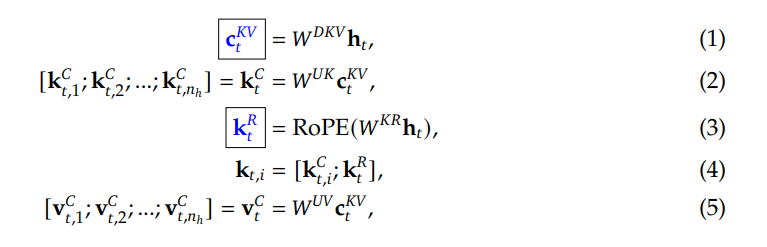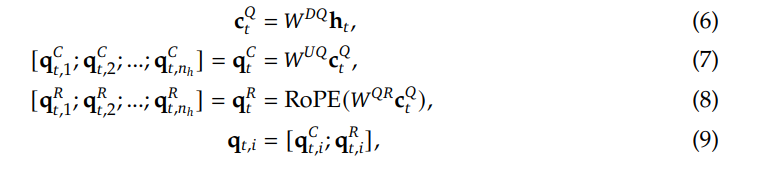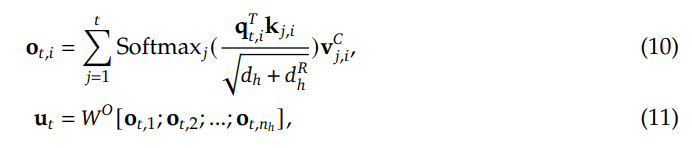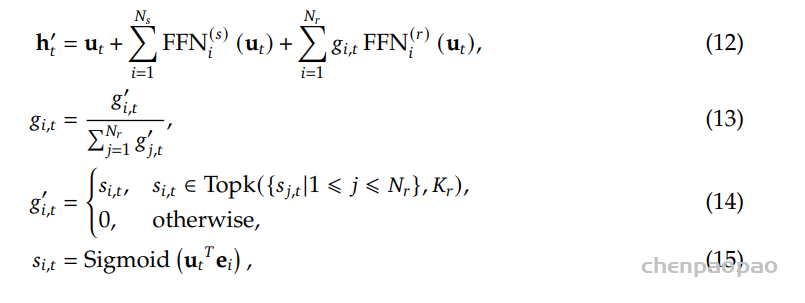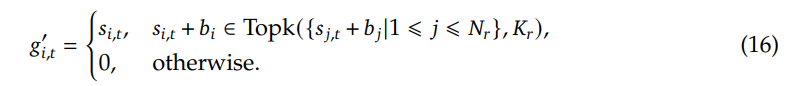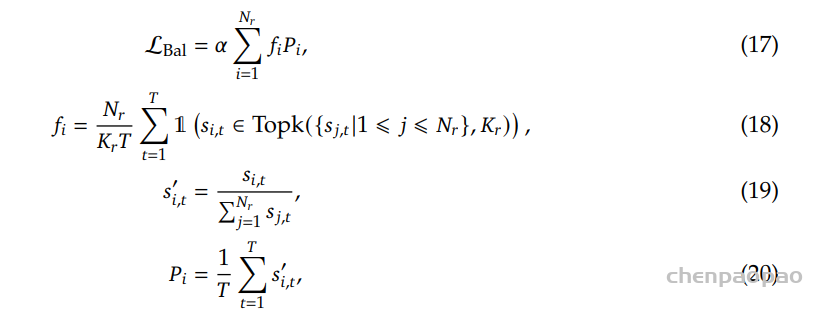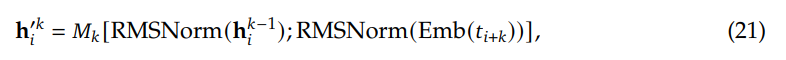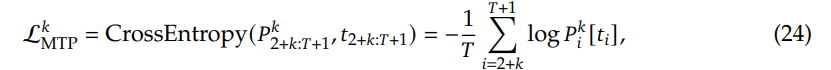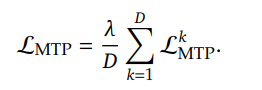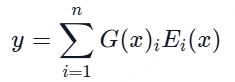FunAudioLLM Team Tongyi Lab, Alibaba Group
用于语音交互的语音-文本多模态模型的先前工作可以大致分为 原生 模型和 对齐 模型。原生多模态模型使用单个框架同时对语音和文本的端到端理解和生成进行建模,然而,他们面临着语音和文本序列长度之间巨大差异、语音预训练不足以及灾难性地忘记文本LLMs的挑战;对齐的多模态模型在保持文本LLMs,然而,现有模型通常在小规模语音数据上进行训练,在有限的语音任务集上进行研究,并且缺乏对丰富而细致的说话风格的指令跟踪能力的系统探索
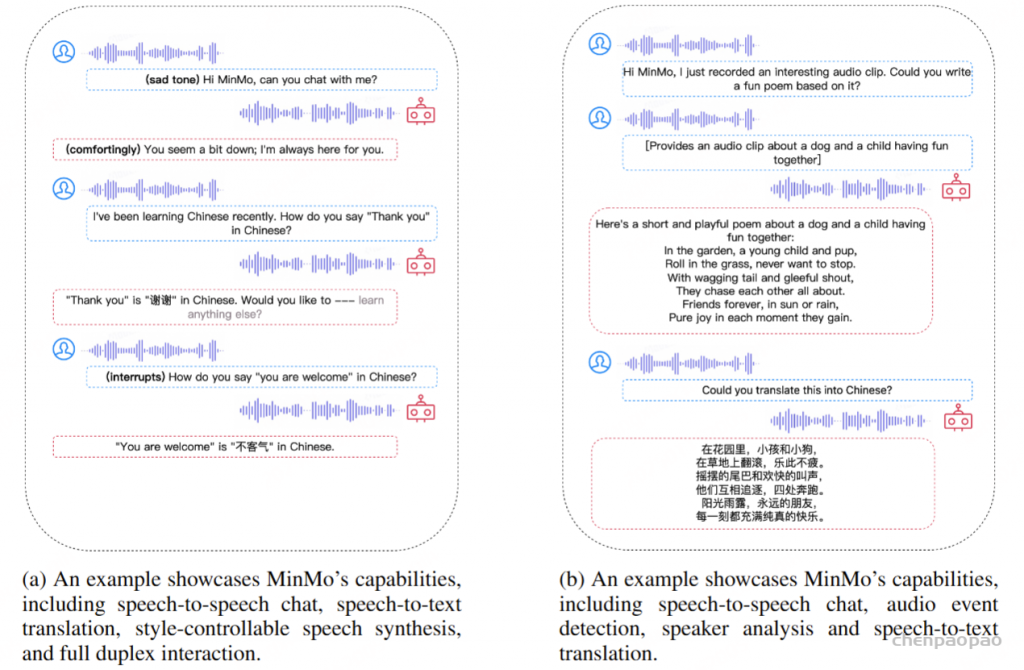
MinMo,这是一种多模态大型语言模型,具有大约 8B 参数,可实现无缝语音交互。 解决了先前对齐多模态模型的主要局限性。在 140 万小时的不同语音数据和广泛的语音任务上,通过语音到文本对齐、文本到语音对齐、语音到语音对齐和双工交互对齐等多个阶段来训练 MinMo。 经过多阶段训练后,MinMo 在保持文本LLMs,并且还促进了全双工对话,即用户和系统之间的同时双向通信。 此外,还提出了一种新颖而简单的语音解码器,它在语音生成方面优于以前的模型。MinMo 增强的指令跟踪功能支持根据用户指令控制语音生成,包括各种细微差别,包括情绪、方言和语速,并模仿特定声音。对于 MinMo,语音到文本的延迟约为 100 毫秒,理论上全双工延迟约为 600 毫秒,实际约为 800 毫秒。
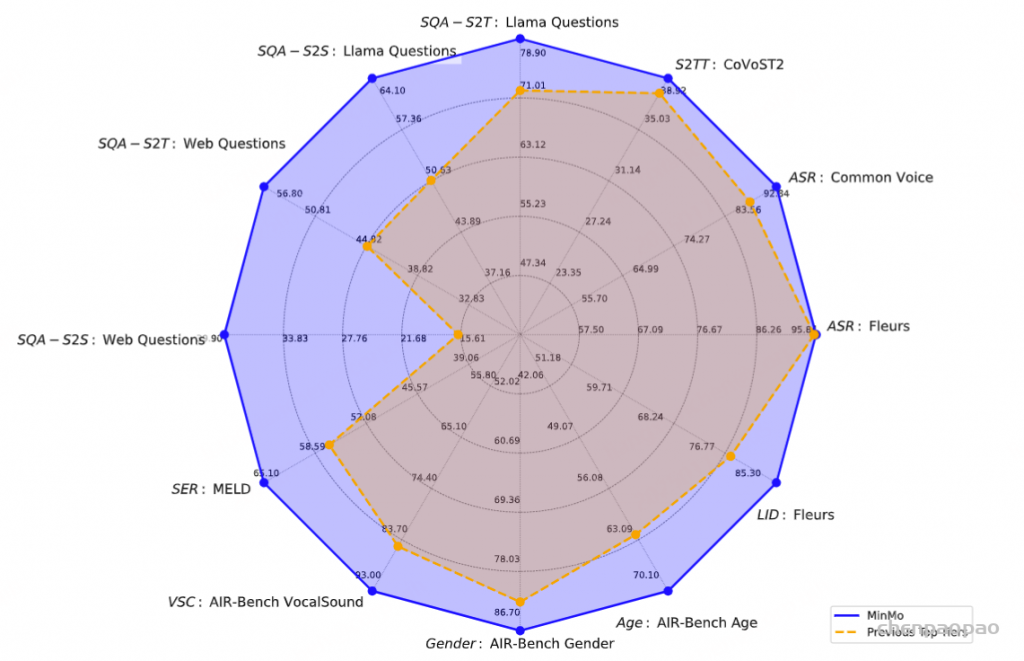
- 最先进的 (SOTA) 性能:MinMo 在语音对话、多语言语音识别、多语言语音翻译、情感识别、说话人分析和音频事件分析等基准测试中实现了当前的 SOTA 性能,同时还确保了文本大型模型的功能基本保持不变。
- 指令控制音频生成:MinMo 支持端到端语音交互,按照用户指示控制生成音频的情感、方言和说话风格,以及模仿特定的语音音调,生成效率超过 90%。
- 低延迟双工语音交互:MinMo 支持全双工语音交互,可实现流畅的多轮对话并防止背景噪音打断。语音到文本的延迟约为 100 毫秒,全双工延迟理论上约为 600 毫秒,实际约为 800 毫秒。
Introduction
无缝语音交互表示用户与系统进行实时、自然、相关且类似人类的语音对话。促进无缝语音交互带来了巨大的挑战:
- 系统需要准确、全面地理解音频,包括理解内容以及语音中的副语言线索(例如,情感、韵律)以及音频事件;
- 系统应产生自然且富有表现力的语音响应;
- 系统应向用户提供相关且合理的响应,作为智能聊天机器人;
- 系统应支持全双工对话(同时双向通信),即系统在说话时倾听,用户在系统说话时可以自由打断,然后系统要么继续语音,要么停止响应,倾听用户,并提供对新用户查询的响应。
近年来,无缝语音交互系统获得了巨大的发展势头,尤其是随着多模态大型语言模型的进步,例如 GPT-4o和 Moshi。这些系统不仅可以产生自然而富有表现力的语音,还可以理解文字以外的线索,包括情感语气和音频事件。当前用于语音交互的多模态语言模型可分为两大类。
第一类包括原生多模态模型,例如 Moshi 和 GLM-4-Voice 。这些模型通常使用仅解码器的 Transformer 作为主干,在单个框架内同时对语音和文本模态的理解和生成进行建模;它们通常需要使用语音和文本数据进行预训练。这些模型存在两个主要限制。首先,在语音离散化之后,语音标记序列的长度通常是文本长度的两倍以上(例如,在 Moshi 中每秒 12.5 个标记)。随着模型大小的增长,序列长度的这种差异会带来挑战,例如 175B GPT-3 。其次,与文本相比,语音数据的稀缺性导致语音-文本训练数据高度不平衡,进而导致灾难性的遗忘。
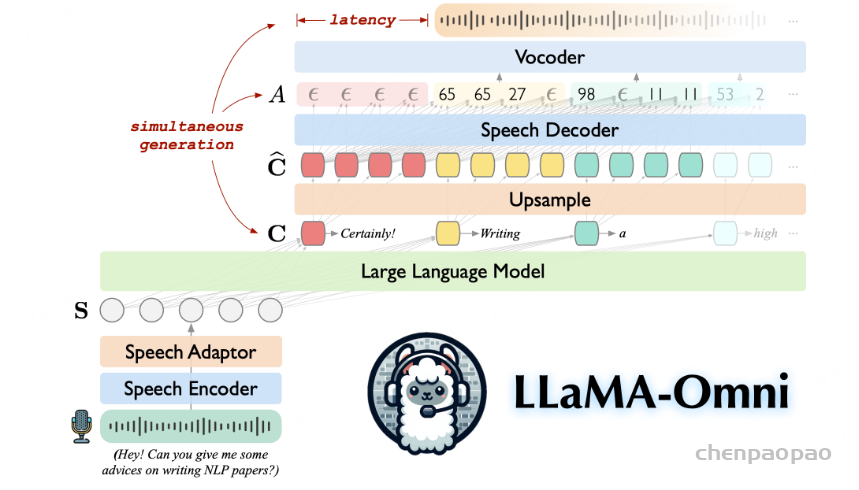
第二类包括对齐的多模态模型,集成语音功能,同时旨在保持现有预训练文本LLM。这导致中间输出仍然包含文本,如 Llama-Omni 和 Freeze-Omni 等模型所示。然而,这些基于对齐的模型通常是在有限的语音数据(LLaMA-Omni 为 200K 样本,Freeze-Omni 为 120K 小时)上进行训练的,这导致了关于大型语音数据集对模型功能的影响以及原始文本LLM可能受到影响的问题。此外,尚未对这些模型进行广泛的语音任务调查,例如语音翻译、情感识别、说话人分析、语言识别和音频事件检测。此外,这些模型缺乏对丰富而细致的说话风格的指令遵循能力的系统评估,也缺乏对全双工对话能力的开发和评估,以实现无缝语音交互。
