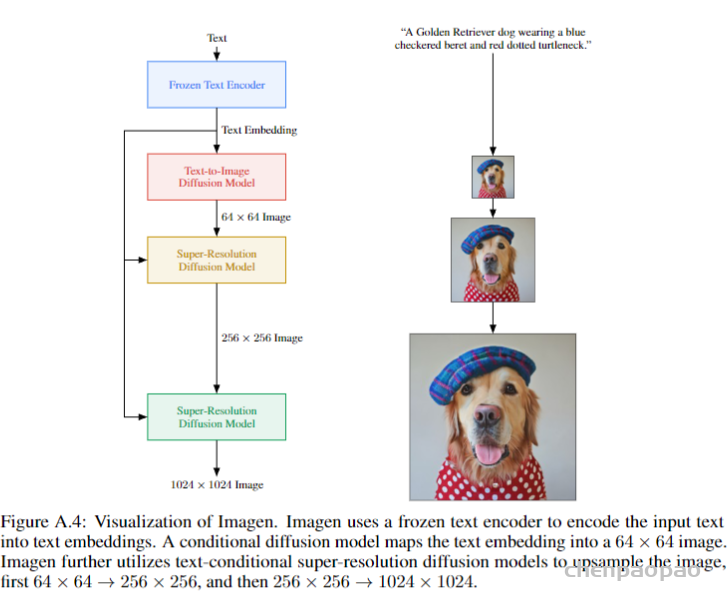
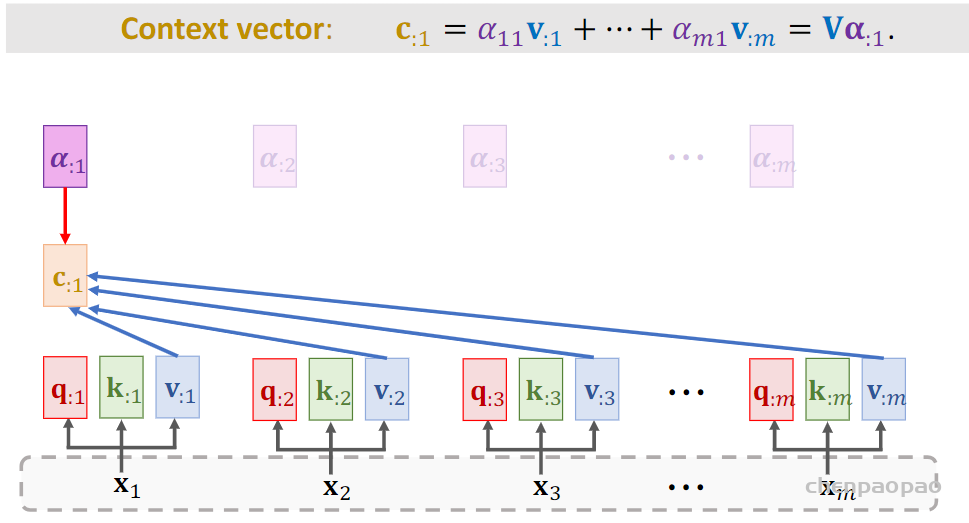
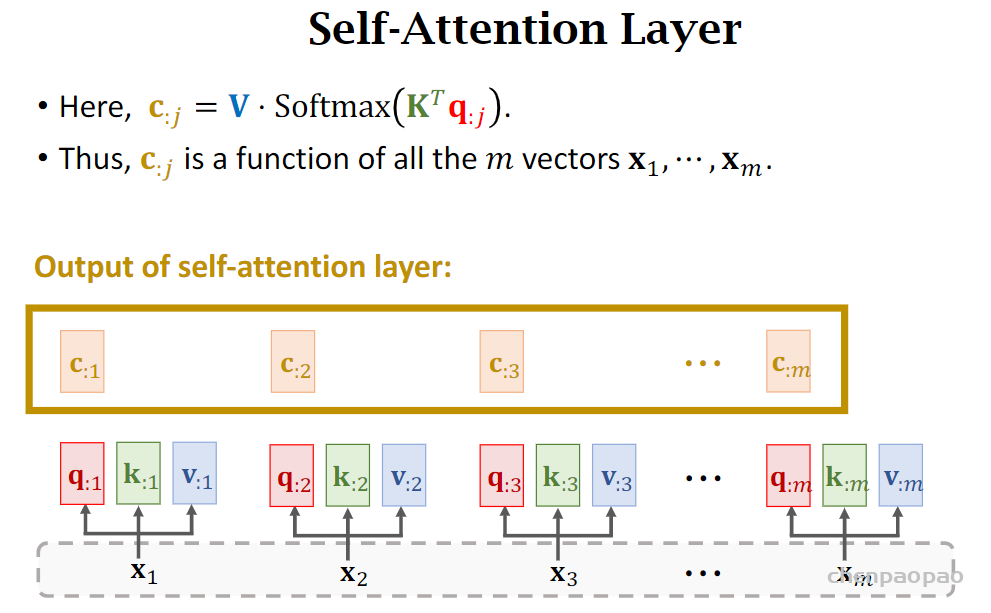
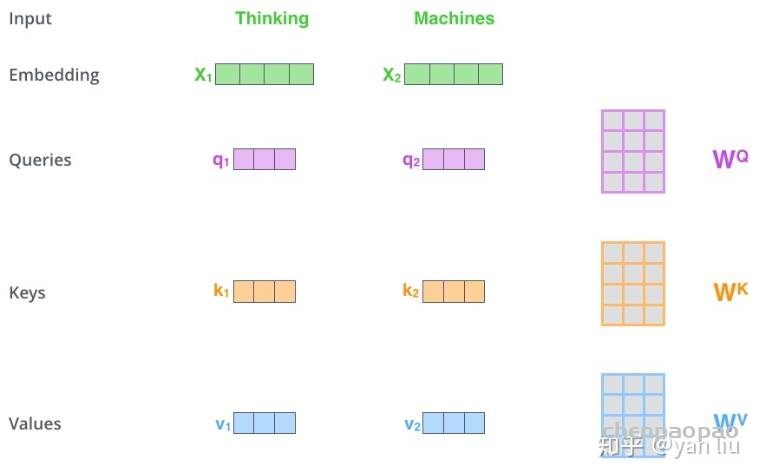
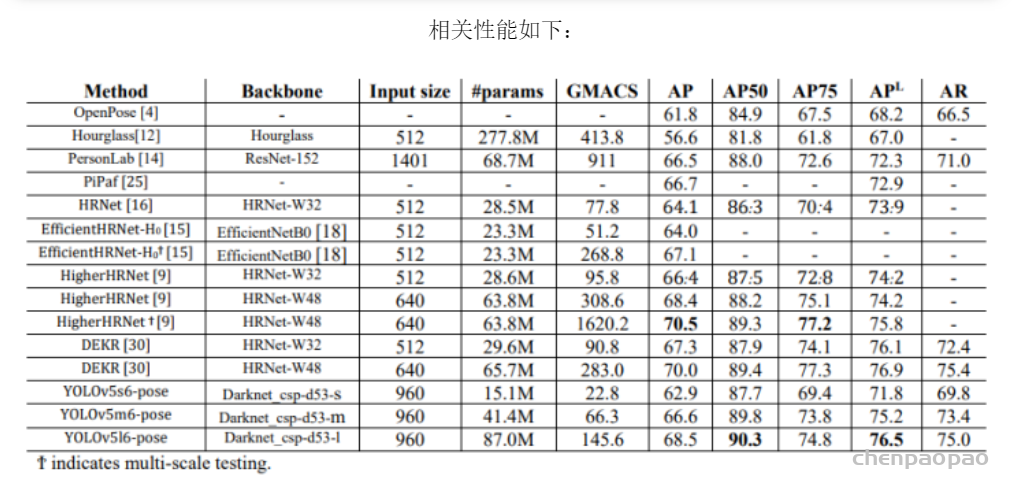
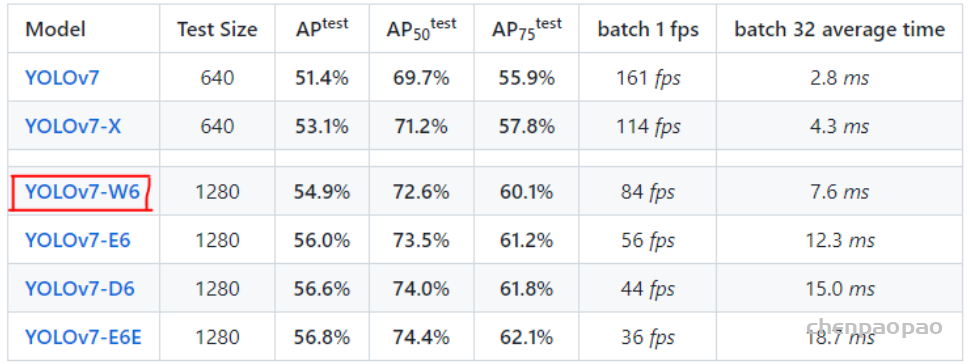
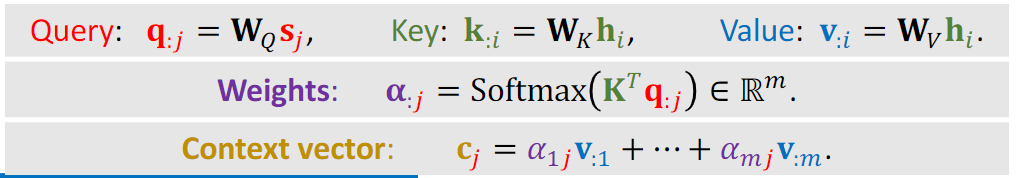论文:https://arxiv.org/abs/1809.00219
github: https://github.com/xinntao/ESRGAN
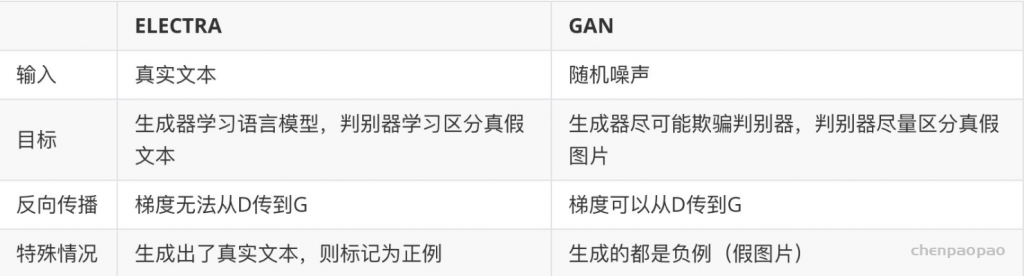
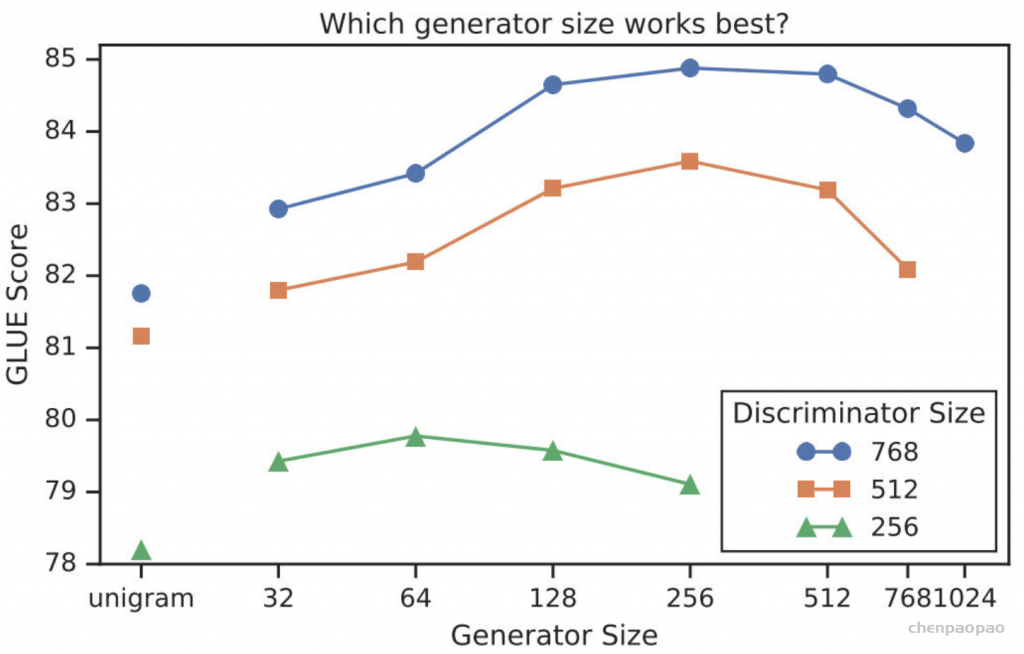
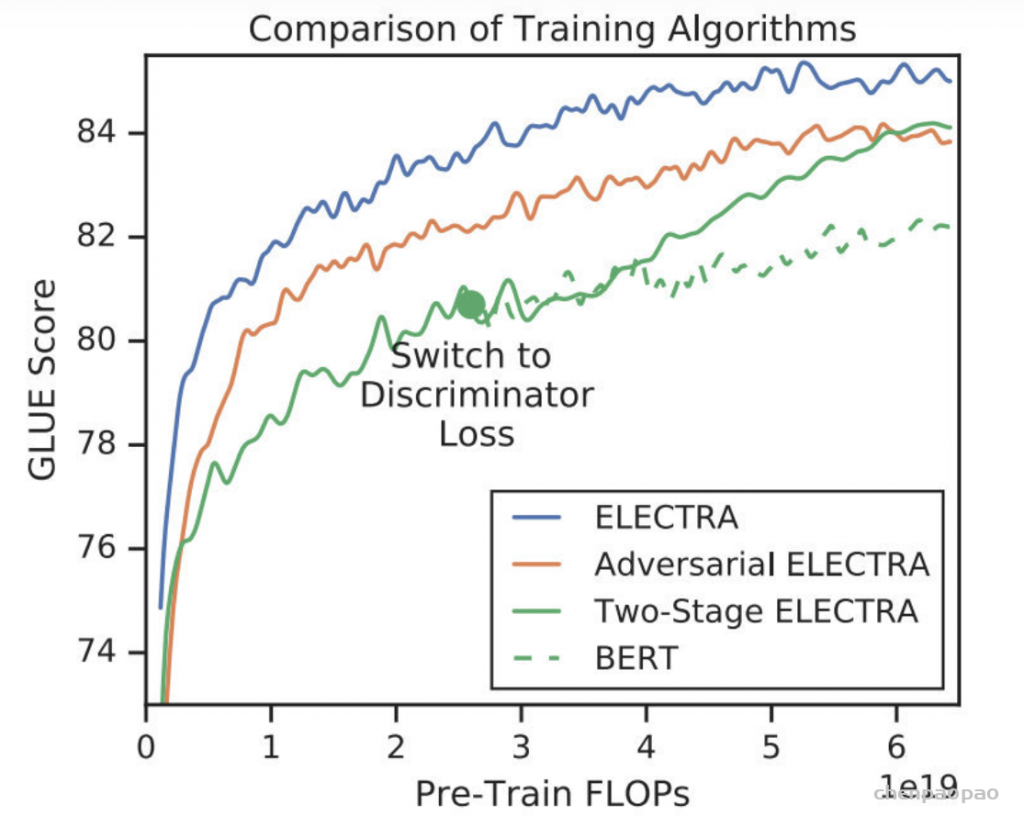
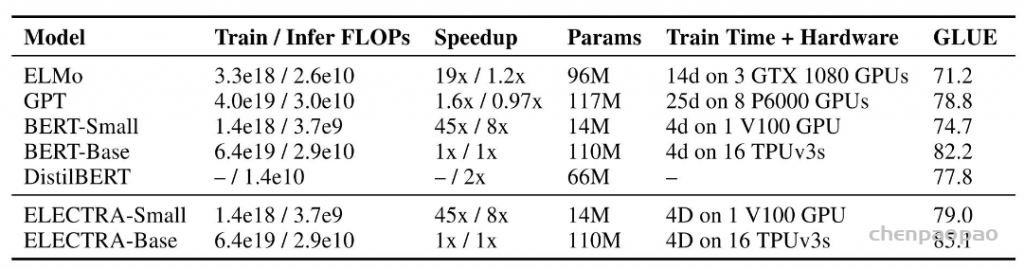
ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks发表于ECCV 2018 的 Workshops,在SRGAN的基础上进行了改进,包括改进网络的结构,判决器的判决形式,以及更换了一个用于计算感知域损失的预训练网络。
