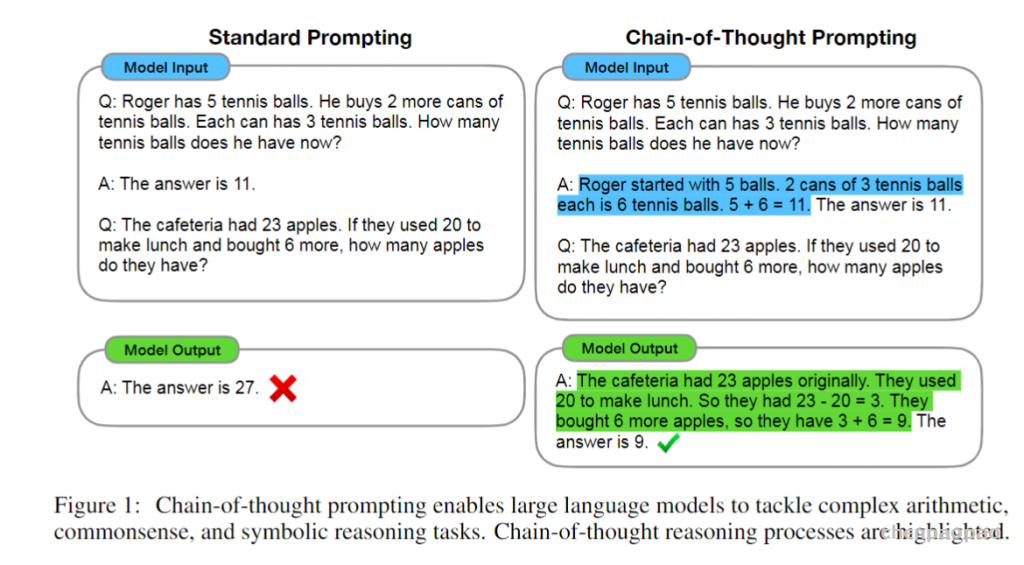
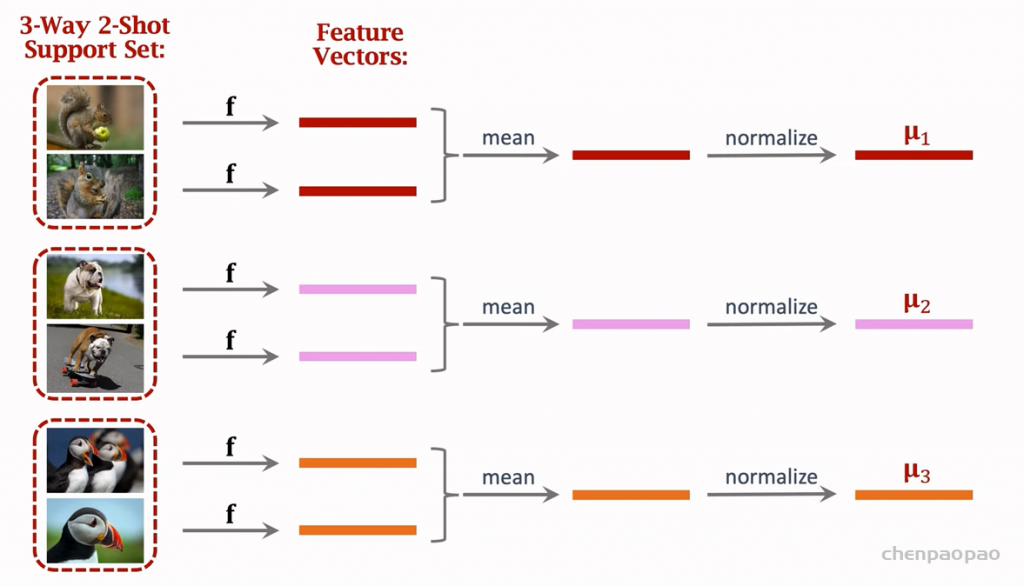
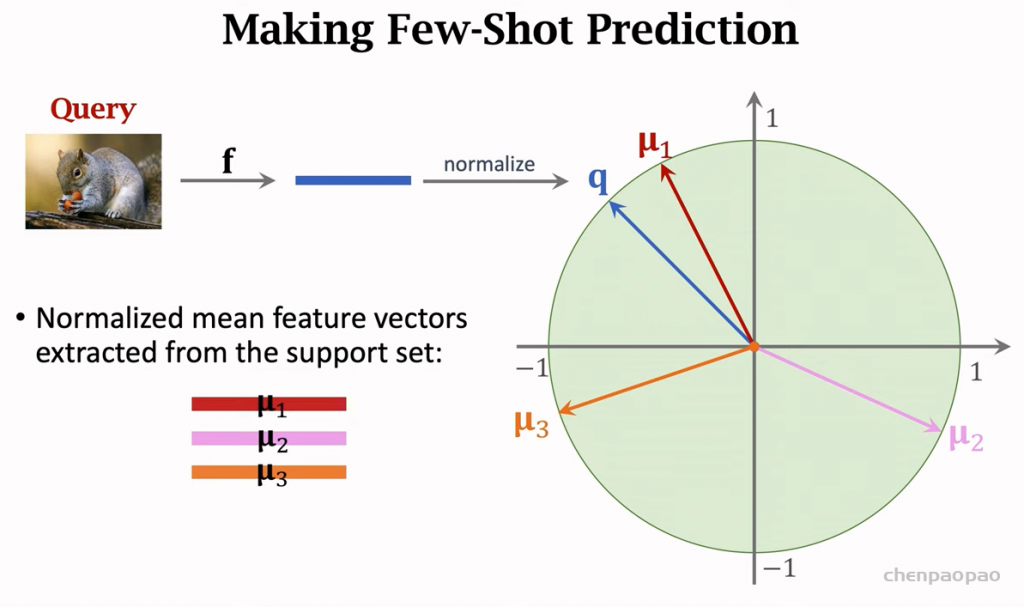
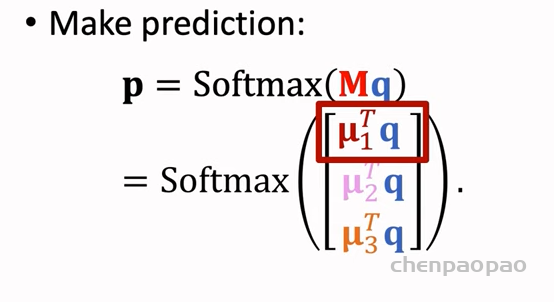
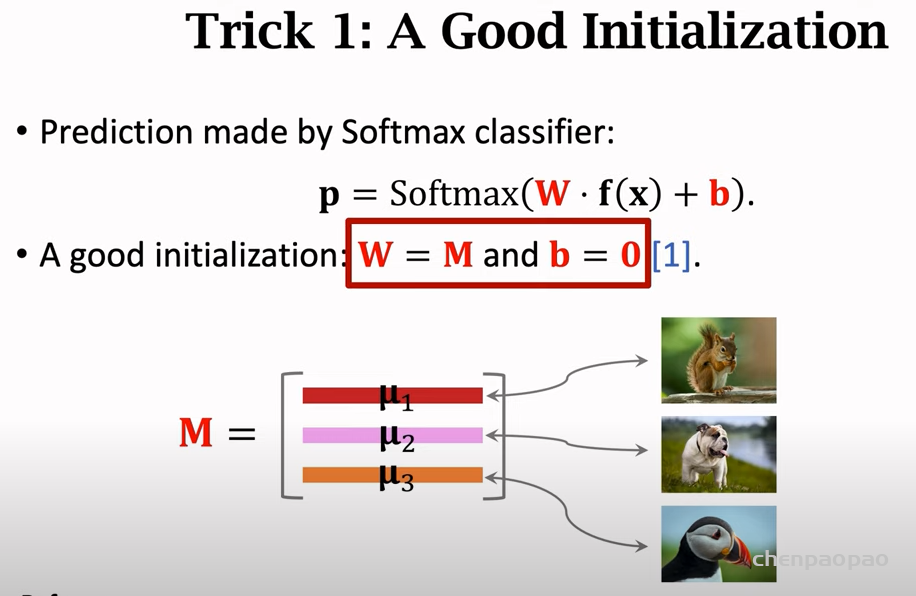
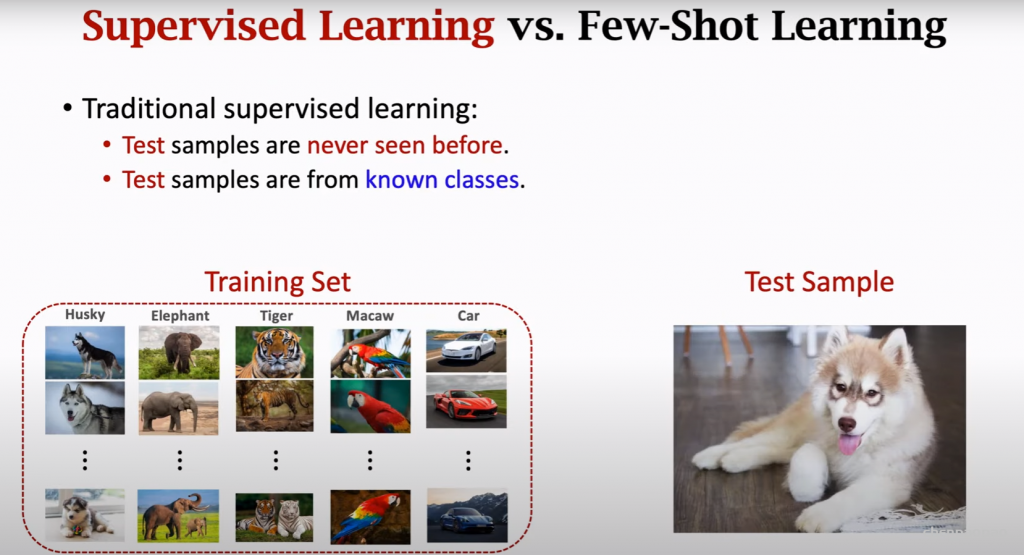
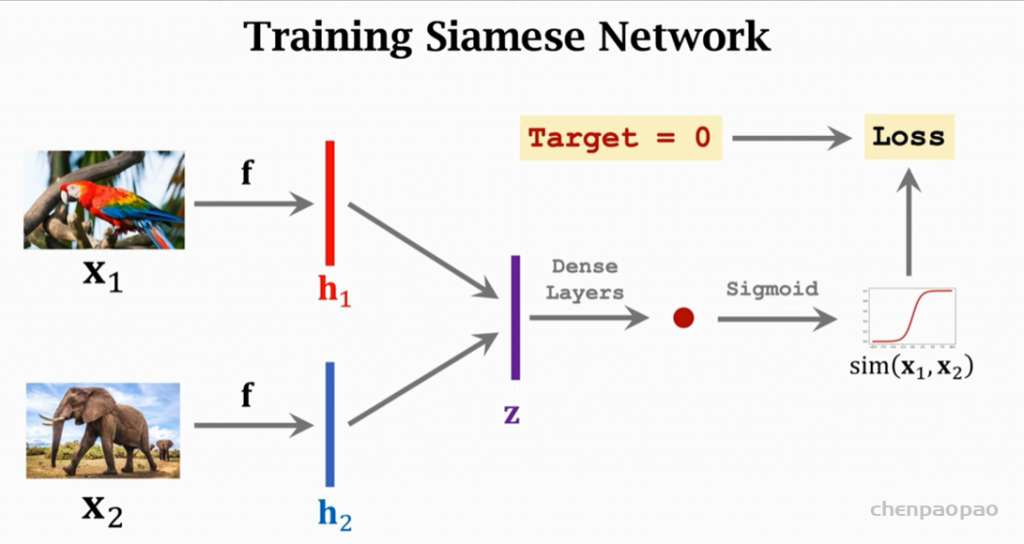
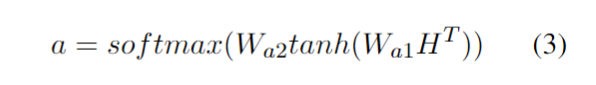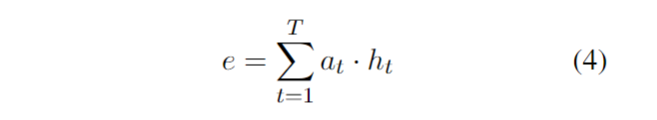融入了 Prompt 的模式大致可以归纳成 “Pre-train, Prompt, and Predict”,在该模式中,下游任务被重新调整成类似预训练任务的形式。例如,通常的预训练任务有 MLM(Masked Language Model),在文本情感分类任务中,对于 “I love this movie” 这句输入,可以在后面加上 Prompt:”the movie is ___”,组成如下这样一句话:
Prompt 在 PLM debias 方面的应用。由于 PLM 在预训练过程中见过了大量的人类世界的自然语言,所以很自然地会受到一些影响。举一个简单的例子,比如说训练语料中有非常多 “The capital of China is Beijing”,导致模型每次看到 “capital” 的时候都会预测出 “Beijing”,而不是去分析到底是哪个国家的首都。在应用的过程中,Prompt 还暴露了 PLM 学习到的很多其它 bias,比如种族歧视、性别对立等。这也许会是一个值得研究的方向
This repository contains few-shot learning (FSL) papers mentioned in our FSL survey published in ACM Computing Surveys (JCR Q1, CORE A*).
For convenience, we also include public implementations of respective authors.
We will update this paper list to include new FSL papers periodically.
Citation
Please cite our paper if you find it helpful.
