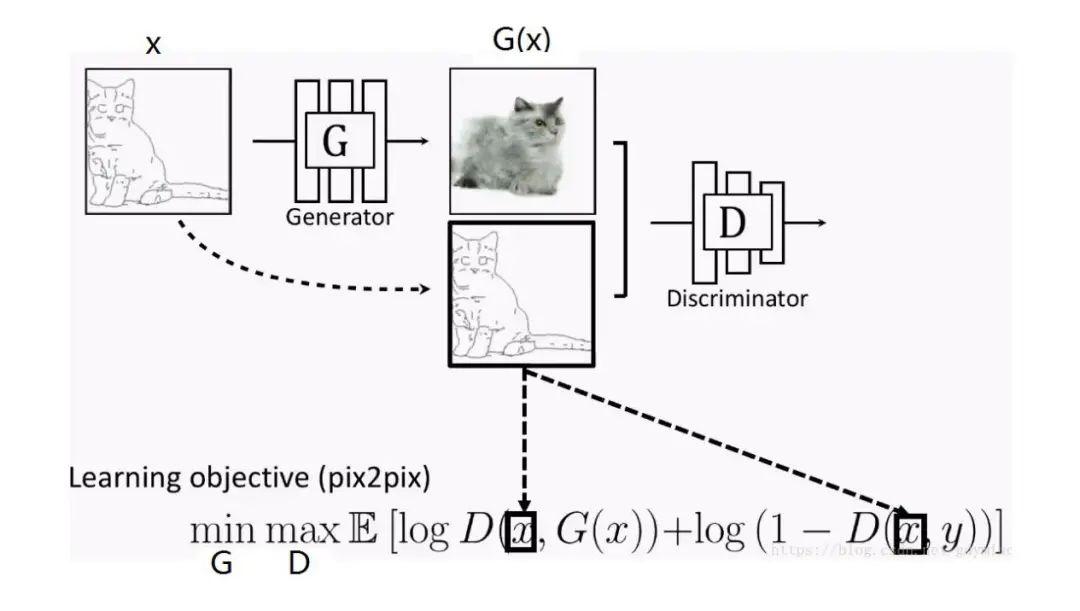
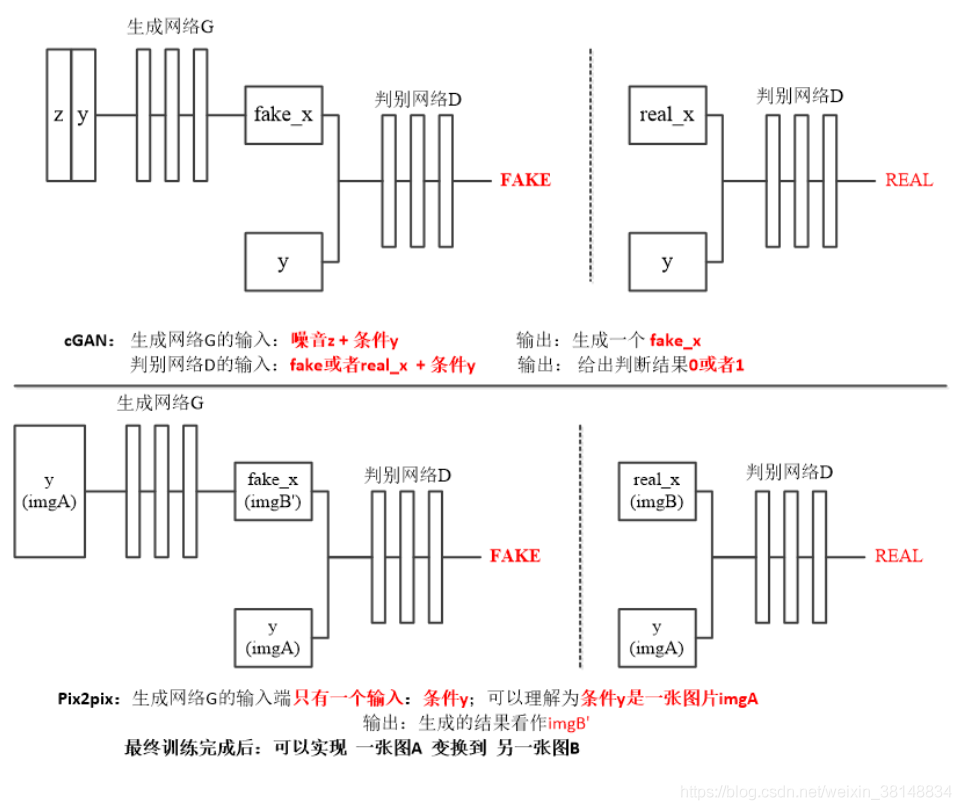
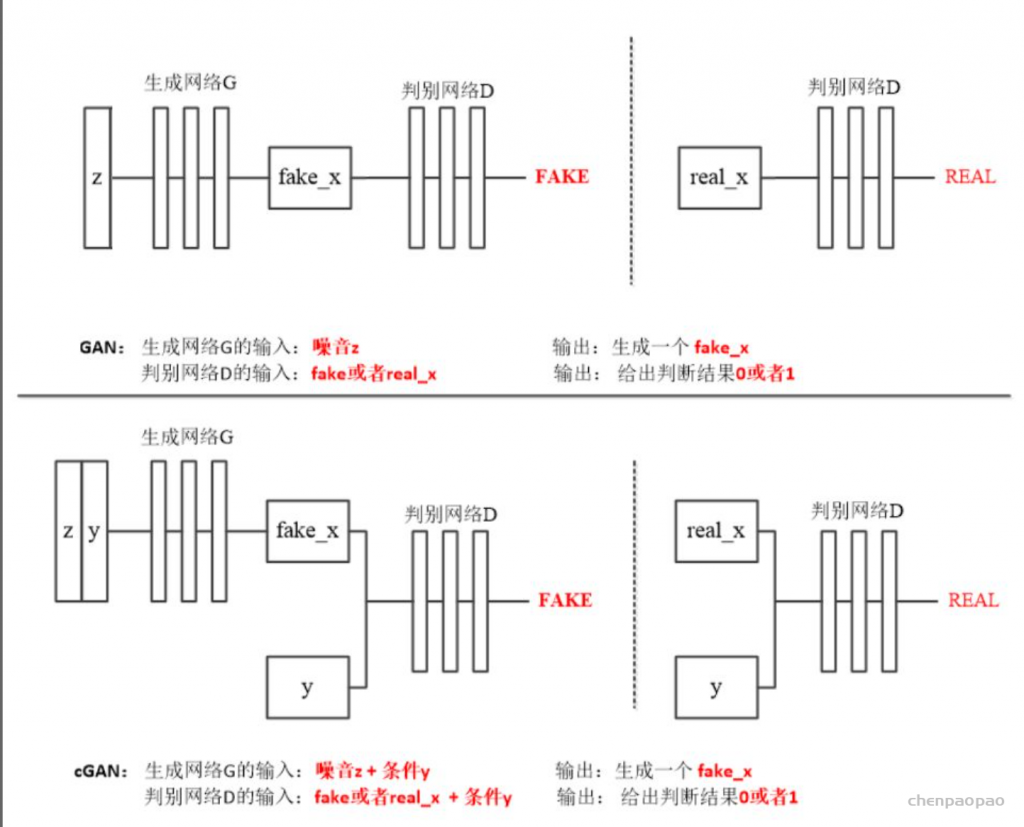
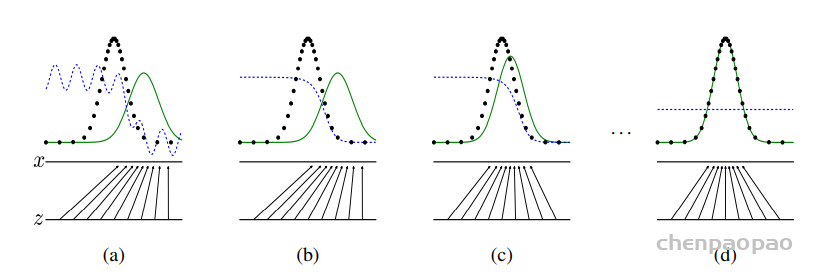
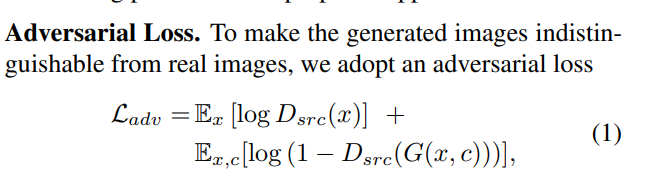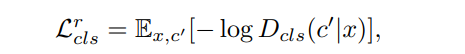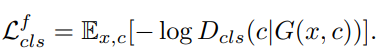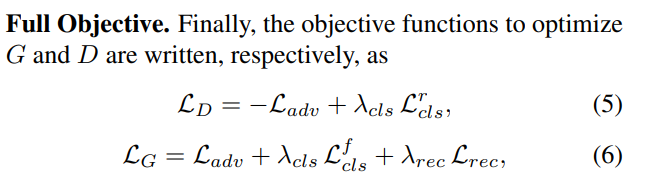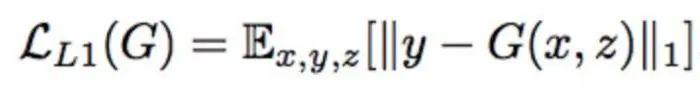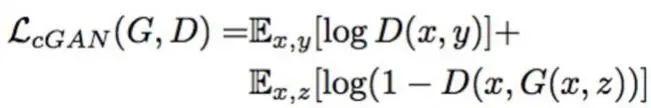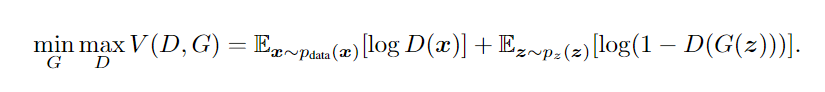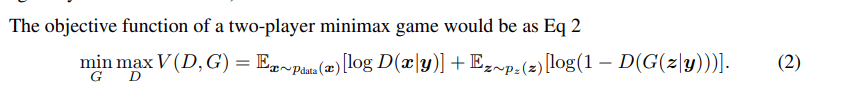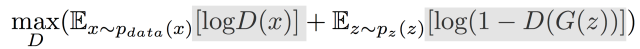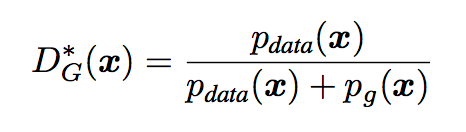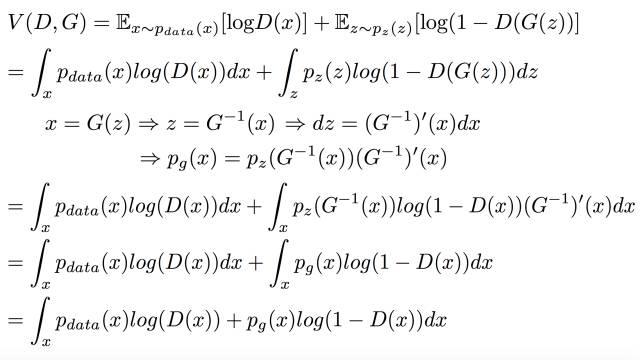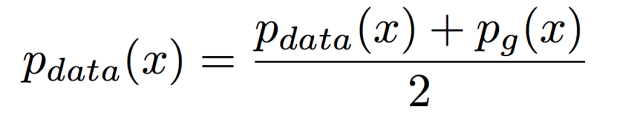StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
Authors
Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, Jaegul Choo
Abstract
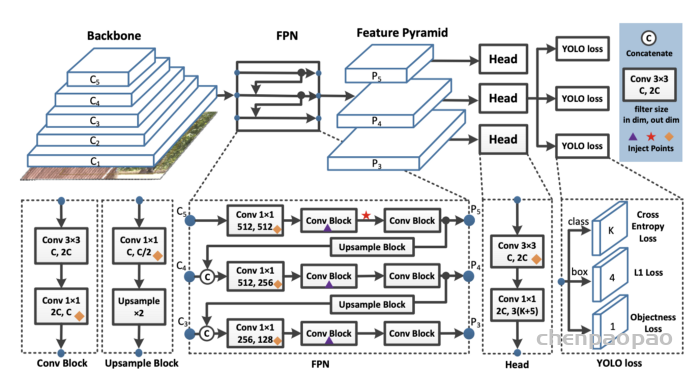
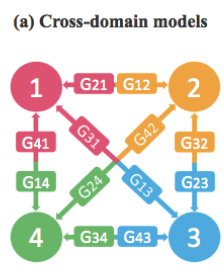
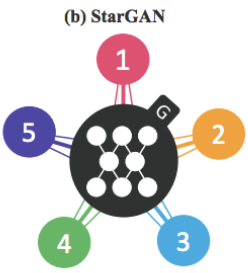
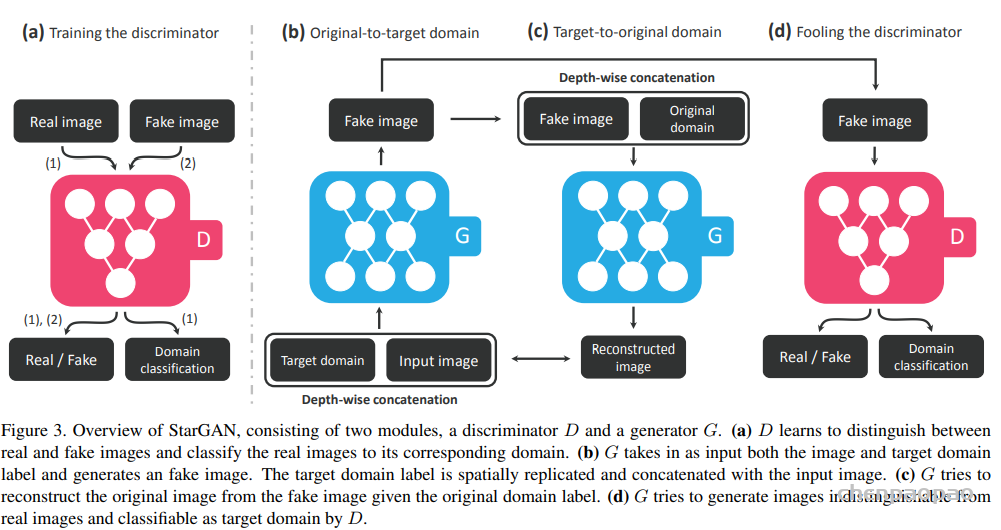
