

类别:跨模态大模型(用于文档分类、信息抽取、文档问答等)
模型试玩:https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout
Github: https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/document_intelligence
随着众多行业的数字化转型,电子文档的结构化分析和内容提取成为一项热门的研究课题。电子文档包括扫描图像文件和计算机生成的数字文档两大类,涉及单据、行业报告、合同、雇佣协议、发票、简历等多种类型。智能文档理解任务以理解格式、布局、内容多种多样的文档为目标,包括了文档分类、文档信息抽取、文档问答等任务。与纯文本文档不同的是,文档包含表格、图片等多种内容,包含丰富的视觉信息。因为文档内容丰富、布局复杂、字体样式多样、数据存在噪声,文档理解任务极具挑战性。随着ERNIE等预训练语言模型在NLP领域取得了巨大的成功,人们开始关注在文档理解领域进行大规模预训练。百度提出跨模态文档理解模型 ERNIE-Layout,首次将布局知识增强技术融入跨模态文档预训练,在 4 项文档理解任务上刷新世界最好效果,登顶 DocVQA 榜首。同时,ERNIE-Layout 已集成至百度智能文档分析平台 TextMind,助力企业数字化升级。
原理介绍
对文档理解来说,文档中的文字阅读顺序至关重要,目前主流的基于 OCR(Optical Character Recognition,文字识别)技术的模型大多遵循「从左到右、从上到下」的原则,然而对于文档中分栏、文本图片表格混杂的复杂布局,根据 OCR 结果获取的阅读顺序多数情况下都是错误的,从而导致模型无法准确地进行文档内容的理解。
而人类通常会根据文档结构和布局进行层次化分块阅读,受此启发,百度研究者提出在文档预训模型中对阅读顺序进行校正的布局知识增强创新思路。TextMind 平台上业界领先的文档解析工具(Document Parser)能够准确识别文档中的分块信息,产出正确的文档阅读顺序,将阅读顺序信号融合到模型的训练中,从而增强对布局信息的有效利用,提升模型对于复杂文档的理解能力。
基于布局知识增强技术,同时依托文心 ERNIE,百度研究者提出了融合文本、图像、布局等信息进行联合建模的跨模态通用文档预训练模型 ERNIE-Layout。如下图所示,ERNIE-Layout 创新性地提出了阅读顺序预测和细粒度图文匹配两个自监督预训练任务,有效提升模型在文档任务上跨模态语义对齐能力和布局理解能力。
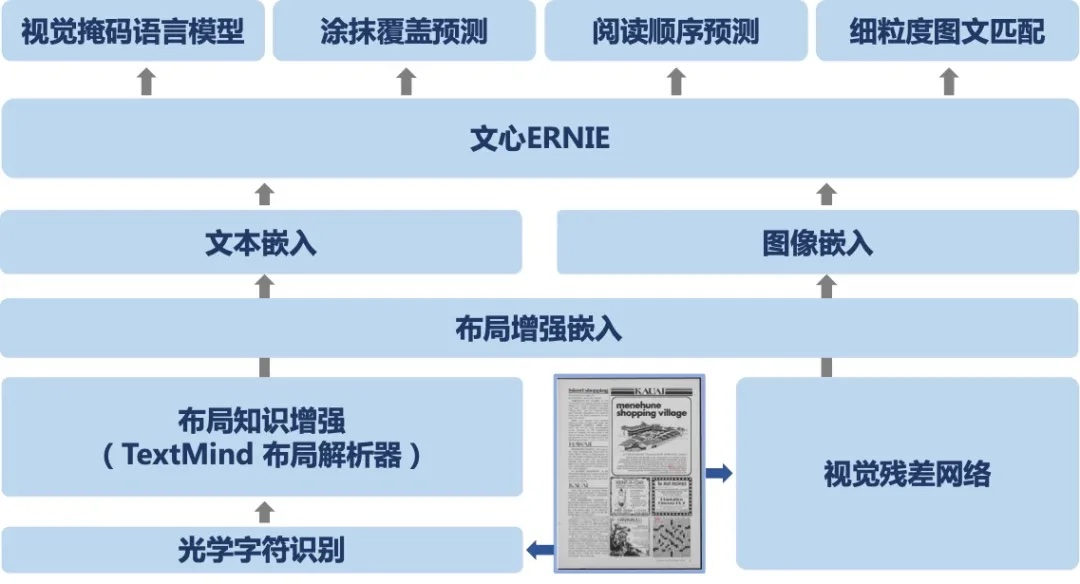
文心ERNIE-Layout以文心ERNIE为底座,融合文本、图像、布局等信息进行跨模态联合建模,创新性引入布局知识增强,提出阅读顺序预测、细粒度图文匹配等自监督预训练任务,升级空间解耦注意力机制。输入基于VIMER-StrucTexT大模型提供的OCR结果,在各数据集上效果取得大幅度提升,相关工作已被EMNLP 2022 Findings 会议收录。
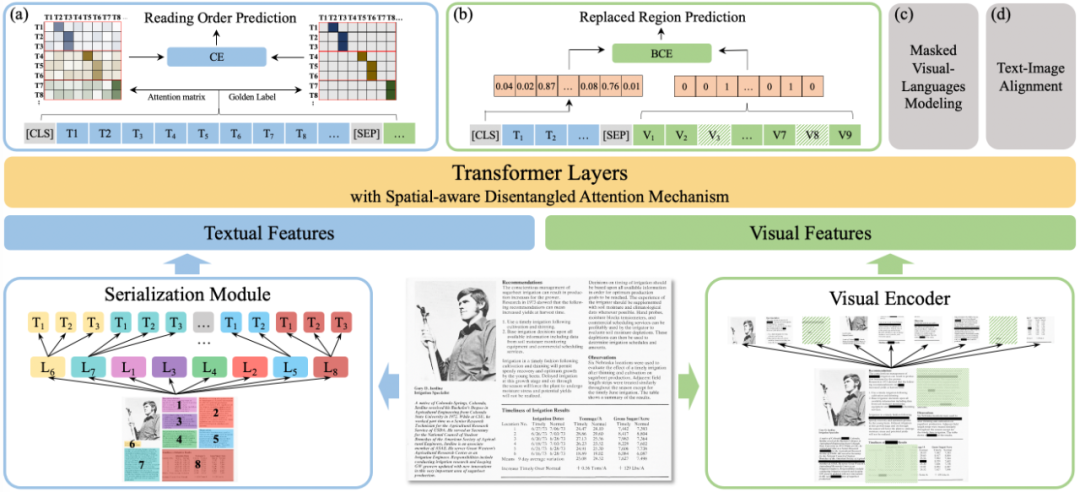
Embedding
Embedding 的输入包括:文本的token_ids,文本内容对应的 bounding box(包含 x1, x2,y1,y2,h,w),图片,以及图片对应的 bounding box。
其中 bounding box 的数值被转换到 0-1000 范围。而后通过一个 Embedding 来分别计算得到对应的 x1_embedding, x2_embedding, y1_embedding 等等 6 个 embeddings。
文字 Embedding
embeddings = (input_embedings + position_embeddings + x1 + y1 + x2 +
y2 + h + w + token_type_embeddings)
# x1, y1, x2 , y2 , h , w : bounding box 各个值对应的 embedding
embeddings = self.layer_norm(embeddings)
text_embeddings = self.dropout(embeddings)- 其中采用可学习的
position_embeddings。 - 采用 Layout-Parser 对图片中的文本内容,根据阅读顺序进行排序,安排对应的
position_ids。 - Layout Embedding:the OCR tool provides its 2D coordinates with the width and height of the bounding box
图像 Embedding
图片被转换成 224* 224 的格式,经过 backbone 编码后,分割成了 7*7 个 patch。
x = self.visual(image) # x [batch, 49, 256]
visual_embeddings = self.visual_act_fn(self.visual_proj(x) # batch, 49, hidden_size与文本 Embedding 相同,visual_embeddings 需要再加上 position_embeddings, token_type_embeddigns, bbox_embeddigns 等,得到最终图像 embedding。
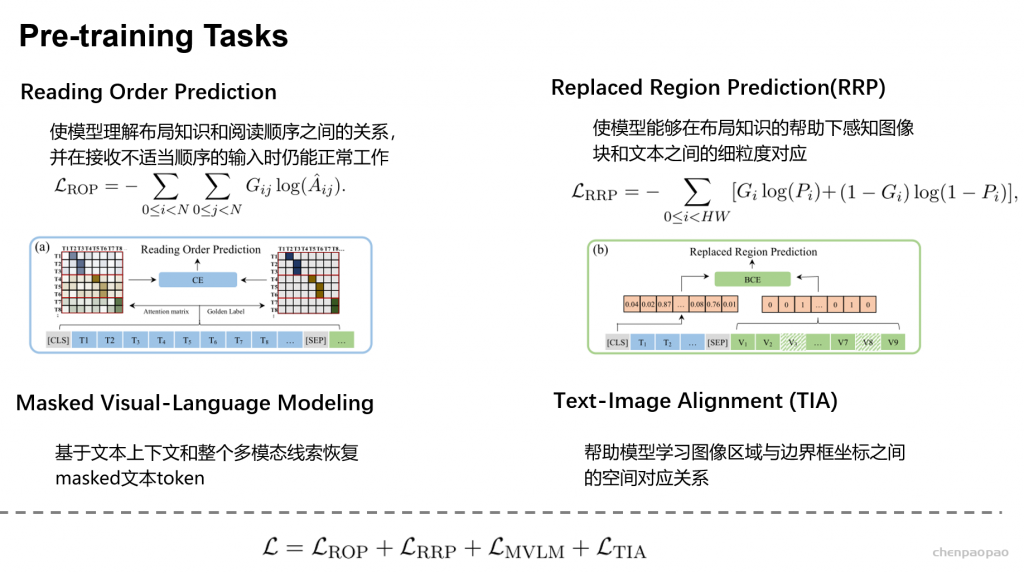
预训练
- Reading Order Prediction:对文字部分,判断token之间的先后阅读顺序。可以通过阅读顺序构建一个包含 01 的邻接矩阵,而后与 attention matrix 计算交叉熵。
- Replaced Region Prediction:对于图片部分,有 10% 的概率替换图片 patch,通过 cls 位置的编码判断哪些 patch 被替换了
- Masked Visual-Language Modeling:类似 MLM,只是这次我们可以用图片部分的embedding信息来预测被遮盖的文字内容。
- Text-Image Alignment:随意覆盖一些文字,然后用一个线性层进行分类任务,判断文字是否被覆盖住了。
文心ERNIE-mmLayout为进一步探索不同粒度元素关系对文档理解的价值,在文心ERNIE-Layout的基础上引入基于GNN的多粒度、多模态Transformer层,实现文档图聚合(Document Graph Aggregation)表示。最终,在多个信息抽取任务上以更少的模型参数量超过SOTA成绩,相关论文被ACM MM 2022会议收录 。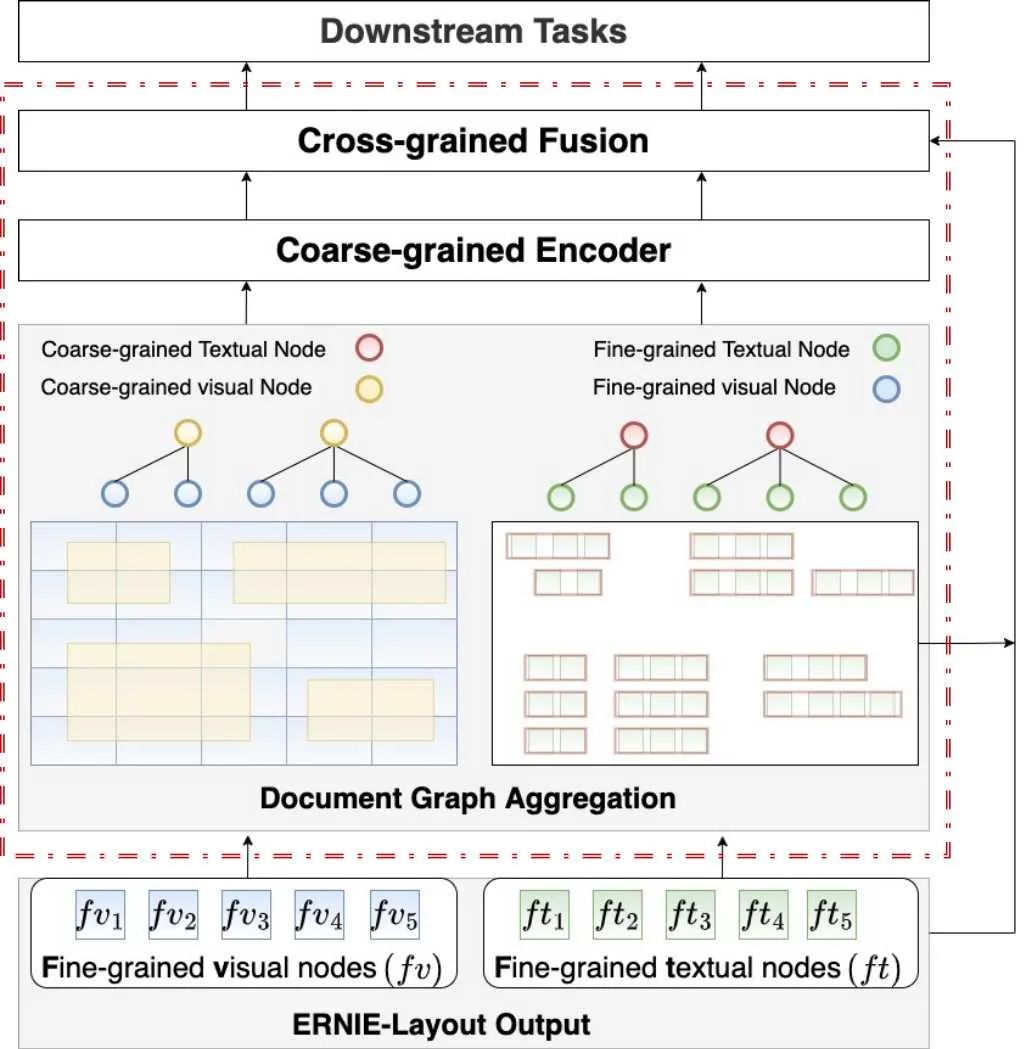
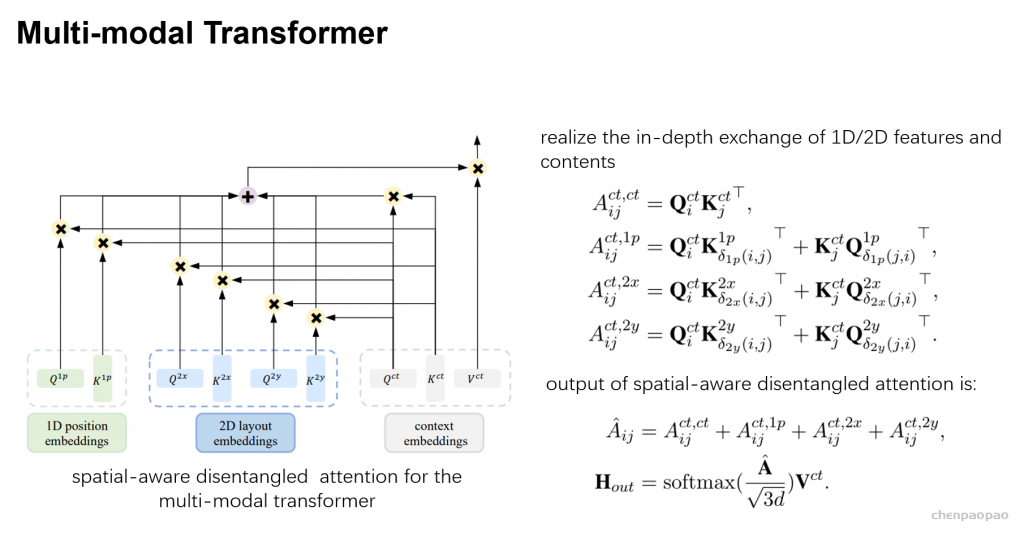
Ernie-layout 整体采用 Transformer Encoder 架构,特点在于:
- 借鉴了 DeBERTa 的解耦注意力,依靠额外的 Layout-Parser 来设计 position_ids。
- 同时对文档图片及文档中的文字进行编码,并设计了4种图文结合的预训练方式。
- 需要依靠额外的 OCR 工具来获得图片中的文字内容,及其对应位置信息。
以下是文档智能技术的一些应用场景展示:
- 发票抽取问答

- 海报抽取问答

- 网页抽取问答

- 表格抽取问答

- 试卷抽取问答

- 英文票据多语种(中、英、日、泰、西班牙、俄语)抽取问答

- 中文票据多语种(中简、中繁、英、日、法语)抽取问答

Visual Prompting
(a)Fine-tuning adapts the entire model parameters.
(b)Linear probes adapt the model outputs (usually activations at the penultimate layer) by learning a linear layer.
(c)Prompting adapts the (downstream) dataset by reformulating the input and/or output.

相关论文:https://github.com/thunlp/PromptPapers