@article{wang2020generalizing,
title={Generalizing from a few examples: A survey on few-shot learning},
author={Wang, Yaqing and Yao, Quanming and Kwok, James T and Ni, Lionel M},
journal={ACM Computing Surveys},
volume={53},
number={3},
pages={1--34},
year={2020},
publisher={ACM New York, NY, USA}
}
Learning from one example through shared densities on transforms, in CVPR, 2000. E. G. Miller, N. E. Matsakis, and P. A. Viola.paper
Domain-adaptive discriminative one-shot learning of gestures, in ECCV, 2014. T. Pfister, J. Charles, and A. Zisserman.paper
One-shot learning of scene locations via feature trajectory transfer, in CVPR, 2016. R. Kwitt, S. Hegenbart, and M. Niethammer.paper
Low-shot visual recognition by shrinking and hallucinating features, in ICCV, 2017. B. Hariharan and R. Girshick.papercode
Improving one-shot learning through fusing side information, arXiv preprint, 2017. Y.H.Tsai and R.Salakhutdinov.paper
Fast parameter adaptation for few-shot image captioning and visual question answering, in ACM MM, 2018. X. Dong, L. Zhu, D. Zhang, Y. Yang, and F. Wu.paper
Exploit the unknown gradually: One-shot video-based person re-identification by stepwise learning, in CVPR, 2018. Y. Wu, Y. Lin, X. Dong, Y. Yan, W. Ouyang, and Y. Yang.paper
Low-shot learning with large-scale diffusion, in CVPR, 2018. M. Douze, A. Szlam, B. Hariharan, and H. Jégou.paper
Diverse few-shot text classification with multiple metrics, in NAACL-HLT, 2018. M. Yu, X. Guo, J. Yi, S. Chang, S. Potdar, Y. Cheng, G. Tesauro, H. Wang, and B. Zhou.papercode
Delta-encoder: An effective sample synthesis method for few-shot object recognition, in NeurIPS, 2018. E. Schwartz, L. Karlinsky, J. Shtok, S. Harary, M. Marder, A. Kumar, R. Feris, R. Giryes, and A. Bronstein.paper
Low-shot learning via covariance-preserving adversarial augmentation networks, in NeurIPS, 2018. H. Gao, Z. Shou, A. Zareian, H. Zhang, and S. Chang.paper
Learning to self-train for semi-supervised few-shot classification, in NeurIPS, 2019. X. Li, Q. Sun, Y. Liu, S. Zheng, Q. Zhou, T.-S. Chua, and B. Schiele.paper
Few-shot learning with global class representations, in ICCV, 2019. A. Li, T. Luo, T. Xiang, W. Huang, and L. Wang.paper
AutoAugment: Learning augmentation policies from data, in CVPR, 2019. E. D. Cubuk, B. Zoph, D. Mane, V. Vasudevan, and Q. V. Le.paper
EDA: Easy data augmentation techniques for boosting performance on text classification tasks, in EMNLP and IJCNLP, 2019. J. Wei and K. Zou.paper
LaSO: Label-set operations networks for multi-label few-shot learning, in CVPR, 2019. A. Alfassy, L. Karlinsky, A. Aides, J. Shtok, S. Harary, R. Feris, R. Giryes, and A. M. Bronstein.papercode
Image deformation meta-networks for one-shot learning, in CVPR, 2019. Z. Chen, Y. Fu, Y.-X. Wang, L. Ma, W. Liu, and M. Hebert.papercode
Spot and learn: A maximum-entropy patch sampler for few-shot image classification, in CVPR, 2019. W.-H. Chu, Y.-J. Li, J.-C. Chang, and Y.-C. F. Wang.paper
Data augmentation using learned transformations for one-shot medical image segmentation, in CVPR, 2019. A. Zhao, G. Balakrishnan, F. Durand, J. V. Guttag, and A. V. Dalca.paper
Adversarial feature hallucination networks for few-shot learning, in CVPR, 2020. K. Li, Y. Zhang, K. Li, and Y. Fu.paper
Instance credibility inference for few-shot learning, in CVPR, 2020. Y. Wang, C. Xu, C. Liu, L. Zhang, and Y. Fu.paper
Diversity transfer network for few-shot learning, in AAAI, 2020. M. Chen, Y. Fang, X. Wang, H. Luo, Y. Geng, X. Zhang, C. Huang, W. Liu, and B. Wang.papercode
Neural snowball for few-shot relation learning, in AAAI, 2020. T. Gao, X. Han, R. Xie, Z. Liu, F. Lin, L. Lin, and M. Sun.papercode
Associative alignment for few-shot image classification, in ECCV, 2020. A. Afrasiyabi, J. Lalonde, and C. Gagné.papercode
Information maximization for few-shot learning, in NeurIPS, 2020. M. Boudiaf, I. Ziko, J. Rony, J. Dolz, P. Piantanida, and I. B. Ayed.papercode
Self-training for few-shot transfer across extreme task differences, in ICLR, 2021. C. P. Phoo, and B. Hariharan.paper
Free lunch for few-shot learning: Distribution calibration, in ICLR, 2021. S. Yang, L. Liu, and M. Xu.papercode
Parameterless transductive feature re-representation for few-shot learning, in ICML, 2021. W. Cui, and Y. Guo;.paper
Learning intact features by erasing-inpainting for few-shot classification, in AAAI, 2021. J. Li, Z. Wang, and X. Hu.paper
Variational feature disentangling for fine-grained few-shot classification, in ICCV, 2021. J. Xu, H. Le, M. Huang, S. Athar, and D. Samaras.paper
Coarsely-labeled data for better few-shot transfer, in ICCV, 2021. C. P. Phoo, and B. Hariharan.paper
Pseudo-loss confidence metric for semi-supervised few-shot learning, in ICCV, 2021. K. Huang, J. Geng, W. Jiang, X. Deng, and Z. Xu.paper
Iterative label cleaning for transductive and semi-supervised few-shot learning, in ICCV, 2021. M. Lazarou, T. Stathaki, and Y. Avrithis.paper
Meta two-sample testing: Learning kernels for testing with limited data, in NeurIPS, 2021. F. Liu, W. Xu, J. Lu, and D. J. Sutherland.paper
Dynamic distillation network for cross-domain few-shot recognition with unlabeled data, in NeurIPS, 2021. A. Islam, C.-F. Chen, R. Panda, L. Karlinsky, R. Feris, and R. Radke.paper
Towards better understanding and better generalization of low-shot classification in histology images with contrastive learning, in ICLR, 2022. J. Yang, H. Chen, J. Yan, X. Chen, and J. Yao.papercode
FlipDA: Effective and robust data augmentation for few-shot learning, in ACL, 2022. J. Zhou, Y. Zheng, J. Tang, L. Jian, and Z. Yang.papercode
PromDA: Prompt-based data augmentation for low-resource NLU tasks, in ACL, 2022. Y. Wang, C. Xu, Q. Sun, H. Hu, C. Tao, X. Geng, and D. Jiang.papercode
N-shot learning for augmenting task-oriented dialogue state tracking, in Findings of ACL, 2022. I. T. Aksu, Z. Liu, M. Kan, and N. F. Chen.paper
Generating representative samples for few-shot classification, in CVPR, 2022. J. Xu, and H. Le.papercode
Semi-supervised few-shot learning via multi-factor clustering, in CVPR, 2022. J. Ling, L. Liao, M. Yang, and J. Shuai.paper
Multi-task transfer methods to improve one-shot learning for multimedia event detection, in BMVC, 2015. W. Yan, J. Yap, and G. Mori.paper
Label efficient learning of transferable representations across domains and tasks, in NeurIPS, 2017. Z. Luo, Y. Zou, J. Hoffman, and L. Fei-Fei.paper
Few-shot adversarial domain adaptation, in NeurIPS, 2017. S. Motiian, Q. Jones, S. Iranmanesh, and G. Doretto.paper
One-shot unsupervised cross domain translation, in NeurIPS, 2018. S. Benaim and L. Wolf.paper
Multi-content GAN for few-shot font style transfer, in CVPR, 2018. S. Azadi, M. Fisher, V. G. Kim, Z. Wang, E. Shechtman, and T. Darrell.papercode
Feature space transfer for data augmentation, in CVPR, 2018. B. Liu, X. Wang, M. Dixit, R. Kwitt, and N. Vasconcelos.paper
Fine-grained visual categorization using meta-learning optimization with sample selection of auxiliary data, in ECCV, 2018. Y. Zhang, H. Tang, and K. Jia.paper
Few-shot charge prediction with discriminative legal attributes, in COLING, 2018. Z. Hu, X. Li, C. Tu, Z. Liu, and M. Sun.paper
Boosting few-shot visual learning with self-supervision, in ICCV, 2019. S. Gidaris, A. Bursuc, N. Komodakis, P. Pérez, and M. Cord.paper
When does self-supervision improve few-shot learning?, in ECCV, 2020. J. Su, S. Maji, and B. Hariharan.paper
Pareto self-supervised training for few-shot learning, in CVPR, 2021. Z. Chen, J. Ge, H. Zhan, S. Huang, and D. Wang.paper
Bridging multi-task learning and meta-learning: Towards efficient training and effective adaptation, in ICML, 2021. H. Wang, H. Zhao, and B. Li;.papercode
Embedding/Metric Learning
Object classification from a single example utilizing class relevance metrics, in NeurIPS, 2005. M. Fink.paper
Optimizing one-shot recognition with micro-set learning, in CVPR, 2010. K. D. Tang, M. F. Tappen, R. Sukthankar, and C. H. Lampert.paper
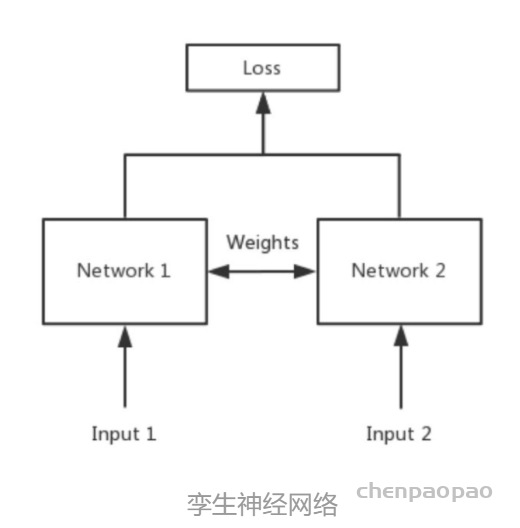
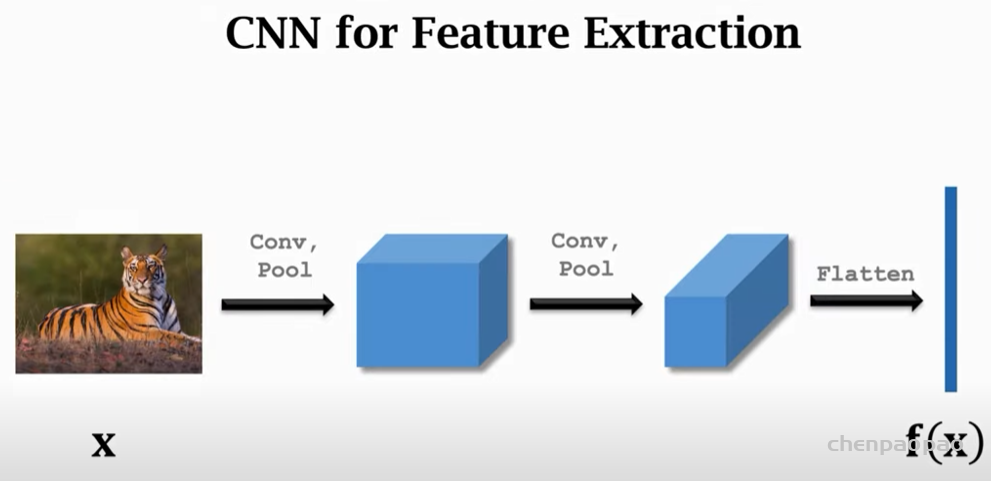
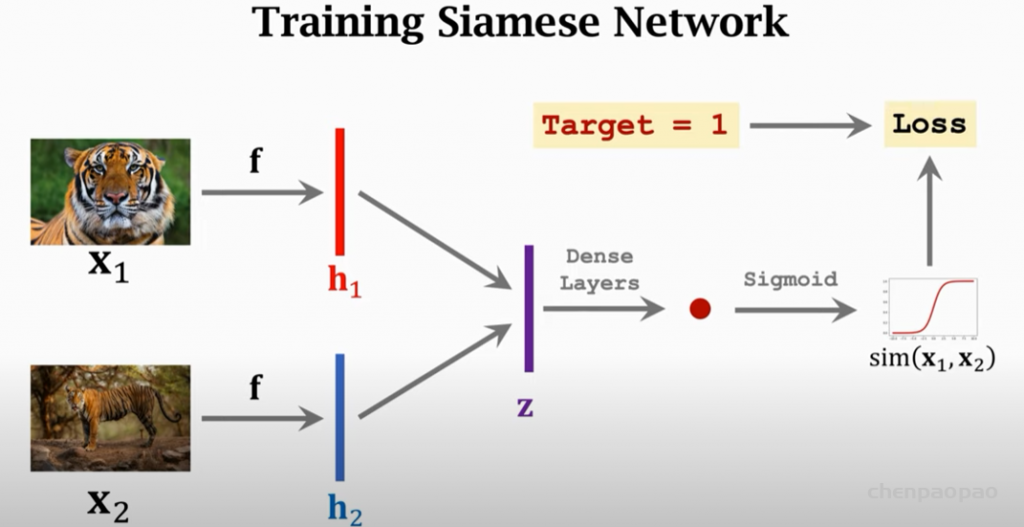
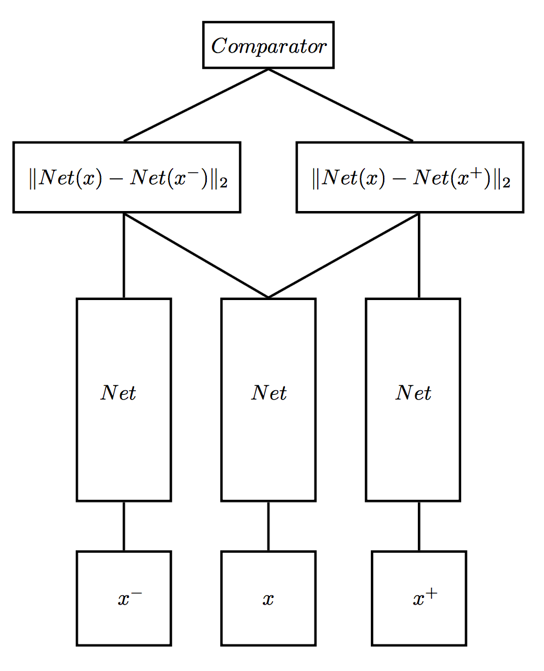
Siamese neural networks for one-shot image recognition, ICML deep learning workshop, 2015. G. Koch, R. Zemel, and R. Salakhutdinov.paper
Matching networks for one shot learning, in NeurIPS, 2016. O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra et al.paper
Learning feed-forward one-shot learners, in NeurIPS, 2016. L. Bertinetto, J. F. Henriques, J. Valmadre, P. Torr, and A. Vedaldi.paper
Few-shot learning through an information retrieval lens, in NeurIPS, 2017. E. Triantafillou, R. Zemel, and R. Urtasun.paper
Prototypical networks for few-shot learning, in NeurIPS, 2017. J. Snell, K. Swersky, and R. S. Zemel.papercode
Attentive recurrent comparators, in ICML, 2017. P. Shyam, S. Gupta, and A. Dukkipati.paper
Learning algorithms for active learning, in ICML, 2017. P. Bachman, A. Sordoni, and A. Trischler.paper
Active one-shot learning, arXiv preprint, 2017. M. Woodward and C. Finn.paper
Structured set matching networks for one-shot part labeling, in CVPR, 2018. J. Choi, J. Krishnamurthy, A. Kembhavi, and A. Farhadi.paper
Low-shot learning from imaginary data, in CVPR, 2018. Y.-X. Wang, R. Girshick, M. Hebert, and B. Hariharan.paper
Learning to compare: Relation network for few-shot learning, in CVPR, 2018. F. Sung, Y. Yang, L. Zhang, T. Xiang, P. H. Torr, and T. M. Hospedales.papercode
Dynamic conditional networks for few-shot learning, in ECCV, 2018. F. Zhao, J. Zhao, S. Yan, and J. Feng.papercode
TADAM: Task dependent adaptive metric for improved few-shot learning, in NeurIPS, 2018. B. Oreshkin, P. R. López, and A. Lacoste.paper
Meta-learning for semi-supervised few-shot classification, in ICLR, 2018. M. Ren, S. Ravi, E. Triantafillou, J. Snell, K. Swersky, J. B. Tenen- baum, H. Larochelle, and R. S. Zemel.papercode
Few-shot learning with graph neural networks, in ICLR, 2018. V. G. Satorras and J. B. Estrach.papercode
A simple neural attentive meta-learner, in ICLR, 2018. N. Mishra, M. Rohaninejad, X. Chen, and P. Abbeel.paper
Meta-learning with differentiable closed-form solvers, in ICLR, 2019. L. Bertinetto, J. F. Henriques, P. Torr, and A. Vedaldi.paper
Learning to propagate labels: Transductive propagation network for few-shot learning, in ICLR, 2019. Y. Liu, J. Lee, M. Park, S. Kim, E. Yang, S. Hwang, and Y. Yang.papercode
Multi-level matching and aggregation network for few-shot relation classification, in ACL, 2019. Z.-X. Ye, and Z.-H. Ling.paper
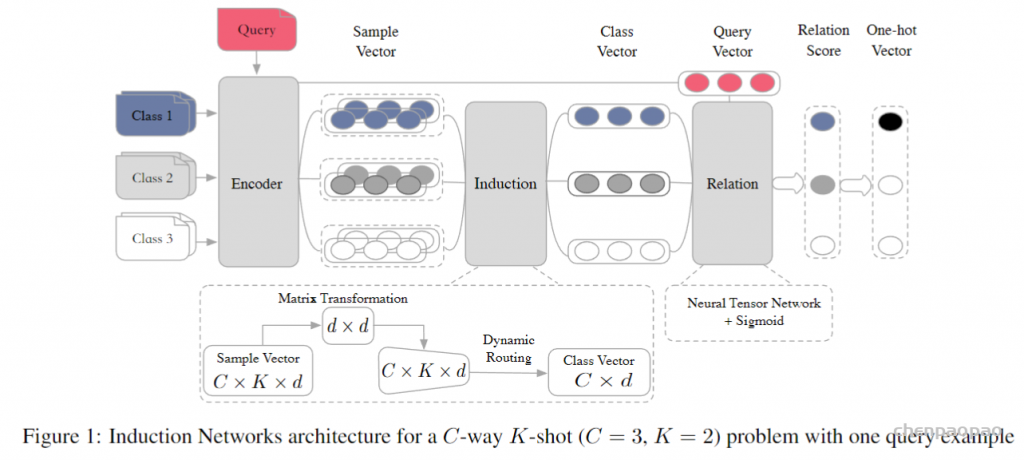
Induction networks for few-shot text classification, in EMNLP-IJCNLP, 2019. R. Geng, B. Li, Y. Li, X. Zhu, P. Jian, and J. Sun.paper
Hierarchical attention prototypical networks for few-shot text classification, in EMNLP-IJCNLP, 2019. S. Sun, Q. Sun, K. Zhou, and T. Lv.paper
Cross attention network for few-shot classification, in NeurIPS, 2019. R. Hou, H. Chang, B. Ma, S. Shan, and X. Chen.paper
Hybrid attention-based prototypical networks for noisy few-shot relation classification, in AAAI, 2019. T. Gao, X. Han, Z. Liu, and M. Sun.papercode
Attention-based multi-context guiding for few-shot semantic segmentation, in AAAI, 2019. T. Hu, P. Yang, C. Zhang, G. Yu, Y. Mu and C. G. M. Snoek.paper
Distribution consistency based covariance metric networks for few-shot learning, in AAAI, 2019. W. Li, L. Wang, J. Xu, J. Huo, Y. Gao and J. Luo.paper
A dual attention network with semantic embedding for few-shot learning, in AAAI, 2019. S. Yan, S. Zhang, and X. He.paper
TapNet: Neural network augmented with task-adaptive projection for few-shot learning, in ICML, 2019. S. W. Yoon, J. Seo, and J. Moon.paper
Prototype propagation networks (PPN) for weakly-supervised few-shot learning on category graph, in IJCAI, 2019. L. Liu, T. Zhou, G. Long, J. Jiang, L. Yao, C. Zhang.papercode
Collect and select: Semantic alignment metric learning for few-shot learning, in ICCV, 2019. F. Hao, F. He, J. Cheng, L. Wang, J. Cao, and D. Tao.paper
Transductive episodic-wise adaptive metric for few-shot learning, in ICCV, 2019. L. Qiao, Y. Shi, J. Li, Y. Wang, T. Huang, and Y. Tian.paper
Few-shot learning with embedded class models and shot-free meta training, in ICCV, 2019. A. Ravichandran, R. Bhotika, and S. Soatto.paper
PARN: Position-aware relation networks for few-shot learning, in ICCV, 2019. Z. Wu, Y. Li, L. Guo, and K. Jia.paper
PANet: Few-shot image semantic segmentation with prototype alignment, in ICCV, 2019. K. Wang, J. H. Liew, Y. Zou, D. Zhou, and J. Feng.papercode
RepMet: Representative-based metric learning for classification and few-shot object detection, in CVPR, 2019. L. Karlinsky, J. Shtok, S. Harary, E. Schwartz, A. Aides, R. Feris, R. Giryes, and A. M. Bronstein.papercode
Edge-labeling graph neural network for few-shot learning, in CVPR, 2019. J. Kim, T. Kim, S. Kim, and C. D. Yoo.paper
Finding task-relevant features for few-shot learning by category traversal, in CVPR, 2019. H. Li, D. Eigen, S. Dodge, M. Zeiler, and X. Wang.papercode
Revisiting local descriptor based image-to-class measure for few-shot learning, in CVPR, 2019. W. Li, L. Wang, J. Xu, J. Huo, Y. Gao, and J. Luo.papercode
TAFE-Net: Task-aware feature embeddings for low shot learning, in CVPR, 2019. X. Wang, F. Yu, R. Wang, T. Darrell, and J. E. Gonzalez.papercode
Improved few-shot visual classification, in CVPR, 2020. P. Bateni, R. Goyal, V. Masrani, F. Wood, and L. Sigal.paper
Boosting few-shot learning with adaptive margin loss, in CVPR, 2020. A. Li, W. Huang, X. Lan, J. Feng, Z. Li, and L. Wang.paper
Adaptive subspaces for few-shot learning, in CVPR, 2020. C. Simon, P. Koniusz, R. Nock, and M. Harandi.paper
DPGN: Distribution propagation graph network for few-shot learning, in CVPR, 2020. L. Yang, L. Li, Z. Zhang, X. Zhou, E. Zhou, and Y. Liu.paper
Few-shot learning via embedding adaptation with set-to-set functions, in CVPR, 2020. H.-J. Ye, H. Hu, D.-C. Zhan, and F. Sha.papercode
DeepEMD: Few-shot image classification with differentiable earth mover’s distance and structured classifiers, in CVPR, 2020. C. Zhang, Y. Cai, G. Lin, and C. Shen.papercode
Few-shot text classification with distributional signatures, in ICLR, 2020. Y. Bao, M. Wu, S. Chang, and R. Barzilay.papercode
Learning task-aware local representations for few-shot learning, in IJCAI, 2020. C. Dong, W. Li, J. Huo, Z. Gu, and Y. Gao.paper
SimPropNet: Improved similarity propagation for few-shot image segmentation, in IJCAI, 2020. S. Gairola, M. Hemani, A. Chopra, and B. Krishnamurthy.paper
Asymmetric distribution measure for few-shot learning, in IJCAI, 2020. W. Li, L. Wang, J. Huo, Y. Shi, Y. Gao, and J. Luo.paper
Transductive relation-propagation network for few-shot learning, in IJCAI, 2020. Y. Ma, S. Bai, S. An, W. Liu, A. Liu, X. Zhen, and X. Liu.paper
Weakly supervised few-shot object segmentation using co-attention with visual and semantic embeddings, in IJCAI, 2020. M. Siam, N. Doraiswamy, B. N. Oreshkin, H. Yao, and M. Jägersand.paper
Few-shot learning on graphs via super-classes based on graph spectral measures, in ICLR, 2020. J. Chauhan, D. Nathani, and M. Kaul.paper
SGAP-Net: Semantic-guided attentive prototypes network for few-shot human-object interaction recognition, in AAAI, 2020. Z. Ji, X. Liu, Y. Pang, and X. Li.paper
