
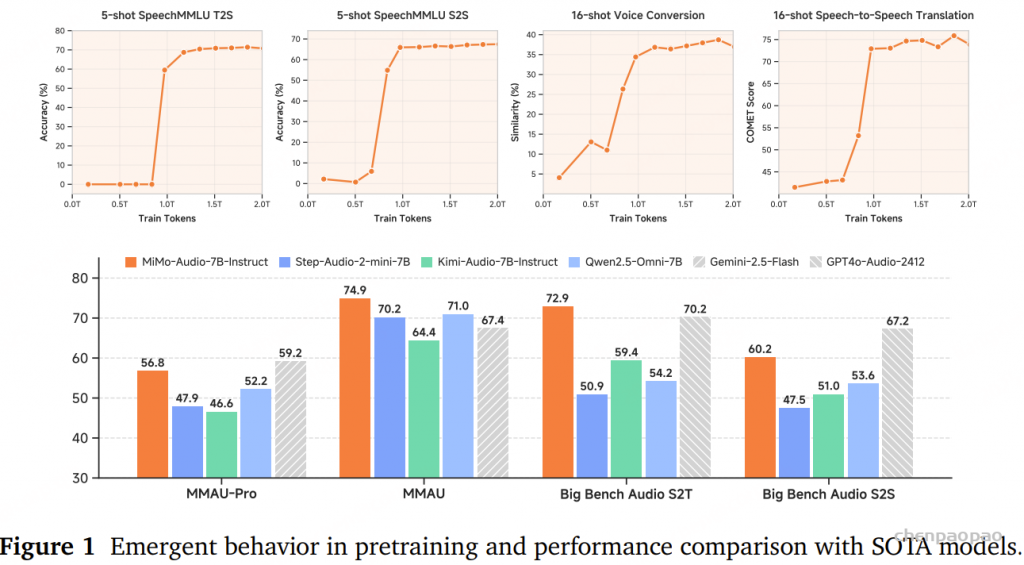
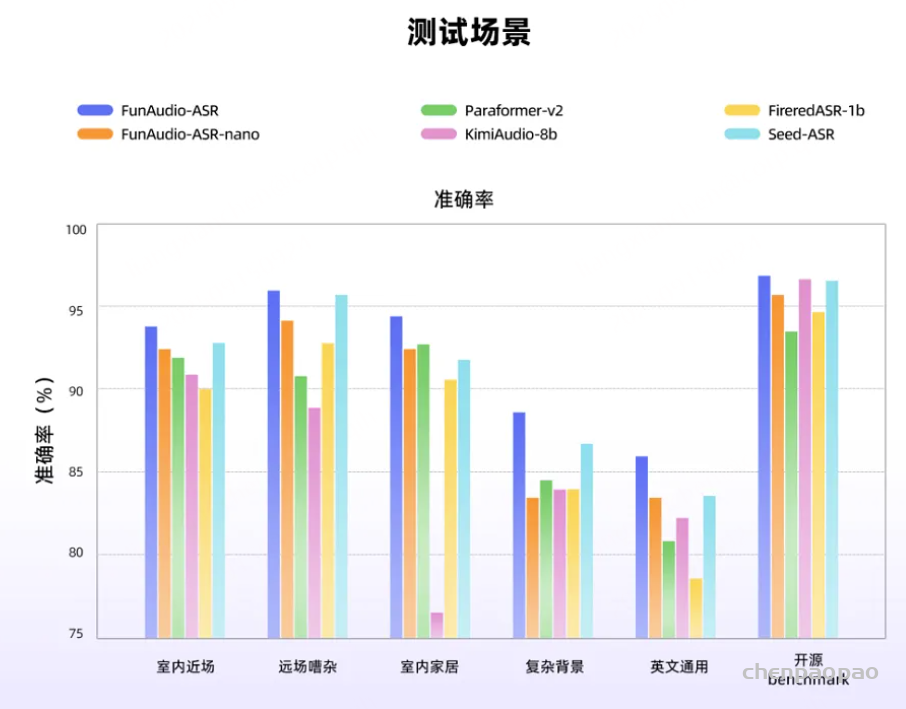
- PAL: Probing Audio Encoders via LLMs — A Study of Information Transfer from Audio Encoders to LLMs
- https://ta012.github.io/PAL/
- https://github.com/ta012/PAL-AudioLLM
如何设计音频编码器与 LLM 的集成架构,使得 LLM 能够高效、准确地从音频编码中“探测”出与文本查询相关的信息?
如何将丰富的音频语义高效地从音频编码器传递到 LLM 中,仍然缺乏系统性的研究。目前最常用的集成范式,是将音频编码器输出的 token 映射到 LLM 的输入 token 空间(例如通过 MLP 或 Q-Former),并将其前置或插入到文本 token 序列中。将这一通用方案称为 PLITS(Prepend to the LLM’s Input Token Space)集成方式。
论文提出了一种高效的替代方案——轻量级音频 LLM 集成方法(Lightweight Audio LLM Integration,LAL)。LAL 仅通过 LLM 不同层中的注意力机制引入音频表示,而绕过其前馈网络模块。该方法能够在合适的抽象层级上对丰富的音频语义进行编码,从而有效地将其集成到 LLM 的不同模块中。与现有的集成方式相比,该设计显著降低了计算开销。
在完全相同的训练流程下,LAL 在多种基础 LLM 和任务上均能够保持与现有集成方法相当的性能,甚至取得更优表现。对于通用音频任务,LAL 相较于强 PLITS 基线模型的性能提升最高可达 30%,同时内存占用最多降低 64.1%,吞吐量最高提升 247.5%。此外,在通用音频-音乐-语音 LLM 场景下,PAL 的性能与完全基于 PLITS 集成的系统相当,但在计算效率和内存效率方面具有显著优势。
LLM 中内在的两类知识:(1)参数化知识,主要源于大规模语言预训练并嵌入于 FFN 层中;(2)上下文知识,通过注意力机制动态地引入和调制。 音频输入作为一种上下文信息,可以仅通过基于注意力的调制,在文本 token 表征中激活所需的概念,而无需对音频表示进行直接的 FFN 处理。由此,音频信息得以间接访问 LLM 的参数化知识:音频上下文“搭载”在文本 token 之上,注意力机制对其表征进行重构,进而在 FFN 处理中触发与相关概念对应的路径。该策略不仅在架构效率上具有优势,也为多模态信息融合机制提供了更为深入的理解。
Introduction
两种主流的架构范式:
- PLITS(Prepend to the LLM’s Input Token Space)集成方式。将一个或多个音频编码器的输出映射到 LLM 的输入空间(例如通过 MLP、Q-Former),随后将这些音频 token 前置或插入到文本 token 序列中,并将整个序列作为统一输入。
