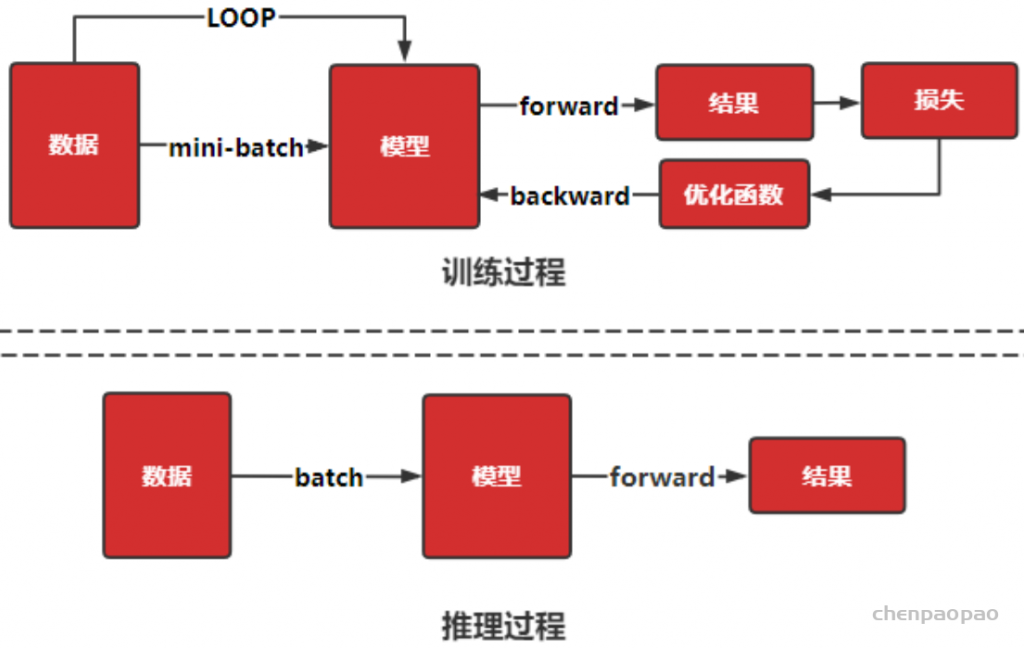
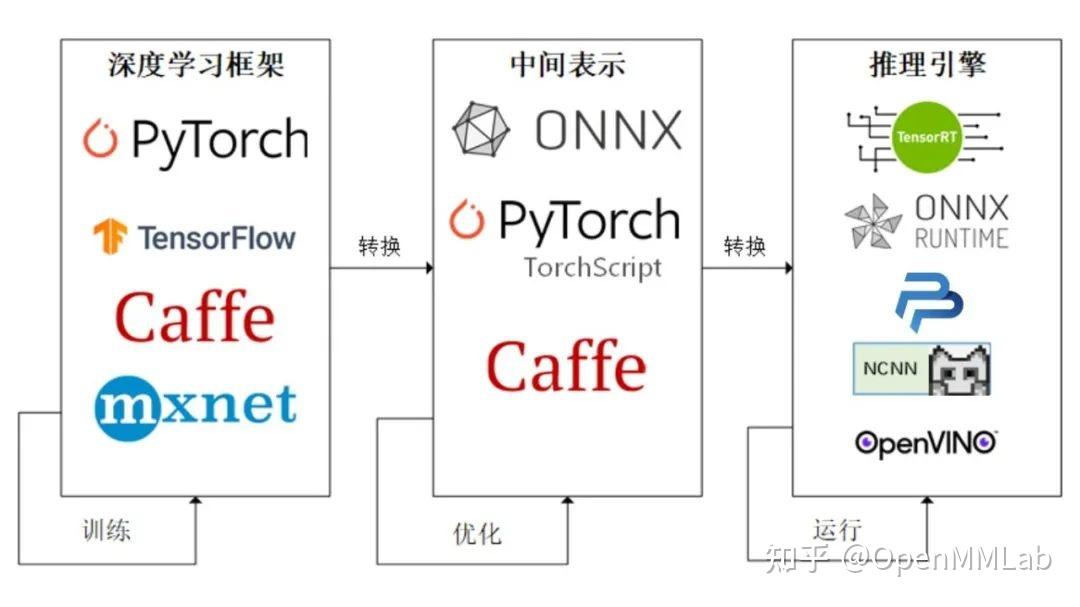
学习了 PyTorch 转 ONNX 的方法,可以发现 PyTorch 对 ONNX 的支持还不错。但在实际的部署过程中,难免碰到模型无法用原生 PyTorch 算子表示的情况。这个时候,我们就得考虑扩充 PyTorch,即在 PyTorch 中支持更多 ONNX 算子。
而要使 PyTorch 算子顺利转换到 ONNX ,我们需要保证以下三个环节都不出错:
- 算子在 PyTorch 中有实现
- 有把该 PyTorch 算子映射成一个或多个 ONNX 算子的方法
- ONNX 有相应的算子
可在实际部署中,这三部分的内容都可能有所缺失。其中最坏的情况是:我们定义了一个全新的算子,它不仅缺少 PyTorch 实现,还缺少 PyTorch 到 ONNX 的映射关系。但所谓车到山前必有路,对于这三个环节,我们也分别都有以下的添加支持的方法:
- PyTorch 算子
- 组合现有算子
- 添加 TorchScript 算子
- 添加普通 C++ 拓展算子
- 映射方法
- 为 ATen 算子添加符号函数
- 为 TorchScript 算子添加符号函数
- 封装成
torch.autograd.Function并添加符号函数
- ONNX 算子
- 使用现有 ONNX 算子
- 定义新 ONNX 算子
那么面对不同的情况时,就需要我们灵活地选用和组合这些方法。听起来是不是很复杂?别担心,本篇文章中,我们将围绕着三种算子映射方法,学习三个添加算子支持的实例,来理清如何合适地为 PyTorch 算子转 ONNX 算子的三个环节添加支持。
支持 ATen 算子
实际的部署过程中,我们都有可能会碰到一个最简单的算子缺失问题: 算子在 ATen 中已经实现了,ONNX 中也有相关算子的定义,但是相关算子映射成 ONNX 的规则没有写。在这种情况下,我们只需要为 ATen 算子补充描述映射规则的符号函数就行了。
ATen 是 PyTorch 内置的 C++ 张量计算库,PyTorch 算子在底层绝大多数计算都是用 ATen 实现的。
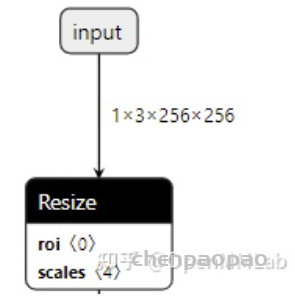
上期习题中,我们曾经提到了 ONNX 的 Asinh 算子。这个算子在 ATen 中有实现,却缺少了映射到 ONNX 算子的符号函数。在这里,我们来尝试为它补充符号函数,并导出一个包含这个算子的 ONNX 模型。
获取 ATen 中算子接口定义
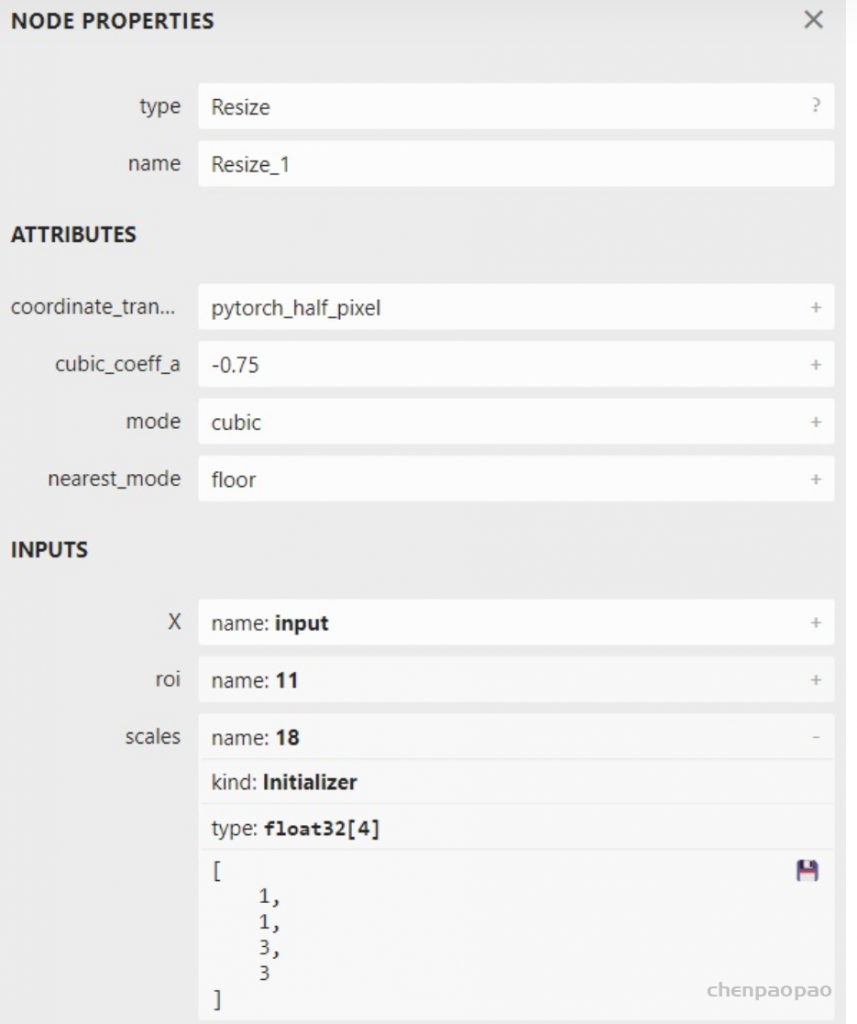
为了编写符号函数,我们需要获得 asinh 推理接口的输入参数定义。这时,我们要去 torch/_C/_VariableFunctions.pyi 和 torch/nn/functional.pyi 这两个文件中搜索我们刚刚得到的这个算子名。这两个文件是编译 PyTorch 时本地自动生成的文件,里面包含了 ATen 算子的 PyTorch 调用接口。通过搜索,我们可以知道 asinh 在文件 torch/_C/_VariableFunctions.pyi 中,其接口定义为:
def asinh(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ... 经过这些步骤,我们确认了缺失的算子名为 asinh,它是一个有实现的 ATen 算子。我们还记下了 asinh 的调用接口。接下来,我们要为它补充符号函数,使它在转换成 ONNX 模型时不再报错。
添加符号函数
到目前为止,我们已经多次接触了定义 PyTorch 到 ONNX 映射规则的符号函数了。现在,我们向大家正式介绍一下符号函数。
符号函数,可以看成是 PyTorch 算子类的一个静态方法。在把 PyTorch 模型转换成 ONNX 模型时,各个 PyTorch 算子的符号函数会被依次调用,以完成 PyTorch 算子到 ONNX 算子的转换。符号函数的定义一般如下:
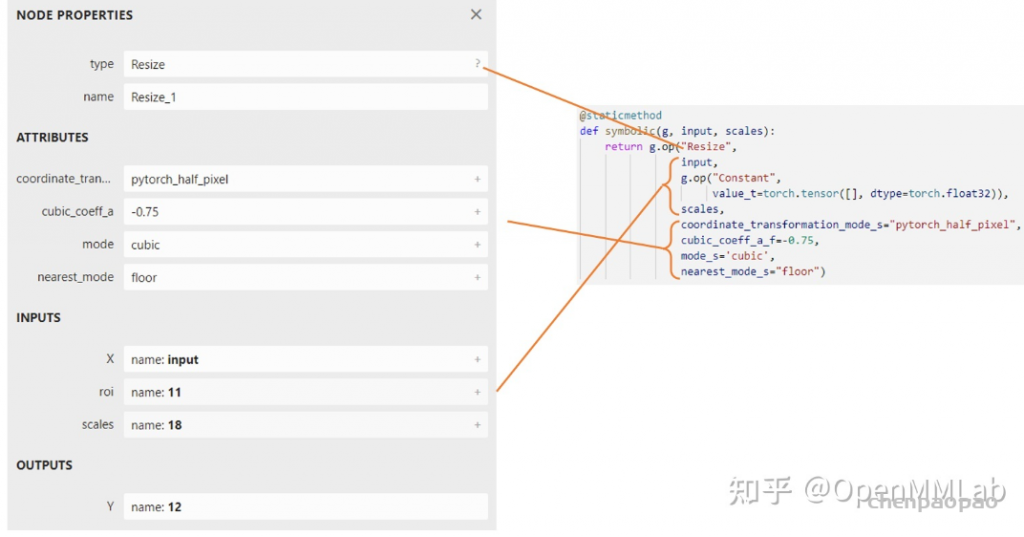
def symbolic(g: torch._C.Graph, input_0: torch._C.Value, input_1: torch._C.Value, ...): 其中,torch._C.Graph 和 torch._C.Value 都对应 PyTorch 的 C++ 实现里的一些类。我们在这篇文章不深究它们的细节(感兴趣的话可以参考我们的 TorchScript 系列文章中对 trace 机制的解读),只需要知道第一个参数就固定叫 g,它表示和计算图相关的内容;后面的每个参数都表示算子的输入,需要和算子的前向推理接口的输入相同。对于 ATen 算子来说,它们的前向推理接口就是上述两个 .pyi 文件里的函数接口。
g 有一个方法 op。在把 PyTorch 算子转换成 ONNX 算子时,需要在符号函数中调用此方法来为最终的计算图添加一个 ONNX 算子。其定义如下:
def op(name: str, input_0: torch._C.Value, input_1: torch._C.Value, ...) 其中,第一个参数是算子名称。如果该算子是普通的 ONNX 算子,只需要把它在 ONNX 官方文档里的名称填进去即可(我们稍后再讲其他情况)。
在最简单的情况下,我们只要把 PyTorch 算子的输入用g.op()一一对应到 ONNX 算子上即可,并把g.op()的返回值作为符号函数的返回值。在情况更复杂时,我们转换一个 PyTorch 算子可能要新建若干个 ONNX 算子。
补充完了背景知识,让我们回到 asinh 算子上,来为它编写符号函数。我们先去翻阅一下 ONNX 算子文档,学习一下我们在符号函数里的映射关系 g.op() 里应该怎么写。Asinh 的文档写道:该算子有一个输入 input,一个输出 output,二者的类型都为张量。
到这里,我们已经完成了信息收集环节。我们在上一小节得知了 asinh 的推理接口定义,在这一小节里收集了 ONNX 算子 Asinh 的定义。现在,我们可以用代码来补充这二者的映射关系了。在刚刚导出 asinh 算子的代码中,我们添加以下内容:
from torch.onnx.symbolic_registry import register_op
def asinh_symbolic(g, input, *, out=None):
return g.op("Asinh", input)
register_op('asinh', asinh_symbolic, '', 9) 这里的asinh_symbolic就是asinh的符号函数。从除g以外的第二个输入参数开始,其输入参数应该严格对应它在 ATen 中的定义:
def asinh(input: Tensor, *, out: Optional[Tensor]=None) -> Tensor: ... 在符号函数的函数体中,g.op("Asinh", input)则完成了 ONNX 算子的定义。其中,第一个参数"Asinh"是算子在 ONNX 中的名称。至于第二个参数 input,如我们刚刚在文档里所见,这个算子只有一个输入,因此我们只要把符号函数的输入参数 input 对应过去就行。ONNX 的 Asinh 的输出和 ATen 的 asinh 的输出是一致的,因此我们直接把 g.op() 的结果返回即可。
定义完符号函数后,我们要把这个符号函数和原来的 ATen 算子“绑定”起来。这里,我们要用到 register_op 这个 PyTorch API 来完成绑定。如示例所示,只需要一行简单的代码即可把符号函数 asinh_symbolic 绑定到算子 asinh 上:
register_op('asinh', asinh_symbolic, '', 9) register_op的第一个参数是目标 ATen 算子名,第二个是要注册的符号函数,这两个参数很好理解。第三个参数是算子的“域”,对于普通 ONNX 算子,直接填空字符串即可。第四个参数表示向哪个算子集版本注册。我们遵照 ONNX 标准,向第 9 号算子集注册。值得注意的是,这里向第 9 号算子集注册,不代表较新的算子集(第 10 号、第 11 号……)都得到了注册。在示例中,我们先只向第 9 号算子集注册。
整理一下,我们最终的代码如下:
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return torch.asinh(x)
from torch.onnx.symbolic_registry import register_op
def asinh_symbolic(g, input, *, out=None):
return g.op("Asinh", input)
register_op('asinh', asinh_symbolic, '', 9)
model = Model()
input = torch.rand(1, 3, 10, 10)
torch.onnx.export(model, input, 'asinh.onnx')
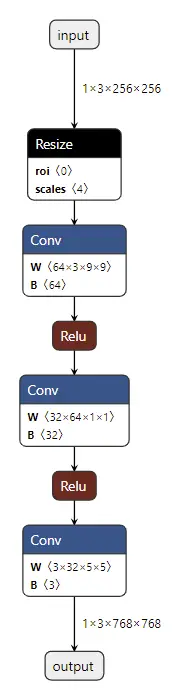
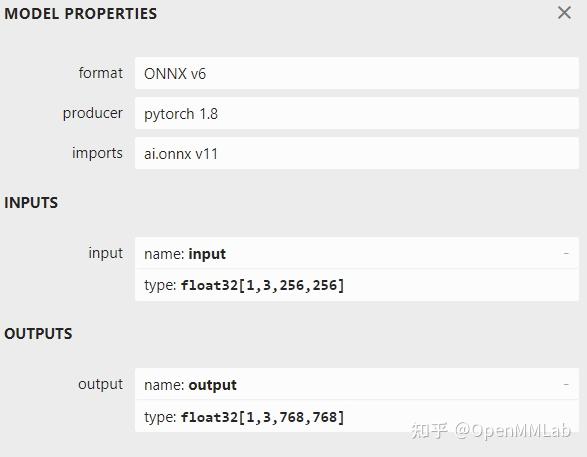
成功导出的话,asinh.onnx 应该长这个样子:
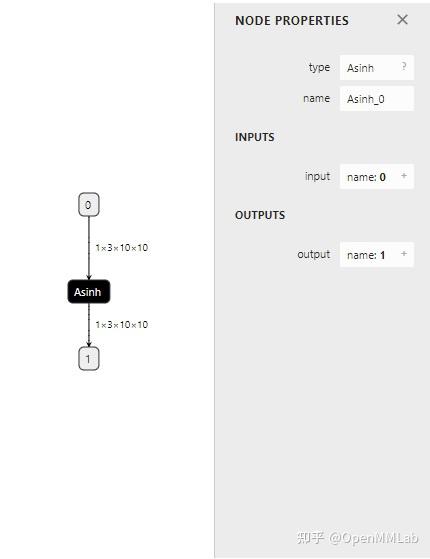
测试算子
在完成了一份自定义算子后,我们一定要测试一下算子的正确性。一般我们要用 PyTorch 运行一遍原算子,再用推理引擎(比如 ONNX Runtime)运行一下 ONNX 算子,最后比对两次的运行结果。对于我们刚刚得到的 asinh.onnx,可以用如下代码来验证:
import onnxruntime
import torch
import numpy as np
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return torch.asinh(x)
model = Model()
input = torch.rand(1, 3, 10, 10)
torch_output = model(input).detach().numpy()
sess = onnxruntime.InferenceSession('asinh.onnx')
ort_output = sess.run(None, {'0': input.numpy()})[0]
assert np.allclose(torch_output, ort_output) 在这份代码里,我们用 PyTorch 做了一遍推理,并把结果转成了 numpy 格式。之后,我们又用 ONNX Runtime 对 onnx 文件做了一次推理。
忘了 ONNX Runtime 的调用方法的话,欢迎回顾第一篇教程~
最后,我们使用 np.allclose 来保证两个结果张量的误差在一个可以允许的范围内。一切正常的话,运行这段代码后,assert 所在行不会报错,程序应该没有任何输出。
支持 TorchScript 算子
对于一些比较复杂的运算,仅使用 PyTorch 原生算子是无法实现的。这个时候,就要考虑自定义一个 PyTorch 算子,再把它转换到 ONNX 中了。新增 PyTorch 算子的方法有很多,PyTorch 官方比较推荐的一种做法是添加 TorchScript 算子 。
由于添加算子的方法较繁琐,我们今天跳过新增 TorchScript 算子的内容,以可变形卷积(Deformable Convolution)算子为例,介绍为现有 TorchScript 算子添加 ONNX 支持的方法。
可变形卷积(Deformable Convolution)是在 Torchvision 中实现的 TorchScript 算子,虽然尚未得到广泛支持,但是出现在许多模型中。
