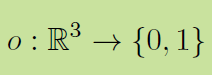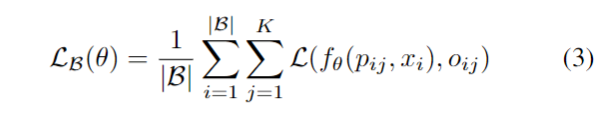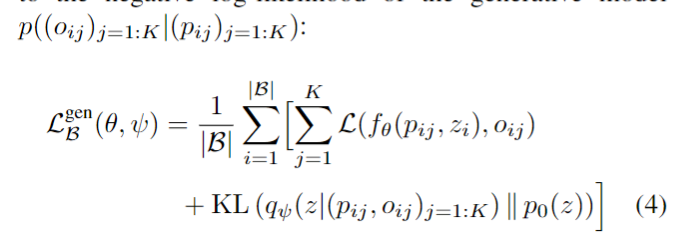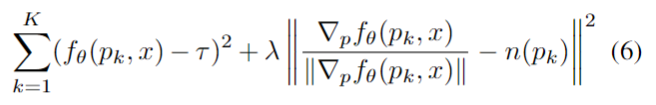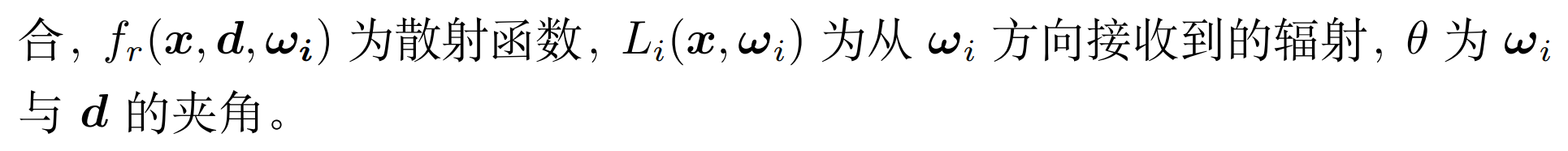转自:Leviosa
1 引言
NeRF是2020年ECCV论文。仅仅过去不到2年,关于NeRF的论文数量已经十分可观。相比于计算机视觉,尤其是相比于基于深度学习的计算机视觉,计算机图形学是比较困难、比较晦涩的。被深度学习席卷的计算机视觉任务数不胜数,但被深度学习席卷的计算机图形学任务仍然尚少。
由于NeRF及其众多follow-up工作在图形学中非常重要的渲染任务上给出了优秀的结果,可以预见未来用深度学习完成图形学任务的工作会快速增长。今年的GIRAFFE是NeRF的后续工作之一,它摘下2021CVPR的最佳论文奖对整个方向的繁荣都起到积极的推动作用。
本文希望讨论以下问题:
- NeRF被提出的基础(2 前NeRF时代);
- NeRF是什么(3 NeRF!);
- NeRF的代表性follow-up工作(4 后NeRF时代);
- 包含NeRF的更宽泛的研究方向Neural Rendering的简介(5 不止是NeRF)。
2 前NeRF时代
2.1 传统图形学的渲染
本质上,NeRF做的事情就是用深度学习完成了图形学中的3D渲染任务。那么我们提两个问题。
- 问题1:3D渲染是要干什么?
看2个比较官方的定义。
MIT计算机图形学课程EECS 6.837对渲染(Rendering)的定义:
“Rendering” refers to the entire process that produces color values for pixels, given a 3D representation of the scene.
综述State of the Art on Neural Rendering对渲染(Rendering)的定义:
The process of transforming a scene definition including cameras, lights, surface geometry and material into a simulated camera image is known as rendering.