- Flamingo 风格的架构。在相邻的 LLM 层之间插入交叉注意力(cross-attention)和前馈网络(FFN)模块。在每一次插入中,文本 token 首先对一组潜在的音频 token 进行注意力计算,随后通过该模块中的 FFN,最后再进入下一层 LLM。缺点:交叉注意力与 FFN 模块的交错堆叠会增加模型的顺序深度以及单层计算量,从而可能减慢前向传播速度。
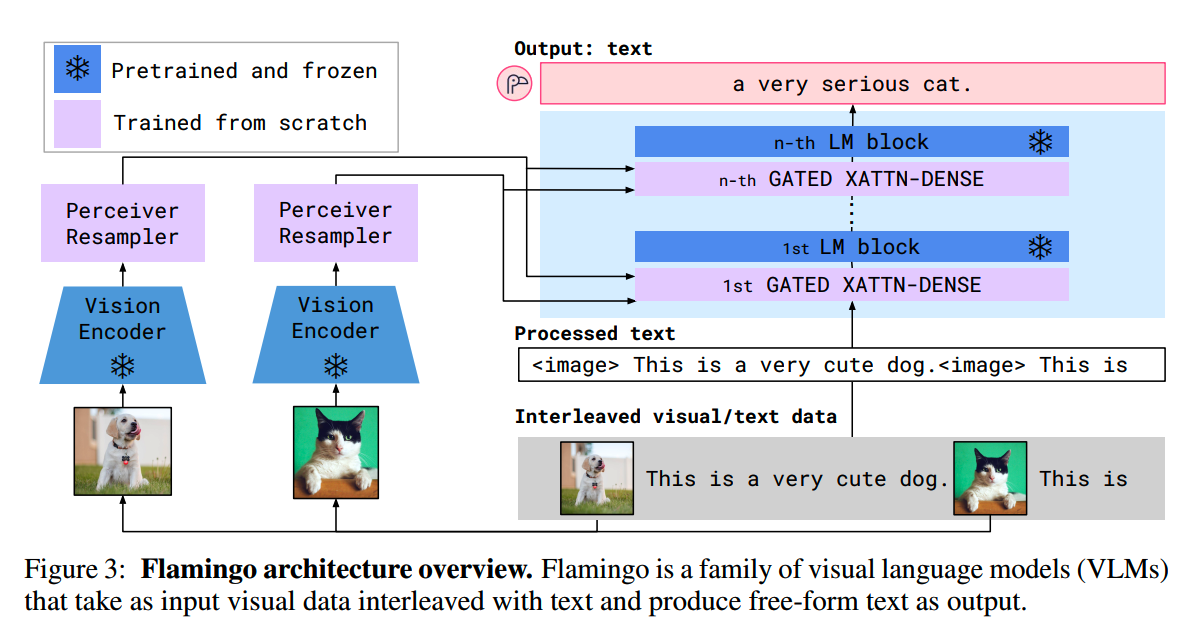
本文提出了 LAL,一种轻量级的集成方式,其仅将音频 token 作为 Key和值Value 注入到 LLM 的注意力模块中(不构造音频查询 Query),并且使音频 token 绕过 LLM 的前馈网络(FFN)。这种设计将注意力计算复杂度从
O((Na+Nt)2)
降低至 O((Na+Nt)Nt),
其中 Na 和 Nt分别表示音频 token 与文本 token 的数量。由于在实际场景中通常满足 Na ≫ Nt ,该设计能够带来显著的计算效率提升。LAL 在内存占用和计算量方面均实现了显著降低。与 LoRA 等参数高效训练方法不同,LAL 属于一种核心架构层面的改动,因此其带来的效率优势不仅体现在训练阶段,同样适用于推理阶段。
PLITS 与 Flamingo 类集成方法代表了从音频编码器中提取信息的两种互补策略。LAL 通过限制音频 token 与 LLM 的交互方式,提供了一种计算与内存高效的机制;而在 PLITS 风格的集成下,某些音频编码器则可以从 LLM 内部更丰富的解码过程中获益。具体而言,采用语言对比学习或自监督目标训练的编码器(如 CLAP、SSLAM)更适合使用 LAL 集成方式;而 Whisper 由于其采用自回归语音到文本转写及下一 token 预测目标进行预训练,则能够从 PLITS 风格集成所提供的额外解码能力中获得更多收益。

基于上述观察,本文提出了一种 LAL 与 PLITS 相结合的混合集成框架——PAL,用于构建通用的音频、音乐和语音 LLM。该框架实现了一种面向音频编码器感知的融合策略,在效率与性能之间取得平衡。与单独采用 PLITS 集成方式相比,该设计在显著降低计算与内存开销的同时,仍能获得强劲的性能表现。实验系统地探索了性能与效率之间的权衡关系,揭示了面向编码器感知的融合策略如何在最小参数开销的前提下,实现音频编码器向 LLM 的高效信息传递。
Methodology
以当前最先进的集成方式 PLITS 作为基线方法,LAL 为本文提出的方法,PAL 为二者的混合方案。需要说明的是,文中使用 LAL 和 PAL 同时指代集成策略本身以及相应的音频-LLM 模型。
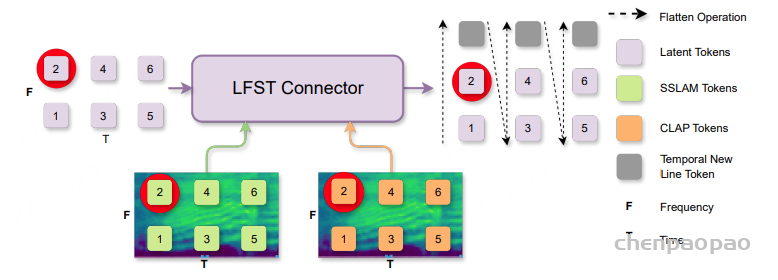
在音频编码器方面,采用 SSLAM 和 CLAP,并使用一种高效的、基于 Q-Former 的连接器来融合二者的信息,在不增加 token 数量的情况下完成融合,称为 LFST。若未使用 LFST,则音频编码器默认为 SSLAM;当使用 LFST 时,则表示 SSLAM 与 CLAP 的组合。
