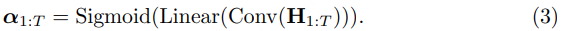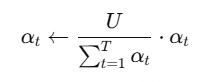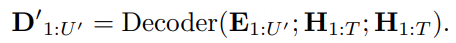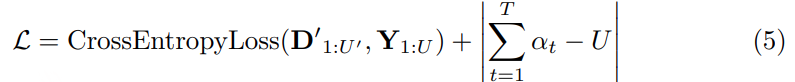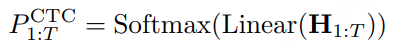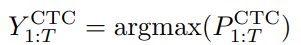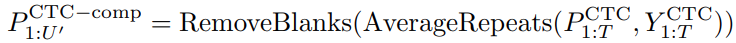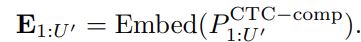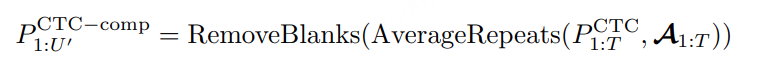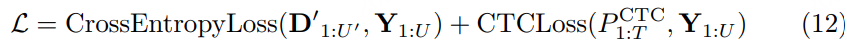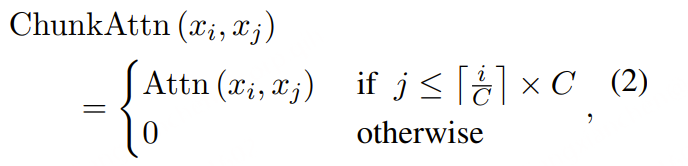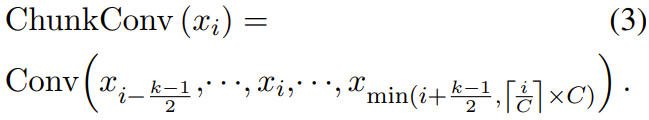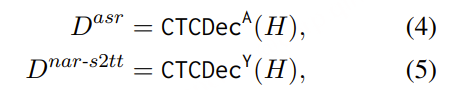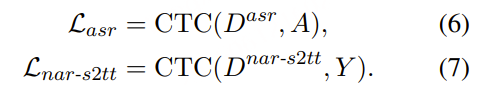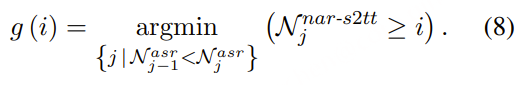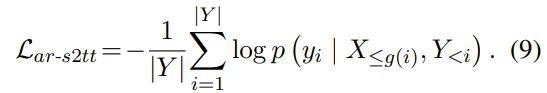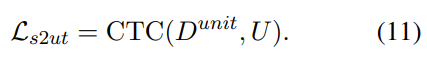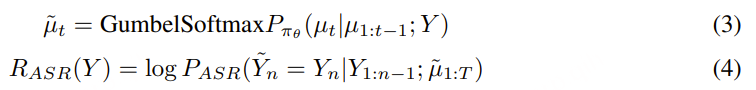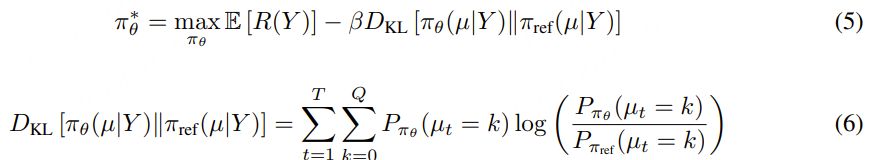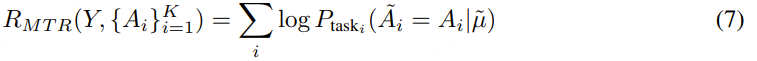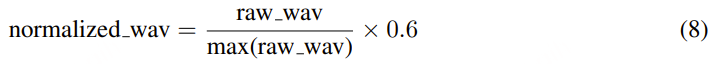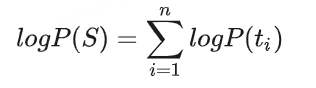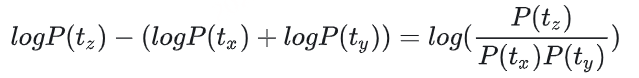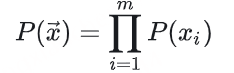CosyVoice 2 在语言覆盖范围、领域多样性、数据量和文本格式多样性方面 存在明显局限性,在实现野外语音生成方面仍有较大改进空间。阿里巴巴团队全新发布的CosyVoice 3 ,以超越人类基线的自然度、覆盖 9 国语言 18 种方言 的超强泛化能力,重新定义了「野外语音生成」的标准。
