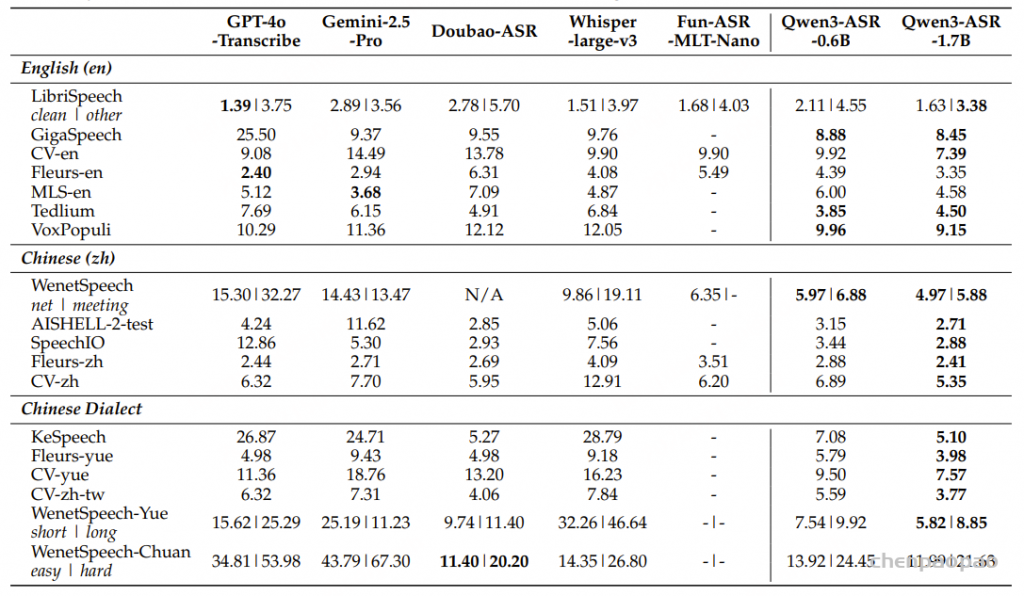
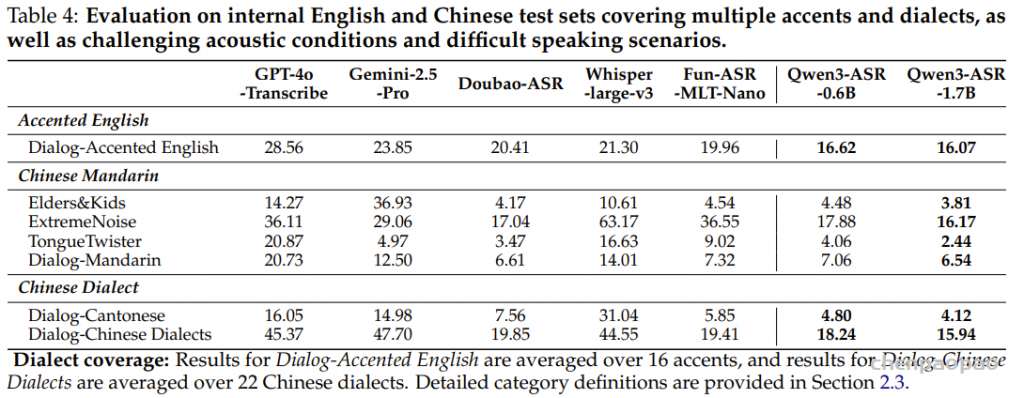
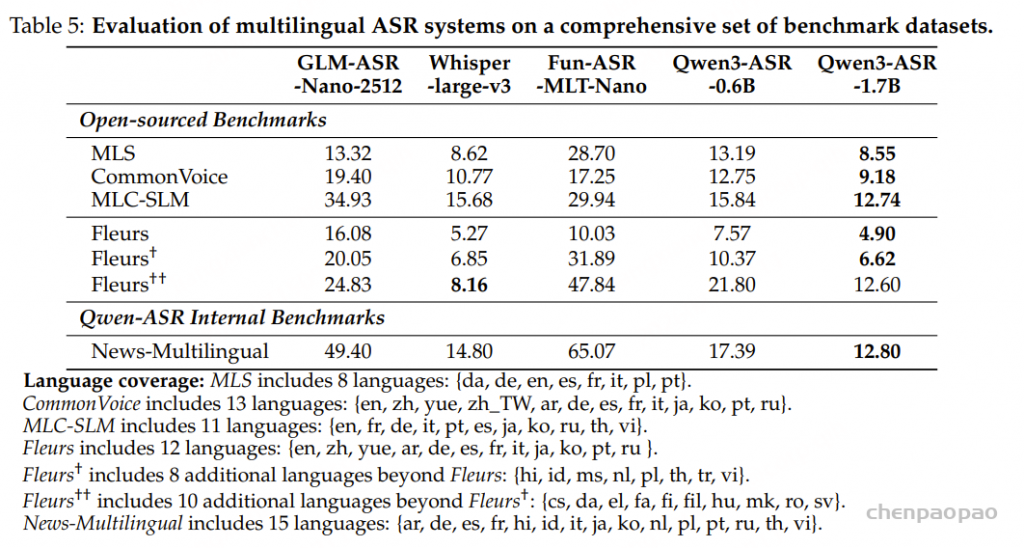
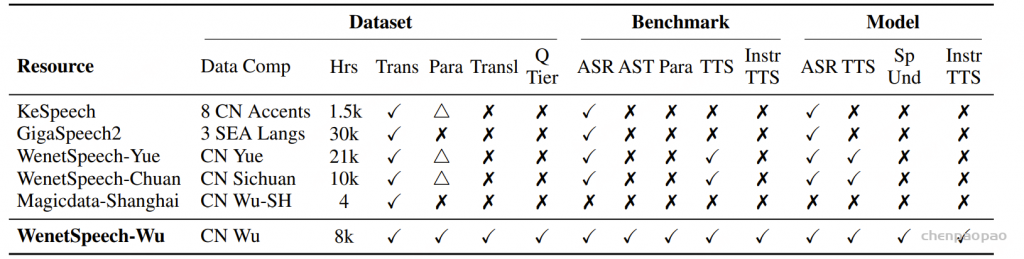
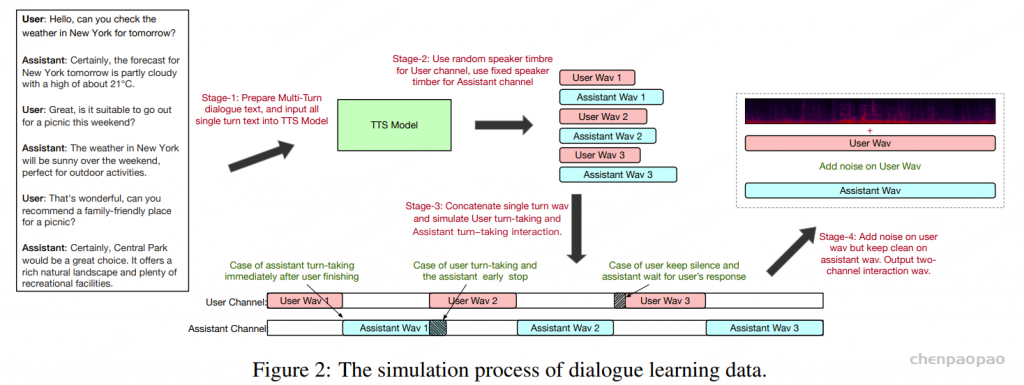
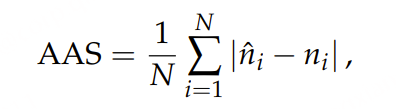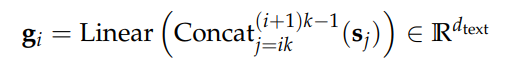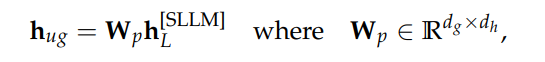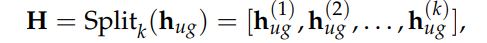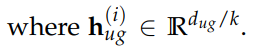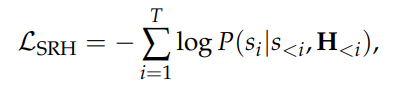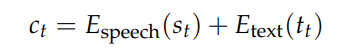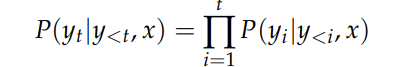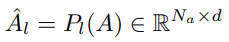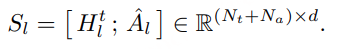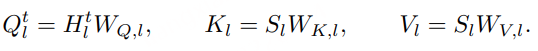原文链接:https://kyutai.org/codec-explainer
方案:将语言模型嵌入音频编码器/解码器对(=神经音频编解码器)中,使其能够预测音频的后续内容。 截至 2025 年 10 月,Speech LLM 的表现还很糟糕。许多 LLM 都提供了语音接口,但它们的工作流通常是:语音转文字,生成文本答案,再通过 text-to-speech (TTS) 读出来。这在很多场景下够用了(比如 Unmute),但这本质上只是一个 wrapper,并非真正的语音理解。模型无法感知你声音里的沮丧并共情地回应,无法在回答中强调重点,也听不出讽刺。
是的,现在确实有一些 LLM(如 Gemini、ChatGPT 的 Advanced Voice Mode、Qwen、Moshi)能够原生 (natively) 理解和生成语音。但在实践中,它们要么不够智能,要么其行为就像一个 text model wrapper。你可以试试用很高的音调问它们任何一个:“我说话的声音是低还是高?”,它们都答不上来。
显然,Speech LLM 的发展滞后于 Text LLM。但为什么呢?对于文本,我们几年前就发现,只要有海量文本数据、一个巨大的 Transformer 模型和大量的 GPU,就能得到效果惊人的文本续写模型。那为什么我们不能直接把 text 换成 audio,然后得到同样惊人的语音续写模型呢?
先卖个关子,如果你真的天真地这么做了,就会得到下面这种结果(警告,音量很大):
接下来,我们将探讨为什么 audio 比 text 更难建模,以及如何利用 neural audio codec 来降低建模难度。——这已是将 audio 输入和输出 LLM 的实际标准方法。通过 codec,我们可以将连续的音频信号转换成更大粒度的离散 token,然后训练模型来预测这些 token 的后续序列,最后再将这些 续写的token 解码还原成 audio:请看上面的动画。
Kyutai 的同仁们在这个领域做了大量工作,这也是我选择这个主题的部分原因。我们将从基础讲起,一直讲到我们的 neural audio codec——Mimi Moshi CSM 模型
Text is easy 在文本分词方面,业界普遍采用一种称为字节对编码 (Byte-Pair Encoding, BPE)的技术,并且极少对分词器进行更改。以 OpenAI 为例,自 GPT-4o 以来一直沿用同一套分词器——如果以大语言模型的发展节奏来衡量,GPT-4o 已可算作“相当久远”的模型。