超分辨率生成对抗网络(SRGAN)是一项开创性的工作,能够在单一图像超分辨率中生成逼真的纹理。这项工作发表于CVPR 2017,
文章链接:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
但是,放大后的细节通常伴随着令人不快的伪影。为了更进一步地提升视觉质量,作者仔细研究了SRGAN的三个关键部分:1.网络结构 2.对抗性损失 3.感知域损失;并对每一项进行改进,得到ESRGAN。具体而言,文章提出了一种Residual-in-Residual Dense Block (RRDB)的网络单元,在这个单元中,去掉了BN(Batch Norm)层。此外,作者借鉴了relativistic GAN的想法,让判别器预测图像的真实性而不是图像“是否是fake图像”。最后,文章对感知域损失进行改进,使用激活前的特征,这样可以为亮度一致性和纹理恢复提供更强的监督。在这些改进的帮助下,ESRGAN得到了更好的视觉质量以及更逼真和自然的纹理。

SRGAN的思考与贡献
现有的超分辨率网络在不同的网络结构设计以及训练策略下,超分辨的效果得到了很大的提升,特别是PSNR指标。但是,基于PSNR指标的模型会倾向于生成过度平滑的结果,这些结果缺少必要的高频信息。PSNR指标与人类观察者的主观评价从根本上就不统一。
一些基于感知域信息驱动的方法已经提出来用于提升超分辨率结果的视觉质量。例如,感知域的损失函数提出来用于在特征空间(instead of 像素空间)中优化超分辨率模型;生成对抗网络通过鼓励网络生成一些更接近于自然图像的方法来提升超分辨率的质量;语义图像先验信息用于进一步改善恢复的纹理细节。
