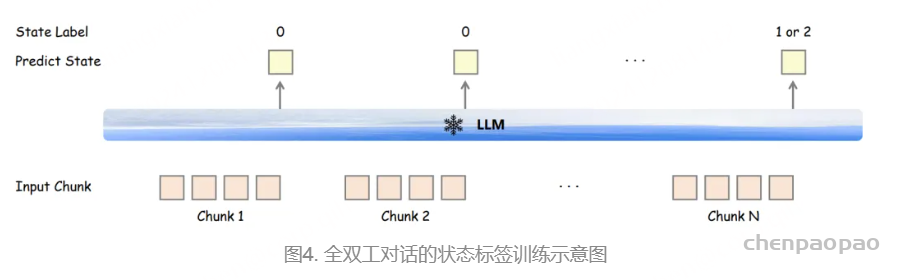
在训练过程中,采用教师强制策略,并引入一个特殊标记,用于指示下一个语义向量应被连接。当 LLM 的文本响应完成且语义向量耗尽时,我们插入一个“语音轮次”(turn of speech)标记,提示语音标记语言模型接下来的标记应完全为语音标记。当生成“语音结束”(end of speech)标记时,语音合成过程结束。
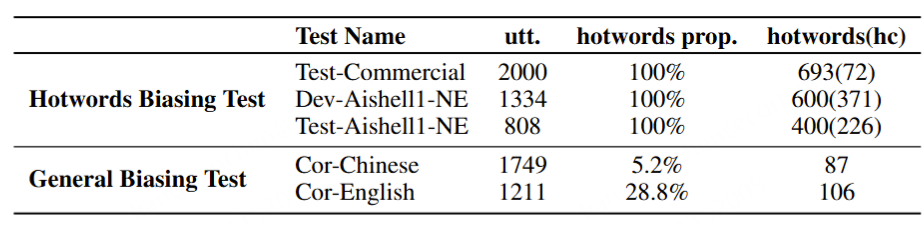
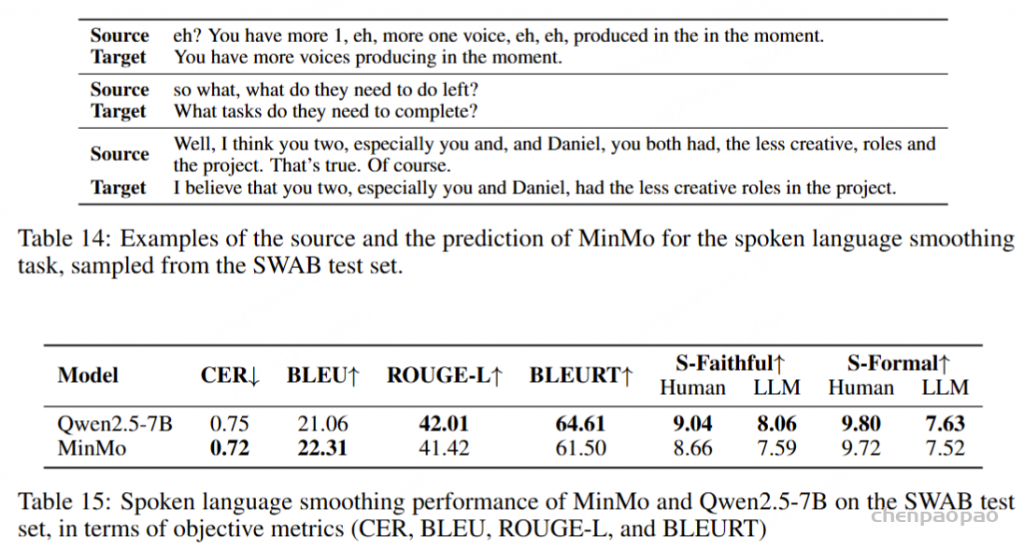
口语语言平滑任务以口语ASR(自动语音识别)转录文本为输入,输出正式风格的书面文本。表14展示了口语语言平滑的一些示例。为该任务,我们通过扩展为ASR转录文本的口语到书面转换而创建的SWAB数据集(Liu et al., 2025),构建了一个多领域数据集用于训练和评估。SWAB数据集源自中文和英文的会议、播客及讲座。
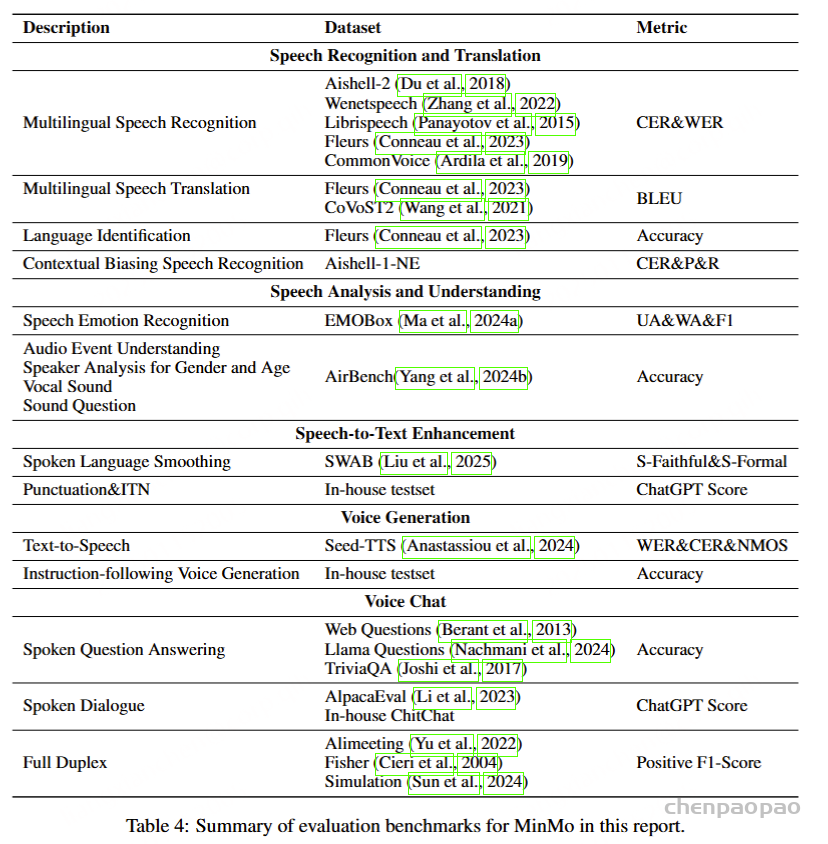
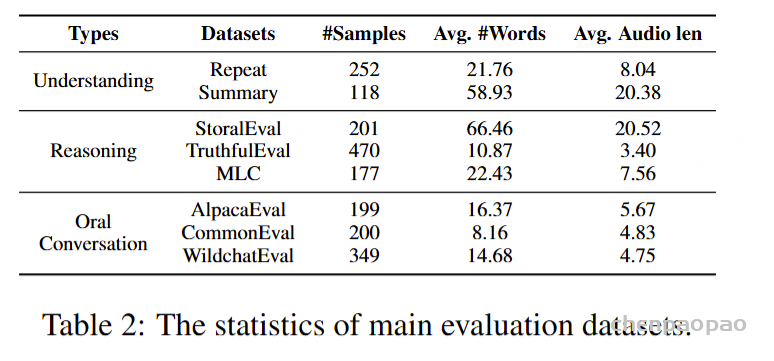
在客观指标评估中,我们使用BLEU(Papineni et al., 2002)、ROUGE(Lin, 2004)和BLEURT(Sellam et al., 2020),以人工目标为参考。然而,我们注意到口语语言平滑任务具有显著的主观性和多样性,因此基于词汇匹配的客观指标可能无法充分反映模型性能。因此,我们采用人工和LLM注释来提供信实性(S-Faithful,即对原始内容的信实性)和正式性(S-Formal)的排名评估。自动化LLM评分的提示见附录A.1。
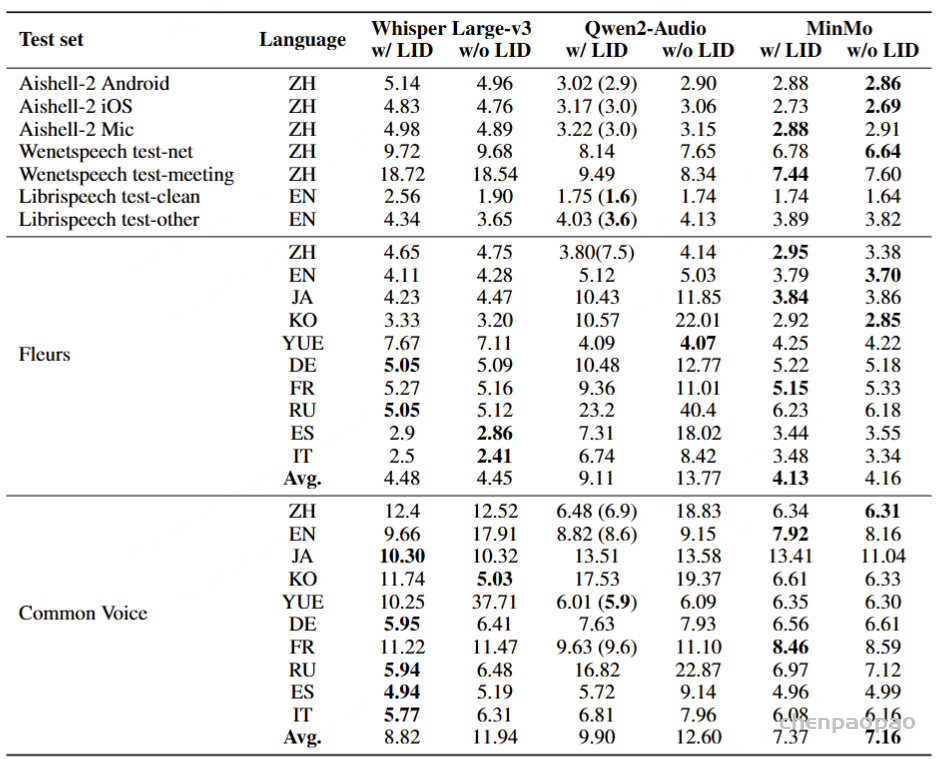
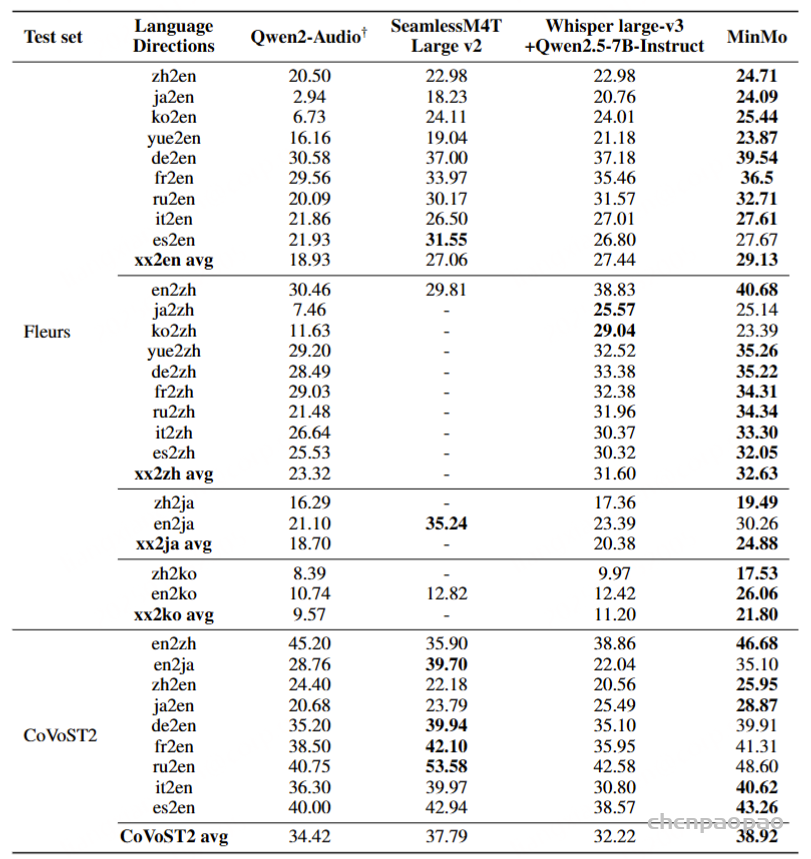
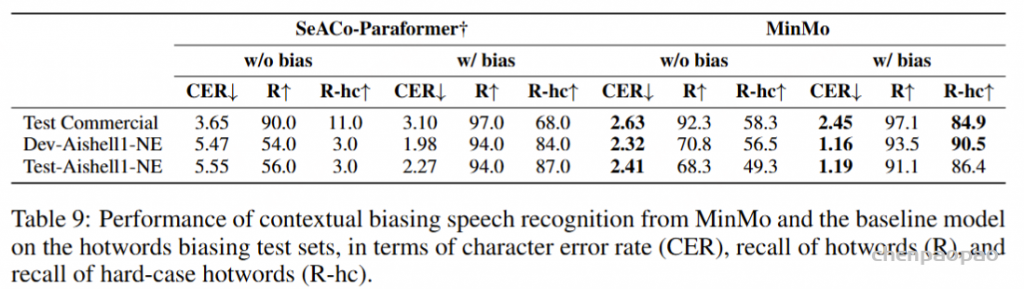
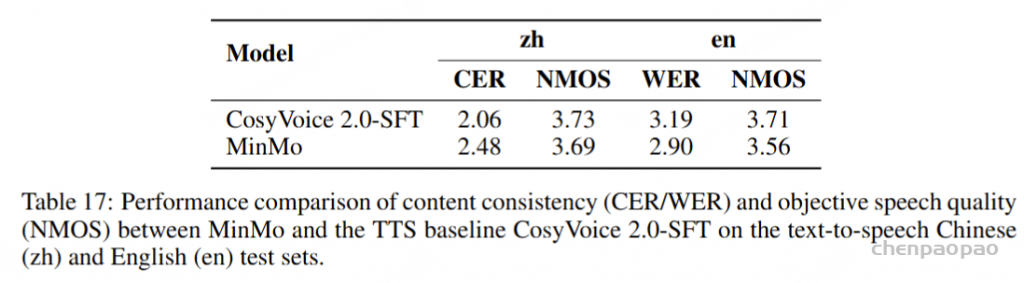
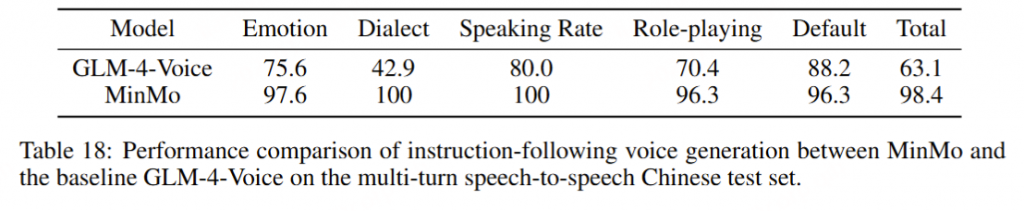
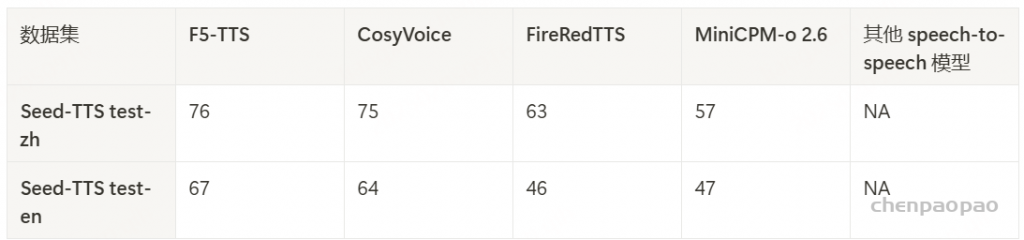
