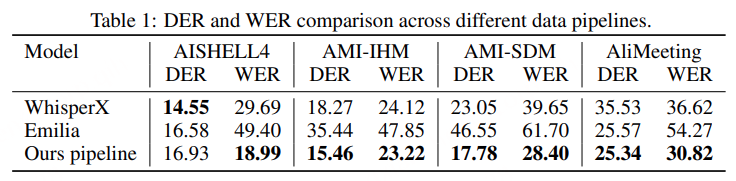
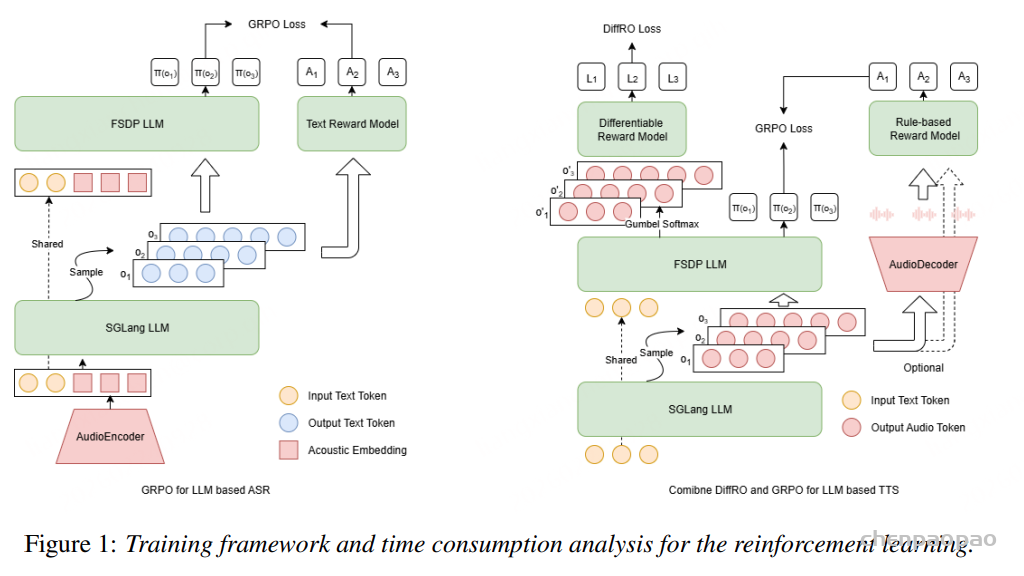
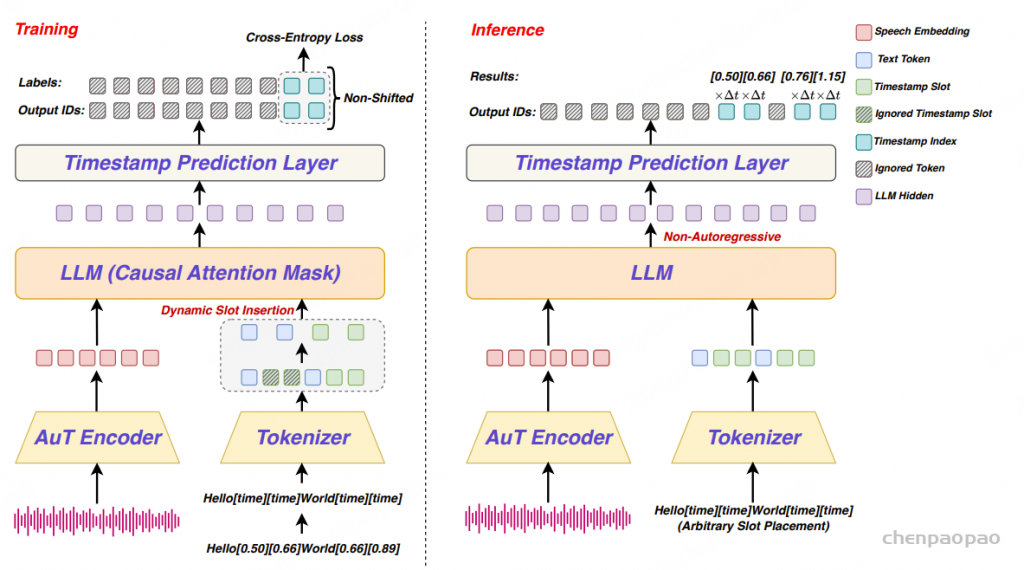
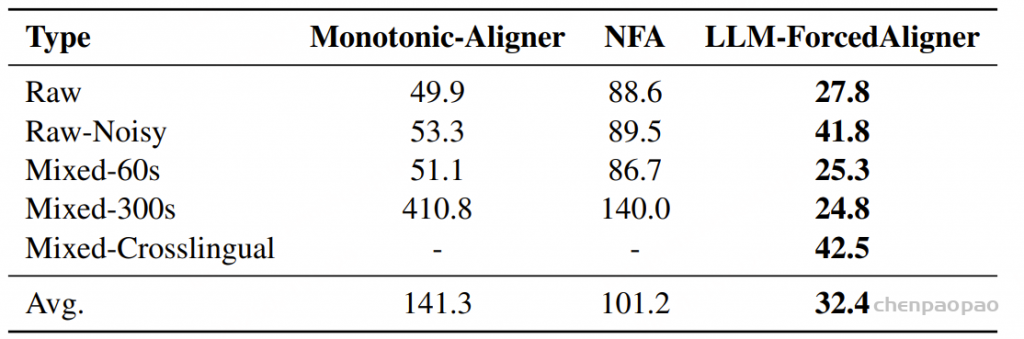
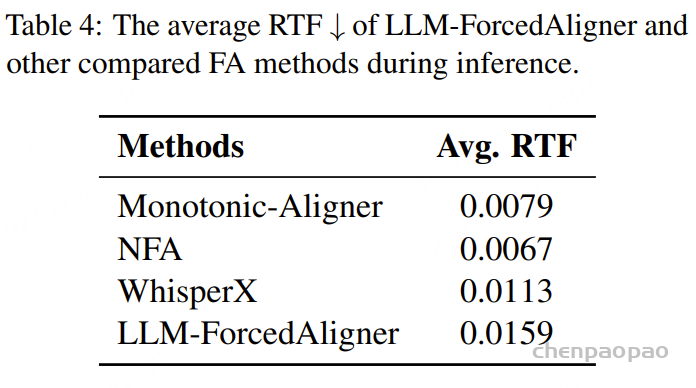
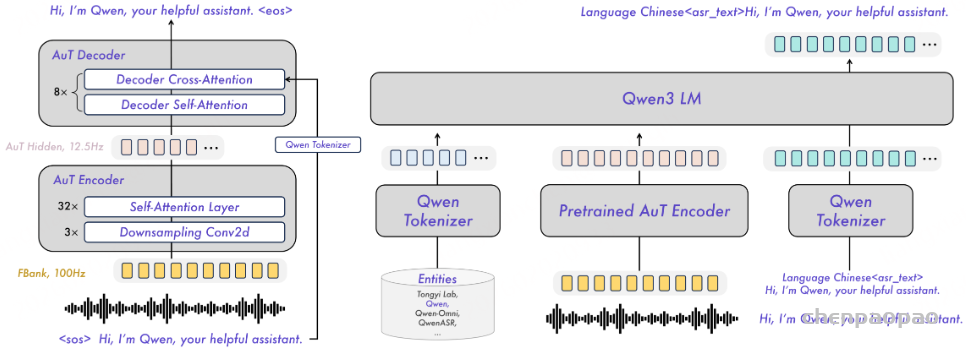
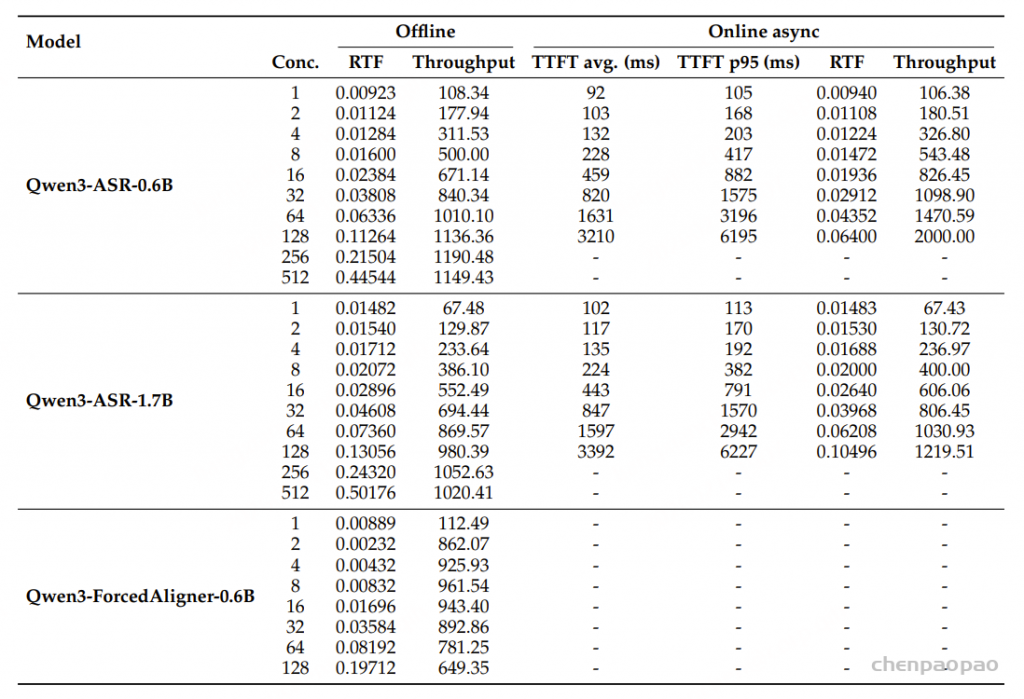
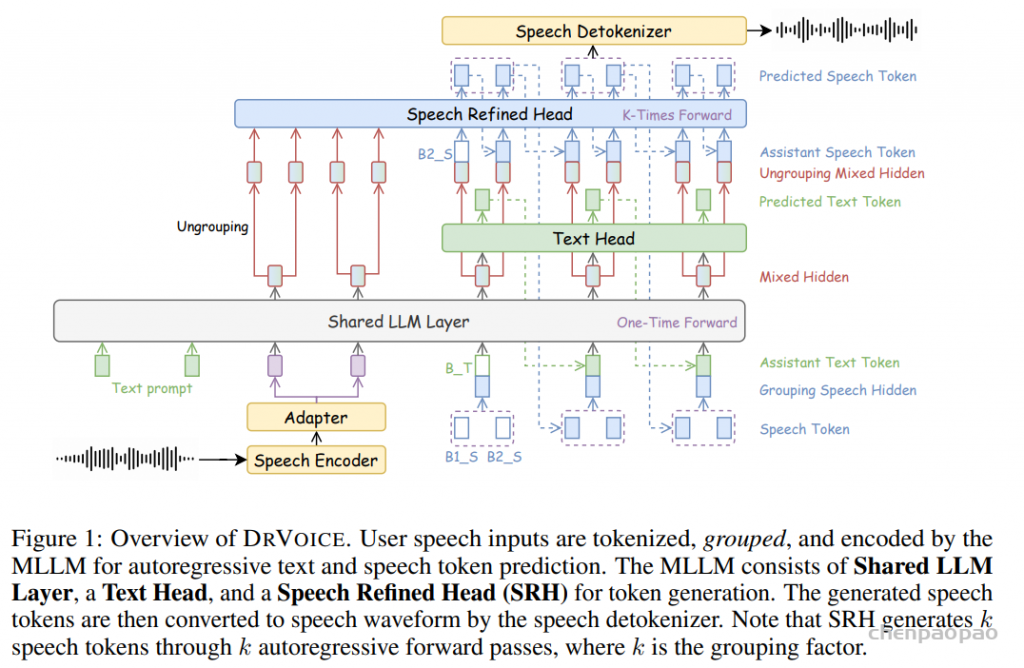
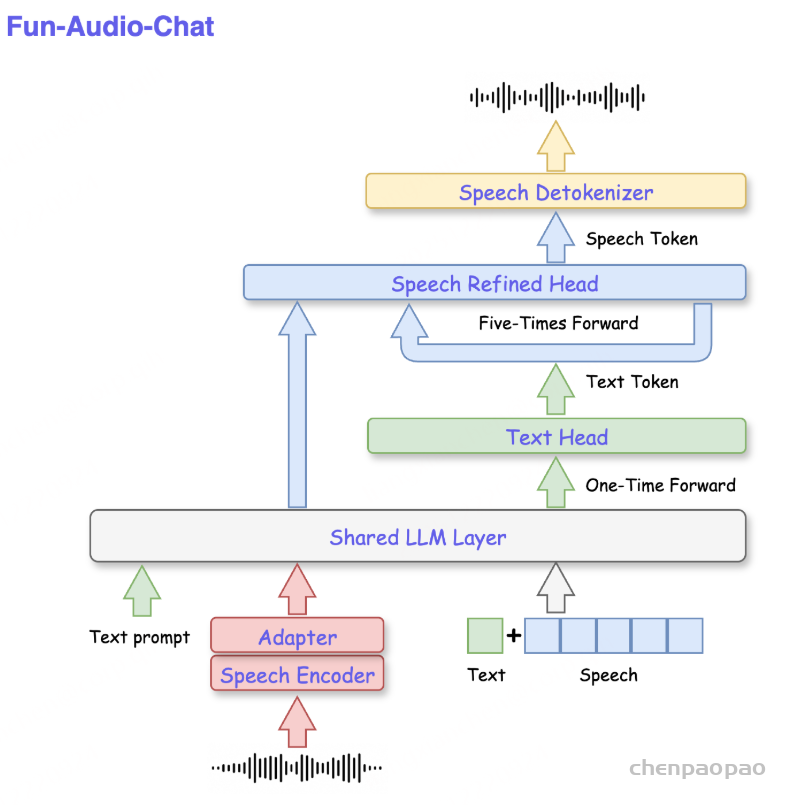
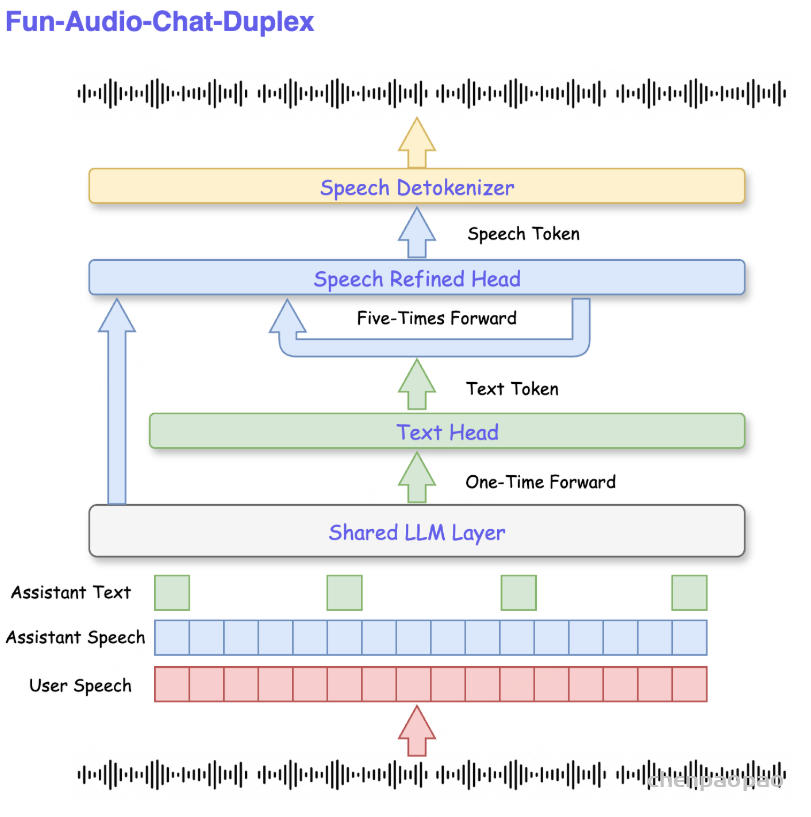
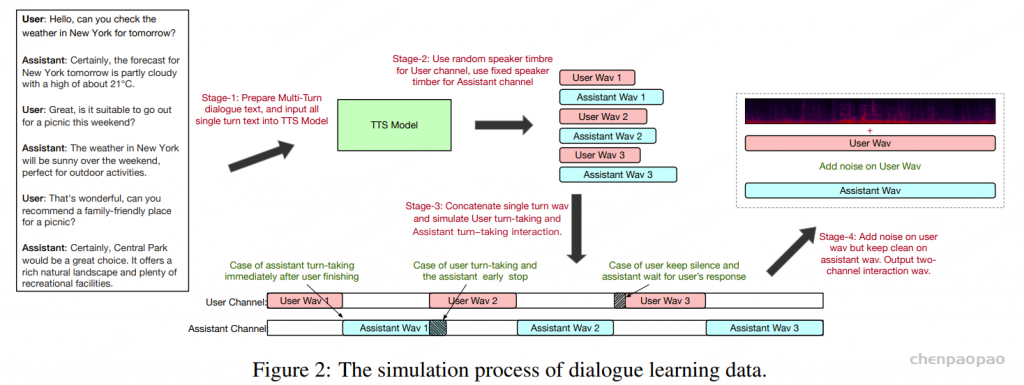