摘要
尽管 CosyVoice 2 在中文和英文广播场景中表现良好,但它在语言覆盖范围、领域多样性、数据规模以及文本格式多样性方面仍存在明显局限,距离实现真实环境中的语音生成还有较大提升空间。此外,针对语音生成模型的模型和数据的扩展规律,以及训练后的优化技术尚未被充分探索。
为了解决上述问题,我们推出了 CosyVoice 3 —— 一款面向真实环境应用的大规模零样本语音生成模型,具备更广泛的语言覆盖和多样化的使用场景,在内容一致性、说话人相似度和韵律自然度等方面显著超越其前代产品 CosyVoice 2。
我们的主要贡献如下:
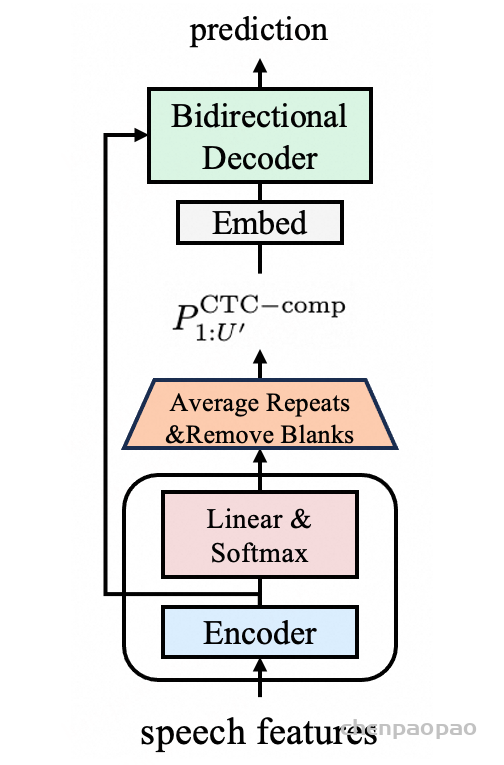
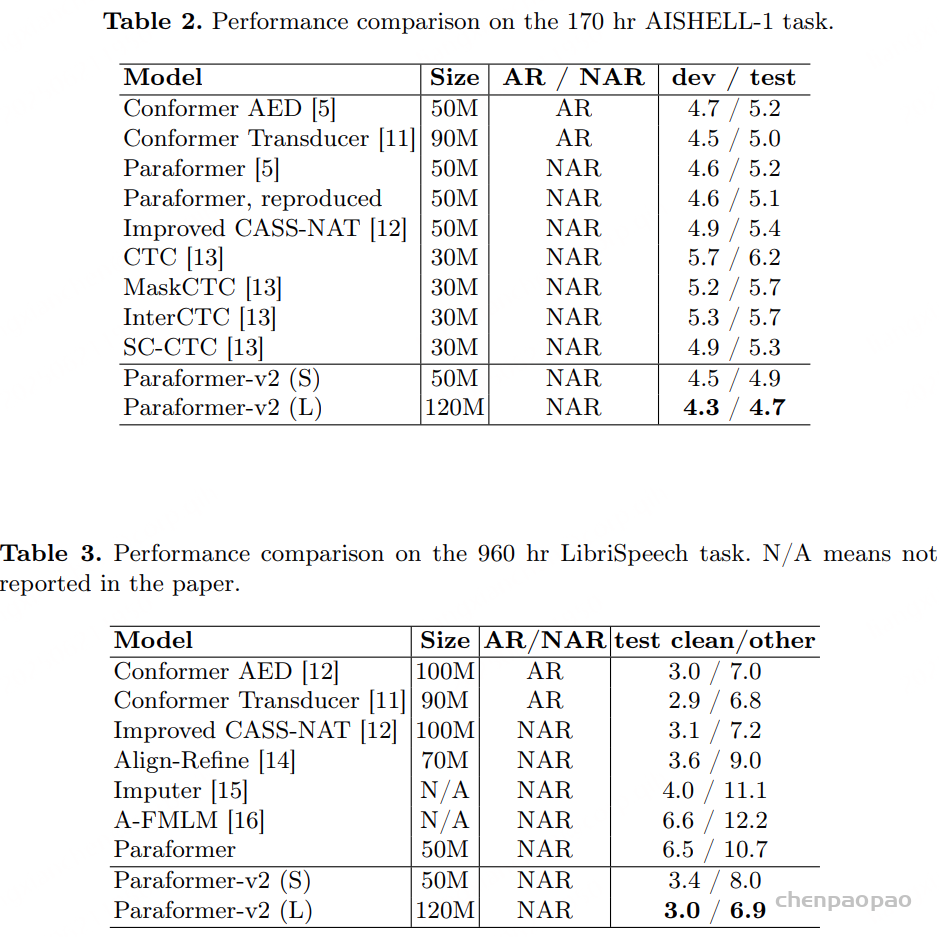
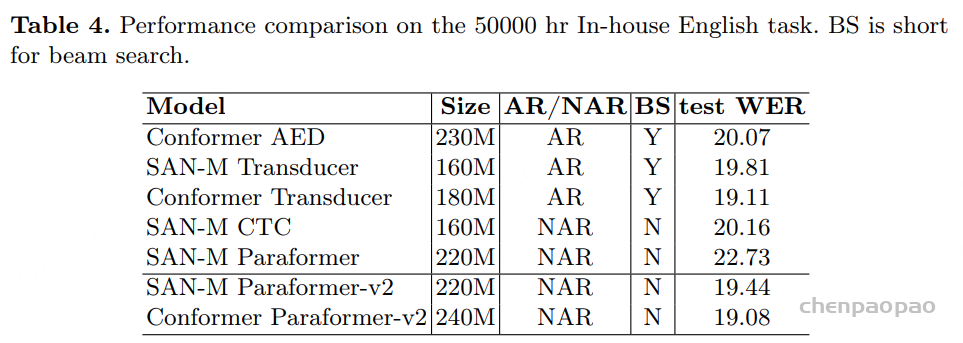
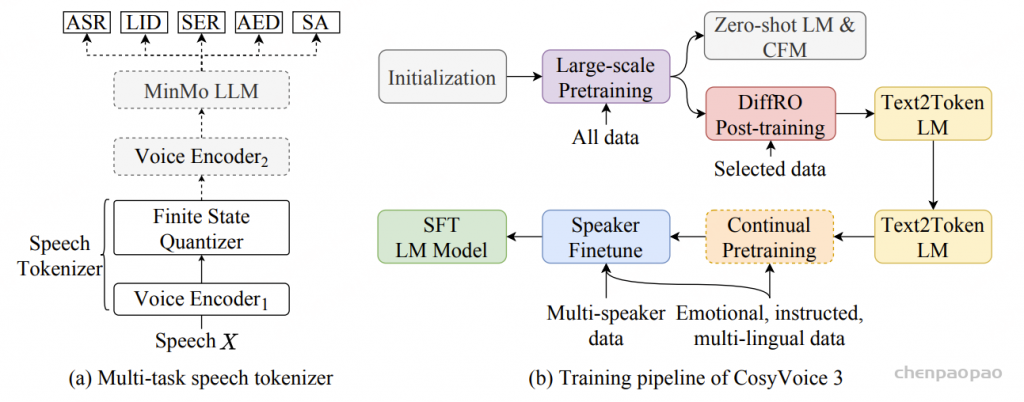
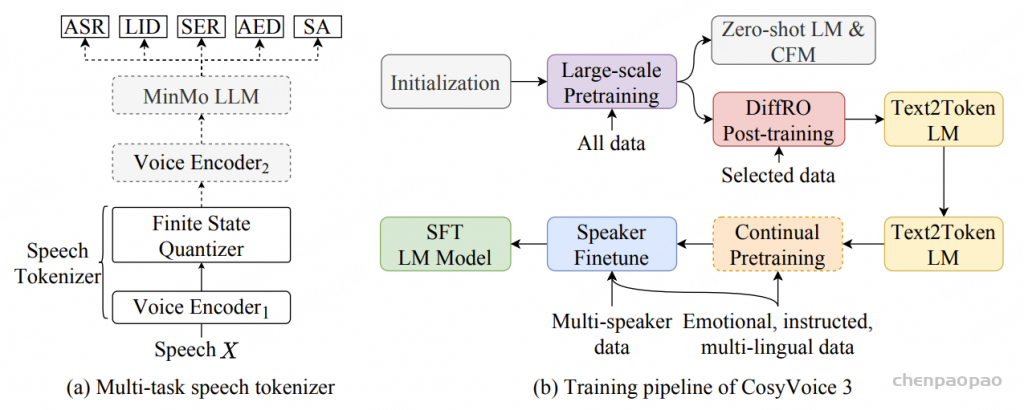
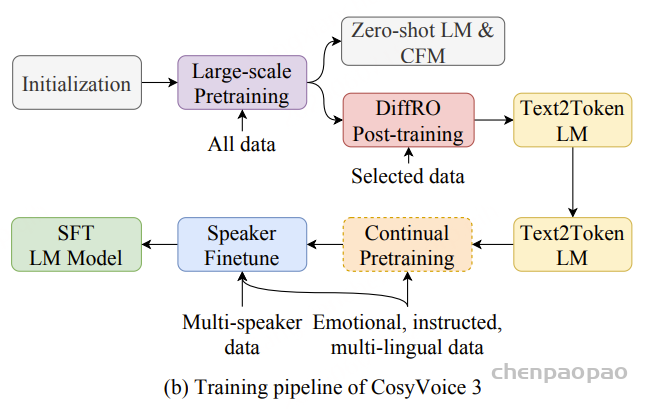
1)通过监督多任务训练开发的新型语音分词器 ,用于改善韵律自然度,包括自动语音识别、语音情感识别、语言识别、音频事件检测和说话人分析 。 2)一种适用于后期训练的新型可微分奖励模型[DiffRO],不仅适用于 CosyVoice 3,还适用于其他基于 LLM 的语音合成模型。 3)数据集规模扩展:训练数据从万小时扩展到百万小时,涵盖 9 种语言和 18 种汉语方言,跨越多个领域和文本格式 。 4)模型规模扩展:模型参数从 5 亿增加到 15 亿 ,由于更大的模型容量,在多语言基准测试中性能得到提升。这些进展显著推动了野外语音合成的发展。 为应对真实世界中语音合成场景的多样性与泛化挑战 ,我们发布了面向零样本真实场景语音合成的评测基准集 CV3-Eval 。该基准集基于 Common Voice、FLUERS、EmoBox 及网络爬取的真实音频数据构建,涵盖广泛的语言与方言、应用领域与环境、情绪与风格。技术方案 图2:(a)监督式多任务训练的语音分词器 和(b)CosyVoice 3 的训练流程示意图。