也就是说,渲染就是用计算机模拟照相机拍照,它们的结果都是生成一张照片。
用照相机拍照是一个现实世界的物理过程,主要是光学过程,拍照对象是现实世界中真实的万事万物,形成照片的机制主要就是:光经过镜头,到达传感器,被记录下来。
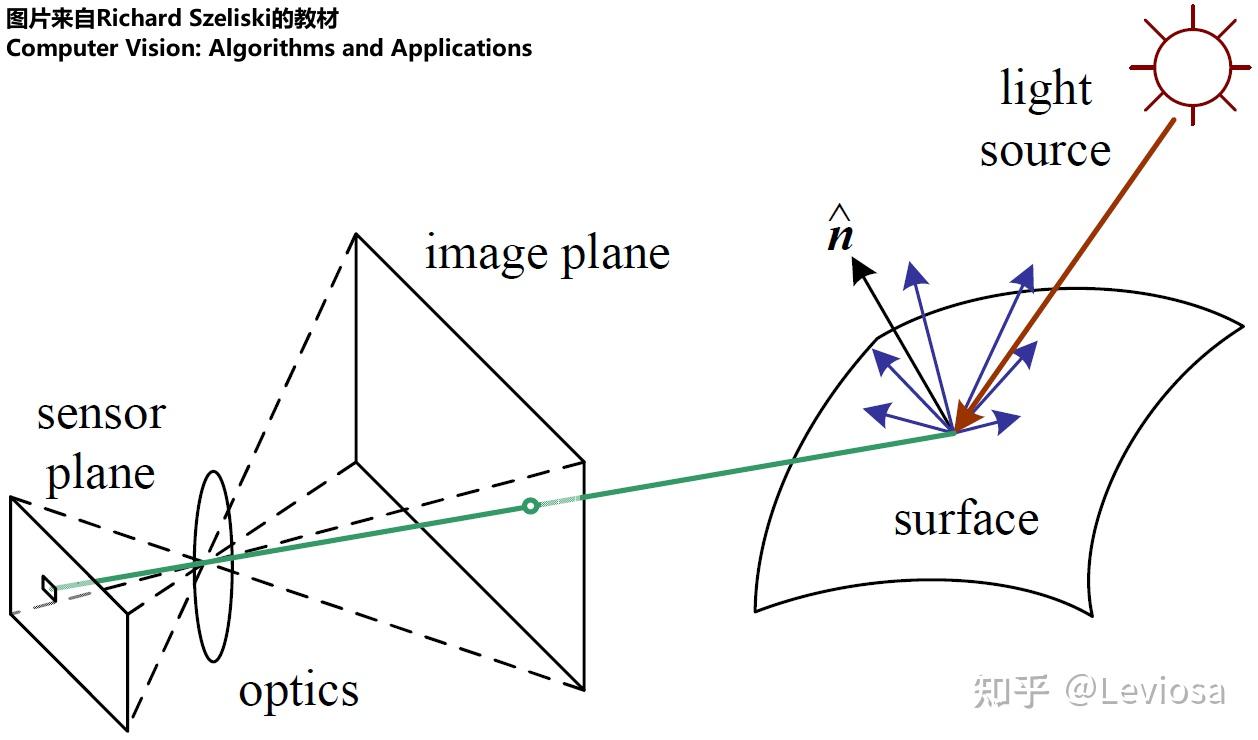
而渲染就是用计算机模拟这一过程,模拟“拍照”的对象是已存在的某种三维场景表示(3D representation of the scene),模拟生成照片的机制是图形学研究人员精心设计的算法。
关键前提:渲染的前提是某种三维场景表示已经存在。渲染一词本身不包办生成三维场景表示。不过,渲染的确与三维场景表示的形式息息相关;因此研究渲染的工作通常包含对三维场景表示的探讨。
- 问题2:3D渲染是图形学问题,那么原先大家是用什么传统图形学方法实现3D渲染的呢?
主要有两种算法:光栅化(rasterization),光线追踪(ray tracing);都是对照相机拍照的光学过程进行数学物理建模来实现的。
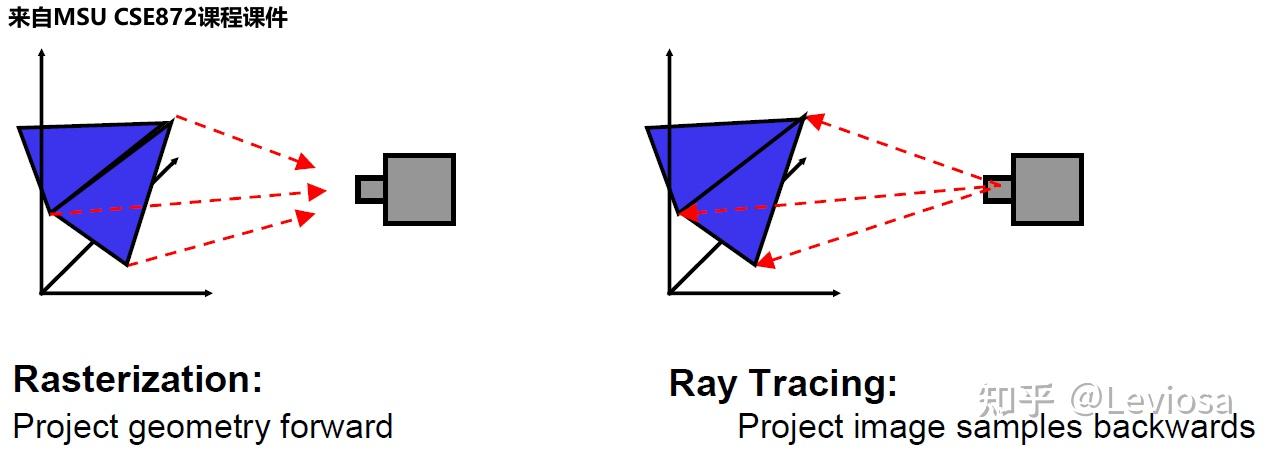
传统渲染的详细原理参阅此教材。
光栅化是一种前馈过程,几何体被转换为图像域,是上世纪比较早的算法。光线追踪则是将光线从图像像素向后投射到虚拟三维场景中,并通过从与几何体的交点递归投射新光线来模拟反射和折射,有全局光照的优势(能模拟光线的多次反射或折射)。
当下,在学术界,还在研究传统图形学的渲染算法的人应该大部分在搞优化加速,怎么用GPU实时渲染更复杂的场景之类的事儿。在工业界,不少游戏重度依赖渲染技术,所以应该也有不少游戏公司在研究更逼真、更快速、更省算力的渲染算法。去年虚幻引擎出的新款“虚幻引擎5”效果很是震撼,光照、纹理、流体的实时渲染模拟都逼真到了前所未有的新高度,可以看下虚幻引擎官方的宣传视频,真的很不错。

2.2 神经网络侵略3D渲染任务:NeRF呼之欲出
隐式场景表示(implicit scene representation)