A random text from Wikipedia tokenized via the GPT-4o tokenizer 即便完全不对文本进行分词、仅对单个字符进行逐字符预测,也能够取得相当不错的效果。早期让我对机器学习产生浓厚兴趣的一篇文章,是 Andrej Karpathy 于 2015 年发表的关于循环神经网络(RNN)有效性的博客。在那篇文章中,Karpathy 使用单块 GPU 训练了一个三层 LSTM 模型,使其能够生成结构上较为合理的代码与 LaTeX 文本。
要知道,这可是十年前的事了,那时候我们甚至还不知道 “attention is all we need”。现在,我们再来对比一下 Karpathy 的结果和 WaveNet 的样本,后者是 DeepMind 在一年后发布的模型:
从纯声学角度来看,这段音频的听感质量较高,但却几乎无法生成哪怕一个正确的英文单词。当然,我们也不应对 WaveNet 过于苛责。Karpathy 的 RNN 所生成的文本样本长度不过数千个字符,而这段 10 秒的音频却包含约 16 万个音频采样点;并且,WaveNet 是以逐采样点预测(sample-by-sample generation)的方式,极其细致地生成整段音频的。
一秒钟的音频通常包含数以万计的采样点,然而其语义内容往往只对应少量几个词语。(动画引自 WaveNet 博客文章。) 在如此长的时间尺度上维持生成内容的连贯性是极具挑战性的;同时,由于需要执行数量庞大的逐步预测,模型的运行开销也十分高昂。
因此,与其让模型直接逐采样点地进行预测,不如先训练一个模型,将音频压缩到更易处理的表示空间。具体而言,可以先对音频进行压缩,在压缩后的表示上利用大语言模型预测其后续内容,再将预测结果解压还原为音频信号。
Sample by sample
不过,在此之前,我们先构建一个基线模型,像 WaveNet 那样逐采样点生成音频。这些实验的代码均已开源,可在相应仓库中获取。我基于 Andrej Karpathy 的 nanoGPT 仓库进行了复现与扩展;该仓库是 GPT-2 的一个简洁实现版本。
从语言模型的视角来看,文本与音频在形式上并无本质区别:本质都是“输入 token,输出 token”。因此,我们需要做的仅是将连续的音频采样值量化为离散的取值区间。与 WaveNet 类似,我们采用 μ-law(μ律)算法,将连续振幅映射到 256 个离散桶(buckets),并将其视作 256 个可能的离散 token。
在此基础上,我们使用这种逐采样点量化后的音频 token 来训练一个语言模型。数据集方面,沿用 AudioLM (Neil Zeghidour 与 Eugene Kharitonov)的设置,采用 Libri-Light 数据集。该数据集的训练集总时长约为 5 万小时,但在本实验中我们仅使用其中 1000 小时的数据。采用逐采样点的离散化方式后,最终得到的训练数据规模约为 53GB。
模型方面,我们训练了一个规模相对较小的 Transformer,总参数量为 151.28M,与最小规格的 GPT-2 模型大致相当。当从该模型进行采样生成时,其输出表现为类似咿呀学语般的声音(提示:音量有时较大)。
模型往往会进入一种“噼啪杂音模式”(crackling mode),并且一旦陷入其中,似乎难以自行恢复:
我还训练了一个较小的模型,就是之前开头提到的那个。它容易生成令人不适的尖锐噪声(音量较大!)。
正如你所看到的,我们还远未达到通用人工智能(AGI)的水平。模型生成的音频听起来像是语音,但你几乎听不出任何单词,而且声音也在不断变化。这也不足为奇:模型的上下文长度为 2048,对于 16 kHz 的音频而言,仅相当于 128 毫秒,连一个单词的长度都不到。此外,这些 10 秒的音频样本在 H100 上生成耗时约 30 分钟——距离实时生成还有几个数量级的差距。