虚线框中的模块仅在训练阶段使用。语音分词器通过监督训练,涵盖自动语音识别(ASR)、语言识别(LID)、语音情感识别(SER)、音频事件检测(AED)以及说话人分析(SA)等任务。CFM 表示条件流匹配模型(Conditional Flow Matching model)。 通过监督多任务训练实现语音分词器
CosyVoice 3 的语音分词器基于 MinMo语音大模型[基于sensevoice-large的encoder],这是一种在多个语音任务中表现优异的大规模预训练语音理解模型。
与 CosyVoice 2 将有限标量量化(FSQ)模块插入 SenseVoice-Large ASR 模型的编码器不同,CosyVoice 3 将 FSQ 模块插入到了 MinMo 模型的语音编码器 【也是 SenseVoice-Large encoder,但重新进行了多任务训练】中。相比于 SenseVoice-Large ASR 模型,MinMo 是一款更为先进的多模态大语言模型(LLM),在超过140万小时的语音数据上进行了训练,在多种基准任务中展现出更优越且达到了SOTA水平的表现,包括口语对话、多语种语音识别、以及情感识别等任务。
为了进一步增强语义信息的捕捉能力,我们在 MinMo 的训练数据中选取了约53万小时的数据子集,针对我们的语音分词器进行监督多任务学习 ,涵盖了多语种ASR、语言识别(LID)、语音情感识别(SER)、音频事件检测(AED)以及说话人分析(SA)等任务 。
在训练阶段,如图2a所示,输入语音 X 首先经过 Voice Encoder1 【 SenseVoice-Large Encoder 】得到中间表示 H,其中 Voice Encoder1 包含12个带旋转位置嵌入(RoPE)的Transformer模块。接着,中间表示H 被送入 FSQ 模块进行量化,量化后的表示再传递至 MinMo 的其余模块,包括 Voice Encoder2 和 MinMo LLM,用于预测对应文本标记的后验概率。
Voice Encoder1、FSQ 模块中的低秩投影器、有限舍入操作(bounded round operation)以及索引计算模块共同构成了 CosyVoice 3 的语音分词器。我们的语音分词器的标记速率为 25 Hz,即每秒生成 25 个语音标记(speech tokens)。