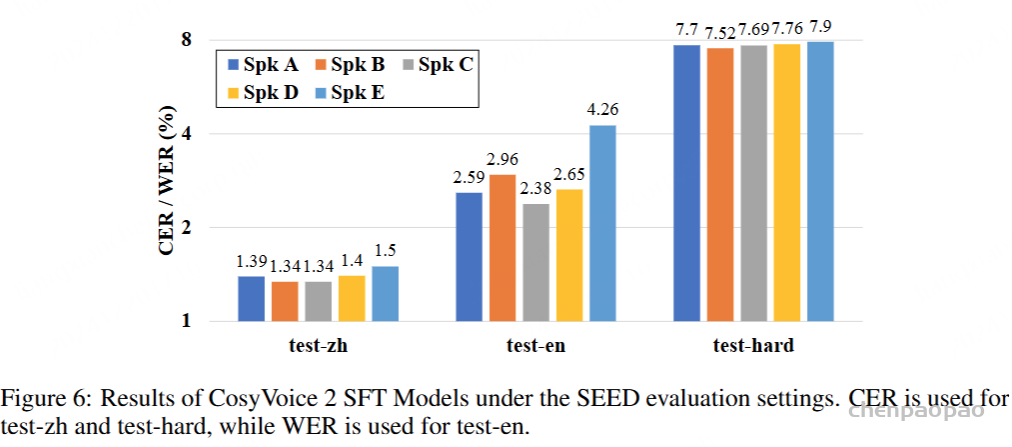
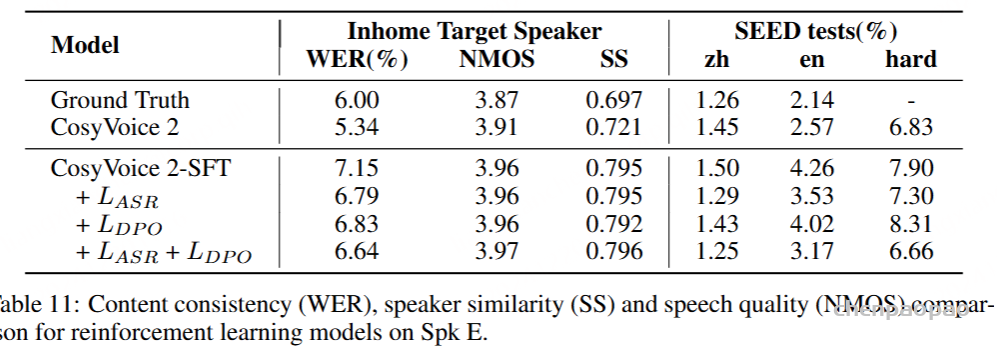
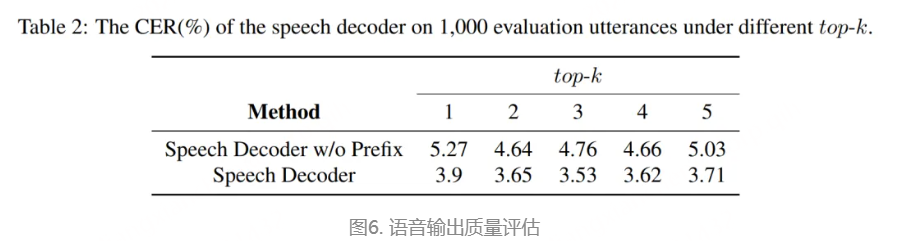
为了评估我们语音解码器的合成准确性,我们将最新的SEED测试集(Anastassiou et al., 2024)转换为ChatLM格式。在该格式中,文本以用户内容的形式呈现,并以“Copy:”命令为前缀,LLM预计会复制该文本。测试集包括2,020个中文案例和1,088个英文案例。对于中文案例,我们使用了Paraformer-zh模型(Gao et al., 2022),而英文案例则使用了Whisper-large V3(Radford et al., 2023)。鉴于LLM存在的指令跟随问题,我们在推理过程中应用了教师强制方案,以最小化输入和输出文本之间的差异。语音解码器的内容一致性通过中文的CER(字符错误率)和英文的WER(词错误率)进行评估。
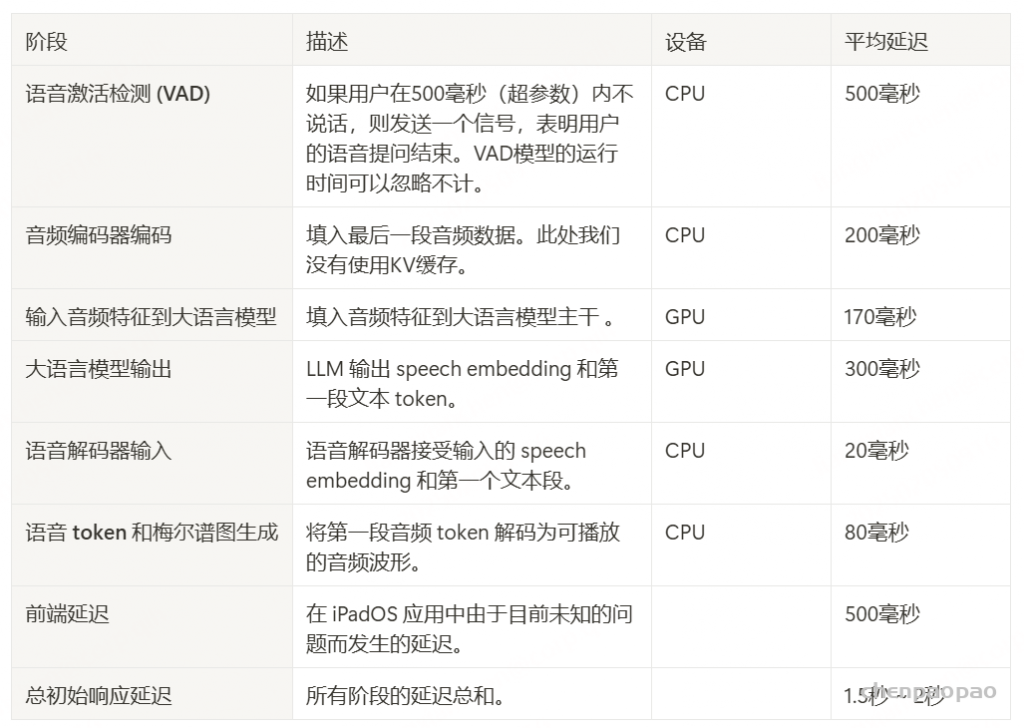
我们的发现表明,即使在应用了教师强制方案的情况下,只有大约20%的测试案例的输入和输出文本与LLM完全一致。由于不一致的输入和输出可能导致语音解码器的隐藏状态混乱,因此仅包括输入和输出文本一致的测试案例来计算错误率。结果如表17所示。我们观察到,与TTS基线模型CosyVoice 2.0-SFT(Du et al., 2024b)相比,MinMo在中文测试集上表现出稍微较低的内容一致性和语音质量。在英文测试集上,MinMo在内容一致性上表现相似,但NMOS(语音质量评分)稍低。这个下降可以归因于微调的说话人不同的声学特性,这影响了识别模型和NMOS评分器。然而,这种下降不会显著影响人类的理解。因此,主观评估可能更适合语音到语音的语音聊天模型,我们将在未来的工作中进一步探讨这一点。
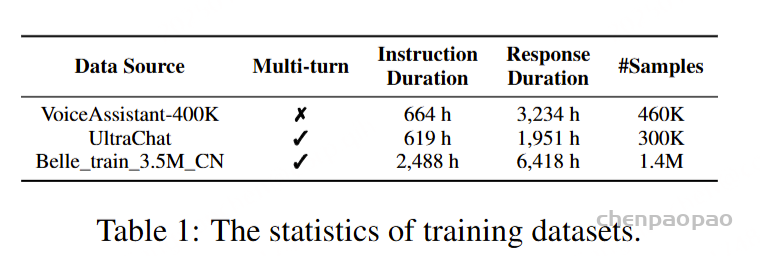
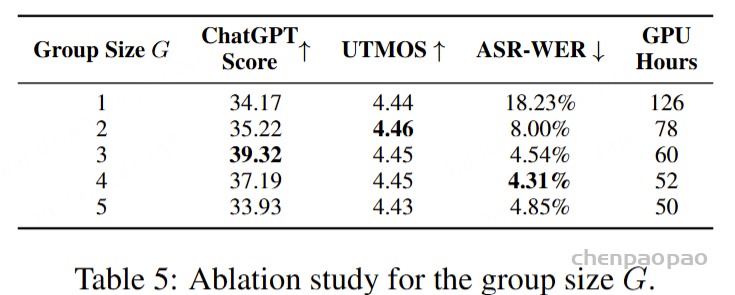
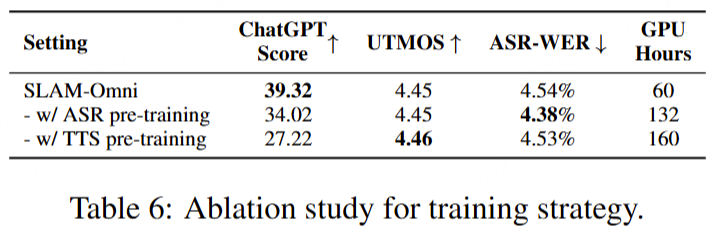
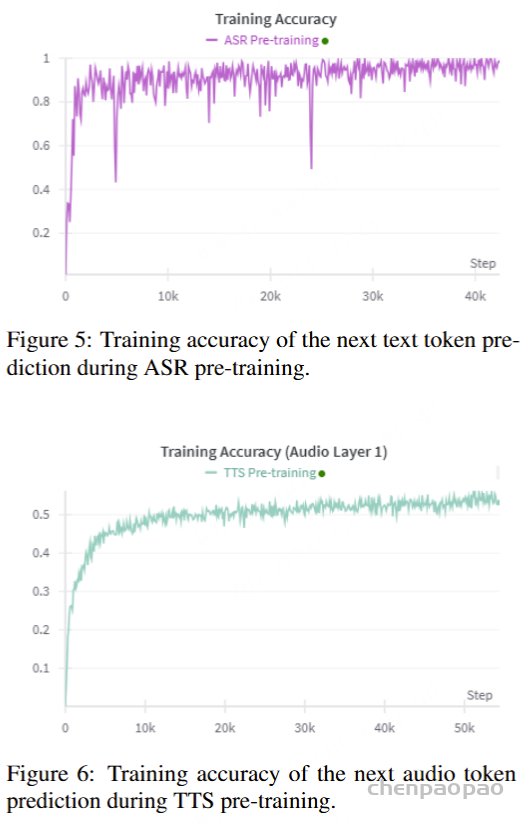
