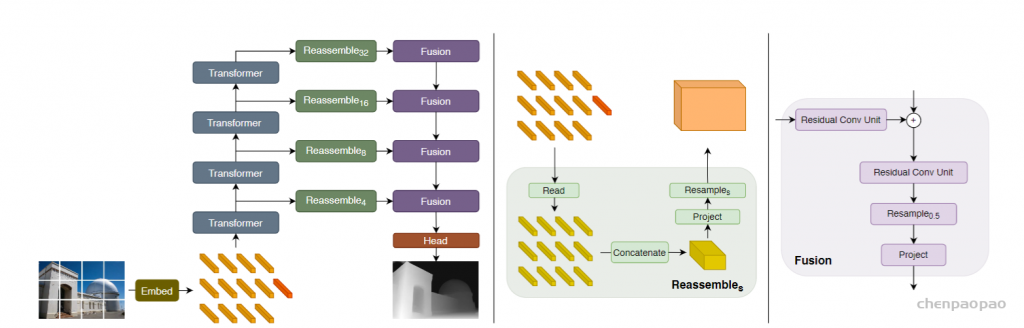
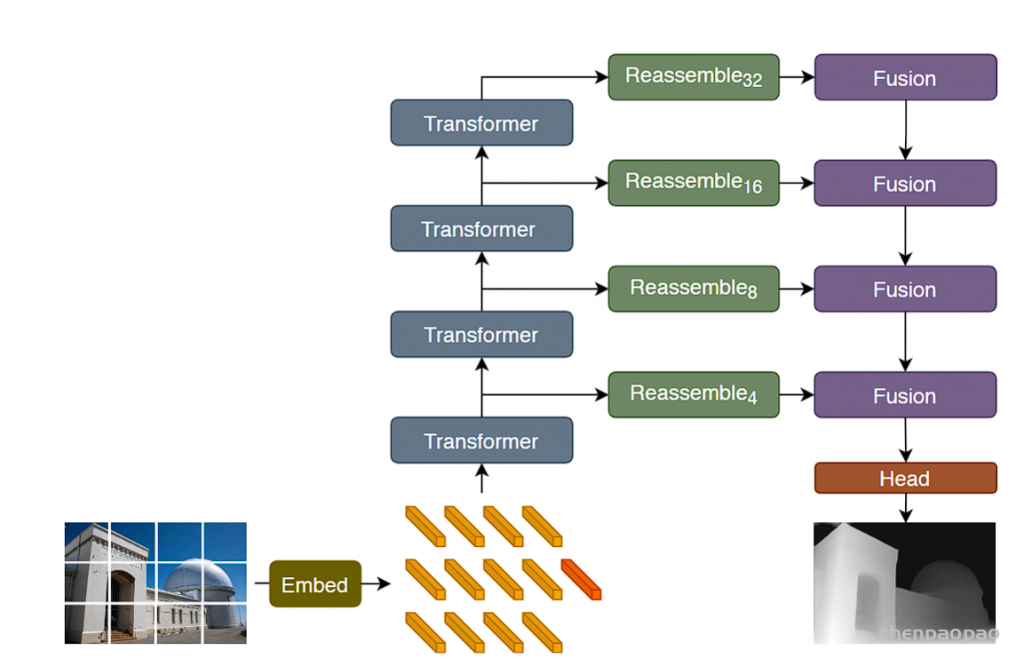
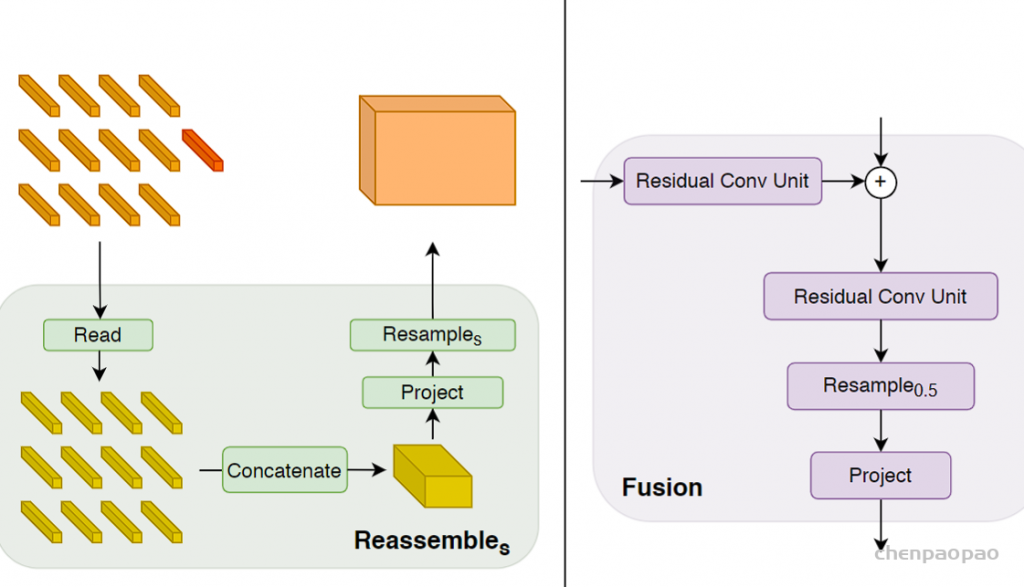
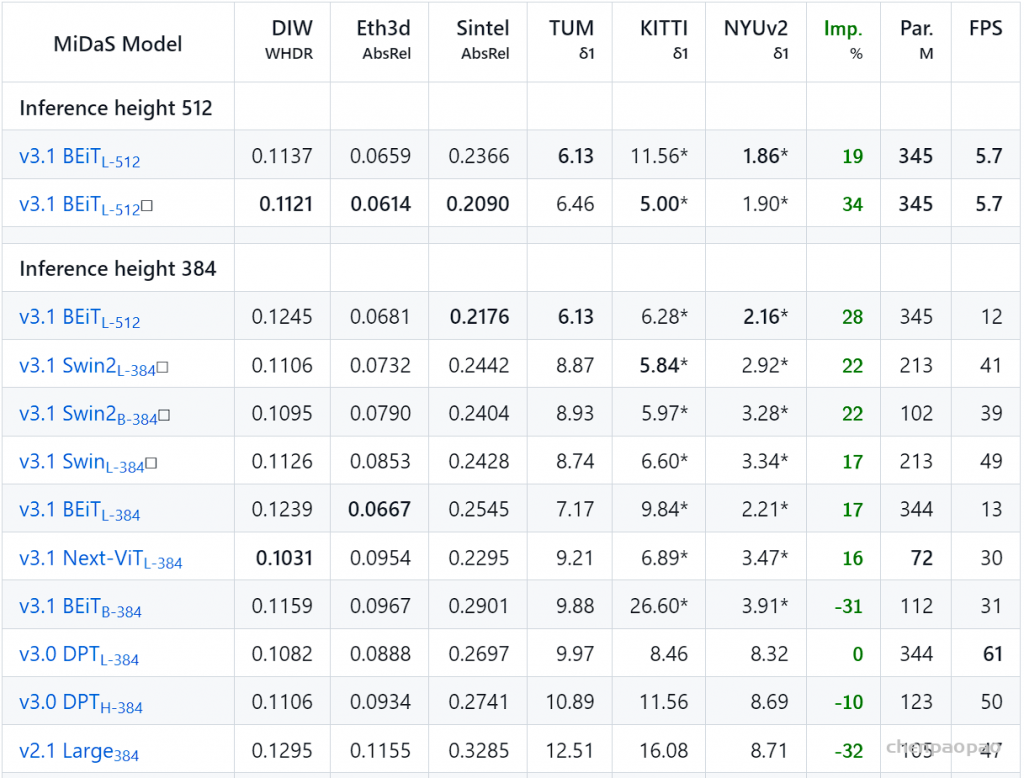
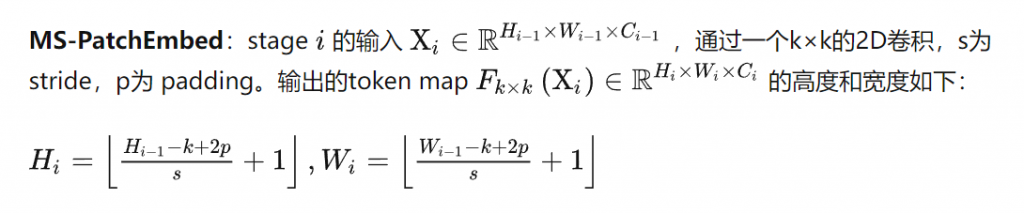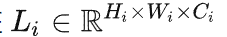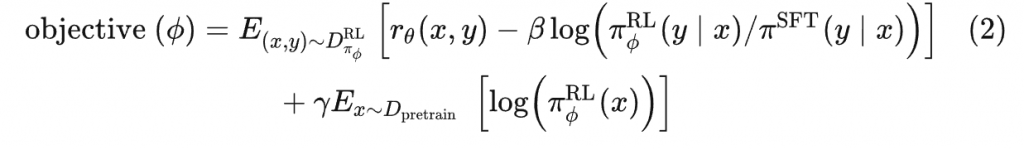不管具体的transformer主干如何,都在四个不同的阶段和四个不同的分辨率上重新组装特征。以更低分辨率组装transformer深层的特征,而早期层的特征以更高分辨率组装。当使用ViT-Large时,从 l ={5,12,18,24}层重新组装tokens,而使用ViT-Base,使用 l ={3,6,9,12}层。当使用ViT-Hybrid时,使用了来自嵌入网络的第一和第二个ResNet块和阶段 l ={9,12}的特性。默认体系结构使用投影作为读出操作,并使用=256维度生成特性映射,将这些架构分别称为DPT-Base、DPT-Large和DPTHybrid。
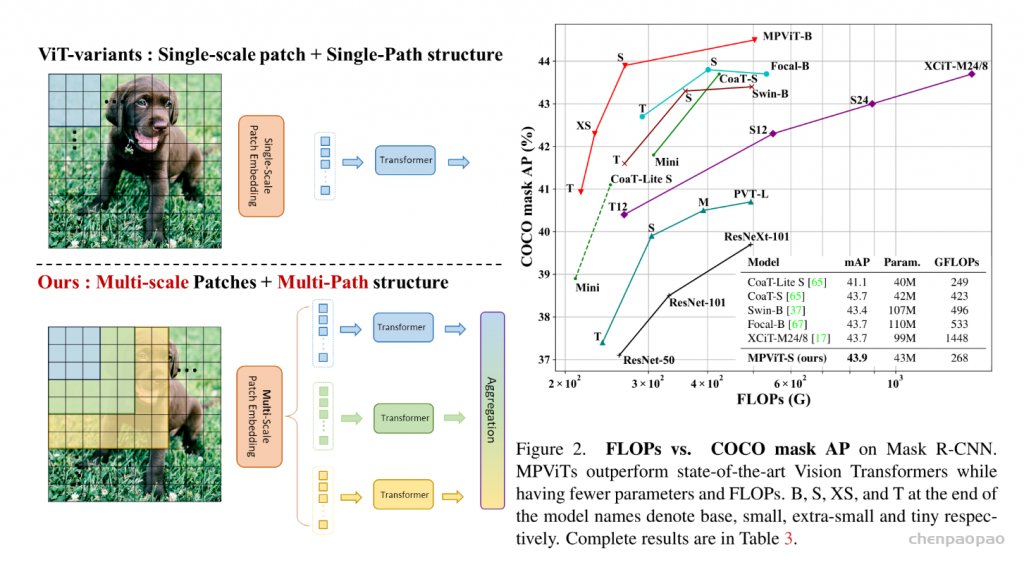
In LeViT , a convolutional stem block shows better low-level representation (i.e., without losing salient information) than non-overlapping patch embedding.
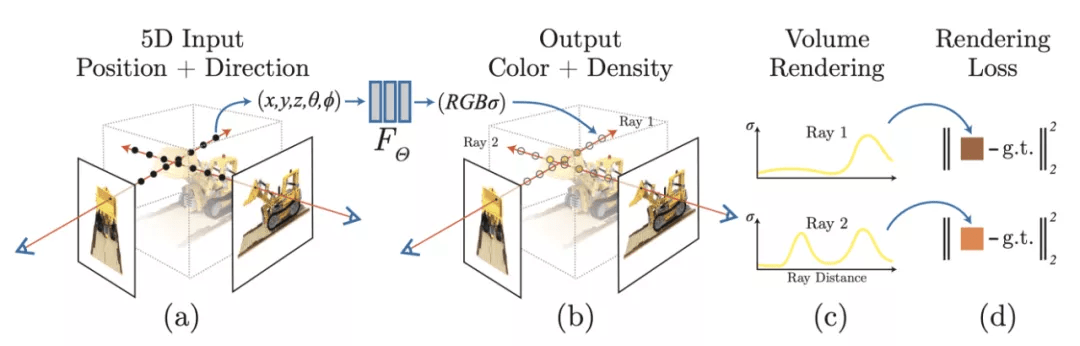