基于深度学习的渲染的先驱是使用神经网络隐式表示三维场景。 许多3D-aware的图像生成方法使用体素、网格、点云等形式表示三维场景,通常基于卷积架构。 而在CVPR 2019上,开始出现 使用神经网络拟合标量函数 来表示三维场景的工作。
DeepSDF
2019年CVPR的DeepSDF或许是最接近NeRF的先驱工作。
SDF是Signed Distance Function的缩写。DeepSDF通过回归(regress)一个分布来表达三维表面的。如下图所示,SDF>0的地方,表示该点在三维表面外面;SDF<0的地方,表示该点在三维表面里面。回归这一分布的神经网络是多层感知机(Multi-Layer Perceptron,MLP),非常简单原始的神经网络结构。

NeRF比DeepSDF进步的地方就在于,NeRF用RGBσ代替了SDF,所以除了能推理一个点离物体表面的距离,还能推理RGB颜色和透明度,且颜色是view-dependent的(观察视角不同,同一物点的颜色不同),从而实现功能更强大的渲染。
3 NeRF!
建议前往NeRF项目网站查看视频效果图。
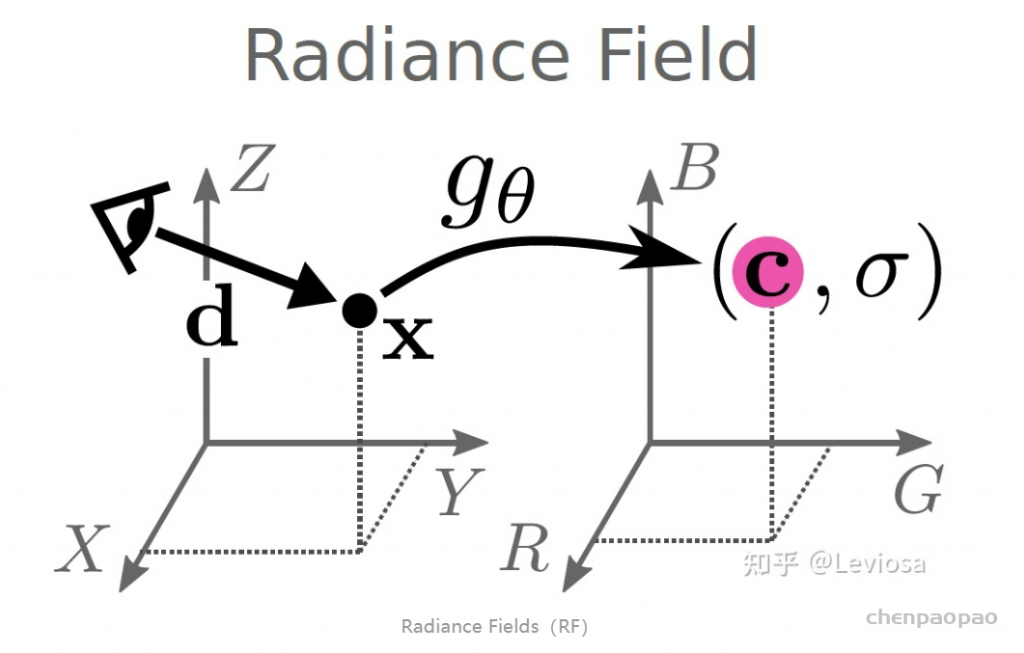
3.1 Radiance Fields(RF)
NeRF是Neural Radiance Fields的缩写。其中的Radiance Fields是指一个函数、或者说映射gθ 。
(σ,c)=gθ(x,d)
映射的输入是 x 和d 。 x∈R3是三维空间点的坐标, d∈S2 是观察角度。
映射的输出是 σ 和 c 。 σ∈R+ 是volume density(可以简单理解为不透明度), c∈R3 是color,即RGB颜色值。
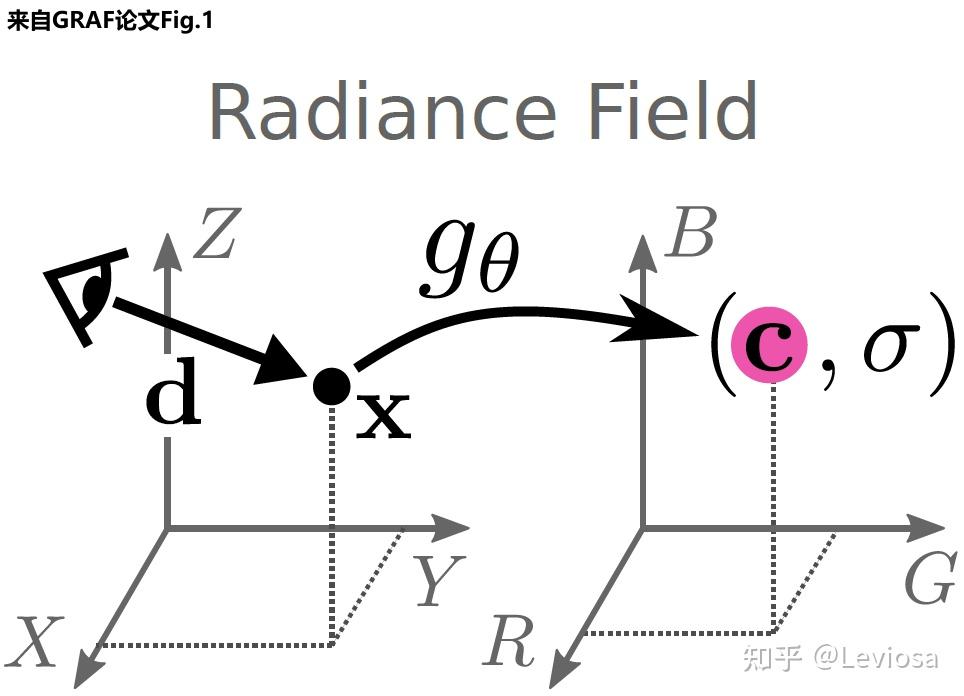
Radiance Fields,或者说映射 gθ ,能对三维场景进行隐式表示(implicit scene representation)。在上一节,我们说过某种三维场景表示正是渲染的前提。实现渲染也是 作者提出Radiance Fields这一新型三维场景表示方法 的目的所在。
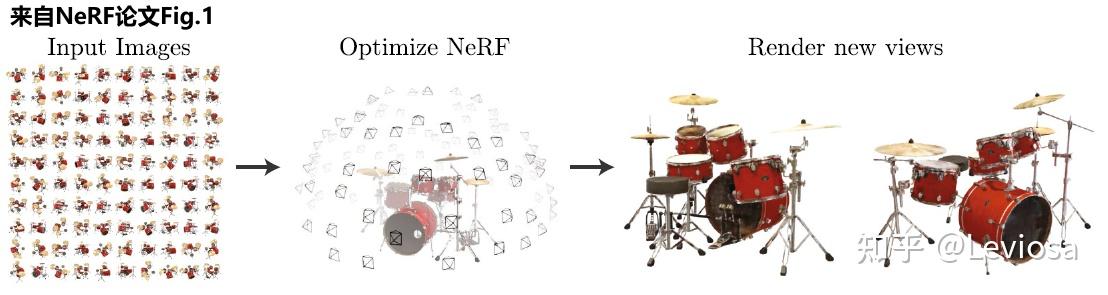
3.2 Neural Radiance Fields(NeRF)
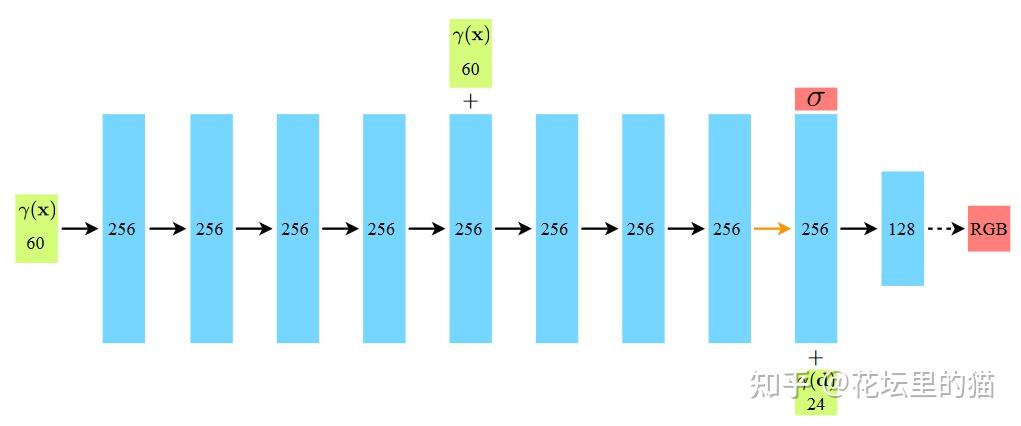
Radiance Fields是映射gθ 。那么Neural Radiance Fields则是指用神经网络拟合Radiance Fields gθ 。论文中,该神经网络具体是多层感知机(与DeepSDF一样)。
3.3 NeRF的体积渲染
NeRF(Neural Radiance Fields)其实是一种三维场景表示(scene representation),而且是一种隐式的场景表示(implicit scene representation),因为不能像point cloud、mesh、voxel一样直接看见一个三维模型。
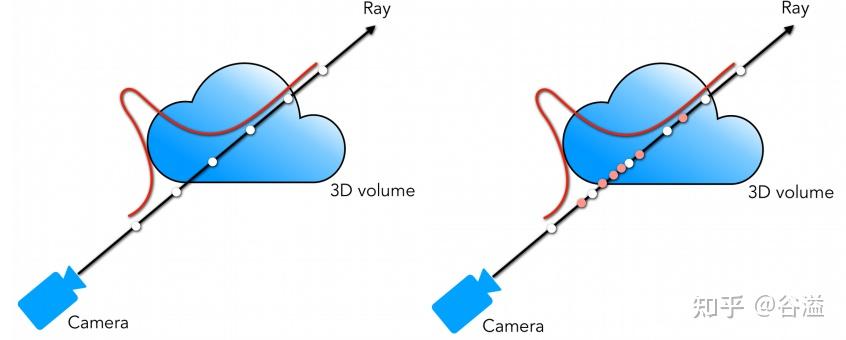
NeRF将场景表示为空间中任何点的volume density σ 和颜色值 c 。 有了以NeRF形式存在的场景表示后,可以对该场景进行渲染,生成新视角的模拟图片。论文使用经典体积渲染(volume rendering)的原理,求解穿过场景的任何光线的颜色,从而渲染合成新的图像。


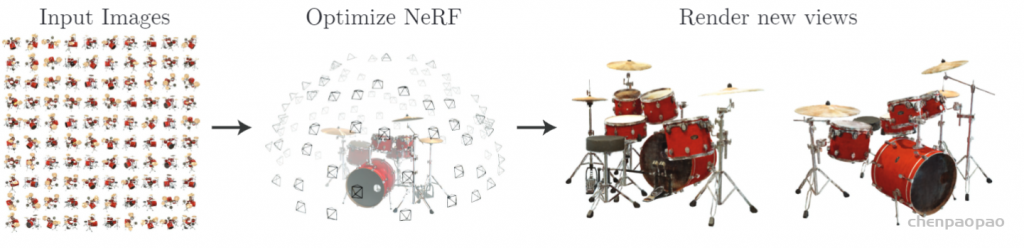
3.4 NeRF的训练
训练NeRF的输入数据是:从不同位置拍摄同一场景的图片,拍摄这些图片的相机位姿、相机内参,以及场景的范围。若图像数据集缺少相机参数真值,作者便使用经典SfM重建解决方案COLMAP估计了需要的参数,当作真值使用。
在训练使用NeRF渲染新图片的过程中,
- 先将这些位置输入MLP以产生volume density和RGB颜色值;
- 取不同的位置,使用体积渲染技术将这些值合成为一张完整的图像;
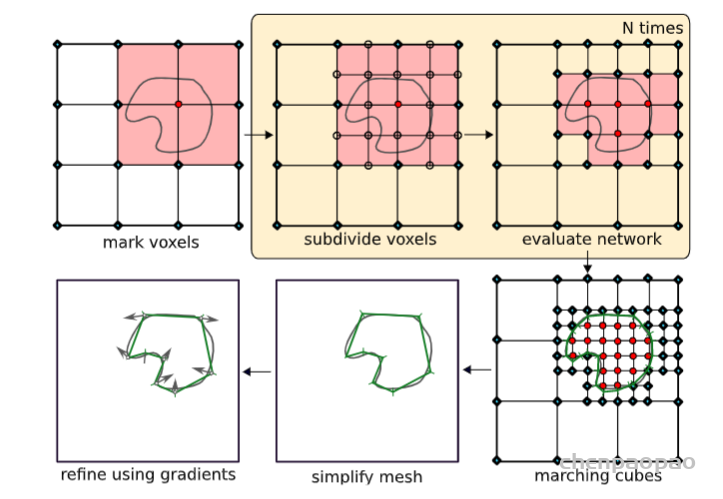