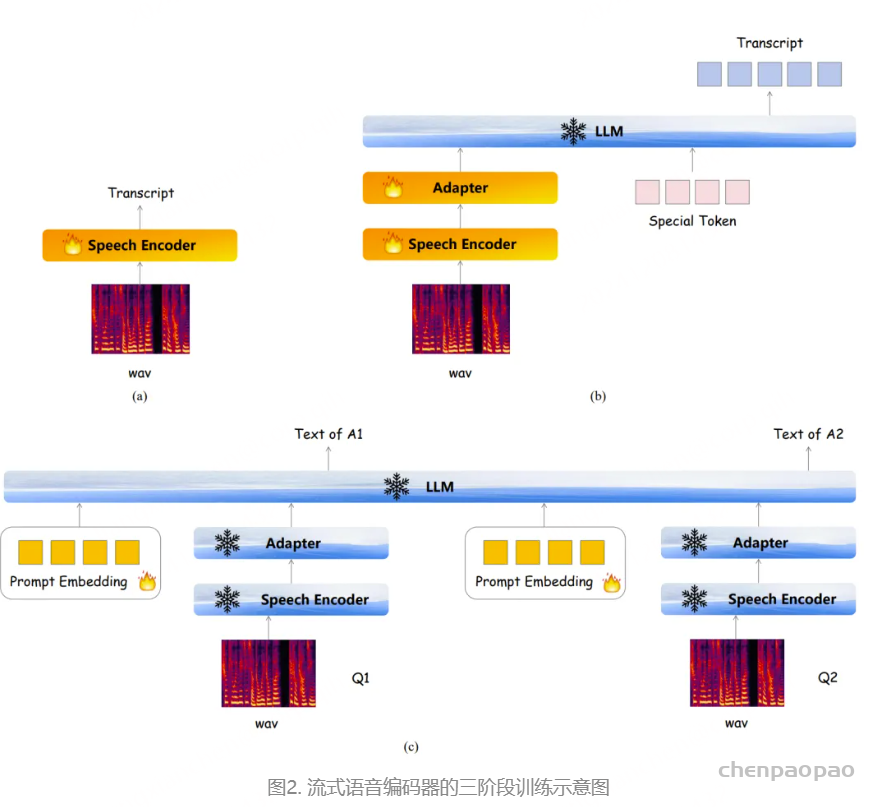
对于ASR和TTS预训练,专门使用VoiceAssistant-400K数据集来确保一致性并避免引入外部数据。在 ASR 预训练期间,提供语音指令作为输入,其相应的转录文本作为目标输出。相反,对于 TTS 预训练,语音响应的转录被用作输入文本,而相应的语义token被设置为预测目标。优化和学习策略与微调期间采用的策略一致,值得注意的是,在 ASR 预训练期间仅计算文本层损失,而 TTS 预训练专门关注多层音频损失作为训练目标。
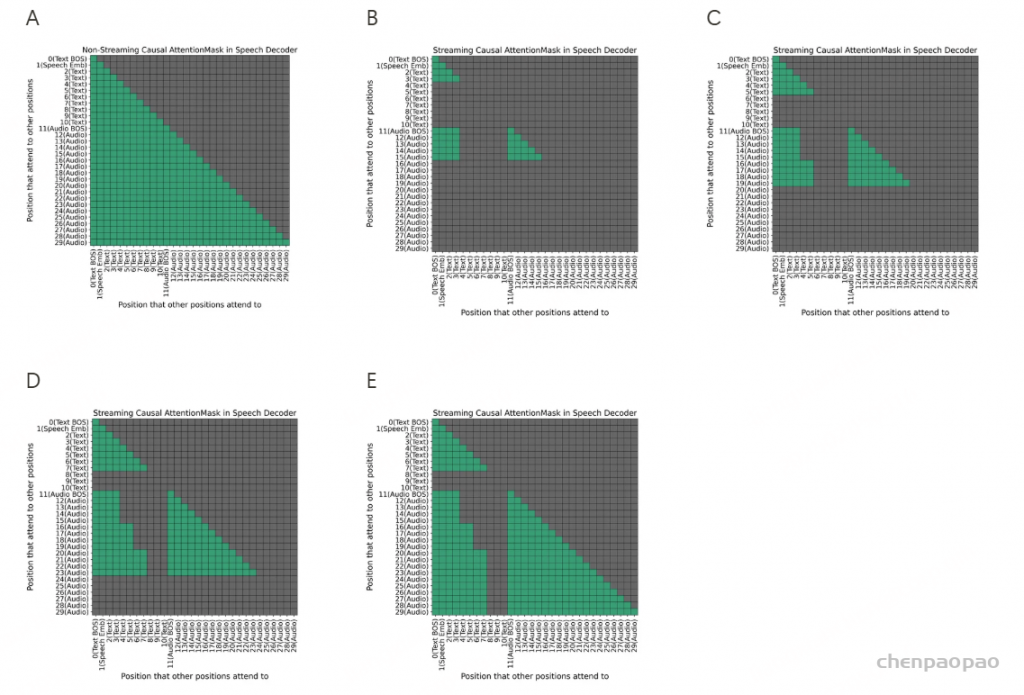
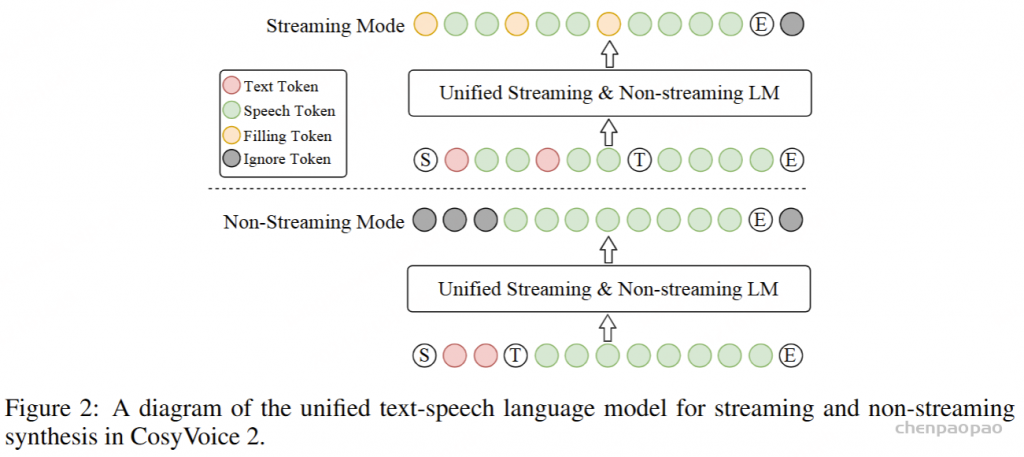
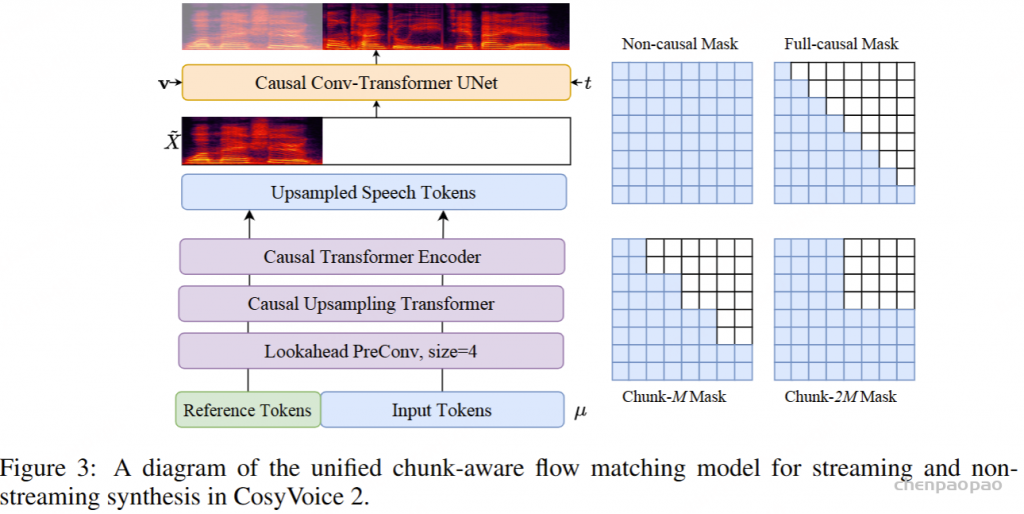
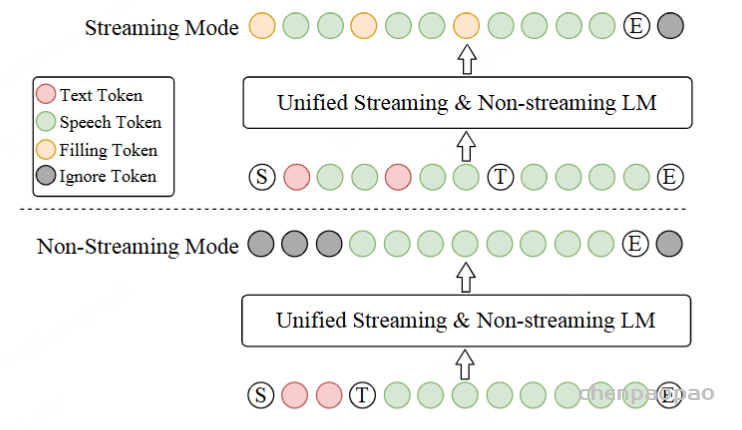
ICL,非流式:在 ICL 中,LM 需要来自参考音频的提示文本和语音标记,以模仿重音、韵律、情感和风格。在非流式处理模式下,提示和要合成的文本标记连接为整个实体,提示语音标记被视为预先生成的结果并固定:“S 、 prompt_text、 text 、T、 prompt_speech”。LM 的自回归生成从此类序列开始,直到检测到 “End of sequence” 标记。
ICL,流式处理:在此方案中,我们假设要生成的文本是已知的,并且语音令牌应以流式处理方式生成。同样,我们将 prompt 和 to-generate 文本视为一个整体。然后,我们将其与提示语音标记混合,比例为 N : M : “S, mixed_text_speech,T,remaining_speech”。如果文本长度大于提示语音 Token 的长度,LM 将生成 “filling token”。在这种情况下,我们手动填充 N个文本标记。如果文本令牌用完,将添加“Turn of speech” T 令牌。在流式处理模式下,我们为每个 M 令牌返回生成结果,直到检测到 E为止。