Monocular Depth Estimation is the task of estimating the depth value (distance relative to the camera) of each pixel given a single (monocular) RGB image. This challenging task is a key prerequisite for determining scene understanding for applications such as 3D scene reconstruction, autonomous driving, and AR. State-of-the-art methods usually fall into one of two categories: designing a complex network that is powerful enough to directly regress the depth map, or splitting the input into bins or windows to reduce computational complexity. The most popular benchmarks are the KITTI and NYUv2 datasets. Models are typically evaluated using RMSE or absolute relative error. 这项具有挑战性的任务是确定 3D 场景重建、自动驾驶和 AR 等应用场景理解的关键先决条件。
任务介绍
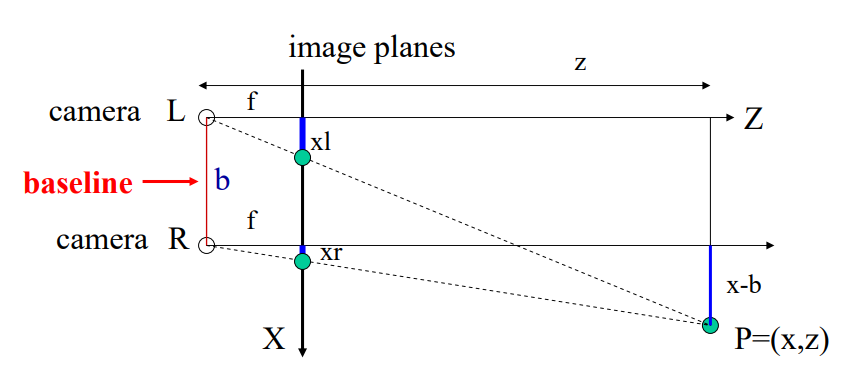
深度估计是计算机视觉领域的一个基础性问题,其可以应用在机器人导航、增强现实、三维重建、自动驾驶等领域。而目前大部分深度估计都是基于二维RGB图像到RBG-D图像的转化估计,主要包括从图像明暗、不同视角、光度、纹理信息等获取场景深度形状的Shape from X方法,还有结合SFM(Structure from motion)和SLAM(Simultaneous Localization And Mapping)等方式预测相机位姿的算法。其中虽然有很多设备可以直接获取深度,但是设备造价昂贵。也可以利用双目进行深度估计,但是由于双目图像需要利用立体匹配进行像素点对应和视差计算,所以计算复杂度也较高,尤其是对于低纹理场景的匹配效果不好。而单目深度估计则相对成本更低,更容易普及。
