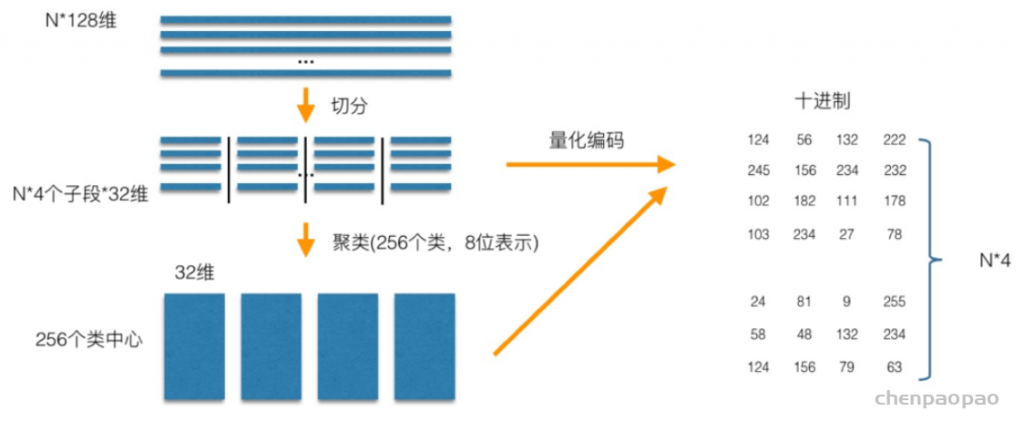
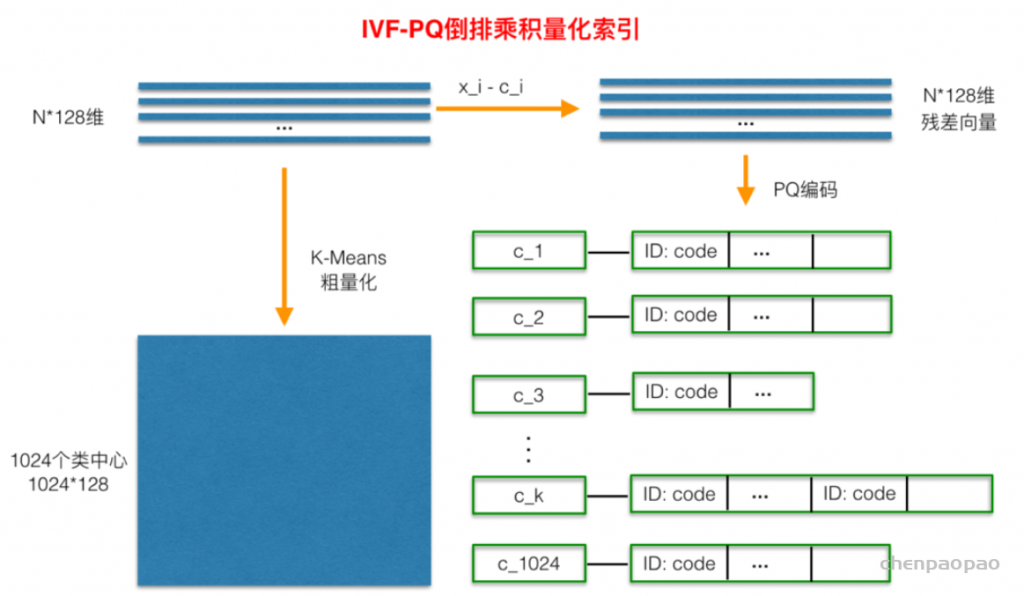
进程与线程的概念,以及为什么要有进程线程,其中有什么区别?