有了支持 ATen 算子的经验之后,我们可以知道为算子添加符号函数一般要经过以下几步:
- 获取原算子的前向推理接口。
- 获取目标 ONNX 算子的定义。
- 编写符号函数并绑定。
在为可变形卷积添加符号函数时,我们也可以尝试走一遍这个流程。
使用 TorchScript 算子
和之前一样,我们首先定义一个包含了算子的模型,为之后转换 ONNX 模型做准备。
import torch
import torchvision
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = torch.nn.Conv2d(3, 18, 3)
self.conv2 = torchvision.ops.DeformConv2d(3, 3, 3)
def forward(self, x):
return self.conv2(x, self.conv1(x)) 其中,torchvision.ops.DeformConv2d 就是 Torchvision 中的可变形卷积层。相比于普通卷积,可变形卷积的其他参数都大致相同,唯一的区别就是在推理时需要多输入一个表示偏移量的张量。
然后,我们查询算子的前向推理接口。DeformConv2d 层最终会调用 deform_conv2d 这个算子。我们可以在 torchvision/csrc/ops/deform_conv2d.cpp 中查到该算子的调用接口:
m.def(TORCH_SELECTIVE_SCHEMA(
"torchvision::deform_conv2d(Tensor input,
Tensor weight,
Tensor offset,
......
bool use_mask) -> Tensor")); 那么接下来,根据之前的经验,我们就是要去 ONNX 官方文档中查找算子的定义了。
自定义 ONNX 算子
很遗憾的是,如果我们去 ONNX 的官方算子页面搜索 “deform”,将搜不出任何内容。目前,ONNX 还没有提供可变形卷积的算子,我们要自己定义一个 ONNX 算子了。
我们在前面讲过,g.op() 是用来定义 ONNX 算子的函数。对于 ONNX 官方定义的算子,g.op() 的第一个参数就是该算子的名称。而对于一个自定义算子,g.op() 的第一个参数是一个带命名空间的算子名,比如:
g.op("custom::deform_conv2d, ...) 其中,”::”前面的内容就是我们的命名空间。该概念和 C++ 的命名空间类似,是为了防止命名冲突而设定的。如果在 g.op() 里不加前面的命名空间,则算子会被默认成 ONNX 的官方算子。
PyTorch 在运行 g.op() 时会对官方的算子做检查,如果算子名有误,或者算子的输入类型不正确, g.op() 就会报错。为了让我们随心所欲地定义新 ONNX 算子,我们必须设定一个命名空间,给算子取个名,再定义自己的算子。
我们在第一篇教程讲过:ONNX 是一套标准,本身不包括实现。在这里,我们就简略地定义一个 ONNX 可变形卷积算子,而不去写它在某个推理引擎上的实现。在后续的文章中,我们再介绍在各个推理引擎中添加新 ONNX 算子支持的方法。此处,我们只关心如何导出一个包含新 ONNX 算子节点的 onnx 文件。因此,我们可以为新算子编写如下简单的符号函数:
@parse_args("v", "v", "v", "v", "v", "i", "i", "i", "i", "i", "i", "i", "i", "none")
def symbolic(g,
input,
weight,
offset,
mask,
bias,
stride_h, stride_w,
pad_h, pad_w,
dil_h, dil_w,
n_weight_grps,
n_offset_grps,
use_mask):