One-shot image classification by learning to restore prototypes, in AAAI, 2020. W. Xue, and W. Wang.paper
Negative margin matters: Understanding margin in few-shot classification, in ECCV, 2020. B. Liu, Y. Cao, Y. Lin, Q. Li, Z. Zhang, M. Long, and H. Hu.papercode
Prototype rectification for few-shot learning, in ECCV, 2020. J. Liu, L. Song, and Y. Qin.paper
Rethinking few-shot image classification: A good embedding is all you need?, in ECCV, 2020. Y. Tian, Y. Wang, D. Krishnan, J. B. Tenenbaum, and P. Isola.papercode
SEN: A novel feature normalization dissimilarity measure for prototypical few-shot learning networks, in ECCV, 2020. V. N. Nguyen, S. Løkse, K. Wickstrøm, M. Kampffmeyer, D. Roverso, and R. Jenssen.paper
TAFSSL: Task-adaptive feature sub-space learning for few-shot classification, in ECCV, 2020. M. Lichtenstein, P. Sattigeri, R. Feris, R. Giryes, and L. Karlinsky.paper
Attentive prototype few-shot learning with capsule network-based embedding, in ECCV, 2020. F. Wu, J. S.Smith, W. Lu, C. Pang, and B. Zhang.paper
Embedding propagation: Smoother manifold for few-shot classification, in ECCV, 2020. P. Rodríguez, I. Laradji, A. Drouin, and A. Lacoste.papercode
Laplacian regularized few-shot learning, in ICML, 2020. I. M. Ziko, J. Dolz, E. Granger, and I. B. Ayed.papercode
TAdaNet: Task-adaptive network for graph-enriched meta-learning, in KDD, 2020. Q. Suo, i. Chou, W. Zhong, and A. Zhang.paper
Concept learners for few-shot learning, in ICLR, 2021. K. Cao, M. Brbic, and J. Leskovec.paper
Reinforced attention for few-shot learning and beyond, in CVPR, 2021. J. Hong, P. Fang, W. Li, T. Zhang, C. Simon, M. Harandi, and L. Petersson.paper
Mutual CRF-GNN for few-shot learning, in CVPR, 2021. S. Tang, D. Chen, L. Bai, K. Liu, Y. Ge, and W. Ouyang.paper
Few-shot classification with feature map reconstruction networks, in CVPR, 2021. D. Wertheimer, L. Tang, and B. Hariharan.papercode
ECKPN: Explicit class knowledge propagation network for transductive few-shot learning, in CVPR, 2021. C. Chen, X. Yang, C. Xu, X. Huang, and Z. Ma.paper
Exploring complementary strengths of invariant and equivariant representations for few-shot learning, in CVPR, 2021. M. N. Rizve, S. Khan, F. S. Khan, and M. Shah.paper
Rethinking class relations: Absolute-relative supervised and unsupervised few-shot learning, in CVPR, 2021. H. Zhang, P. Koniusz, S. Jian, H. Li, and P. H. S. Torr.paper
Unsupervised embedding adaptation via early-stage feature reconstruction for few-shot classification, in ICML, 2021. D. H. Lee, and S. Chung.papercode
Learning a few-shot embedding model with contrastive learning, in AAAI, 2021. C. Liu, Y. Fu, C. Xu, S. Yang, J. Li, C. Wang, and L. Zhang.paper
Looking wider for better adaptive representation in few-shot learning, in AAAI, 2021. J. Zhao, Y. Yang, X. Lin, J. Yang, and L. He.paper
Tailoring embedding function to heterogeneous few-shot tasks by global and local feature adaptors, in AAAI, 2021. S. Lu, H. Ye, and D.-C. Zhan.paper
Knowledge guided metric learning for few-shot text classification, in NAACL-HLT, 2021. D. Sui, Y. Chen, B. Mao, D. Qiu, K. Liu, and J. Zhao.paper
Mixture-based feature space learning for few-shot image classification, in ICCV, 2021. A. Afrasiyabi, J. Lalonde, and C. Gagné.paper
Z-score normalization, hubness, and few-shot learning, in ICCV, 2021. N. Fei, Y. Gao, Z. Lu, and T. Xiang.paper
Relational embedding for few-shot classification, in ICCV, 2021. D. Kang, H. Kwon, J. Min, and M. Cho.papercode
Transductive few-shot classification on the oblique manifold, in ICCV, 2021. G. Qi, H. Yu, Z. Lu, and S. Li.papercode
Curvature generation in curved spaces for few-shot learning, in ICCV, 2021. Z. Gao, Y. Wu, Y. Jia, and M. Harandi.paper
On episodes, prototypical networks, and few-shot learning, in NeurIPS, 2021. S. Laenen, and L. Bertinetto.paper
Few-shot learning as cluster-induced voronoi diagrams: A geometric approach, in ICLR, 2022. C. Ma, Z. Huang, M. Gao, and J. Xu.papercode
Few-shot learning with siamese networks and label tuning, in ACL, 2022. T. Müller, G. Pérez-Torró, and M. Franco-Salvador.papercode
Learning to affiliate: Mutual centralized learning for few-shot classification, in CVPR, 2022. Y. Liu, W. Zhang, C. Xiang, T. Zheng, D. Cai, and X. He.paper
Matching feature sets for few-shot image classification, in CVPR, 2022. A. Afrasiyabi, H. Larochelle, J. Lalonde, and C. Gagné.papercode
Joint distribution matters: Deep Brownian distance covariance for few-shot classification, in CVPR, 2022. J. Xie, F. Long, J. Lv, Q. Wang, and P. Li.paper
CAD: Co-adapting discriminative features for improved few-shot classification, in CVPR, 2022. P. Chikontwe, S. Kim, and S. H. Park.paper
Ranking distance calibration for cross-domain few-shot learning, in CVPR, 2022. P. Li, S. Gong, C. Wang, and Y. Fu.paper
EASE: Unsupervised discriminant subspace learning for transductive few-shot learning, in CVPR, 2022. H. Zhu, and P. Koniusz.papercode
Cross-domain few-shot learning with task-specific adapters, in CVPR, 2022. W. Li, X. Liu, and H. Bilen.papercode
Learning with External Memory
Meta-learning with memory-augmented neural networks, in ICML, 2016. A. Santoro, S. Bartunov, M. Botvinick, D. Wierstra, and T. Lillicrap.paper
Few-shot object recognition from machine-labeled web images, in CVPR, 2017. Z. Xu, L. Zhu, and Y. Yang.paper
Learning to remember rare events, in ICLR, 2017. Ł. Kaiser, O. Nachum, A. Roy, and S. Bengio.paper
Meta networks, in ICML, 2017. T. Munkhdalai and H. Yu.paper
Memory matching networks for one-shot image recognition, in CVPR, 2018. Q. Cai, Y. Pan, T. Yao, C. Yan, and T. Mei.paper
Compound memory networks for few-shot video classification, in ECCV, 2018. L. Zhu and Y. Yang.paper
Memory, show the way: Memory based few shot word representation learning, in EMNLP, 2018. J. Sun, S. Wang, and C. Zong.paper
Rapid adaptation with conditionally shifted neurons, in ICML, 2018. T. Munkhdalai, X. Yuan, S. Mehri, and A. Trischler.paper
Adaptive posterior learning: Few-shot learning with a surprise-based memory module, in ICLR, 2019. T. Ramalho and M. Garnelo.papercode
Coloring with limited data: Few-shot colorization via memory augmented networks, in CVPR, 2019. S. Yoo, H. Bahng, S. Chung, J. Lee, J. Chang, and J. Choo.paper
ACMM: Aligned cross-modal memory for few-shot image and sentence matching, in ICCV, 2019. Y. Huang, and L. Wang.paper
Dynamic memory induction networks for few-shot text classification, in ACL, 2020. R. Geng, B. Li, Y. Li, J. Sun, and X. Zhu.paper
Few-shot visual learning with contextual memory and fine-grained calibration, in IJCAI, 2020. Y. Ma, W. Liu, S. Bai, Q. Zhang, A. Liu, W. Chen, and X. Liu.paper
Learn from concepts: Towards the purified memory for few-shot learning, in IJCAI, 2021. X. Liu, X. Tian, S. Lin, Y. Qu, L. Ma, W. Yuan, Z. Zhang, and Y. Xie.paper
Prototype memory and attention mechanisms for few shot image generation, in ICLR, 2022. T. Li, Z. Li, A. Luo, H. Rockwell, A. B. Farimani, and T. S. Lee.papercode
Hierarchical variational memory for few-shot learning across domains, in ICLR, 2022. Y. Du, X. Zhen, L. Shao, and C. G. M. Snoek.papercode
Remember the difference: Cross-domain few-shot semantic segmentation via meta-memory transfer, in CVPR, 2022. W. Wang, L. Duan, Y. Wang, Q. En, J. Fan, and Z. Zhang.paper
Generative Modeling
One-shot learning of object categories, TPAMI, 2006. L. Fei-Fei, R. Fergus, and P. Perona.paper
Learning to learn with compound HD models, in NeurIPS, 2011. A. Torralba, J. B. Tenenbaum, and R. R. Salakhutdinov.paper
One-shot learning with a hierarchical nonparametric bayesian model, in ICML Workshop on Unsupervised and Transfer Learning, 2012. R. Salakhutdinov, J. Tenenbaum, and A. Torralba.paper
Human-level concept learning through probabilistic program induction, Science, 2015. B. M. Lake, R. Salakhutdinov, and J. B. Tenenbaum.paper
One-shot generalization in deep generative models, in ICML, 2016. D. Rezende, I. Danihelka, K. Gregor, and D. Wierstra.paper
One-shot video object segmentation, in CVPR, 2017. S. Caelles, K.-K. Maninis, J. Pont-Tuset, L. Leal-Taixé, D. Cremers, and L. Van Gool.paper
Towards a neural statistician, in ICLR, 2017. H. Edwards and A. Storkey.paper
Extending a parser to distant domains using a few dozen partially annotated examples, in ACL, 2018. V. Joshi, M. Peters, and M. Hopkins.paper
MetaGAN: An adversarial approach to few-shot learning, in NeurIPS, 2018. R. Zhang, T. Che, Z. Ghahramani, Y. Bengio, and Y. Song.paper
Few-shot autoregressive density estimation: Towards learning to learn distributions, in ICLR, 2018. S. Reed, Y. Chen, T. Paine, A. van den Oord, S. M. A. Eslami, D. Rezende, O. Vinyals, and N. de Freitas.paper
The variational homoencoder: Learning to learn high capacity generative models from few examples, in UAI, 2018. L. B. Hewitt, M. I. Nye, A. Gane, T. Jaakkola, and J. B. Tenenbaum.paper
Meta-learning probabilistic inference for prediction, in ICLR, 2019. J. Gordon, J. Bronskill, M. Bauer, S. Nowozin, and R. Turner.paper
Variational prototyping-encoder: One-shot learning with prototypical images, in CVPR, 2019. J. Kim, T.-H. Oh, S. Lee, F. Pan, and I. S. Kweon.papercode
Variational few-shot learning, in ICCV, 2019. J. Zhang, C. Zhao, B. Ni, M. Xu, and X. Yang.paper
Infinite mixture prototypes for few-shot learning, in ICML, 2019. K. Allen, E. Shelhamer, H. Shin, and J. Tenenbaum.paper
Dual variational generation for low shot heterogeneous face recognition, in NeurIPS, 2019. C. Fu, X. Wu, Y. Hu, H. Huang, and R. He.paper
Bayesian meta sampling for fast uncertainty adaptation, in ICLR, 2020. Z. Wang, Y. Zhao, P. Yu, R. Zhang, and C. Chen.paper
Empirical Bayes transductive meta-learning with synthetic gradients, in ICLR, 2020. S. X. Hu, P. G. Moreno, Y. Xiao, X. Shen, G. Obozinski, N. D. Lawrence, and A. C. Damianou.paper
Few-shot relation extraction via bayesian meta-learning on relation graphs, in ICML, 2020. M. Qu, T. Gao, L. A. C. Xhonneux, and J. Tang.papercode
Interventional few-shot learning, in NeurIPS, 2020. Z. Yue, H. Zhang, Q. Sun, and X. Hua.papercode
Bayesian few-shot classification with one-vs-each pólya-gamma augmented gaussian processes, in ICLR, 2021. J. Snell, and R. Zemel.paper
Few-shot Bayesian optimization with deep kernel surrogates, in ICLR, 2021. M. Wistuba, and J. Grabocka.paper
Modeling the probabilistic distribution of unlabeled data for one-shot medical image segmentation, in AAAI, 2021. Y. Ding, X. Yu, and Y. Yang.papercode
A hierarchical transformation-discriminating generative model for few shot anomaly detection, in ICCV, 2021. S. Sheynin, S. Benaim, and L. Wolf.paper
Reinforced few-shot acquisition function learning for Bayesian optimization, in NeurIPS, 2021. B. Hsieh, P. Hsieh, and X. Liu.paper
GanOrCon: Are generative models useful for few-shot segmentation?, in CVPR, 2022. O. Saha, Z. Cheng, and S. Maji.paper
Few shot generative model adaption via relaxed spatial structural alignment, in CVPR, 2022. J. Xiao, L. Li, C. Wang, Z. Zha, and Q. Huang.paper
Cross-generalization: Learning novel classes from a single example by feature replacement, in CVPR, 2005. E. Bart and S. Ullman.paper
One-shot adaptation of supervised deep convolutional models, in ICLR, 2013. J. Hoffman, E. Tzeng, J. Donahue, Y. Jia, K. Saenko, and T. Darrell.paper
Learning to learn: Model regression networks for easy small sample learning, in ECCV, 2016. Y.-X. Wang and M. Hebert.paper
Learning from small sample sets by combining unsupervised meta-training with CNNs, in NeurIPS, 2016. Y.-X. Wang and M. Hebert.paper
Efficient k-shot learning with regularized deep networks, in AAAI, 2018. D. Yoo, H. Fan, V. N. Boddeti, and K. M. Kitani.paper
CLEAR: Cumulative learning for one-shot one-class image recognition, in CVPR, 2018. J. Kozerawski and M. Turk.paper
Learning structure and strength of CNN filters for small sample size training, in CVPR, 2018. R. Keshari, M. Vatsa, R. Singh, and A. Noore.paper
Dynamic few-shot visual learning without forgetting, in CVPR, 2018. S. Gidaris and N. Komodakis.papercode
Low-shot learning with imprinted weights, in CVPR, 2018. H. Qi, M. Brown, and D. G. Lowe.paper
Neural voice cloning with a few samples, in NeurIPS, 2018. S. Arik, J. Chen, K. Peng, W. Ping, and Y. Zhou.paper
Text classification with few examples using controlled generalization, in NAACL-HLT, 2019. A. Mahabal, J. Baldridge, B. K. Ayan, V. Perot, and D. Roth.paper
Low shot box correction for weakly supervised object detection, in IJCAI, 2019. T. Pan, B. Wang, G. Ding, J. Han, and J. Yong.paper
Diversity with cooperation: Ensemble methods for few-shot classification, in ICCV, 2019. N. Dvornik, C. Schmid, and J. Mairal.paper
Few-shot image recognition with knowledge transfer, in ICCV, 2019. Z. Peng, Z. Li, J. Zhang, Y. Li, G.-J. Qi, and J. Tang.paper
Generating classification weights with gnn denoising autoencoders for few-shot learning, in CVPR, 2019. S. Gidaris, and N. Komodakis.papercode
Dense classification and implanting for few-shot learning, in CVPR, 2019. Y. Lifchitz, Y. Avrithis, S. Picard, and A. Bursuc.paper
Few-shot adaptive faster R-CNN, in CVPR, 2019. T. Wang, X. Zhang, L. Yuan, and J. Feng.paper
TransMatch: A transfer-learning scheme for semi-supervised few-shot learning, in CVPR, 2020. Z. Yu, L. Chen, Z. Cheng, and J. Luo.paper
Learning to select base classes for few-shot classification, in CVPR, 2020. L. Zhou, P. Cui, X. Jia, S. Yang, and Q. Tian.paper
Few-shot NLG with pre-trained language model, in ACL, 2020. Z. Chen, H. Eavani, W. Chen, Y. Liu, and W. Y. Wang.papercode
Span-ConveRT: Few-shot span extraction for dialog with pretrained conversational representations, in ACL, 2020. S. Coope, T. Farghly, D. Gerz, I. Vulic, and M. Henderson.paper
Structural supervision improves few-shot learning and syntactic generalization in neural language models, in EMNLP, 2020. E. Wilcox, P. Qian, R. Futrell, R. Kohita, R. Levy, and M. Ballesteros.papercode
A baseline for few-shot image classification, in ICLR, 2020. G. S. Dhillon, P. Chaudhari, A. Ravichandran, and S. Soatto.paper
Cross-domain few-shot classification via learned feature-wise transformation, in ICLR, 2020. H. Tseng, H. Lee, J. Huang, and M. Yang.papercode
Graph few-shot learning via knowledge transfer, in AAAI, 2020. H. Yao, C. Zhang, Y. Wei, M. Jiang, S. Wang, J. Huang, N. V. Chawla, and Z. Li.paper
Knowledge graph transfer network for few-shot recognition, in AAAI, 2020. R. Chen, T. Chen, X. Hui, H. Wu, G. Li, and L. Lin.paper
Context-Transformer: Tackling object confusion for few-shot detection, in AAAI, 2020. Z. Yang, Y. Wang, X. Chen, J. Liu, and Y. Qiao.paper
A broader study of cross-domain few-shot learning, in ECCV, 2020. Y. Guo, N. C. Codella, L. Karlinsky, J. V. Codella, J. R. Smith, K. Saenko, T. Rosing, and R. Feris.papercode
Selecting relevant features from a multi-domain representation for few-shot classification, in ECCV, 2020. N. Dvornik, C. Schmid, and J. Mairal.papercode
Prototype completion with primitive knowledge for few-shot learning, in CVPR, 2021. B. Zhang, X. Li, Y. Ye, Z. Huang, and L. Zhang.papercode
Partial is better than all: Revisiting fine-tuning strategy for few-shot learning, in AAAI, 2021. Z. Shen, Z. Liu, J. Qin, M. Savvides, and K.-T. Cheng.paper