可微奖励优化的强化学习
强化学习(RL)在提升生成语音质量方面是有效的,目前尚未建立一个通用适用于语音生成任务的强化学习方法论。与自然语言处理任务中的大语言模型(LLMs)不同,TTS 系统需要额外的下游条件流匹配(CFM)模块和声码器模型 ,将离散的语音标记转换为音频波形。这些下游模型带来了巨大的计算负担。更严重的是,经过下游处理后生成的语音通常表现出高度相似性,因此在训练奖励模型时,很难区分正反馈与负反馈 。
为了解决这些问题,我们提出了可微奖励优化(DiffRO) 方法,该方法直接优化语音标记 ,而非合成音频。DiffRO 首先在 ASR 训练数据上训练一个类似 ASR 的 Token2Text 模型,并将后验概率作为奖励。为了进一步简化训练策略,DiffRO 使用 Gumbel-Softmax 操作对大语言模型预测的标记进行采样,并通过反向传播直接优化语音标记,以最大化奖励分数,而无需传统的强化学习训练循环。
Gumbel-Softmax 是一种用来在离散空间中实现可微分采样 的技巧,常用于需要从分类分布中抽样但又想保持梯度可传播的场景,比如强化学习中的策略采样、生成模型中的词生成,以及如 DiffRO 中对离散语音 token 的优化。
其中,µₜ 和 µ̃ₜ 分别表示第 t 个时间步的真实语音标记和其采样预测值。RASR ASR
除了 Token2Text 模型之外,DiffRO 还利用情感识别(SER)、MOS 评分预测、音频事件检测(AED)以及其他音频理解任务,用于多任务奖励(MTR)建模 。MTR 机制可以帮助 TTS 系统根据指令控制语音属性Ai
发音修复
基于大语言模型的语音合成(TTS)系统主要采用基于BPE的文本分词器,输入为原始文本 。与传统的基于音素的方法相比,这类系统在发音的可控性方面存在不足 。具体来说,对于由多音字 或训练数据中稀少或未出现的罕见词 引起的错误发音,缺乏基于人工干预的稳健方法。通过扩充分词器词汇表来建模混合的词和音素序列 。为实现该目标,我们构建了一个辅助训练集,将中文单音字替换为拼音 ,将英文单音词用CMU发音词典中的音素替换 ,并将该辅助数据集加入基础训练集中。
文本规范化的自我训练