在这项工作中,我们引入了一种新的多模态大型语言模型 MinMo,以解决现有对齐多模态模型的这些局限性。MinMo 经过超过 140 万小时的语音数据训练,包括各种任务,例如语音转文本、文本转语音和语音转语音。这种广泛的培训使 MinMo 能够在各种基准上实现最先进的 (SOTA) 性能。还采用了一些方法,有效缓解了在大规模数据集训练后,模型对原始文本语言模型(text-LLM)聊天能力的灾难性遗忘问题,同时增强了语音理解和生成能力。
还提出了一种新颖的语音解码器,在保持结构简单的同时,兼具了优异的语音生成性能。LLaMA-Omni 使用一种非自回归(NAR)流式 Transformer,它将语言模型(LLM)的输出隐藏状态作为输入,并通过连接时序分类(CTC)预测响应的离散语音标记序列。然而,这种方法的性能相比自回归语音解码器较差。Freeze-Omni 使用了三种语音解码器,包括 NAR 前缀语音解码器、NAR 语音解码器和 AR(自回归)语音解码器,使模型结构更为复杂。有别于这两种策略,我们为 MinMo 设计了一种自回归(AR)流式 Transformer,其通过固定比例将 LLM 的输出隐藏状态与语音标记混合处理。
开发了一种机制,可以有效地促进与 MinMo 的全双工相互作用。具体来说,我们实现了一个全双工预测模块,该模块利用文本LLM 的语义理解功能来决定是继续系统响应,还是让步、倾听和响应新的用户查询。对于 MinMo,语音到文本的延迟约为 100 毫秒;全双工延迟理论上约为 600 毫秒,实际时约为 800 毫秒。
Related Work
Multimodal Spoken Dialogue Models:
多种语音基础模型已被开发用于通用音频理解,但尚未系统地探索其在语音交互方面的应用。例如,Qwen2-Audio 将 Whisper 语音编码器与预训练文本语言模型(LLM)集成,并通过多任务预训练和基于指令的监督微调使 LLM 具备语音理解能力。SALMONN 是另一种用于通用音频理解的语音-文本 LLM,通过 Q-Former 将单独的语音和音频编码器与预训练文本 LLM 集成,并采用 LoRA 进行模态对齐。
由于本研究旨在开发一种端到端多模态模型以实现无缝语音交互,我们将重点比较 MinMo 与用于语音交互的语音-文本模型(或称多模态语音对话模型)。同时或受到 GPT-4o 的启发,多模态语音对话模型的开发正如火如荼地进行,以实现与用户实时语音对话的能力。(Ji et al., 2024a) 对近期的语音对话模型进行了深入综述。一些研究支持传统的回合制语音聊天(即半双工通信),但无法处理全双工语音交互(即同时双向通信)。这些模型包括协作系统和端到端框架。
PSLM (Mitsui et al., 2024) 是一种协作系统,因为它依赖 ASR 处理音频输入,这会丢弃副语言信息并导致错误传播。PSLM 同时生成语音和文本标记,从而减少语音生成延迟;然而,其响应质量较低。与 PSLM 等协作系统不同,端到端框架直接接受音频输入并生成音频输出。
Llama-Omni (Fang et al., 2024) 和 Mini-Omni (Xie & Wu, 2024) 是两个近期的端到端框架,但尚未针对全双工通信进行训练。Llama-Omni 集成了 Whisper 语音编码器、语音适配器、流式语音解码器和声码器,并以预训练文本 LLM 作为基础。其语音解码器以非自回归(NAR)方式生成与生成文本前缀对应的离散单元。该模型采用两阶段训练策略:第一阶段冻结语音编码器,仅对语音适配器和 LLM 进行自回归训练;第二阶段冻结语音编码器、语音适配器和 LLM,仅使用 CTC 损失对语音解码器进行训练。Llama-Omni 被评估在语音转文本指令执行和语音转语音指令执行任务上的表现。
Mini-Omni 同样采用 Whisper 编码器,并通过适配器进行最小化训练,以保留 LLM 的能力。该模型通过模态对齐、适配器训练和多模态微调三个阶段进行训练。Mini-Omni 同时生成文本和音频标记,并填充 N 个标记以确保首先生成对应的文本标记,从而指导音频标记的生成。
MinMo 支持全双工语音对话。现有的全双工语音聊天系统同样可以分为协作系统和端到端模型两类。在协作系统中,VITA (Fu et al., 2024) 同时运行两个模型,即生成模型和监控模型,以支持全双工通信。当生成模型正在生成系统响应时,监控模型会监控环境,并在检测到有效的用户打断后结合上下文对新的用户查询提供响应,同时生成模型暂停并切换到监控角色。值得注意的是,VITA 仍然依赖外部的 TTS 模块生成语音输出。
另一种协作系统 (Wang et al., 2024a) 则通过 LLM 接入 ASR 模块和流式 TTS 模块运行。该系统不需要模态对齐,而是对预训练的文本 LLM 进行监督微调,采用以下范式:在每个时间步,LLM 要么处理一个输入标记,要么生成一个文本标记,要么输出一个特殊的控制标记,用于在 SPEAK 和 LISTEN 状态之间进行状态转换。所有这些任务都被定义为基于单一序列化流对话的下一个标记预测。全双工对话学习基于由 GPT-4 合成的数据进行,这些数据生成了包含不同类型用户打断的对话。值得注意的是,由于其级联架构,该系统面临高达 680ms 的高延迟问题。
在端到端全双工模型中,早期的 dGSLM (Nguyen et al., 2022) 提出了一个双塔架构,用于联合处理用户语音和系统语音的音频标记流。然而,该方法存在以下几个缺点:它依赖于仅基于语音的训练,未能利用预训练文本 LLM 的能力;仅使用语义标记,未充分建模语音的声学信息;不支持在线模式。LSLM (Ma et al., 2024b) 使用仅解码器的 Transformer 生成语音标记,并通过流式 SSL 编码器处理监听标记。该模型引入了一个中断标记,用于在检测到用户尝试轮流对话时停止发言。然而,模型在生成合理响应方面表现不足。
