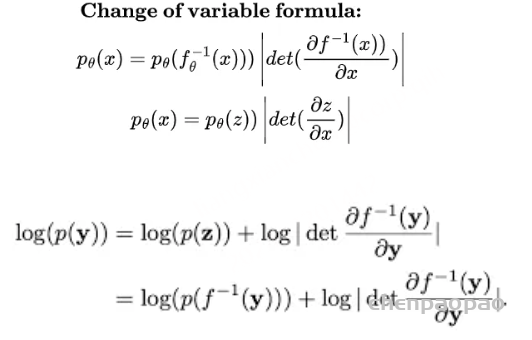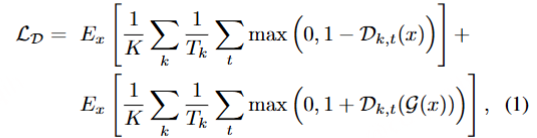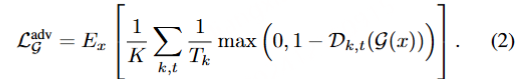This is a curated list of open speech datasets for speech-related research (mainly for Automatic Speech Recognition).
Over 110 speech datasets are collected in this repository, and more than 70 datasets can be downloaded directly without further application or registration.
Notice:
This repository does not show corresponding License of each dataset. Basically it’s OK to use these datasets for research purpose only. Please make sure the License is suitable before using for commercial purpose.
Some small-scale speech corpora are not shown here for concision.
1. Data Overview
Dataset Acquisition
Sup/Unsup
All Languages (Hours)
Mandarin (Hours)
English (Hours)
download directly
supervised
199k +
2110 +
34k +
download directly
unsupervised
530k +
1360 +
68k +
download directly
total
729k +
3470 +
102k +
need application
supervised
53k +
16740 +
50k +
need application
unsupervised
60k +
12400 +
57k +
need application
total
113k +
29140 +
107k +
total
supervised
252k +
18850 +
84k +
total
unsupervised
590k +
13760 +
125k +
total
total
842k +
32610 +
209k +
Mandarin here includes Mandarin-English CS corpora.