[1] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440.
[2] Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015: 234-241.
[3] Laina I, Rupprecht C, Belagiannis V, et al. Deeper depth prediction with fully convolutional residual networks[C]//2016 Fourth international conference on 3D vision (3DV). IEEE, 2016: 239-248.
[4] Fu H, Gong M, Wang C, et al. Deep ordinal regression network for monocular depth estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2002-2011.
[5] Godard C, Mac Aodha O, Brostow G J. Unsupervised monocular depth estimation with left-right consistency[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 270-279.
[6] Dosovitskiy A, Fischer P, Ilg E, et al. Flownet: Learning optical flow with convolutional networks[C]//Proceedings of the IEEE international conference on computer vision. 2015: 2758-2766.
[7] Ilg E, Mayer N, Saikia T, et al. Flownet 2.0: Evolution of optical flow estimation with deep networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2462-2470.
[8] Mayer N, Ilg E, Hausser P, et al. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 4040-4048.
[9] Xie J, Girshick R, Farhadi A. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks[C]//European Conference on Computer Vision. Springer, Cham, 2016: 842-857.
[10] Luo Y, Ren J, Lin M, et al. Single View Stereo Matching[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
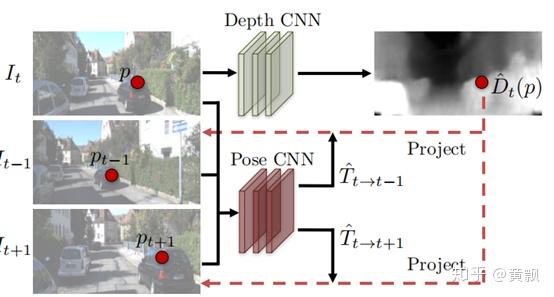
[11] Zhou T, Brown M, Snavely N, et al. Unsupervised learning of depth and ego-motion from video[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 1851-1858.
[12] Yin Z, Shi J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 1983-1992.