- 因为体积渲染函数是可微的,所以可以通过最小化上一步渲染合成的、真实图像之间的差来训练优化NeRF场景表示。
这样的一个NeRF训练完成后,就得到一个 以多层感知机的权重表示的 模型。一个模型只含有该场景的信息,不具有生成别的场景的图片的能力。
除此之外,NeRF还有两个优化的trick:
- 位置编码(positional encoding),类似于傅里叶变换,将低维输入映射到高维空间,提升网络捕捉高频信息的能力;
- 体积渲染的分层采样(hierarchical volume sampling),通过更高效的采样策略减小估算积分式的计算开销,加快训练速度。
4 后NeRF时代
GIRAFFE:composition方向的代表作
2021CVPR的最佳论文奖得主GIRAFFE是NeRF、GRAF工作的延申。
在NeRF之后,有人提出了GRAF(Generative Radiance Fields),关键点在于引入了GAN来实现Neural Radiance Fields;并使用conditional GAN实现对渲染内容的可控性。
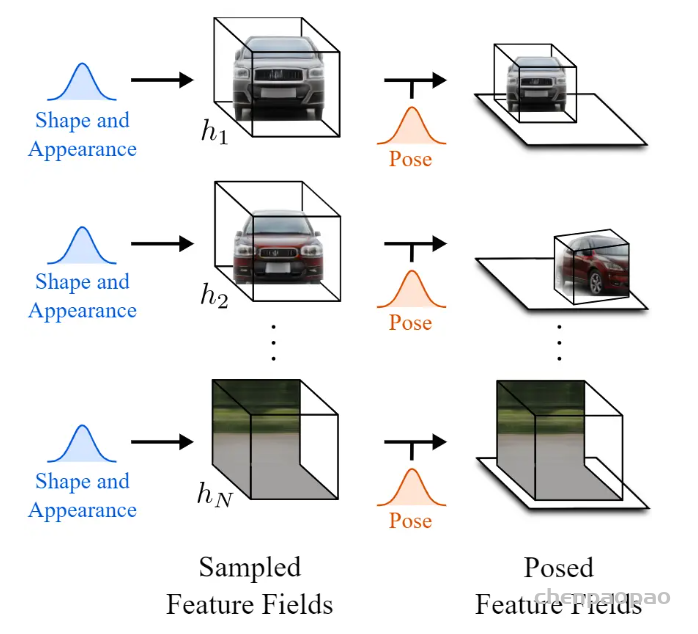
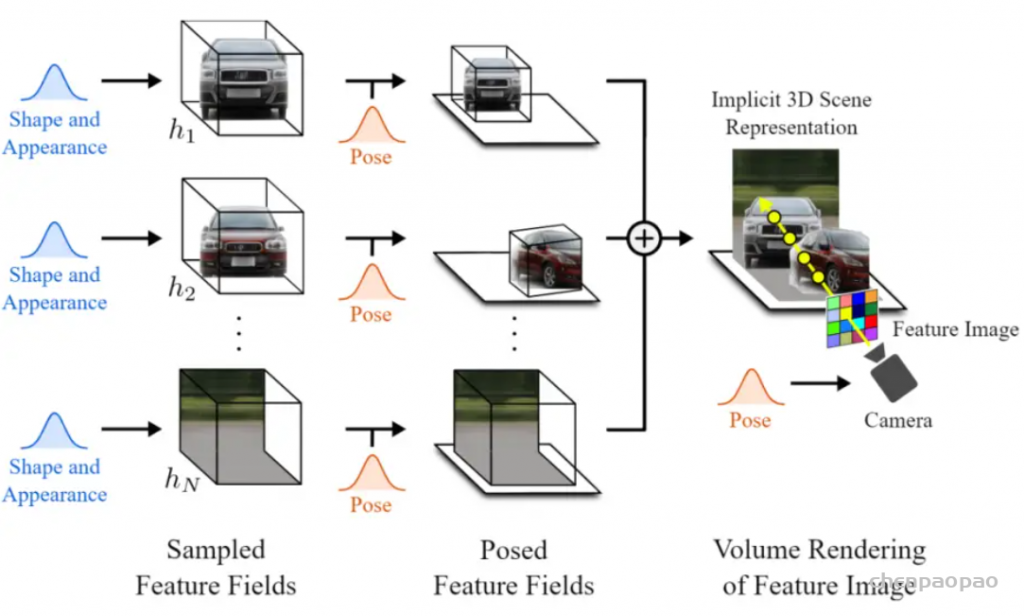
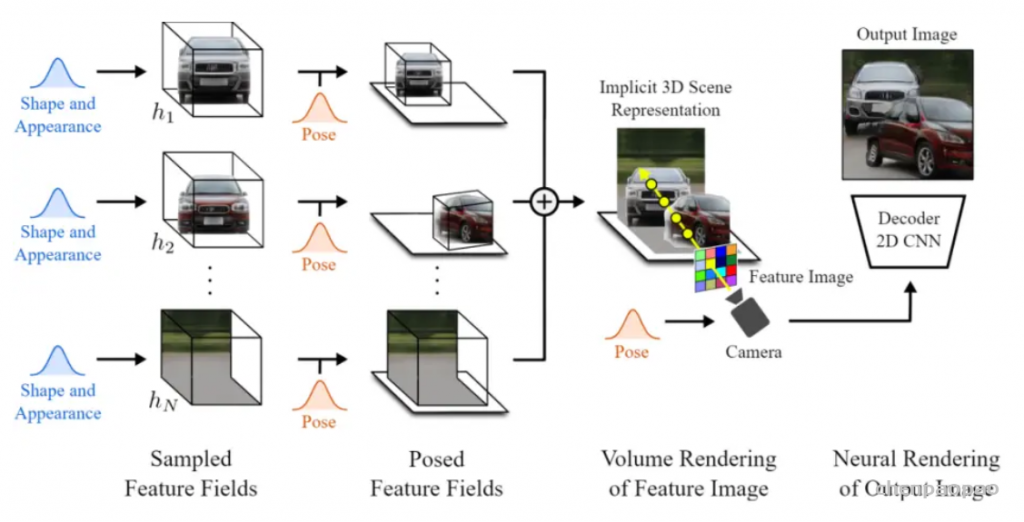
在GRAF之后,GIRAFFE实现了composition。在NeRF、GRAF中,一个Neural Radiance Fields表示一个场景,one model per scene。而在GIRAFFE中,一个Neural Radiance Fields只表示一个物体,one object per scene(背景也算一个物体)。这样做的妙处在于可以随意组合不同场景的物体,可以改变同一场景中不同物体间的相对位置,渲染生成更多训练数据中没有的全新图像。

如图所示,GIRAFFE可以平移、旋转场景中的物体,还可以在场景中增添原本没有的新物体。