PTN: A poisson transfer network for semi-supervised few-shot learning, in AAAI, 2021. H. Huang, J. Zhang, J. Zhang, Q. Wu, and C. Xu.paper
A universal representation transformer layer for few-shot image classification, in ICLR, 2021. L. Liu, W. L. Hamilton, G. Long, J. Jiang, and H. Larochelle.paper
Making pre-trained language models better few-shot learners, in ACL-IJCNLP, 2021. T. Gao, A. Fisch, and D. Chen.papercode
Self-supervised network evolution for few-shot classification, in IJCAI, 2021. X. Tang, Z. Teng, B. Zhang, and J. Fan.paper
Calibrate before use: Improving few-shot performance of language models, in ICML, 2021. Z. Zhao, E. Wallace, S. Feng, D. Klein, and S. Singh.papercode
Language models are few-shot learners, in NeurIPS, 2020. T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei.paper
It’s not just size that matters: Small language models are also few-shot learners, in NAACL-HLT, 2021. T. Schick, and H. Schütze.papercode
Self-training improves pre-training for few-shot learning in task-oriented dialog systems, in EMNLP, 2021. F. Mi, W. Zhou, L. Kong, F. Cai, M. Huang, and B. Faltings.paper
Few-shot intent detection via contrastive pre-training and fine-tuning, in EMNLP, 2021. J. Zhang, T. Bui, S. Yoon, X. Chen, Z. Liu, C. Xia, Q. H. Tran, W. Chang, and P. S. Yu.papercode
Avoiding inference heuristics in few-shot prompt-based finetuning, in EMNLP, 2021. P. A. Utama, N. S. Moosavi, V. Sanh, and I. Gurevych.papercode
Constrained language models yield few-shot semantic parsers, in EMNLP, 2021. R. Shin, C. H. Lin, S. Thomson, C. Chen, S. Roy, E. A. Platanios, A. Pauls, D. Klein, J. Eisner, and B. V. Durme.papercode
Revisiting self-training for few-shot learning of language model, in EMNLP, 2021. Y. Chen, Y. Zhang, C. Zhang, G. Lee, R. Cheng, and H. Li.papercode
Language models are few-shot butlers, in EMNLP, 2021. V. Micheli, and F. Fleuret.papercode
FewshotQA: A simple framework for few-shot learning of question answering tasks using pre-trained text-to-text models, in EMNLP, 2021. R. Chada, and P. Natarajan.paper
TransPrompt: Towards an automatic transferable prompting framework for few-shot text classification, in EMNLP, 2021. C. Wang, J. Wang, M. Qiu, J. Huang, and M. Gao.paper
Meta distant transfer learning for pre-trained language models, in EMNLP, 2021. C. Wang, H. Pan, M. Qiu, J. Huang, F. Yang, and Y. Zhang.paper
STraTA: Self-training with task augmentation for better few-shot learning, in EMNLP, 2021. T. Vu, M. Luong, Q. V. Le, G. Simon, and M. Iyyer.papercode
Few-shot image classification: Just use a library of pre-trained feature extractors and a simple classifier, in ICCV, 2021. A. Chowdhury, M. Jiang, S. Chaudhuri, and C. Jermaine.papercode
On the importance of distractors for few-shot classification, in ICCV, 2021. R. Das, Y. Wang, and J. M. F. Moura.papercode
A multi-mode modulator for multi-domain few-shot classification, in ICCV, 2021. Y. Liu, J. Lee, L. Zhu, L. Chen, H. Shi, and Y. Yang.paper
Universal representation learning from multiple domains for few-shot classification, in ICCV, 2021. W. Li, X. Liu, and H. Bilen.papercode
Boosting the generalization capability in cross-domain few-shot learning via noise-enhanced supervised autoencoder, in ICCV, 2021. H. Liang, Q. Zhang, P. Dai, and J. Lu.paper
How fine-tuning allows for effective meta-learning, in NeurIPS, 2021. K. Chua, Q. Lei, and J. D. Lee.paper
Multimodal few-shot learning with frozen language models, in NeurIPS, 2021. M. Tsimpoukelli, J. Menick, S. Cabi, S. M. A. Eslami, O. Vinyals, and F. Hill.paper
Grad2Task: Improved few-shot text classification using gradients for task representation, in NeurIPS, 2021. J. Wang, K. Wang, F. Rudzicz, and M. Brudno.paper
True few-shot learning with language models, in NeurIPS, 2021. E. Perez, D. Kiela, and K. Cho.paper
POODLE: Improving few-shot learning via penalizing out-of-distribution samples, in NeurIPS, 2021. D. Le, K. Nguyen, Q. Tran, R. Nguyen, and B. Hua.paper
TOHAN: A one-step approach towards few-shot hypothesis adaptation, in NeurIPS, 2021. H. Chi, F. Liu, W. Yang, L. Lan, T. Liu, B. Han, W. Cheung, and J. Kwok.paper
Task affinity with maximum bipartite matching in few-shot learning, in ICLR, 2022. C. P. Le, J. Dong, M. Soltani, and V. Tarokh.paper
Differentiable prompt makes pre-trained language models better few-shot learners, in ICLR, 2022. N. Zhang, L. Li, X. Chen, S. Deng, Z. Bi, C. Tan, F. Huang, and H. Chen.papercode
ConFeSS: A framework for single source cross-domain few-shot learning, in ICLR, 2022. D. Das, S. Yun, and F. Porikli.paper
Switch to generalize: Domain-switch learning for cross-domain few-shot classification, in ICLR, 2022. Z. Hu, Y. Sun, and Y. Yang.paper
LM-BFF-MS: Improving few-shot fine-tuning of language models based on multiple soft demonstration memory, in ACL, 2022. E. Park, D. H. Jeon, S. Kim, I. Kang, and S. Na.papercode
Meta-learning via language model in-context tuning, in ACL, 2022. Y. Chen, R. Zhong, S. Zha, G. Karypis, and H. He.papercode
Few-shot tabular data enrichment using fine-tuned transformer architectures, in ACL, 2022. A. Harari, and G. Katz.paper
Noisy channel language model prompting for few-shot text classification, in ACL, 2022. S. Min, M. Lewis, H. Hajishirzi, and L. Zettlemoyer.papercode
Prompt for extraction? PAIE: Prompting argument interaction for event argument extraction, in ACL, 2022. Y. Ma, Z. Wang, Y. Cao, M. Li, M. Chen, K. Wang, and J. Shao.papercode
Are prompt-based models clueless?, in ACL, 2022. P. Kavumba, R. Takahashi, and Y. Oda.paper
Prototypical verbalizer for prompt-based few-shot tuning, in ACL, 2022. G. Cui, S. Hu, N. Ding, L. Huang, and Z. Liu.papercode
Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity, in ACL, 2022. Y. Lu, M. Bartolo, A. Moore, S. Riedel, and P. Stenetorp.paper
PPT: Pre-trained prompt tuning for few-shot learning, in ACL, 2022. Y. Gu, X. Han, Z. Liu, and M. Huang.papercode
ASCM: An answer space clustered prompting method without answer engineering, in Findings of ACL, 2022. Z. Wang, Y. Yang, Z. Xi, B. Ma, L. Wang, R. Dong, and A. Anwar.papercode
Exploiting language model prompts using similarity measures: A case study on the word-in-context task, in ACL, 2022. M. Tabasi, K. Rezaee, and M. T. Pilehvar.paper
P-Tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks, in ACL, 2022. X. Liu, K. Ji, Y. Fu, W. Tam, Z. Du, Z. Yang, and J. Tang.paper
Cutting down on prompts and parameters: Simple few-shot learning with language models, in Findings of ACL, 2022. R. L. L. IV, I. Balazevic, E. Wallace, F. Petroni, S. Singh, and S. Riedel.papercode
Prompt-free and efficient few-shot learning with language models, in ACL, 2022. R. K. Mahabadi, L. Zettlemoyer, J. Henderson, L. Mathias, M. Saeidi, V. Stoyanov, and M. Yazdani.papercode
Pre-training to match for unified low-shot relation extraction, in ACL, 2022. F. Liu, H. Lin, X. Han, B. Cao, and L. Sun.papercode
Dual context-guided continuous prompt tuning for few-shot learning, in Findings of ACL, 2022. J. Zhou, L. Tian, H. Yu, Z. Xiao, H. Su, and J. Zhou.paper
Cluster & tune: Boost cold start performance in text classification, in ACL, 2022. E. Shnarch, A. Gera, A. Halfon, L. Dankin, L. Choshen, R. Aharonov, and N. Slonim.papercode
Pushing the limits of simple pipelines for few-shot learning: External data and fine-tuning make a difference, in CVPR, 2022. S. X. Hu, D. Li, J. Stühmer, M. Kim, and T. M. Hospedales.papercode
Refining Meta-learned Parameters
Model-agnostic meta-learning for fast adaptation of deep networks, in ICML, 2017. C. Finn, P. Abbeel, and S. Levine.paper
Bayesian model-agnostic meta-learning, in NeurIPS, 2018. J. Yoon, T. Kim, O. Dia, S. Kim, Y. Bengio, and S. Ahn.paper
Probabilistic model-agnostic meta-learning, in NeurIPS, 2018. C. Finn, K. Xu, and S. Levine.paper
Gradient-based meta-learning with learned layerwise metric and subspace, in ICML, 2018. Y. Lee and S. Choi.paper
Recasting gradient-based meta-learning as hierarchical Bayes, in ICLR, 2018. E. Grant, C. Finn, S. Levine, T. Darrell, and T. Griffiths.paper
Few-shot human motion prediction via meta-learning, in ECCV, 2018. L.-Y. Gui, Y.-X. Wang, D. Ramanan, and J. Moura.paper
The effects of negative adaptation in model-agnostic meta-learning, arXiv preprint, 2018. T. Deleu and Y. Bengio.paper
Unsupervised meta-learning for few-shot image classification, in NeurIPS, 2019. S. Khodadadeh, L. Bölöni, and M. Shah.paper
Amortized bayesian meta-learning, in ICLR, 2019. S. Ravi and A. Beatson.paper
Meta-learning with latent embedding optimization, in ICLR, 2019. A. A. Rusu, D. Rao, J. Sygnowski, O. Vinyals, R. Pascanu, S. Osindero, and R. Hadsell.papercode
Meta relational learning for few-shot link prediction in knowledge graphs, in EMNLP-IJCNLP, 2019. M. Chen, W. Zhang, W. Zhang, Q. Chen, and H. Chen.paper
Adapting meta knowledge graph information for multi-hop reasoning over few-shot relations, in EMNLP-IJCNLP, 2019. X. Lv, Y. Gu, X. Han, L. Hou, J. Li, and Z. Liu.paper
LGM-Net: Learning to generate matching networks for few-shot learning, in ICML, 2019. H. Li, W. Dong, X. Mei, C. Ma, F. Huang, and B.-G. Hu.papercode
Meta R-CNN: Towards general solver for instance-level low-shot learning, in ICCV, 2019. X. Yan, Z. Chen, A. Xu, X. Wang, X. Liang, and L. Lin.paper
Task agnostic meta-learning for few-shot learning, in CVPR, 2019. M. A. Jamal, and G.-J. Qi.paper
Meta-transfer learning for few-shot learning, in CVPR, 2019. Q. Sun, Y. Liu, T.-S. Chua, and B. Schiele.papercode
Meta-learning of neural architectures for few-shot learning, in CVPR, 2020. T. Elsken, B. Staffler, J. H. Metzen, and F. Hutter.paper
Attentive weights generation for few shot learning via information maximization, in CVPR, 2020. Y. Guo, and N.-M. Cheung.paper
Few-shot open-set recognition using meta-learning, in CVPR, 2020. B. Liu, H. Kang, H. Li, G. Hua, and N. Vasconcelos.paper
Incremental few-shot object detection, in CVPR, 2020. J.-M. Perez-Rua, X. Zhu, T. M. Hospedales, and T. Xiang.paper
Automated relational meta-learning, in ICLR, 2020. H. Yao, X. Wu, Z. Tao, Y. Li, B. Ding, R. Li, and Z. Li.paper
Meta-learning with warped gradient descent, in ICLR, 2020. S. Flennerhag, A. A. Rusu, R. Pascanu, F. Visin, H. Yin, and R. Hadsell.paper
Meta-learning without memorization, in ICLR, 2020. M. Yin, G. Tucker, M. Zhou, S. Levine, and C. Finn.paper
ES-MAML: Simple Hessian-free meta learning, in ICLR, 2020. X. Song, W. Gao, Y. Yang, K. Choromanski, A. Pacchiano, and Y. Tang.paper
Self-supervised tuning for few-shot segmentation, in IJCAI, 2020. K. Zhu, W. Zhai, and Y. Cao.paper
Multi-attention meta learning for few-shot fine-grained image recognition, in IJCAI, 2020. Y. Zhu, C. Liu, and S. Jiang.paper
An ensemble of epoch-wise empirical Bayes for few-shot learning, in ECCV, 2020. Y. Liu, B. Schiele, and Q. Sun.papercode
Incremental few-shot meta-learning via indirect discriminant alignment, in ECCV, 2020. Q. Liu, O. Majumder, A. Achille, A. Ravichandran, R. Bhotika, and S. Soatto.paper
Model-agnostic boundary-adversarial sampling for test-time generalization in few-shot learning, in ECCV, 2020. J. Kim, H. Kim, and G. Kim.papercode
Bayesian meta-learning for the few-shot setting via deep kernels, in NeurIPS, 2020. M. Patacchiola, J. Turner, E. J. Crowley, M. O’Boyle, and A. J. Storkey.papercode
OOD-MAML: Meta-learning for few-shot out-of-distribution detection and classification, in NeurIPS, 2020. T. Jeong, and H. Kim.papercode
Unraveling meta-learning: Understanding feature representations for few-shot tasks, in ICML, 2020. M. Goldblum, S. Reich, L. Fowl, R. Ni, V. Cherepanova, and T. Goldstein.papercode
Node classification on graphs with few-shot novel labels via meta transformed network embedding, in NeurIPS, 2020. L. Lan, P. Wang, X. Du, K. Song, J. Tao, and X. Guan.paper
Adversarially robust few-shot learning: A meta-learning approach, in NeurIPS, 2020. M. Goldblum, L. Fowl, and T. Goldstein.papercode
BOIL: Towards representation change for few-shot learning, in ICLR, 2021. J. Oh, H. Yoo, C. Kim, and S. Yun.papercode
Few-shot open-set recognition by transformation consistency, in CVPR, 2021. M. Jeong, S. Choi, and C. Kim.paper
Improving generalization in meta-learning via task augmentation, in ICML, 2021. H. Yao, L. Huang, L. Zhang, Y. Wei, L. Tian, J. Zou, J. Huang, and Z. Li.paper
A representation learning perspective on the importance of train-validation splitting in meta-learning, in ICML, 2021. N. Saunshi, A. Gupta, and W. Hu.papercode
Data augmentation for meta-learning, in ICML, 2021. R. Ni, M. Goldblum, A. Sharaf, K. Kong, and T. Goldstein.papercode
Task cooperation for semi-supervised few-shot learning, in AAAI, 2021. H. Ye, X. Li, and D.-C. Zhan.paper
Conditional self-supervised learning for few-shot classification, in IJCAI, 2021. Y. An, H. Xue, X. Zhao, and L. Zhang.paper
Cross-domain few-shot classification via adversarial task augmentation, in IJCAI, 2021. H. Wang, and Z.-H. Deng.papercode
DReCa: A general task augmentation strategy for few-shot natural language inference, in NAACL-HLT, 2021. S. Murty, T. Hashimoto, and C. D. Manning.paper
MetaXL: Meta representation transformation for low-resource cross-lingual learning, in NAACL-HLT, 2021. M. Xia, G. Zheng, S. Mukherjee, M. Shokouhi, G. Neubig, and A. H. Awadallah.papercode
Meta-learning with task-adaptive loss function for few-shot learning, in ICCV, 2021. S. Baik, J. Choi, H. Kim, D. Cho, J. Min, and K. M. Lee.papercode
Meta-Baseline: Exploring simple meta-learning for few-shot learning, in ICCV, 2021. Y. Chen, Z. Liu, H. Xu, T. Darrell, and X. Wang.paper
A lazy approach to long-horizon gradient-based meta-learning, in ICCV, 2021. M. A. Jamal, L. Wang, and B. Gong.paper
Task-aware part mining network for few-shot learning, in ICCV, 2021. J. Wu, T. Zhang, Y. Zhang, and F. Wu.paper
Binocular mutual learning for improving few-shot classification, in ICCV, 2021. Z. Zhou, X. Qiu, J. Xie, J. Wu, and C. Zhang.papercode
Meta-learning with an adaptive task scheduler, in NeurIPS, 2021. H. Yao, Y. Wang, Y. Wei, P. Zhao, M. Mahdavi, D. Lian, and C. Finn.paper
Memory efficient meta-learning with large images, in NeurIPS, 2021. J. Bronskill, D. Massiceti, M. Patacchiola, K. Hofmann, S. Nowozin, and R. Turner.paper
EvoGrad: Efficient gradient-based meta-learning and hyperparameter optimization, in NeurIPS, 2021. O. Bohdal, Y. Yang, and T. Hospedales.paper
Towards enabling meta-learning from target models, in NeurIPS, 2021. S. Lu, H. Ye, L. Gan, and D. Zhan.paper
The role of global labels in few-shot classification and how to infer them, in NeurIPS, 2021. R. Wang, M. Pontil, and C. Ciliberto.paper
How to train your MAML to excel in few-shot classification, in ICLR, 2022. H. Ye, and W. Chao.papercode
Meta-learning with fewer tasks through task interpolation, in ICLR, 2022. H. Yao, L. Zhang, and C. Finn.papercode
Continuous-time meta-learning with forward mode differentiation, in ICLR, 2022. T. Deleu, D. Kanaa, L. Feng, G. Kerg, Y. Bengio, G. Lajoie, and P. Bacon.paper
Bootstrapped meta-learning, in ICLR, 2022. S. Flennerhag, Y. Schroecker, T. Zahavy, H. v. Hasselt, D. Silver, and S. Singh.paper