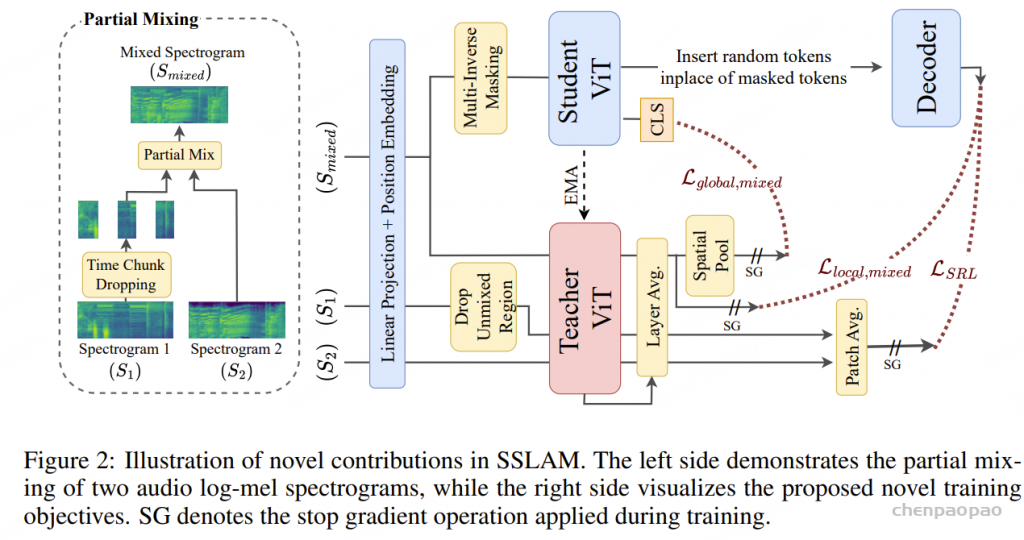
关于 LFST 的 连接器:
用于融合语言对齐的编码器(如 CLAP)与自监督编码器(如 SSLAM)。该连接器生成一组紧凑的潜在 token,既融合了 CLAP 的语义信息,又保留了 SSLAM 的细粒度时空特征,同时保持序列长度固定,避免了简单拼接带来的计算开销。
编码器输出为:
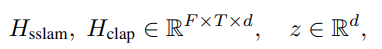
其中 F表示频率,T表示时间,d 表示特征维度。单个潜在 token z会广播到每一个时空位置,从而得到每个 zf,t。
在连接器内部,该模块包含 3 层交叉注意力(cross attention)层,每个 zf,t 会通过与对应局部区域的 Hsslam和 Hclap 的交叉注意力进行更新。
为了在跨 (F,T)扁平化时保留时间结构,我们在频率轴上插入换行符(newline token),使得每一个新的时间步以该标记开头,然后才是其频谱 token
基线音频 LLM:
将音频 token 前置到 LLM 输入空间(PLITS):将音频 token 前置到 LLM 输入 token 空间的基线音频 LLM 作为基准。
音频编码器的输出首先通过一个 Q-Former 连接器映射到 LLM 的输入嵌入空间,生成音频 token。随后,这些音频 token 被直接拼接在文本 token 之前,形成一个联合序列,并共同经过 LLM 的所有层进行处理,从而实现音频与文本的联合解码。该范式的核心特征在于音频 token 向 LLM 提供的方式——即作为前置 token 与文本一同输入。
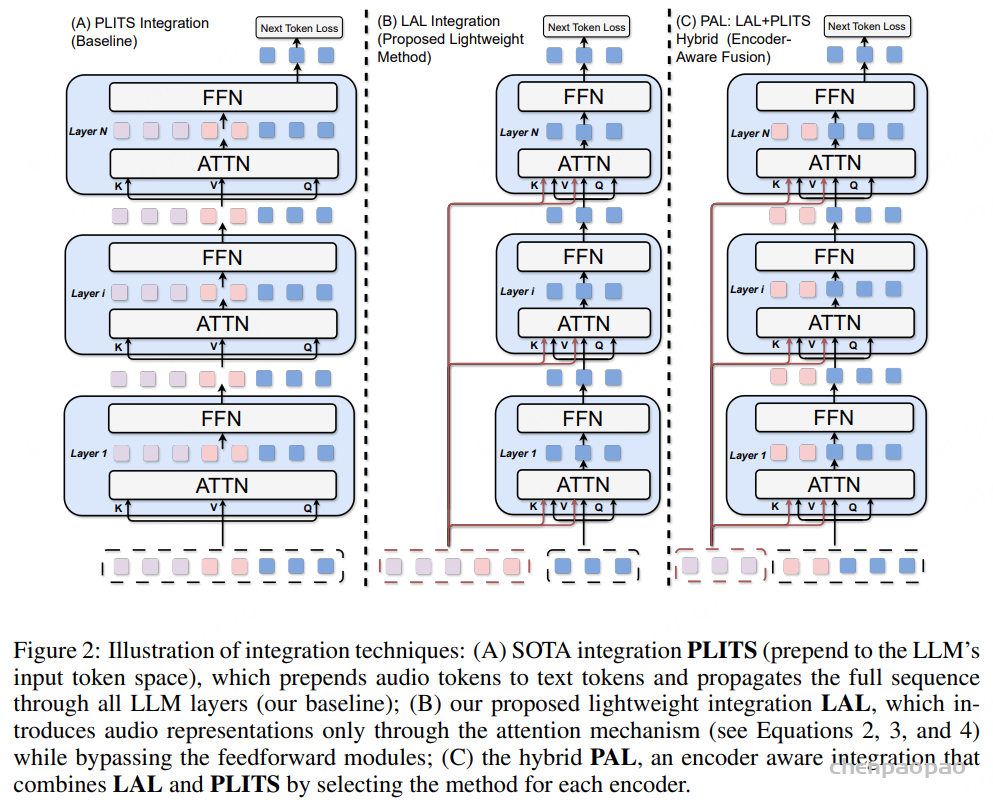
LAL:轻量级音频-LLM 集成方法:
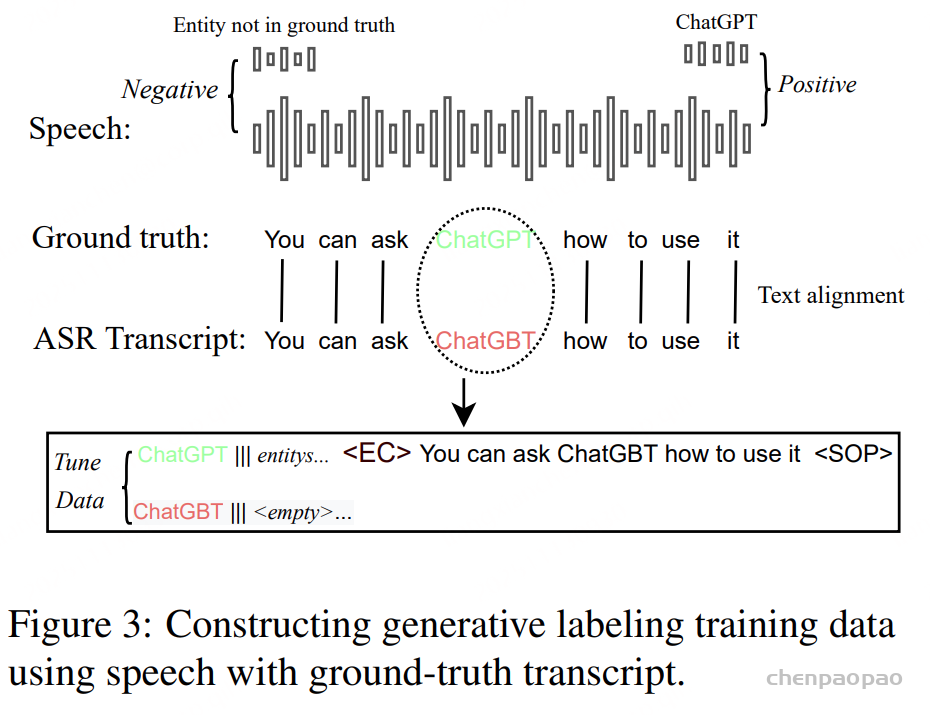
有研究表明,LLM 会将语义编码为可在隐藏状态中被选择性激活的特征。基于这一观点,提出如下假设:有效的音频-LLM 集成,并不需要对 LLM 做复杂改动,而是需要音频 token 能够触发文本 token embding 中与声音相关的概念特征。
换言之,不同的听觉输入应当在文本表示中激活相应的语言概念。例如,当输入中包含狗叫声时,与“狗”这一概念相关的特征应被激活,使模型能够将听觉信号锚定到语言层面,并正确回答诸如“当前包含哪种动物的声音?”这样的问题。该假设直接指导了我们的架构设计目标:寻找一条最简单、但又能可靠地将音频线索传递到承载语义概念的文本特征中的路径。
一个标准的 LLM 层由注意力子模块和前馈网络(FFN)子模块组成。由于注意力机制负责 token 之间的信息交互,它是音频影响文本的必要通道;同时我们认为,仅通过注意力机制,文本 token 便足以从音频中获取所需信息。
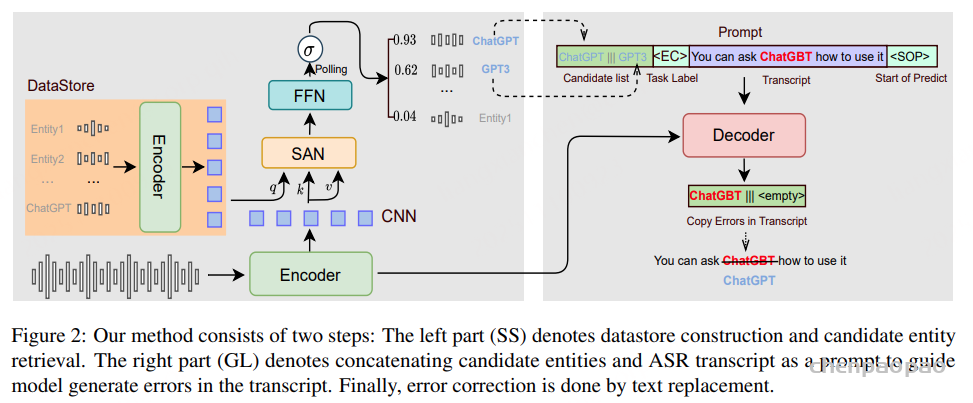