现在,很多后来推出的声码器都使用非自回归方法来改善自回归方法生成速度慢的问题。换句话说,一种无需查看先前样本(通常表示为平行)即可生成后续样本的方法。已经提出了各种各样的非自回归方法,但最近一篇表明自回归方法依旧抗打的论文是 Chunked Autoregressive GAN (CARGAN),它表明许多非自回归声码器存在音高错误,这个问题可以通过使用自回归方法来解决。当然,速度是个问题,但是通过提示可以分成chunked单元计算,绍一种可以显着降低速度和内存的方法。
在这篇文章的开头,在处理 TTS 的历史时,我们简单地了解了 Formant Synthesis。人声是一种建模方法,认为基本声源(正弦音等)经过口部结构过滤,转化为我们听到的声音。这种方法最重要的部分是如何制作过滤器。在 DL 时代,如果这个过滤器用神经网络建模,性能会不会更好。在神经源滤波器方法 [Wang19a] 中,使用 f0(音高)信息创建基本正弦声音,并训练使用扩张卷积的滤波器以产生优质声音。不是自回归的方法,所以速度很快。之后,在Neural harmonic-plus-noise waveform model with trainable maximum voice frequency for text-to-speech synthesis.中,将其扩展重构为谐波+噪声模型以提高性能。DDSP 提出了一种使用神经网络和多个 DSP 组件创建各种声音的方法,其中谐波使用加法合成方法,噪声使用线性时变滤波器。
另一种方法是将与语音音高相关的部分(共振峰)和其他部分(称为残差、激励等)进行划分和处理的方法。这也是一种历史悠久的方法。共振峰主要使用了LP(线性预测),激励使用了各种模型。GlotNet在神经网络时代提出,将(声门)激励建模为 WaveNet。之后,GELP 用 GAN 训练方法将其扩展为并行格式。
Naver/Yonsei University 的 ExcitNet也可以看作是具有类似思想的模型,然后,在扩展模型 LP-WaveNet中,source 和 filter 一起训练,并使用更复杂的模型。在 Neural text-to-speech with a modeling-by-generation excitation vocoder(Interspeech 2020)中,引入了逐代建模 (MbG) 概念,从声学模型生成的信息可用于声码器以提高性能。在神经同态声码器中,谐波使用线性时变 (LTV) 脉冲序列,噪声使用 LTV 噪声。