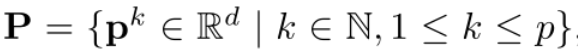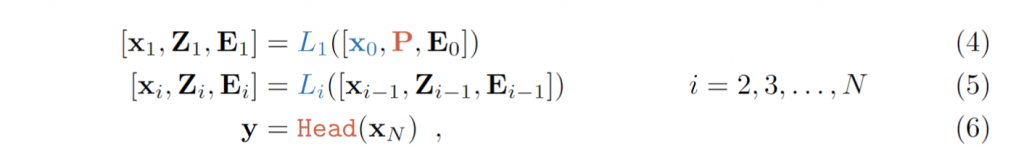最近非常火的ChatGPT和今年年初公布的[1]是一对姐妹模型,是在GPT-4之前发布的预热模型,有时候也被叫做GPT3.5。ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。所以要搞懂ChatGPT,我们必须要先读懂InstructGPT。
指示学习是谷歌Deepmind的Quoc V.Le团队在2021年的一篇名为《Finetuned Language Models Are Zero-Shot Learners》[5]文章中提出的思想。指示学习和提示学习的目的都是去挖掘语言模型本身具备的知识。不同的是Prompt是激发语言模型的补全能力,例如根据上半句生成下半句,或是完形填空等。Instruct是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。我们可以通过下面的例子来理解这两个不同的学习方式:
^Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” *arXiv preprint arXiv:2203.02155* (2022). https://arxiv.org/pdf/2203.02155.pdf