return g.op("custom::deform_conv2d", input, offset)
在这个符号函数中,我们以刚刚搜索到的算子输入参数作为符号函数的输入参数,并只用 input 和 offset 来构造一个简单的 ONNX 算子。
这段代码中,最令人疑惑的就是装饰器 @parse_args 了。简单来说,TorchScript 算子的符号函数要求标注出每一个输入参数的类型。比如”v”表示 Torch 库里的 value 类型,一般用于标注张量,而”i”表示 int 类型,”f”表示 float 类型,”none”表示该参数为空。具体的类型含义可以在 torch.onnx.symbolic_helper.py (https://github.com/pytorch/pytorch/blob/master/torch/onnx/symbolic_helper.py)中查看。这里输入参数中的 input, weight, offset, mask, bias 都是张量,所以用”v”表示。后面的其他参数同理。我们不必纠结于 @parse_args 的原理,根据实际情况对符号函数的参数标注类型即可。
有了符号函数后,我们通过如下的方式注册符号函数:
register_custom_op_symbolic("torchvision::deform_conv2d", symbolic, 9) 和前面的 register_op 类似,注册符号函数时,我们要输入算子名、符号函数、算子集版本。与前面不同的是,这里的算子集版本是最早生效版本,在这里设定版本 9,意味着之后的第 10 号、第 11 号……版本集都能使用这个新算子。
最后,我们完整的模型导出代码如下:
import torch
import torchvision
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = torch.nn.Conv2d(3, 18, 3)
self.conv2 = torchvision.ops.DeformConv2d(3, 3, 3)
def forward(self, x):
return self.conv2(x, self.conv1(x))
from torch.onnx import register_custom_op_symbolic
from torch.onnx.symbolic_helper import parse_args
@parse_args("v", "v", "v", "v", "v", "i", "i", "i", "i", "i", "i", "i", "i", "none")
def symbolic(g,
input,
weight,
offset,
mask,
bias,
stride_h, stride_w,
pad_h, pad_w,
dil_h, dil_w,
n_weight_grps,
n_offset_grps,
use_mask):
return g.op("custom::deform_conv2d", input, offset)
register_custom_op_symbolic("torchvision::deform_conv2d", symbolic, 9)
model = Model()
input = torch.rand(1, 3, 10, 10)
torch.onnx.export(model, input, 'dcn.onnx')
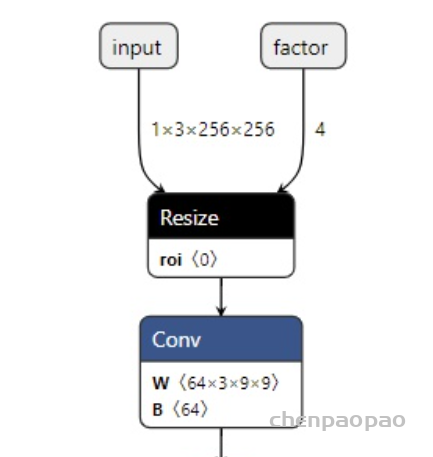
代码成功运行的话,我们应该能得到如下的 ONNX 模型:
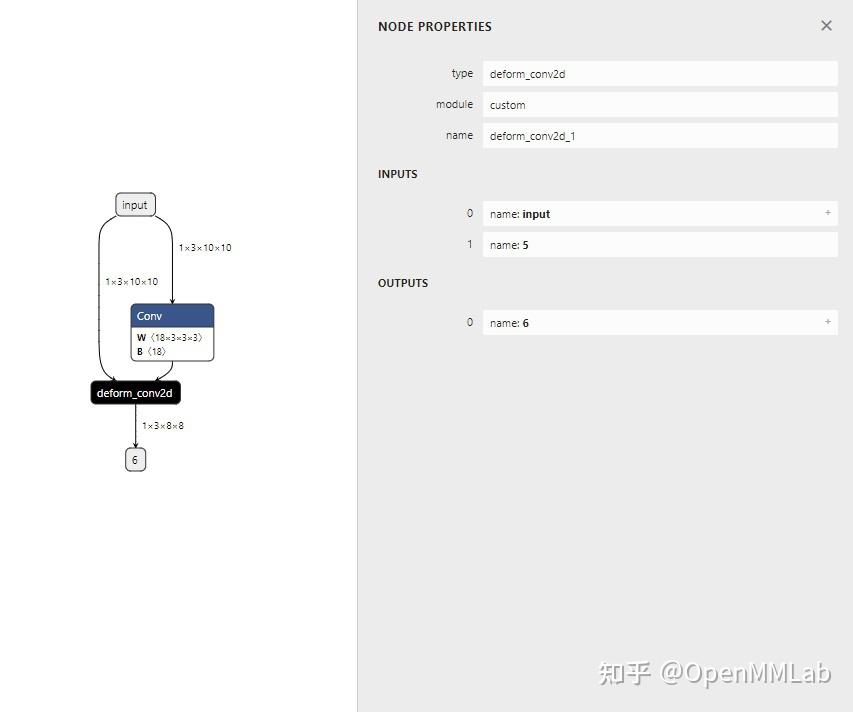
可以看到,我们自定义的 ONNX 算子 deform_conv2d 包含了两个输入,一个输出,和我们预想得一样。
使用 torch.autograd.Function