[13] Zhan H, Garg R, Saroj Weerasekera C, et al. Unsupervised learning of monocular depth estimation and visual odometry with deep feature reconstruction[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 340-349.
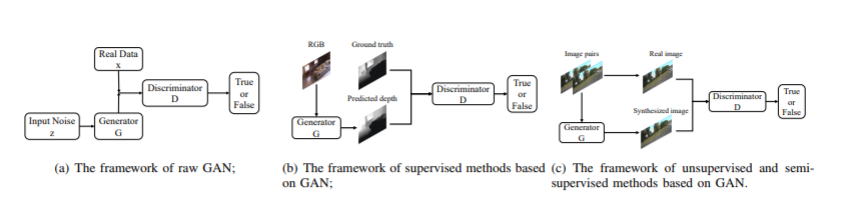
[14] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial nets[C]//Advances in neural information processing systems. 2014: 2672-2680.
[15] Radford A , Metz L , Chintala S . Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks[J]. Computer Science, 2015.
[16] Arjovsky M, Chintala S, Bottou L. Wasserstein gan[J]. arXiv preprint arXiv:1701.07875, 2017.
[17] Gulrajani I, Ahmed F, Arjovsky M, et al. Improved training of wasserstein gans[C]//Advances in Neural Information Processing Systems. 2017: 5767-5777.
[18] Mao X, Li Q, Xie H, et al. Least squares generative adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 2794-2802.
[19] Mirza M, Osindero S. Conditional generative adversarial nets[J]. arXiv preprint arXiv:1411.1784, 2014.
[20] Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1125-1134.