通过结合上面的方法,SRGAN模型极大地提升了超分辨率结果的视觉质量。但是SRGAN模型得到的图像和GT图像仍有很大的差距。
ESRGAN的改进
文章对这三点做出改进:1.网络的基本单元从基本的残差单元变为Residual-in-Residual Dense Block (RRDB);2.GAN网络改进为Relativistic average GAN (RaGAN);3.改进感知域损失函数,使用激活前的VGG特征,这个改进会提供更尖锐的边缘和更符合视觉的结果。
网络结构及思想
生成器部分
首先,作者参考SRResNet结构作为整体的网络结构,SRResNet的基本结构如下:
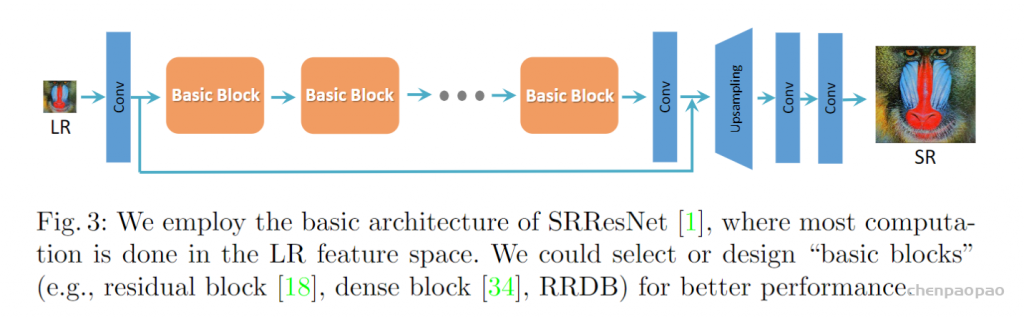
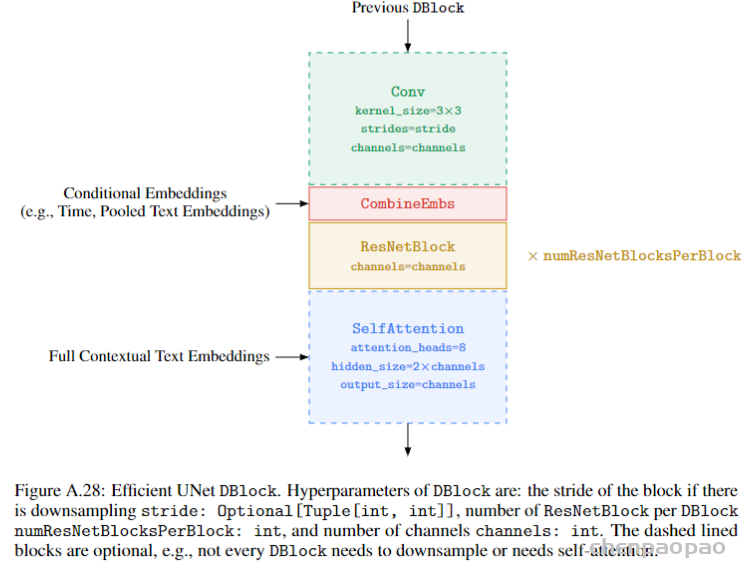
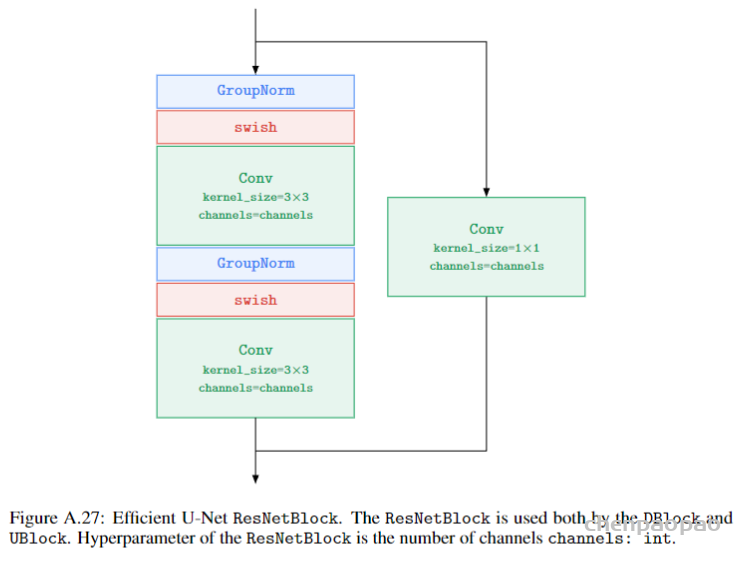
为了提升SRGAN重构的图像的质量,作者主要对生成器G做出如下改变:1.去掉所有的BN层;2.把原始的block变为Residual-in-Residual Dense Block (RRDB),这个block结合了多层的残差网络和密集连接。
如下图所示:
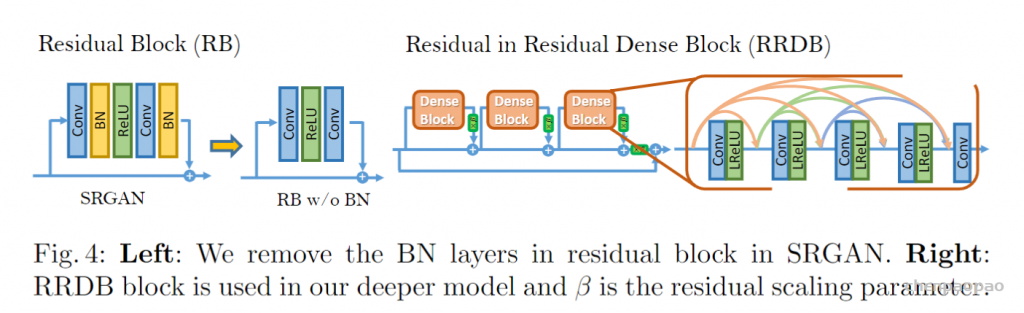
思想:
BN层的影响