最后,我们来学习一种简单的为 PyTorch 添加 C++ 算子实现的方法,来代替较为复杂的新增 TorchScript 算子。同时,我们会用 torch.autograd.Function 封装这个新算子。torch.autograd.Function 能完成算子实现和算子调用的隔离。不管算子是怎么实现的,它封装后的使用体验以及 ONNX 导出方法会和原生的 PyTorch 算子一样。这是我们比较推荐的为算子添加 ONNX 支持的方法。
为了应对更复杂的情况,我们来自定义一个奇怪的 my_add 算子。这个算子的输入张量 a, b ,输出 2a + b 的值。我们会先把它在 PyTorch 中实现,再把它导出到 ONNX 中。
为 PyTorch 添加 C++ 拓展
为 PyTorch 添加简单的 C++ 拓展还是很方便的。对于我们定义的 my_add 算子,可以用以下的 C++ 源文件来实现。我们把该文件命名为 “my_add.cpp”:
// my_add.cpp
#include <torch/torch.h>
torch::Tensor my_add(torch::Tensor a, torch::Tensor b)
{
return 2 * a + b;
}
PYBIND11_MODULE(my_lib, m)
{
m.def("my_add", my_add);
}
由于在 PyTorch 中添加 C++ 拓展和模型部署关系不大,这里我们仅给出这个简单的示例,并不对其原理做过多讲解。
在这段代码中,torch::Tensor 就是 C++ 中 torch 的张量类型,它的加法和乘法等运算符均已重载。因此,我们可以像对普通标量一样对张量做加法和乘法。
轻松地完成了算子的实现后,我们用 PYBIND11_MODULE 来为 C++ 函数提供 Python 调用接口。这里的 my_lib 是我们未来要在 Python 里导入的模块名。双引号中的 my_add 是 Python 调用接口的名称,这里我们对齐 C++ 函数的名称,依然用 “my_add”这个名字。
之后,我们可以编写如下的 Python 代码并命名为 “setup.py”,来编译刚刚的 C++ 文件:
from setuptools import setup
from torch.utils import cpp_extension
setup(name='my_add',
ext_modules=[cpp_extension.CppExtension('my_lib', ['my_add.cpp'])],
cmdclass={'build_ext': cpp_extension.BuildExtension}) 这段代码使用了 Python 的 setuptools 编译功能和 PyTorch 的 C++ 拓展工具函数,可以编译包含了 torch 库的 C++ 源文件。这里我们需要填写的只有模块名和模块中的源文件名。我们刚刚把模块命名为 my_lib,而源文件只有一个 my_add.cpp,因此拓展模块那一行要写成 ext_modules=[cpp_extension.CppExtension('my_lib', ['my_add.cpp'])],。
之后,像处理普通的 Python 包一样执行安装命令,我们的 C++ 代码就会自动编译了。
python setup.py develop
用 torch.autograd.Function 封装
直接用 Python 接口调用 C++ 函数不太“美观”,一种比较优雅的做法是把这个调用接口封装起来。这里我们用 torch.autograd.Function 来封装算子的底层调用:
import torch
import my_lib
class MyAddFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, a, b):
return my_lib.my_add(a, b)
@staticmethod
def symbolic(g, a, b):