Sup means supervised speech corpus with high-quality transcription.
Unsup means unsupervised or weakly-supervised speech corpus.
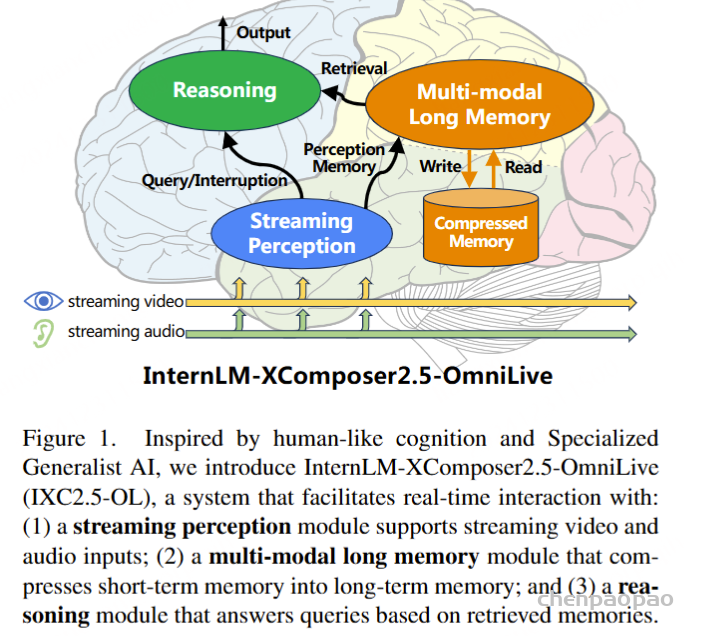
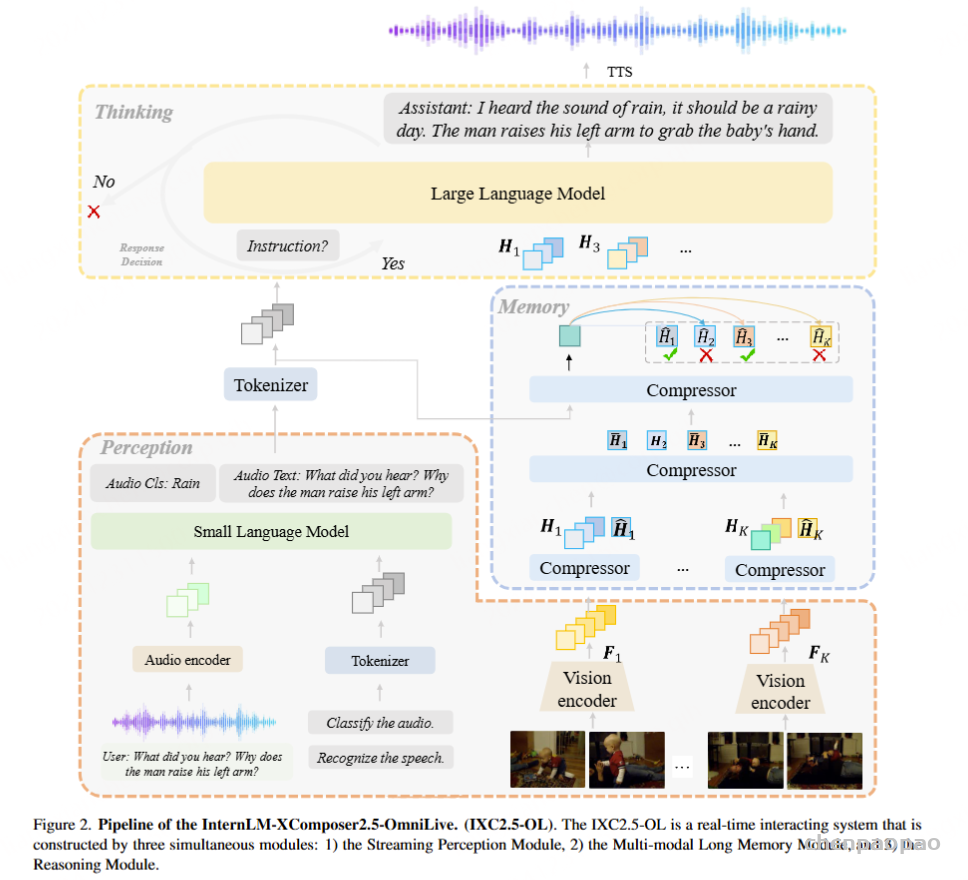
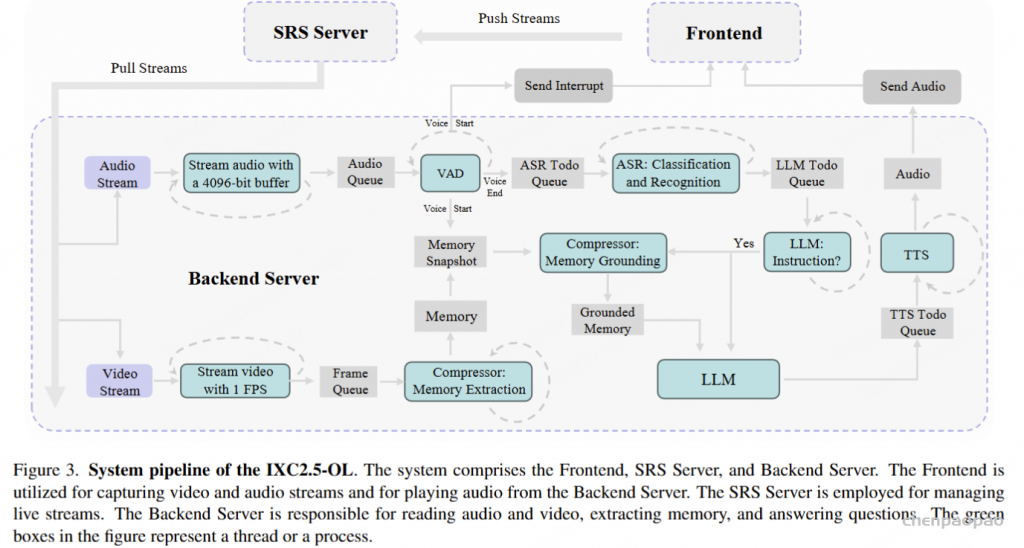
随着人工智能的发展,构建能够实时感知环境、进行复杂推理并记忆的系统,已成为研究者们追求的目标。这不仅要求 AI 系统能处理音频、视频和文本等多模态数据,还需在动态环境中模拟人类感知、推理与记忆的协同能力。然而,现有多模态大语言模型(MLLMs)在这方面仍存在诸多限制,尤其是在同时处理任务时的效率和可扩展性。
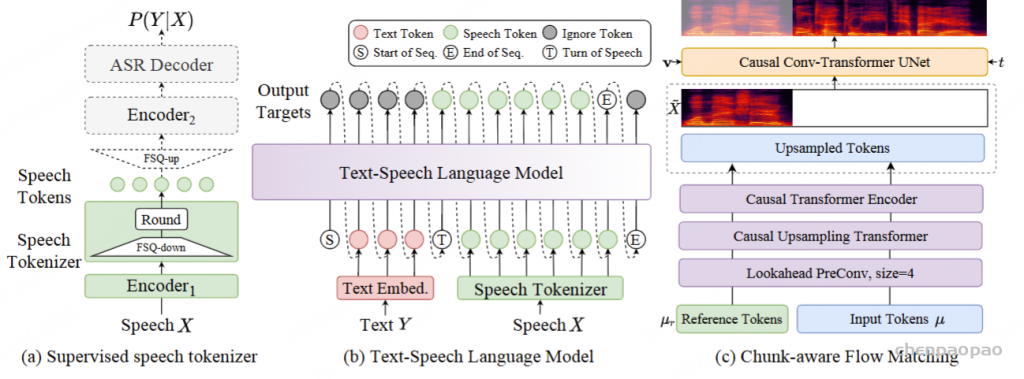
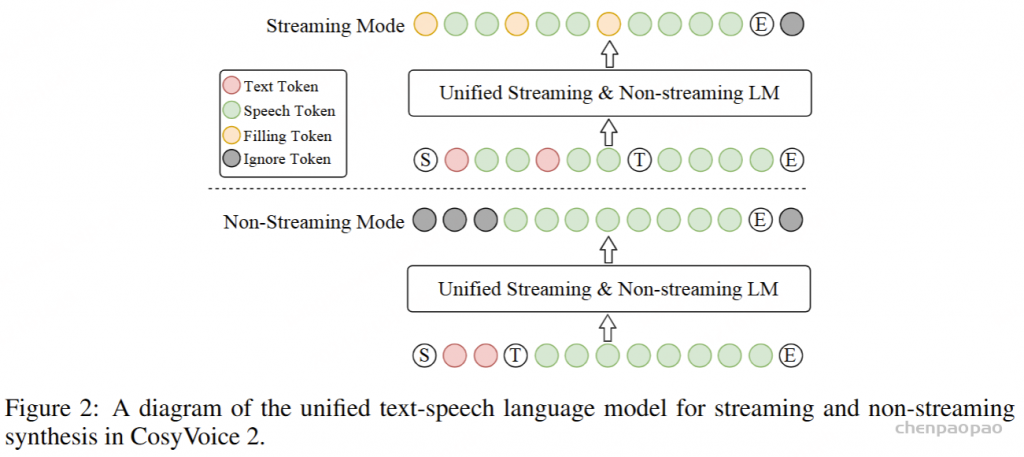
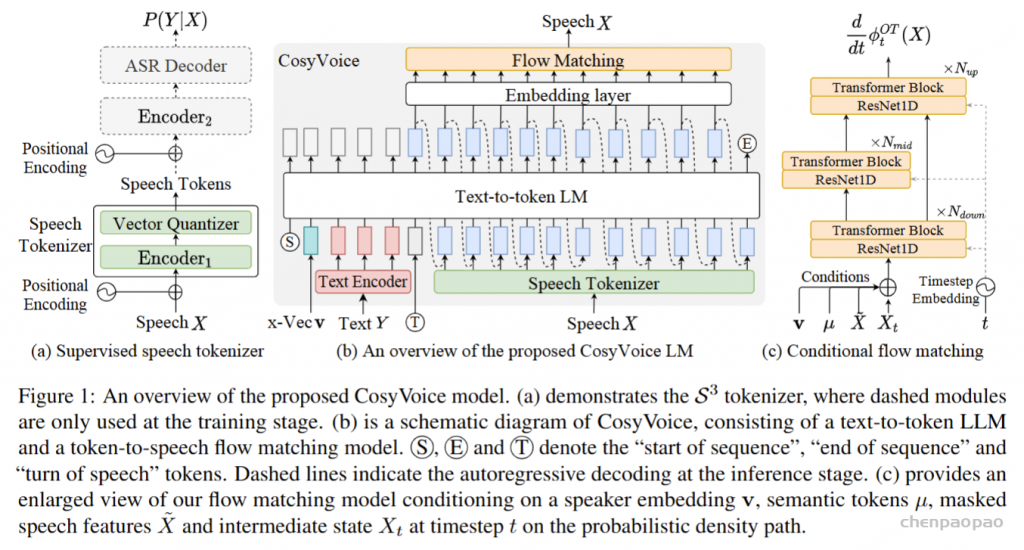
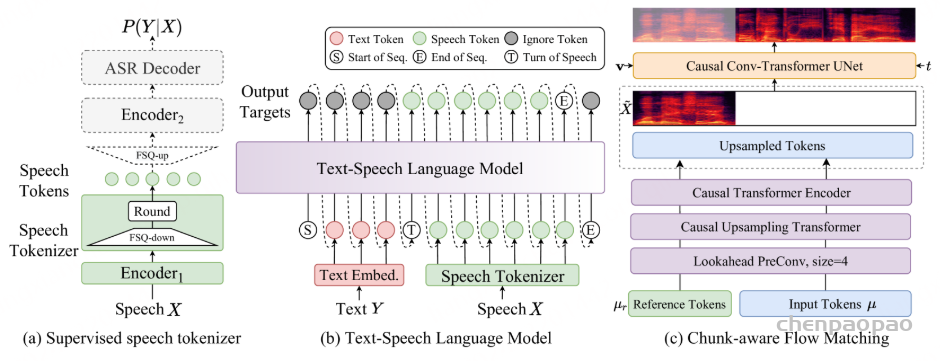
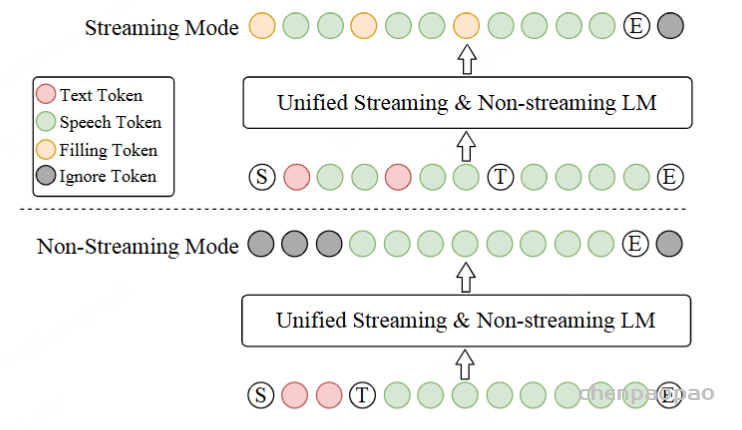
ICL,非流式:在 ICL 中,LM 需要来自参考音频的提示文本和语音标记,以模仿重音、韵律、情感和风格。在非流式处理模式下,提示和要合成的文本标记连接为整个实体,提示语音标记被视为预先生成的结果并固定:“S 、 prompt_text、 text 、T、 prompt_speech”。LM 的自回归生成从此类序列开始,直到检测到 “End of sequence” 标记。
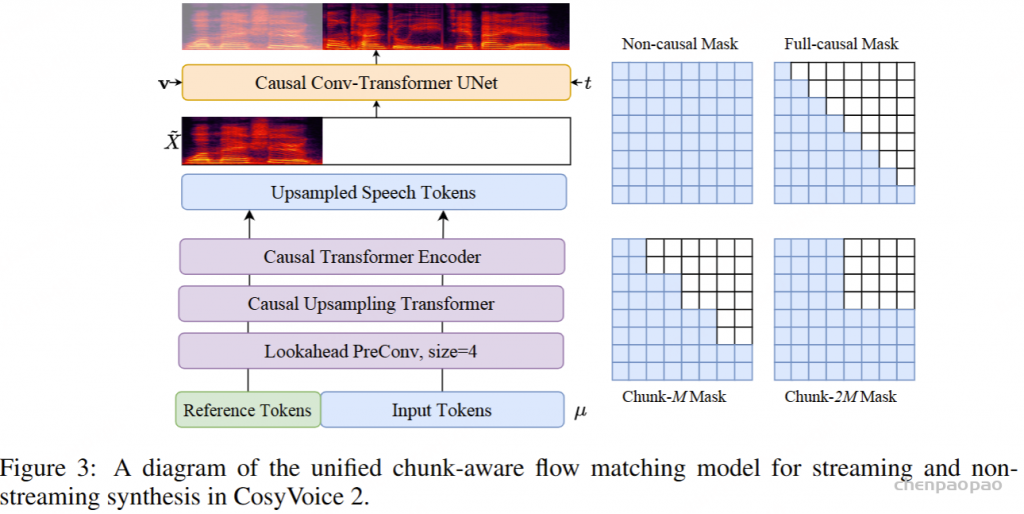
ICL,流式处理:在此方案中,我们假设要生成的文本是已知的,并且语音令牌应以流式处理方式生成。同样,我们将 prompt 和 to-generate 文本视为一个整体。然后,我们将其与提示语音标记混合,比例为 N : M : “S, mixed_text_speech,T,remaining_speech”。如果文本长度大于提示语音 Token 的长度,LM 将生成 “filling token”。在这种情况下,我们手动填充 N个文本标记。如果文本令牌用完,将添加“Turn of speech” T 令牌。在流式处理模式下,我们为每个 M 令牌返回生成结果,直到检测到 E为止。
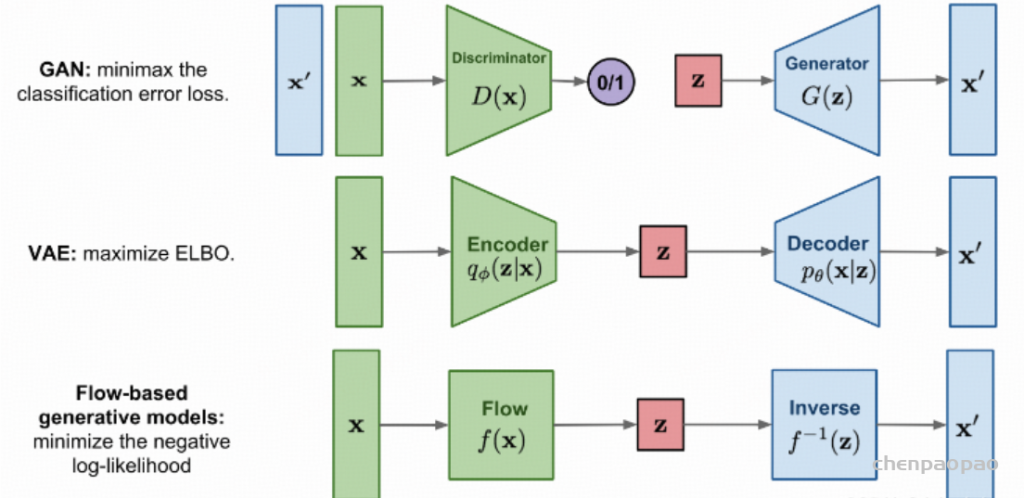
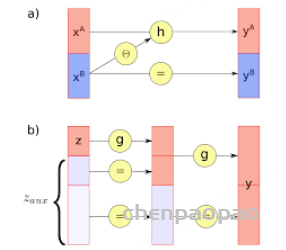
每个生成模型(generative model)理想情况下都是密度估计(density estimaor);因此模拟概率密度,最终是 JPD,具有两个预期特征,即采样和压缩,压缩基本上是将数据推送到信息空间,这似乎是较低维的,而采样是从任何特征分布(z)开始生成 P(x|z) 的能力,可以是正态分布(如 VAE 的情况),因此,在非常高的层次上,我们试图找到将 z 映射到 x 以及将 x 映射到 z(采样和压缩)的映射/函数。
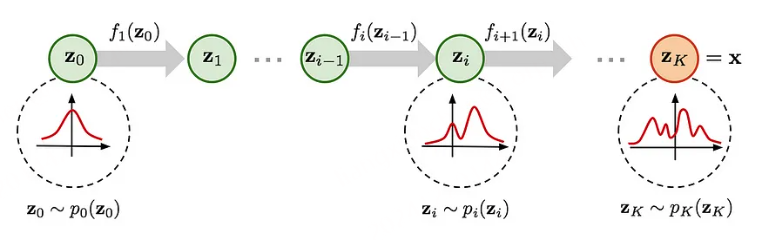
假设两个 Normalizing Flows,一个表示为 z(潜在或可处理分布),另一个表示为 X(数据分布),因为我们想要找到一个可以将 z 映射到 x 的函数,我们会得到 X 和 Z 密度之间的关系,这必然指出假设 X 和 Z 是共轭分布(变换前后同一家族 z 的分布),X 和 Z 的变化应该是相对的,因此,X 的变化是 Z 的某个函数,反之亦然。但是,按某个量缩放。这个量由雅可比矩阵给出的 z 和 x 之间每个维度的变化表示,在非常简单的尺度上,它基本上是 Z 和 X 之间变量的变化。但是,它不是那么简单,因为 X 和 Z 实际上并不共轭,因此,我们只剩下迭代采样和近似方法,比如最佳传输或吉布斯采样(用于 RBM)。鉴于这些限制,大多数方法都绕道去模拟分布并近似非精确映射,而像 Normalizing flow 这样的方法则做出简化假设,使计算和公式易于处理,形式为 p(x)dx = p(z)dz,可以将其重新表述为两个项,第一个是 MLE 项,第二个是雅可比行列式。
要解决这个问题,我们需要假设 z 和 X 之间的状态依赖性,使得它是双射的并且行列式可以有效计算,有三种主要方法
1. 耦合块:基本上你将 z 分成两块,只有最后 k 值预测 X 的最后 k 值(通过基于均值/方差的采样),X 的其他部分基本上是 z 的直接复制,这有何帮助?由于这种方法,雅可比矩阵变成了对角矩阵,左上角(<k)部分是恒等矩阵,右下角(>=k)变成元素乘积,右上角变成 0,因为 z(<k)和 x(>=k)之间没有依赖关系,因此,雅可比行列式的计算是有效的。
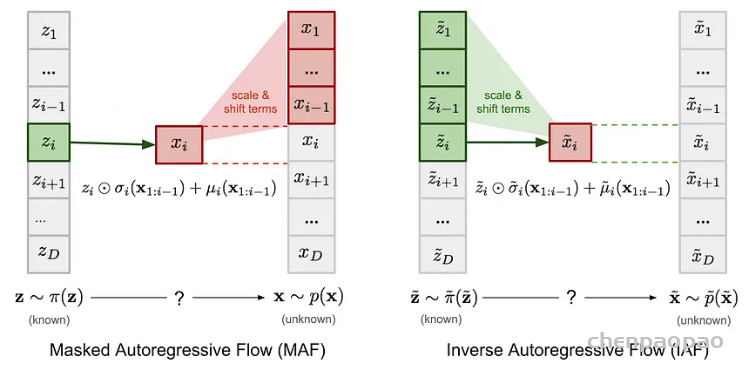
2. AR 流或自回归流是下一个合乎逻辑的扩展,与其制作大 k 块,为什么不将每个状态/特征视为马尔可夫链的一部分,从而消除额外的依赖关系,这会导致雅可比矩阵的下三角矩阵,这也很容易计算。但是,这种方法保留了更多的特征,并且不易受到我们在耦合层中为保留特征而进行的置换操作的影响。
图 MAF 和 IAF 的比较。具有已知密度的变量为绿色,而未知的变量为红色。
3. 最后,残差流,我们保留整个特征空间,而不牺牲计算。这个想法很简单,但却有非常复杂的数学支持。公式是残差形式 x = z + f(z),但这不是双射,因为 f 是一个神经网络。有趣的是,多亏了 Banach 和他的收缩映射,在理想情况下,存在一个唯一的 z*,它总是映射到相同的 x(稳定状态 z),因此,它也变成了双射,形式为 x = z* + f(z*),其中 f 是一个收缩映射(函数受 Lipschitz 小于 1 的限制,因此,z 的变化受 X 的变化的限制),该形式还为我们提供了一种在给定先前 z(k) 的情况下表示 z(k+1) 的方法,这有助于迭代近似 X,而不是单次框架。我们可以通过相同的公式从 z(0) 转到 z(t),也可以恢复回来,听起来很熟悉,这大致就是扩散。那么行列式呢,迭代变换导致雅可比矩阵迹的无穷项之和,这对于满秩雅可比矩阵来说是可怕的,但可以通过类似的矩阵公式使用哈钦森方法进行迹估计来简单地计算。
Fig. 4. Three substeps in one step of flow in Glow.
现在,很多后来推出的声码器都使用非自回归方法来改善自回归方法生成速度慢的问题。换句话说,一种无需查看先前样本(通常表示为平行)即可生成后续样本的方法。已经提出了各种各样的非自回归方法,但最近一篇表明自回归方法依旧抗打的论文是 Chunked Autoregressive GAN (CARGAN),它表明许多非自回归声码器存在音高错误,这个问题可以通过使用自回归方法来解决。当然,速度是个问题,但是通过提示可以分成chunked单元计算,绍一种可以显着降低速度和内存的方法。
在这篇文章的开头,在处理 TTS 的历史时,我们简单地了解了 Formant Synthesis。人声是一种建模方法,认为基本声源(正弦音等)经过口部结构过滤,转化为我们听到的声音。这种方法最重要的部分是如何制作过滤器。在 DL 时代,如果这个过滤器用神经网络建模,性能会不会更好。在神经源滤波器方法 [Wang19a] 中,使用 f0(音高)信息创建基本正弦声音,并训练使用扩张卷积的滤波器以产生优质声音。不是自回归的方法,所以速度很快。之后,在Neural harmonic-plus-noise waveform model with trainable maximum voice frequency for text-to-speech synthesis.中,将其扩展重构为谐波+噪声模型以提高性能。DDSP 提出了一种使用神经网络和多个 DSP 组件创建各种声音的方法,其中谐波使用加法合成方法,噪声使用线性时变滤波器。
另一种方法是将与语音音高相关的部分(共振峰)和其他部分(称为残差、激励等)进行划分和处理的方法。这也是一种历史悠久的方法。共振峰主要使用了LP(线性预测),激励使用了各种模型。GlotNet在神经网络时代提出,将(声门)激励建模为 WaveNet。之后,GELP 用 GAN 训练方法将其扩展为并行格式。
Naver/Yonsei University 的 ExcitNet也可以看作是具有类似思想的模型,然后,在扩展模型 LP-WaveNet中,source 和 filter 一起训练,并使用更复杂的模型。在 Neural text-to-speech with a modeling-by-generation excitation vocoder(Interspeech 2020)中,引入了逐代建模 (MbG) 概念,从声学模型生成的信息可用于声码器以提高性能。在神经同态声码器中,谐波使用线性时变 (LTV) 脉冲序列,噪声使用 LTV 噪声。Unified source-filter GAN: Unified source-filter network based on factorization of quasi-periodic Parallel WaveGAN(Interspeech 2021)提出了一种模型,它使用 Parallel WaveGAN 作为声码器,并集成了上述几种源滤波器模型。Parallel WaveGAN本身也被Naver不断扩充,首先在High-fidelity Parallel WaveGAN with multi-band harmonic-plus-noise model(Interspeech 2021)中,Generator被扩充为Harmonic + Noise模型,同时也加入了subband版本。
LPCNet可以被认为是继这种源过滤器方法之后使用最广泛的模型。作为在 WaveRNN 中加入线性预测的模型, LPCNet 此后也进行了多方面的改进。在 Bunched LPCNet 中,通过利用原始 WaveRNN 中引入的技术,LPCNet 变得更加高效。Gaussian LPCNet还通过允许同时预测多个样本来提高效率。Lightweight LPCNet-based neural vocoder with tensor decomposition(Interspeech 2020)通过使用张量分解进一步减小 WaveRNN 内部组件的大小来提高另一个方向的效率。iLPCNet该模型通过利用连续形式的混合密度网络显示出比现有 LPCNet 更高的性能。Fast and lightweight on-device tts with Tacotron2 and LPCNet(Interspeech 2020)提出了一种模型,在LPCNet中的语音中找到可以切断的部分(例如,停顿或清音),将它们划分,并行处理,并通过交叉淡入淡出来加快生成速度. LPCNet 也扩展到了子带版本,首先在 FeatherWave中引入子带 LPCNet。在An efficient subband linear prediction for lpcnet-based neural synthesis(Interspeech 2020)中,提出了考虑子带之间相关性的子带 LPCNet 的改进版本.
声码器的发展正朝着从高质量、慢速的AR(Autoregressive)方法向快速的NAR(Non-autoregressive)方法转变的方向发展。由于几种先进的生成技术,NAR 也逐渐达到 AR 的水平。例如在TTS-BY-TTS [Hwang21a]中,使用AR方法创建了大量数据并用于NAR模型的训练,效果不错。但是,使用所有数据可能会很糟糕。因此,TTS-BY-TTS2提出了一种仅使用此数据进行训练的方法,方法是使用 RankSVM 获得与原始音频更相似的合成音频。
也许这个领域的第一个是 Char2Wav ,这是蒙特利尔大学名人Yoshua Bengio教授团队的论文,通过将其团队制作的SampleRNN vocoder添加到Acoustic Model using seq2seq中一次性训练而成。ClariNet的主要内容其实就是让WaveNet->IAF方法的Vocoder更加高效。
每个量化器在训练 codebook 的时候,都使用 EMA (Exponential Moving Average,指数移动平均)的更新方式。训练 VQ 的 codebook 使用 EMA 方法由 Aäron van den Oord首次提出。论文 Neural Discrete Representation Learning(https://arxiv.org/abs/1711.00937)提出使用 EMA 指数移动平均的方式训练码本 codebook。
EMA 指数移动平均:每次迭代相当于对之前所有 batch 累计值和当前 batch 新获取的数据值进行加权平均,权重又称为 decay factor,通常选择数值为 0.99 ,使得参数的迭代更新不至于太激进。
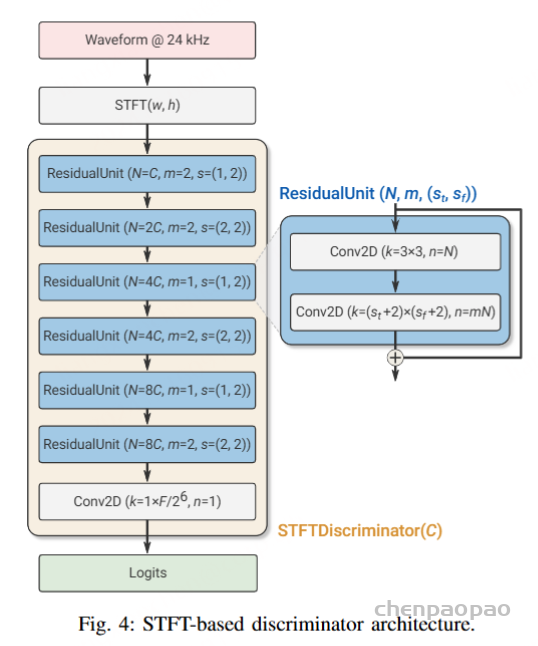
SoundStream 整体使用 GAN(生成对抗网络)作为训练目标,采用 hinge loss 形式的对抗 loss。对应到 GAN 模型中,整个编解码器作为 Generator 生成器,使用前文所述的两种 Discriminator 判别器:一个 STFT 判别器和三个参数不同的 multi-resolution 判别器。判别器用来区分是解码出的音频还是真实的原始音频,本文采用 hinge loss 形式的损失函数进行真假二分类:
生成器的损失函数是为了让生成器的输出被分类为 1 类别,以达到以假乱真的目标,损失函数形式为:
训练目标中还增加了 GAN 中常用的 feature matching 损失函数和多尺度频谱重建的损失函数。feature matching 就是让生成器恢复出的音频和真实的音频,在判别器的中间层上达到相近的分布,用l表示在中间层上进行求和,feature matching 的损失函数为:
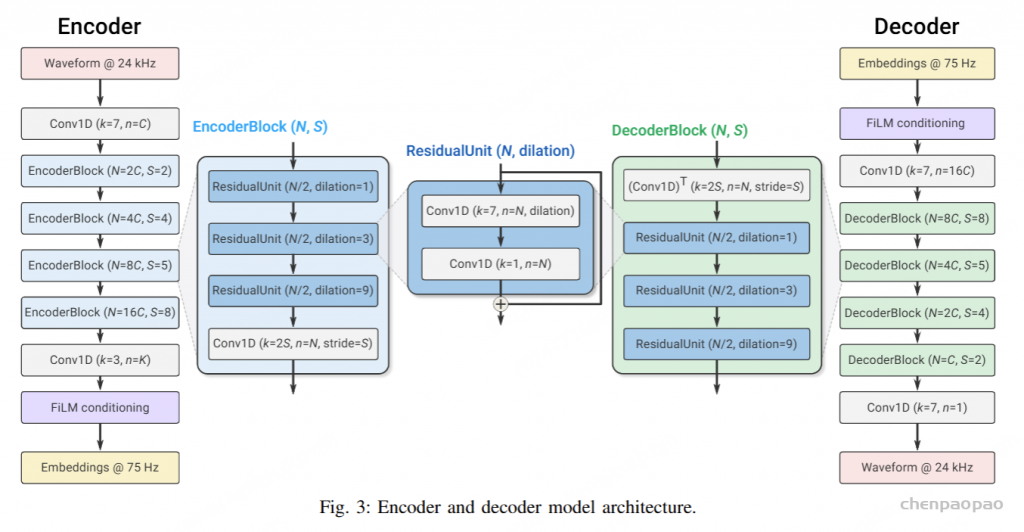
从 SoundStream 的编解码器图例中可以看到一个 FiLM 的模块,表示特征级别的线性调制(Feature-wise Linear Modulation),在编码器中使用时位于 embedding 之前(编码前进行降噪),在解码器中使用时输入是 embedding(编码后进行降噪),论文验证了在图中位置的效果是最好的。
Lyra v1: Kleijn, W. Bastiaan, et al. “Generative Speech Coding with Predictive Variance Regularization.” arXiv preprint arXiv:2102.09660 (2021).
AudioLM: Borsos, Zalán, et al. “Audiolm: a language modeling approach to audio generation.” arXiv preprint arXiv:2209.03143 (2022).
MusicLM: Agostinelli, Andrea, et al. “MusicLM: Generating Music From Text.” arXiv preprint arXiv:2301.11325 (2023).
EMA 训练 codebook 1: Van Den Oord, Aaron, and Oriol Vinyals. “Neural discrete representation learning.” Advances in neural information processing systems 30 (2017).
EMA 训练 codebook 2: Razavi, Ali, Aaron Van den Oord, and Oriol Vinyals. “Generating diverse high-fidelity images with vq-vae-2.” Advances in neural information processing systems 32 (2019).
Jukebox: Dhariwal, Prafulla, et al. “Jukebox: A generative model for music.” arXiv preprint arXiv:2005.00341 (2020).
FiLM: Perez, Ethan, et al. “Film: Visual reasoning with a general conditioning layer.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.
ViSQOL 指标: Chinen, Michael, et al. “ViSQOL v3: An open source production ready objective speech and audio metric.” 2020 twelfth international conference on quality of multimedia experience (QoMEX). IEEE, 2020.
其他设备是常见的客户设备:设备 B 是三星 Galaxy S7,设备 C 是 iPhone SE,设备 D 是 GoPro Hero5 Session。所有同时录制的内容都是时间同步的。
TAU Urban Acoustic Scenes 2019 开发数据集:仅包含使用设备 A 录制的材料,包含 40 小时的音频,在课程之间保持平衡。数据来自12个城市中的10个。TAU Urban Acoustic Scenes 2019 评估数据集包含来自所有 12 个城市的数据。
TAU Urban Acoustic Scenes 2019 移动开发数据集:包含使用设备 A、B 和 C 录制的材料。它由使用设备 A 录制的 TAU Urban Acoustic Scenes 2019 数据和使用设备 B 和 C 录制的一些并行音频组成。来自设备的数据A 被重新采样并平均到单个通道中,以与设备 B 和 C 记录的数据的属性保持一致。数据集总共包含 46 小时的音频(40h + 3h + 3h)。TAU Urban Acoustic Scenes 2019 移动评估数据集还包含来自设备 D 的数据。
Bus 公共汽车-在城市乘坐公共汽车(车辆)
Cafe / Restaurant 咖啡厅/餐厅 - 小咖啡厅/餐厅(室内)
Car 汽车 - 在城市中驾驶或作为乘客旅行(车辆)
City center 市中心(室外)
Forest path 林间小径(室外)
Grocery store 杂货店 - 中型杂货店(室内)