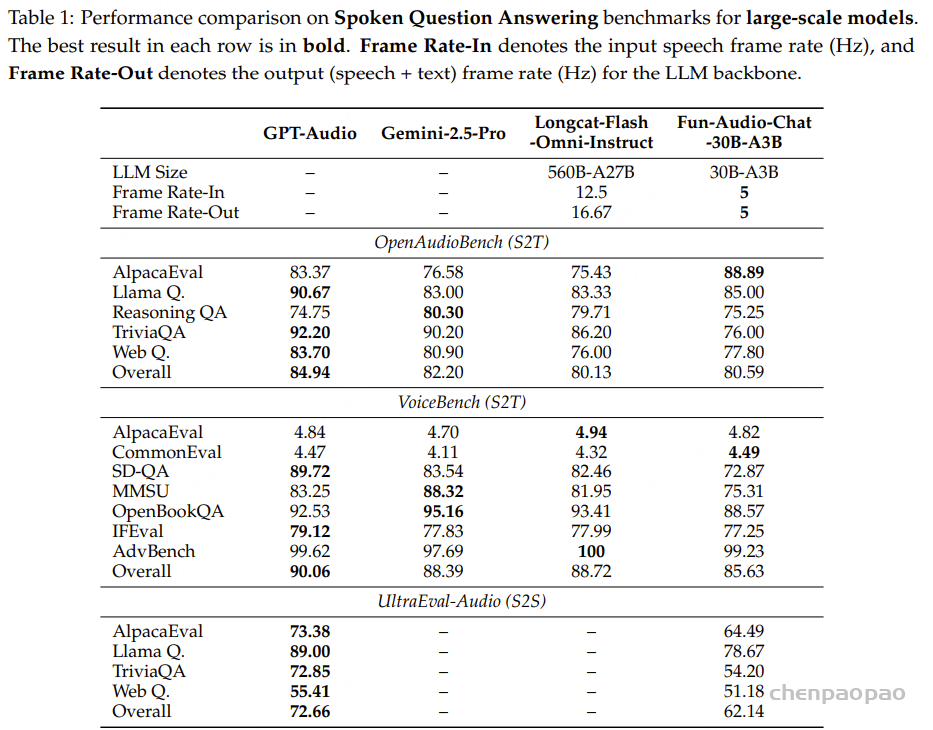
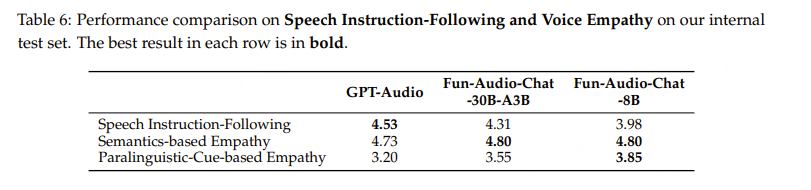
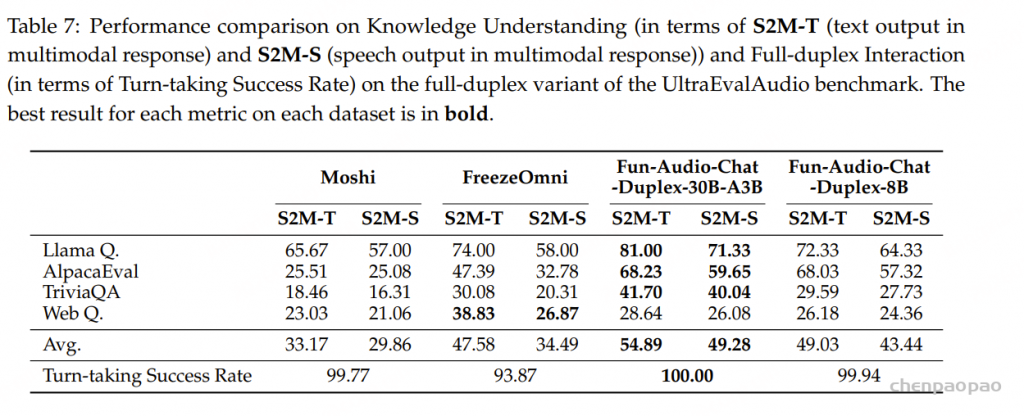
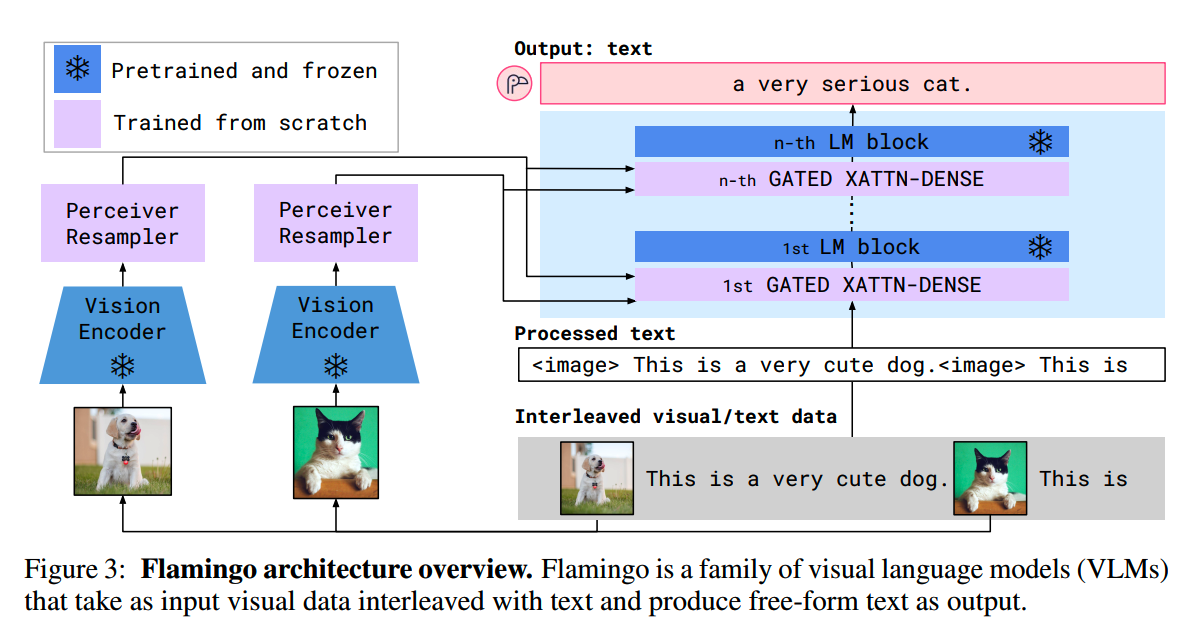
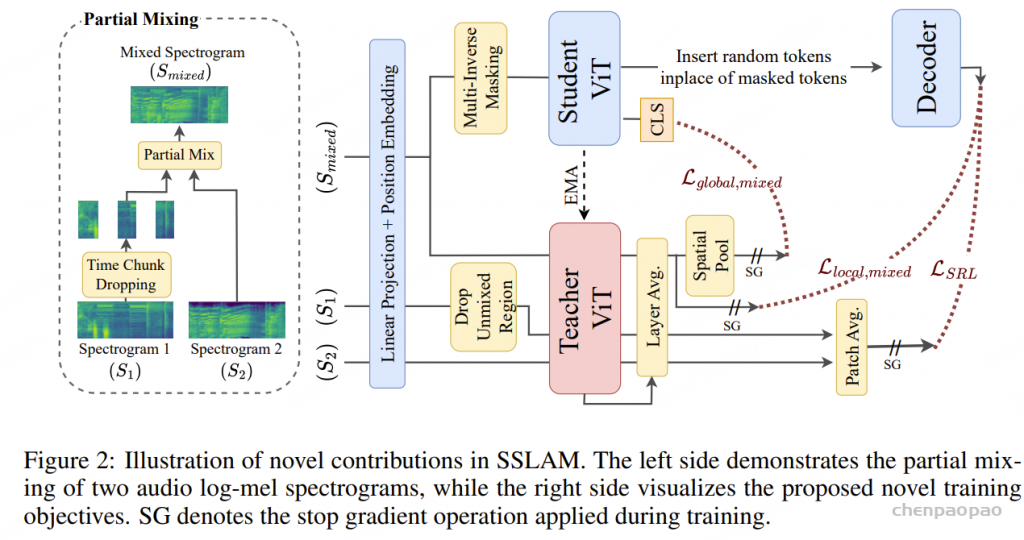
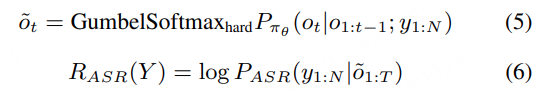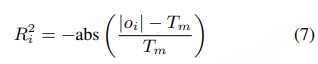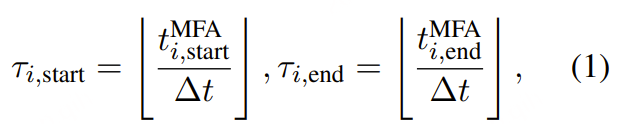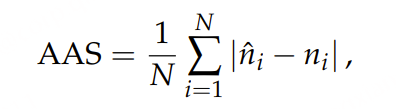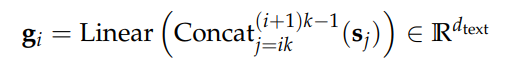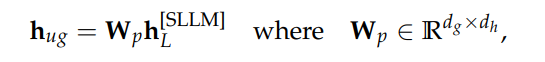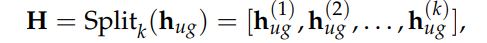