在最近的端到端全双工模型中,Moshi、GLM-4-Voice 、SyncLM 、IntrinsicVoice 和 Omni-Flatten 是原生多模态模型。这些模型在单一框架中同时建模语音和文本模态的理解和生成,基于 GPT 主干,并需要使用语音和文本数据进行自监督自回归预训练。如第 1 节所述,这些原生多模态模型需要应对语音标记与文本标记之间序列长度差异显著的问题,以及语音-文本训练数据高度不平衡及其导致的灾难性遗忘。IntrinsicVoice 使用 GroupFormer 从 LLM 的隐藏状态生成 HuBERT 标记,有效地将语音序列缩短到与文本序列相当的长度。Omni-Flatten 采用分阶段的逐步后期训练策略,通过块级的单流平铺语音和文本标记来学习全双工和无文本的语音到语音交互。
与这些原生多模态模型不同,我们的 MinMo 属于对齐多模态模型类别,该类别还包括 Llama-Omni、Mini-Omni2和 Freeze-Omni 。对齐多模态模型集成了语音功能,同时旨在保留现有预训练文本 LLM 的能力。Mini-Omni2 引入了基于命令的中断机制以支持全双工对话,但仅在 ASR 任务上进行评估,并与 Whisper、VITA 和 Mini-Omni 进行比较。Freeze-Omni是一个语音到语音模型,通过冻结预训练的文本 LLM 来保留其能力。它支持流式输入语音和生成流式输出语音,使用多任务训练,并通过块级状态预测来建模全双工语音交互。
我们的 MinMo 与这些对齐多模态模型在以下方面不同:我们探索了在更大规模的语音数据集(1.4 百万小时多样化语音数据,相较于 LLaMA-Omni 的 20 万样本和 Freeze-Omni 的 12 万小时)以及更广泛的语音任务上训练 MinMo。MinMo 还通过新颖的语音解码器、增强的指令跟随能力,以及对全双工语音对话能力的系统性训练和评估,与现有的对齐多模态模型形成了差异化。
文本风格 – 可控语音合成
多模态语音对话模型相比于基于文本的对话模型的显著特征在于其能够理解和生成超越文本内容的声学信息。语音模态不仅包含内容,还包括情感、方言和语速等声学信息。一个智能的多模态语音对话模型应该能够全面理解输入语音中的声学信息(例如情感),并且能够生成带有指定情感、方言、语速的响应,甚至模仿特定的声音,从而在沟通中实现更深层次的理解和响应。
协作系统如 ParalinGPT 、E-Chat 和 Spoken-LLM 通过整合副语言特征增强对情感等声学信息的理解。这些系统可以与可控风格的文本转语音(TTS)系统结合,以生成带有特定情感、语速和音量的响应。在文本风格可控 TTS 方面取得了显著进展,例如 TextrolSpeech 、PromptTTS 、PromptTTS2、InstructTTS 和 ControlSpeech 。
与这些协作系统相比,Moshi 使用一个具有单一演员声音和超过 70 种说话风格录音的 TTS 引擎,生成训练数据以支持在端到端模型中理解和生成声学信息。GLM-4-Voice利用高质量的多轮语音对话数据,这些数据针对特定语音风格需求(如语速、情感或方言)进行定制,从而支持风格可控的语音对话。然而,据我们所知,尚无研究表明对齐的多模态模型能够支持风格可控的语音生成。
与之前的研究声称对齐的多模态模型(如 Llama-Omni 和 Freeze-Omni)仅允许语言模型控制语音的内容而非风格和韵律相反,我们在本研究中提出了一种新型的流式语音解码器,用于对齐多模态模型 MinMo,并发现该解码器不仅增强了指令跟随能力,还使 MinMo 能够生成符合用户指定情感、方言、语速以及模仿特定声音的语音。
MinMo
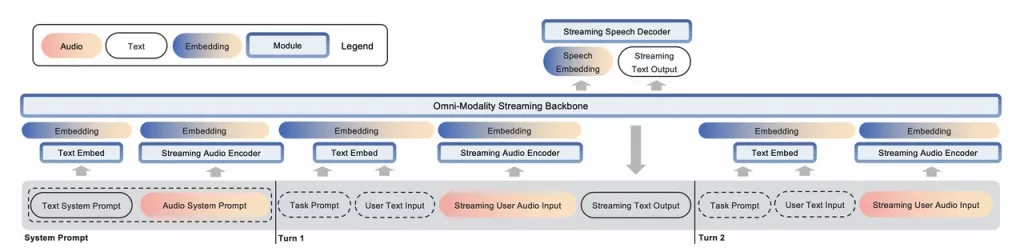
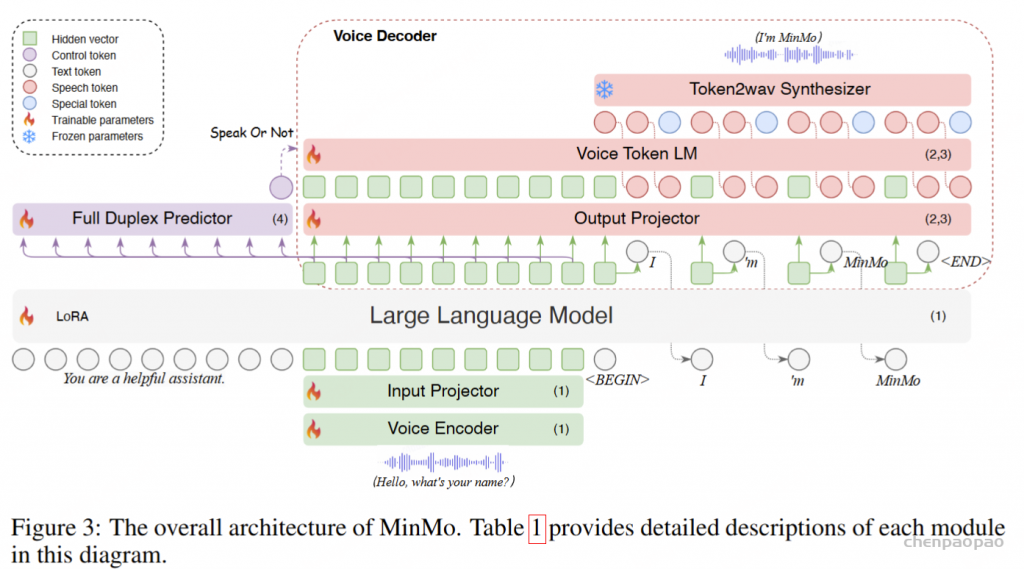
模型架构
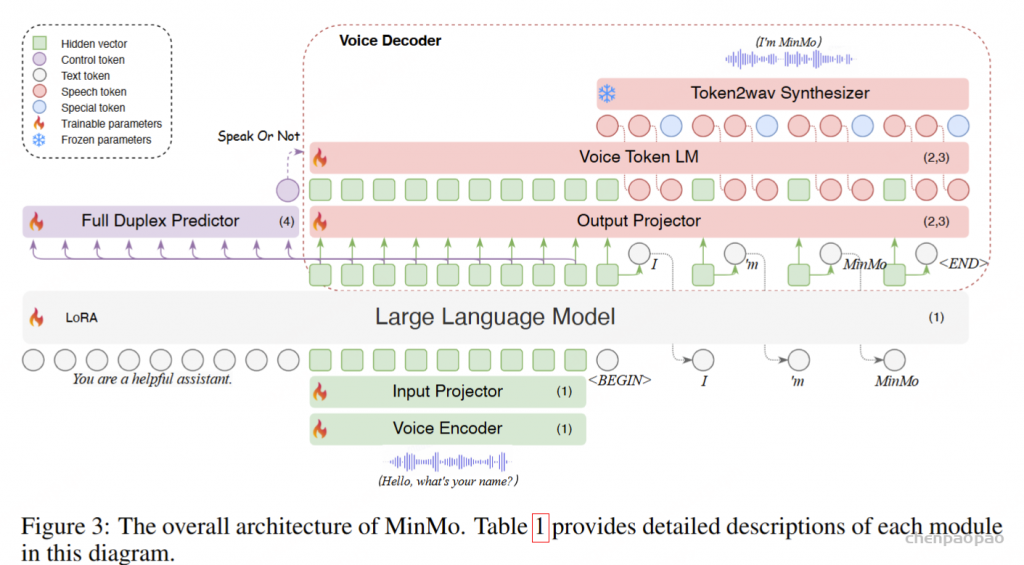
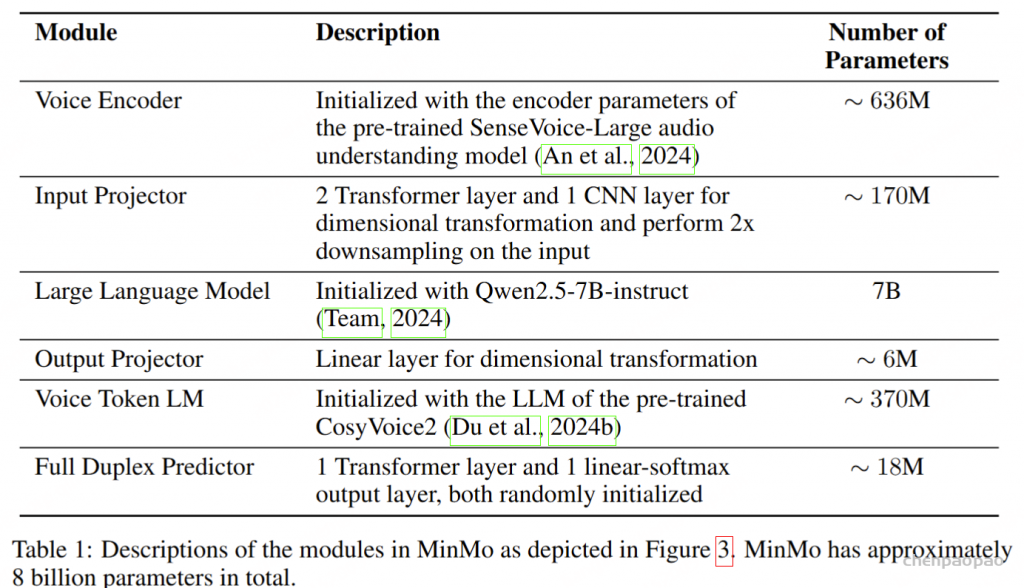
语音编码器采用预训练的 SenseVoice-large 编码模块,提供了强大的语音理解能力,支持多语言语音识别、情感识别和音频事件检测。输入投影器由一个随机初始化的两层 Transformer 和一个 CNN 层组成,用于维度对齐和降采样。我们选用预训练的 Qwen2.5-7B-instruct 模型作为预训练的文本 LLM,因为其在各种基准测试中的表现卓越(Team, 2024)。此外,我们利用 CosyVoice 2的流式音频生成机制,该机制具备低延迟并提供具有竞争力的语音合成性能。
对于每批接收的五个文本标记,我们将这些标记及其对应的最终隐藏层向量同时传递到输出投影器和语音标记语言模型(Voice Token LM)。输出投影器是一个单层线性模块,随机初始化用于维度对齐。语音标记语言模型(Voice Token LM)采用预训练的 CosyVoice 2 LM 模块,并以自回归方式生成十五个语音标记,确保高效且无缝的音频合成。这些语音标记由 Token2wav 合成器模块实时处理,生成最终的音频输出。
Token2wav 合成器包括一个预训练的流匹配模型,该模型将标记转换为梅尔频谱图,以及一个预训练的声码器,将梅尔频谱图转换为波形,两者均来源于 CosyVoice 2。MinMo 通过额外的隐藏嵌入实现端到端的完整训练,这些嵌入有助于根据用户指令控制语音风格,例如情感、方言和语速等。语音生成的详细信息详见 3.2 节。
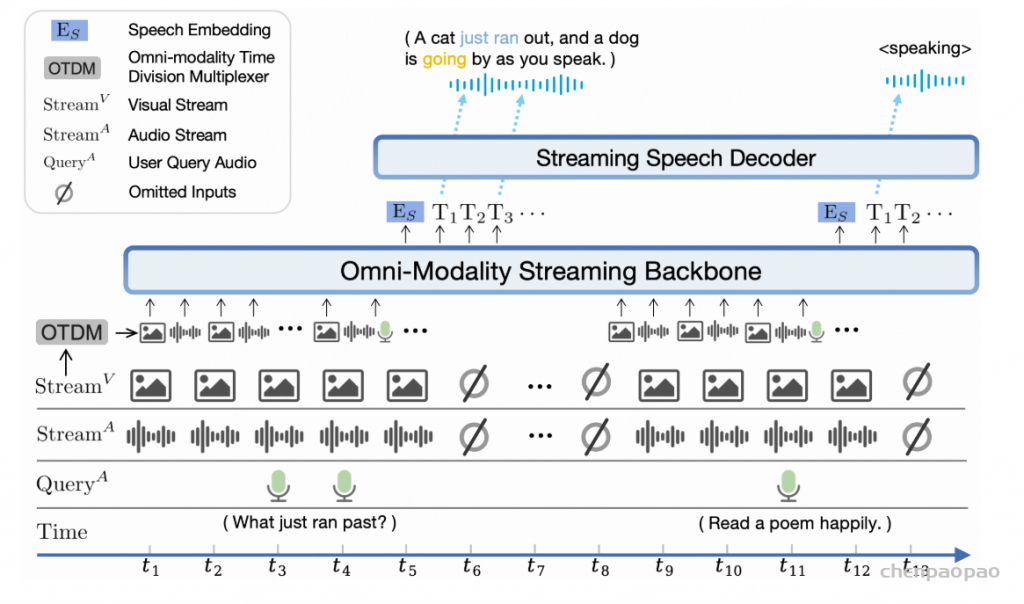
全双工预测器模块由一个单层 Transformer 和一个线性 softmax 输出层组成,两者均为随机初始化。该模块实时预测是否响应用户指令或暂时停止当前系统播报,以处理来自用户的进一步音频输入。一旦全双工预测器决定系统响应是合适的,MinMo 会生成文本输出并同步以逐标记方式生成音频标记。
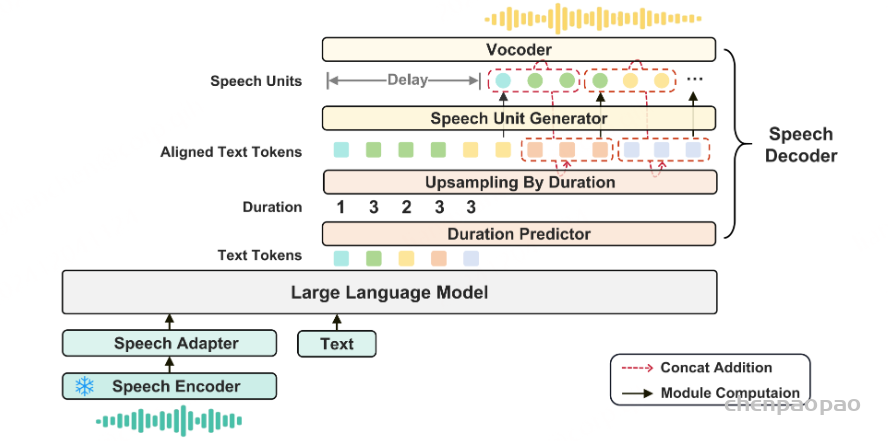
Streaming Voice Decoder
语音解码器包括三个组件:输出投影器、语音标记语言模型(Voice Token LM)和流式标记到波形(Token2wav)合成器。
输出投影器对齐 LLM 的维度与语音解码器的维度。LLM 的隐藏状态包含丰富的上下文信息,但语义上可能不够明确;而采样得到的文本标记更加精确,与生成的文本一致。同时,当前用户输入的隐藏状态包含显式的指令信息。在每轮对话中,用户输入的嵌入与 LLM 最后一层输出的隐藏状态将沿特征维度拼接,形成查询嵌入。查询嵌入与五个采样文本标记的嵌入,以及 LLM 最后一层输出的隐藏状态,将沿序列维度拼接并输入到投影器中。投影器的输出被称为语义向量,这些向量代表了丰富且准确的语义信息。
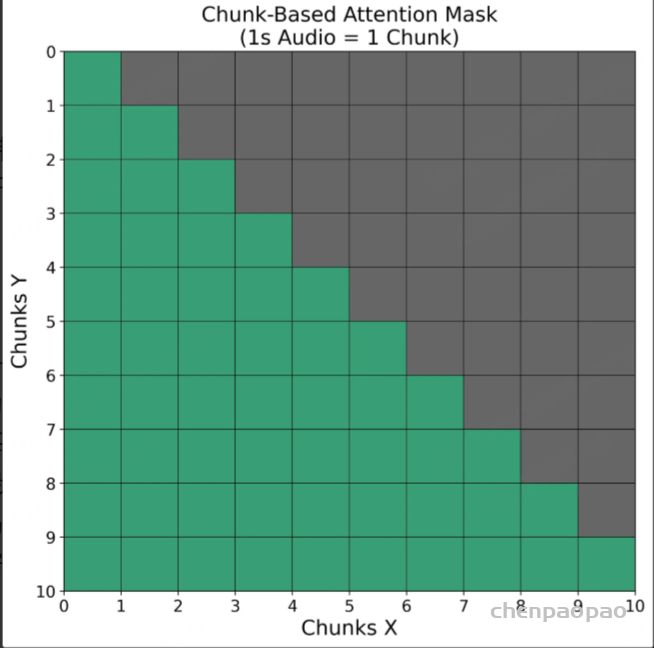
在输出投影器之后,使用语音标记语言模型(Voice Token LM)以自回归方式生成语音标记。该语言模型在交替的文本和语音标记序列上运行。具体而言,我们以 5:15 的固定比例混合语义向量和语音标记,即每五个语义向量后跟随十五个语音标记。
在训练过程中,采用教师强制策略,并引入一个特殊标记,用于指示下一个语义向量应被连接。当 LLM 的文本响应完成且语义向量耗尽时,我们插入一个“语音轮次”(turn of speech)标记,提示语音标记语言模型接下来的标记应完全为语音标记。当生成“语音结束”(end of speech)标记时,语音合成过程结束。
为了从语音令牌重建波形,我们使用现成的流式 token2wav 合成器。token2wav 合成器包含一个数据块感知流匹配模型和一个 mel 到 wave 声码器,能够以 15 个令牌为块合成波形。
语音解码器的理论延迟可以按以下方式计算:
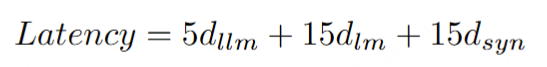
其中 dllm 表示 LLM 生成一个文本令牌的计算时间, dlm 表示 LM 生成一个语音令牌的时间, dsyn 表示 token2wav 合成器生成每个语音令牌对应的波形的时间。
Tasks and Training Data
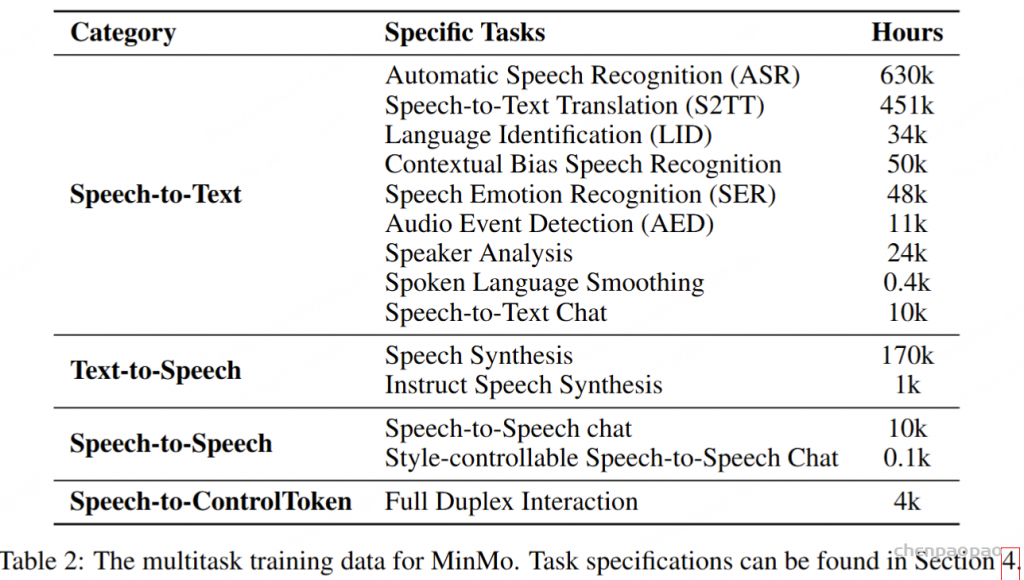
MinMo 的训练任务包括四类,包括 Speech-to-Text、Text-to-Speech、Speech-to-Speech 和 Speech-to-ControlToken 任务。表 2 列出了每个类别中的具体任务及其相应的数据量表。
Speech-to-Text 任务。此类别包含大约 120 万小时的语音-文本配对数据,包括自动语音识别 (ASR)、语音到文本翻译 (S2TT)、语言识别 (LID)、上下文偏差语音识别、语音情感识别 (SER)、音频事件检测 (AED)、说话人分析、口语平滑等任务。这些任务的训练数据以 ChatML 格式组织,如以下示例所示:

Text-to-Speech tasks。该类别的数据主要由基础语音合成数据组成,与训练 CosyVoice 2 的数据相同。它包括 170000 小时的文本语音配对数据,并支持四种语言:中文、英文、韩文和日文。此外,还有大约 1000 小时的音频生成数据由指令控制。这些说明扩展为包括由 Qwen-Max 生成的自然语言描述,利用人类标记的属性,例如情感、语速、方言和角色扮演。

Speech-to-Speech 任务。 Speech-to-Speech 数据主要通过模拟获取,包括大约 10000 小时的多轮对话语音和 100 小时的风格可控多轮对话语音。模拟 Speech-to-Speech 聊天数据的方法如下:
对于主要来源于 Alpaca 和 ShareGPT3 的文本聊天数据,我们利用 CosyVoice 的零样本上下文生成方法 将用户文本转换为用户语音。我们使用来自选定说话人的 2 小时数据对 CosyVoice 的基本模型进行微调,为目标说话人创建一个语音合成模型,称为 CosyVoice-SFT。该模型合成了助手的语音(即系统语音)。使用zero-shot上下文生成进行用户语音合成的优势在于它能够确保生成的用户语音的多样性,从而增强 MinMo 的泛化性。
为了解决合成音频和真实音频之间的差异,我们从 ASR 数据中选择合适的真实语音作为用户语音查询,并使用相应的文本作为 Qwen-Max 的输入生成响应文本,然后使用 CosyVoice-SFT 模型将其合成为辅助语音。这种方法进一步增强了模型对真实用户音频输入的鲁棒性。
为了生成涵盖不同说话风格的对话语音,我们最初使用 Qwen-Max 来创建丰富的风格可控、多轮次文本对话集合。用户查询通过 Cosyvoice 的 zero-shot generation 转换为语音。随后,我们使用 Cosyvoice 2 来生成助手的富有表现力的语音。具体来说,我们将助手的响应内容和指导提示输入到 Cosyvoice 2 中,以合成特定风格的语音。此外,使用小型、多样化和初步录制的语音语料库作为提示语音,通过零镜头生成合成表达性响应语音。前一种方法增强了模拟语音的多样性,而后者更有效地构建了各种风格的表现力。
Speech-to-ControlToken 任务。Speech-to-ControlToken 数据主要由两部分组成。第一部分是从现有的真实语音交互数据中提取的,而第二部分是使用文本对话数据进行模拟的。具体来说,现有的真实语音交互数据包括 Alimeeting 、Fisher 等资源,以及我们内部的语音交互数据,总共大约 3000 小时。模拟数据主要包括开源 MOSS 数据集 和通过合成我们内部文本对话数据的口语对话,产生了大约 1000 小时的语音聊天数据。当使用这些语音交互数据构建双工训练数据时,我们应用启发式规则在样本上自动注释双工标签,如下所示:
- 对于助手的轮流,将用户轮到的终点作为助手轮次的起点。
- 对于用户的轮次,将助手轮次结束后的时间间隔 T 作为用户轮次的起点,其中 T∼𝒩(0.6,0.42) 。
- 对于用户的 Back-Channel,当用户(以对话中的一个说话者为用户)无法打断另一个说话者时,我们从语音交互数据中选择实例,并将其视为用户 Back-channel 的训练样本。
模型训练
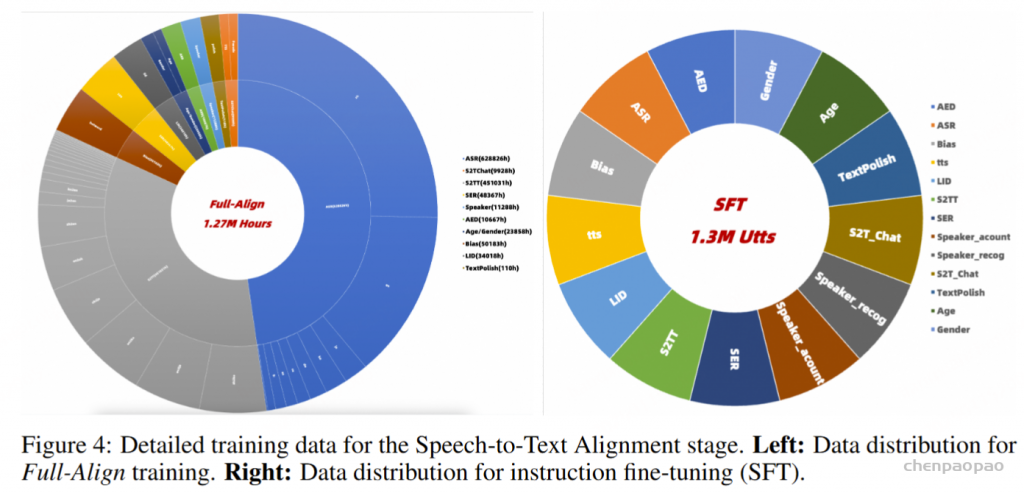
MinMo 通过四个对齐阶段逐步训练:(1) 语音到文本对齐,(2) 文本到语音对齐,(3) 语音到语音对齐,以及 (4) 双工交互对齐。通过四个对齐阶段,MinMo 获得了端到端的音频理解和生成能力,同时保留了主干文本LLM,实现了低延迟并为用户提供了无缝的语音聊天体验,类似于 GPT-4o。这四个阶段详细说明如下。
语音到文本对齐: Pre-align > Full-Align > SFT[LoRA]
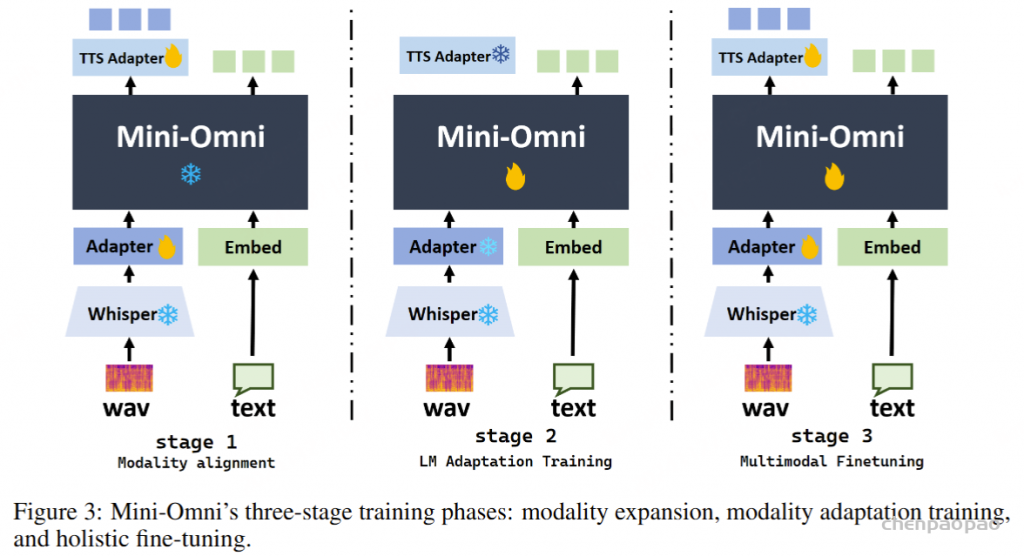
第一阶段使用表 2 所示的语音转文本数据,将音频模态的输入潜在空间与预训练文本LLM。此阶段包括对图 3 中的输入投影和语音编码器的逐步更新,以及使用 LoRA 更新文本 LLM。考虑到语音编码器和LLM (Qwen2.5-7B) 是预先训练的,而输入投影的参数是随机初始化的,我们使用表 2 所示的语音转文本数据子集执行预对齐训练 (Pre-align),仅更新输入投影器。这个 Pre-align 阶段有效地防止了随机初始化的参数在初始训练阶段对预训练的 Voice Encoder 产生大的梯度影响。在预对齐之后,我们使用完整的语音转文本数据来训练输入投影器和语音编码器,同时保持 LLM 参数冻结,这个过程称为完全对齐。在 Full-Align 之后,使用涵盖各种任务的大约 130 万个样本进行指令微调 (SFT)。在此阶段,LLM 使用 LoRA 进行更新,从而增强模型遵循指令的能力。Full-Align 和 SFT 阶段中使用的特定数据比例如图 4 所示。Pre-Align 阶段使用大约 1/10 的 Full-Align 数据。
文本到语音对齐
第二阶段使用文本转语音数据将文本LLM音频模态的输出潜在空间对齐。此阶段首先训练 Output Projector,然后联合训练 Output Projector 和 Voice Token LM,同时保持其他 MinMo 参数冻结。除了基本的文本转语音功能外,我们还利用端到端框架使 MinMo 能够在语音交互中遵循用户指示,从而提供更富有表现力和娱乐性的音频响应。例如,用户可以通过指令控制音频输出的情感、语速、方言口音或说话人风格。构建了大约 1000 小时的 Instruct 语音合成数据,格式如表 3 所示。
语音到语音对齐。
第三阶段使用大约 10,000 小时的配对音频数据继续训练 MinMo。与文本到语音对齐阶段一致,我们继续仅更新 Output Projector 和语音令牌 LM。语音到语音对齐的训练数据不仅包括一般的语音到语音对话,还包括具有各种设置的音频生成指令,例如采用特定的方言、语速和口语对话的情感。我们发现,即使不更新 LLM,仅通过利用与小规模指令数据集对齐的嵌入(150 小时),大型模型仍然可以学习相当有效的音频生成控制能力。
双工交互对齐。
在完成前三个训练阶段后,MinMo 获得了音频理解、音频生成和半双工语音对话的能力。在此基础上,我们进一步添加了一个全双工模块,该模块经过 4000 小时的长篇人际口语对话训练。Full Duplex Predictor 模块在此阶段专门进行训练。Full Duplex Predictor 采用 全双工预测器将LLM的隐藏嵌入作为输入,用于预测模型是否需要生成响应。全双工预测器利用LLM固有的语义理解能力来判断:1)模型是否应该回应当前用户查询,2)模型是否应该停止正在进行的语音输出以聆听用户查询并提供适当的响应。来预测模型是否需要生成响应。
Experiments
根据多个基准评估 MinMo:
语音识别和翻译
在普通话、英语、日语、韩语和其他六种语言的公共测试集上评估了 MinMo 的语音到文本转录功能。
对于普通话 (ZH)、日语 (JA)、韩语 (KO) 和粤语 (YUE),我们采用字符错误率 (CER) 来评估转录性能。对于英语 (EN)、德语 (DE)、法语 (FR)、俄语 (RU)、西班牙语 (ES) 和意大利语 (IT),单词错误率 (WER) 用作评估指标。
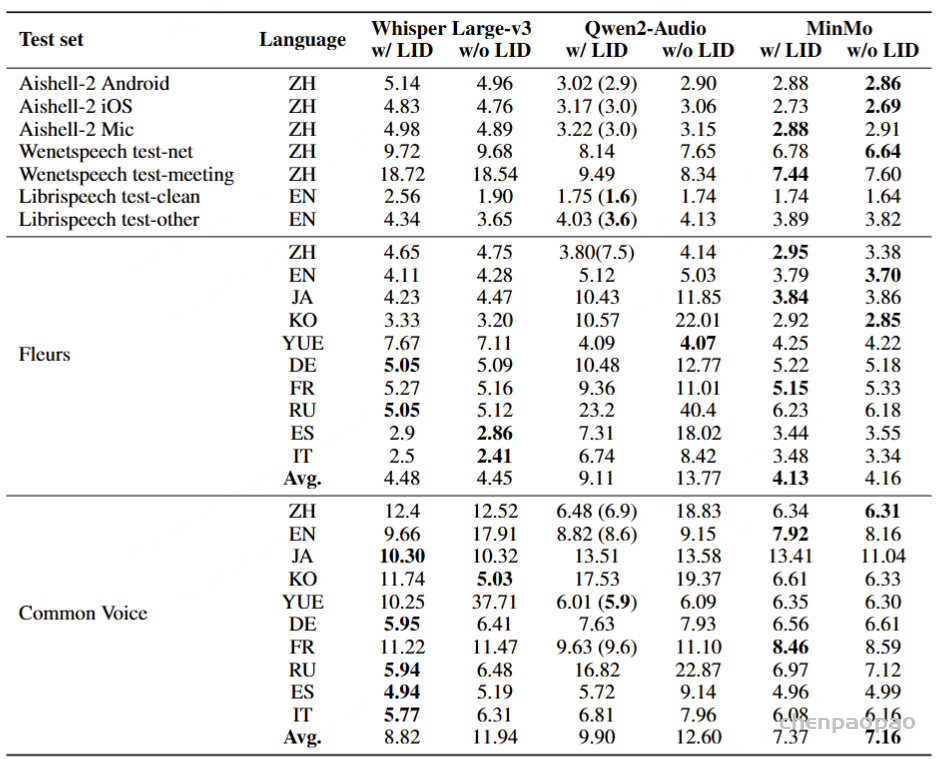
与 Whisper Large v3 和 Qwen2-Audio相比,MinMo 在各种语言的大多数测试集上都实现了卓越的 ASR 性能。
在提示符显示或不带有 LID【语言ID】 信息的 Common Voice 上进行测试时,Whisper Large v3 和 Qwen2-Audio 的平均错误率存在显著差距,这表明这两个模型强烈依赖 LID 信息。相比之下,无论是否存在语言识别,MinMo 都表现出稳健且一致的 ASR 性能。
多语言语音翻译
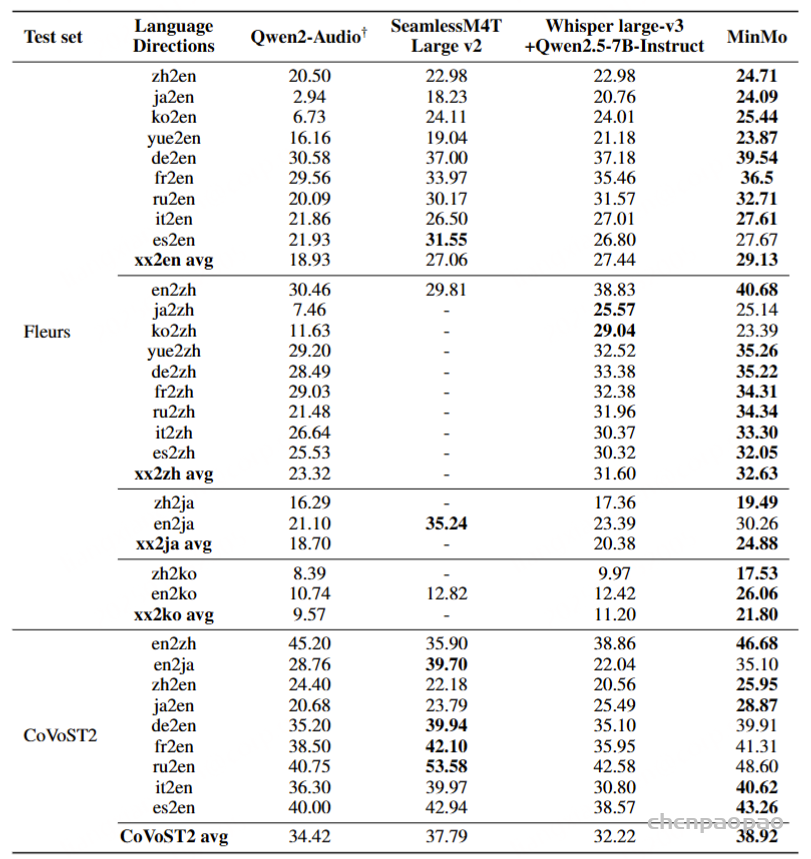
在 Fleurs 和 CoVoST2 测试集上评估了语音到文本的翻译能力。
与其他端到端基线相比,MinMo 在中 ↔ 英和日 ↔ 英翻译上实现了 SOTA 性能,在其他语言对上实现了顶级性能。我们将这种强劲的性能归功于广泛的语音翻译训练数据(表 2 中 451K 小时的 S2TT 训练数据)和强大的音频编码器。 值得注意的是,尽管我们只用 CoVoST2 集(不包括 Fleurs 集)来增强我们的训练数据,但我们的模型在两个测试集上保持一致的性能,表明具有高鲁棒性。
Language Identification 语言识别
使用 Fleurs 数据集,该数据集涵盖 102 种语言。MinMo 实现了 85.3% 的语言识别准确率,优于表 7 所示的所有先前模型。具体来说,零样本 Whisper-V3 经常将粤语错误地归类为中文,而 MinMo 可以准确地识别粤语。

上下文偏见语音识别
上下文偏见,或称为热词定制,允许用户根据特定的上下文或热词获得定制化的ASR(自动语音识别)结果。MinMo通过集成用于上下文偏见的高级提示增强了ASR功能。我们为对齐和SFT阶段准备了相应的训练数据,通过将热词组织到语音处理指令之前的提示中,从而实现有效的定制。评估包括热词偏见测试和一般偏见测试,如表8所示。
热词偏见测试涉及使用SeACo-Paraformer(Shi et al., 2024)提供的三个数据集,这些数据集包含用于偏见评估的热词。一般偏见测试则使用包含较少热词的数据集,用于评估对无关热词的抗干扰能力。
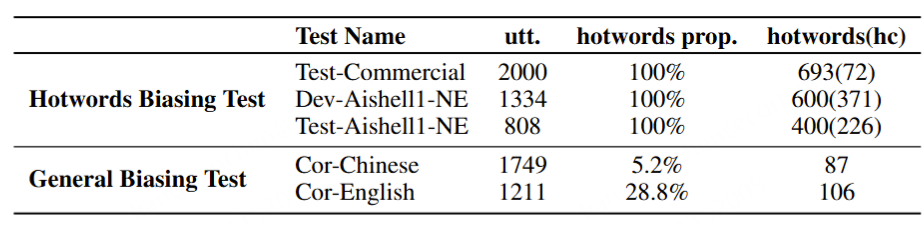
MinMo 在 ASR 准确性(带和不带热词)以及硬质热词的召回率方面优于竞争性基线 SeACo-Paraformer。
Speech Analysis and Understanding
Speech Emotion Recognition
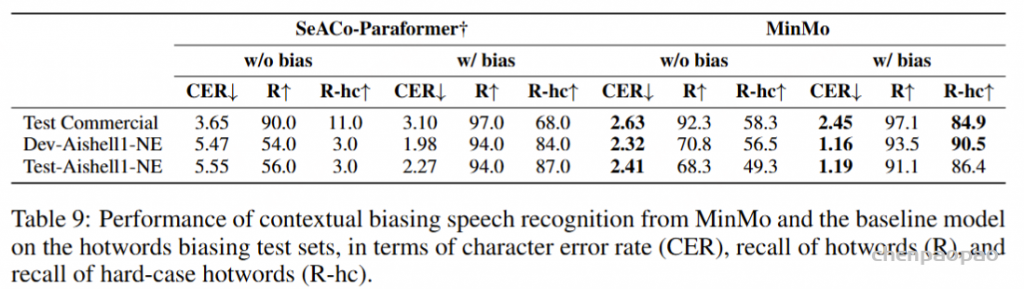
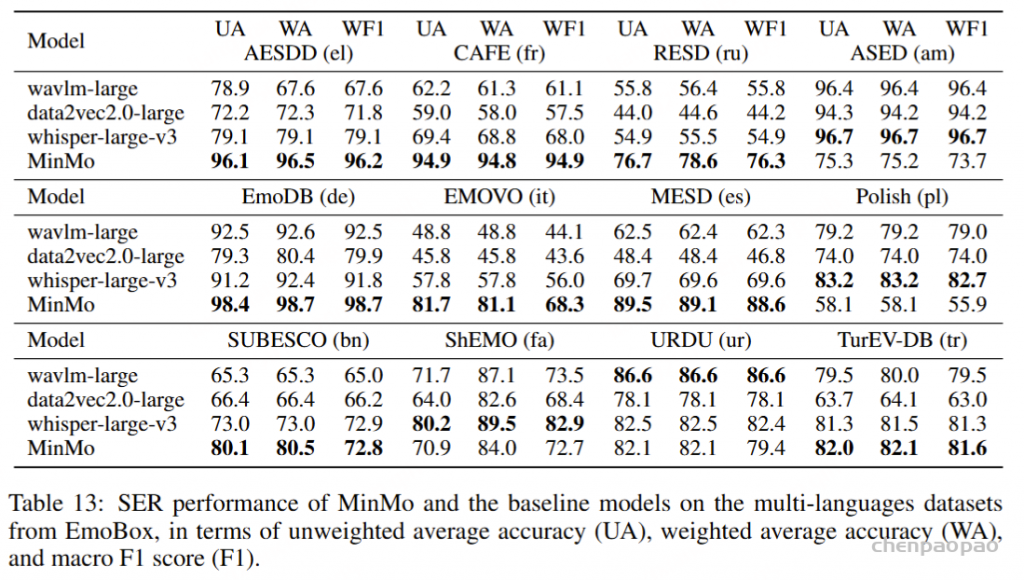
使用来自 EmoBox 的七个广泛使用的情绪识别数据集评估了 MinMo 的语音情感识别 (SER) 能力,包括 CREMA-D (Cao et al., 2014)、MELD (Poria et al., 2019)、IEMOCAP (Busso et al., 2008)、MSP-Podcast (Martinez-Lucas et al., 2020)、CASIA (Zhang & Jia, 2008)、MER2023 (Lian et al., 2023) 和 ESD (周 et al., 2021)。这些数据集包括中英文语言和场景,例如表演、电视剧和日常对话。我们采用未加权平均准确率 (UA)、加权平均准确率 (WA) 和宏观 F1 分数 (F1) 作为评价指标。引用了来自最近的 SER 工具包 EmoBox(马 et al., 2024a)的这些测试集的结果。我们还使用其发布的模型检查点评估了基线音频LLM 模型 SALMONN 和 Qwen-Audio。
MinMo 在该基准测试的所有任务上都优于所有基线模型,包括语言 ID、性别、年龄、情感、发声分类任务,除了在声音问题分类任务上表现优于 Qwen-Audio。
Audio Event Understanding
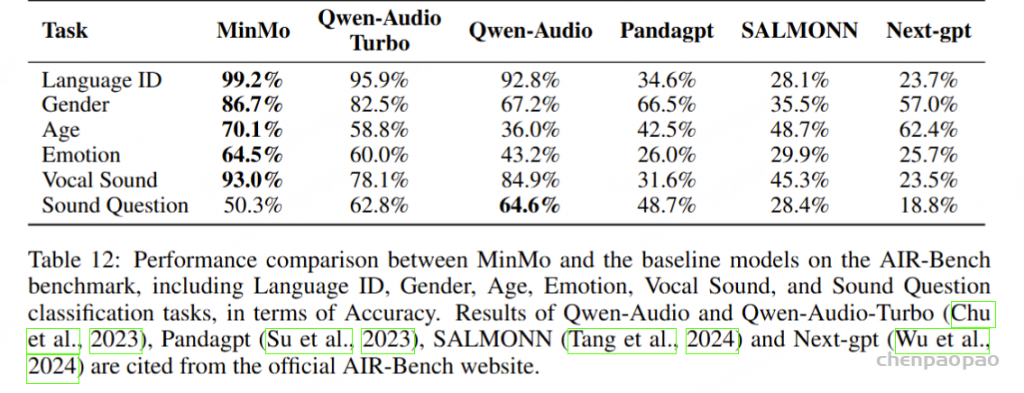
使用 Air-Bench 基准测试,将 MinMo 的语音和音频事件理解能力与其他 Audio-LLM。结果如表 12 所示。在语音声音分类任务 (Vocal Sound) 上,MinMo 超越了所有基线模型。然而,我们发现,在更复杂的声音问答任务中,MinMo 的表现比 Qwen-Audio 差,尽管性能仍然优于其他模型。这可以归因于两个因素:首先,在语音编码器和训练范式中,MinMo 主要是为语音交互而设计的,因此一些声音问题可能会超出其范围;其次,在评估过程中,MinMo 会预测音频中发生的情况,而不是严格选择 Air-Bench 提供的选项,因此 MinMo 生成的一些正确或相似的正确响应与后处理脚本的错误选择保持一致。
Speaker Analysis
说话人分析涉及几项对于理解音频数据并与之交互至关重要的任务,包括性别检测、年龄估计、说话人计数、说话人识别、多说话人识别和目标说话人识别。结果表明,MinMo 在性别检测和年龄估计任务上优于所有基线模型。
Speech-to-Text Enhancement
Spoken Language Smoothing【口语平滑】
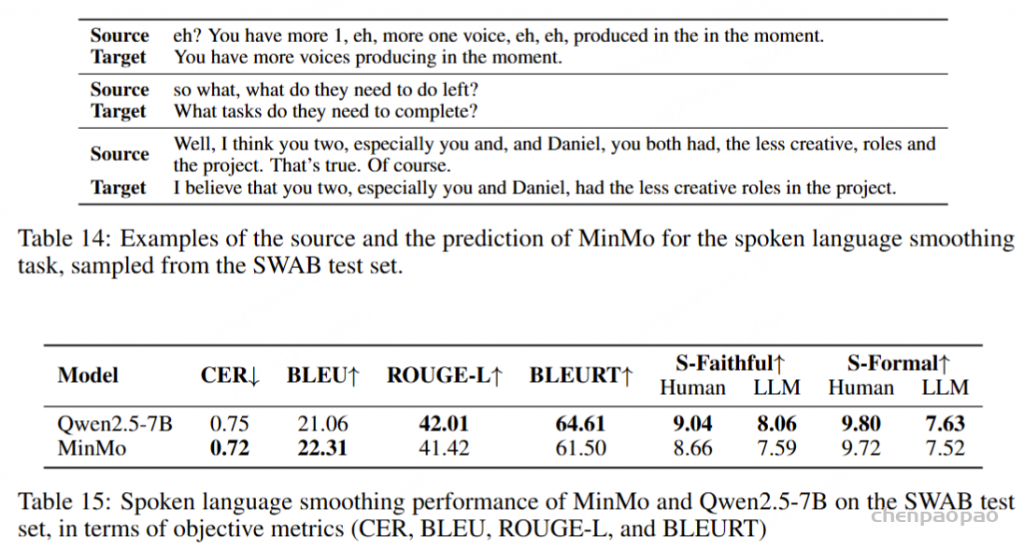
口语语言平滑任务以口语ASR(自动语音识别)转录文本为输入,输出正式风格的书面文本。表14展示了口语语言平滑的一些示例。为该任务,我们通过扩展为ASR转录文本的口语到书面转换而创建的SWAB数据集(Liu et al., 2025),构建了一个多领域数据集用于训练和评估。SWAB数据集源自中文和英文的会议、播客及讲座。
在为原始视频和音频生成ASR转录文本后,大约十位注释人员根据ASR转录文本创建正式风格的书面文本,同时保留原始内容。SWAB的训练集包含20,000段文本,测试集包括100段中文和英文的随机抽样段落。我们对SWAB测试集进行全面微调,并将MinMo与基于Qwen2.5-7B的模型进行比较,结果如表15所示。
在客观指标评估中,我们使用BLEU(Papineni et al., 2002)、ROUGE(Lin, 2004)和BLEURT(Sellam et al., 2020),以人工目标为参考。然而,我们注意到口语语言平滑任务具有显著的主观性和多样性,因此基于词汇匹配的客观指标可能无法充分反映模型性能。因此,我们采用人工和LLM注释来提供信实性(S-Faithful,即对原始内容的信实性)和正式性(S-Formal)的排名评估。自动化LLM评分的提示见附录A.1。
表15显示,我们的模型与Qwen2.5-7B的性能相当,表明MinMo在平滑口语语言方面具有较好的能力。
标点插入和反向文本规范化
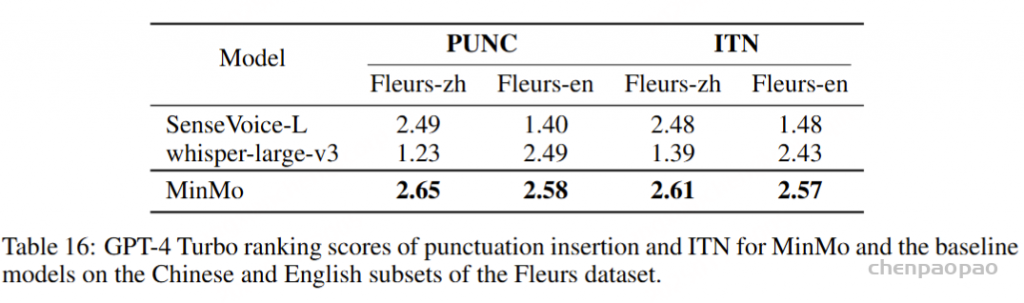
对于标点插入 (PUNC) 和反向文本归一化 (ITN) 任务,我们使用来自 Fleurs 数据集的中文和英文数据。我们将 MinMo 与 SenseVoice-L 和 whisper-large-v3 进行比较,如表 16 所示。鉴于标点符号插入和 ITN 任务的主观性,我们使用 GPT-4 Turbo 对三个结果进行排序进行评估。附录 A.2 中提供了自动评分的任务提示。第一名获得 3 分,第二名获得 2 分,第三名获得 1 分。最终分数是所有分数的平均值。在准备测试数据时,我们使用随机选项洗牌和多轮评分,以减少使用 ChatGPT 进行评估时的不确定性。最终结果表明,MinMo 在标点插入和 ITN 的主观评价中表现更好。
Voice Generation
文本到语音(TTS)
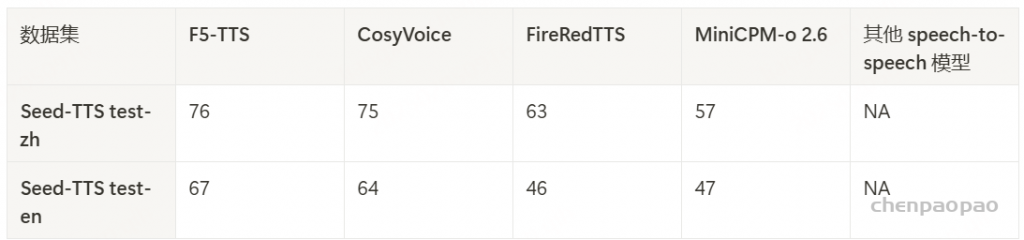
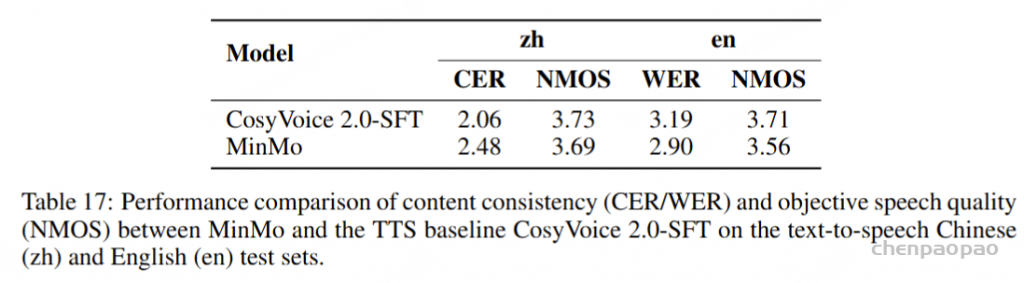
为了评估我们语音解码器的合成准确性,我们将最新的SEED测试集(Anastassiou et al., 2024)转换为ChatLM格式。在该格式中,文本以用户内容的形式呈现,并以“Copy:”命令为前缀,LLM预计会复制该文本。测试集包括2,020个中文案例和1,088个英文案例。对于中文案例,我们使用了Paraformer-zh模型(Gao et al., 2022),而英文案例则使用了Whisper-large V3(Radford et al., 2023)。鉴于LLM存在的指令跟随问题,我们在推理过程中应用了教师强制方案,以最小化输入和输出文本之间的差异。语音解码器的内容一致性通过中文的CER(字符错误率)和英文的WER(词错误率)进行评估。
我们的发现表明,即使在应用了教师强制方案的情况下,只有大约20%的测试案例的输入和输出文本与LLM完全一致。由于不一致的输入和输出可能导致语音解码器的隐藏状态混乱,因此仅包括输入和输出文本一致的测试案例来计算错误率。结果如表17所示。我们观察到,与TTS基线模型CosyVoice 2.0-SFT(Du et al., 2024b)相比,MinMo在中文测试集上表现出稍微较低的内容一致性和语音质量。在英文测试集上,MinMo在内容一致性上表现相似,但NMOS(语音质量评分)稍低。这个下降可以归因于微调的说话人不同的声学特性,这影响了识别模型和NMOS评分器。然而,这种下降不会显著影响人类的理解。因此,主观评估可能更适合语音到语音的语音聊天模型,我们将在未来的工作中进一步探讨这一点。
指令跟随语音生成
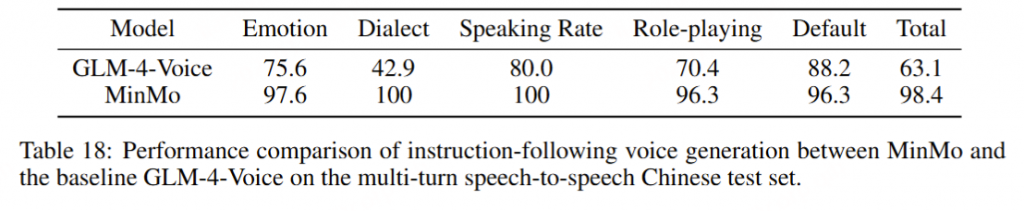
为了评估指令跟随语音生成的性能,我们开发了一个包含30个会话和122个回合的多轮中文语音到语音测试集,涉及12种指令控制类型。这些控制类型包括情感(高兴、悲伤、惊讶、愤怒、恐惧)、方言(粤语、四川话)、语速(快、慢)、角色扮演(机器人、佩佩)以及默认风格。
为了评估指令跟随语音生成的准确性,听众根据指令类型对生成的音频进行分类。如表18所示,MinMo在指令控制准确性方面优于基线模型GLM-4-Voice,特别是在方言和角色扮演方面。
Voice Chat
为了将基础模型的对话功能转移到语音模态,我们为语音转文本 (speech2text) 和语音转语音 (speech2speech) 场景构建了多轮次对话数据。speech2text 数据主要分为两部分。首先,它源自开源多轮次纯文本数据,我们使用零样本文本转语音 (TTS) 技术合成用户轮次。其次,我们使用真实的自动语音识别 (ASR) 训练数据作为聊天查询,从大型模型获取文本响应,从而为 speech2text 生成交互式训练数据。
MinMo 模型在语音转语音 (S2S) 模式下与现有基线相比具有显著优势,实现了新的最先进的 (SOTA) 结果。在语音转文本 (S2T) 模式下,它还在 Llama Question 和 Web Question 数据集上实现了 SOTA 性能。但是,MinMo 的测试结果仍然表明,与 S2T 模式相比,S2S 模式的性能明显下降。我们将其归因于这样一个事实,即测试集中的许多答案都具有丰富的文本结构和专业词汇,这对模型的文本转语音 (TTS) 功能提出了更高的要求。此外,在 S2S 评估中用于获取答案文本换语音的自动语音识别 (ASR) 模型也会在一定程度上影响 S2S 指标。
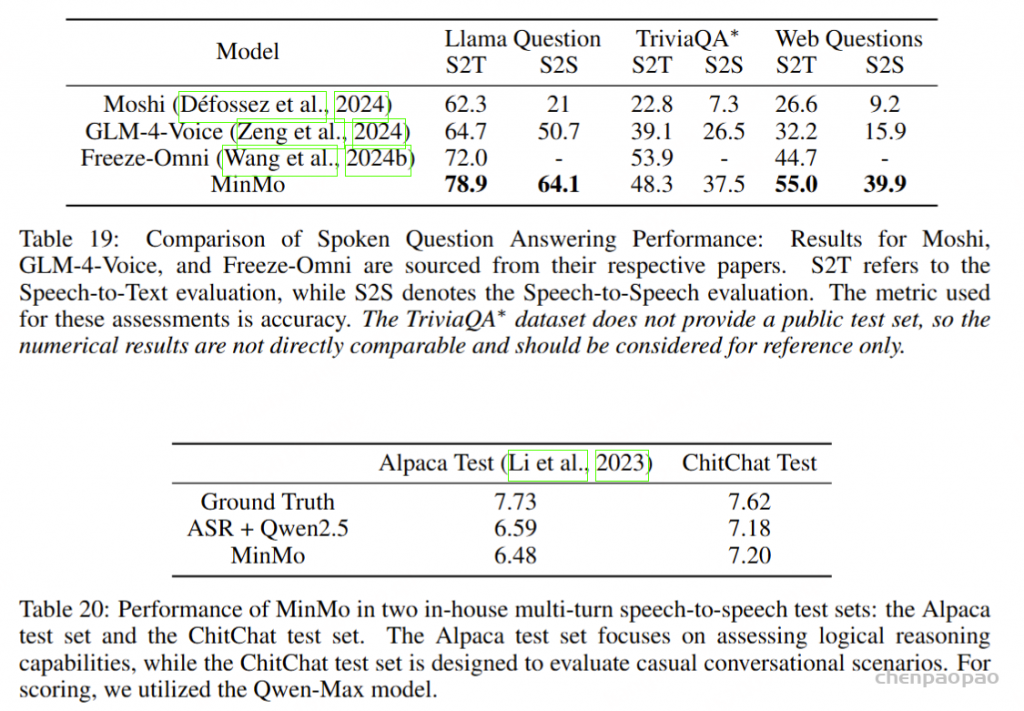
从表 20 中可以观察到,通过将额外的 speech2text 任务数据整合到 MinMo 训练中,我们能够有效地保持基础模型的对话能力。与 ASR 与纯文本基本模型相结合的性能相比,MinMo 的对话能力在很大程度上保持一致。但是,MinMo 的响应分数略低于 Ground Truth 响应的质量。我们认为这种差异可以归因于两个主要原因。首先,多个语音任务的集成和在基础模型上实现 LoRA 训练,在一定程度上削弱了原始大型语言模型 (LLM。该表显示,与 ChitChat 测试集相比,MinMo 在 Alpaca 测试集上表现出更大的性能变化。其次,MinMo 的音频理解能力还有进一步改进的空间,并且仍有可能降低 ASR 任务中的字符错误率 (CER)。
Full Duplex Spoken Dialogue
为了评估 MinMo 在全双工语音交互中的能力,我们构建了三个测试集:中文 Alimeeting 数据集、英文 Fisher 数据集和一个模拟测试集,旨在更接近真实的人机对话场景。我们从两个角度评估 MinMo 的全双工能力:预测性能和预测效率。关于预测性能,评估分为三个任务:辅助轮流、用户轮流和用户反向引导。对于轮流任务,我们采用正 F1 分数作为分析指标,并引入了偏移距离 ( K ) 来更好地分析模型的性能。对于用户反向通道任务,我们利用准确性来评估 MinMo 识别反向通道话语的能力。
MinMo 模型在人机对话数据集上表现出值得称道的结果,无论是用户轮流还是助手轮流。当 K=10 时,预测性能接近 99%。在实际人机对话的测试集中,与人机对话测试集相比,MinMo 模型在辅助轮流上的表现表现出一定程度的下降。我们认为这主要是由于真实人类对话中背景噪音、语速、停顿和其他因素的高度可变性,这可能导致模型在助理轮流任务中出现一定程度的误判。但是,对于人与人对话中的用户轮流预测,MinMo 模型仍然保持了高水平的灵敏度和预测性能,确保在用户说话时系统及时停止说话,从而避免与用户重叠语音。这种敏感性和对用户语音的尊重也解释了为什么 MinMo 模型对用户反向通道评论保持 70%-80% 的预测准确性,如表所示。这与 user turn-taking model 的调优是一致的,表明两者之间存在一定的权衡。
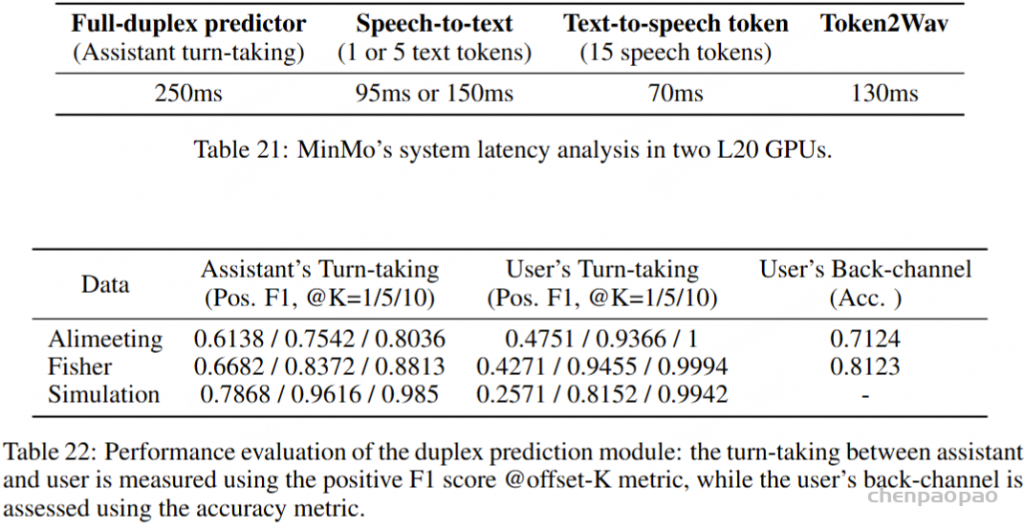

为了对 MinMo 双工模式进行效率分析,我们还分别对人机对话和人机对话测试集进行了测试。如表 23 所示,MinMo 在用户轮流中的平均响应延迟为 250ms。在人机测试集中观察到最快的响应速度,为 88.8 毫秒,而最具挑战性的 Alimeeting 测试集显示延迟为 448.8 毫秒。在辅助轮流方面,MinMo 的平均响应延迟在 660ms 左右,与用户轮流预测所需的响应时间相比,这要长。我们将其归因于以下事实:用户轮流涉及用户语音的开始部分,而助手轮流涉及用户轮到即将结束的部分。因此,助理轮流的上下文语义信息更加全面,从而缩短了决策所需的时间滞后。
Full Duplex System Latency
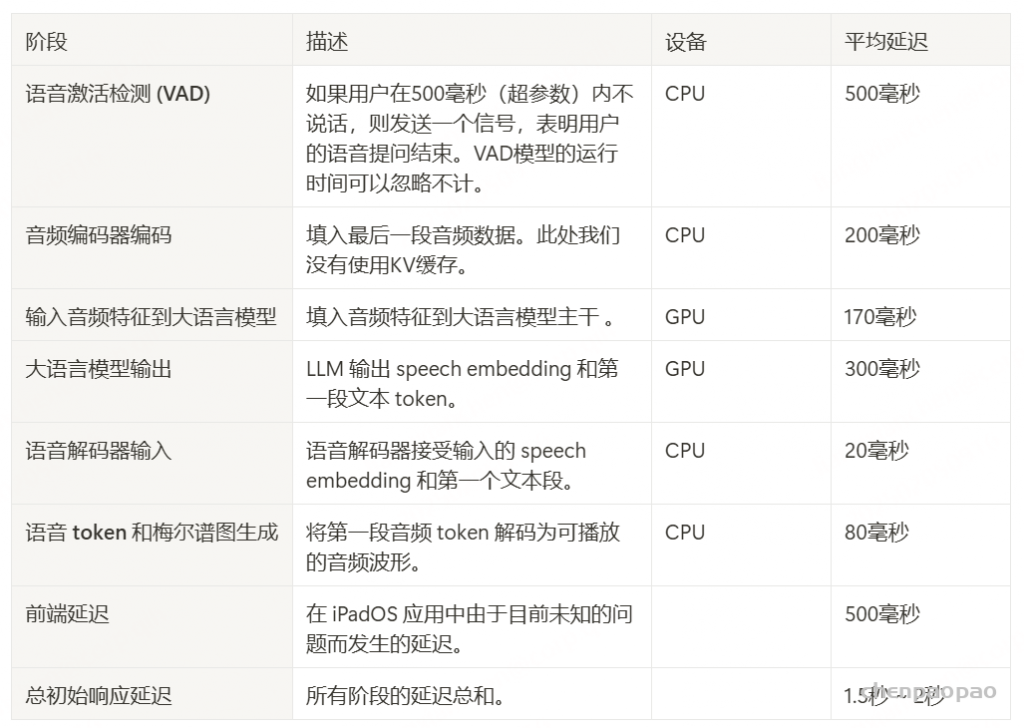
MinMo 的双工交互由四个模块组成:全双工预测器,负责双工控制,语音转文本模块(语音编码器+输入投影仪+LLM)、文本转语音标记模块(输出投影仪+语音标记 LM)和 Token2Wav 模块。表 21 显示了每个模块的延迟。以 Assistant Turn-taking 为例,当用户的实际语音结束时,双工模型通常需要 250 ms 的延迟进行评估。在 Speech-to-Text 过程中,对前 5 个文本标记的预测大约需要 150 毫秒。预测最初的 15 个语音令牌大约需要 70 毫秒,从语音令牌转换到第一个音频数据包需要额外的 130 毫秒。因此,在开发基于 MinMo 的全双工语音对话系统时,助理轮流的标准体验延迟约为 250 + 150 + 70 + 130 = 600 毫秒。上述数值估计值是在使用 L20 GPU 和 BF16 模型格式进行测试期间得出的。
总结/局限性
MinMo 在超过 140 万小时语音的广泛数据集上进行了训练,展示了各种基准(包括口语对话、多语言语音识别和情感识别)的最新性能。通过利用多阶段对齐策略,MinMo 巧妙地平衡了音频理解和生成,同时最大限度地减少了基于文本的 LLMs。一项关键创新是 MinMo 用于流式端到端音频生成的新颖对齐方法。通过利用文本模型的隐藏层表示,MinMo 的语音解码器实现了结构简单性和有竞争力的性能以及低延迟。这种方法显著增强了模型的指令遵循能力,能够生成细致入微的语音,准确反映用户指定的情感、方言和说话风格。此外,MinMo 支持全双工交互,以大约 600 毫秒的延迟提供无缝的对话体验。总之,MinMo 代表了语音交互系统领域的重大进步。它不仅解决了序列长度差异和数据不平衡的固有挑战,还为自然和富有表现力的语音交互设定了新标准,为多模态语言模型的未来发展铺平了道路。
MinMo 有一些需要解决的局限性。首先,MinMo 基于预训练的文本大模型,使用对齐方式集成音频理解和音频生成能力;文本大型模型仅参与 LoRA 更新,其遵循各种指令(例如语言和任务遵循)的能力需要改进。需要进一步探索以确定使用更多高质量的文本数据对文本大型模型进行更全面的更新是否可以增强其指令跟踪能力。其次,MinMo 的端到端音频生成存在一些长尾发音错误问题。这个问题部分是由于保留了 LLM,部分原因是端到端建模输出文本中的一些特殊符号无法有效地转换为语音。可以探索数据扩展来解决这些长尾问题。此外,由 MinMo 中的指令控制的音频生成的整体效率需要提高。这部分是由于当前指令数据的整体大小较小,并且仅使用隐藏嵌入进行端到端对齐的限制,这限制了历史信息的传输。最后,虽然 MinMo 实现了基于语义的双工模块,但它仍然需要单独的 AEC 【AEC模块用于消除语音通信中由于麦克风拾取扬声器输出信号而产生的回声。】和 VAD 模块。将来,将探索完全端到端的双工模型。