另外,GIRAFFE还可以改变物体的形状和外观,因为网络中加入了形状编码、外观编码变量(shape codes zsi , appearance codes zai )。
其他最新相关工作
2021年CVPR还有许多相关的精彩工作发表。例如,提升网络的泛化性:
- pixelNeRF:将每个像素的特征向量而非像素本身作为输入,允许网络在不同场景的多视图图像上进行训练,学习场景先验,然后测试时直接接收一个或几个视图为输入合成新视图。
- IBRNet:学习一个适用于多种场景的通用视图插值函数,从而不用为每个新的场景都新学习一个模型才能渲染;且网络结构上用了另一个时髦的东西 Transformer。
- MVSNeRF:训练一个具有泛化性能的先验网络,在推理的时候只用3张输入图片就重建一个新的场景。
针对动态场景的NeRF:
- Nerfies:多使用了一个多层感知机来拟合形变的SE(3) field,从而建模帧间场景形变。
- D-NeRF:多使用了一个多层感知机来拟合场景形变的displacement。
- Neural Scene Flow Fields:多提出了一个scene flow fields来描述时序的场景形变。
其他创新点:
- PhySG:用球状高斯函数模拟BRDF(高级着色的上古神器)和环境光照,针对更复杂的光照环境,能处理非朗伯表面的反射。
- NeX:用MPI(Multi-Plane Image )代替NeRF的RGBσ作为网络的输出。
5 不止是NeRF:Neural Rendering
Neural Radiance Fields的外面是Neural Rendering;换句话说,NeRF(Neural Radiance Fields)是Neural Rendering方向的子集。
在针对这个更宽泛的概念的综述State of the Art on Neural Rendering中,Neural Rendering的主要研究方向被分为5类,NeRF在其中应属于第2类“Novel View Synthesis”(不过这篇综述早于NeRF发表,表中没有NeRF条目)。