基于这一原则,我们提出了 LAL(Lightweight Audio LLM integration)。与基线方法类似,首先通过一个共享的 Q-Former 生成音频 token;在 LLM 的每一层中,使用一个 MLP 将这些音频 token 投影到该层的输入空间。随后,音频信息仅以 Key 和 Value 的形式注入到注意力模块中,而 Query 仍然仅由文本 token 构成。这样,音频只会调制文本 token 的注意力上下文,而不会经过 LLM 的前馈网络,从而实现更高效的音频-文本融合。
设第 l 层的文本隐藏状态为:Hlt∈RNt×d, Q-Former 输出的音频特征为 A∈RNa×da.在每一层引入一个投影器:Pl:Rda→Rd,将音频特征映射到该层的表示空间:
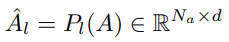
随后,在 token 维度上将文本与音频表示进行拼接:
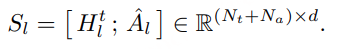
如图 2(B) 所示,Query 仅由文本 token 生成,而 Key 和 Value 则由拼接后的序列计算:
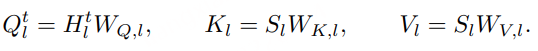
由此得到文本 token 的 LAL 更新形式为:
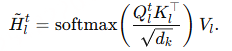
更新后的H~lt随后按照标准做法进入 FFN,并结合残差连接进行处理。通过这种方式,音频信息仅通过注意力上下文影响文本 token,使由音频激活的特征与其对应的语言概念对齐,从而实现有效的跨模态信息传递。
计算与内存效率
与 PLITS 以及 Flamingo 风格架构相比,LAL 在三个方面显著提升了效率,且随着音频序列长度的增加,这些优势会进一步放大。实验中,我们观察到最高可达 64.1% 的显存占用降低,以及最高 247.5% 的训练吞吐提升(samples/sec)。
注意力复杂度
- PLITS:在 Na+Nt 个 token 上执行完整的因果注意力,计算复杂度为:
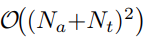
- LAL:仅文本 token 生成 Query,Key 和 Value 包含音频与文本,复杂度为
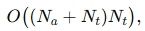
从而消除了 Na2项以及所有音频—音频之间的注意力交互。
前馈网络(FFN):
- PLITS:音频 token 在每一层中既参与注意力计算,又通过 FFN,导致浮点运算量和激活存储随 NaN_aNa 成比例增长。
- LAL:音频 token 不进入 FFN,仅作为 Key 和 Value 服务于文本 Query,从而减少了每层的浮点运算量以及反向传播所需的激活存储。
随音频长度的扩展性。