因此,我们需要构建一个神经音频编解码器(neural audio codec)来压缩音频。思路是:如果将采样率降低 100 倍,模型生成的内容也有望变得“100 倍更连贯”。在机器学习中,一个经典方法是使用自编码器(autoencoder) :该模型接收输入,将其压缩到较小的“潜在空间(latent space)”,然后尝试重构原始输入。
在我们的场景下,需要一个潜在表示可量化(quantized)的自编码器 ,这样才能将潜在向量输入到语言模型中,并生成后续内容。当然,也可以使用未量化的潜在向量生成后续音频,但操作会更复杂——具体可参见“进一步阅读 ”部分。
Autoencoders with vector quantization (VQ-VAE)
请耐心一点,因为我们将从音频领域绕个弯:让我们基于 Fashion MNIST 的图像来构建一个量化的自编码器(quantized autoencoder)。我们会使用一个包含前三个类别的数据子集:T恤 、裤子 和套头衫 。
首先,我们先训练一个普通自编码器 ,将图像编码到二维潜在空间(2D latent space)中:
Training a regular autoencoder on Fashion MNIST 每一帧显示的是一个训练批次(有些批次被略过)。小图像表示自编码器对该批次图像的重构结果。我为三类图像添加了颜色标记(T 恤/上衣 = 蓝色、裤子 = 绿色、套头衫 = 黄色),但自编码器并没有接收类别信息作为输入——潜在空间自然会根据类别形成聚类。接下来,我们放大观察几张重构结果:
Original images (top) and their reconstructed versions (bottom) 如你所见,重构效果并不理想。图像比较模糊,而且前两张重构几乎完全相同。但我们使用的网络非常小——编码器和解码器各只有四层全连接网络,并且只将数据投影到二维空间,因此不能对模型期望过高。
接下来,我们将对这些潜在向量进行量化(quantization),方法是通过聚类实现。大致步骤如下:
类似 k-means :维护一个簇中心(cluster center)的位置列表。 簇中心初始化为随机位置。 对每个训练批次:查看每个潜在向量属于哪个簇(assignment),注意我们 不修改潜在向量 ,仅进行分配。 将每个簇中心向其所属潜在向量的平均位置轻微移动(nudge)。 如果某个簇中心长时间未被分配到任何潜在向量,则将其重新“传送”到当前批次的某个随机潜在向量上,以避免簇中心陷入局部停滞。 Quantizing by fitting a clustering on top of the autoencoder 你可以看到,随着训练的进行,簇中心的重构效果逐渐被优化和细化。
接下来,我们希望让编码器(encoder)和解码器(decoder)在训练过程中更好地处理量化后的潜在向量(quantized embeddings)。目前,我们只是将聚类操作叠加在一个对量化“未知”的自编码器 之上——也就是说,模型在训练时并没有意识到潜在向量会被量化。我们希望自编码器在训练过程中适应量化操作 ,从而生成更易重构的量化表示。目前的做法是:
x = get_batch()
z = encoder(x)
x_reconstructed = decoder(z)
loss = reconstruction_loss(x, x_reconstructed)与其将未量化的潜在向量直接输入解码器,我们先将其映射到最近的簇中心 :
x = get_batch()
z = encoder(x)
z_quantized = to_nearest_cluster(z) # 👈
x_reconstructed = decoder(z_quantized) # 👈
loss = reconstruction_loss(x, x_reconstructed)这里有一个问题:如果直接这样做,自编码器就无法继续训练了。原因是量化操作不可微 ,也就是说,损失函数的梯度无法传回编码器的权重。本质上,模型无法回答这个问题:“如果我想让损失减少一点,应该沿哪个方向调整编码器的权重?”
解决方法很巧妙:假装这个问题不存在 。具体来说,我们将量化后的潜在向量 zquantized 任意向量,但不影响梯度 。这样, zquantized straight-through gradient estimator(直通梯度估计器) 的原理。
x = get_batch()
z = encoder(x)
residual = z - to_nearest_cluster(z)
# .detach() means "forget that this needs a gradient"
z_quantized = z - residual.detach()
x_reconstructed = decoder(z_quantized)
loss = reconstruction_loss(x, x_reconstructed)在前向传播(forward pass)中, zquantized quantized to_nearest_cluster(z) 操作而为 0。
这种“假装”做法是有代价的:在训练时,编码器的权重会根据重构损失进行更新,但更新的方向是假设量化不存在的方向 ,因此不一定是最优的梯度方向。但只要潜在向量大致保持在各自簇中心附近,这个梯度方向仍然是“基本正确”的。
为了让编码器生成更容易量化的潜在向量,我们可以引入承诺损失(commitment loss) :对每个潜在向量根据其距离簇中心的远近施加惩罚 。这一损失的梯度会将潜在向量推向对应的簇中心,从而提高量化友好性。
通过在训练时进行量化并加入承诺损失,模型不再只是单纯在嵌入上做聚类,而是自编码器本身被训练成对量化友好 ,从而在后续生成和压缩中表现更好。
An autoencoder trained explicitly to be easy to quantize 你会注意到,训练动态发生了变化:加入承诺损失(commitment loss)为潜在向量增加了一定的“约束力(stiffness)”,使它们不再像之前那样自由移动。
下面是使用量化潜在向量 进行重构的效果:
注意前两张图被重构成了完全相同的图像。这只是因为它们的潜在向量被分配到同一个簇,因此量化后取到了相同的值。
这里描述的模型被称为 VQ-VAE(向量量化变分自编码器) 。其中的“变分(variational)”一词在这里已经没有实际意义,只是历史遗留的命名。
Residual vector quantization
为了提高重构的保真度,我们可以简单地增加簇中心的数量。但如果簇中心过多,计算和内存开销会变得非常昂贵。因此,我们采用一个巧妙的做法:如果希望潜在向量有 2^20(约 100 万)种可能值,我们不会直接创建 2^20 个簇。相反,我们使用两个独立的量化器(quantizer),每个量化器有 2^10=1024 个簇,然后将它们的结果组合起来。这样,每个潜在向量就量化为两个整数的元组(每个在 0–1023 之间),总共有 2^20 种可能组合。
那么具体怎么做呢?回想一下我们在直通梯度估计器(straight-through estimator)中使用的残差变量:residual=z−to_nearest_cluster(z)
它表示在量化到最近簇中心时,原向量 z 中未被捕捉到的部分。
对于批次中的每个潜在向量,我们都有对应的残差向量。解决方案很自然:用与原始潜在向量相同的方法对残差向量进行量化 ,通过训练另一个向量量化器实现。
这一次,由于我们需要组合两个量化器,单个量化器的二维簇位置并不再对应图像,因此我们将其可视化为点的分布 即可:
这是二级量化(two-level quantization)的思路:在第一级量化器量化后的 残差(residuals,也就是第一级量化器的误差)上,再训练一个量化器进行进一步量化,从而更精细地表示潜在向量。 这样,每张图像就可以用潜在向量所在簇的索引 和残差簇的索引 来表示。接下来,我们用这个二级量化器尝试重构几张图像:
原始图像(顶部)、一级量化重构(中部)、二级量化重构(底部)。这些图像在二级量化下分别被编码为索引对:(4, 3)、(4, 5)、(16, 21) 和 (30, 3)。 前两张图像的重构仍然相似,但不再完全相同:第一张图被编码为 (4, 3),第二张图为 (4, 5)。换句话说,它们在第一级量化器 上使用相同的 token,但在残差的量化上有所不同。由于差异较为微小,下面是一级量化与二级量化重构效果的对比 :
我想强调的是,第二级量化作用在潜在向量(embedding)上,而不是直接修改输出像素。这一点可以从最左和最右的图像看出,它们分别编码为 (4, 3) 和 (30, 3)。也就是说,它们使用了相同的残差编码 3,但对两张重构图像的影响却不同。
显然,重构效果仍然不够精确。潜在向量未量化时的重构质量才是上限,因此如果自编码器本身性能不好(我们的就是如此),改进量化方法也无法带来显著提升。
到这里我们先暂停,但这个思路的自然延伸是超过两级量化 :对二级重构的残差继续量化,依次我们在这里就先停下。不过,这个思路的一个自然扩展是引入多于两级的量化。只需要对 two-level reconstruction 的 residual 再次进行量化,如此反复即可。这个广义的 Residual Vector Quantization 算法形式如下:
def rvq_quantize(z):
residual = z
codes = []
for level in range(levels):
quantized, cluster_i = to_nearest_cluster(level, residual)
residual -= quantized
codes.append(cluster_i)
return codes残差向量量化(Residual Vector Quantization, RVQ)最早在 SoundStream 中应用于神经音频编解码器,但这一思想其实早在 1980 年代就已出现。
Now let’s tokenize audio
将 RVQ 应用于音频是相当直接的。作为我们的自编码器(autoencoder),我们将使用一个类似于 Jukebox 所使用的卷积神经网络(CNN)。这里的架构细节并不太重要。重要的是,这是一个能接收 t 个采样点的音频,并将其转换为形状为 (t/128, 32) 的向量的网络。换句话说,它以 128 倍的系数进行降采样(downsamples),并为我们提供 32 维的浮点数表示。然后,解码器(decoder)接收这个 (t/128, 32) 的嵌入(embeddings),并将它们解码回 t 个采样点。
audio = get_batch() # shape: [B, T]
z = encoder(audio) # shape: [B, T/128, 32]
audio_reconstructed = decoder(z) # shape: [B, T]和之前一样,我们将在编码器之后添加一个 RVQ。与处理图像的唯一区别是,对于每个音频样本,我们有 t/128 个嵌入向量,而不仅仅是像图像那样只有一个。我们只需独立地对这些向量进行量化(即使编码器“看到”的音频范围比单个向量所对应的范围要广)。在训练期间,我们还有一个批次维度(batch dimension),所以我们的模型现在看起来是这样的:
audio = get_batch() # [B, T]
z = encoder(audio) # [B, T/128, 32]
# Combine the batch and time dimensions
z = rearrange( # [B*T/128, 32]
z, "b t_emb d -> (b t_emb) d"
)
codes = rvq_quantize(z) # integers, [B*T/128, levels]
z_quantized = codes_to_embeddings(codes) # [B*T/128, 32]
z_quantized = rearrange( # [B, T/128, 32]
z_quantized, "(b t_emb) d -> b t_emb d"
)
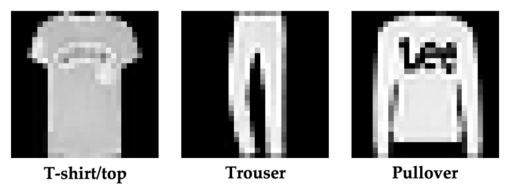
audio_reconstructed = decoder(z_quantized) # [B, T]在我们训练第一个神经音频编解码器(neural audio codec)之前,最后缺少的一块是损失函数(loss function)。关于选择哪一个损失函数,我们可以深入探讨一整套复杂理论,但我们将避开它,只使用一个非常简单的。我们会计算原始音频和重建音频的对数振幅谱图(log amplitude spectrogram),然后取它们的差值。这个差值的均方值就是损失。
为了让模型更难对这个损失函数过拟合,我们使用三种不同的短时傅里叶变换(short-time Fourier transform)参数来计算谱图,并将我们的损失设为这三个子损失的平均值。这被称为多尺度频谱损失(multi-scale spectral loss) 。
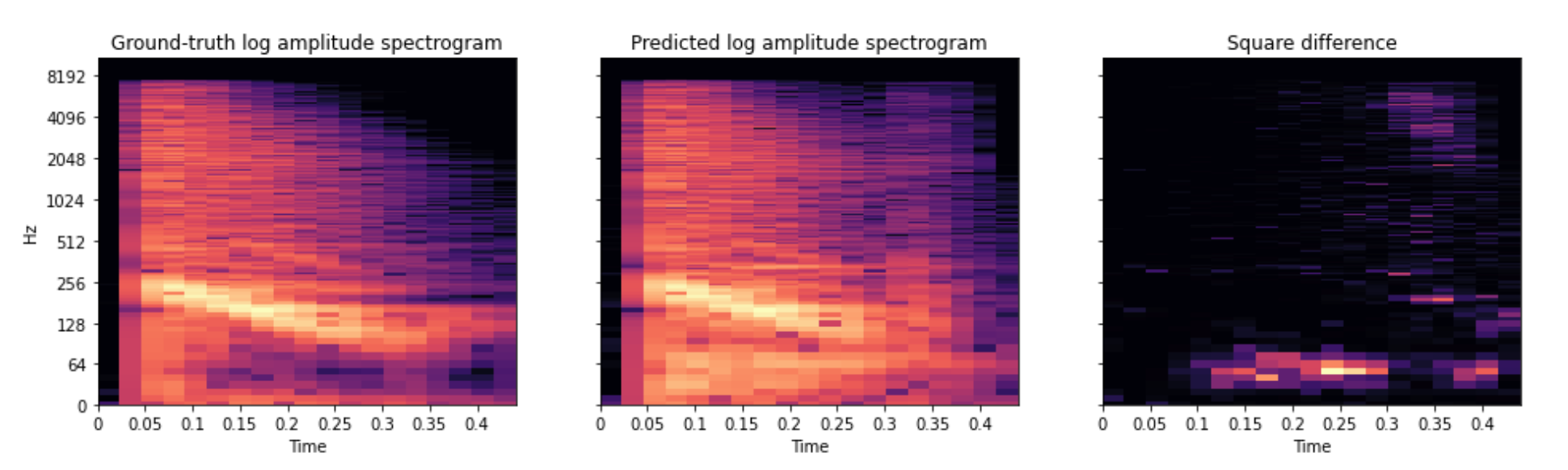
最后,让我们来训练一些编解码器(codecs)吧!我们将观察改变 RVQ 的层级(levels)数量如何影响重建质量。正如我们所预期的,增加层级数量有助于降低频谱损失(spectral loss):
让我们听听这些编解码器听起来怎么样。我们将使用这三个编解码器来重建来自 Expresso 数据集的这段音频:
原始音频 重建结果:
4 RVQ levels 8 RVQ levels 12RVQ levels 显然,随着增加更多的残差向量量化(RVQ)级数,音频质量逐渐提升。
即便使用 16 级量化,仍然会出现一些噼啪杂音,音频听起来有些闷,并伴随持续的高频噪声。后续我们会讨论进一步改进编解码器的方法,但出于演示目的,目前的效果已经足够。
为什么要关心音频 所以现在我们有了一个 神经音频编解码器 :我们可以把音频转换成适合 LLM 的 token,然后再还原回音频。这里的 “Codec” 本质上就是音频的 分词器 (tokenizer),但我们用 “codec” 这个词,是因为它在经典压缩格式(比如 MP3)里已经被使用。我会把 codec 和 tokenizer 交替使用。
回到我们最初想做的事情:建模音频 。具体来说,我们要做一个模型,它可以接受一段音频前缀,然后生成一个合理的续段。
提醒一下,我们的目标是训练优秀的音频 LLM,使模型能够 原生理解并生成语音 ,理解情绪、重音等特征。它们还可以进一步微调成 文本转语音、语音转文本、翻译模型 等。
既然你已经相信音频 LLM 是通向 AGI 的路径,那我们就开始训练几个模型吧。
在数据集方面,我们将使用 Libri-Light ,就像之前训练逐样本模型时用的那样。这一次我们会使用 10000 小时音频 ,而不是之前的 1000 小时。这个数据集是 公共领域有声书 ,所以如果我们训练出了一个不错的模型,也许能生成更多故事(不过不要抱太大希望)。我们唯一需要做的,就是把音频数据集转换成 离散 token 序列 ,以便输入到 LLM 中。
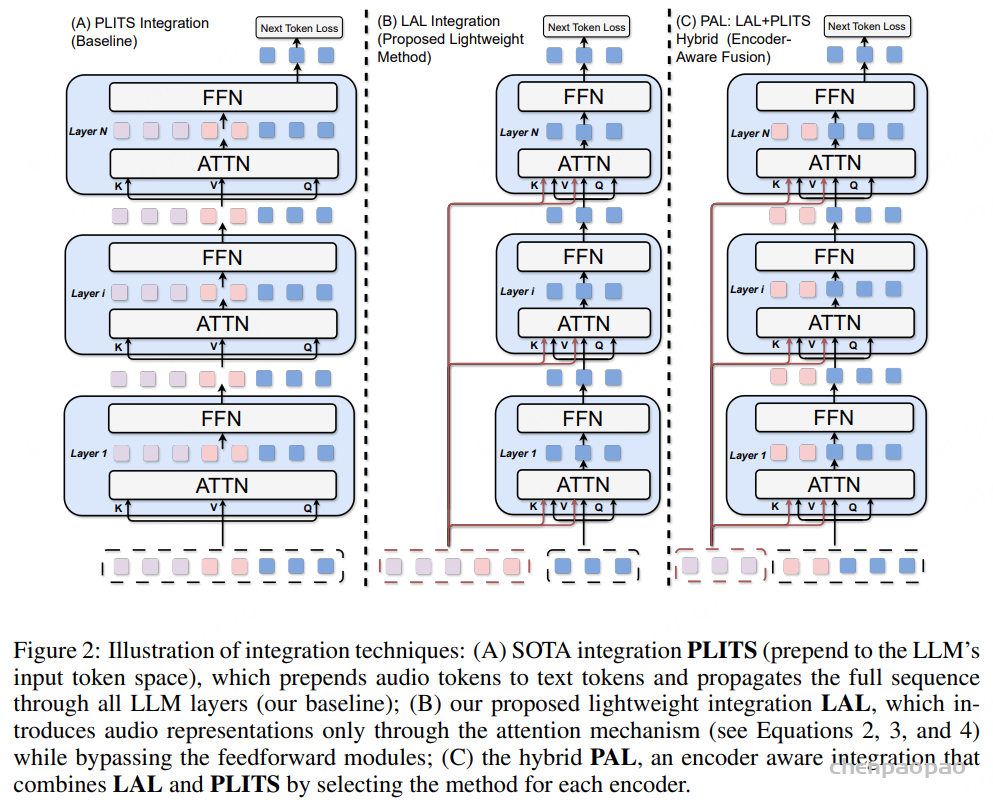
处理多个层级(levels) 我们将使用我们的 8 层 RVQ codec 来实现这一点。对于一个有 t 个采样点的音频,我们将得到一个形状为 (t/128, 8) 的 token 数组。但现在有一个问题:如何处理在每个时间步(time step)不是一个而是 8 个 token 的情况?在文本 LLM 中我们无需处理这个问题,因为我们只有一个 token 序列。
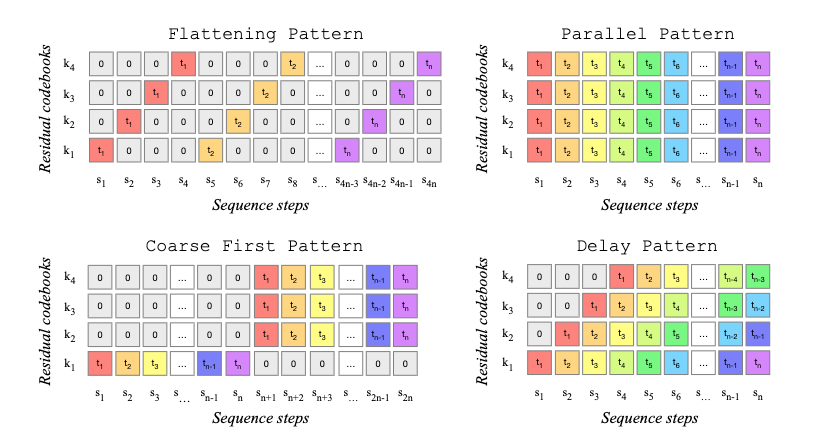
我们将采取最简单的方法,直接将该数组展平(flatten)成一个形状为 (t/128 * 8) 的一维数组,并让我们的 LLM 在不同的时间步中预测这八个层级。
lattening a three-level RVQ to allow it to be fed into a language mode 这样做的一大缺点是我们损失了一部分时间压缩(temporal compression)能力。我们将音频降采样了 128 倍,但现在通过展平层级,又将其“膨胀”了 8 倍。这使得推理(inference)效率降低,并且可能导致质量下降,因为有效上下文大小(context size)减小了。我们将使用 8 层的 RVQ codec 而不是 16 层的,以避免让压缩情况变得更糟。
你也可以一次性预测单个时间步的所有 RVQ 层级(“并行模式”,parallel pattern),但这也会让模型更难处理,因为它必须一次性决定所有层级。人们还尝试了许多其他方案来平衡压缩与质量。以下是 MusicGen 中尝试过的几种方案:
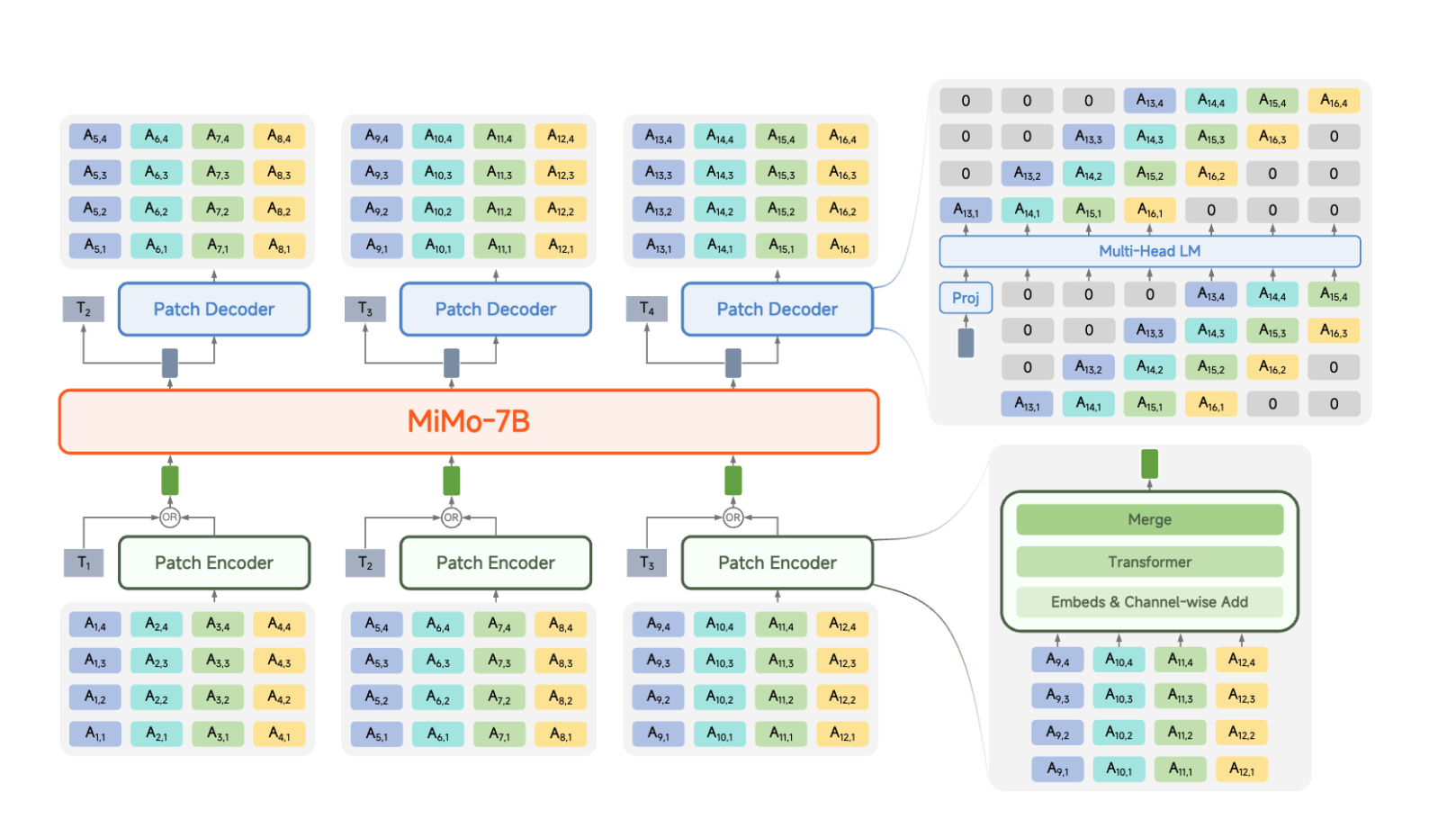
有趣的是,截至 2025 年,还没有一个“胜出”的统一解决方案:每篇论文的做法都不同,而且这些方案可能变得相当复杂。看看这个来自 MiMo-Audio 的图表就知道了,这是一个在 2025 年 9 月发布的模型:
处理 多个 RVQ 级别 的方法可能会相当复杂。 Finally, let’s train
终于到了训练一个封装了 codec 的语言模型的时候了!正如我所提到的,我们的代码基于 Andrej Karpathy 用于训练文本 LLM 的 nanoGPT 代码库。我们只需要修改它以接受音频作为输入。但这很简单,因为 LLM 并不关心你输入的是哪种 token——对它来说都只是数字而已。一旦我们将数据集标记化(tokenized)并将其展平(flattened)为一维序列,我们就可以开始了。以这种方式标记化后,我们 10000 小时的音频占用了 134 GB 的空间。相比之下,将这么多数据存储为未压缩的音频将需要超过 1 TB。
我们将使用与逐样本(sample-by-sample)模型完全相同的模型架构和超参数(hyperparameters):唯一的区别在于标记化(tokenization)方式。我们的数据集也大了 10 倍,但逐样本模型甚至连 1000 小时的数据集都无法容纳,所以更多的数据也救不了它。
我用 8 个 H100 显卡训练了这个模型大约 5 天。为了得到一些样本,我决定用 Michael Field 的诗《七月》中的两行 Libri-Light 朗读样本来提示(prompt)模型。(在做这个项目时我了解到,Michael Field 是 Katherine Harris 和 Edith Emma Cooper 的笔名。)让我们看看能从我们的模型中得到什么样的诗歌:
可以看到一些“生命的迹象”,但我们还没有一个真正的“诗人”。听起来就像有人在 帘幕后面说话 :你无法完全听清它在说什么,但 语调是存在的 ——听起来像有人在朗读书本,而这正是模型训练时的内容。
它还能保持 连贯的声音 ,直到最后几秒才切换到另一个声音。这也与训练数据一致:我们从所有有声书中 剪切片段并混合在一起 来采样训练数据,所以模型确实会遇到 不同说话人之间的界限 。
一个 codec 能带我们走多远? 我们的 codec 是有意设计得非常简单的,这也解释了为什么结果不尽如人意——但在过去四年里,关于神经音频编解码器的研究已经相当丰富,我们可以加以利用。我们不会在这里实现所有的改进,而是看看当我们使用 Mimi 作为分词器(tokenizer)时会发生什么。
Mimi 是 Kyutai 为我们的音频语言模型 Moshi 构建的一款现代神经音频编解码器。此后,它也被用作其他模型的分词器,如 Sesame CSM、VoXtream 和 LFM2-Audio。
不出所料,Mimi 听起来比我们之前训练的自制 codec 好得多。
Mimi 没有使用多尺度频谱损失(multi-scale spectral loss),而是使用了像 GAN 一样的对抗性损失(adversarial loss)。有一个判别器网络(discriminator network)试图将音频分类为原始的或由 codec 重建的,而 codec 的目标就是骗过这个判别器。
Mimi 增加的另一个改进是使用 RVQ dropout :它使用 32 个 RVQ 层级,但在训练期间,重建有时会随机截断到较少的层级数。这使得我们可以在推理时以较少的 RVQ 层级运行 Mimi,并且仍然获得不错的结果,因为它不依赖于所有层级的存在。而对于我们的自制 codec,我们必须分开训练。
让我们听听用 Mimi 重建的示例音频:
Original:
重建:
4 RVQ levels 16 RVQ levels 32 RVQ levels 就我们的目的而言,层级较少的变体可能更容易建模,因为它压缩程度更高。让我们用 8 层和 32 层的 Mimi 来训练模型,并比较结果。
我训练了和之前完全相同的模型架构,唯一改变的是分词器。数据集仍然是来自 Libri-Light 的 10000 小时音频,就像我们使用简单 codec 时一样。Mimi 的采样率是 24 kHz,但 Libri-Light 使用的是 16 kHz,这限制了声音的最高品质,因为我们丢失了音频的更高频率部分。
Mimi 对音频的降采样(downsample)也更激进:它的帧率是每秒 12.5 帧,而我们的 codec 是每秒 125 帧——高了 10 倍!这意味着数据集在磁盘上的体积也更小。用我们的 codec,它占了 134 GB,但用 Mimi,“仅仅”是 54 GB。
这是一首用在 Mimi 标记化数据上训练的模型生成的诗。我和之前一样,用诗中的两行来提示它:
这是我尽力尝试的转录:
When the grass is gone sees zin in them.
对我来说有点太超现实主义了,但也许刘易斯·卡罗尔会喜欢。
语义 token (Semantic tokens) 我得坦白一件事:我刚才对你撒谎了。但只是一点点,而且是为了教学目的。实际上,上面的模型是在一个 31 层的 Mimi 音频上训练的,我省略了第一层,也就是包含 “semantic token ” 的那一层。
这个 token 的作用是表示音频的语义信息,而不一定有助于重建。我不会深入探讨它们的工作原理,但简单来说,Mimi 的 semantic tokens 是从 WavLM 中提炼出来的,你可以把它看作是语音领域的 BERT。
为了感受 semantic tokens 编码了什么信息,让我们以这个示例音频为例,将其通过 Mimi 处理:
现在,让我们训练一个基于完整 Mimi(包括 semantic tokens)的语言模型。我们将以一种特殊的方式运行模型:保留原始音频的 semantic tokens,但丢弃其他所有 token,然后让模型来预测它们。这意味着来自 semantic tokens 的信息是固定的(“teacher-forced”),但模型可以根据它认为合理的延续自由决定其他 token。
通过固定 semantic tokens 并让模型重新生成其余部分,我们可以了解 semantic tokens 中包含了哪些信息。 听听我们用这种方式得到的两个不同的重建版本:
声音完全不同,但说的内容是一样的!这意味着 semantic tokens 编码了说话者在说什么,但与嗓音无关。这很有用,因为它帮助模型专注于 说什么 ,而不是 怎么说 。在这方面,它们更接近于文本 token,因为文本 token 也不包含关于嗓音、语调、时间或情感的信息。
让诗歌更具语义 现在,让我们用在包含语义的 Mimi 上训练的模型来完成这首诗:
When grass is gone from the man was nothing moan. .
它仍然会编造词汇,句子也不太连贯,但很明显,真实单词的比例高了很多;模型变得“更具语义”了。声音质量和之前一样,这也符合我们的预期。
让我们听第二首诗:
When grass is gone
确实,the whom?
语义与声学的权衡 (Semantic–acoustic tradeoff) 我们可以 牺牲一些声学质量 来提升语义效果,通过 减少 RVQ 级别的数量 。我们选择 8 级。这样一来,我们获得了 更高的音频压缩率 ,同时损失中 语义 token 占比也相应提高 ,因为现在是 1/8 的 token,而不是之前的 1/32。
我对这个模型的第一印象之一是,它学会了 记忆 Librivox 的版权声明 ,所以有时它会生成类似这样的内容:
Chapter 6 of The Founday, by R. Auclair.
重复训练数据通常不是你想要的,但在我们的案例中,这是一个极好的生命迹象,因为之前的模型甚至连这个都做不到。它还编造了书名、作者和朗读者,所以这里仍然有创新性。
现在,让我们尝试创作更多的诗:
When grass is gone
end of poem.
This recording is in the public domain.
[different voice]
这太棒了。有几个迹象表明这个模型比之前的更好。我喜欢它编造了“mollity”这个词,然后在下一行重复它。而且,它意识到自己正在背诵一首诗,并在该部分结尾加上了 “end of poem”。然后它认为这是章节/部分的结尾,并以“This recording is in the public domain.”的声明结束。之后,它换了个声音继续说话。这是合理的,因为在训练过程中,来自不同有声读物的片段只是被随机打乱并连接在一起,所以在这里模型模拟了一个片段边界。
如果我们给 semantic tokens 的损失赋予比声学 tokens 更高的权重,可能会得到更好的结果,让模型更关注意义而非声音——事实上,Moshi 使用了高达 100 倍的 semantic loss !但我们总得有个终点。
Conclusion
我们成功地使用神经音频编解码器制作了一个能生成某种程度上连贯语音的音频语言模型。显然,这还不是 2025 年的顶尖水平(我们在这里也并非追求于此),但请记住,使用完全相同的模型,若不采用神经音频编解码器,我们得到的是类似于开头的音频。
当然,要赶上文本模型还有很长的路要走!目前,语音理解和推理能力之间似乎存在一种权衡。在文章开头我提到,那些原生支持语音的模型(Gemini、ChatGPT 的高级语音模式、Qwen、Moshi)都无法判断你是在用高音还是低音说话,尽管它们被训练来原生理解音频。这可能是因为它们在大量使用文本到语音技术合成的数据上进行训练,或因为理解声音的音调(显然)并不能帮助模型做出更准确的预测。
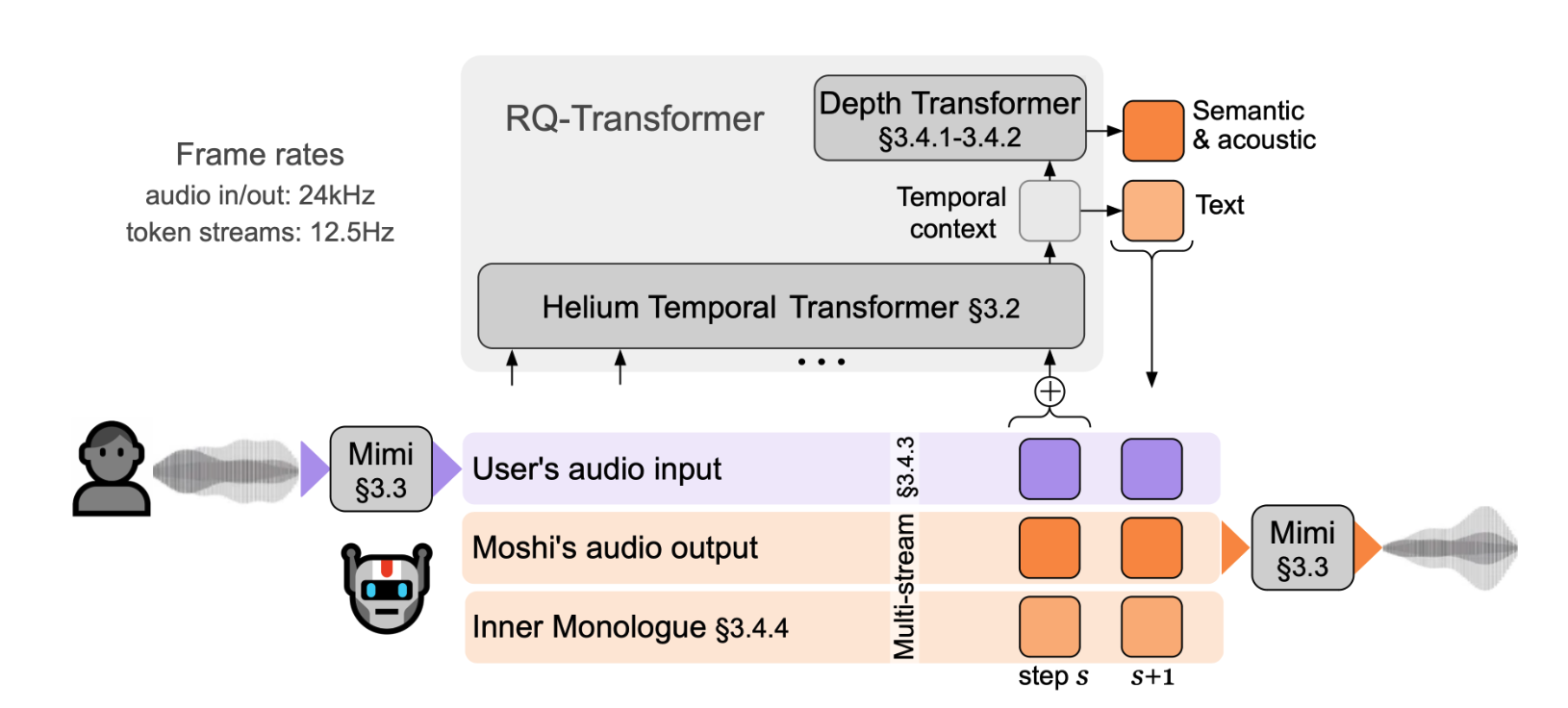
Kyutai 曾尝试用 Moshi(demo,论文)创建一个基于音频语言模型的语音聊天应用,并于 2024 年 7 月发布。Moshi 可能不是你会选择帮你做作业的 AI,但请对它宽容一些:它是第一个端到端的语音 AI,甚至比 OpenAI 的高级语音模式发布得还要早。
Moshi 为自己和用户并行地模拟了一个“内心独白”的文本流和音频流。文本流帮助它规划要说什么,而消融研究(ablations)表明,文本流对模型的帮助巨大。同时,这也有点可悲:大部分的推理似乎都被委托给了文本流,而音频流只是用来提供集成的语音到文本和文本到语音功能。
Moshi models two audio streams and a text stream in parallel这不仅仅是 Moshi 的问题:正如“我是在用高音说话吗”的实验所示,这种对文本而非音频的过度依赖是所有音频 LLM 的一个问题。尽管主流的建模方法与 Moshi 有所不同:它们是交错处理文本和音频 token,而不是在并行流中建模。
在 Moshi 发布一年多后,音频模型仍然落后于文本 LLM。但为什么呢?对我来说,这个神秘且未解的“模态鸿沟”(modality gap)使得音频机器学习成为一个令人兴奋的研究领域。