[21] Wang T C, Liu M Y, Zhu J Y, et al. High-resolution image synthesis and semantic manipulation with conditional gans[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8798-8807.
[22] Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2223-2232.
[23] Wang T C , Liu M Y , Zhu J Y , et al. Video-to-Video Synthesis[J]. arXiv preprint arXiv:1808.06601,2018.
[24] Zheng C, Cham T J, Cai J. T2net: Synthetic-to-realistic translation for solving single-image depth estimation tasks[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 767-783.
[25] Atapour-Abarghouei A, Breckon T P. Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 2800-2810.
[26] Nekrasov V , Dharmasiri T , Spek A , et al. Real-Time Joint Semantic Segmentation and Depth Estimation Using Asymmetric Annotations[J]. arXiv preprint arXiv:1809.04766,2018.
[27] Nekrasov V , Shen C , Reid I . Light-Weight RefineNet for Real-Time Semantic Segmentation[J]. arXiv preprint arXiv:1810.03272, 2018.
[28] Lin G , Milan A , Shen C , et al. RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.,2017:1925-1934
[29] Zou Y , Luo Z , Huang J B . DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Task Consistency[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018:36-53.
[30] Ranjan A, Jampani V, Balles L, et al. Competitive collaboration: Joint unsupervised learning of depth, camera motion, optical flow and motion segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 12240-12249.
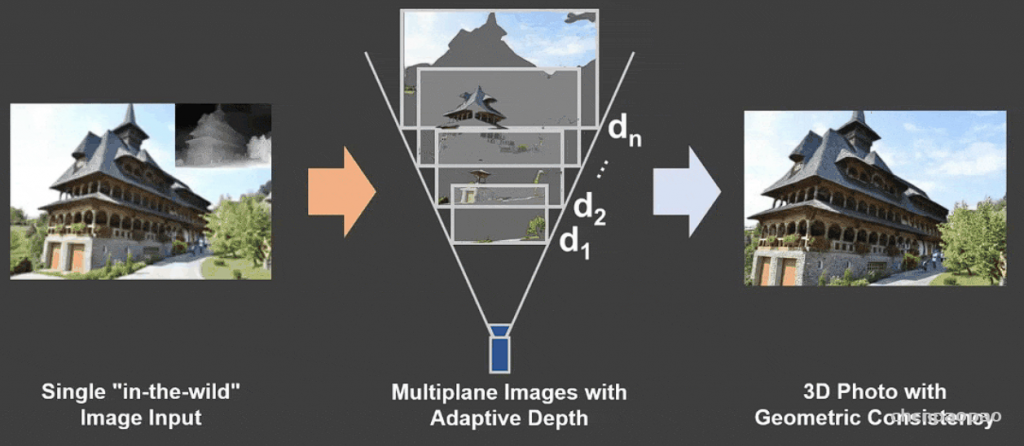
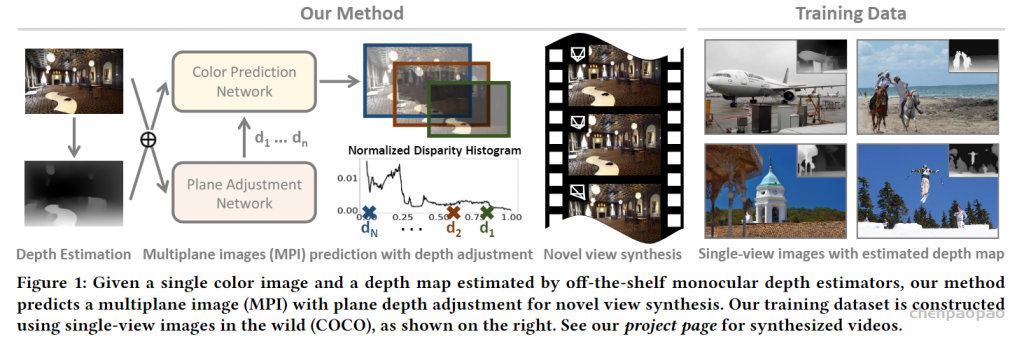
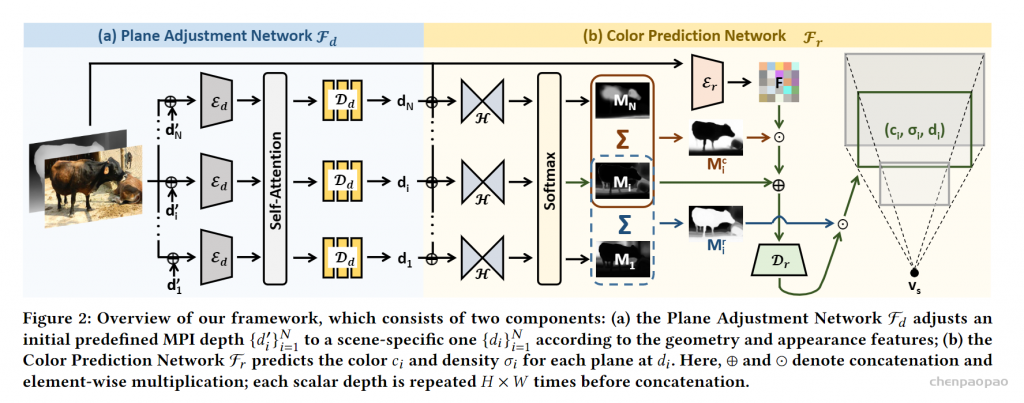
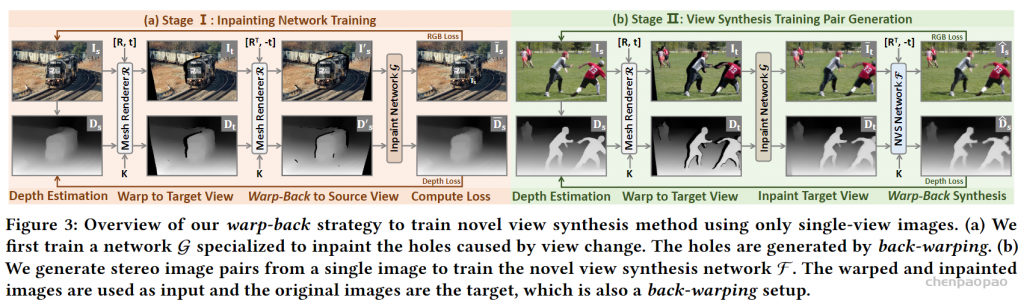
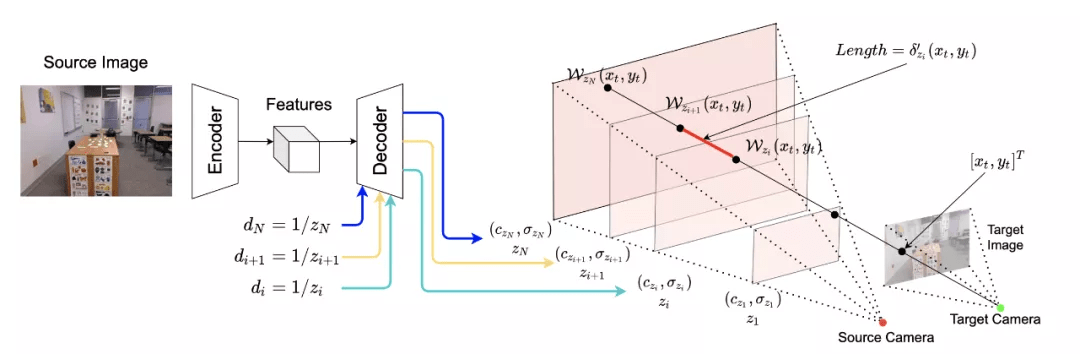
结合了NeRF和Multiplane Image(MPI),提出了一种新的三维空间表达方式MINE。MINE利用了NeRF的思路,将MPI扩展成了连续深度的形式。输入单张RGB图片,我们的方法会对source相机的视锥(frustum)做稠密的三维重建,同时对被遮挡的部分做inpainting,预测出相机视锥的三维表达。利用这个三维表达,给出target相机相对于source相机的在三维空间中的相对位置和角度变化(rotation and translation),我们可以方便且高效地渲染出在目标相机视图下的RGB图片以及深度图。
[1]. Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, Noah Snavely. Stereo Magnification: Learning View Synthesis using Multiplane Images. (SIGGRAPH 2018)
[2]. Ben Mildenhall, Pratul P. Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, Abhishek Kar. Local Light Field Fusion: Practical View Synthesis with Prescriptive Sampling Guidelines. (SIGGRAPH 2019)
[3]. Richard Tucker, Noah Snavely. Single-View View Synthesis with Multiplane Images. (CVPR 2020)