在多模态 LLM 中,非文本模态通常会产生远多于文本的 token,音频亦是如此。随着音频片段变长或 token 化更密集,Na增大,PLITS 的计算代价为 (Na+Nt)2,其中 Na2 项将占据主导。相比之下,LAL 的复杂度为 (Na+Nt)Nt,对 Na 呈线性增长。因此,音频越长或切分越细,二者在计算与内存上的差距就越大。此外,由于更多 token 绕过了每一层中最昂贵的 FFN,LAL 在前馈阶段的节省也会随 Na 的增大而进一步扩大。
相比Lora:
LAL 是一种核心架构层面的修改。LoRA 等方法主要改变训练阶段参数的适配方式,而在推理阶段基本保持原有的前向计算模式;LAL 则直接改变了注意力与 FFN 的路由方式,因此其计算与内存效率的收益不仅在训练阶段成立,在推理阶段同样适用。
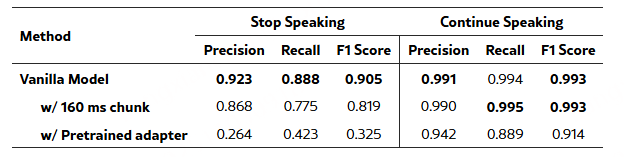
冻结 LLM FFN 的 LAL 集成:验证了在冻结 LLM 前馈网络(FFN)模块的情况下,LAL 集成方式仍然保持有效,且性能并未出现显著下降。这一结果对于降低训练成本、提升参数效率,以及在实现多模态对齐的同时保留 LLM 预训练知识,具有重要意义。出于表述清晰与实验一致性的考虑,本文的主要实验仍聚焦于 FFN 可训练的标准设置。
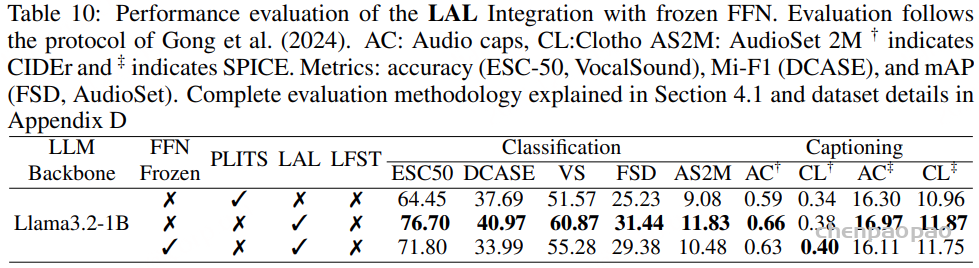
参数化知识与上下文知识的利用。
LAL 如何高效利用预训练 LLM 中内在的两类知识:(1)参数化知识,主要源于大规模语言预训练并嵌入于 FFN 层中;(2)上下文知识,通过注意力机制动态地引入和调制。
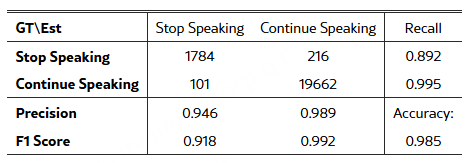
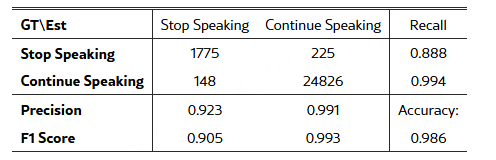
LAL 的实验成功(见表 1 和表 2)表明,音频输入作为一种上下文信息,可以仅通过基于注意力的调制,在文本 token 表征中激活所需的概念,而无需对音频表示进行直接的 FFN 处理。由此,音频信息得以间接访问 LLM 的参数化知识:音频上下文“搭载”在文本 token 之上,注意力机制对其表征进行重构,进而在 FFN 处理中触发与相关概念对应的路径。该策略不仅在架构效率上具有优势,也为多模态信息融合机制提供了更为深入的理解。
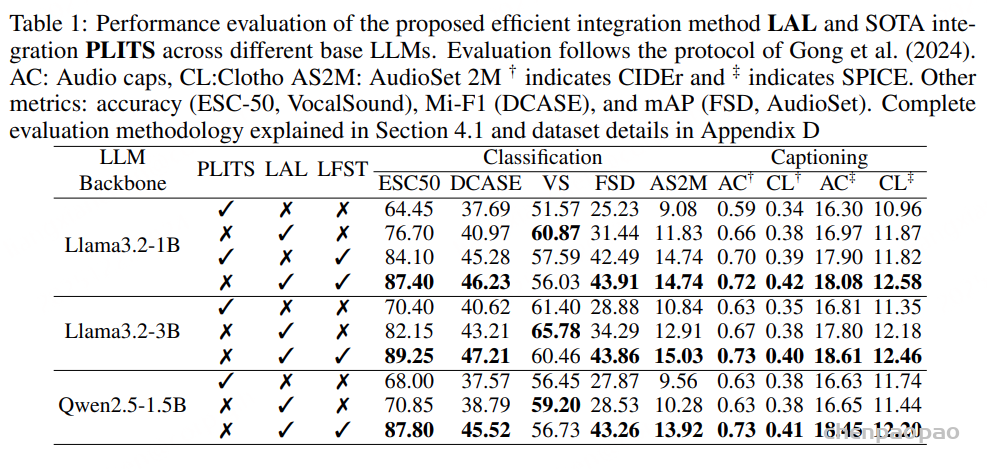
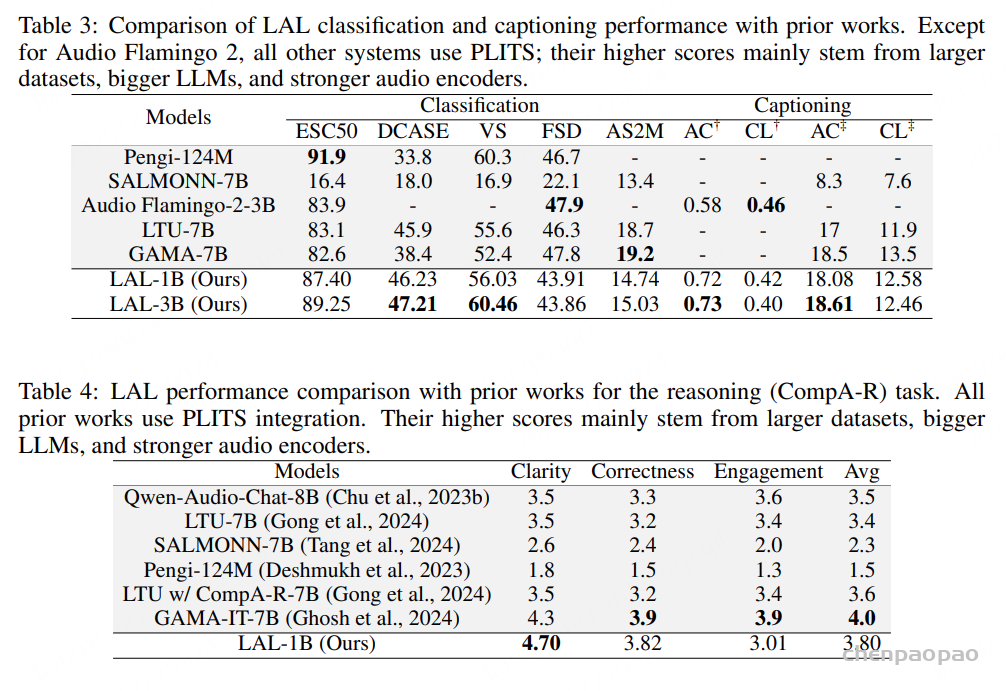
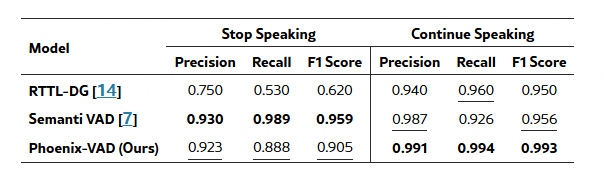
LAL 的实证评估。在多种基础 LLM 上对 LAL 进行了训练与评估,覆盖通用音频任务,包括分类、描述生成(captioning)和推理。在表 1(分类与描述生成)和表 2(推理)中,我们给出了 LAL 与 PLITS 的受控对比,结果表明 LAL 在推理速度与内存占用更优的同时,能够达到与 PLITS 相当甚至更高的准确率。其次,在表 3(分类与描述生成)和表 4(推理)中,我们将 LAL 与已有方法进行了比较。需要注意的是,不同先前方法在训练数据规模和模型规模上存在显著差异,而我们的模型实验训练在这两个维度上均处于较低水平。
