
Kullback-Leibler Divergence,即K-L散度,是一种量化两种概率分布P和Q之间差异的方式,又叫相对熵。在概率学和统计学上,我们经常会使用一种更简单的、近似的分布来替代观察数据或太复杂的分布。K-L散度能帮助我们度量使用一个分布来近似另一个分布时所损失的信息量。
数据的熵
K-L散度源于信息论。信息论主要研究如何量化数据中的信息。最重要的信息度量单位是熵Entropy,一般用H表示。分布的熵的公式如下:
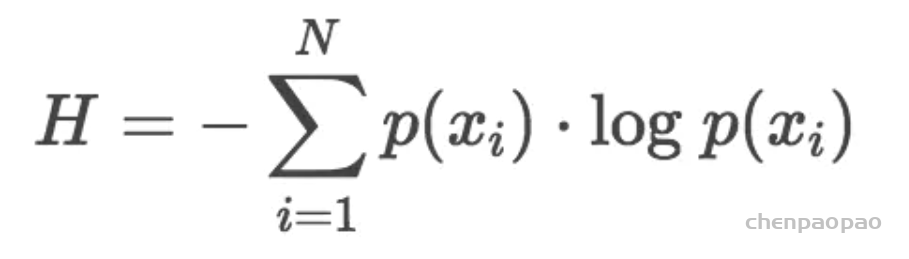
上面对数没有确定底数,可以是2、e或10,等等。如果我们使用以2为底的对数计算H值的话,可以把这个值看作是编码信息所需要的最少二进制位个数bits。上面空间蠕虫的例子中,信息指的是根据观察所得的经验分布给出的蠕虫牙齿数量。计算可以得到原始数据概率分布的熵值为3.12 bits。这个值只是告诉我们编码蠕虫牙齿数量概率的信息需要的二进制位bit的位数。
可是熵值并没有给出压缩数据到最小熵值的方法,即如何编码数据才能达到最优(存储空间最优)。优化信息编码是一个非常有意思的主题,但并不是理解K-L散度所必须的。熵的主要作用是告诉我们最优编码信息方案的理论下界(存储空间),以及度量数据的信息量的一种方式。理解了熵,我们就知道有多少信息蕴含在数据之中,现在我们就可以计算当我们用一个带参数的概率分布来近似替代原始数据分布的时候,到底损失了多少信息。
K-L散度度量信息损失
只需要稍加修改熵H的计算公式就能得到K-L散度的计算公式。设p为观察得到的概率分布,q为另一分布来近似p,则p、q的K-L散度为:

显然,根据上面的公式,K-L散度其实是数据的原始分布p和近似分布q之间的对数差值的期望。如果继续用2为底的对数计算,则K-L散度值表示信息损失的二进制位数。下面公式以期望表达K-L散度:
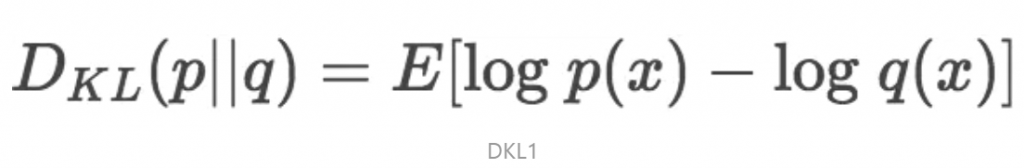
一般,K-L散度以下面的书写方式更常见:

注:log a - log b = log (a/b)
OK,现在我们知道当用一个分布来近似另一个分布时如何计算信息损失量了
散度并非距离
很自然地,一些同学把K-L散度看作是不同分布之间距离的度量。这是不对的,因为从K-L散度的计算公式就可以看出它不符合对称性(距离度量应该满足对称性)。也就是说,用p近似q和用q近似p,二者所损失的信息并不是一样的。
如果你熟悉神经网络,你肯能已经猜到我们接下来要学习的内容。除去神经网络结构的细节信息不谈,整个神经网络模型其实是在构造一个参数数量巨大的函数(百万级,甚至更多),不妨记为f(x),通过设定目标函数,可以训练神经网络逼近非常复杂的真实函数g(x)。训练的关键是要设定目标函数,反馈给神经网络当前的表现如何。训练过程就是不断减小目标函数值的过程。