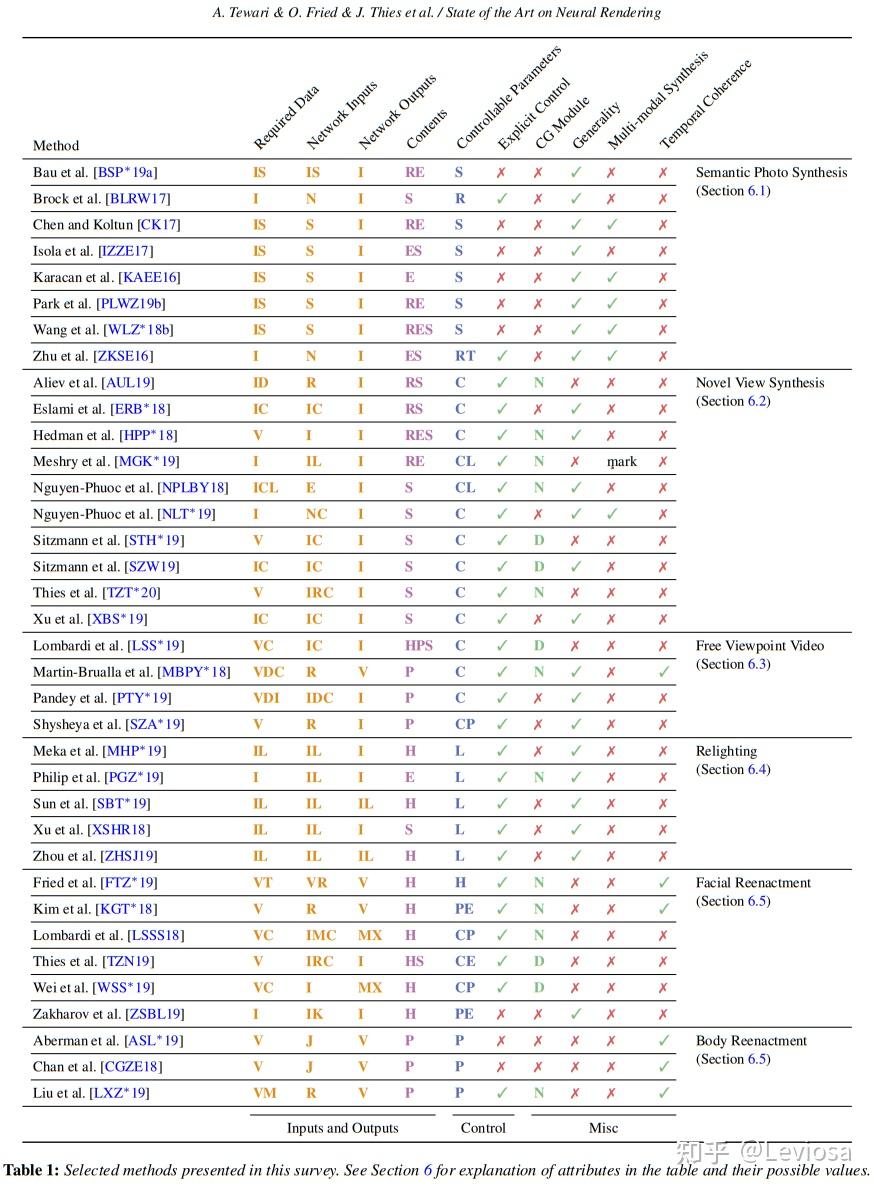
表中彩色字母缩写的含义:

在这篇综述中,Neural Rendering被定义为:
Deep image or video generation approaches that enable explicit or implicit control of scene properties such as illumination, camera parameters, pose, geometry, appearance, and semantic structure.
Neural Rendering包含所有使用神经网络生成可控(且photo-realistic)的新图片的方法。“可控”指人可以显式或隐式地控制生成新图片的属性,常见的属性包括:光照,相机内参,相机位姿(外参),几何关系,外观,语义分割结构。在这个大框架下,NeRF是一种比较受欢迎的可控相机位姿的Neural Rendering算法。但Neural Rendering这个方向不止于此。
在目前的Neural Rendering方向,最火的子方向就是“Novel View Synthesis”,这与NeRF的强势蹿红密不可分;第二火的子方向是“Semantic Photo Synthesis”,这主要归功于语义分割以及相关的GAN领域的成熟度。“Semantic Photo Synthesis”方向也是成果颇丰,例如2019年CVPR的Semantic Image Synthesis with Spatially-Adaptive Normalization,其效果图如下。

相关资源
Github论文收集仓库
小仓库(仅限于NeRF):
https://github.com/yenchenlin/awesome-NeRF
大仓库(neural rendering):
https://github.com/weihaox/awesome-neural-rendering