Learning prototype-oriented set representations for meta-learning, in ICLR, 2022. D. d. Guo, L. Tian, M. Zhang, M. Zhou, and H. Zha.paper
Dynamic kernel selection for improved generalization and memory efficiency in meta-learning, in CVPR, 2022. A. Chavan, R. Tiwari, U. Bamba, and D. K. Gupta.papercode
What matters for meta-learning vision regression tasks?, in CVPR, 2022. N. Gao, H. Ziesche, N. A. Vien, M. Volpp, and G. Neumann.papercode
Multidimensional belief quantification for label-efficient meta-learning, in CVPR, 2022. D. S. Pandey, and Q. Yu.paper
Learning Search Steps
Optimization as a model for few-shot learning, in ICLR, 2017. S. Ravi and H. Larochelle.papercode
Meta Navigator: Search for a good adaptation policy for few-shot learning, in ICCV, 2021. C. Zhang, H. Ding, G. Lin, R. Li, C. Wang, and C. Shen.paper
Learning robust visual-semantic embeddings, in CVPR, 2017. Y.-H. Tsai, L.-K. Huang, and R. Salakhutdinov.paper
One-shot action localization by learning sequence matching network, in CVPR, 2018. H. Yang, X. He, and F. Porikli.paper
Incremental few-shot learning for pedestrian attribute recognition, in EMNLP, 2018. L. Xiang, X. Jin, G. Ding, J. Han, and L. Li.paper
Few-shot video-to-video synthesis, in NeurIPS, 2019. T.-C. Wang, M.-Y. Liu, A. Tao, G. Liu, J. Kautz, and B. Catanzaro.papercode
Few-shot object detection via feature reweighting, in ICCV, 2019. B. Kang, Z. Liu, X. Wang, F. Yu, J. Feng, and T. Darrell.papercode
Few-shot unsupervised image-to-image translation, in ICCV, 2019. M.-Y. Liu, X. Huang, A. Mallya, T. Karras, T. Aila, J. Lehtinen, and J. Kautz.papercode
Feature weighting and boosting for few-shot segmentation, in ICCV, 2019. K. Nguyen, and S. Todorovic.paper
Few-shot adaptive gaze estimation, in ICCV, 2019. S. Park, S. D. Mello, P. Molchanov, U. Iqbal, O. Hilliges, and J. Kautz.paper
AMP: Adaptive masked proxies for few-shot segmentation, in ICCV, 2019. M. Siam, B. N. Oreshkin, and M. Jagersand.papercode
Few-shot generalization for single-image 3D reconstruction via priors, in ICCV, 2019. B. Wallace, and B. Hariharan.paper
Few-shot adversarial learning of realistic neural talking head models, in ICCV, 2019. E. Zakharov, A. Shysheya, E. Burkov, and V. Lempitsky.papercode
Pyramid graph networks with connection attentions for region-based one-shot semantic segmentation, in ICCV, 2019. C. Zhang, G. Lin, F. Liu, J. Guo, Q. Wu, and R. Yao.paper
Time-conditioned action anticipation in one shot, in CVPR, 2019. Q. Ke, M. Fritz, and B. Schiele.paper
Few-shot learning with localization in realistic settings, in CVPR, 2019. D. Wertheimer, and B. Hariharan.papercode
Improving few-shot user-specific gaze adaptation via gaze redirection synthesis, in CVPR, 2019. Y. Yu, G. Liu, and J.-M. Odobez.paper
CANet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning, in CVPR, 2019. C. Zhang, G. Lin, F. Liu, R. Yao, and C. Shen.papercode
Multi-level Semantic Feature Augmentation for One-shot Learning, in TIP, 2019. Z. Chen, Y. Fu, Y. Zhang, Y.-G. Jiang, X. Xue, and L. Sigal.papercode
Few-shot pill recognition, in CVPR, 2020. S. Ling, A. Pastor, J. Li, Z. Che, J. Wang, J. Kim, and P. L. Callet.paper
LT-Net: Label transfer by learning reversible voxel-wise correspondence for one-shot medical image segmentation, in CVPR, 2020. S. Wang, S. Cao, D. Wei, R. Wang, K. Ma, L. Wang, D. Meng, and Y. Zheng.paper
3FabRec: Fast few-shot face alignment by reconstruction, in CVPR, 2020. B. Browatzki, and C. Wallraven.paper
Few-shot video classification via temporal alignment, in CVPR, 2020. K. Cao, J. Ji, Z. Cao, C.-Y. Chang, J. C. Niebles.paper
One-shot adversarial attacks on visual tracking with dual attention, in CVPR, 2020. X. Chen, X. Yan, F. Zheng, Y. Jiang, S.-T. Xia, Y. Zhao, and R. Ji.paper
FGN: Fully guided network for few-shot instance segmentation, in CVPR, 2020. Z. Fan, J.-G. Yu, Z. Liang, J. Ou, C. Gao, G.-S. Xia, and Y. Li.paper
CRNet: Cross-reference networks for few-shot segmentation, in CVPR, 2020. W. Liu, C. Zhang, G. Lin, and F. Liu.paper
Revisiting pose-normalization for fine-grained few-shot recognition, in CVPR, 2020. L. Tang, D. Wertheimer, and B. Hariharan.paper
Few-shot learning of part-specific probability space for 3D shape segmentation, in CVPR, 2020. L. Wang, X. Li, and Y. Fang.paper
Semi-supervised learning for few-shot image-to-image translation, in CVPR, 2020. Y. Wang, S. Khan, A. Gonzalez-Garcia, J. van de Weijer, and F. S. Khan.paper
Multi-domain learning for accurate and few-shot color constancy, in CVPR, 2020. J. Xiao, S. Gu, and L. Zhang.paper
One-shot domain adaptation for face generation, in CVPR, 2020. C. Yang, and S.-N. Lim.paper
MetaPix: Few-shot video retargeting, in ICLR, 2020. J. Lee, D. Ramanan, and R. Girdhar.paper
Few-shot human motion prediction via learning novel motion dynamics, in IJCAI, 2020. C. Zang, M. Pei, and Y. Kong.paper
Shaping visual representations with language for few-shot classification, in ACL, 2020. J. Mu, P. Liang, and N. D. Goodman.paper
MarioNETte: Few-shot face reenactment preserving identity of unseen targets, in AAAI, 2020. S. Ha, M. Kersner, B. Kim, S. Seo, and D. Kim.paper
One-shot learning for long-tail visual relation detection, in AAAI, 2020. W. Wang, M. Wang, S. Wang, G. Long, L. Yao, G. Qi, and Y. Chen.papercode
Differentiable meta-learning model for few-shot semantic segmentation, in AAAI, 2020. P. Tian, Z. Wu, L. Qi, L. Wang, Y. Shi, and Y. Gao.paper
Part-aware prototype network for few-shot semantic segmentation, in ECCV, 2020. Y. Liu, X. Zhang, S. Zhang, and X. He.papercode
Prototype mixture models for few-shot semantic segmentation, in ECCV, 2020. B. Yang, C. Liu, B. Li, J. Jiao, and Q. Ye.papercode
Self-supervision with superpixels: Training few-shot medical image segmentation without annotation, in ECCV, 2020. C. Ouyang, C. Biffi, C. Chen, T. Kart, H. Qiu, and D. Rueckert.papercode
Few-shot action recognition with permutation-invariant attention, in ECCV, 2020. H. Zhang, L. Zhang, X. Qi, H. Li, P. H. S. Torr, and P. Koniusz.paper
Few-shot compositional font generation with dual memory, in ECCV, 2020. J. Cha, S. Chun, G. Lee, B. Lee, S. Kim, and H. Lee.papercode
Few-shot object detection and viewpoint estimation for objects in the wild, in ECCV, 2020. Y. Xiao, and R. Marlet.paper
Few-shot scene-adaptive anomaly detection, in ECCV, 2020. Y. Lu, F. Yu, M. K. K. Reddy, and Y. Wang.papercode
Few-shot semantic segmentation with democratic attention networks, in ECCV, 2020. H. Wang, X. Zhang, Y. Hu, Y. Yang, X. Cao, and X. Zhen.paper
Few-shot single-view 3-D object reconstruction with compositional priors, in ECCV, 2020. M. Michalkiewicz, S. Parisot, S. Tsogkas, M. Baktashmotlagh, A. Eriksson, and E. Belilovsky.paper
COCO-FUNIT: Few-shot unsupervised image translation with a content conditioned style encoder, in ECCV, 2020. K. Saito, K. Saenko, and M. Liu.papercode
Deep complementary joint model for complex scene registration and few-shot segmentation on medical images, in ECCV, 2020. Y. He, T. Li, G. Yang, Y. Kong, Y. Chen, H. Shu, J. Coatrieux, J. Dillenseger, and S. Li.paper
Multi-scale positive sample refinement for few-shot object detection, in ECCV, 2020. J. Wu, S. Liu, D. Huang, and Y. Wang.papercode
Large-scale few-shot learning via multi-modal knowledge discovery, in ECCV, 2020. S. Wang, J. Yue, J. Liu, Q. Tian, and M. Wang.paper
Graph convolutional networks for learning with few clean and many noisy labels, in ECCV, 2020. A. Iscen, G. Tolias, Y. Avrithis, O. Chum, and C. Schmid.paper
Self-supervised few-shot learning on point clouds, in NeurIPS, 2020. C. Sharma, and M. Kaul.papercode
Restoring negative information in few-shot object detection, in NeurIPS, 2020. Y. Yang, F. Wei, M. Shi, and G. Li.papercode
Few-shot image generation with elastic weight consolidation, in NeurIPS, 2020. Y. Li, R. Zhang, J. Lu, and E. Shechtman.paper
Few-shot visual reasoning with meta-analogical contrastive learning, in NeurIPS, 2020. Y. Kim, J. Shin, E. Yang, and S. J. Hwang.paper
CrossTransformers: spatially-aware few-shot transfer, in NeurIPS, 2020. C. Doersch, A. Gupta, and A. Zisserman.paper
Make one-shot video object segmentation efficient again, in NeurIPS, 2020. T. Meinhardt, and L. Leal-Taixé.papercode
Frustratingly simple few-shot object detection, in ICML, 2020. X. Wang, T. E. Huang, J. Gonzalez, T. Darrell, and F. Yu.papercode
Adversarial style mining for one-shot unsupervised domain adaptation, in NeurIPS, 2020. Y. Luo, P. Liu, T. Guan, J. Yu, and Y. Yang.papercode
Disentangling 3D prototypical networks for few-shot concept learning, in ICLR, 2021. M. Prabhudesai, S. Lal, D. Patil, H. Tung, A. W. Harley, and K. Fragkiadaki.paper
Learning normal dynamics in videos with meta prototype network, in CVPR, 2021. H. Lv, C. Chen, Z. Cui, C. Xu, Y. Li, and J. Yang.papercode
Learning dynamic alignment via meta-filter for few-shot learning, in CVPR, 2021. C. Xu, Y. Fu, C. Liu, C. Wang, J. Li, F. Huang, L. Zhang, and X. Xue.paper
Delving deep into many-to-many attention for few-shot video object segmentation, in CVPR, 2021. H. Chen, H. Wu, N. Zhao, S. Ren, and S. He.papercode
Adaptive prototype learning and allocation for few-shot segmentation, in CVPR, 2021. G. Li, V. Jampani, L. Sevilla-Lara, D. Sun, J. Kim, and J. Kim.papercode
FAPIS: A few-shot anchor-free part-based instance segmenter, in CVPR, 2021. K. Nguyen, and S. Todorovic.paper
FSCE: Few-shot object detection via contrastive proposal encoding, in CVPR, 2021. B. Sun, B. Li, S. Cai, Y. Yuan, and C. Zhang.papercode
Few-shot 3D point cloud semantic segmentation, in CVPR, 2021. N. Zhao, T. Chua, and G. H. Lee.papercode
Generalized few-shot object detection without forgetting, in CVPR, 2021. Z. Fan, Y. Ma, Z. Li, and J. Sun.paper
Few-shot human motion transfer by personalized geometry and texture modeling, in CVPR, 2021. Z. Huang, X. Han, J. Xu, and T. Zhang.papercode
Labeled from unlabeled: Exploiting unlabeled data for few-shot deep HDR deghosting, in CVPR, 2021. K. R. Prabhakar, G. Senthil, S. Agrawal, R. V. Babu, and R. K. S. S. Gorthi.paper
Few-shot transformation of common actions into time and space, in CVPR, 2021. P. Yang, P. Mettes, and C. G. M. Snoek.papercode
Temporal-relational CrossTransformers for few-shot action recognition, in CVPR, 2021. T. Perrett, A. Masullo, T. Burghardt, M. Mirmehdi, and D. Damen.paper
pixelNeRF: Neural radiance fields from one or few images, in CVPR, 2021. A. Yu, V. Ye, M. Tancik, and A. Kanazawa.papercode
Hallucination improves few-shot object detection, in CVPR, 2021. W. Zhang, and Y. Wang.paper
Few-shot object detection via classification refinement and distractor retreatment, in CVPR, 2021. Y. Li, H. Zhu, Y. Cheng, W. Wang, C. S. Teo, C. Xiang, P. Vadakkepat, and T. H. Lee.paper
Dense relation distillation with context-aware aggregation for few-shot object detection, in CVPR, 2021. H. Hu, S. Bai, A. Li, J. Cui, and L. Wang.papercode
Few-shot segmentation without meta-learning: A good transductive inference is all you need? , in CVPR, 2021. M. Boudiaf, H. Kervadec, Z. I. Masud, P. Piantanida, I. B. Ayed, and J. Dolz.papercode
Few-shot image generation via cross-domain correspondence, in CVPR, 2021. U. Ojha, Y. Li, J. Lu, A. A. Efros, Y. J. Lee, E. Shechtman, and R. Zhang.paper
Self-guided and cross-guided learning for few-shot segmentation, in CVPR, 2021. B. Zhang, J. Xiao, and T. Qin.papercode
Anti-aliasing semantic reconstruction for few-shot semantic segmentation, in CVPR, 2021. B. Liu, Y. Ding, J. Jiao, X. Ji, and Q. Ye.paper
Beyond max-margin: Class margin equilibrium for few-shot object detection, in CVPR, 2021. B. Li, B. Yang, C. Liu, F. Liu, R. Ji, and Q. Ye.papercode
Incremental few-shot instance segmentation, in CVPR, 2021. D. A. Ganea, B. Boom, and R. Poppe.papercode
Scale-aware graph neural network for few-shot semantic segmentation, in CVPR, 2021. G. Xie, J. Liu, H. Xiong, and L. Shao.paper
Semantic relation reasoning for shot-stable few-shot object detection, in CVPR, 2021. C. Zhu, F. Chen, U. Ahmed, Z. Shen, and M. Savvides.paper
Accurate few-shot object detection with support-query mutual guidance and hybrid loss, in CVPR, 2021. L. Zhang, S. Zhou, J. Guan, and J. Zhang.paper
Transformation invariant few-shot object detection, in CVPR, 2021. A. Li, and Z. Li.paper
MetaHTR: Towards writer-adaptive handwritten text recognition, in CVPR, 2021. A. K. Bhunia, S. Ghose, A. Kumar, P. N. Chowdhury, A. Sain, and Y. Song.paper
What if we only use real datasets for scene text recognition? Toward scene text recognition with fewer labels, in CVPR, 2021. J. Baek, Y. Matsui, and K. Aizawa.papercode
Few-shot font generation with localized style representations and factorization, in AAAI, 2021. S. Park, S. Chun, J. Cha, B. Lee, and H. Shim.papercode
Attributes-guided and pure-visual attention alignment for few-shot recognition, in AAAI, 2021. S. Huang, M. Zhang, Y. Kang, and D. Wang.papercode
One-shot face reenactment using appearance adaptive normalization, in AAAI, 2021. G. Yao, Y. Yuan, T. Shao, S. Li, S. Liu, Y. Liu, M. Wang, and K. Zhou.paper
FL-MSRE: A few-shot learning based approach to multimodal social relation extraction, in AAAI, 2021. H. Wan, M. Zhang, J. Du, Z. Huang, Y. Yang, and J. Z. Pan.papercode
StarNet: Towards weakly supervised few-shot object detection, in AAAI, 2021. L. Karlinsky, J. Shtok, A. Alfassy, M. Lichtenstein, S. Harary, E. Schwartz, S. Doveh, P. Sattigeri, R. Feris, A. Bronstein, and R. Giryes.papercode
Progressive one-shot human parsing, in AAAI, 2021. H. He, J. Zhang, B. Thuraisingham, and D. Tao.papercode
Knowledge is power: Hierarchical-knowledge embedded meta-learning for visual reasoning in artistic domains, in KDD, 2021. W. Zheng, L. Yan, C. Gou, and F.-Y. Wang.paper
MEDA: Meta-learning with data augmentation for few-shot text classification, in IJCAI, 2021. P. Sun, Y. Ouyang, W. Zhang, and X.-Y. Dai.paper
Learning implicit temporal alignment for few-shot video classification, in IJCAI, 2021. S. Zhang, J. Zhou, and X. He.papercode
Few-shot neural human performance rendering from sparse RGBD videos, in IJCAI, 2021. A. Pang, X. Chen, H. Luo, M. Wu, J. Yu, and L. Xu.paper
Uncertainty-aware few-shot image classification, in IJCAI, 2021. Z. Zhang, C. Lan, W. Zeng, Z. Chen, and S. Chan.paper
Few-shot learning with part discovery and augmentation from unlabeled images, in IJCAI, 2021. W. Chen, C. Si, W. Wang, L. Wang, Z. Wang, and T. Tan.paper
Few-shot partial-label learning, in IJCAI, 2021. Y. Zhao, G. Yu, L. Liu, Z. Yan, L. Cui, and C. Domeniconi.paper
One-shot affordance detection, in IJCAI, 2021. H. Luo, W. Zhai, J. Zhang, Y. Cao, and D. Tao.paper
DeFRCN: Decoupled faster R-CNN for few-shot object detection, in ICCV, 2021. L. Qiao, Y. Zhao, Z. Li, X. Qiu, J. Wu, and C. Zhang.paper
Learning meta-class memory for few-shot semantic segmentation, in ICCV, 2021. Z. Wu, X. Shi, G. Lin, and J. Cai.paper
UVStyle-Net: Unsupervised few-shot learning of 3D style similarity measure for B-Reps, in ICCV, 2021. P. Meltzer, H. Shayani, A. Khasahmadi, P. K. Jayaraman, A. Sanghi, and J. Lambourne.paper
LoFGAN: Fusing local representations for few-shot image generation, in ICCV, 2021. Z. Gu, W. Li, J. Huo, L. Wang, and Y. Gao.paper
Recurrent mask refinement for few-shot medical image segmentation, in ICCV, 2021. H. Tang, X. Liu, S. Sun, X. Yan, and X. Xie.papercode
H3D-Net: Few-shot high-fidelity 3D head reconstruction, in ICCV, 2021. E. Ramon, G. Triginer, J. Escur, A. Pumarola, J. Garcia, X. Giró-i-Nieto, and F. Moreno-Noguer.paper
Learned spatial representations for few-shot talking-head synthesis, in ICCV, 2021. M. Meshry, S. Suri, L. S. Davis, and A. Shrivastava.paper
Putting NeRF on a diet: Semantically consistent few-shot view synthesis, in ICCV, 2021. A. Jain, M. Tancik, and P. Abbeel.paper
Hypercorrelation squeeze for few-shot segmentation, in ICCV, 2021. J. Min, D. Kang, and M. Cho.papercode
Few-shot semantic segmentation with cyclic memory network, in ICCV, 2021. G. Xie, H. Xiong, J. Liu, Y. Yao, and L. Shao.paper
Simpler is better: Few-shot semantic segmentation with classifier weight transformer, in ICCV, 2021. Z. Lu, S. He, X. Zhu, L. Zhang, Y. Song, and T. Xiang.papercode
Unsupervised few-shot action recognition via action-appearance aligned meta-adaptation, in ICCV, 2021. J. Patravali, G. Mittal, Y. Yu, F. Li, and M. Chen.paper
Multiple heads are better than one: few-shot font generation with multiple localized experts, in ICCV, 2021. S. Park, S. Chun, J. Cha, B. Lee, and H. Shim.papercode
Mining latent classes for few-shot segmentation, in ICCV, 2021. L. Yang, W. Zhuo, L. Qi, Y. Shi, and Y. Gao.papercode
Partner-assisted learning for few-shot image classification, in ICCV, 2021. J. Ma, H. Xie, G. Han, S. Chang, A. Galstyan, and W. Abd-Almageed.paper
Hierarchical graph attention network for few-shot visual-semantic learning, in ICCV, 2021. C. Yin, K. Wu, Z. Che, B. Jiang, Z. Xu, and J. Tang.paper
Video pose distillation for few-shot, fine-grained sports action recognition, in ICCV, 2021. J. Hong, M. Fisher, M. Gharbi, and K. Fatahalian.paper
Universal-prototype enhancing for few-shot object detection, in ICCV, 2021. A. Wu, Y. Han, L. Zhu, and Y. Yang.papercode
Query adaptive few-shot object detection with heterogeneous graph convolutional networks, in ICCV, 2021. G. Han, Y. He, S. Huang, J. Ma, and S. Chang.paper
Few-shot visual relationship co-localization, in ICCV, 2021. R. Teotia, V. Mishra, M. Maheshwari, and A. Mishra.papercode
Shallow Bayesian meta learning for real-world few-shot recognition, in ICCV, 2021. X. Zhang, D. Meng, H. Gouk, and T. M. Hospedales.papercode
Super-resolving cross-domain face miniatures by peeking at one-shot exemplar, in ICCV, 2021. P. Li, X. Yu, and Y. Yang.paper
Few-shot segmentation via cycle-consistent transformer, in NeurIPS, 2021. G. Zhang, G. Kang, Y. Yang, and Y. Wei.paper
Generalized and discriminative few-shot object detection via SVD-dictionary enhancement, in NeurIPS, 2021. A. WU, S. Zhao, C. Deng, and W. Liu.paper
Re-ranking for image retrieval and transductive few-shot classification, in NeurIPS, 2021. X. SHEN, Y. Xiao, S. Hu, O. Sbai, and M. Aubry.paper
Neural view synthesis and matching for semi-supervised few-shot learning of 3D pose, in NeurIPS, 2021. A. Wang, S. Mei, A. L. Yuille, and A. Kortylewski.paper
MetaAvatar: Learning animatable clothed human models from few depth images, in NeurIPS, 2021. S. Wang, M. Mihajlovic, Q. Ma, A. Geiger, and S. Tang.paper
Few-shot object detection via association and discrimination, in NeurIPS, 2021. Y. Cao, J. Wang, Y. Jin, T. Wu, K. Chen, Z. Liu, and D. Lin.paper
Rectifying the shortcut learning of background for few-shot learning, in NeurIPS, 2021. X. Luo, L. Wei, L. Wen, J. Yang, L. Xie, Z. Xu, and Q. Tian.paper
D2C: Diffusion-decoding models for few-shot conditional generation, in NeurIPS, 2021. A. Sinha, J. Song, C. Meng, and S. Ermon.paper
Few-shot backdoor attacks on visual object tracking, in ICLR, 2022. Y. Li, H. Zhong, X. Ma, Y. Jiang, and S. Xia.papercode
Temporal alignment prediction for supervised representation learning and few-shot sequence classification, in ICLR, 2022. B. Su, and J. Wen.papercode
Learning non-target knowledge for few-shot semantic segmentation, in CVPR, 2022. Y. Liu, N. Liu, Q. Cao, X. Yao, J. Han, and L. Shao.paper
Learning what not to segment: A new perspective on few-shot segmentation, in CVPR, 2022. C. Lang, G. Cheng, B. Tu, and J. Han.papercode
Few-shot keypoint detection with uncertainty learning for unseen species, in CVPR, 2022. C. Lu, and P. Koniusz.paper
XMP-Font: Self-supervised cross-modality pre-training for few-shot font generation, in CVPR, 2022. W. Liu, F. Liu, F. Ding, Q. He, and Z. Yi.paper
Spatio-temporal relation modeling for few-shot action recognition, in CVPR, 2022. A. Thatipelli, S. Narayan, S. Khan, R. M. Anwer, F. S. Khan, and B. Ghanem.papercode
Attribute group editing for reliable few-shot image generation, in CVPR, 2022. G. Ding, X. Han, S. Wang, S. Wu, X. Jin, D. Tu, and Q. Huang.papercode
Few-shot backdoor defense using Shapley estimation, in CVPR, 2022. J. Guan, Z. Tu, R. He, and D. Tao.paper
Hybrid relation guided set matching for few-shot action recognition, in CVPR, 2022. X. Wang, S. Zhang, Z. Qing, M. Tang, Z. Zuo, C. Gao, R. Jin, and N. Sang.papercode
Label, verify, correct: A simple few shot object detection method, in CVPR, 2022. P. Kaul, W. Xie, and A. Zisserman.paper
InfoNeRF: Ray entropy minimization for few-shot neural volume rendering, in CVPR, 2022. M. Kim, S. Seo, and B. Han.paper
A closer look at few-shot image generation, in CVPR, 2022. Y. Zhao, H. Ding, H. Huang, and N. Cheung.papercode
Motion-modulated temporal fragment alignment network for few-shot action recognition, in CVPR, 2022. J. Wu, T. Zhang, Z. Zhang, F. Wu, and Y. Zhang.paper
Kernelized few-shot object detection with efficient integral aggregation, in CVPR, 2022. S. Zhang, L. Wang, N. Murray, and P. Koniusz.papercode
FS6D: Few-shot 6D pose estimation of novel objects, in CVPR, 2022. Y. He, Y. Wang, H. Fan, J. Sun, and Q. Chen.paper
Look closer to supervise better: One-shot font generation via component-based discriminator, in CVPR, 2022. Y. Kong, C. Luo, W. Ma, Q. Zhu, S. Zhu, N. Yuan, and L. Jin.paper
Generalized few-shot semantic segmentation, in CVPR, 2022. Z. Tian, X. Lai, L. Jiang, S. Liu, M. Shu, H. Zhao, and J. Jia.papercode
Which images to label for few-shot medical landmark detection?, in CVPR, 2022. Q. Quan, Q. Yao, J. Li, and S. K. Zhou.paper
Dynamic prototype convolution network for few-shot semantic segmentation, in CVPR, 2022. J. Liu, Y. Bao, G. Xie, H. Xiong, J. Sonke, and E. Gavves.paper
OSOP: A multi-stage one shot object pose estimation framework, in CVPR, 2022. I. Shugurov, F. Li, B. Busam, and S. Ilic.paper
Semantic-aligned fusion transformer for one-shot object detection, in CVPR, 2022. Y. Zhao, X. Guo, and Y. Lu.paper
OnePose: One-shot object pose estimation without CAD models, in CVPR, 2022. J. Sun, Z. Wang, S. Zhang, X. He, H. Zhao, G. Zhang, and X. Zhou.papercode
Few-shot object detection with fully cross-transformer, in CVPR, 2022. G. Han, J. Ma, S. Huang, L. Chen, and S. Chang.paper
Learning to memorize feature hallucination for one-shot image generation, in CVPR, 2022. Y. Xie, Y. Fu, Y. Tai, Y. Cao, J. Zhu, and C. Wang.paper
Few-shot font generation by learning fine-grained local styles, in CVPR, 2022. L. Tang, Y. Cai, J. Liu, Z. Hong, M. Gong, M. Fan, J. Han, J. Liu, E. Ding, and J. Wang.paper
Balanced and hierarchical relation learning for one-shot object detection, in CVPR, 2022. H. Yang, S. Cai, H. Sheng, B. Deng, J. Huang, X. Hua, Y. Tang, and Y. Zhang.paper
Few-shot head swapping in the wild, in CVPR, 2022. C. Shu, H. Wu, H. Zhou, J. Liu, Z. Hong, C. Ding, J. Han, J. Liu, E. Ding, and J. Wang.paper
Integrative few-shot learning for classification and segmentation, in CVPR, 2022. D. Kang, and M. Cho.paper
Attribute surrogates learning and spectral tokens pooling in transformers for few-shot learning, in CVPR, 2022. Y. He, W. Liang, D. Zhao, H. Zhou, W. Ge, Y. Yu, and W. Zhang.papercode
Task discrepancy maximization for fine-grained few-shot classification, in CVPR, 2022. S. Lee, W. Moon, and J. Heo.paper
Robotics
Towards one shot learning by imitation for humanoid robots, in ICRA, 2010. Y. Wu and Y. Demiris.paper
Learning manipulation actions from a few demonstrations, in ICRA, 2013. N. Abdo, H. Kretzschmar, L. Spinello, and C. Stachniss.paper
Learning assistive strategies from a few user-robot interactions: Model-based reinforcement learning approach, in ICRA, 2016. M. Hamaya, T. Matsubara, T. Noda, T. Teramae, and J. Morimoto.paper
One-shot imitation learning, in NeurIPS, 2017. Y. Duan, M. Andrychowicz, B. Stadie, J. Ho, J. Schneider, I. Sutskever, P. Abbeel, and W. Zaremba.paper
Meta-learning language-guided policy learning, in ICLR, 2019. J. D. Co-Reyes, A. Gupta, S. Sanjeev, N. Altieri, J. DeNero, P. Abbeel, and S. Levine.paper
Meta reinforcement learning with autonomous inference of subtask dependencies, in ICLR, 2020. S. Sohn, H. Woo, J. Choi, and H. Lee.paper
Watch, try, learn: Meta-learning from demonstrations and rewards, in ICLR, 2020. A. Zhou, E. Jang, D. Kappler, A. Herzog, M. Khansari, P. Wohlhart, Y. Bai, M. Kalakrishnan, S. Levine, and C. Finn.paper
Few-shot Bayesian imitation learning with logical program policies, in AAAI, 2020. T. Silver, K. R. Allen, A. K. Lew, L. P. Kaelbling, and J. Tenenbaum.paper
One solution is not all you need: Few-shot extrapolation via structured MaxEnt RL, in NeurIPS, 2020. S. Kumar, A. Kumar, S. Levine, and C. Finn.paper
Bowtie networks: Generative modeling for joint few-shot recognition and novel-view synthesis, in ICLR, 2021. Z. Bao, Y. Wang, and M. Hebert.paper
Demonstration-conditioned reinforcement learning for few-shot imitation, in ICML, 2021. C. R. Dance, J. Perez, and T. Cachet.paper
Hierarchical few-shot imitation with skill transition models, in ICLR, 2022. K. Hakhamaneshi, R. Zhao, A. Zhan, P. Abbeel, and M. Laskin.paper
Natural Language Processing
High-risk learning: Acquiring new word vectors from tiny data, in EMNLP, 2017. A. Herbelot and M. Baroni.paper
MetaEXP: Interactive explanation and exploration of large knowledge graphs, in TheWebConf, 2018. F. Behrens, S. Bischoff, P. Ladenburger, J. Rückin, L. Seidel, F. Stolp, M. Vaichenker, A. Ziegler, D. Mottin, F. Aghaei, E. Müller, M. Preusse, N. Müller, and M. Hunger.papercode
Few-shot representation learning for out-of-vocabulary words, in ACL, 2019. Z. Hu, T. Chen, K.-W. Chang, and Y. Sun.paper
Learning to customize model structures for few-shot dialogue generation tasks, in ACL, 2020. Y. Song, Z. Liu, W. Bi, R. Yan, and M. Zhang.paper
Few-shot slot tagging with collapsed dependency transfer and label-enhanced task-adaptive projection network, in ACL, 2020. Y. Hou, W. Che, Y. Lai, Z. Zhou, Y. Liu, H. Liu, and T. Liu.paper
Meta-reinforced multi-domain state generator for dialogue systems, in ACL, 2020. Y. Huang, J. Feng, M. Hu, X. Wu, X. Du, and S. Ma.paper
Few-shot knowledge graph completion, in AAAI, 2020. C. Zhang, H. Yao, C. Huang, M. Jiang, Z. Li, and N. V. Chawla.paper
Universal natural language processing with limited annotations: Try few-shot textual entailment as a start, in EMNLP, 2020. W. Yin, N. F. Rajani, D. Radev, R. Socher, and C. Xiong.papercode
Simple and effective few-shot named entity recognition with structured nearest neighbor learning, in EMNLP, 2020. Y. Yang, and A. Katiyar.papercode
Discriminative nearest neighbor few-shot intent detection by transferring natural language inference, in EMNLP, 2020. J. Zhang, K. Hashimoto, W. Liu, C. Wu, Y. Wan, P. Yu, R. Socher, and C. Xiong.papercode
Few-shot learning for opinion summarization, in EMNLP, 2020. A. Bražinskas, M. Lapata, and I. Titov.papercode
Adaptive attentional network for few-shot knowledge graph completion, in EMNLP, 2020. J. Sheng, S. Guo, Z. Chen, J. Yue, L. Wang, T. Liu, and H. Xu.papercode
Few-shot complex knowledge base question answering via meta reinforcement learning, in EMNLP, 2020. Y. Hua, Y. Li, G. Haffari, G. Qi, and T. Wu.papercode
Self-supervised meta-learning for few-shot natural language classification tasks, in EMNLP, 2020. T. Bansal, R. Jha, T. Munkhdalai, and A. McCallum.papercode
Uncertainty-aware self-training for few-shot text classification, in NeurIPS, 2020. S. Mukherjee, and A. Awadallah.papercode
Learning to extrapolate knowledge: Transductive few-shot out-of-graph link prediction, in NeurIPS, 2020:. J. Baek, D. B. Lee, and S. J. Hwang.papercode
MetaNER: Named entity recognition with meta-learning, in TheWebConf, 2020. J. Li, S. Shang, and L. Shao.paper
Conditionally adaptive multi-task learning: Improving transfer learning in NLP using fewer parameters & less data, in ICLR, 2021. J. Pilault, A. E. hattami, and C. Pal.papercode
Revisiting few-sample BERT fine-tuning, in ICLR, 2021. T. Zhang, F. Wu, A. Katiyar, K. Q. Weinberger, and Y. Artzi.papercode
Few-shot conversational dense retrieval, in SIGIR, 2021. S. Yu, Z. Liu, C. Xiong, T. Feng, and Z. Liu.papercode
Relational learning with gated and attentive neighbor aggregator for few-shot knowledge graph completion, in SIGIR, 2021. G. Niu, Y. Li, C. Tang, R. Geng, J. Dai, Q. Liu, H. Wang, J. Sun, F. Huang, and L. Si.paper
Few-shot language coordination by modeling theory of mind, in ICML, 2021. H. Zhu, G. Neubig, and Y. Bisk.papercode
Graph-evolving meta-learning for low-resource medical dialogue generation, in AAAI, 2021. S. Lin, P. Zhou, X. Liang, J. Tang, R. Zhao, Z. Chen, and L. Lin.paper
KEML: A knowledge-enriched meta-learning framework for lexical relation classification, in AAAI, 2021. C. Wang, M. Qiu, J. Huang, and X. He.paper
Few-shot learning for multi-label intent detection, in AAAI, 2021. Y. Hou, Y. Lai, Y. Wu, W. Che, and T. Liu.papercode
SALNet: Semi-supervised few-shot text classification with attention-based lexicon construction, in AAAI, 2021. J.-H. Lee, S.-K. Ko, and Y.-S. Han.paper
Learning from my friends: Few-shot personalized conversation systems via social networks, in AAAI, 2021. Z. Tian, W. Bi, Z. Zhang, D. Lee, Y. Song, and N. L. Zhang.papercode
Relative and absolute location embedding for few-shot node classification on graph, in AAAI, 2021. Z. Liu, Y. Fang, C. Liu, and S. C.H. Hoi.paper
Few-shot question answering by pretraining span selection, in ACL-IJCNLP, 2021. O. Ram, Y. Kirstain, J. Berant, A. Globerson, and O. Levy.papercode
A closer look at few-shot crosslingual transfer: The choice of shots matters, in ACL-IJCNLP, 2021. M. Zhao, Y. Zhu, E. Shareghi, I. Vulic, R. Reichart, A. Korhonen, and H. Schütze.papercode
Learning from miscellaneous other-classwords for few-shot named entity recognition, in ACL-IJCNLP, 2021. M. Tong, S. Wang, B. Xu, Y. Cao, M. Liu, L. Hou, and J. Li.papercode
Distinct label representations for few-shot text classification, in ACL-IJCNLP, 2021. S. Ohashi, J. Takayama, T. Kajiwara, and Y. Arase.papercode
Entity concept-enhanced few-shot relation extraction, in ACL-IJCNLP, 2021. S. Yang, Y. Zhang, G. Niu, Q. Zhao, and S. Pu.papercode
On training instance selection for few-shot neural text generation, in ACL-IJCNLP, 2021. E. Chang, X. Shen, H.-S. Yeh, and V. Demberg.papercode
Unsupervised neural machine translation for low-resource domains via meta-learning, in ACL-IJCNLP, 2021. C. Park, Y. Tae, T. Kim, S. Yang, M. A. Khan, L. Park, and J. Choo.papercode
Meta-learning with variational semantic memory for word sense disambiguation, in ACL-IJCNLP, 2021. Y. Du, N. Holla, X. Zhen, C. Snoek, and E. Shutova.papercode
Multi-label few-shot learning for aspect category detection, in ACL-IJCNLP, 2021. M. Hu, S. Z. H. Guo, C. Xue, H. Gao, T. Gao, R. Cheng, and Z. Su.paper
TextSETTR: Few-shot text style extraction and tunable targeted restyling, in ACL-IJCNLP, 2021. P. Rileya, N. Constantb, M. Guob, G. Kumarc, D. Uthusb, and Z. Parekh.paper
Few-shot text ranking with meta adapted synthetic weak supervision, in ACL-IJCNLP, 2021. S. Sun, Y. Qian, Z. Liu, C. Xiong, K. Zhang, J. Bao, Z. Liu, and P. Bennett.papercode
PROTAUGMENT: Intent detection meta-learning through unsupervised diverse paraphrasing, in ACL-IJCNLP, 2021. T. Dopierre, C. Gravier, and W. Logerais.papercode
AUGNLG: Few-shot natural language generation using self-trained data augmentation, in ACL-IJCNLP, 2021. X. Xu, G. Wang, Y.-B. Kim, and S. Lee.papercode
Meta self-training for few-shot neural sequence labeling, in KDD, 2021. Y. Wang, S. Mukherjee, H. Chu, Y. Tu, M. Wu, J. Gao, and A. H. Awadallah.papercode
Knowledge-enhanced domain adaptation in few-shot relation classification, in KDD, 2021. J. Zhang, J. Zhu, Y. Yang, W. Shi, C. Zhang, and H. Wang.papercode
Few-shot text classification with triplet networks, data augmentation, and curriculum learning, in NAACL-HLT, 2021. J. Wei, C. Huang, S. Vosoughi, Y. Cheng, and S. Xu.papercode
Few-shot intent classification and slot filling with retrieved examples, in NAACL-HLT, 2021. D. Yu, L. He, Y. Zhang, X. Du, P. Pasupat, and Q. Li.paper
Non-parametric few-shot learning for word sense disambiguation, in NAACL-HLT, 2021. H. Chen, M. Xia, and D. Chen.papercode
Towards few-shot fact-checking via perplexity, in NAACL-HLT, 2021. N. Lee, Y. Bang, A. Madotto, and P. Fung.paper
ConVEx: Data-efficient and few-shot slot labeling, in NAACL-HLT, 2021. M. Henderson, and I. Vulic.paper
Few-shot text generation with natural language instructions, in EMNLP, 2021. T. Schick, and H. Schütze.paper
Towards realistic few-shot relation extraction, in EMNLP, 2021. S. Brody, S. Wu, and A. Benton.papercode
Few-shot emotion recognition in conversation with sequential prototypical networks, in EMNLP, 2021. G. Guibon, M. Labeau, H. Flamein, L. Lefeuvre, and C. Clavel.papercode
Learning prototype representations across few-shot tasks for event detection, in EMNLP, 2021. V. Lai, F. Dernoncourt, and T. H. Nguyen.paper
Exploring task difficulty for few-shot relation extraction, in EMNLP, 2021. J. Han, B. Cheng, and W. Lu.papercode
Honey or poison? Solving the trigger curse in few-shot event detection via causal intervention, in EMNLP, 2021. J. Chen, H. Lin, X. Han, and L. Sun.papercode
Nearest neighbour few-shot learning for cross-lingual classification, in EMNLP, 2021. M. S. Bari, B. Haider, and S. Mansour.paper
Knowledge-aware meta-learning for low-resource text classification, in EMNLP, 2021. H. Yao, Y. Wu, M. Al-Shedivat, and E. P. Xing.papercode
Few-shot named entity recognition: An empirical baseline study, in EMNLP, 2021. J. Huang, C. Li, K. Subudhi, D. Jose, S. Balakrishnan, W. Chen, B. Peng, J. Gao, and J. Han.paper
MetaTS: Meta teacher-student network for multilingual sequence labeling with minimal supervision, in EMNLP, 2021. Z. Li, D. Zhang, T. Cao, Y. Wei, Y. Song, and B. Yin.paper
Meta-LMTC: Meta-learning for large-scale multi-label text classification, in EMNLP, 2021. R. Wang, X. Su, S. Long, X. Dai, S. Huang, and J. Chen.paper
Ontology-enhanced prompt-tuning for few-shot learning., in TheWebConf, 2022. H. Ye, N. Zhang, S. Deng, X. Chen, H. Chen, F. Xiong, X. Chen, and H. Chen.paper
EICO: Improving few-shot text classification via explicit and implicit consistency regularization, in Findings of ACL, 2022. L. Zhao, and C. Yao.paper
Dialogue summaries as dialogue states (DS2), template-guided summarization for few-shot dialogue state tracking, in Findings of ACL, 2022. J. Shin, H. Yu, H. Moon, A. Madotto, and J. Park.papercode
A few-shot semantic parser for wizard-of-oz dialogues with the precise thingtalk representation, in Findings of ACL, 2022. G. Campagna, S. J. Semnani, R. Kearns, L. J. K. Sato, S. Xu, and M. S. Lam.paper
Multi-stage prompting for knowledgeable dialogue generation, in Findings of ACL, 2022. Z. Liu, M. Patwary, R. Prenger, S. Prabhumoye, W. Ping, M. Shoeybi, and B. Catanzaro.papercode
Few-shot named entity recognition with self-describing networks, in ACL, 2022. J. Chen, Q. Liu, H. Lin, X. Han, and L. Sun.papercode
CLIP models are few-shot learners: Empirical studies on VQA and visual entailment, in ACL, 2022. H. Song, L. Dong, W. Zhang, T. Liu, and F. Wei.paper
CONTaiNER: Few-shot named entity recognition via contrastive learning, in ACL, 2022. S. S. S. Das, A. Katiyar, R. J. Passonneau, and R. Zhang.papercode
Few-shot controllable style transfer for low-resource multilingual settings, in ACL, 2022. K. Krishna, D. Nathani, X. Garcia, B. Samanta, and P. Talukdar.paper
Label semantic aware pre-training for few-shot text classification, in ACL, 2022. A. Mueller, J. Krone, S. Romeo, S. Mansour, E. Mansimov, Y. Zhang, and D. Roth.paper
Inverse is better! Fast and accurate prompt for few-shot slot tagging, in Findings of ACL, 2022. Y. Hou, C. Chen, X. Luo, B. Li, and W. Che.paper
Label semantics for few shot named entity recognition, in Findings of ACL, 2022. J. Ma, M. Ballesteros, S. Doss, R. Anubhai, S. Mallya, Y. Al-Onaizan, and D. Roth.paper
Hierarchical recurrent aggregative generation for few-shot NLG, in Findings of ACL, 2022. G. Zhou, G. Lampouras, and I. Iacobacci.paper
Towards few-shot entity recognition in document images: A label-aware sequence-to-sequence framework, in Findings of ACL, 2022. Z. Wang, and J. Shang.paper
A good prompt is worth millions of parameters: Low-resource prompt-based learning for vision-language models, in ACL, 2022. W. Jin, Y. Cheng, Y. Shen, W. Chen, and X. Ren.papercode
Generated knowledge prompting for commonsense reasoning, in ACL, 2022. J. Liu, A. Liu, X. Lu, S. Welleck, P. West, R. L. Bras, Y. Choi, and H. Hajishirzi.papercode
End-to-end modeling via information tree for one-shot natural language spatial video grounding, in ACL, 2022. M. Li, T. Wang, H. Zhang, S. Zhang, Z. Zhao, J. Miao, W. Zhang, W. Tan, J. Wang, P. Wang, S. Pu, and F. Wu.paper
Leveraging task transferability to meta-learning for clinical section classification with limited data, in ACL, 2022. Z. Chen, J. Kim, R. Bhakta, and M. Y. Sir.paper
Improving meta-learning for low-resource text classification and generation via memory imitation, in ACL, 2022. Y. Zhao, Z. Tian, H. Yao, Y. Zheng, D. Lee, Y. Song, J. Sun, and N. L. Zhang.paper
A simple yet effective relation information guided approach for few-shot relation extraction, in Findings of ACL, 2022. Y. Liu, J. Hu, X. Wan, and T. Chang.papercode
Decomposed meta-learning for few-shot named entity recognition, in Findings of ACL, 2022. T. Ma, H. Jiang, Q. Wu, T. Zhao, and C. Lin.papercode
Meta-learning for fast cross-lingual adaptation in dependency parsing, in ACL, 2022. A. Langedijk, V. Dankers, P. Lippe, S. Bos, B. C. Guevara, H. Yannakoudakis, and E. Shutova.papercode
Enhancing cross-lingual natural language inference by prompt-learning from cross-lingual templates, in ACL, 2022. K. Qi, H. Wan, J. Du, and H. Chen.papercode
Acoustic Signal Processing
One-shot learning of generative speech concepts, in CogSci, 2014. B. Lake, C.-Y. Lee, J. Glass, and J. Tenenbaum.paper
Machine speech chain with one-shot speaker adaptation, INTERSPEECH, 2018. A. Tjandra, S. Sakti, and S. Nakamura.paper
Investigation of using disentangled and interpretable representations for one-shot cross-lingual voice conversion, INTERSPEECH, 2018. S. H. Mohammadi and T. Kim.paper
Few-shot audio classification with attentional graph neural networks, INTERSPEECH, 2019. S. Zhang, Y. Qin, K. Sun, and Y. Lin.paper
One-shot voice conversion with disentangled representations by leveraging phonetic posteriorgrams, INTERSPEECH, 2019. S. H. Mohammadi, and T. Kim.paper
One-shot voice conversion with global speaker embeddings, INTERSPEECH, 2019. H. Lu, Z. Wu, D. Dai, R. Li, S. Kang, J. Jia, and H. Meng.paper
One-shot voice conversion by separating speaker and content representations with instance normalization, INTERSPEECH, 2019. J.-C. Chou, and H.-Y. Lee.paper
Audio2Head: Audio-driven one-shot talking-head generation with natural head motion, in IJCAI, 2021. S. Wang, L. Li, Y. Ding, C. Fan, and X. Yu.paper
Recommendation
A meta-learning perspective on cold-start recommendations for items, in NeurIPS, 2017. M. Vartak, A. Thiagarajan, C. Miranda, J. Bratman, and H. Larochelle.paper
MeLU: Meta-learned user preference estimator for cold-start recommendation, in KDD, 2019. H. Lee, J. Im, S. Jang, H. Cho, and S. Chung.papercode
Sequential scenario-specific meta learner for online recommendation, in KDD, 2019. Z. Du, X. Wang, H. Yang, J. Zhou, and J. Tang.papercode
Few-shot learning for new user recommendation in location-based social networks, in TheWebConf, 2020. R. Li, X. Wu, X. Chen, and W. Wang.paper
MAMO: Memory-augmented meta-optimization for cold-start recommendation, in KDD, 2020. M. Dong, F. Yuan, L. Yao, X. Xu, and L. Zhu.papercode
Meta-learning on heterogeneous information networks for cold-start recommendation, in KDD, 2020. Y. Lu, Y. Fang, and C. Shi.papercode
MetaSelector: Meta-learning for recommendation with user-level adaptive model selection, in TheWebConf, 2020. M. Luo, F. Chen, P. Cheng, Z. Dong, X. He, J. Feng, and Z. Li.paper
Fast adaptation for cold-start collaborative filtering with meta-learning, in ICDM, 2020. T. Wei, Z. Wu, R. Li, Z. Hu, F. Feng, X. H. Sun, and W. Wang.paper
Preference-adaptive meta-learning for cold-start recommendation, in IJCAI, 2021. L. Wang, B. Jin, Z. Huang, H. Zhao, D. Lian, Q. Liu, and E. Chen.paper
Meta-learning helps personalized product search., in TheWebConf, 2022. B. Wu, Z. Meng, Q. Zhang, and S. Liang.paper
Alleviating cold-start problem in CTR prediction with a variational embedding learning framework., in TheWebConf, 2022. X. Xu, C. Yang, Q. Yu, Z. Fang, J. Wang, C. Fan, Y. He, C. Peng, Z. Lin, and J. Shao.paper
PNMTA: A pretrained network modulation and task adaptation approach for user cold-start recommendation., in TheWebConf, 2022. H. Pang, F. Giunchiglia, X. Li, R. Guan, and X. Feng.paper
Others
Low data drug discovery with one-shot learning, ACS Central Science, 2017. H. Altae-Tran, B. Ramsundar, A. S. Pappu, and V. Pande.paper
SMASH: One-shot model architecture search through hypernetworks, in ICLR, 2018. A. Brock, T. Lim, J. Ritchie, and N. Weston.paper
SPARC: Self-paced network representation for few-shot rare category characterization, in KDD, 2018. D. Zhou, J. He, H. Yang, and W. Fan.paper
MetaPred: Meta-learning for clinical risk prediction with limited patient electronic health records, in KDD, 2019. X. S. Zhang, F. Tang, H. H. Dodge, J. Zhou, and F. Wang.papercode
AffnityNet: Semi-supervised few-shot learning for disease type prediction, in AAAI, 2019. T. Ma, and A. Zhang.paper
Learning from multiple cities: A meta-learning approach for spatial-temporal prediction, in TheWebConf, 2019. H. Yao, Y. Liu, Y. Wei, X. Tang, and Z. Li.papercode
Federated meta-learning for fraudulent credit card detection, in IJCAI, 2020. W. Zheng, L. Yan, C. Gou, and F. Wang.paper
Differentially private meta-learning, in ICLR, 2020. J. Li, M. Khodak, S. Caldas, and A. Talwalkar.paper
Towards fast adaptation of neural architectures with meta learning, in ICLR, 2020. D. Lian, Y. Zheng, Y. Xu, Y. Lu, L. Lin, P. Zhao, J. Huang, and S. Gao.paper
Using optimal embeddings to learn new intents with few examples: An application in the insurance domain, in KDD, 2020:. S. Acharya, and G. Fung.paper
Meta-learning for query conceptualization at web scale, in KDD, 2020. F. X. Han, D. Niu, H. Chen, W. Guo, S. Yan, and B. Long.paper
Few-sample and adversarial representation learning for continual stream mining, in TheWebConf, 2020. Z. Wang, Y. Wang, Y. Lin, E. Delord, and L. Khan.paper
Few-shot graph learning for molecular property prediction, in TheWebConf, 2021. Z. Guo, C. Zhang, W. Yu, J. Herr, O. Wiest, M. Jiang, and N. V. Chawla.papercode
Taxonomy-aware learning for few-shot event detection, in TheWebConf, 2021. J. Zheng, F. Cai, W. Chen, W. Lei, and H. Chen.paper
Learning from graph propagation via ordinal distillation for one-shot automated essay scoring, in TheWebConf, 2021. Z. Jiang, M. Liu, Y. Yin, H. Yu, Z. Cheng, and Q. Gu.paper
Few-shot network anomaly detection via cross-network meta-learning, in TheWebConf, 2021. K. Ding, Q. Zhou, H. Tong, and H. Liu.paper
Few-shot knowledge validation using rules, in TheWebConf, 2021. M. Loster, D. Mottin, P. Papotti, J. Ehmüller, B. Feldmann, and F. Naumann.paper
Graph learning regularization and transfer learning for few-shot event detection, in SIGIR, 2021. V. D. Lai, M. V. Nguyen, T. H. Nguyen, and F. Dernoncourt.papercode
Progressive network grafting for few-shot knowledge distillation, in AAAI, 2021. C. Shen, X. Wang, Y. Yin, J. Song, S. Luo, and M. Song.papercode
Curriculum meta-learning for next POI recommendation, in KDD, 2021. Y. Chen, X. Wang, M. Fan, J. Huang, S. Yang, and W. Zhu.papercode
MFNP: A meta-optimized model for few-shot next POI recommendation, in IJCAI, 2021. H. Sun, J. Xu, K. Zheng, P. Zhao, P. Chao, and X. Zhou.paper
Physics-aware spatiotemporal modules with auxiliary tasks for meta-learning, in IJCAI, 2021. S. Seo, C. Meng, S. Rambhatla, and Y. Liu.paper
Property-aware relation networks for few-shot molecular property prediction, in NeurIPS, 2021. Y. Wang, A. Abuduweili, Q. Yao, and D. Dou.papercode
Few-shot data-driven algorithms for low rank approximation, in NeurIPS, 2021. P. Indyk, T. Wagner, and D. Woodruff.paper
Non-Gaussian Gaussian processes for few-shot regression, in NeurIPS, 2021. M. Sendera, J. Tabor, A. Nowak, A. Bedychaj, M. Patacchiola, T. Trzcinski, P. Spurek, and M. Zieba.paper
HELP: Hardware-adaptive efficient latency prediction for NAS via meta-learning, in NeurIPS, 2021. H. Lee, S. Lee, S. Chong, and S. J. Hwang.paper
Learning to learn dense Gaussian processes for few-shot learning, in NeurIPS, 2021. Z. Wang, Z. Miao, X. Zhen, and Q. Qiu.paper
A meta-learning based stress category detection framework on social media., in TheWebConf, 2022. X. Wang, L. Cao, H. Zhang, L. Feng, Y. Ding, and N. Li.paper
Learning to learn around a common mean, in NeurIPS, 2018. G. Denevi, C. Ciliberto, D. Stamos, and M. Pontil.paper
Meta-learning and universality: Deep representations and gradient descent can approximate any learning algorithm, in ICLR, 2018. C. Finn and S. Levine.paper
A theoretical analysis of the number of shots in few-shot learning, in ICLR, 2020. T. Cao, M. T. Law, and S. Fidler.paper
Rapid learning or feature reuse? Towards understanding the effectiveness of MAML, in ICLR, 2020. A. Raghu, M. Raghu, S. Bengio, and O. Vinyals.paper
Robust meta-learning for mixed linear regression with small batches, in NeurIPS, 2020. W. Kong, R. Somani, S. Kakade, and S. Oh.paper
One-shot distributed ridge regression in high dimensions, in ICML, 2020. Y. Sheng, and E. Dobriban.paper
Bridging the gap between practice and PAC-Bayes theory in few-shot meta-learning, in NeurIPS, 2021. N. Ding, X. Chen, T. Levinboim, S. Goodman, and R. Soricut.paper
Generalization bounds for meta-learning: An information-theoretic analysis, in NeurIPS, 2021. Q. CHEN, C. Shui, and M. Marchand.paper
Generalization bounds for meta-learning via PAC-Bayes and uniform stability, in NeurIPS, 2021. A. Farid, and A. Majumdar.paper
Unraveling model-agnostic meta-learning via the adaptation learning rate, in ICLR, 2022. Y. Zou, F. Liu, and Q. Li.paper
On the importance of firth bias reduction in few-shot classification, in ICLR, 2022. S. Ghaffari, E. Saleh, D. Forsyth, and Y. Wang.papercode
Global convergence of MAML and theory-inspired neural architecture search for few-shot learning, in CVPR, 2022. H. Wang, Y. Wang, R. Sun, and B. Li.paper
Label-embedding for attribute-based classification, in CVPR, 2013. Z. Akata, F. Perronnin, Z. Harchaoui, and C. Schmid.paper
A unified semantic embedding: Relating taxonomies and attributes, in NeurIPS, 2014. S. J. Hwang and L. Sigal.paper
Multi-attention network for one shot learning, in CVPR, 2017. P. Wang, L. Liu, C. Shen, Z. Huang, A. van den Hengel, and H. T. Shen.paper
Few-shot and zero-shot multi-label learning for structured label spaces, in EMNLP, 2018. A. Rios and R. Kavuluru.paper
Learning compositional representations for few-shot recognition, in ICCV, 2019. P. Tokmakov, Y.-X. Wang, and M. Hebert.papercode
Large-scale few-shot learning: Knowledge transfer with class hierarchy, in CVPR, 2019. A. Li, T. Luo, Z. Lu, T. Xiang, and L. Wang.paper
Generalized zero- and few-shot learning via aligned variational autoencoders, in CVPR, 2019. E. Schonfeld, S. Ebrahimi, S. Sinha, T. Darrell, and Z. Akata.papercode
F-VAEGAN-D2: A feature generating framework for any-shot learning, in CVPR, 2019. Y. Xian, S. Sharma, B. Schiele, and Z. Akata.paper
TGG: Transferable graph generation for zero-shot and few-shot learning, in ACM MM, 2019. C. Zhang, X. Lyu, and Z. Tang.paper
Adaptive cross-modal few-shot learning, in NeurIPS, 2019. C. Xing, N. Rostamzadeh, B. N. Oreshkin, and P. O. Pinheiro.paper
Learning meta model for zero- and few-shot face anti-spoofing, in AAAI, 2020. Y. Qin, C. Zhao, X. Zhu, Z. Wang, Z. Yu, T. Fu, F. Zhou, J. Shi, and Z. Lei.paper
RD-GAN: Few/Zero-shot chinese character style transfer via radical decomposition and rendering, in ECCV, 2020. Y. Huang, M. He, L. Jin, and Y. Wang.paper
An empirical study on large-scale multi-label text classification including few and zero-shot labels, in EMNLP, 2020. I. Chalkidis, M. Fergadiotis, S. Kotitsas, P. Malakasiotis, N. Aletras, and I. Androutsopoulos.paper
Multi-label few/zero-shot learning with knowledge aggregated from multiple label graphs, in EMNLP, 2020. J. Lu, L. Du, M. Liu, and J. Dipnall.paper
Emergent complexity and zero-shot transfer via unsupervised environment design, in NeurIPS, 2020. M. Dennis, N. Jaques, E. Vinitsky, A. Bayen, S. Russell, A. Critch, and S. Levine.paper
Learning graphs for knowledge transfer with limited labels, in CVPR, 2021. P. Ghosh, N. Saini, L. S. Davis, and A. Shrivastava.paper
Improving zero and few-shot abstractive summarization with intermediate fine-tuning and data augmentation, in NAACL-HLT, 2021. A. R. Fabbri, S. Han, H. Li, H. Li, M. Ghazvininejad, S. R. Joty, D. R. Radev, and Y. Mehdad.paper
Label verbalization and entailment for effective zero and few-shot relation extraction, in EMNLP, 2021. O. Sainz, O. L. d. Lacalle, G. Labaka, A. Barrena, and E. Agirre.papercode
An empirical investigation of word alignment supervision for zero-shot multilingual neural machine translation, in EMNLP, 2021. A. Raganato, R. Vázquez, M. Creutz, and J. Tiedemann.paper
Bridge to target domain by prototypical contrastive learning and label confusion: Re-explore zero-shot learning for slot filling, in EMNLP, 2021. L. Wang, X. Li, J. Liu, K. He, Y. Yan, and W. Xu.papercode
A label-aware BERT attention network for zero-shot multi-intent detection in spoken language understanding, in EMNLP, 2021. T. Wu, R. Su, and B. Juang.paper
Zero-shot dialogue disentanglement by self-supervised entangled response selection, in EMNLP, 2021. T. Chi, and A. I. Rudnicky.papercode
Robust retrieval augmented generation for zero-shot slot filling, in EMNLP, 2021. M. R. Glass, G. Rossiello, M. F. M. Chowdhury, and A. Gliozzo.papercode
Everything is all it takes: A multipronged strategy for zero-shot cross-lingual information extraction, in EMNLP, 2021. M. Yarmohammadi, S. Wu, M. Marone, H. Xu, S. Ebner, G. Qin, Y. Chen, J. Guo, C. Harman, K. Murray, A. S. White, M. Dredze, and B. V. Durme.papercode
An empirical study on multiple information sources for zero-shot fine-grained entity typing, in EMNLP, 2021. Y. Chen, H. Jiang, L. Liu, S. Shi, C. Fan, M. Yang, and R. Xu.paper
Zero-shot dialogue state tracking via cross-task transfer, in EMNLP, 2021. Z. Lin, B. Liu, A. Madotto, S. Moon, Z. Zhou, P. Crook, Z. Wang, Z. Yu, E. Cho, R. Subba, and P. Fung.papercode
Finetuned language models are zero-shot learners, in ICLR, 2022. J. Wei, M. Bosma, V. Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V. Le.papercode
Zero-shot stance detection via contrastive learning., in TheWebConf, 2022. B. Liang, Z. Chen, L. Gui, Y. He, M. Yang, and R. Xu.papercode
Reframing instructional prompts to GPTk’s language, in Findings of ACL, 2022. D. Khashabi, C. Baral, Y. Choi, and H. Hajishirzi.paper
JointCL: A joint contrastive learning framework for zero-shot stance detection, in ACL, 2022. B. Liang, Q. Zhu, X. Li, M. Yang, L. Gui, Y. He, and R. Xu.papercode
Knowledgeable prompt-tuning: Incorporating knowledge into prompt verbalizer for text classification, in ACL, 2022. S. Hu, N. Ding, H. Wang, Z. Liu, J. Wang, J. Li, W. Wu, and M. Sun.papercode
Uni-Perceiver: Pre-training unified architecture for generic perception for zero-shot and few-shot tasks, in CVPR, 2022. X. Zhu, J. Zhu, H. Li, X. Wu, H. Li, X. Wang, and J. Dai.paper
Continuous adaptation via meta-learning in nonstationary and competitive environments, in ICLR, 2018. M. Al-Shedivat, T. Bansal, Y. Burda, I. Sutskever, I. Mordatch, and P. Abbeel.paper
Deep online learning via meta-learning: Continual adaptation for model-based RL, in ICLR, 2018. A. Nagabandi, C. Finn, and S. Levine.paper
Incremental few-shot learning with attention attractor networks, in NeurIPS, 2019. M. Ren, R. Liao, E. Fetaya, and R. S. Zemel.papercode
Bidirectional one-shot unsupervised domain mapping, in ICCV, 2019. T. Cohen, and L. Wolf.paper
XtarNet: Learning to extract task-adaptive representation for incremental few-shot learning, in ICML, 2020. S. W. Yoon, D. Kim, J. Seo, and J. Moon.papercode
Few-shot class-incremental learning, in CVPR, 2020. X. Tao, X. Hong, X. Chang, S. Dong, X. Wei, and Y. Gong.paper
Wandering within a world: Online contextualized few-shot learning, in ICLR, 2021. M. Ren, M. L. Iuzzolino, M. C. Mozer, and R. Zemel.paper
Repurposing pretrained models for robust out-of-domain few-shot learning, in ICLR, 2021. N. Kwon, H. Na, G. Huang, and S. Lacoste-Julien.papercode
Prototypical cross-domain self-supervised learning for few-shot unsupervised domain adaptation, in CVPR, 2021. X. Yue, Z. Zheng, S. Zhang, Y. Gao, T. Darrell, K. Keutzer, and A. S. Vincentelli.paper
Self-promoted prototype refinement for few-shot class-incremental learning, in CVPR, 2021. K. Zhu, Y. Cao, W. Zhai, J. Cheng, and Z. Zha.paper
Semantic-aware knowledge distillation for few-shot class-incremental learning, in CVPR, 2021. A. Cheraghian, S. Rahman, P. Fang, S. K. Roy, L. Petersson, and M. Harandi.paper
Few-shot incremental learning with continually evolved classifiers, in CVPR, 2021. C. Zhang, N. Song, G. Lin, Y. Zheng, P. Pan, and Y. Xu.paper
Learning a universal template for few-shot dataset generalization, in ICML, 2021. E. Triantafillou, H. Larochelle, R. Zemel, and V. Dumoulin.paper
GP-Tree: A gaussian process classifier for few-shot incremental learning, in ICML, 2021. I. Achituve, A. Navon, Y. Yemini, G. Chechik, and E. Fetaya.papercode
Addressing catastrophic forgetting in few-shot problems, in ICML, 2021. P. Yap, H. Ritter, and D. Barber.papercode
Few-shot conformal prediction with auxiliary tasks, in ICML, 2021. A. Fisch, T. Schuster, T. Jaakkola, and R. Barzilay.papercode
Few-shot lifelong learning, in AAAI, 2021. P. Mazumder, P. Singh, and P. Rai.paper
Few-shot class-incremental learning via relation knowledge distillation, in AAAI, 2021. S. Dong, X. Hong, X. Tao, X. Chang, X. Wei, and Y. Gong.paper
Few-shot one-class classification via meta-learning, in AAAI, 2021. A. Frikha, D. Krompass, H. Koepken, and V. Tresp.papercode
Practical one-shot federated learning for cross-silo setting, in IJCAI, 2021. Q. Li, B. He, and D. Song.papercode
Incremental few-shot text classification with multi-round new classes: Formulation, dataset and system, in NAACL-HLT, 2021. C. Xia, W. Yin, Y. Feng, and P. S. Yu.paper
Continual few-shot learning for text classification, in EMNLP, 2021. R. Pasunuru, V. Stoyanov, and M. Bansal.papercode
Self-training with few-shot rationalization, in EMNLP, 2021. M. M. Bhat, A. Sordoni, and S. Mukherjee.paper
Diverse distributions of self-supervised tasks for meta-learning in NLP, in EMNLP, 2021. T. Bansal, K. P. Gunasekaran, T. Wang, T. Munkhdalai, and A. McCallum.paper
Generalized and incremental few-shot learning by explicit learning and calibration without forgetting, in ICCV, 2021. A. Kukleva, H. Kuehne, and B. Schiele.paper
Meta learning on a sequence of imbalanced domains with difficulty awareness, in ICCV, 2021. Z. Wang, T. Duan, L. Fang, Q. Suo, and M. Gao.papercode
Synthesized feature based few-shot class-incremental learning on a mixture of subspaces, in ICCV, 2021. A. Cheraghian, S. Rahman, S. Ramasinghe, P. Fang, C. Simon, L. Petersson, and M. Harandi.paper
Few-shot and continual learning with attentive independent mechanisms, in ICCV, 2021. E. Lee, C. Huang, and C. Lee.papercode
Low-shot validation: Active importance sampling for estimating classifier performance on rare categories, in ICCV, 2021. F. Poms, V. Sarukkai, R. T. Mullapudi, N. S. Sohoni, W. R. Mark, D. Ramanan, and K. Fatahalian.paper
Overcoming catastrophic forgetting in incremental few-shot learning by finding flat minima, in NeurIPS, 2021. G. SHI, J. CHEN, W. Zhang, L. Zhan, and X. Wu.paper
Variational continual Bayesian meta-learning, in NeurIPS, 2021. Q. Zhang, J. Fang, Z. Meng, S. Liang, and E. Yilmaz.paper
LFPT5: A unified framework for lifelong few-shot language learning based on prompt tuning of T5, in ICLR, 2022. C. Qin, and S. Joty.papercode
Subspace regularizers for few-shot class incremental learning, in ICLR, 2022. A. F. Akyürek, E. Akyürek, D. Wijaya, and J. Andreas.papercode
Meta discovery: Learning to discover novel classes given very limited data, in ICLR, 2022. H. Chi, F. Liu, W. Yang, L. Lan, T. Liu, B. Han, G. Niu, M. Zhou, and M. Sugiyama.paper
Topological transduction for hybrid few-shot learning., in TheWebConf, 2022. J. Chen, and A. Zhang.paper
Continual few-shot relation learning via embedding space regularization and data augmentation, in ACL, 2022. C. Qin, and S. Joty.papercode
Few-shot class-incremental learning for named entity recognition, in ACL, 2022. R. Wang, T. Yu, H. Zhao, S. Kim, S. Mitra, R. Zhang, and R. Henao.paper
Task-adaptive negative envision for few-shot open-set recognition, in CVPR, 2022. S. Huang, J. Ma, G. Han, and S. Chang.papercode
Forward compatible few-shot class-incremental learning, in CVPR, 2022. D. Zhou, F. Wang, H. Ye, L. Ma, S. Pu, and D. Zhan.papercode
Sylph: A hypernetwork framework for incremental few-shot object detection, in CVPR, 2022. L. Yin, J. M. Perez-Rua, and K. J. Liang.paper
Constrained few-shot class-incremental learning, in CVPR, 2022. M. Hersche, G. Karunaratne, G. Cherubini, L. Benini, A. Sebastian, and A. Rahimi.paper
iFS-RCNN: An incremental few-shot instance segmenter, in CVPR, 2022. K. Nguyen, and S. Todorovic.paper
MetaFSCIL: A meta-learning approach for few-shot class incremental learning, in CVPR, 2022. Z. Chi, L. Gu, H. Liu, Y. Wang, Y. Yu, and J. Tang.paper
Few-shot incremental learning for label-to-image translation, in CVPR, 2022. P. Chen, Y. Zhang, Z. Li, and L. Sun.paper
Revisiting learnable affines for batch norm in few-shot transfer learning, in CVPR, 2022. M. Yazdanpanah, A. A. Rahman, M. Chaudhary, C. Desrosiers, M. Havaei, E. Belilovsky, and S. E. Kahou.paper
Few-shot learning with noisy labels, in CVPR, 2022. K. J. Liang, S. B. Rangrej, V. Petrovic, and T. Hassner.paper
Improving adversarially robust few-shot image classification with generalizable representations, in CVPR, 2022. J. Dong, Y. Wang, J. Lai, and X. Xie.paper
FewRel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation, in EMNLP, 2018. X. Han, H. Zhu, P. Yu, Z. Wang, Y. Yao, Z. Liu, and M. Sun.papercode
Meta-World: A benchmark and evaluation for multi-task and meta reinforcement learning, arXiv preprint, 2019. T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine.papercode
The Omniglot challenge: A 3-year progress report, in Current Opinion in Behavioral Sciences, 2019. B. M. Lake, R. Salakhutdinov, and J. B. Tenenbaum.papercode
FewRel 2.0: Towards more challenging few-shot relation classification, in EMNLP-IJCNLP, 2019. T. Gao, X. Han, H. Zhu, Z. Liu, P. Li, M. Sun, and J. Zhou.papercode
META-DATASET: A dataset of datasets for learning to learn from few examples, in ICLR, 2020. E. Triantafillou, T. Zhu, V. Dumoulin, P. Lamblin, U. Evci, K. Xu, R. Goroshin, C. Gelada, K. Swersky, P. Manzagol, and H. Larochelle.papercode
Few-shot object detection with attention-rpn and multi-relation detector, in CVPR, 2020. Q. Fan, W. Zhuo, C.-K. Tang, Y.-W. Tai.papercode
FSS-1000: A 1000-class dataset for few-shot segmentation, in CVPR, 2020. X. Li, T. Wei, Y. P. Chen, Y.-W. Tai, and C.-K. Tang.papercode
Impact of base dataset design on few-shot image classification, in ECCV, 2020. O. Sbai, C. Couprie, and M. Aubry.papercode
A large-scale benchmark for few-shot program induction and synthesis, in ICML, 2021. F. Alet, J. Lopez-Contreras, J. Koppel, M. Nye, A. Solar-Lezama, T. Lozano-Perez, L. Kaelbling, and J. Tenenbaum.papercode
FEW-NERD: A few-shot named entity recognition dataset, in ACL-IJCNLP, 2021. N. Ding, G. Xu, Y. Chen, X. Wang, X. Han, P. Xie, H. Zheng, and Z. Liu.papercode
CrossFit: A few-shot learning challenge for cross-task generalization in NLP, in EMNLP, 2021. Q. Ye, B. Y. Lin, and X. Ren.papercode
ORBIT: A real-world few-shot dataset for teachable object recognition, in ICCV, 2021. D. Massiceti, L. Zintgraf, J. Bronskill, L. Theodorou, M. T. Harris, E. Cutrell, C. Morrison, K. Hofmann, and S. Stumpf.papercode
FLEX: Unifying evaluation for few-shot NLP, in NeurIPS, 2021. J. Bragg, A. Cohan, K. Lo, and I. Beltagy.paper
Two sides of meta-learning evaluation: In vs. out of distribution, in NeurIPS, 2021. A. Setlur, O. Li, and V. Smith.paper
Realistic evaluation of transductive few-shot learning, in NeurIPS, 2021. O. Veilleux, M. Boudiaf, P. Piantanida, and I. B. Ayed.paper
FewNLU: Benchmarking state-of-the-art methods for few-shot natural language understanding, in ACL, 2022. Y. Zheng, J. Zhou, Y. Qian, M. Ding, C. Liao, L. Jian, R. Salakhutdinov, J. Tang, S. Ruder, and Z. Yang.papercode
Bongard-HOI: Benchmarking few-shot visual reasoning for human-object interactions, in CVPR, 2022. H. Jiang, X. Ma, W. Nie, Z. Yu, Y. Zhu, and A. Anandkumar.papercode