这些实验结果不应被简单理解为“全面优于所有方法”,而应被解读为一个更有说服力的结论:即在使用更少训练数据、更小模型、计算资源更受限的情况下,LAL 能够达到与现有方法相当的性能水平,表现出良好的竞争力。

PAL:一种面向编码器的、在 LAL 基础上扩展语音理解能力的架构
前文已经证明:
- LAL:高效、省算力,适合通用音频(general audio)
- PLITS:计算更重,但允许音频 token 在 LLM 内部被“语言化”处理
本节提出的关键问题是:
是否所有音频编码器都适合用 LAL?还是有些情况下必须用 PLITS?
对于 Whisper 语音编码器在 情感识别、性别分类 等任务上:PLITS 明显优于 LAL,这一现象与经典神经语言学理论相符:Wernicke 区主要负责语言理解,长期以来被认为处理书面语和口语,而角回则支持跨听觉、视觉及其他感官输入的关联。类比而言,语音特征在结合语言上下文进行解释时最为有用,而通用音频则受益于模态专属的处理通路。
语音(speech)-人类声音
→ 本质上是“语言的声学形式”
→ 在 LLM 内部、结合语言上下文进行解码更有价值
→ 因此更适合 PLITS(直接进入 LLM token 流)
通用音频 / 音乐 / 事件音
→ 非语言模态
→ 更适合走 模态专属通路
→ 用 LAL 即可
基于此,我们提出了 PAL(Probing the Audio Encoders via LLM),一种面向编码器的混合集成架构,可根据不同编码器选择合适的集成方式:通用音频编码器(SSLAM 和 CLAP)采用 LAL 集成,而语音编码器 Whisper 采用 PLITS 集成.
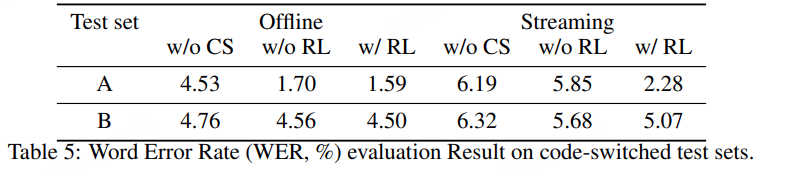
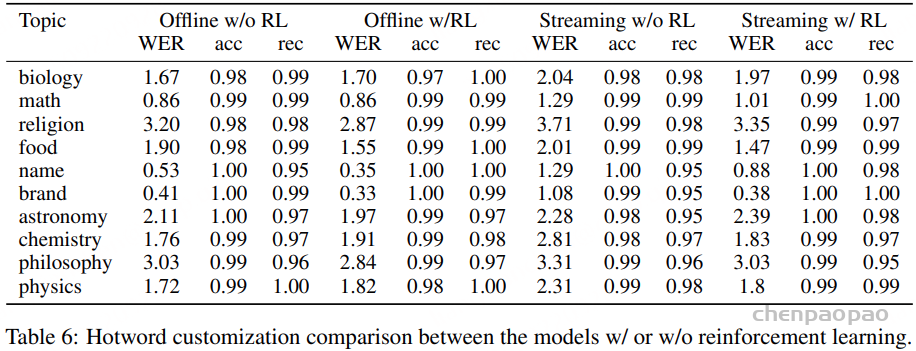
PAL 的实验评估:我们在涵盖语音、音乐和通用音频的统一 instruction tuning 数据集上训练 PAL,并在分类与推理基准上进行评测。结果显示,在分类任务中(表 5)以及推理任务中(表 6 和表 7):

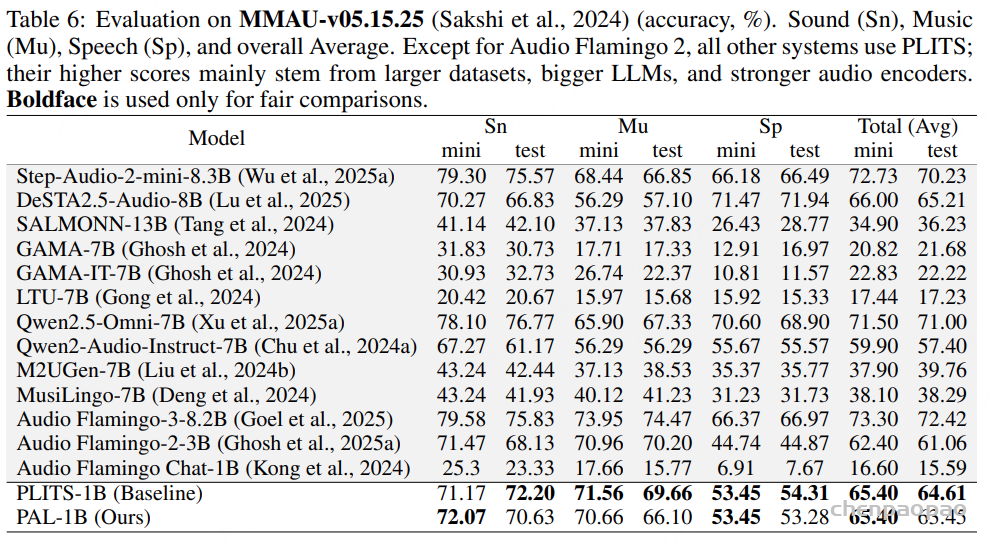
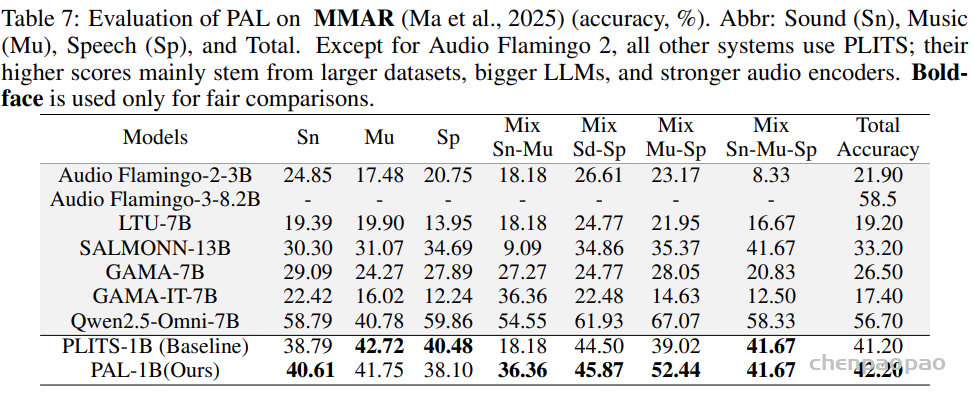
PAL 的准确率与 PLITS 相当,同时保持了更高的计算效率。
Whisper 的“副作用”:对非语音任务也有帮助:
此外,我们观察到引入 Whisper 编码器后,通用音频(sound)和音乐任务的性能有所变化。我们推测,这是因为 Whisper 会编码背景声音,从而具备一定的事件检测能力。
在 PAL 与 PLITS 的对比中,我们严格控制实验条件,使用相同的 backbone、数据和训练超参数。除 Audio Flamingo 2 外,其他系统均基于 PLITS。表7种一些已有系统(Qwen2.5-Omni-7B)在指标上高于 PLITS,主要是因为它们使用了更大的训练数据集、更大的语言模型(LLM)以及更强的音频编码器。