对于不同的基于PSNR的任务(包括超分辨率和去模糊)来说,去掉BN层已经被证明会提高表现和减小计算复杂度。BN层在训练时,使用一个batch的数据的均值和方差对该batch特征进行归一化,在测试时,使用在整个测试集上的数据预测的均值和方差。当训练集和测试集的统计量有很大不同的时候,BN层就会倾向于生成不好的伪影,并且限制模型的泛化能力。作者发现,BN层在网络比较深,而且在GAN框架下进行训练的时候,更会产生伪影。这些伪影偶尔出现在迭代和不同的设置中,违反了对训练稳定性能的需求。所以为了稳定的训练和一致的性能,作者去掉了BN层。此外,去掉BN层也能提高模型的泛化能力,减少计算复杂度和内存占用。
Trick:
除了上述的改进,作者也使用了一些技巧来训练深层网络:1.对残差信息进行scaling,即将残差信息乘以一个0到1之间的数,用于防止不稳定;2.更小的初始化,作者发现当初始化参数的方差变小时,残差结构更容易进行训练。
判别器部分
除了改进的生成器,作者也基于Relativistic GAN改进了判别器。判别器 D 使用的网络是 VGG 网络,SRGAN中的判别器D用于估计输入到判别器中的图像是真实且自然图像的概率,而Relativistic判别器则尝试估计真实图像相对来说比fake图像更逼真的概率。

具体而言,作者把标准的判别器换成Relativistic average Discriminator(RaD),所以判别器的损失函数定义为:
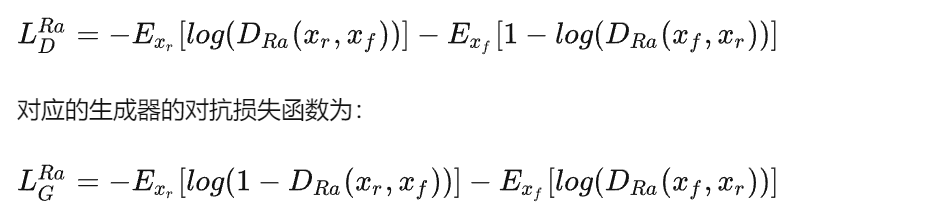
求均值的操作是通过对mini-batch中的所有数据求平均得到的,xf是原始低分辨图像经过生成器以后的图像。