1. 基本概念:
进程是对运行时程序的封装,是系统进行资源调度和分配的的基本单位,实现了操作系统的并发;
线程是进程的子任务,是CPU调度和分派的基本单位,用于保证程序的实时性,实现进程内部的并发;线程是操作系统可识别的最小执行和调度单位。每个线程都独自占用一个虚拟处理器:独自的寄存器组,指令计数器和处理器状态。每个线程完成不同的任务,但是共享同一地址空间(也就是同样的动态内存,映射文件,目标代码等等),打开的文件队列和其他内核资源。
2. 区别:
- 一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。线程依赖于进程而存在。
- 进程在执行过程中拥有独立的内存单元,而多个线程共享进程的内存。(资源分配给进程,同一进程的所有线程共享该进程的所有资源。同一进程中的多个线程共享代码段(代码和常量),数据段(全局变量和静态变量),扩展段(堆存储)。但是每个线程拥有自己的栈段,栈段又叫运行时段,用来存放所有局部变量和临时变量。)
- 进程是资源分配的最小单位,线程是CPU调度的最小单位;
- 系统开销: 由于在创建或撤消进程时,系统都要为之分配或回收资源,如内存空间、I/o设备等。因此,操作系统所付出的开销将显着地大于在创建或撤消线程时的开销。类似地,在进行进程切换时,涉及到整个当前进程CPU环境的保存以及新被调度运行的进程的CPU环境的设置。而线程切换只须保存和设置少量寄存器的内容,并不涉及存储器管理方面的操作。可见,进程切换的开销也远大于线程切换的开销。
- 通信:由于同一进程中的多个线程具有相同的地址空间,致使它们之间的同步和通信的实现,也变得比较容易。进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。在有的系统中,线程的切换、同步和通信都无须操作系统内核的干预
- 进程编程调试简单可靠性高,但是创建销毁开销大;线程正相反,开销小,切换速度快,但是编程调试相对复杂。
- 进程间不会相互影响 ;线程一个线程挂掉将导致整个进程挂掉
- 进程适应于多核、多机分布;线程适用于多核
进程与线程的一个简单解释:
计算机的核心是CPU,它承担了所有的计算任务。它就像一座工厂,时刻在运行。假定工厂的电力有限,一次只能供给一个车间使用。也就是说,一个车间开工的时候,其他车间都必须停工。背后的含义就是,单个CPU一次只能运行一个任务。进程就好比工厂的车间,它代表CPU所能处理的单个任务。任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。
一个车间里,可以有很多工人。他们协同完成一个任务。线程就好比车间里的工人。一个进程可以包括多个线程。
车间的空间是工人们共享的,比如许多房间是每个工人都可以进出的。这象征一个进程的内存空间是共享的,每个线程都可以使用这些共享内存。可是,每间房间的大小不同,有些房间最多只能容纳一个人,比如厕所。里面有人的时候,其他人就不能进去了。这代表一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。
一个防止他人进入的简单方法,就是门口加一把锁。先到的人锁上门,后到的人看到上锁,就在门口排队,等锁打开再进去。这就叫“互斥锁”(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域。
还有些房间,可以同时容纳n个人,比如厨房。也就是说,如果人数大于n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用。
这时的解决方法,就是在门口挂n把钥匙。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,就知道必须在门口排队等着了。这种做法叫做“信号量”(Semaphore),用来保证多个线程不会互相冲突。
不难看出,mutex是semaphore的一种特殊情况(n=1时)。也就是说,完全可以用后者替代前者。但是,因为mutex较为简单,且效率高,所以在必须保证资源独占的情况下,还是采用这种设计。
操作系统的设计,因此可以归结为三点:
(1)以多进程形式,允许多个任务同时运行;
(2)以多线程形式,允许单个任务分成不同的部分运行;
(3)提供协调机制,一方面防止进程之间和线程之间产生冲突,另一方面允许进程之间和线程之间共享资源。
Python中的进程和线程:
python中的的multiprocess和threading模块用于进行多线程和多进程编程。
Python的多进程编程与multiprocess模块
python的多进程编程主要依靠multiprocess模块。我们先对比两段代码,看看多进程编程的优势。我们模拟了一个非常耗时的任务,计算8的20次方,为了使这个任务显得更耗时,我们还让它sleep 2秒。第一段代码是单进程计算(代码如下所示),我们按顺序执行代码,重复计算2次,并打印出总共耗时。
import time
import os
def long_time_task():
print('当前进程: {}'.format(os.getpid()))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__ == "__main__":
print('当前母进程: {}'.format(os.getpid()))
start = time.time()
for i in range(2):
long_time_task()
end = time.time()
print("用时{}秒".format((end-start)))
输出结果如下,总共耗时4秒,至始至终只有一个进程14236。看来电脑计算8的20次方基本不费时。
当前母进程: 14236
当前进程: 14236
结果: 1152921504606846976
当前进程: 14236
结果: 1152921504606846976
用时4.01080060005188秒
第2段代码是多进程计算代码。我们利用multiprocess模块的Process方法创建了两个新的进程p1和p2来进行并行计算。Process方法接收两个参数, 第一个是target,一般指向函数名,第二个时args,需要向函数传递的参数。对于创建的新进程,调用start()方法即可让其开始。我们可以使用os.getpid()打印出当前进程的名字。
from multiprocessing import Process
import os
import time
def long_time_task(i):
print('子进程: {} - 任务{}'.format(os.getpid(), i))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
print('当前母进程: {}'.format(os.getpid()))
start = time.time()
p1 = Process(target=long_time_task, args=(1,))
p2 = Process(target=long_time_task, args=(2,))