Unified source-filter GAN: Unified source-filter network based on factorization of quasi-periodic Parallel WaveGAN(Interspeech 2021)提出了一种模型,它使用 Parallel WaveGAN 作为声码器,并集成了上述几种源滤波器模型。Parallel WaveGAN本身也被Naver不断扩充,首先在High-fidelity Parallel WaveGAN with multi-band harmonic-plus-noise model(Interspeech 2021)中,Generator被扩充为Harmonic + Noise模型,同时也加入了subband版本。
LPCNet可以被认为是继这种源过滤器方法之后使用最广泛的模型。作为在 WaveRNN 中加入线性预测的模型, LPCNet 此后也进行了多方面的改进。在 Bunched LPCNet 中,通过利用原始 WaveRNN 中引入的技术,LPCNet 变得更加高效。Gaussian LPCNet还通过允许同时预测多个样本来提高效率。Lightweight LPCNet-based neural vocoder with tensor decomposition(Interspeech 2020)通过使用张量分解进一步减小 WaveRNN 内部组件的大小来提高另一个方向的效率。iLPCNet该模型通过利用连续形式的混合密度网络显示出比现有 LPCNet 更高的性能。Fast and lightweight on-device tts with Tacotron2 and LPCNet(Interspeech 2020)提出了一种模型,在LPCNet中的语音中找到可以切断的部分(例如,停顿或清音),将它们划分,并行处理,并通过交叉淡入淡出来加快生成速度. LPCNet 也扩展到了子带版本,首先在 FeatherWave中引入子带 LPCNet。在An efficient subband linear prediction for lpcnet-based neural synthesis(Interspeech 2020)中,提出了考虑子带之间相关性的子带 LPCNet 的改进版本.