可以观察到,对抗损失包含了xr和xf,所以这个生成器受益于对抗训练中的生成数据和实际数据的梯度,这种调整会使得网络学习到更尖锐的边缘和更细节的纹理。
感知域损失
文章也提出了一个更有效的感知域损失,使用激活前的特征(VGG16网络)。
感知域的损失当前是定义在一个预训练的深度网络的激活层,这一层中两个激活了的特征的距离会被最小化。与此相反,文章使用的特征是激活前的特征,这样会克服两个缺点。第一,激活后的特征是非常稀疏的,特别是在很深的网络中。这种稀疏的激活提供的监督效果是很弱的,会造成性能低下;第二,使用激活后的特征会导致重建图像与GT的亮度不一致。

作者对使用的感知域损失进行了探索。与目前多数使用的用于图像分类的VGG网络构建的感知域损失相反,作者提出一种更适合于超分辨的感知域损失,这个损失基于一个用于材料识别的VGG16网络(MINCNet),这个网络更聚焦于纹理而不是物体。尽管这样带来的增益很小,但作者仍然相信,探索关注纹理的感知域损失对超分辨至关重要。
损失函数
经过上面对网络模块的定义和构建以后,再定义损失函数,就可以进行训练了。
对于生成器G,它的损失函数为:


代码解析:
https://zhuanlan.zhihu.com/p/54473407?utm_id=0
3.提取感知域损失的网络(Perceptual Network)
文章使用了一个用于材料识别的VGG16网络(MINCNet)来提取感知域特征,定义如下:
class MINCNet(nn.Module):