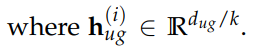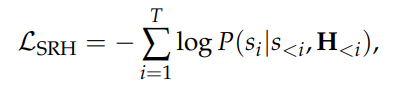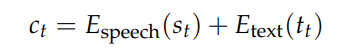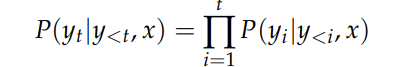阿里通义实验室的论文《Explore the Reinforcement Learning for the LLM based ASR and TTS system》,给出了一套 “轻量、高效、通用” 的解决方案。它不仅设计了适配音频大模型的 RL 框架,还在 ASR 和 TTS 任务上做了深度探索:ASR 用 GRPO + 规则奖励,WER 相对下降 5.3%;TTS 把 GRPO 和 DiffRO 结合,既提升发音准确率,又保住自然度,彻底解决了 “顾此失彼” 的问题。实验结果表明,即使在训练数据有限且优化步骤较少的情况下,RL 也能显著提升 ASR 和 TTS 系统的性能。
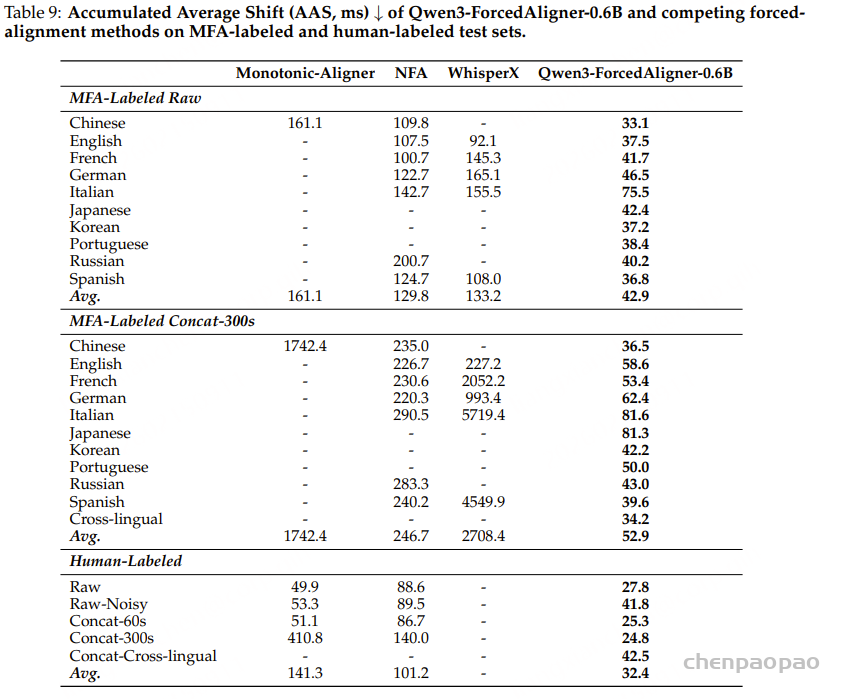
[1] Michael McAuliffe, Michaela Socolof, Sarah Mihuc, Michael Wagner, and Morgan Sonderegger. 2017. Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi. In Proc. Interspeech, pages 498–502.
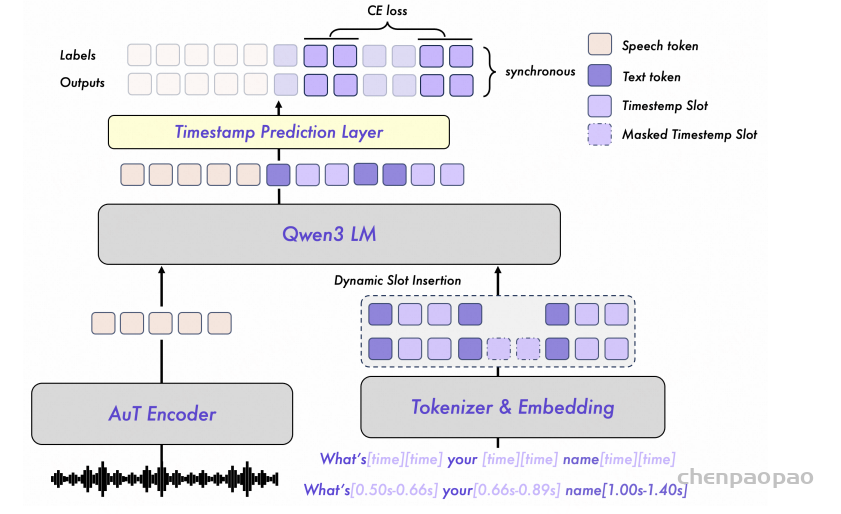
[2] Xian Shi, Yanni Chen, Shiliang Zhang, and Zhijie Yan. 2023. Achieving Timestamp Prediction While Recognizing with Non-Autoregressive End-to-End ASR Model. CoRR, arXiv:2301.12343.