在文本分词之前,TTS系统通常通过文本规范化(TN)模块处理原始文本,将数字和特殊符号转换为其对应的口语化文本 ,这一过程依赖大量手工设计的规则;然而,手工规则在覆盖特殊符号方面面临持续挑战。利用大语言模型(LLM)执行文本规范化任务,从而构建更加统一的端到端TTS系统。 以原始文本为输入 ,我们采用三种方式构建辅助训练集:通过内部基于规则的文本规范化模块处理原始文本,得到规范化文本,再通过CosyVoice 2合成音频。 利用Qwen-Max模型进行文本规范化,然后对规范化文本通过CosyVoice 2合成音频。 利用Qwen-Max对已有的文本-音频对中的文本进行逆向文本规范化,恢复为原始(未规范化)文本,将该原始文本与对应音频作为配对样本,直接加入基础训练集。
指导式语音生成
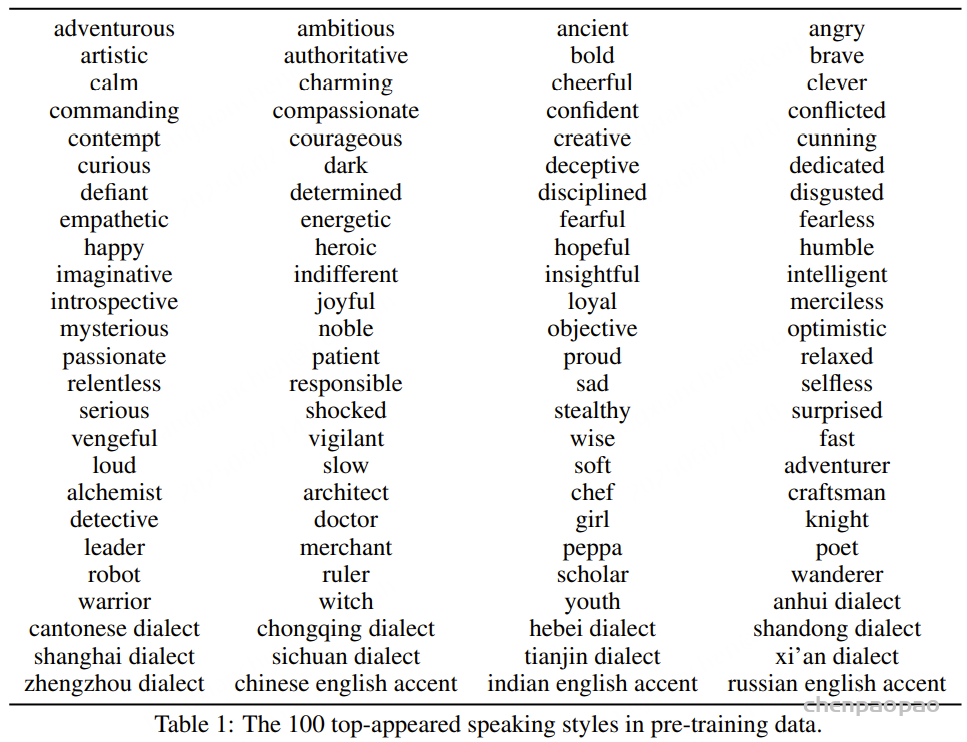
为了提升CosyVoice 3的可控性和表现力,相较于CosyVoice 2,我们在基础训练集中融入了更多富有表现力的语音数据。高质量指令跟随数据的时长从1500小时扩展到5000小时,覆盖了更广泛的类型,包括情感、语速、声调、方言、口音及角色扮演。类型总数增加到100多种,如表1所示。自然语言指令 ,在合成语音的输入文本前添加自然语言描述及特殊结束标记“<|endofprompt|>” 。细粒度指令 ,支持在文本标记间插入声音爆发(vocal bursts)和声音特征标签以实现控制 。例如,输入文本中的“[laughter]”与“[breath]”标记可分别用来生成明显的笑声和呼吸声。标签“<strong>XXX </strong> ”用于强调特定词语。
说话人微调中的能力迁移
将单语说话人转变为多语者 :CosyVoice 3 相较于前代的显著提升之一是语言支持的扩展。为了使单语目标说话人能够说多种语言,我们构建了一个辅助训练数据集,包含来自随机选择说话人的高质量单语录音,覆盖所有支持的语言。每条语音的说话人ID和语言ID均通过自然语言指令进行指定。
指令生成能力的迁移 :通过对预训练模型进行说话人特定数据的微调,可以提升个别说话人生成语音的质量和表现力。我们构建了一个部分标注说话人ID的训练数据集,该数据集包含目标说话人的高质量数据以及预训练时使用的指令跟随数据集。在自然语言指令提示中,我们指定说话人提示和风格提示。例如,一个完整的指令提示可能是:“你是说话人A,请高兴地和我说话。”然而,部分数据条目可能缺少说话人ID或风格标签,此时在提示中对应字段留空。微调过程中,我们还会随机屏蔽说话人提示或风格提示,以增强模型的迁移能力。