声码器的发展正朝着从高质量、慢速的AR(Autoregressive)方法向快速的NAR(Non-autoregressive)方法转变的方向发展。由于几种先进的生成技术,NAR 也逐渐达到 AR 的水平。例如在TTS-BY-TTS [Hwang21a]中,使用AR方法创建了大量数据并用于NAR模型的训练,效果不错。但是,使用所有数据可能会很糟糕。因此,TTS-BY-TTS2提出了一种仅使用此数据进行训练的方法,方法是使用 RankSVM 获得与原始音频更相似的合成音频。
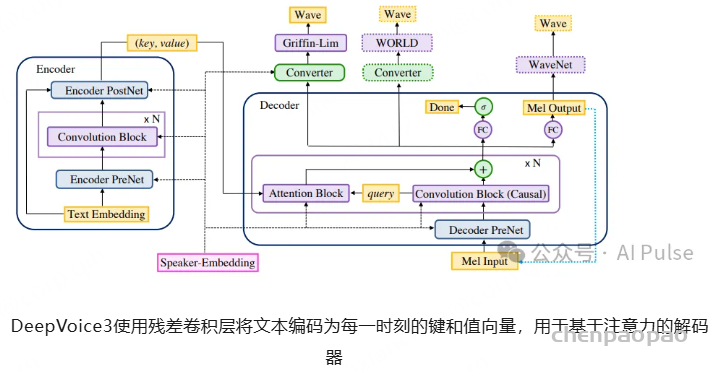
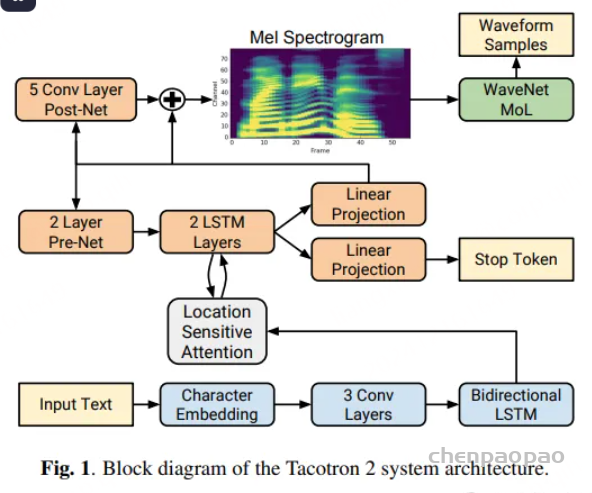
也许这个领域的第一个是 Char2Wav ,这是蒙特利尔大学名人Yoshua Bengio教授团队的论文,通过将其团队制作的SampleRNN vocoder添加到Acoustic Model using seq2seq中一次性训练而成。ClariNet的主要内容其实就是让WaveNet->IAF方法的Vocoder更加高效。
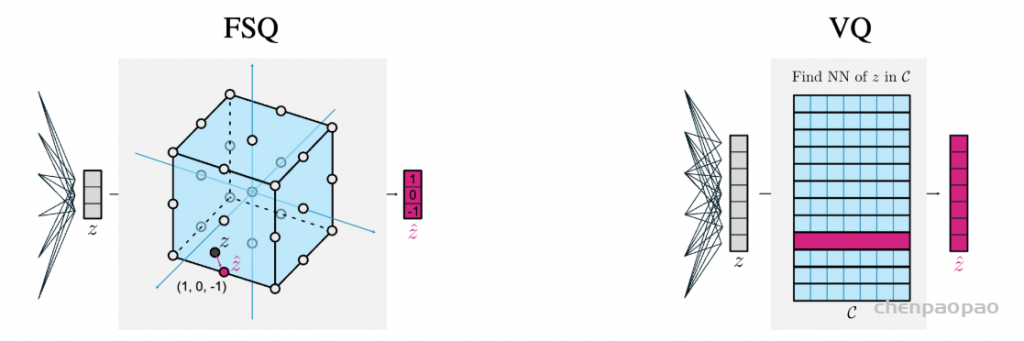
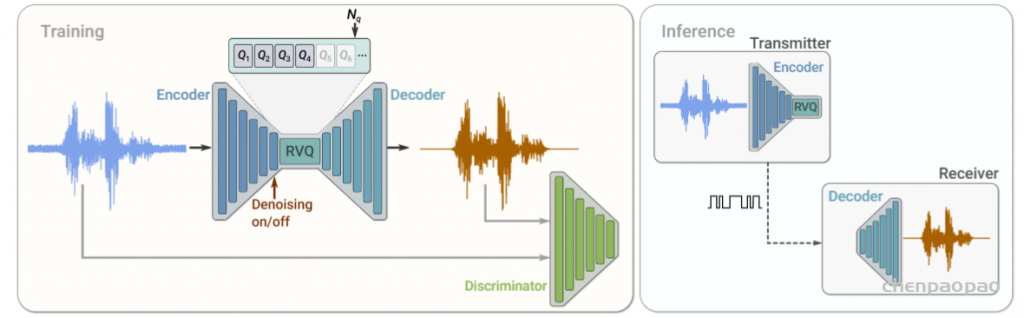
每个量化器在训练 codebook 的时候,都使用 EMA (Exponential Moving Average,指数移动平均)的更新方式。训练 VQ 的 codebook 使用 EMA 方法由 Aäron van den Oord首次提出。论文 Neural Discrete Representation Learning(https://arxiv.org/abs/1711.00937)提出使用 EMA 指数移动平均的方式训练码本 codebook。
EMA 指数移动平均:每次迭代相当于对之前所有 batch 累计值和当前 batch 新获取的数据值进行加权平均,权重又称为 decay factor,通常选择数值为 0.99 ,使得参数的迭代更新不至于太激进。
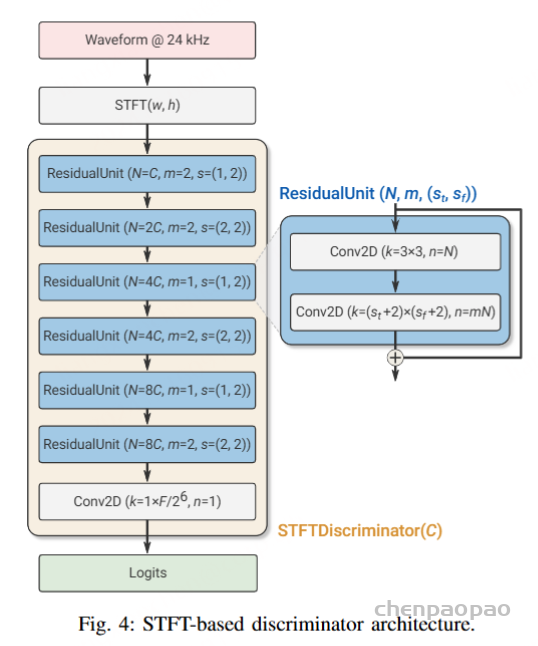
SoundStream 整体使用 GAN(生成对抗网络)作为训练目标,采用 hinge loss 形式的对抗 loss。对应到 GAN 模型中,整个编解码器作为 Generator 生成器,使用前文所述的两种 Discriminator 判别器:一个 STFT 判别器和三个参数不同的 multi-resolution 判别器。判别器用来区分是解码出的音频还是真实的原始音频,本文采用 hinge loss 形式的损失函数进行真假二分类:
生成器的损失函数是为了让生成器的输出被分类为 1 类别,以达到以假乱真的目标,损失函数形式为:
训练目标中还增加了 GAN 中常用的 feature matching 损失函数和多尺度频谱重建的损失函数。feature matching 就是让生成器恢复出的音频和真实的音频,在判别器的中间层上达到相近的分布,用l表示在中间层上进行求和,feature matching 的损失函数为:
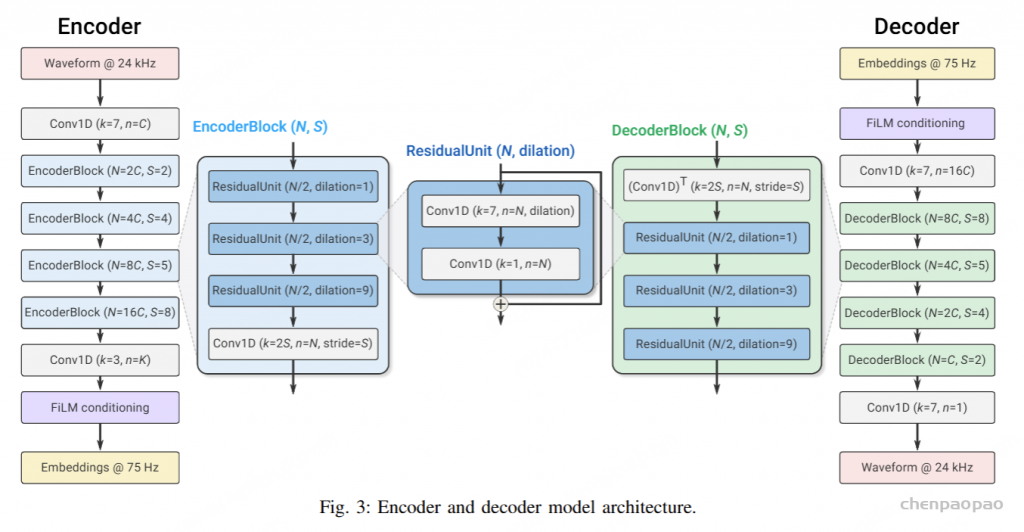
从 SoundStream 的编解码器图例中可以看到一个 FiLM 的模块,表示特征级别的线性调制(Feature-wise Linear Modulation),在编码器中使用时位于 embedding 之前(编码前进行降噪),在解码器中使用时输入是 embedding(编码后进行降噪),论文验证了在图中位置的效果是最好的。
Lyra v1: Kleijn, W. Bastiaan, et al. “Generative Speech Coding with Predictive Variance Regularization.” arXiv preprint arXiv:2102.09660 (2021).