[3] Max Bain, Jaesung Huh, Tengda Han, and Andrew Zisserman. 2023. WhisperX: Time-Accurate Speech Transcription of Long-Form Audio. In Proc. Interspeech
[4] Xian Shi et. al., Qwen3-ASR Technical Report, https://arxiv.org/abs/2601.21337
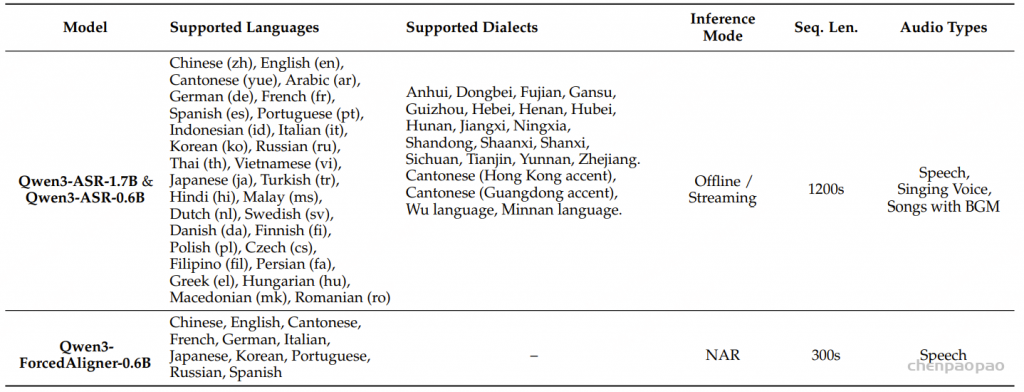
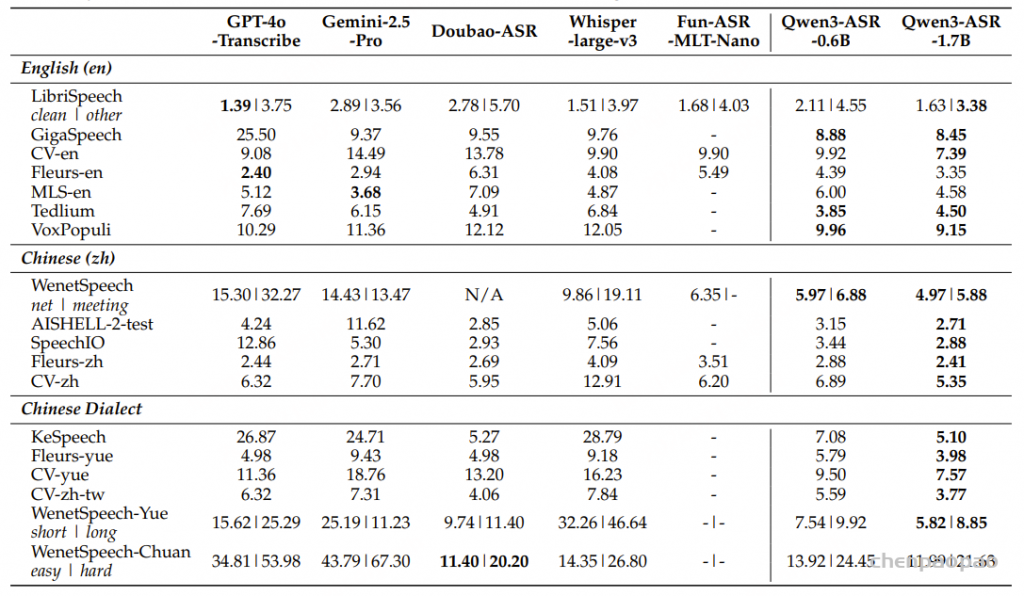
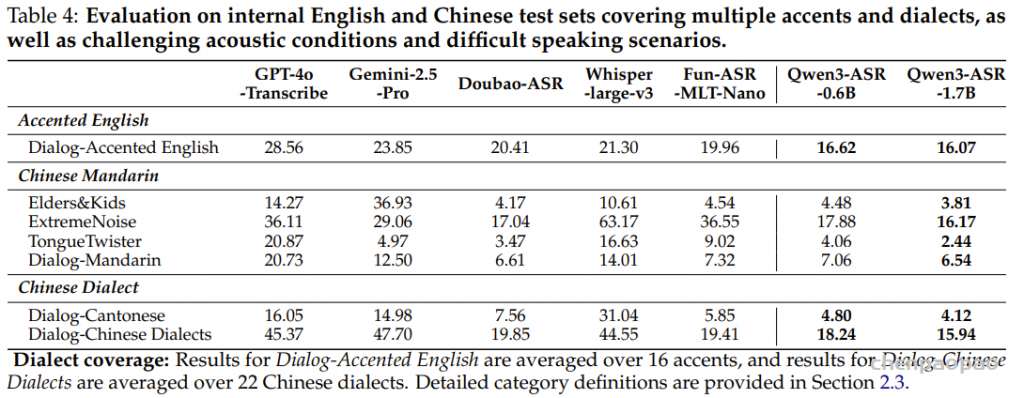
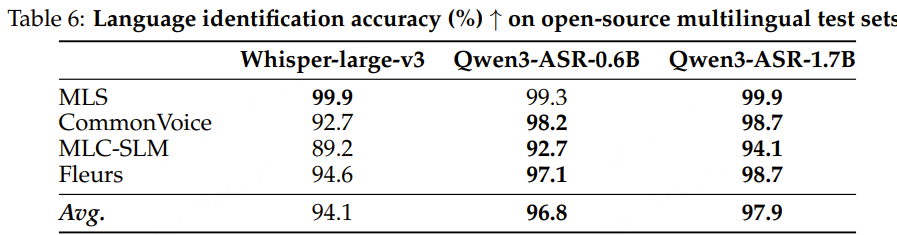
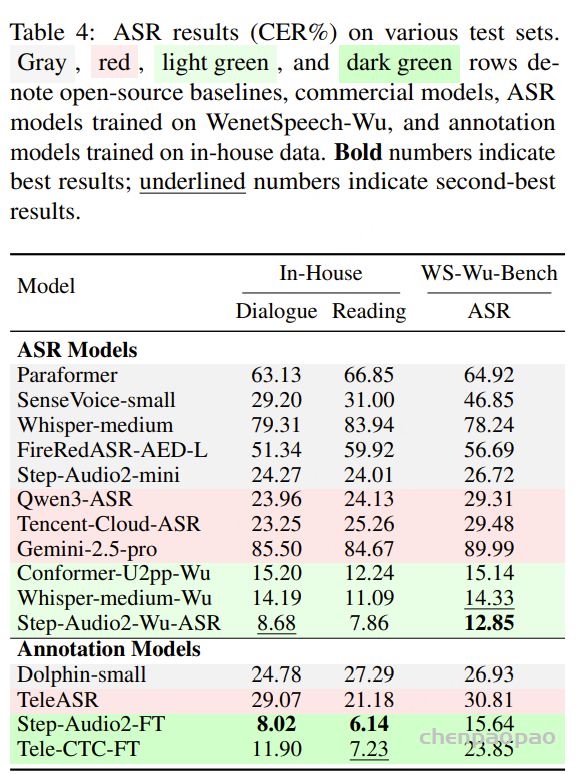
在中文方言基准上,Qwen3-ASR 在存在显著发音和词汇差异的情况下仍保持较强的识别精度。在粤语及其他方言数据集中,它始终位列表现最优的系统之一,并且在更具挑战性的长语句场景下表现尤为突出,体现出超越短句、干净测试条件的鲁棒性。尽管在少数特定方言场景中,一些专门优化的商业 API 略占优势,但总体而言,Qwen3-ASR 依然具有很强竞争力,能够在无需针对每种方言单独定制的情况下提供通用且高性能的解决方案。
总体而言,表 3 总结了 Qwen3-ASR 的三大优势:
在英语基准上具备强大的跨领域泛化能力,尤其是在超越精心筛选的朗读语音场景下表现突出;
在普通话多个公开数据集(包括大规模、噪声较多的会议语音)上达到当前最先进水平;
在中文方言处理方面表现稳健,尤其是在粤语以及长短语句混合的方言语音上具有显著优势。
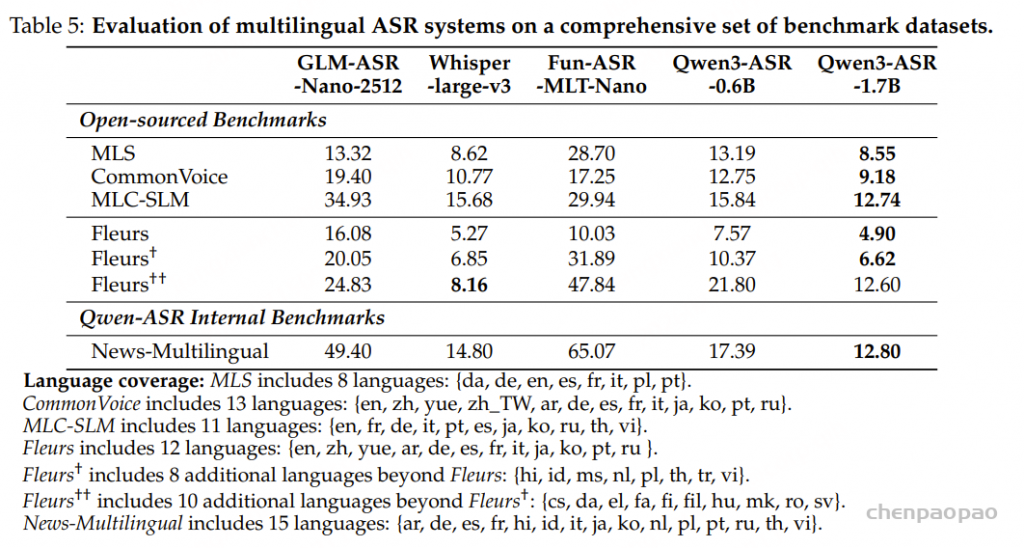
这些结果表明,Qwen3-ASR 在多样化的公开基准测试中展现出强大且可复现的性能,同时在与顶级闭源商业 API 的对比中也保持了高度竞争力。
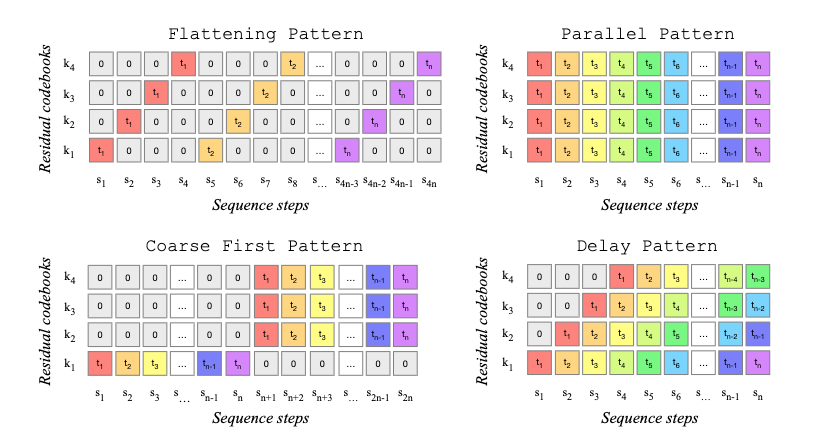
解决方法很巧妙:假装这个问题不存在。具体来说,我们将量化后的潜在向量 zquantized 看作是原向量 z 加上一个任意向量,但不影响梯度。这样, zquantized 的梯度就等同于 z 的梯度。这就是所谓的 straight-through gradient estimator(直通梯度估计器) 的原理。
x = get_batch()
z = encoder(x)
residual = z - to_nearest_cluster(z)
# .detach() means "forget that this needs a gradient"
z_quantized = z - residual.detach()
x_reconstructed = decoder(z_quantized)
loss = reconstruction_loss(x, x_reconstructed)
我用 8 个 H100 显卡训练了这个模型大约 5 天。为了得到一些样本,我决定用 Michael Field 的诗《七月》中的两行 Libri-Light 朗读样本来提示(prompt)模型。(在做这个项目时我了解到,Michael Field 是 Katherine Harris 和 Edith Emma Cooper 的笔名。)让我们看看能从我们的模型中得到什么样的诗歌:
When the grass is gone And corn still grassy; Illness worried in the fur this and pelan in stones during the turan’s ciscerey headforths nepet Paul Twain. He sees zin in them.
Chapter 6 of The Founday, by R. Auclair. This is a Librivox recording. All Librivox recordings are in the public domain. For information, or to volunteer, please visit librivox.org. Reading by: Kelvert
When grass is gone and corn still grassy; When so we could say that in fairy interesting wife who lay there and gone that save the rosy light of life Jay Dien, the antique mollity and a mollity the beast of gray failed summon
end of poem.
This recording is in the public domain.