多语言数据处理流程
语音检测与分段 降噪 自动语音识别(ASR)转录 标点调整 音量标准化 过滤异常音频-文本长度比例的数据 语音检测与分段 :原始数据依次通过说话人分离(speaker diarization) 、语音活动检测(VAD) 和音频事件检测模块 处理,得到说话人级别且时长小于30秒的语音片段 。该步骤虽采用内部模块,但同类开源方案也能实现类似效果。
降噪: 采用MossFormer2模型进行降噪。接着,根据语句起始和结束帧的能量水平,筛除因异常截断导致开头或结尾单词不完整的语句 ;剩余语句去除开头和结尾的静音后保留用于后续处理。
ASR转录: 为获得足够可靠的文本转录,首先使用FasterWhisper Large-V3进行语言识别,然后分别使用多款开源ASR模型(包括Faster-Whisper Large-V3、NVIDIA NeMo Canary-1B、Meta FAIR seamlessM4T-V2-large)对语句进行转录。随后进行交叉验证,选取不同系统ASR结果间平均成对字错误率 (WER)低于15%的转录结果 。
标点调整:由于ASR生成文本中的标点可能不能准确反映对应音频的实际停顿 ,我们采用Montreal Forced Aligner计算词与词、句或短语间的时长,并根据预设阈值对标点进行增删(停顿时间≥300毫秒时添加逗号,≤50毫秒时移除表示停顿的标点,如逗号、分号、冒号、句号、问号和感叹号)。
音量标准化:对音量进行简单直接的归一化处理,
过滤异常音频-文本长度比例的语句 :在完成上述所有处理步骤后,对每个生成的语音-文本对提取语音标记和文本标记,计算并排序语音标记长度与文本标记长度的语句级比例。
Experimental Settings
Training Data for Speech Tokenizer
使用 53 万小时的监督多任务数据集,以标准化转录为标签,训练语音分词器,包括自动语音识别 (ASR)、语种识别 (LID)、语音情感识别 (SER)、音频事件检测 (AED) 和说话人分析 (SA)。训练数据详情如表 3 所示。多语言 ASR 训练数据包括中文、英语、日语、韩语、俄语、法语和德语。
Scaling up Dataset Size and Model Size for CosyVoice 3
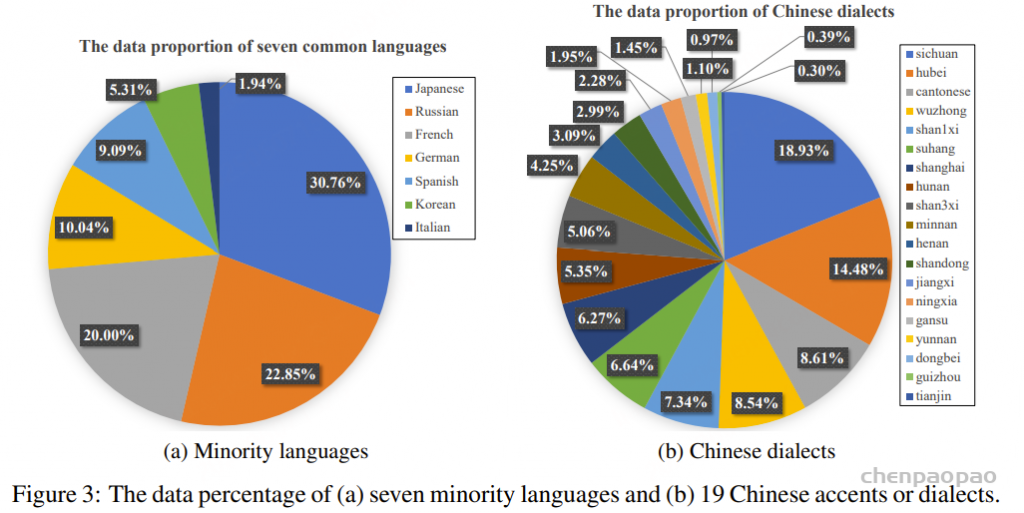