print('等待所有子进程完成。')
p1.start()
p2.start()
p1.join()
p2.join()
end = time.time()
print("总共用时{}秒".format((end - start)))
输出结果如下所示,耗时变为2秒,时间减了一半,可见并发执行的时间明显比顺序执行要快很多。你还可以看到尽管我们只创建了两个进程,可实际运行中却包含里1个母进程和2个子进程。之所以我们使用join()方法就是为了让母进程阻塞,等待子进程都完成后才打印出总共耗时,否则输出时间只是母进程执行的时间。
当前母进程: 6920
等待所有子进程完成。
子进程: 17020 - 任务1
子进程: 5904 - 任务2
结果: 1152921504606846976
结果: 1152921504606846976
总共用时2.131091356277466秒
知识点:
- 新创建的进程与进程的切换都是要耗资源的,所以平时工作中进程数不能开太大。
- 同时可以运行的进程数一般受制于CPU的核数。
- 除了使用Process方法,我们还可以使用Pool类创建多进程。
利用multiprocess模块的Pool类创建多进程
很多时候系统都需要创建多个进程以提高CPU的利用率,当数量较少时,可以手动生成一个个Process实例。当进程数量很多时,或许可以利用循环,但是这需要程序员手动管理系统中并发进程的数量,有时会很麻烦。这时进程池Pool就可以发挥其功效了。可以通过传递参数限制并发进程的数量,默认值为CPU的核数。
Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果进程池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
下面介绍一下multiprocessing 模块下的Pool类的几个方法:
1.apply_async
函数原型:apply_async(func[, args=()[, kwds={}[, callback=None]]])
其作用是向进程池提交需要执行的函数及参数, 各个进程采用非阻塞(异步)的调用方式,即每个子进程只管运行自己的,不管其它进程是否已经完成。这是默认方式。
2.map()
函数原型:map(func, iterable[, chunksize=None])
Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到结果返回。 注意:虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程。
3.map_async()
函数原型:map_async(func, iterable[, chunksize[, callback]])
与map用法一致,但是它是非阻塞的。其有关事项见apply_async。
4.close()
关闭进程池(pool),使其不在接受新的任务。
5. terminate()
结束工作进程,不在处理未处理的任务。
6.join()
主进程阻塞等待子进程的退出, join方法要在close或terminate之后使用。
下例是一个简单的multiprocessing.Pool类的实例。因为小编我的CPU是4核的,一次最多可以同时运行4个进程,所以我开启了一个容量为4的进程池。4个进程需要计算5次,你可以想象4个进程并行4次计算任务后,还剩一次计算任务(任务4)没有完成,系统会等待4个进程完成后重新安排一个进程来计算。
from multiprocessing import Pool, cpu_count
import os
import time
def long_time_task(i):
print('子进程: {} - 任务{}'.format(os.getpid(), i))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
print("CPU内核数:{}".format(cpu_count()))
print('当前母进程: {}'.format(os.getpid()))
start = time.time()
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('等待所有子进程完成。')
p.close()
p.join()
end = time.time()
print("总共用时{}秒".format((end - start)))
知识点:
- 对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close()或terminate()方法,让其不再接受新的Process了。
输出结果如下所示,5个任务(每个任务大约耗时2秒)使用多进程并行计算只需4.37秒,, 耗时减少了60%,可见并行计算优势还是很明显的。
CPU内核数:4
当前母进程: 2556
等待所有子进程完成。
子进程: 16480 - 任务0
子进程: 15216 - 任务1
子进程: 15764 - 任务2
子进程: 10176 - 任务3
结果: 1152921504606846976
结果: 1152921504606846976
子进程: 15216 - 任务4
结果: 1152921504606846976
结果: 1152921504606846976
结果: 1152921504606846976
总共用时4.377134561538696秒
相信大家都知道python解释器中存在GIL(全局解释器锁), 它的作用就是保证同一时刻只有一个线程可以执行代码。由于GIL的存在,很多人认为python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程。然而这并意味着python多线程编程没有意义哦,请继续阅读下文。
多进程间的数据共享与通信
通常,进程之间是相互独立的,每个进程都有独立的内存。通过共享内存(nmap模块),进程之间可以共享对象,使多个进程可以访问同一个变量(地址相同,变量名可能不同)。多进程共享资源必然会导致进程间相互竞争,所以应该尽最大可能防止使用共享状态。还有一种方式就是使用队列queue来实现不同进程间的通信或数据共享,这一点和多线程编程类似。
下例这段代码中中创建了2个独立进程,一个负责写(pw), 一个负责读(pr), 实现了共享一个队列queue。
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: {}'.format(os.getpid()))
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read:{}'.format(os.getpid()))
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
输出结果如下所示:
Process to write: 3036
Put A to queue...