Recent studies have shown remarkable success in image-to-image translation for two domains. However, existing approaches have limited scalability and robustness in handling more than two domains, since different models should be built independently for every pair of image domains. To address this limitation, we propose StarGAN, a novel and scalable approach that can perform image-to-image translations for multiple domains using only a single model. Such a unified model architecture of StarGAN allows simultaneous training of multiple datasets with different domains within a single network. This leads to StarGAN’s superior quality of translated images compared to existing models as well as the novel capability of flexibly translating an input image to any desired target domain. We empirically demonstrate the effectiveness of our approach on a facial attribute transfer and a facial expression synthesis tasks.
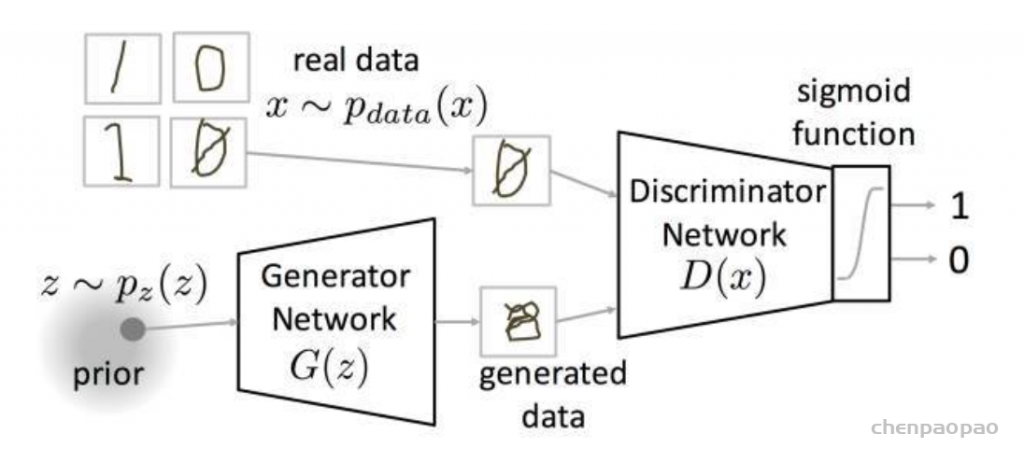