综述论文
可以说是官方综述,作者列表是目前在Neural Rendering领域最活跃的一群人。两篇分别是2021、2020年的SIGGRAPH、CVPR讲座用到的综述,很全面很有条理,值得每位从业者一读!
SIGGRAPH 2021 Course: Advances in Neural Rendering
CVPR 2020 Tutorial: State of the Art on Neural Rendering
范围限定为可微渲染方法的综述:
Differentiable Rendering: A Survey
上面小仓库的库主(MIT博士生Yen-Chen Lin)写的综述:
Neural Volume Rendering: NeRF And Beyond
论文
列论文实在挂一漏万,象征性地放上本文提到的2篇很重要的论文吧。
NeRF项目主页:
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
GIRAFFE项目主页:
GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
教材
传统图形学渲染技术:
计算机视觉经典教材,含有image-based rendering章节:
Computer Vision: Algorithms and Applications
三篇Georgia Tech老师写的博客
NeRF at CVPR 2022 – Frank Dellaert
NeRF at ICCV 2021 – Frank Dellaert
NeRF Explosion 2020 – Frank Dellaert

离散形式
推导一下连续形式变为离散形式的运算。
计算机求解积分式的办法一般是化为黎曼和。在这里,如果我们每次都将积分区间划分为固定的、等间距的窄长方形面积和,其实就失去了NeRF是连续场景表示的优势:因为虽然每个点的RGBσ都可以访问,但是实际上你还是只用了固定点的值求积分。