在 CosyVoice 3 中,我们从多个角度扩展数据量。针对广泛使用的中英文数据,我们采用低成本数据生产流程与自训练数据构建相结合的方式,增强领域、风格、文本格式和稀有案例的多样性。在领域多样性方面,我们收集了电商、导航、金融、教育等多个领域的语音数据。在风格多样性方面,我们添加了对话、演讲、歌唱等多种语言 。在文本多样性方面,我们通过文本规范化 (TN) 和逆文本规范化 (ITN) 为同一段语音构建不同的文本格式,增强模型对各种文本格式的鲁棒性。 此外,我们利用早期版本的 CosyVoice 3 策略性地自训练构建了大量的稀有案例,以提高合成的稳定性。在语言覆盖方面,我们在中英文数据集中新增了日语、俄语、法语、德语、西班牙语、韩语和意大利语等七种常用语言,数据覆盖比例如图 3a 所示。前期工作表明,监督式多任务语音分词器在一些新语言(例如 CosyVoice 3 中的西班牙语和意大利语)上表现良好。除了标准的常见方言发音外,我们还增加了对汉语口音和方言的覆盖范围,目前已支持 19 种常见口音或方言,数据占比如图 3b 所示。通过这些数据扩展,CosyVoice 3 的训练数据已达到百万小时,涵盖了日常生活中的大多数用户案例,并朝着自然界零样本语音生成的目标迈进。
除了扩展数据集大小之外,扩大模型大小对于当前的大规模模型至关重要。因此,我们在 CosyVoice 3 中增加了文本转语音语言模型 (LM) 和条件流匹配 (CFM) 模型的大小。具体而言,文本转语音 LM 的参数数量从 0.5 亿增加到 1.5 亿。对于 CFM,我们采用最新的扩散变换器 (DiT) 作为骨干网络,将参数数量从 1 亿增加到 3 亿。初步实验证明了 DiT 架构的强大性能;因此,复杂的文本编码器和长度正则化模块不再需要,并从 CosyVoice 3 中移除。我们通过简单的插值操作解决了语音标记和 Mel 特征之间的帧率不匹配问题。
为了评估 CosyVoice 3 的零样本语音生成能力,我们关注三个关键方面:内容一致性、说话人相似度和音频质量。对于内容一致性,我们使用 Whisper-large V3测量 ASR 转录文本与给定文本的字符错误率 (CER) 或词错误率 (WER)。对于英文 ASR,我们使用 Paraformer 测量中文 ASR。为了评估说话人相似度,我们使用 ERes2Net 说话人验证模型从生成的语音中提取说话人嵌入,并计算与参考语音嵌入的余弦相似度。对于音频质量,我们使用 DNSMOS 网络对生成的语音进行评分,该网络的得分与人类听觉感知高度相关。