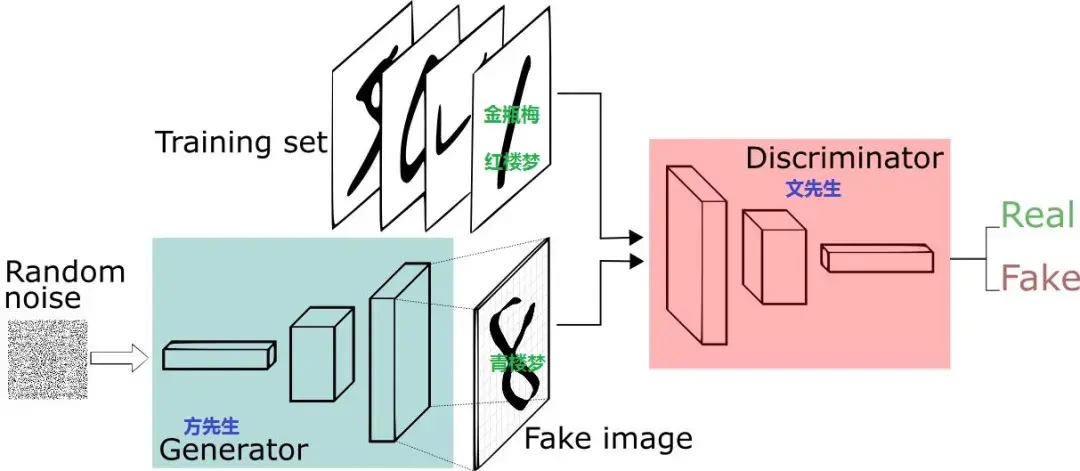
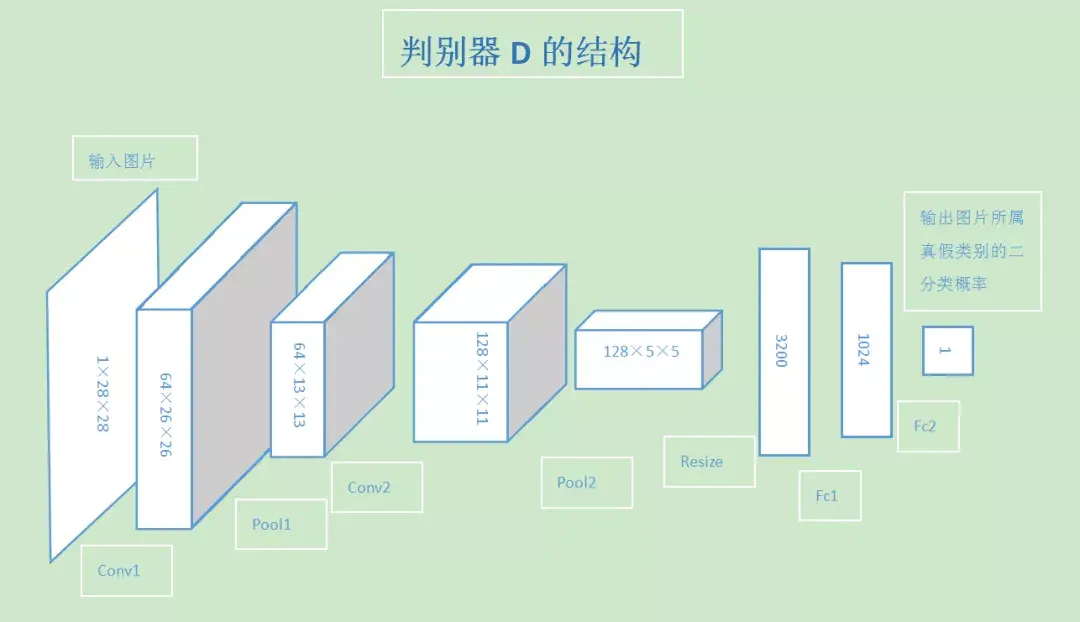
GAN全称:Generative Adversarial Network 即生成对抗网络,由Ian J. Goodfellow等人于2014年10月发表在NIPS大会上的论文《Generative Adversarial Nets》中提出。此后各种花式变体Pix2Pix、CYCLEGAN、STARGAN、StyleGAN等层出不穷,在“换脸”、“换衣”、“换天地”等应用场景下生成的图像、视频以假乱真,好不热闹。前段时间PaddleGAN实现的First Order Motion表情迁移模型,能用一张照片生成一段唱歌视频。各种搞笑鬼畜视频火遍全网。用的就是一种GAN模型哦。深度学习三巨神之一的LeCun也对GAN大加赞赏,称“adversarial training is the coolest thing since sliced bread”。