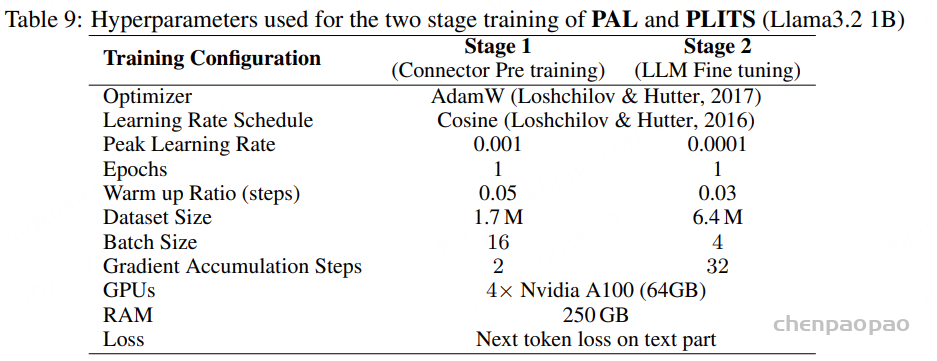
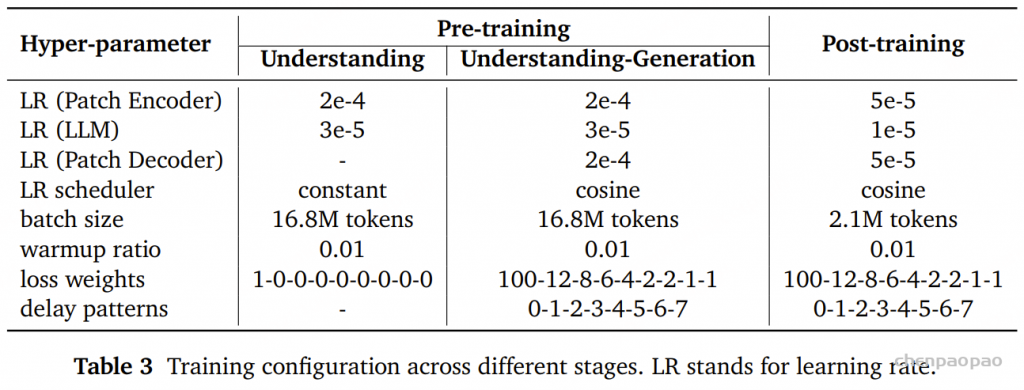
PAL 采用两阶段训练流程(见表 9)。在阶段一中,我们以用于 LAL 的阶段一数据集为基础,并额外引入来自 OpenASQA的、以语音理解为重点的数据进行增强。在阶段二中,我们在一个经过精心整理的音频、语音与音乐推理指令数据集 AudioSkills上进行微调。由于部分源数据集的原始音频文件不可获取,我们使用了 AudioSkills 中的 600 万条样本子集(原始规模为 1000 万)。
实验
LAL:实验设置
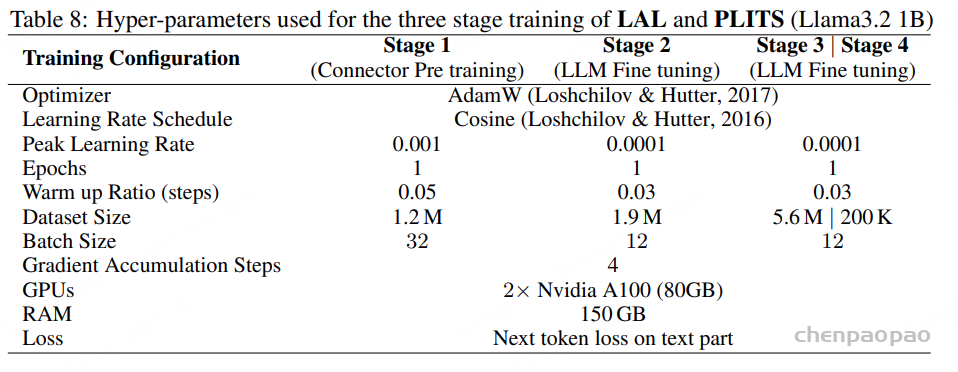
训练流程(Training Protocol)
在两个目前规模最大的通用音频指令微调数据集上训练所提出的音频 LLM 变体:OpenAQA和 CompA-R。整体采用两阶段训练流程:
1)连接器预训练阶段:仅训练音频-文本connector,其余模块全部冻结;
2)联合训练阶段:同时训练connector和 LLM。
在整个训练过程中,音频编码器始终保持冻结状态。
针对推理和开放式问答任务,我们进一步增加两个训练阶段:
- 阶段 3:使用 OpenAQA中的开放式问答数据进行训练;
- 阶段 4:使用推理数据集 CompA-R进行训练。
采用 OpenAQA提出的两阶段训练设置对 LAL 进行训练,并据此获得表 1 中的实验结果。此外,我们还在 OpenAQA提供的更大规模开放式数据以及推理数据集 CompA-R上进行训练,其评测结果见表 2。
评测流程(Evaluation Protocol)
为了评估 LAL 是否能够有效地将关键音频事件信息从编码器传递到 LLM 的潜在表示空间中,我们在下游的分类、描述生成(captioning)和推理任务上进行评测。
- 分类任务:使用
gpt-text-embedding-ada对模型输出文本和目标音频标签进行编码,并计算语义相似度;
- 描述生成任务:在标准音频描述数据集上评测,报告 CIDEr 和 SPICE 指标;
- 推理任务:采用 CompA-R-test 以及 Ghosh 的评测协议,通过一个纯文本的 GPT-4 评审模型,结合音频事件的辅助元数据,对音频-LLM 的输出在 有用性(Helpfulness)、清晰度(Clarity)、正确性(Correctness)、深度(Depth)和参与度(Engagement) 五个维度进行打分。
PAL:实验设置
训练流程:PAL 采用与 LAL 相同的两阶段训练流程。音频编码器在整个过程中同样保持冻结。
在阶段 1 中,构建了一个混合数据集:以通用音频 OpenAQA 的 Stage 1 数据为基础,并加入用于语音理解的 OpenASQA Stage 1 划分。
在阶段 2 中,使用一个精心整理的音频、语音和音乐推理指令微调语料,即 AudioSkills中的 600 万条子集。