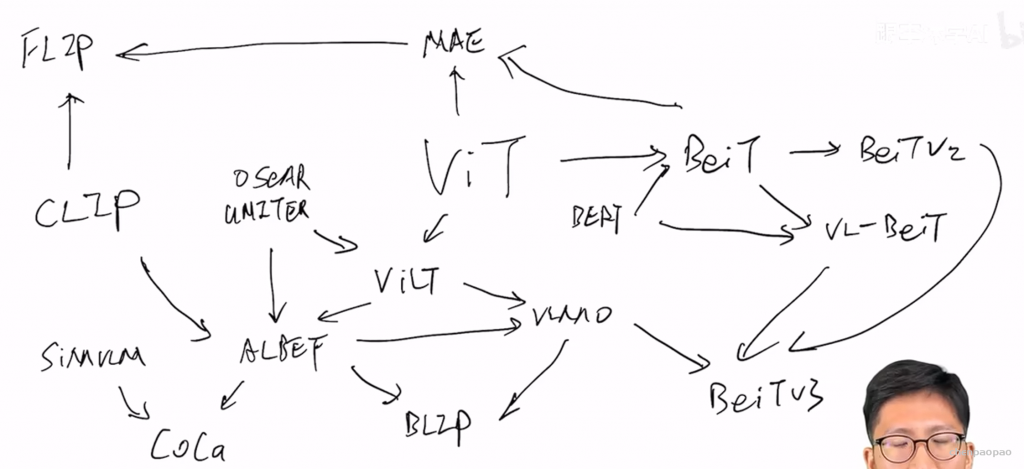
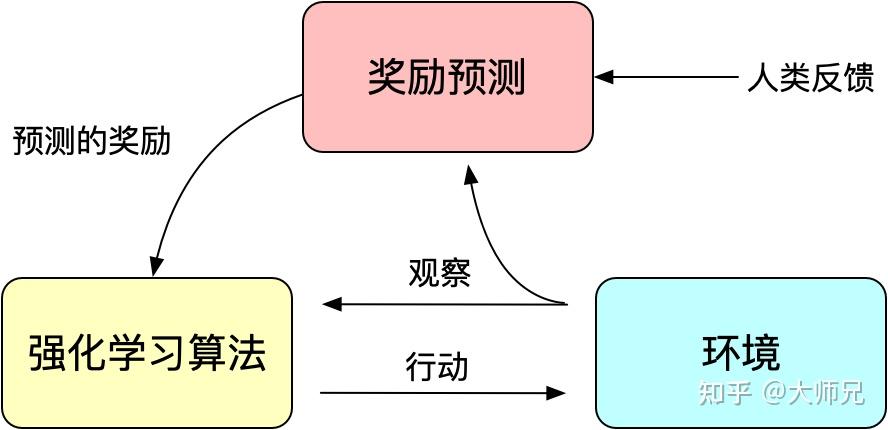
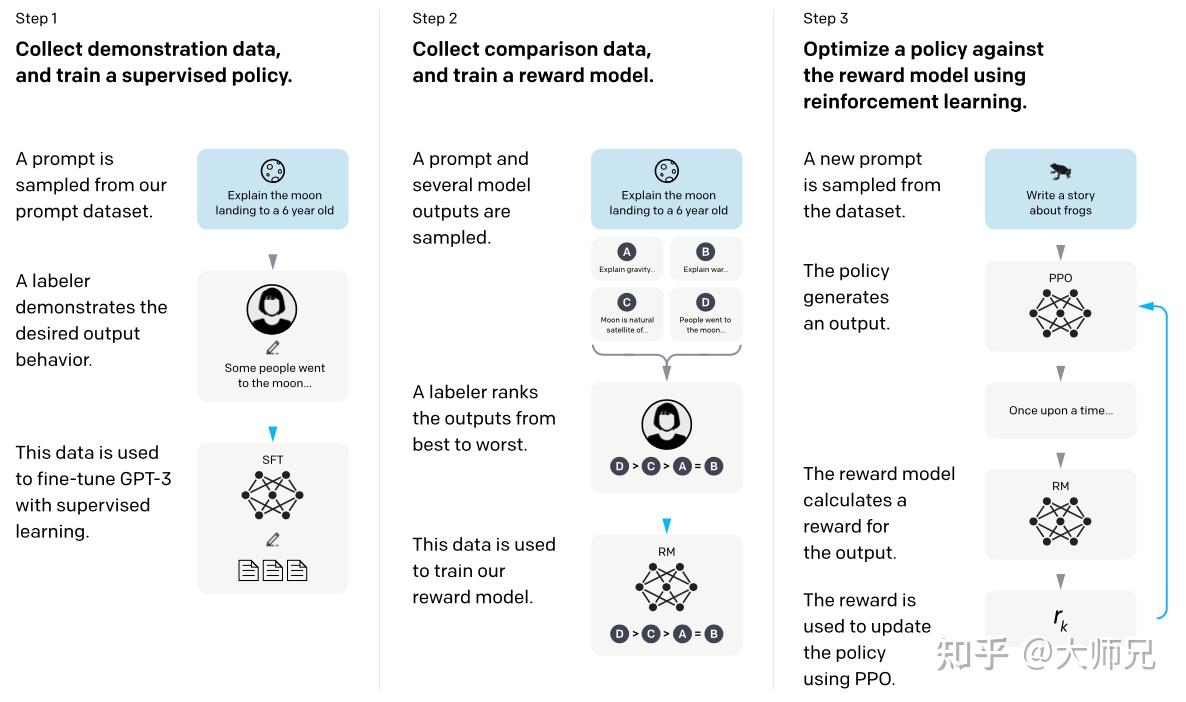
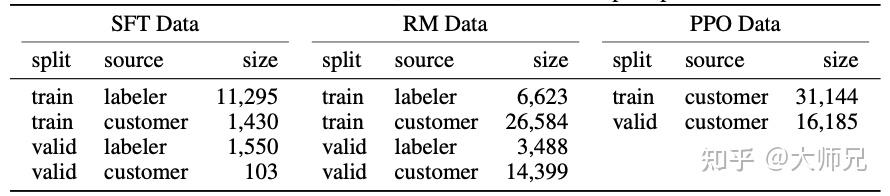
最近非常火的ChatGPT和今年年初公布的[1]是一对姐妹模型,是在GPT-4之前发布的预热模型,有时候也被叫做GPT3.5。ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指示学习(Instruction Learning)和人工反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,它们不同的仅仅是采集数据的方式上有所差异。所以要搞懂ChatGPT,我们必须要先读懂InstructGPT。
指示学习是谷歌Deepmind的Quoc V.Le团队在2021年的一篇名为《Finetuned Language Models Are Zero-Shot Learners》[5]文章中提出的思想。指示学习和提示学习的目的都是去挖掘语言模型本身具备的知识。不同的是Prompt是激发语言模型的补全能力,例如根据上半句生成下半句,或是完形填空等。Instruct是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。我们可以通过下面的例子来理解这两个不同的学习方式:
^Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” *arXiv preprint arXiv:2203.02155* (2022). https://arxiv.org/pdf/2203.02155.pdf
^Wei, Jason, et al. “Finetuned language models are zero-shot learners.” *arXiv preprint arXiv:2109.01652* (2021). https://arxiv.org/pdf/2109.01652.pdf
^Christiano, Paul F., et al. “Deep reinforcement learning from human preferences.” *Advances in neural information processing systems* 30 (2017). https://arxiv.org/pdf/1706.03741.pdf