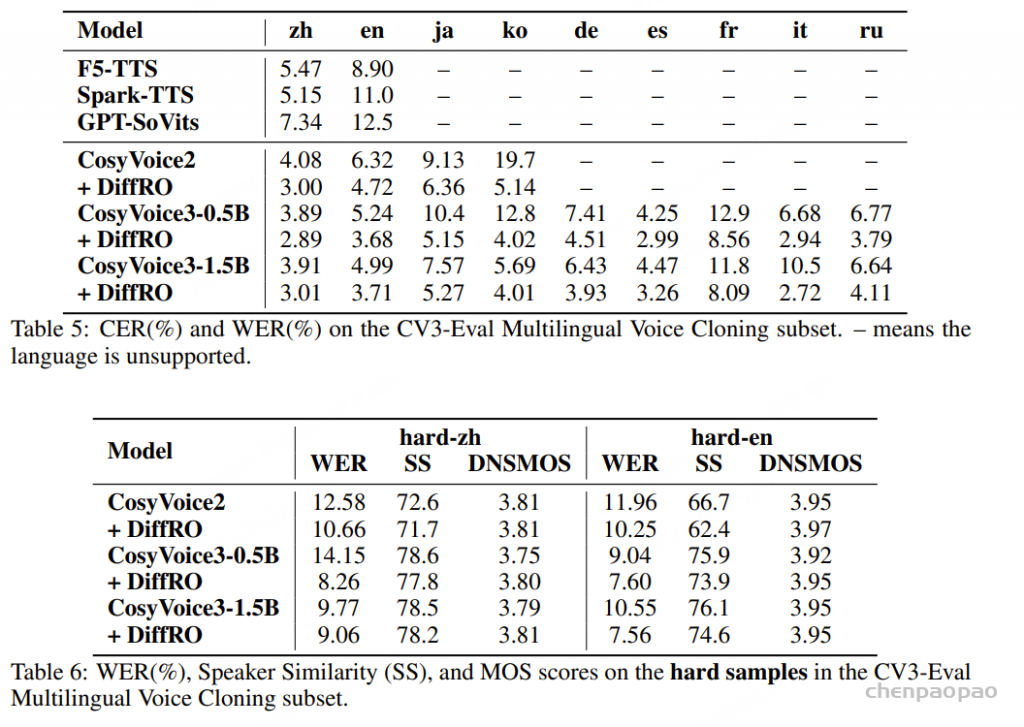
为了更好地评估 CosyVoice 3,我们建立了一个多语言基准 CV3-Eval,其中包括客观和主观评估的子集。
Experimental Results
SEED-TTS-Eval 上的客观 TTS 结果
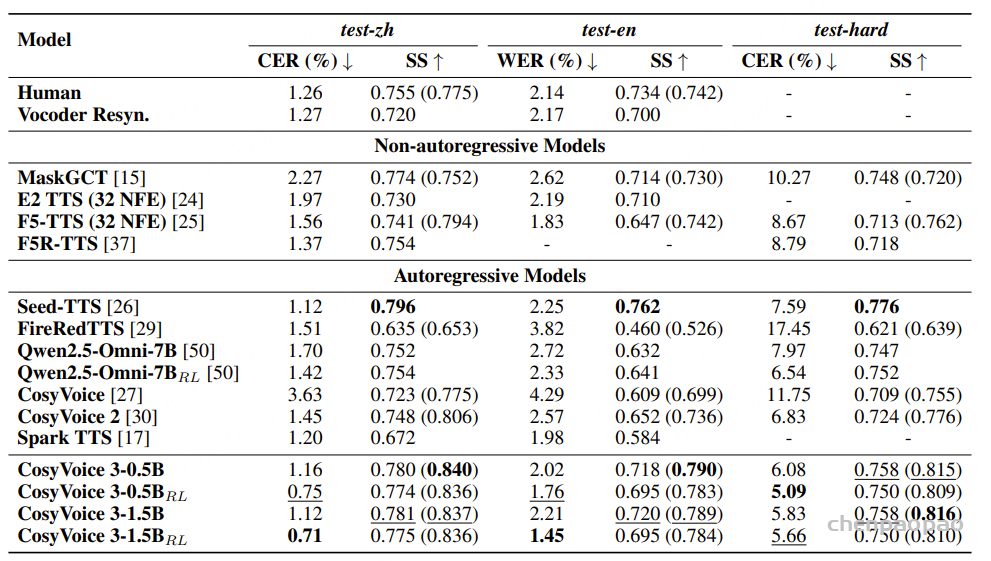
CosyVoice 3 与基线在 SEED 测试集上的内容一致性 (WER/CER) 和说话人相似度 (SS) 方面的零样本 TTS 性能比较。对于说话人相似度,括号外的结果由基于 WavLM 的模型测量,括号内的结果由 ERes2Net 测量。 粗体 表示最佳结果,下划线表示次佳结果 在多语言基准 CV3-Eval 上的客观评估:
对于 CosyVoice 3 来说,生成生僻词、绕口令和领域特定术语仍然很困难,这突显了未来有待改进的地方。
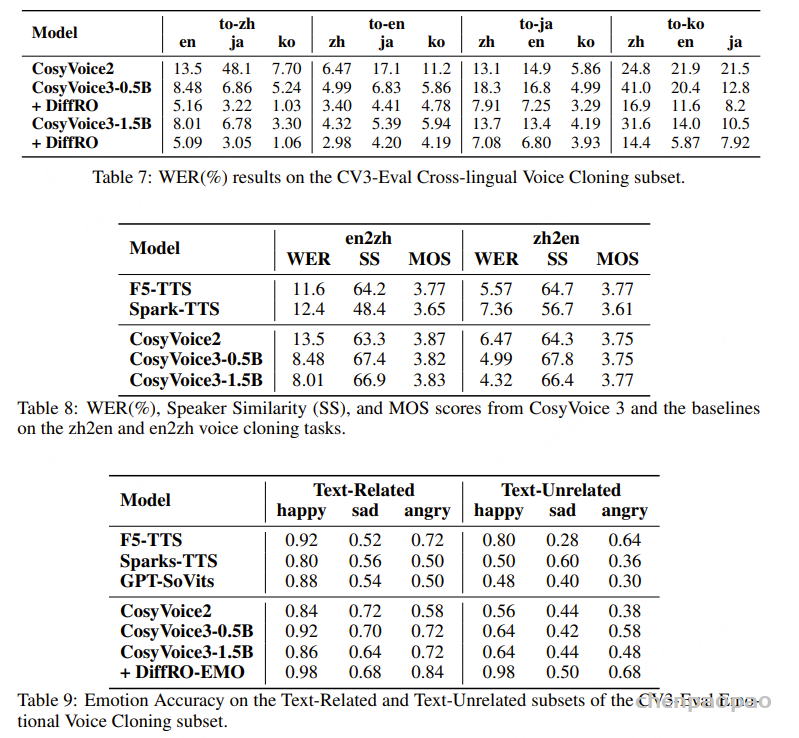
跨语言语音克隆结果:CosyVoice 3 在跨语言语音克隆方面相较 CosyVoice 2 的显著提升。值得注意的是,由于两种语言的字符重叠,CosyVoice 2 在将语音从日语转换为中文时遇到了困难。CosyVoice 3 通过将所有日语字符转换为假名解决了这个问题。此外,扩大模型规模也带来了益处:与 CosyVoice3-0.5B 相比,CosyVoice3-1.5B 在所有条件下都表现出了更佳的字错误率 (WER),同时保持了与 CosyVoice 2 相似的说话人相似度。这表明,由于容量的增加,更大的模型可以提升在挑战性任务上的表现。总体而言,CosyVoice3-1.5B 仍然是 zh2en 和 en2zh 跨语言语音迁移任务中的领先模型。
在与文本无关的任务中,情感准确率显著下降,尤其是“悲伤”和“愤怒”情感。这表明 TTS 系统主要从文本情绪中推断输出音频的情感基调。这一观察结果为了解不太令人满意的表现提供了宝贵的见解,并突出了未来需要改进的地方。
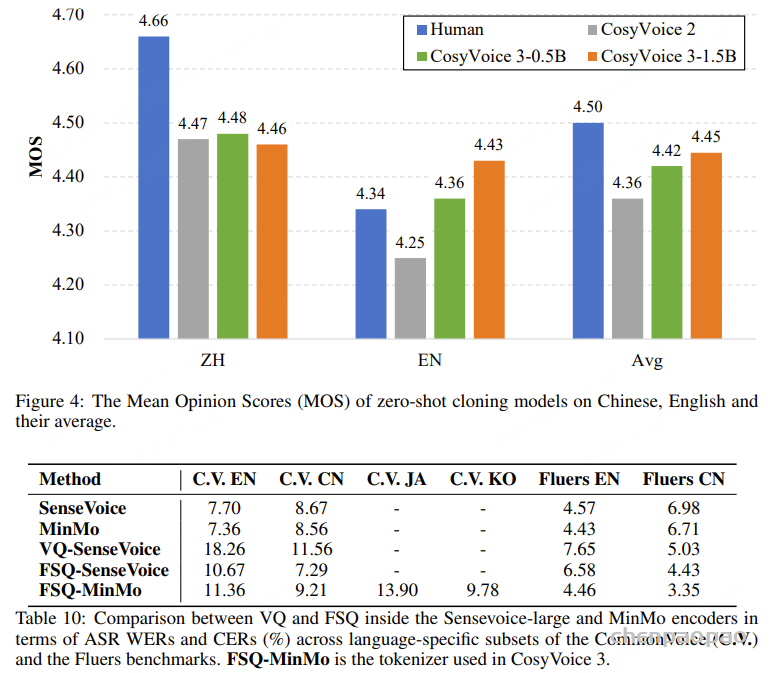
主观评价结果: