- Demo:https://huggingface.co/spaces/KE-Team/KE-Omni
- 论文:https://arxiv.org/pdf/2412.01078
- Github:https://github.com/LianjiaTech/BELLE
贝壳团队最新的语音大模型工作:面对语音交互对话数据稀缺的行业现状,尝试通过多阶段生成的方式来Scale训练数据;构建了超60000+小时、包含40000+说话人的高质量交互对话数据集Ke-SpeechChat;通过这些方式,表现基本能达到SOTA;
个人理解:
- 1、具体做法是先生成文本token,基于文本token在自回归生成语音token,最后基于语音token合成音频,没办法做到打断和全双工对话。另外,只使用hubert的音频token来合成语音可能效果不好,缺乏声学信息,合成的音频可能不会有太多的情感波动,以及音色可能不稳定,看作者demo和论文, HiFi-GAN 声码器针对代理发音人(agent speakers)预先训练,针对中英文男/女 各选了一个音色进行HiFiGAN的训练,如果只在单一音色上训练的HiFiGAN可能音色比较稳定。个人理解应该是每一个音色训练一个HiFiGAN模型,听demo确实语音没有情感波动,另外这种方法跟LLama-omni做法基本一致。
- 2、论文中给出了如何在没有开源的大规模语音交互数据集情况下进行语音对话数据集的制作。比较有借鉴意义。首先对文本数据使用LLM进行重写指令、筛选重写后的指令以及口语化后处理。然后使用TTS技术合成多说话人,多样化的语音。另外在附录中给出了 文本重写指令的prompt以及不同的大小的Qwen2 LLM重写的结果分析。【具体提示词见附录】
论文:通过使用超过 60,000 小时的合成语音对话数据扩展监督微调来推进语音语言模型Advancing Speech Language Models by Scaling Supervised Fine-Tuning with Over 60,000 Hours of Synthetic Speech Dialogue Data
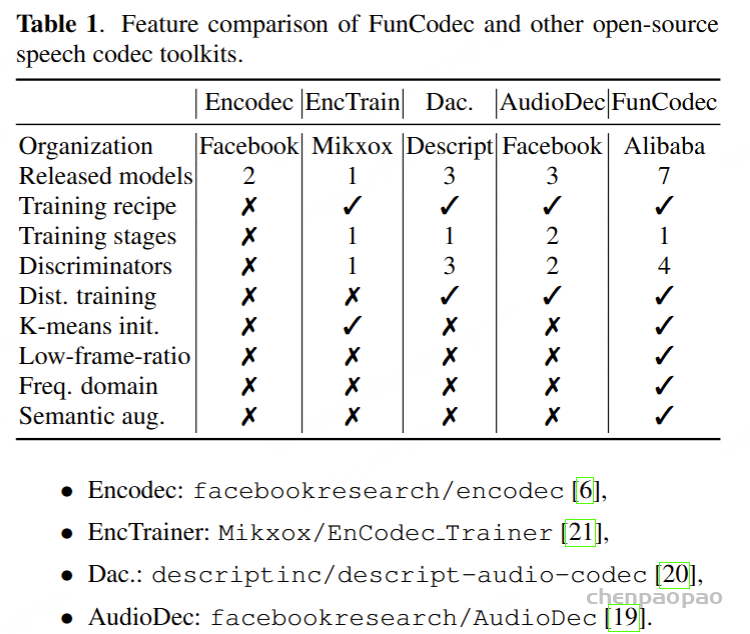
KE-Omni是一个基于 Ke-SpeechChat 构建的无缝大型语音语言模型,这是一个大规模的高质量合成语音交互数据集,由 700 万中英文对话组成,有 42,002 名说话人,总计超过 60,000 小时,这为该领域的研究和开发进步做出了重大贡献。
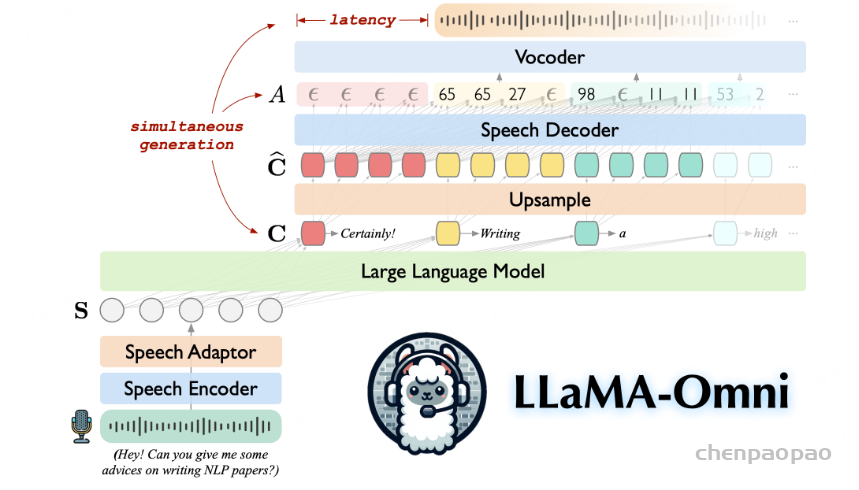
KE-Omni 模型架构
KE-Omni 由三个主要组件组成:语音编码器、大型语言模型(LLM)和语音解码器。针对用户的语音指令,KE-Omni 被设计为无缝生成高质量的文本和语音响应。
语音编码器
采用了 Whisper-large-v3的编码器作为语音编码器。Whisper 是一种广泛使用的多语言语音识别模型,以其在多种语言上的强大性能而著称,非常适合我们的应用场景。一个轻量级的语音适配器被用于语音-文本模态对齐,将语音编码器与 LLM 连接起来。
语音编码器将每秒的音频处理为 50 帧特征。随后,语音适配器进一步压缩语音特征序列的长度,使其与 LLM 的模态对齐。我们在语音适配器中采用了 5 倍的压缩比,这意味着每秒的语音最终被转换为 10 帧特征。这种方法提高了处理速度并降低了 LLM 的延迟,同时保证了质量不受影响。
在整个训练过程中,语音编码器的参数保持冻结状态,仅语音适配器的参数会更新。这种方法保留了编码器强大的语音表示能力,同时使适配器能够学习必要的转换,以实现与 LLM 的高效语音-文本模态对齐。
语言模型
采用了最先进的开源模型 LLaMA作为大型语言模型(LLM)。该模型在多语言推理能力方面表现出色,涵盖中文和英文等多种语言。在 KE-Omni 中,LLM 将提示文本嵌入和语音编码器生成的语音表示拼接后作为输入。这种集成方式使得 LLM 能够利用来自文本和语音模态的上下文信息。然后,LLM 根据用户的语音指令自回归地生成文本响应。为了在性能和效率之间取得平衡,我们选择了 LLaMA-3.1-8B-Instruct 作为我们的 LLM 变体。
语音解码器
语音解码器负责将 LLM 的文本响应映射为对应的语音信号,是实现语音交互的重要组件。解码器包括以下三个关键部分:
- 时长预测器 :来自 Unit-based HiFi-GAN Vocoder with Duration Prediction
- 语音单元生成器
- 基于单元的声码器(vocoder)
语音特征表示
类似于 (Zhang et al., 2023) 和 (Fang et al., 2024) 的方法,我们采用预训练的 HuBERT 模型(Hsu 等人,2021)来提取连续的语音表示,并使用 K-means 模型将这些连续表示转化为离散的聚类索引。
- code:https://github.com/facebookresearch/fairseq/tree/main/examples/textless_nlp/gslm/speech2unit
- paper:Speech Resynthesis from Discrete Disentangled Self-Supervised Representations.
生成语音响应的步骤
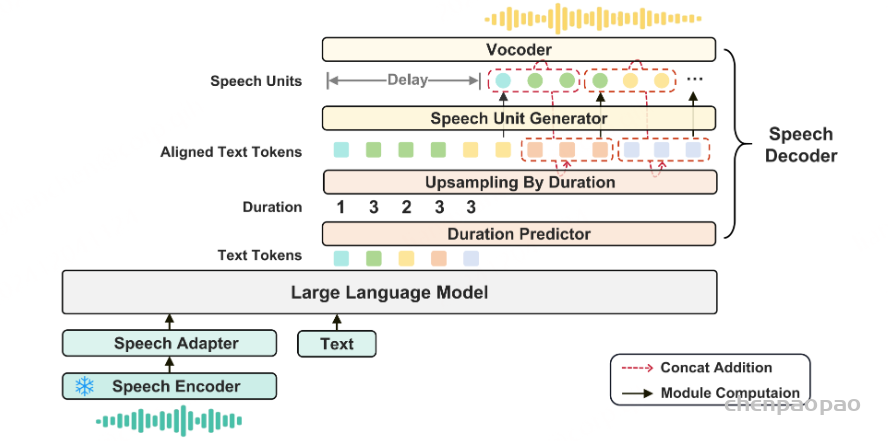
- 时长预测
在生成语音响应之前,时长预测器首先预测每个文本标记(token)的时长。- 时长预测器是一个基于 Transformer 的模型,使用 Whisper 提取的单词级时间戳进行训练。 【参考code:1、https://github.com/facebookresearch/speech-resynthesis/tree/main 2、Unit-based HiFi-GAN Vocoder with Duration Prediction】
- 根据预测的时长信息,文本token序列会被上采样以匹配目标音频帧序列的长度。
- 时长预测器在 KE-Omni 的训练过程中保持冻结状态。
- 语音单元生成
基于 Transformer 的语音单元生成器以自回归方式生成离散语音单元序列。为了提高预测速度,我们采用基于块的自回归方法,分块预测语音单元。- 给定块大小 C 和目标语音单元序列长度 T,第 i 个文本token和第 j 个语音单元的嵌入向量进行拼接【concatenated】作为输入,其中 j=i−C,且 i∈[C,T]。
- 在第一个块中,语音单元使用零嵌入初始化。
- 为了确保语音单元生成的质量,我们在扩展的文本token序列和语音单元序列之间引入了 N 步延迟。
- 波形合成
最终,通过基于单元的声码器(vocoder)将语音单元合成波形。我们选择了 HiFi-GAN 作为声码器。Unit-based HiFi-GAN Vocoder with Duration Prediction HiFi-GAN 声码器针对代理发音人(agent speakers)预先训练,并在 KE-Omni 的训练过程中保持冻结状态。
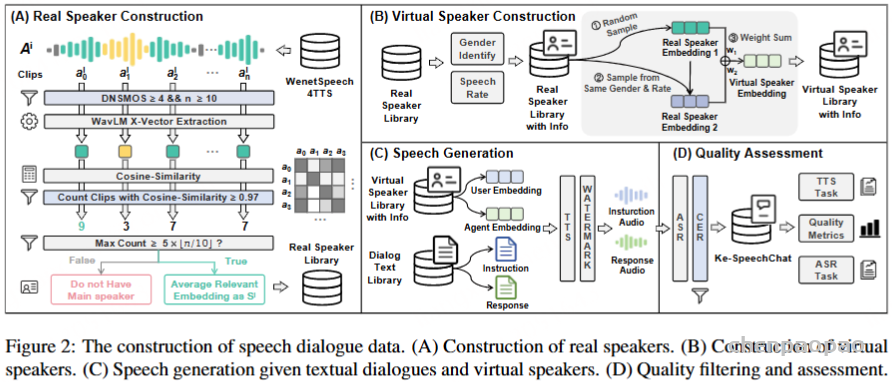
Ke-SpeechChat 数据集构建
目前尚未见到开源的大规模语音交互数据集,这极大地阻碍了语音对话研究的发展。这种稀缺性主要归因于以下两个因素:一是构建语音数据的高成本,二是涉及的隐私风险。
为了有效构建大规模且高质量的语音交互数据集,我们通过利用先进的 LLM 和 TTS 工具包,探索高效的合成数据方法。为避免隐私风险,我们构建了一个虚拟语音库用于语音生成,其中的声音在现实世界中并不存在。此外,我们在数据中嵌入了水印,以表明这些数据是由 AI 生成的,从而防止其被滥用。
在对话数据的构建过程中,我们首先专注于创建能准确反映口语特征的文本对话数据,然后从这些文本对话中合成语音。随后,我们对合成语音进行质量保证和筛选。
文本预处理:
选择的文本对话问答数据集:
| https://huggingface.co/datasets/BelleGroup/train_1M_CN https://huggingface.co/datasets/BelleGroup/train_2M_CN https://huggingface.co/datasets/BelleGroup/train_3.5M_CN https://huggingface.co/datasets/fnlp/SpeechInstruct https://huggingface.co/datasets/fnlp/AnyInstruct |
文本数据集存在的问题:
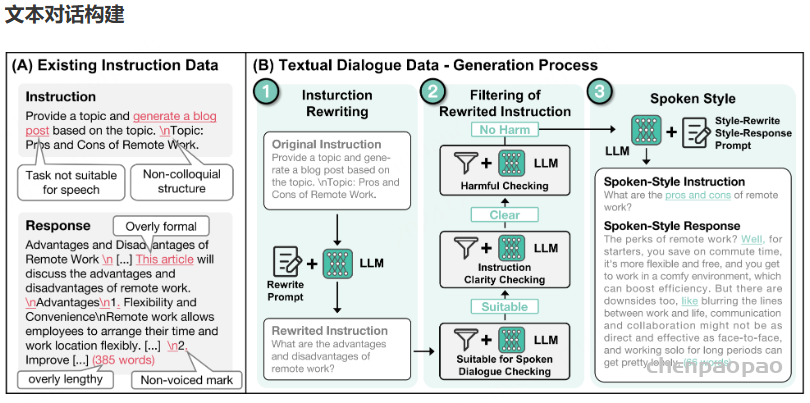
任务不适合语音交互
许多数据集中的指令涉及的任务不适用于语音交互,例如生成图像、撰写长篇文章或创建结构化文本。这些任务难以自然地融入语音对话。
形式过于正式,与口语化不符
数据集中指令的表达通常过于正式和详尽,与日常口语表达存在显著差距。例如,一个数据集中的指令可能是:“如何安装和设置一款软件或设备(例如打印机)”,而在日常对话中,用户通常会简单地问:“怎么用打印机?”
内容过长且包含不可发音的符号
数据集中指令和响应往往过于冗长,并包含不可发音的特殊字符,例如 Markdown 符号、下划线和换行符。这些特性使得文本数据无法很好地适应语音交互的细腻和动态需求。
为了解决上述问题,我们实施了以下三个关键步骤:重写指令、筛选重写后的指令以及口语化后处理。这三个阶段均借助大型语言模型(LLMs)完成,具体的提示词(prompts)详见附录 A.1。
重写指令
重写指令的主要目标是将指令任务转化为更适合口头交互的形式。我们的方法是为大型语言模型(LLM)设计特定的提示,要求其将原始指令数据转换为人类可能会以口语形式提出的问题。
我们发现,当将完整的原始指令提供给 LLM 时,其输出通常只对任务的原始格式进行轻微改写,导致结果仍然不适合对话场景。为了解决这个问题,我们针对特定类型的任务(例如分类、摘要和其他指令性任务)实施了特定策略。我们移除了这些任务中的指令性句子,仅保留关键信息片段。随后,我们告知 LLM 这些片段是不完整的,要求其以此为灵感,创造性地生成新的问题。
这种方法有效降低了 LLM 过于依赖原始指令的倾向,并鼓励生成更加自然的对话式问题。因此,我们能够将正式且结构化的指令文本有效地转化为更适合语音场景的查询。
筛选重写后的指令
在指令重写阶段之后,我们会对重写后的指令进行筛选,以确保其适用于口语交互。筛选过程涉及以下三个关键考量:
- 适合口头交流:评估重写后的指令是否适合口头交流,排除需要生成长篇或结构化内容(如文章、歌词或电子邮件)的任务。
- 清晰度与完整性:评估每条指令的清晰度和完整性,确保其包含足够的背景信息。对于过于模糊或缺乏必要背景的指令(例如“这篇文章的主要内容是什么?”),会被筛除。
- 安全性:使用我们内部的系统和 Qwen2-72B-Instruct 模型对指令进行安全性评估。
通过这一筛选过程,数据集主要由清晰、上下文完整且安全的指令组成,从而提升其在对话交互场景中的适用性。
语音风格后处理
在最后阶段,我们使用大型语言模型(LLM)进一步修改筛选后的指令,以提升其对话质量,并以类似自然口语风格生成相应的回答。具体步骤如下:
- 对话语气:要求 LLM 采用自然的对话语气,避免生成无法发音的内容,并将数字和公式符号转换为其口头表达形式。
- 简洁回答:将回答限制在 100 字以内,确保单次回复不包含过多信息。
通过遵循这些指导原则,数据集被进一步优化,更加适合用于训练支持自然且高效语音交互的模型。
使用的模型版本:
本节使用 Qwen2.5-72B-Instruct,而 重写指令 和 筛选重写指令 节使用的是 Qwen2.5-14B-Instruct。值得注意的是,与较小版本(如 Qwen2.5-32B-Instruct 或 Qwen2.5-14B-Instruct)相比,Qwen2.5-72B-Instruct 生成的指令相似,但回答质量显著提升。示例可在附录中查看。
合成音频对话数据
使用 CosyVoice模型,它支持自定义语音特征,将文本对话转换为语音对话。为确保说话人多样性,我们构建了一个包含大量虚拟说话人的语音库,这些说话人均来自开源语音数据。为保持合成语音对话的质量,我们对合成音频进行转录并计算字符错误率(CER),根据 CER 进行数据筛选,从而确保数据集的高质量。
语音库
数据来源 WenetSpeech4TTS 数据集源自 WenetSpeech(Zhang et al., 2022),该数据集包含从互联网收集的长音频录音,时长从几分钟到数小时不等。WenetSpeech4TTS 通过语音活动检测(VAD)对这些长录音进行分段,将其分割为较短的音频片段,同时计算每段的 DNSMOS 分数(Reddy et al., 2022)。这些短片段根据说话人的余弦相似性进行合并,以确保每个短片段均由同一说话人发出。然而,WenetSpeech4TTS 未检测同一长录音中不同短片段之间的相似性,而这对我们的工作至关重要,因为我们需要识别由同一人发出的多个片段,以生成稳定的语音特征嵌入。
实际说话人
我们首先从 WenetSpeech4TTS 的优质短片段中(DNSMOS ≥ 4.0)提取音频,并根据其来源的长录音进行分类。我们筛选出包含至少 10 个优质短片段的长录音,记为 Ai={ai1,ai2,…,ain},其中 i 是长录音的索引,n≥10表示短片段的数量。
接着,我们使用 WavLM(Chen et al., 2022)为这些短片段提取 X-向量,并计算 Ai 中每对优质短片段之间的说话人相似性。如果某长录音中至少有 floor⌊2n⌋ 对短片段的相似性得分超过 0.97,则这些短片段被认为由同一人发出。通过这种方法,我们识别出了 5000 多名说话人,且性别均衡。
虚拟说话人
对于每个识别出的语音特征,我们计算平均发音速度(即每个字符的平均发音时间,取整至最近的 10 毫秒)。然后,根据发音速度将这些特征进行分类。我们随机选择一个语音特征,并与同性别、发音速度相同的另一语音特征配对,通过加权平均生成合成语音特征,以保护隐私并生成不存在的、虚拟的合成语音。这一过程可以用来生成无限数量的虚拟语音。
通过这些步骤,我们的语音库包含高质量、多样化、性别均衡的虚拟语音,适用于语音合成的多种应用,同时不会对应任何真实个人。
语音合成
CosyVoice 进行语音合成。对于每段对话,我们随机选择一位用户语音和一位代理语音进行合成。为了防止数据滥用,所有合成语音均使用 AudioSeal(San Roman et al., 2024)进行水印保护。
质量保证
为确保合成对话的质量,我们对中文部分使用 Belle-whisper-large-v3-turbo-zh 进行转录,对英文部分使用 Whisper-large-v3-turbo 进行转录。
分别计算中文的字符错误率(CER)和英文的单词错误率(WER)。若某条对话的中文 CER 超过 5% 或英文 WER 超过 10%,则该对话被剔除,以确保数据的高质量。
Ke-SpeechChat 数据集细节
所有元数据存储在单个 JSON 文件中,每条对话都包含以下信息:对话 ID、说话人、性别、文本内容和音频路径。示例详见附录 C。
详细统计信息如表 1 所示,其中中文和英文对话的数据分别列出。
- 中文对话:数量超过 510 万条,总时长达 40,884 小时。
- 英文对话:数量超过 170 万条,总时长达 19,484 小时。
数据集中的说话人性别均衡,包含 40,000 名用户和 2 名代理【输出语音】(用户和代理的分布均适用于中文和英文)。大量的对话和说话人确保了数据集的多样性。
训练数据被随机划分为五个不同大小的子集:XS、S、M、L 和 XL。
- 每个较大的子集都包含所有较小子集的数据。
- 所有子集均完整覆盖 42,002 名说话人。
质量评估
为评估 Ke-SpeechChat 的质量,我们使用以下客观指标:
- DNSMOS(P.835 OVRL)和 UTMOS 评分:分别衡量音频质量和语音自然度。
- ASR 和 TTS 任务:进一步评估数据集性能。
附录
A:PROMPTS提示
指令重写:

指令过滤:

语音风格后处理 [根据指令获得响应]:

B:Qwen不同版本的能力 比较
本附录介绍了使用不同版本的Qwen2.5模型对口语风格后处理的影响,如下表所示

C: Dialogue Format