Process to read:9408
Get A from queue.
Put B to queue...
Get B from queue.
Put C to queue...
Get C from queue.
python中的多线程(伪多线程):
我们知道 Python 之所以灵活和强大,是因为它是一个解释性语言,边解释边执行,实现这种特性的标准实现叫作 CPython。
它分两步来运行 Python 程序:
- 首先解析源代码文本,并将其编译为字节码(bytecode)[1]
- 然后采用基于栈的解释器来运行字节码
- 不断循环这个过程,直到程序结束或者被终止
灵活性有了,但是为了保证程序执行的稳定性,也付出了巨大的代价:
引入了 全局解释器锁 GIL(global interpreter lock)[2]
以保证同一时间只有一个字节码在运行,这样就不会因为没用事先编译,而引发资源争夺和状态混乱的问题了。
看似 “十全十美” ,但,这样做,就意味着多线程执行时,会被 GIL 变为单线程,无法充分利用硬件资源。
戴着镣铐跳舞
难道 Python 里的多线程真的没用吗?
其实也并不是,虽然了因为 GIL,无法实现真正意义上的多线程,但,多线程机制,还是为我们提供了两个重要的特性。
一:多线程写法可以让某些程序更好写
怎么理解呢?
如果要解决一个需要同时维护多种状态的程序,用单线程是实现是很困难的。
比如要检索一个文本文件中的数据,为了提高检索效率,可以将文件分成小段的来处理,最先在那段中找到了,就结束处理过程。
用单线程的话,很难实现同时兼顾多个分段的情况,只能顺序,或者用二分法执行检索任务。
而采用多线程,可以将每个分段交给每个线程,会轮流执行,相当于同时推荐检索任务,处理起来,效率会比顺序查找大大提高。
二:处理阻塞型 I/O 任务效率更高
阻塞型 I/O 的意思是,当系统需要与文件系统(也包括网络和终端显示)交互时,由于文件系统相比于 CPU 的处理速度慢得多,所以程序会被设置为阻塞状态,即,不再被分配计算资源。
直到文件系统的结果返回,才会被激活,将有机会再次被分配计算资源。
也就是说,处于阻塞状态的程序,会一直等着。
那么如果一个程序是需要不断地从文件系统读取数据,处理后在写入,单线程的话就需要等等读取后,才能处理,等待处理完才能写入,于是处理过程就成了一个个的等待。
而用多线程,当一个处理过程被阻塞之后,就会立即被 GIL 切走,将计算资源分配给其他可以执行的过程,从而提示执行效率。
有了这两个特性,就说明 Python 的多线程并非一无是处,如果能根据情况编写好,效率会大大提高,只不过对于计算密集型的任务,多线程特性爱莫能助。
自强不息
了解到 Python 多线程的问题和解决方案,对于钟爱 Python 的我们,何去何从呢?
有句话用在这里很合适:
求人不如求己
哪怕再怎么厉害的工具或者武器,都无法解决所有的问题,而问题之所以能被解决,主要是因为我们的主观能动性。
对情况进行分析判断,选择合适的解决方案,不就是需要我们做的么?
对于 Python 中 多线程的诟病,我们更多的是看到它阳光和美的一面,而对于需要提升速度的地方,采取合适的方式。这里简单总结一下:
- I/O 密集型的任务,采用 Python 的多线程完全没用问题,可以大幅度提高执行效率
- 对于计算密集型任务,要看数据依赖性是否低,如果低,采用 ProcessPoolExecutor 代替多线程处理,可以充分利用硬件资源
- 如果数据依赖性高,可以考虑将关键的地方该用 C 来实现,一方面 C 本身比 Python 更快,另一方面,C 可以之间使用更底层的多线程机制,而完全不用担心受 GIL 的影响
- 大部分情况下,对于只能用多线程处理的任务,不用太多考虑,之间利用 Python 的多线程机制就好了,不用考虑太多
Python的多线程编程与threading模块
python 3中的多进程编程主要依靠threading模块。创建新线程与创建新进程的方法非常类似。threading.Thread方法可以接收两个参数, 第一个是target,一般指向函数名,第二个时args,需要向函数传递的参数。对于创建的新线程,调用start()方法即可让其开始。我们还可以使用current_thread().name打印出当前线程的名字。 下例中我们使用多线程技术重构之前的计算代码。
import threading
import time
def long_time_task(i):
print('当前子线程: {} - 任务{}'.format(threading.current_thread().name, i))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
start = time.time()
print('这是主线程:{}'.format(threading.current_thread().name))
t1 = threading.Thread(target=long_time_task, args=(1,))
t2 = threading.Thread(target=long_time_task, args=(2,))
t1.start()
t2.start()
end = time.time()
print("总共用时{}秒".format((end - start)))
下面是输出结果。为什么总耗时居然是0秒? 我们可以明显看到主线程和子线程其实是独立运行的,主线程根本没有等子线程完成,而是自己结束后就打印了消耗时间。主线程结束后,子线程仍在独立运行,这显然不是我们想要的。
这是主线程:MainThread
当前子线程: Thread-1 - 任务1
当前子线程: Thread-2 - 任务2
总共用时0.0017192363739013672秒
结果: 1152921504606846976
结果: 1152921504606846976
如果要实现主线程和子线程的同步,我们必需使用join方法(代码如下所示)。
import threading
import time
def long_time_task(i):
print('当前子线程: {} 任务{}'.format(threading.current_thread().name, i))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
start = time.time()
print('这是主线程:{}'.format(threading.current_thread().name))
thread_list = []
for i in range(1, 3):
t = threading.Thread(target=long_time_task, args=(i, ))
thread_list.append(t)
for t in thread_list:
t.start()
for t in thread_list:
t.join()
end = time.time()
print("总共用时{}秒".format((end - start)))
修改代码后的输出如下所示。这时你可以看到主线程在等子线程完成后才答应出总消耗时间(2秒),比正常顺序执行代码(4秒)还是节省了不少时间。
这是主线程:MainThread
当前子线程: Thread - 1 任务1
当前子线程: Thread - 2 任务2
结果: 1152921504606846976
结果: 1152921504606846976
总共用时2.0166890621185303秒
当我们设置多线程时,主线程会创建多个子线程,在python中,默认情况下主线程和子线程独立运行互不干涉。如果希望让主线程等待子线程实现线程的同步,我们需要使用join()方法。如果我们希望一个主线程结束时不再执行子线程,我们应该怎么办呢? 我们可以使用t.setDaemon(True),代码如下所示。
import threading
import time
def long_time_task():
print('当子线程: {}'.format(threading.current_thread().name))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
start = time.time()
print('这是主线程:{}'.format(threading.current_thread().name))
for i in range(5):
t = threading.Thread(target=long_time_task, args=())
t.setDaemon(True)
t.start()
end = time.time()
print("总共用时{}秒".format((end - start)))
通过继承Thread类重写run方法创建新进程
除了使用Thread()方法创建新的线程外,我们还可以通过继承Thread类重写run方法创建新的线程,这种方法更灵活。下例中我们自定义的类为MyThread, 随后我们通过该类的实例化创建了2个子线程。
#-*- encoding:utf-8 -*-
import threading
import time
def long_time_task(i):
time.sleep(2)
return 8**20
class MyThread(threading.Thread):
def __init__(self, func, args , name='', ):
threading.Thread.__init__(self)
self.func = func
self.args = args
self.name = name
self.result = None
def run(self):
print('开始子进程{}'.format(self.name))
self.result = self.func(self.args[0],)