two = g.op("Constant", value_t=torch.tensor([2]))
a = g.op('Mul', a, two)
return g.op('Add', a, b) 我们在前面的教程中已经见过 torch.autograd.Function,这里我们正式地对其做一个介绍。Function 类本身表示 PyTorch 的一个可导函数,只要为其定义了前向推理和反向传播的实现,我们就可以把它当成一个普通 PyTorch 函数来使用。
PyTorch 会自动调度该函数,合适地执行前向和反向计算。对模型部署来说,Function 类有一个很好的性质:如果它定义了 symbolic 静态方法,该 Function 在执行 torch.onnx.export() 时就可以根据 symbolic 中定义的规则转换成 ONNX 算子。这个 symbolic 就是前面提到的符号函数,只是它的名称必须是 symbolic 而已。
在 forward 函数中,我们用 my_lib.my_add(a, b) 就可以调用之前写的C++函数了。这里 my_lib 是库名,my_add 是函数名,这两个名字是在前面C++的 PYBIND11_MODULE 中定义的。
在 symbolic 函数中,我们用 g.op() 定义了三个算子:常量、乘法、加法。这里乘法和加法的用法和前面提到的 asinh 一样,只需要根据 ONNX 算子定义规则把输入参数填入即可。而在定义常量算子时,我们要把 PyTorch 张量的值传入 value_t 参数中。
在 ONNX 中,我们需要把新建常量当成一个算子来看待,尽管这个算子并不会以节点的形式出现在 ONNX 模型的可视化结果里。
把算子封装成 Function 后,我们可以把 my_add算子用起来了。
my_add = MyAddFunction.apply
class MyAdd(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, a, b):
return my_add(a, b) 在这份代码里,我们先用 my_add = MyAddFunction.apply 获取了一个奇怪的变量。这个变量是用来做什么的呢?其实,apply是torch.autograd.Function 的一个方法,这个方法完成了 Function 在前向推理或者反向传播时的调度。我们在使用 Function 的派生类做推理时,不应该显式地调用 forward(),而应该调用其 apply 方法。
这里我们使用 my_add = MyAddFunction.apply 把这个调用方法取了一个更简短的别名 my_add。以后在使用 my_add 算子时,我们应该忽略 MyAddFunction 的实现细节,而只通过 my_add 这个接口来访问算子。这里 my_add 的地位,和 PyTorch 的 asinh, interpolate, conv2d等原生函数是类似的。
有了访问新算子的接口后,我们可以进一步把算子封装成一个神经网络中的计算层。我们定义一个叫做的 MyAdd 的 torch.nn.Module,它封装了my_add,就和封装了conv2d 的 torch.nn.Conv2d 一样。
测试算子
费了好大的功夫来“包装”我们的新算子后,我们终于可以来使用它了。和之前的测试流程一样,让我们用下面的代码来导出一个包含新算子的 ONNX 模型,并验证一下它是否正确。
model = MyAdd()
input = torch.rand(1, 3, 10, 10)
torch.onnx.export(model, (input, input), 'my_add.onnx')
torch_output = model(input, input).detach().numpy()
import onnxruntime
import numpy as np
sess = onnxruntime.InferenceSession('my_add.onnx')