Home 家(室内)
Lakeside beach 湖滨海滩(室外)
Library 图书馆(室内)
Metro station 地铁站(室内)
Office 办公室 - 多人,典型工作日(室内)
Residential area 住宅区(室外)
Train 火车里面(旅行,车辆)
Tram 有轨电车(旅行,车辆)
Urban park 城市公园(室外)
- 室内场景——*室内*:
机场(airport):airport
室内商场(shopping_mall):indoor shopping mall
地铁站(metro_station):metro station
- 户外场景-*户外*:
步行街(street_pedestrian):pedestrian street
公共广场(public_square):public square
中等交通街道(street_traffic,):street with medium level of traffic
城市公园(park):urban park
- 交通相关场景-*交通*:
乘坐公共汽车(bus):travelling by a bus
乘坐电车(tram):travelling by a tram
乘坐地铁(metro):travelling by an underground metro
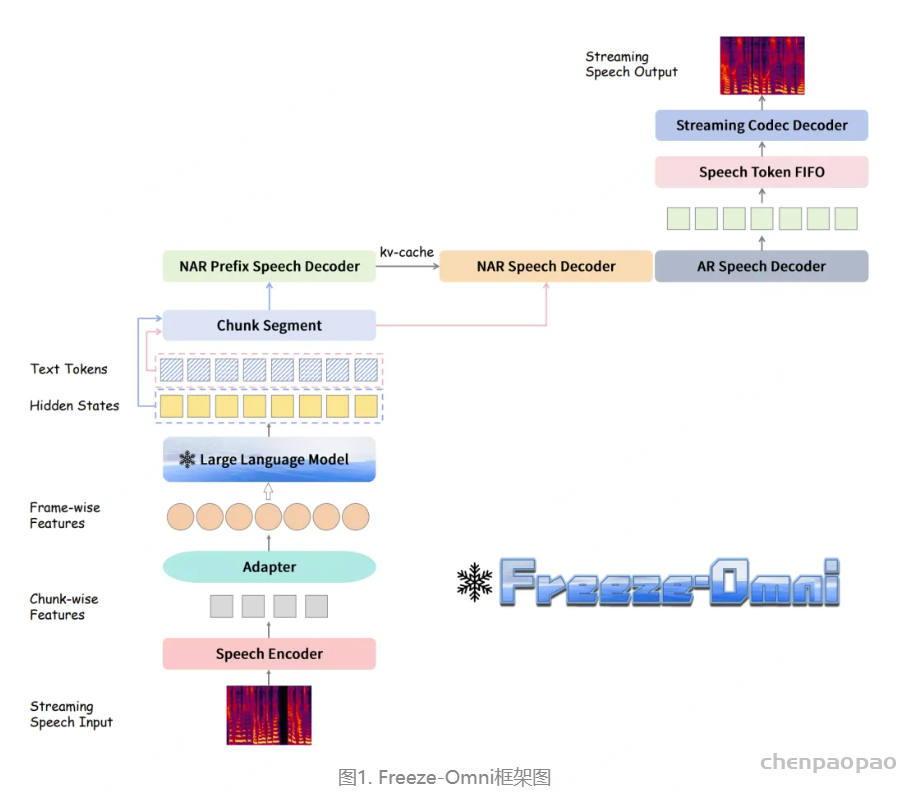
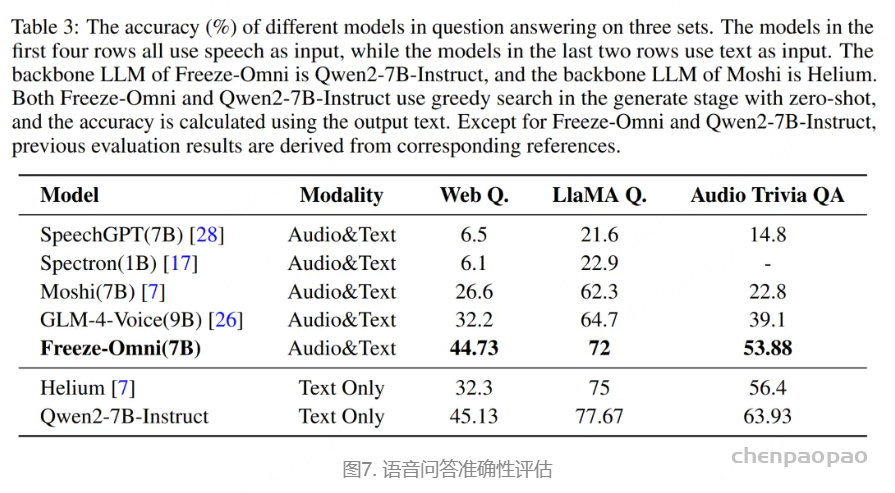
语音问答准确性评估:Freeze-Omni提供了其在LlaMA-Questions, Web Questions, 和Trivia QA三个集合上的语音问答准确率评估,从结果中可以看出Freeze-Omni的准确率具有绝对的领先水平,超越Moshi与GLM-4-Voice等目前SOTA的模型,并且其语音模态下的准确率相比其基底模型Qwen2-7B-Instruct的文本问答准确率而言,差距明显相比Moshi与其文本基底模型Helium的要小,足以证明Freeze-Omni的训练方式可以使得LLM在接入语音模态之后,聪明度和知识能力受到的影响最低。
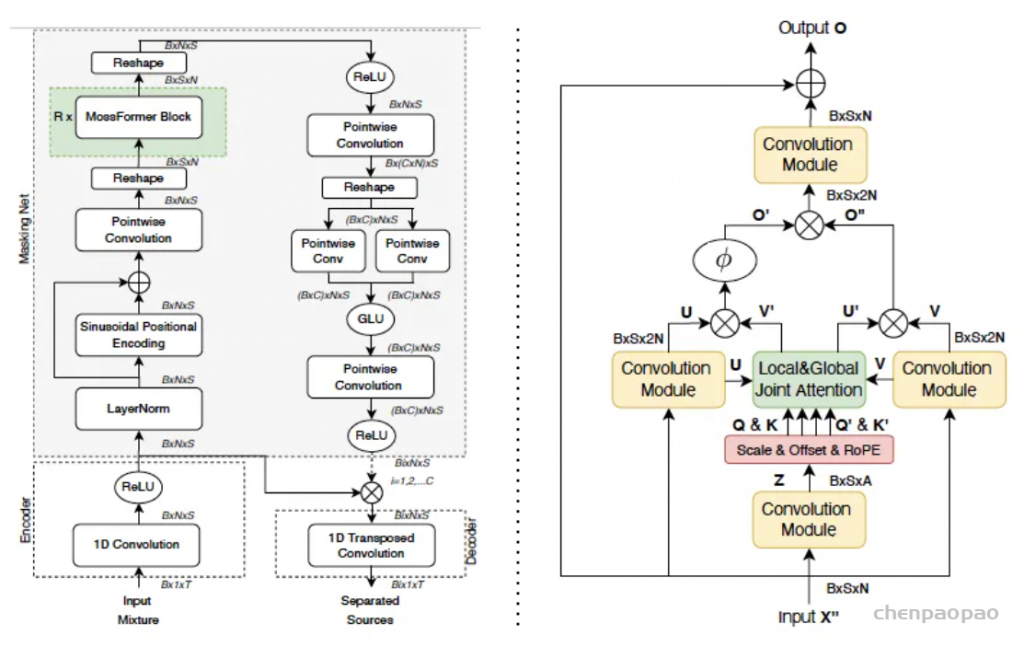
【1】Zhao, Shengkui and Ma, Bin and Watcharasupat, Karn N. and Gan, Woon-Seng, “FRCRN: Boosting Feature Representation Using Frequency Recurrence for Monaural Speech Enhancement”, ICASSP 2022 – 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
【2】Zhao, Shengkui and Ma, Bin, “MossFormer: Pushing the Performance Limit of Monaural Speech Separation using Gated Single-head Transformer with Convolution-augmented Joint Self-Attentions”, ICASSP 2023 – 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
【3】Zhao, Shengkui and Ma, Bin et al, “MossFormer2: Combining Transformer and RNN-Free Recurrent Network for Enhanced Time-Domain Monaural Speech Separation”, ICASSP 2024 – 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).