^Wei, Jason, et al. “Finetuned language models are zero-shot learners.” *arXiv preprint arXiv:2109.01652* (2021). https://arxiv.org/pdf/2109.01652.pdf
^Christiano, Paul F., et al. “Deep reinforcement learning from human preferences.” *Advances in neural information processing systems* 30 (2017). https://arxiv.org/pdf/1706.03741.pdf
Language model performance scales as a power-law of model size, dataset size, and the amount of computation.
A language model trained on enough data can solve NLP tasks that it has never encountered. In other words, GPT-3 studies the model as a general solution for many downstream jobs without fine-tuning.
举个机器翻译的例子,要用 GPT-2 做 zero-shot 的机器翻译,只要将输入给模型的文本构造成 translate english to chinese, [englist text], [chinese text] 就好了。比如:translate english to chinese, [machine learning], [机器学习] 。这种做法就是日后鼎鼎大名的 prompt。
在训练数据的收集部分,作者提到他们没有使用 Common Crawl 的公开网页爬取数据,因为这些数据噪声太多,太多无意义的内容。他们是去 Reddit 爬取了大量有意义的文本。作者还指出,在 Reddit 的高质量文本中,很可能已经有类似 zero-shot 构造方式的样本供模型学习。一个机器翻译的例子如下所示。
In a now-deleted post from Aug. 16, Soheil Eid, Tory candidate in the riding of Joliette, wrote in French: ”Mentez mentez, il en restera toujours quelque chose,” which translates as, ”Lie lie and something will always remain.”
二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。简而言之,就是顶点集V可分割为两个互不相交的子集,并且图中每条边依附的两个顶点都分属于这两个互不相交的子集,两个子集内的顶点不相邻。
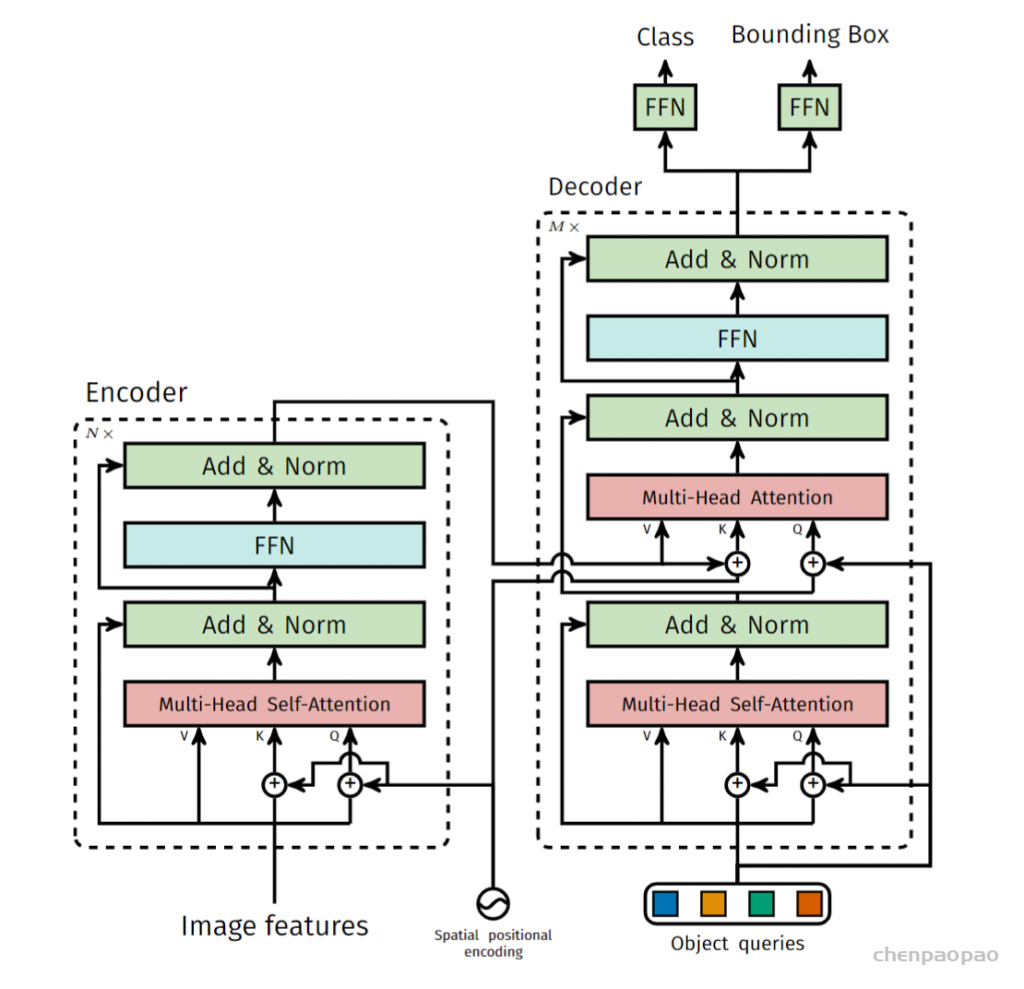
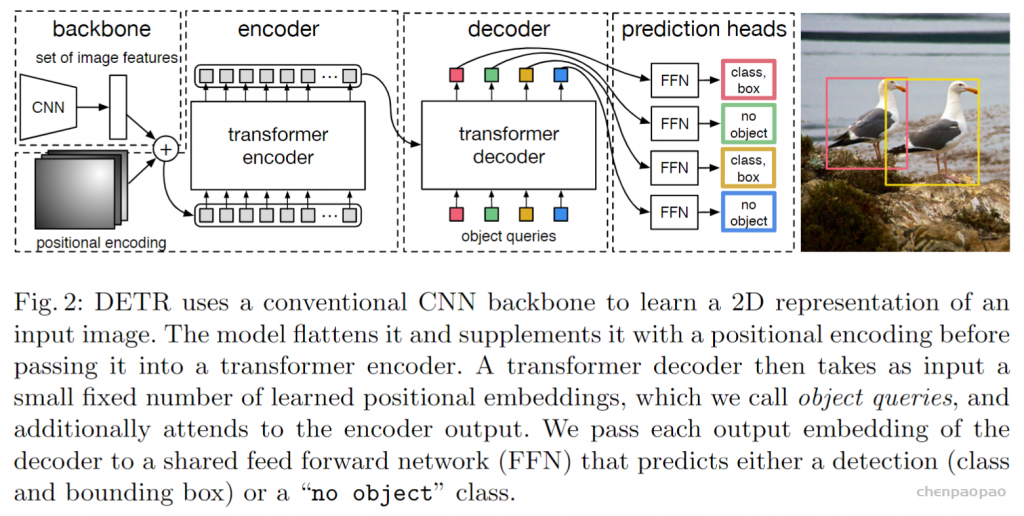
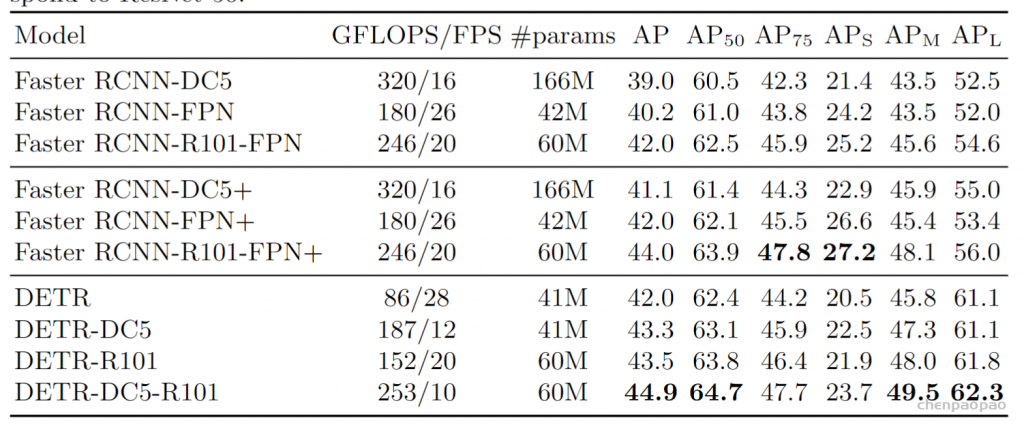
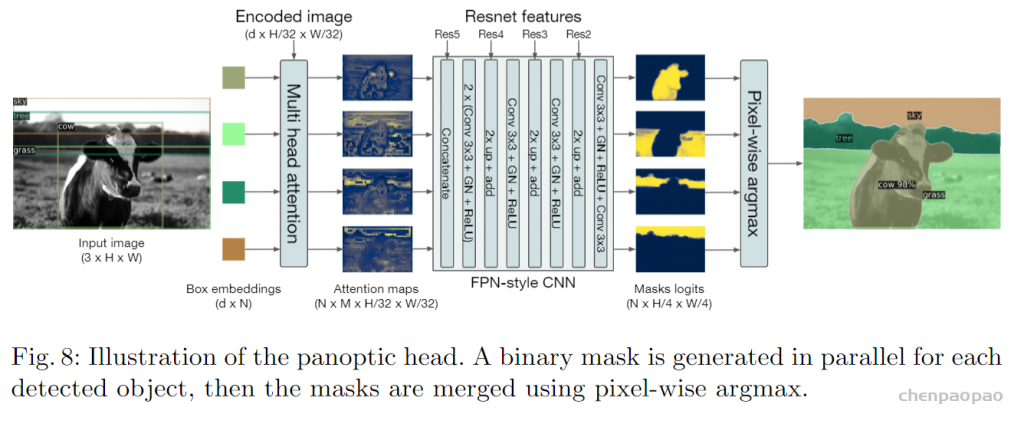
另外scipy包提供的linear sum assignment可以完成这个最优排列。detr论文里:代码也用的linear sum assignment函数来计算对应的匹配关系,只需要提供一个cost matrix矩阵就可以。a,b,c看成100个预测框,x,y,z看成GT框, cost matrix 损失矩阵未必都是正方形,最后丢到这个函数里面得到一个最优匹配。
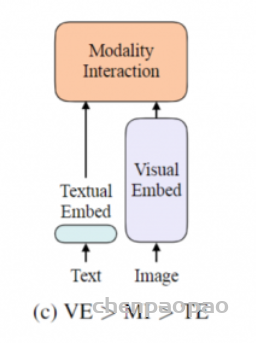
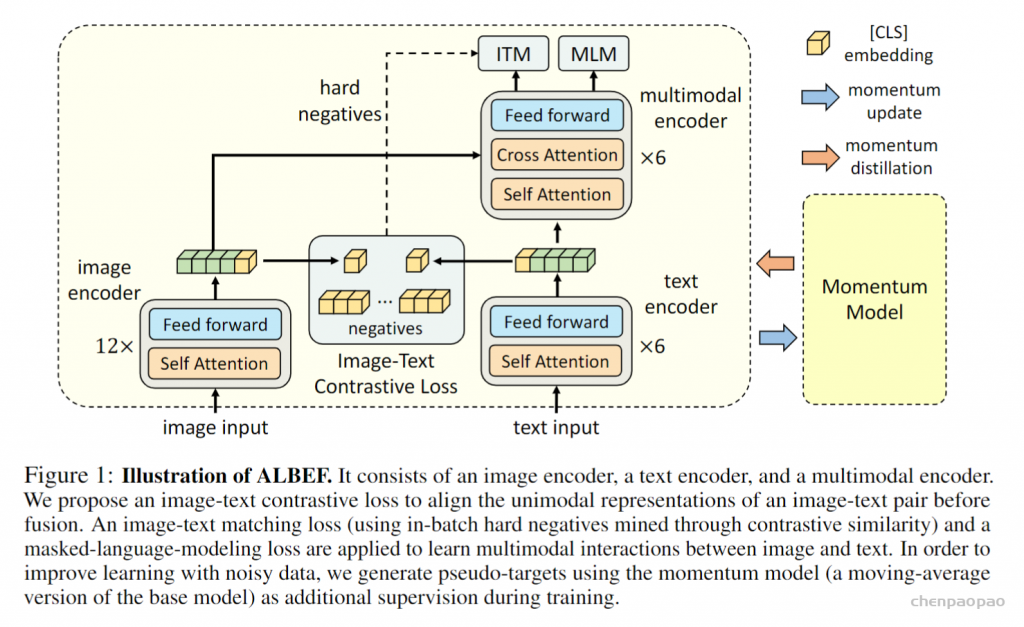
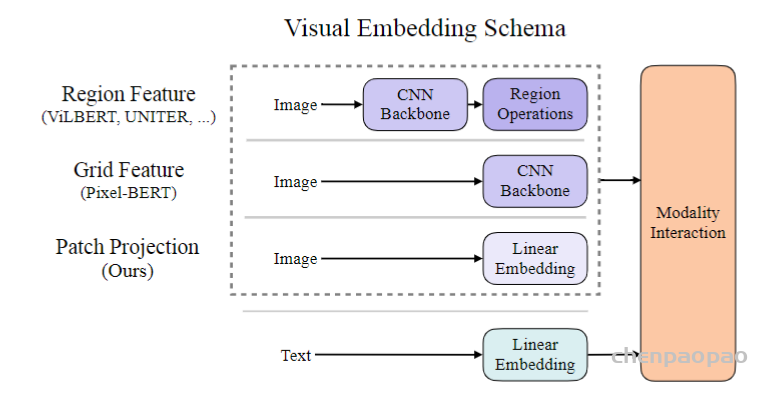
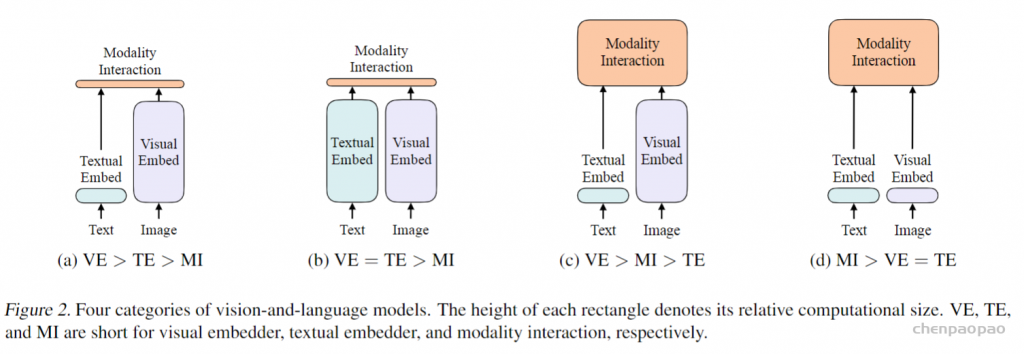
写在前面:最近看了很多多模态的工作,现有的设计有哪些不足?我们又该如何去改进呢?首先来看模型的结构,因为需要处理文本和图片,所以模型开始需要有两个分支,分别抽取图像和文本特征。但是在多模态领域,视觉特征的重要性远远大于文本特征,所以要使用更强大的vision Embed,比如vit,同时对于多模态任务,多模态之间的融合也是十分重要的,也要保证模态融合的模型也要尽可能的大,因此网络应该跟(c)相近。模型确定了,接下来如何去训练呢?我们知道CLIP模型使用了一个对比学习的loss:ITCloss,这个效果很好,所以可以使用。另外常见的两个loss: image text matching(ITM),另一个是masked language modeling(MLM) 也可以继续使用。再回到ALBEF论文,其实它就是按照上述思路进行的设计。
在训练过程中,训练基础模型,使其预测与动量模型的预测相匹配。具体来说,对于ITC,作者首先使用动量单模态编码器的特征计算图像-文本相似性,这个可以认为是一个softmax score,不再是一个 one hot向量。这样在模型训练的时候,我们希望在训练原始model的时候,不只是让预测跟目标值one hot尽可能接近,也希望能够和动量模型的输出保持一致,这样就能达到一个比较好的折中点,很多信息从one hot label来学习,但是当one hot label是错误的或者是有噪声的时候,我们希望这个稳定的动量模型提供一些改进。
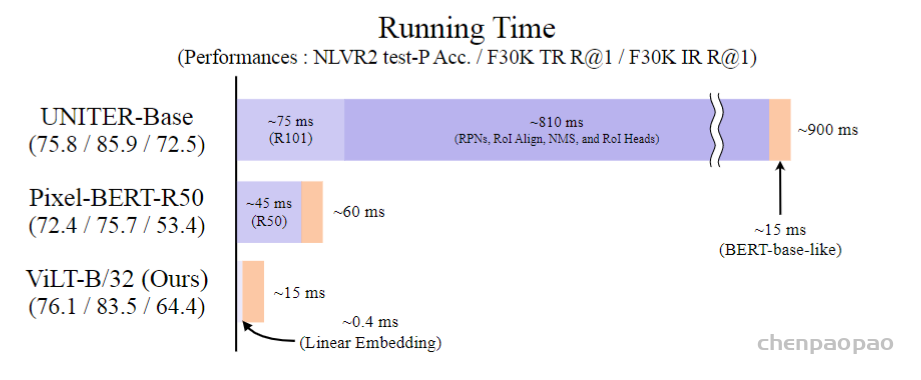
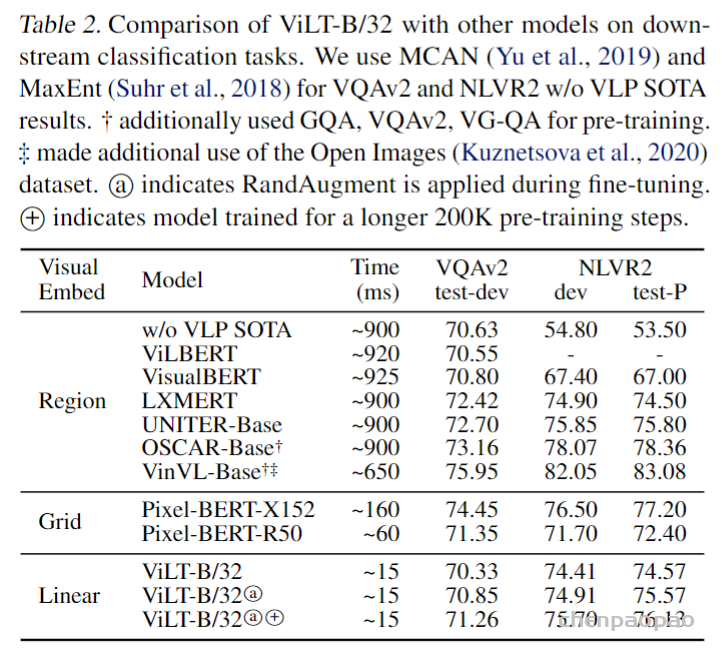
Vision and Language Pre-training(VLP)已经已经在视觉语言的多模态下游任务中发展的很好。然而,当前VLP的工作主要集中在图像特征抽取上,一般来讲,图像特征抽取的越好,下游任务中的表现就越好。但是,现在主要有两个问题,一是效率太低,速度太慢,抽取图像特征花费大量时间,比多模态融合都多。我们应该花费更多时间在融合上。第二个是,你用一个预训练好的模型去抽取特征,表达能力受限。目标检测数据集不够大,规模不够大。如果模型不是端到端学习,只是从预训练模型抽取特征,大概率来说不是最优解。
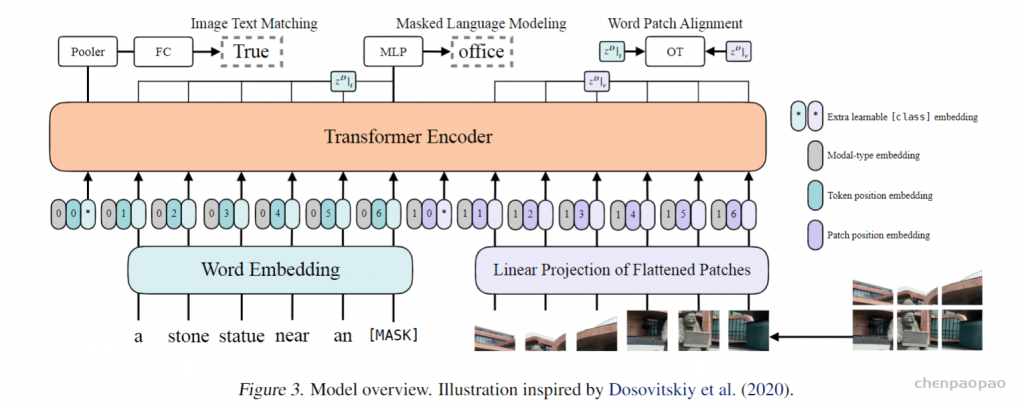
Masked Language Modeling:MLM的目标是通过文本的上下文信息去预测masked的文本tokens。随机以0.15的概率mask掉tokens,然后文本输出接两层MLP与车mask掉的tokens。
Whole Word Masking:另外ViLT还使用了whole word masking技巧。whole word masking是将连续的子词tokens进行mask的技巧,避免了只通过单词上下文进行预测。比如将“giraffe”词tokenized成3个部分[“gi”, “##raf”, “##fe”],可以mask成[“gi”, “[MASK]”, “##fe”],模型会通过mask的上下文信息[“gi”,“##fe”]来预测mask的“##raf”,就会导致不利用图像信息。
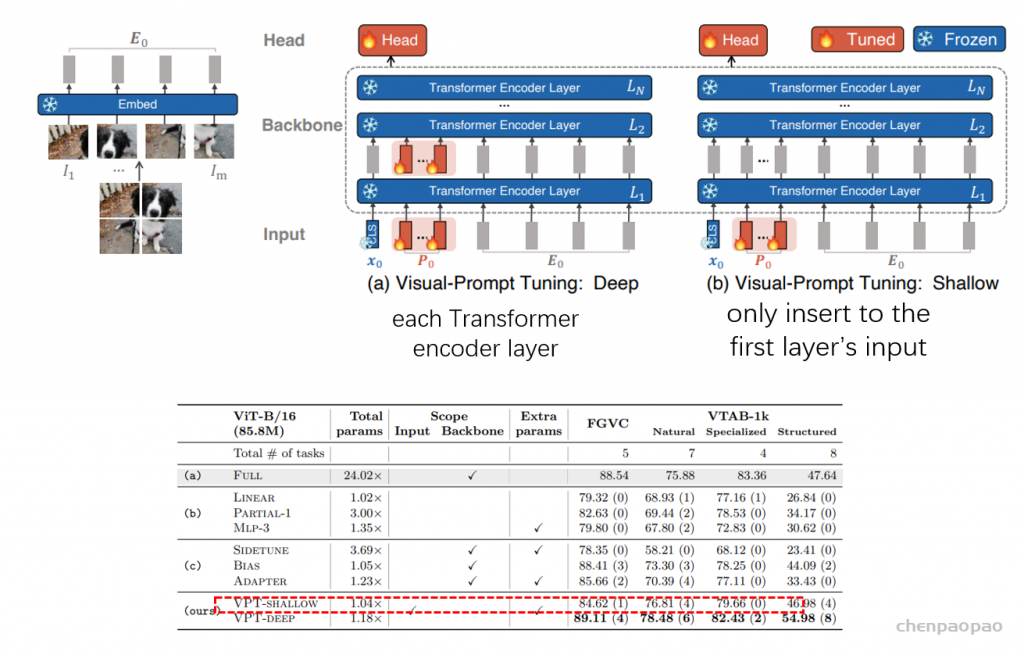
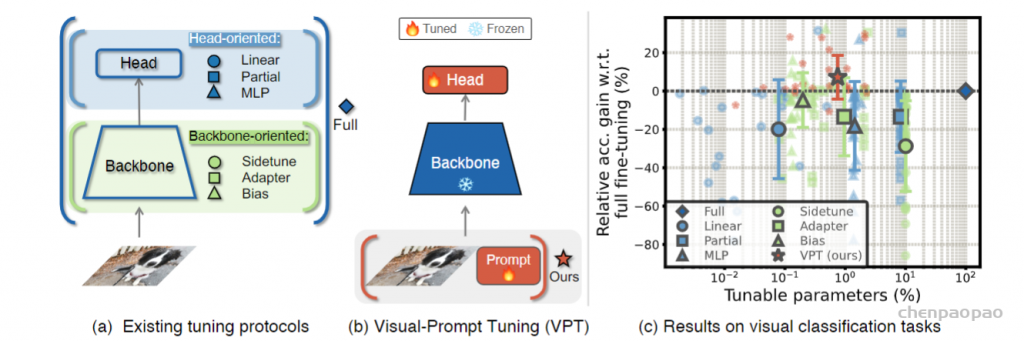
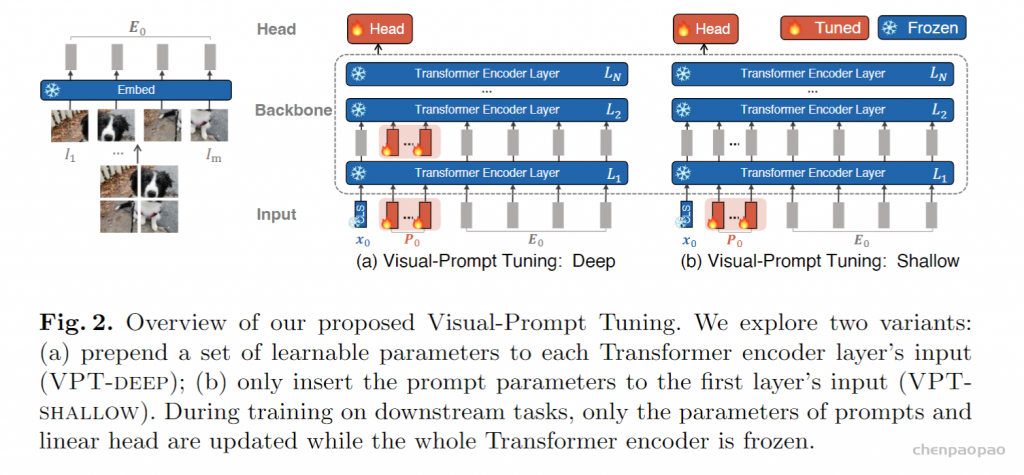
Visual-Prompt Tuning (VPT) vs . other transfer learning methods. (a) Current transfer learning protocols are grouped based on the tuning scope: Full fine-tuning, Head-oriented, and Backbone-oriented approaches. (b) VPT instead adds extra pa- rameters in the input space. (c) Performance of different methods on a wide range of downstream classification tasks adapting a pre-trained ViT-B backbone, with mean and standard deviation annotated. VPT outperforms Full fine-tuning 20 out of 24 cases while using less than 1% of all model parameters























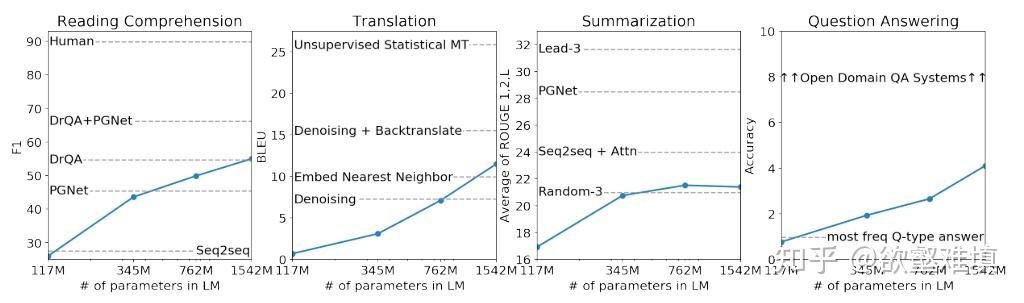



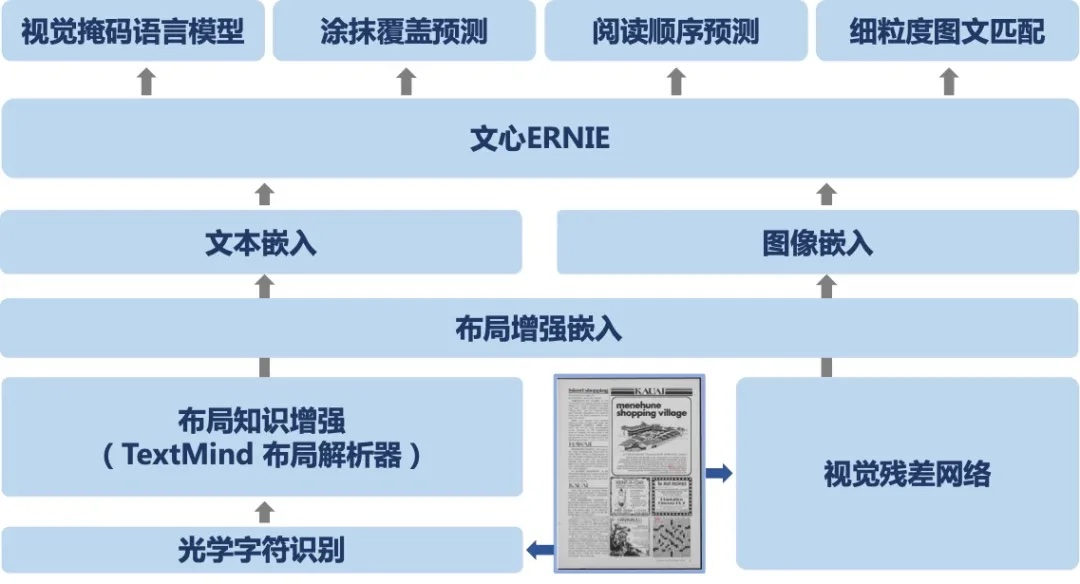
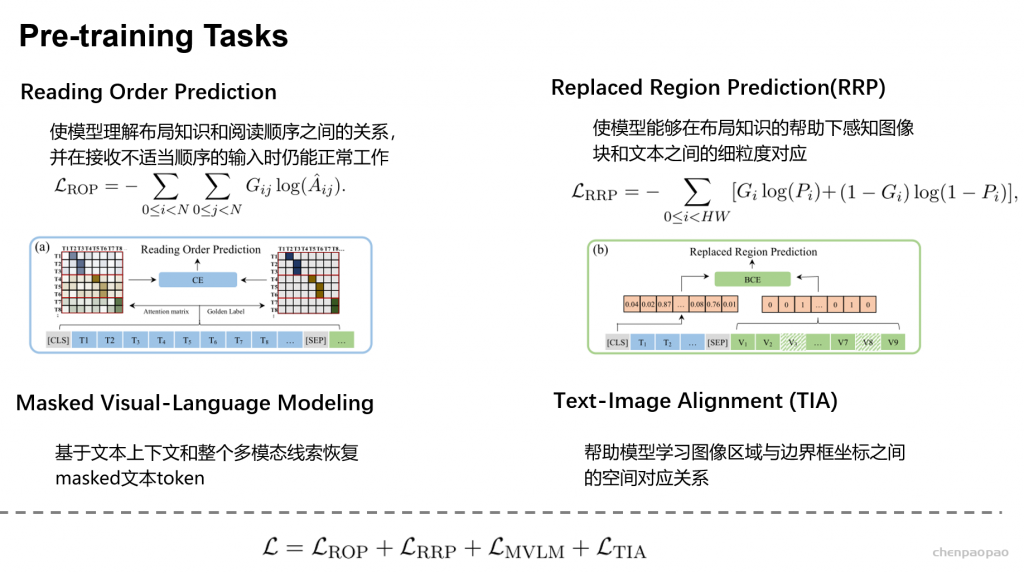
 ▲ 文心ERNIE-Layout 技术框架
▲ 文心ERNIE-Layout 技术框架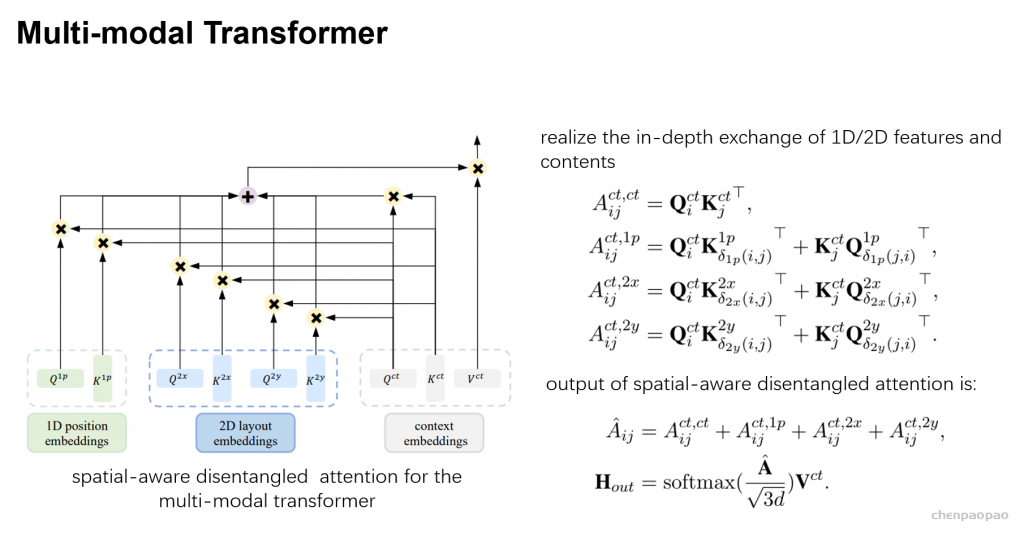
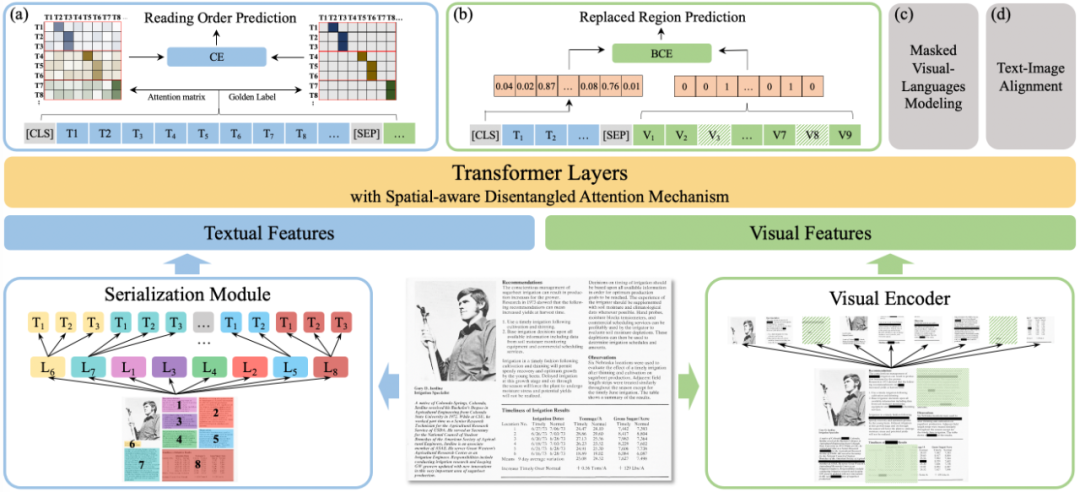
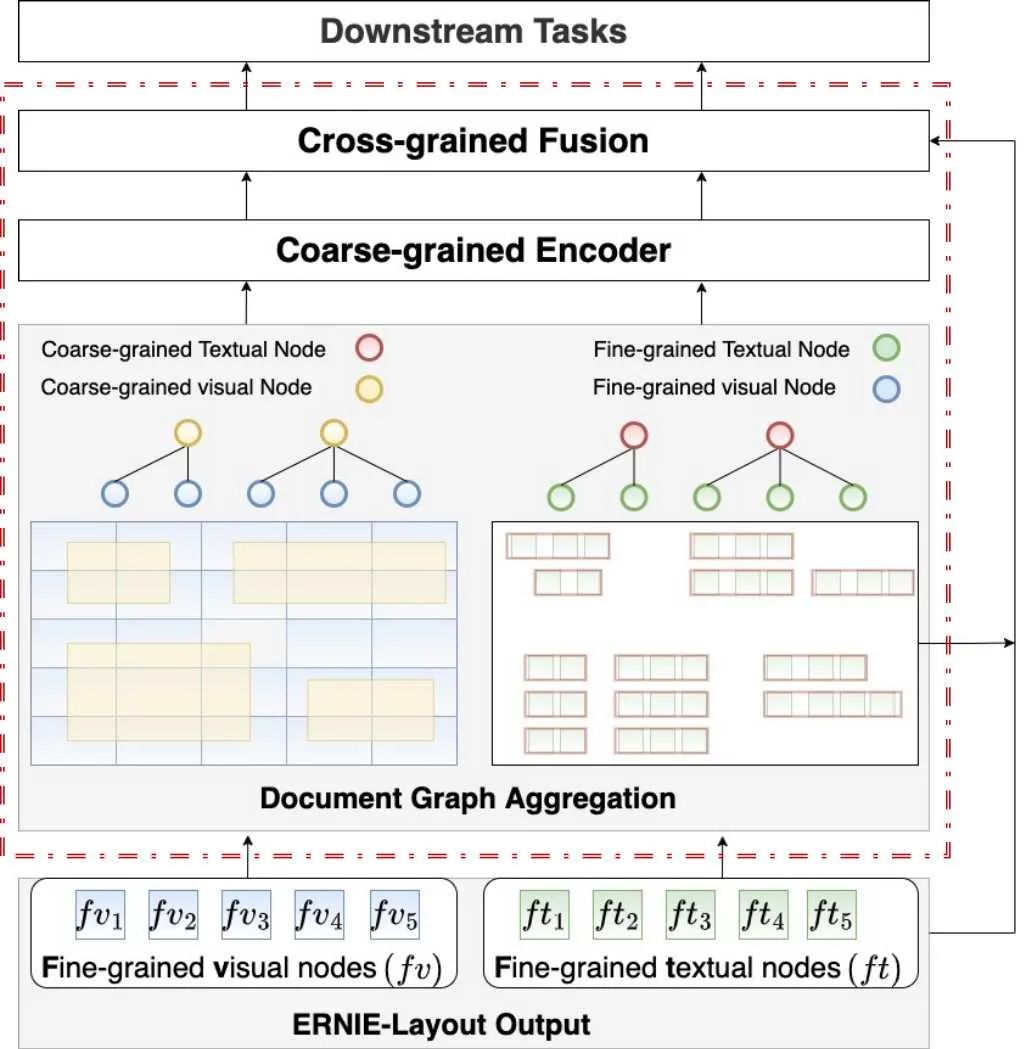 ▲ 文心ERNIE-mmLayout 技术框架
▲ 文心ERNIE-mmLayout 技术框架