语音理解评测:语音识别以及说话人性别分类。这些任务在阶段 1 训练完成后进行评测,用以衡量新引入的 Whisper 编码器与 LLM 的集成效果。随后,在 MMAR 和 MMAU 基准上评测通用音频、音乐以及语音推理能力,并报告细粒度的类别级性能结果。
总结:
提出了 LAL,一种仅通过注意力机制中的 Key 和 Value 注入音频信息、并跳过音频 token 的前馈网络(FFN)处理的轻量级集成方式。该方法减少了注意力交互与中间激活,在分类、描述生成和推理任务上保持与当前最先进基线 PLITS 相当的性能的同时,实现了 最高 64.1% 的显存占用降低 和 最高 247.5% 的训练吞吐提升。
此外,我们提出了 PAL,一种 编码器感知(encoder-aware) 的混合集成框架:对 SSLAM 和 CLAP 采用 LAL,而对 Whisper 采用 PLITS,因为 Whisper 能从 LLM 内部的解码过程中获益。
需要强调的是,LAL 属于核心架构层面的改动,而非参数高效微调(PEFT)方法,因此其效率收益在 训练阶段和推理阶段 均可体现。
在未来工作中,我们计划扩展到更大规模的基础模型,使用更高质量的指令数据以提升推理能力,并探索 流式处理 与 长上下文音频 场景。
PS:数据集说明:
VocalSound:VocalSound 数据集包含 21,024 条众包采集的语音录音,覆盖 6 类不同的发声表达,来自 3,365 名不同的受试者。
ESC-50:ESC-50 数据集由 2,000 条 5 秒长的环境音频片段组成,划分为 50 个类别。
DCASE2017 Task 4:DCASE 2017 Task 4 包含 17 种声音事件,分为“Warning”和“Vehicle”两大类,其评测集包含 1,350 条音频片段。
FSD50K:FSD50K 的评测集包含 10,231 条音频片段。我们在该评测集上进行评估,并报告多标签分类任务的 mAP(mean Average Precision)指标。包括人类声音 、 事物声音 、 动物声音、 自然声音和音乐 。
AudioSet:其中包含来自 YouTube 的 10 秒音频片段,这些片段按照 AudioSet 本体论被标注为一个或多个声音类别。
AudioCaps:AudioCaps 的评测集包含 901 条音频,每条音频配有 5 条文本描述,共计 4,505 对音频-描述样本。
Clotho V2:Clotho V2 的评测集包含 1,045 条音频,每条音频配有 5 条描述,共计 5,225 对音频-描述样本。
复杂音频推理 (CompA-R)是一个合成生成的指令调优 (IT)数据集,其中包含要求模型对输入音频进行复杂推理的指令。











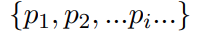


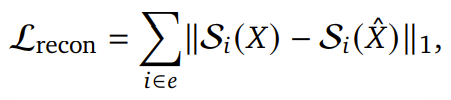
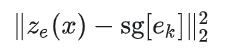
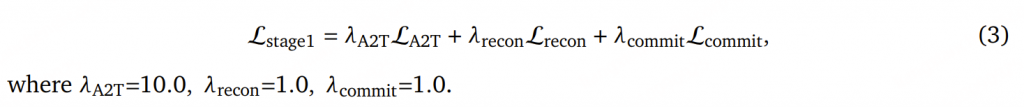





{kind=link}