[different voice] So we have formed a float that sent in would rattle down. The piece of opportunity reading and assimila—
这太棒了。有几个迹象表明这个模型比之前的更好。我喜欢它编造了“mollity”这个词,然后在下一行重复它。而且,它意识到自己正在背诵一首诗,并在该部分结尾加上了 “end of poem”。然后它认为这是章节/部分的结尾,并以“This recording is in the public domain.”的声明结束。之后,它换了个声音继续说话。这是合理的,因为在训练过程中,来自不同有声读物的片段只是被随机打乱并连接在一起,所以在这里模型模拟了一个片段边界。
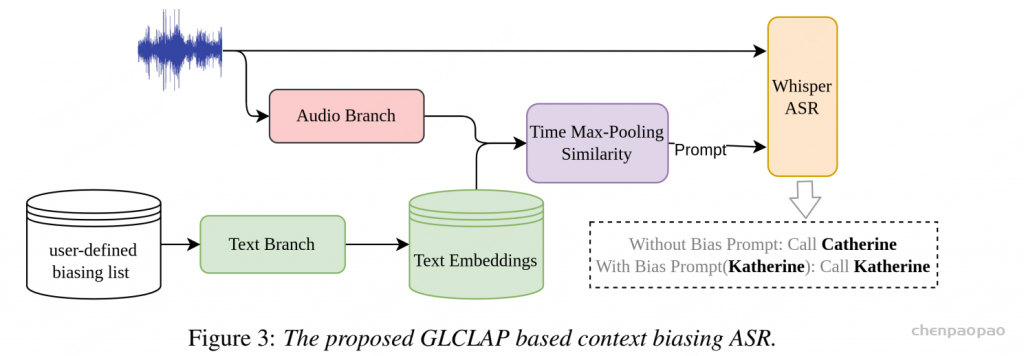
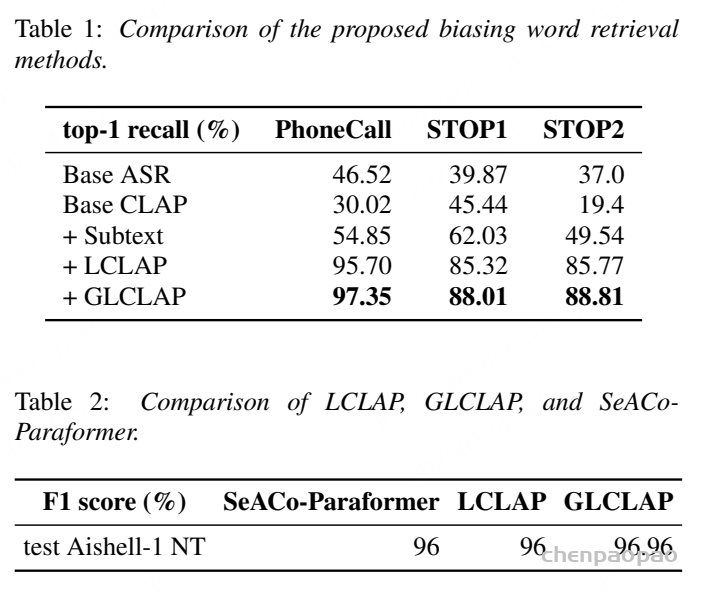
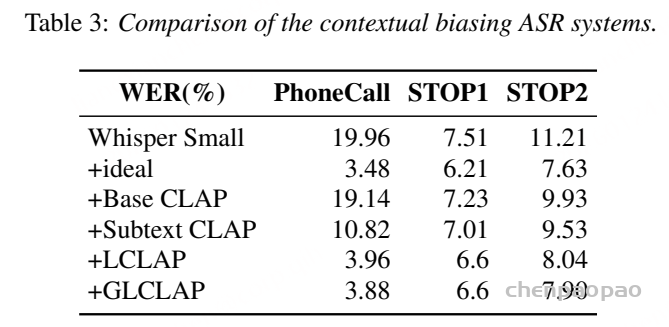
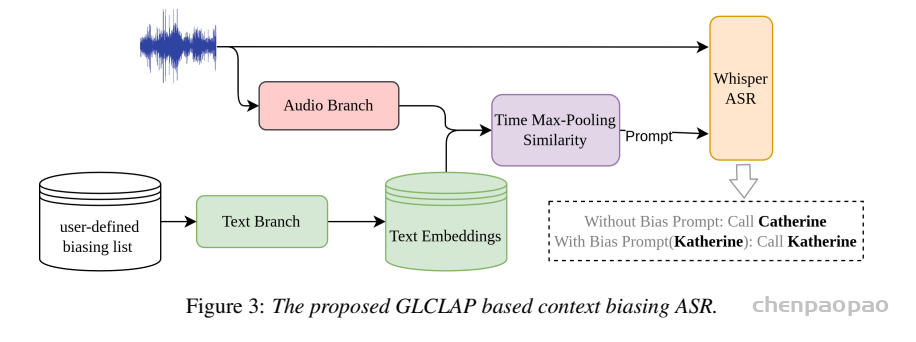
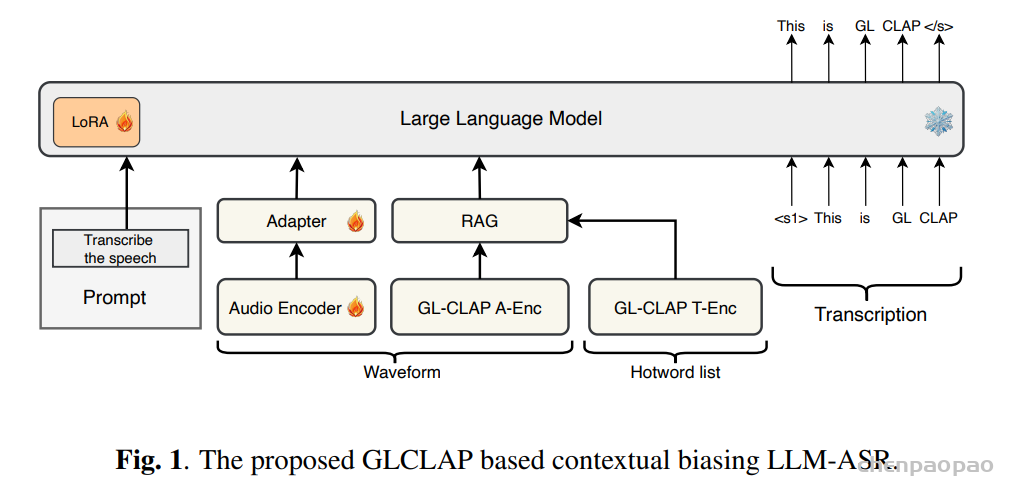
传统的上下文偏置 ASR 解决方案中,主要存在两种范式。第一种依赖发音词典,例如基于加权有限状态转换器(WFST)的相关方法。这类系统利用预先定义的发音信息来提升特定术语的识别准确率。第二种范式是将偏置机制直接融入 ASR 模型结构中,通过与 ASR 模型进行联合训练来实现 ,典型代表包括 SeAco-Paraformer。
然而,这两类系统都不利于在支持 prompt 的 ASR 场景中处理偏置词。对于基于 WFST 的系统而言,获取少数语言或方言的发音词典往往十分困难;而端到端的上下文偏置方法通常需要修改 ASR 模型结构并进行联合训练,这在 prompt 支持的大模型范式下缺乏灵活性,难以快速更新和迭代。同时,大模型训练本身需要大量时间和计算资源,成本较高。
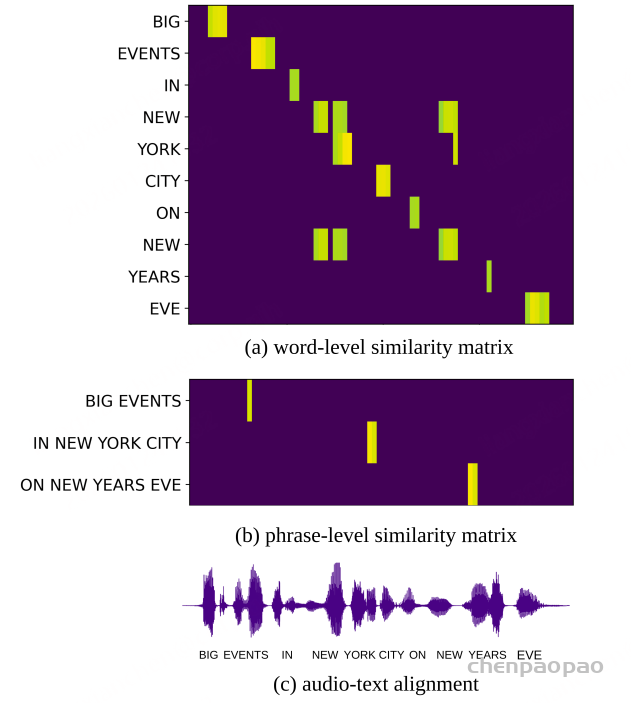
大语言模型(LLMs)中引入的提示机制与检索增强生成(Retrieval-Augmented Generation,RAG)为此提供了重要启示。RAG 通过优化提示来获得期望输出,而无需修改 LLM 的网络结构或进行微调。受这一范式的启发,偏置提示的生成可以作为一个独立模块,与识别过程进行解耦。这样,模型既不需要依赖发音词典,也不必在训练阶段依赖 ASR 模型本身。该方法与当前的大模型框架高度契合,能够利用 RAG 思路实现大规模的上下文偏置增强。
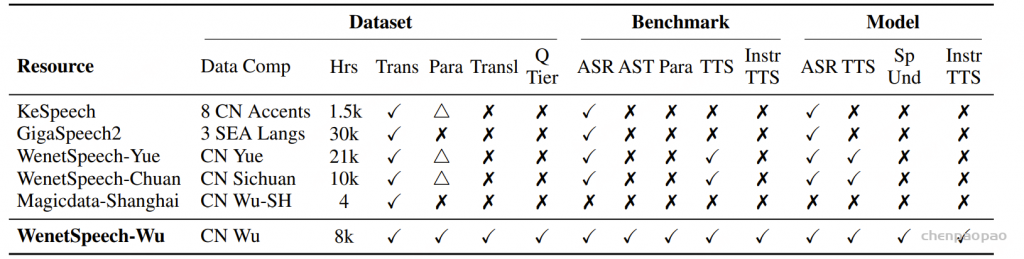
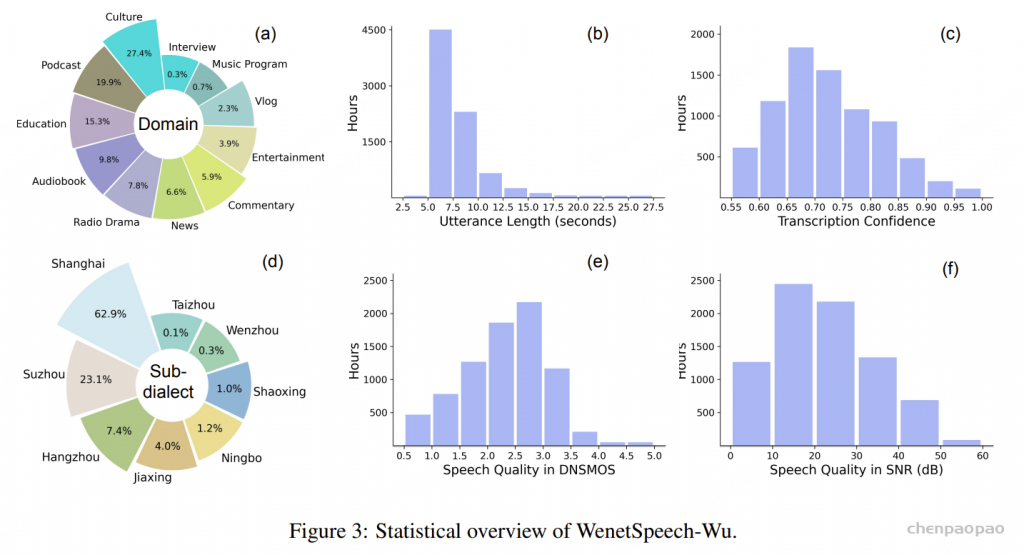
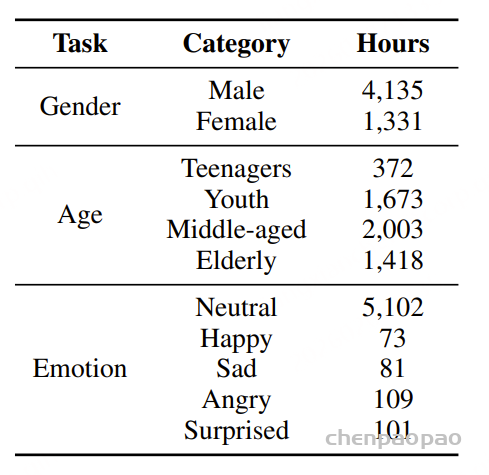
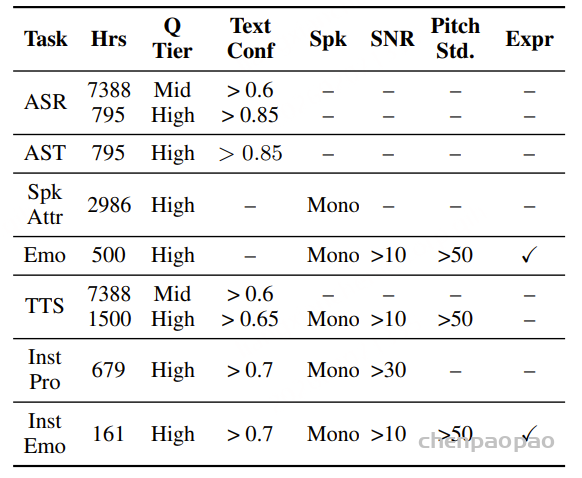
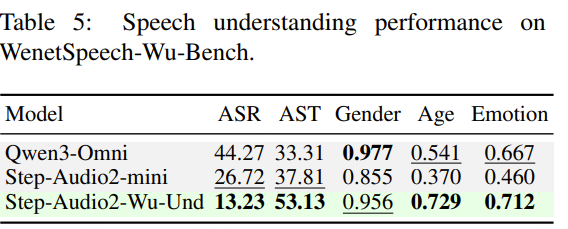
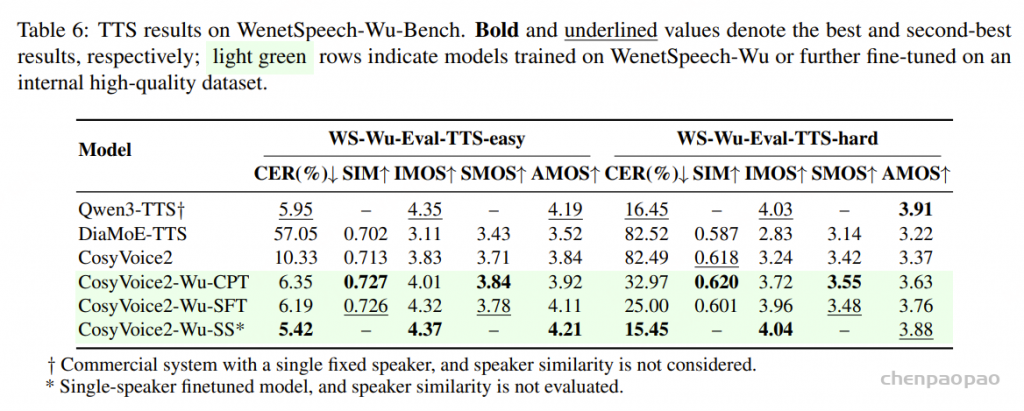
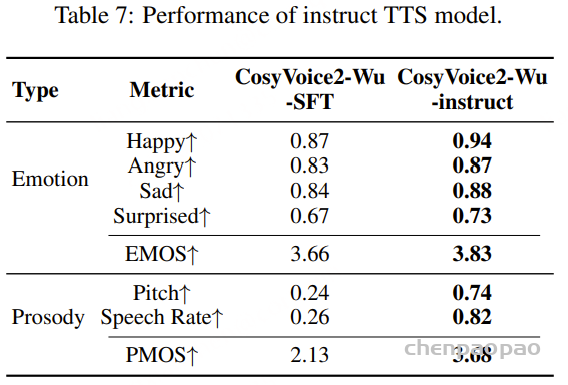
面向任务的数据质量分级:为支持多样化语音任务在实际训练中的不同需求,我们提出了一种与任务特定质量要求相匹配的数据质量分级策略。针对 ASR 和 TTS 任务,我们构建了两个质量等级的数据子集。其中,普通质量子集主要用于大规模预训练,更强调数据覆盖范围和多样性,仅要求中等水平的转写置信度;高质量子集则面向监督微调(SFT),采用更严格的筛选标准,包括更高的转写置信度、更干净的声学环境以及可靠的说话人分离,以提供更稳定、有效的监督信号。对于对标注噪声和语义歧义更为敏感的任务,例如吴语到普通话的自动语音翻译、说话人属性预测、语音情感识别、语音合成以及指令控制语音合成,我们采用了更为严格的数据筛选标准,包括单说话人录音、高 MOS 评分、较高信噪比、音高标准差约束,以及经过一致性验证的标注结果,具体标准如表3所示。