ort_output = sess.run(None, {'a': input.numpy(), 'b': input.numpy()})[0]
assert np.allclose(torch_output, ort_output) 在这份代码中,我们直接把 MyAdd 作为要导出的模型。我们计算了一个 PyTorch 模型的运行结果,又导出 ONNX 模型,计算了 ONNX 模型在 ONNX Runtime 上的运算结果。如果一切正常的话,这两个结果是一样的,这份代码不会报任何错误,没有任何输出。
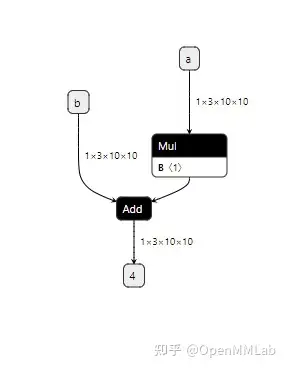
可视化一下 my_add.onnx,可以看出,和我们设计得一样,my_add 算子被翻译成了两个 ONNX 算子节点(其中常量算子被放入了 Mul 的参数中)。
整理一下,整个流程的 Python 代码如下:
import torch
import my_lib
class MyAddFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, a, b):
return my_lib.my_add(a, b)
@staticmethod
def symbolic(g, a, b):
two = g.op("Constant", value_t=torch.tensor([2]))
a = g.op('Mul', a, two)
return g.op('Add', a, b)
my_add = MyAddFunction.apply
class MyAdd(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, a, b):
return my_add(a, b)
model = MyAdd()
input = torch.rand(1, 3, 10, 10)
torch.onnx.export(model, (input, input), 'my_add.onnx')
torch_output = model(input, input).detach().numpy()
import onnxruntime
import numpy as np
sess = onnxruntime.InferenceSession('my_add.onnx')
ort_output = sess.run(None, {'a': input.numpy(), 'b': input.numpy()})[0]
assert np.allclose(torch_output, ort_output) 总结
在这篇教程中,我们围绕“为 ATen 算子添加符号函数”、“为 TorchScript 算子添加符号函数”、“封装成 torch.autograd.Function 并添加符号函数”这三种添加映射关系的方法,讲解了 3 个为 PyTorch 和 ONNX 添加支持的实例。在这个过程中,我们学到了很多零散的知识,来总结一下吧。
- ATen 是 PyTorch 的 C++ 张量运算库。通过查询
torch/_C/_VariableFunctions.pyi和torch/nn/functional.pyi,我们可以知道 ATen 算子的 Python 接口定义。 - 用
register_op可以为 ATen 算子补充注册符号函数 - 用
register_custom_op_symbolic可以为 TorchScript 算子补充注册符号函数 - 如何在 PyTorch 里添加 C++ 拓展
- 如何用
torch.autograd.Function封装一个自定义 PyTorch 算子 - 如何编写符号函数
symbolic(g, ...)。 - 如何用
g.op()把一个 PyTorch 算子映射成一个或多个 ONNX 算子,或者是自定义的 ONNX 算子。