print("结果: {}".format(self.result))
print('结束子进程{}'.format(self.name))
if __name__=='__main__':
start = time.time()
threads = []
for i in range(1, 3):
t = MyThread(long_time_task, (i,), str(i))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
end = time.time()
print("总共用时{}秒".format((end - start)))
输出结果如下所示:
开始子进程1
开始子进程2
结果: 1152921504606846976
结果: 1152921504606846976
结束子进程1
结束子进程2
总共用时2.005445718765259秒
不同线程间的数据共享
一个进程所含的不同线程间共享内存,这就意味着任何一个变量都可以被任何一个线程修改,因此线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。如果不同线程间有共享的变量,其中一个方法就是在修改前给其上一把锁lock,确保一次只有一个线程能修改它。threading.lock()方法可以轻易实现对一个共享变量的锁定,修改完后release供其它线程使用。比如下例中账户余额balance是一个共享变量,使用lock可以使其不被改乱。
# -*- coding: utf-8 -*
import threading
class Account:
def __init__(self):
self.balance = 0
def add(self, lock):
# 获得锁
lock.acquire()
for i in range(0, 100000):
self.balance += 1
# 释放锁
lock.release()
def delete(self, lock):
# 获得锁
lock.acquire()
for i in range(0, 100000):
self.balance -= 1
# 释放锁
lock.release()
if __name__ == "__main__":
account = Account()
lock = threading.Lock()
# 创建线程
thread_add = threading.Thread(target=account.add, args=(lock,), name='Add')
thread_delete = threading.Thread(target=account.delete, args=(lock,), name='Delete')
# 启动线程
thread_add.start()
thread_delete.start()
# 等待线程结束
thread_add.join()
thread_delete.join()
print('The final balance is: {}'.format(account.balance))
另一种实现不同线程间数据共享的方法就是使用消息队列queue。不像列表,queue是线程安全的,可以放心使用,见下文。
使用queue队列通信-经典的生产者和消费者模型
下例中创建了两个线程,一个负责生成,一个负责消费,所生成的产品存放在queue里,实现了不同线程间沟通。
from queue import Queue
import random, threading, time
# 生产者类
class Producer(threading.Thread):
def __init__(self, name, queue):
threading.Thread.__init__(self, name=name)
self.queue = queue
def run(self):
for i in range(1, 5):
print("{} is producing {} to the queue!".format(self.getName(), i))
self.queue.put(i)
time.sleep(random.randrange(10) / 5)
print("%s finished!" % self.getName())
# 消费者类
class Consumer(threading.Thread):
def __init__(self, name, queue):
threading.Thread.__init__(self, name=name)
self.queue = queue
def run(self):
for i in range(1, 5):
val = self.queue.get()
print("{} is consuming {} in the queue.".format(self.getName(), val))
time.sleep(random.randrange(10))
print("%s finished!" % self.getName())
def main():
queue = Queue()
producer = Producer('Producer', queue)
consumer = Consumer('Consumer', queue)
producer.start()
consumer.start()
producer.join()
consumer.join()
print('All threads finished!')
if __name__ == '__main__':
main()
队列queue的put方法可以将一个对象obj放入队列中。如果队列已满,此方法将阻塞至队列有空间可用为止。queue的get方法一次返回队列中的一个成员。如果队列为空,此方法将阻塞至队列中有成员可用为止。queue同时还自带emtpy(), full()等方法来判断一个队列是否为空或已满,但是这些方法并不可靠,因为多线程和多进程,在返回结果和使用结果之间,队列中可能添加/删除了成员。
Python多进程和多线程哪个快?
由于GIL的存在,很多人认为Python多进程编程更快,针对多核CPU,理论上来说也是采用多进程更能有效利用资源。网上很多人已做过比较,我直接告诉你结论吧。
- 对CPU密集型代码(比如循环计算) – 多进程效率更高
- 对IO密集型代码(比如文件操作,网络爬虫) – 多线程效率更高。
为什么是这样呢?其实也不难理解。对于IO密集型操作,大部分消耗时间其实是等待时间,在等待时间中CPU是不需要工作的,那你在此期间提供双CPU资源也是利用不上的,相反对于CPU密集型代码,2个CPU干活肯定比一个CPU快很多。那么为什么多线程会对IO密集型代码有用呢?这时因为python碰到等待会释放GIL供新的线程使用,实现了线程间的切换。