AudioLM: Borsos, Zalán, et al. “Audiolm: a language modeling approach to audio generation.” arXiv preprint arXiv:2209.03143 (2022).
MusicLM: Agostinelli, Andrea, et al. “MusicLM: Generating Music From Text.” arXiv preprint arXiv:2301.11325 (2023).
EMA 训练 codebook 1: Van Den Oord, Aaron, and Oriol Vinyals. “Neural discrete representation learning.” Advances in neural information processing systems 30 (2017).
EMA 训练 codebook 2: Razavi, Ali, Aaron Van den Oord, and Oriol Vinyals. “Generating diverse high-fidelity images with vq-vae-2.” Advances in neural information processing systems 32 (2019).
Jukebox: Dhariwal, Prafulla, et al. “Jukebox: A generative model for music.” arXiv preprint arXiv:2005.00341 (2020).
FiLM: Perez, Ethan, et al. “Film: Visual reasoning with a general conditioning layer.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.
ViSQOL 指标: Chinen, Michael, et al. “ViSQOL v3: An open source production ready objective speech and audio metric.” 2020 twelfth international conference on quality of multimedia experience (QoMEX). IEEE, 2020.
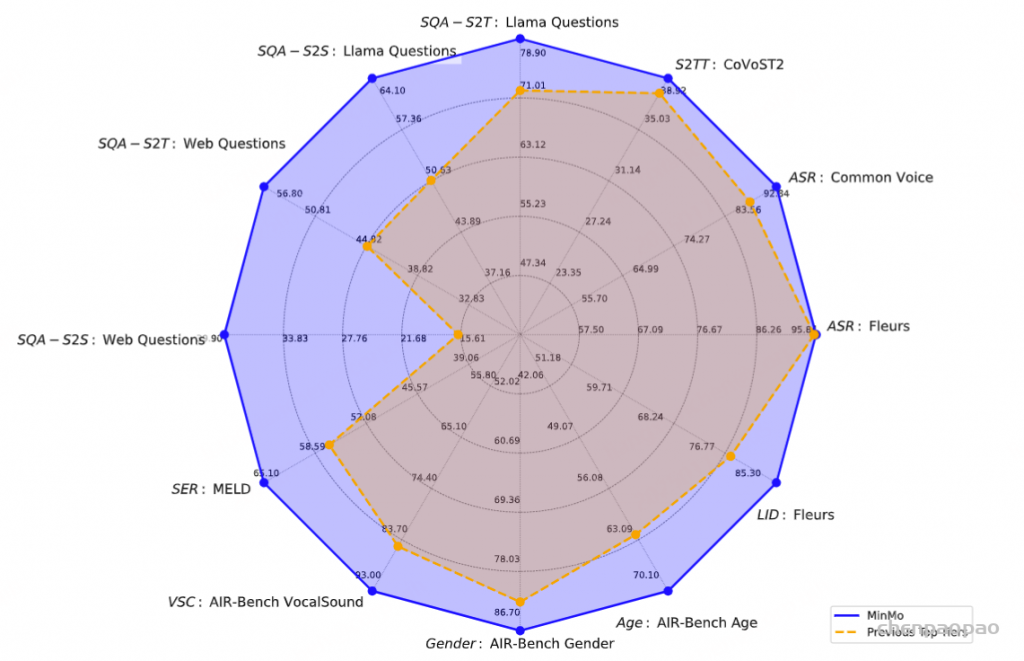
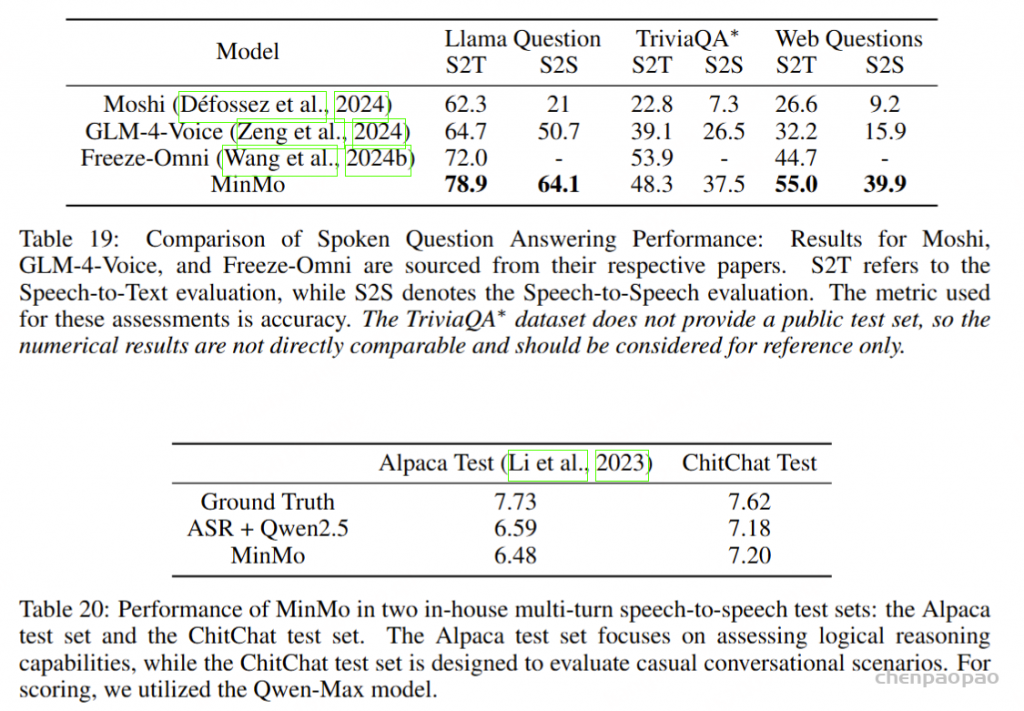
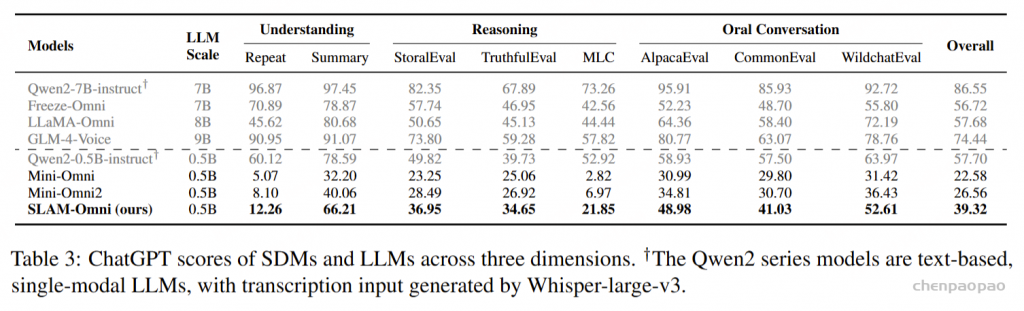
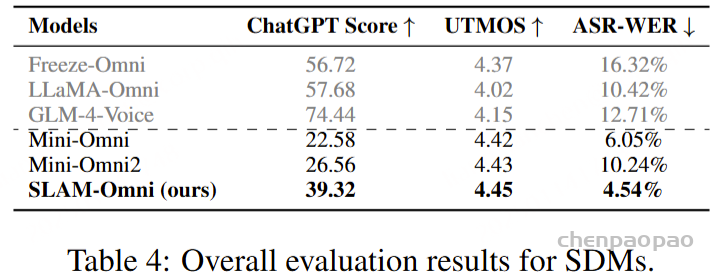
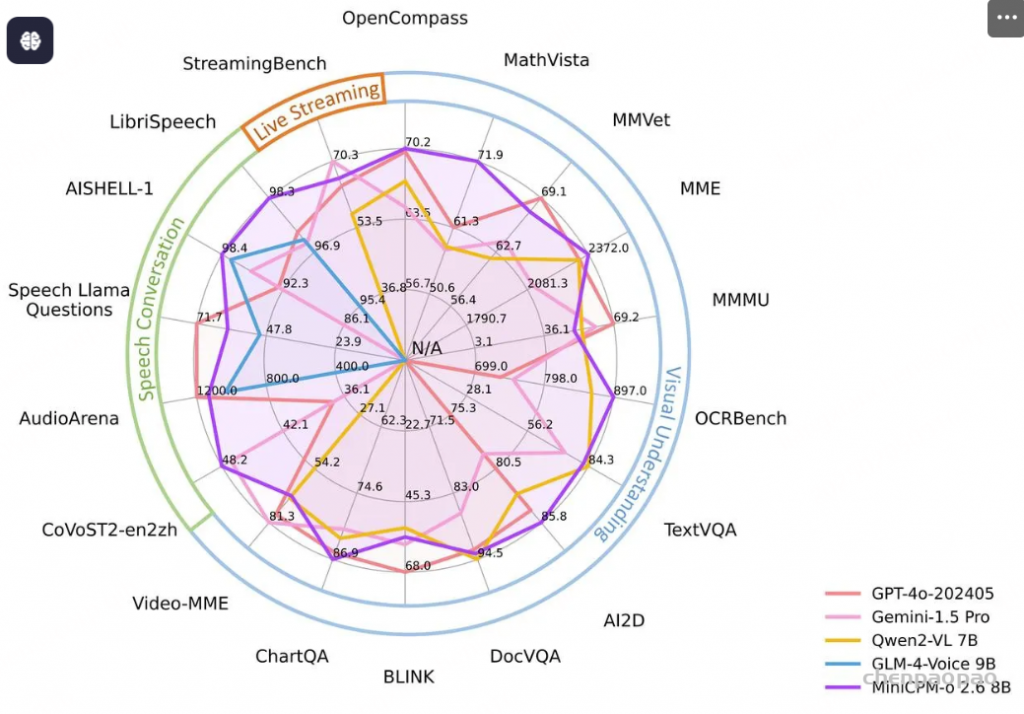
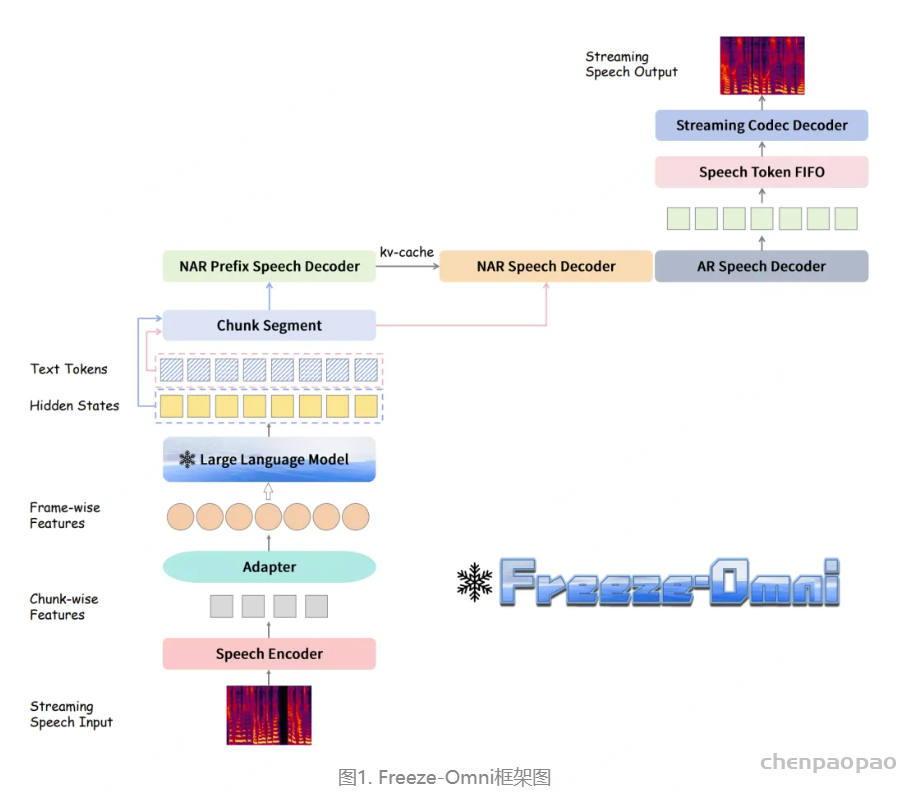
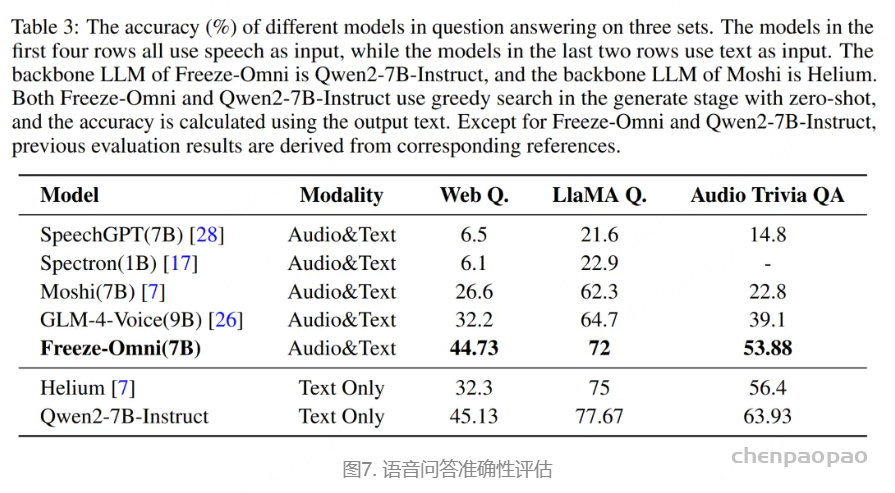
语音问答准确性评估:Freeze-Omni提供了其在LlaMA-Questions, Web Questions, 和Trivia QA三个集合上的语音问答准确率评估,从结果中可以看出Freeze-Omni的准确率具有绝对的领先水平,超越Moshi与GLM-4-Voice等目前SOTA的模型,并且其语音模态下的准确率相比其基底模型Qwen2-7B-Instruct的文本问答准确率而言,差距明显相比Moshi与其文本基底模型Helium的要小,足以证明Freeze-Omni的训练方式可以使得LLM在接入语音模态之后,聪明度和知识能力受到的影响最低。