def __init__(self):
super(MINCNet, self).__init__()
self.ReLU = nn.ReLU(True)
self.conv11 = nn.Conv2d(3, 64, 3, 1, 1)
self.conv12 = nn.Conv2d(64, 64, 3, 1, 1)
self.maxpool1 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv21 = nn.Conv2d(64, 128, 3, 1, 1)
self.conv22 = nn.Conv2d(128, 128, 3, 1, 1)
self.maxpool2 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv31 = nn.Conv2d(128, 256, 3, 1, 1)
self.conv32 = nn.Conv2d(256, 256, 3, 1, 1)
self.conv33 = nn.Conv2d(256, 256, 3, 1, 1)
self.maxpool3 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv41 = nn.Conv2d(256, 512, 3, 1, 1)
self.conv42 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv43 = nn.Conv2d(512, 512, 3, 1, 1)
self.maxpool4 = nn.MaxPool2d(2, stride=2, padding=0, ceil_mode=True)
self.conv51 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv52 = nn.Conv2d(512, 512, 3, 1, 1)
self.conv53 = nn.Conv2d(512, 512, 3, 1, 1)
def forward(self, x):
out = self.ReLU(self.conv11(x))
out = self.ReLU(self.conv12(out))
out = self.maxpool1(out)
out = self.ReLU(self.conv21(out))
out = self.ReLU(self.conv22(out))
out = self.maxpool2(out)
out = self.ReLU(self.conv31(out))
out = self.ReLU(self.conv32(out))
out = self.ReLU(self.conv33(out))
out = self.maxpool3(out)
out = self.ReLU(self.conv41(out))
out = self.ReLU(self.conv42(out))
out = self.ReLU(self.conv43(out))
out = self.maxpool4(out)
out = self.ReLU(self.conv51(out))
out = self.ReLU(self.conv52(out))
out = self.conv53(out)
return out再引入预训练参数,就可以进行特征提取:
class MINCFeatureExtractor(nn.Module):
def __init__(self, feature_layer=34, use_bn=False, use_input_norm=True, \
device=torch.device('cpu')):
super(MINCFeatureExtractor, self).__init__()
self.features = MINCNet()
self.features.load_state_dict(
torch.load('../experiments/pretrained_models/VGG16minc_53.pth'), strict=True)
self.features.eval()
# No need to BP to variable
for k, v in self.features.named_parameters():
v.requires_grad = False
def forward(self, x):
output = self.features(x)
return output网络插值思想
为了平衡感知质量和PSNR等评价值,作者提出了一个灵活且有效的方法—网络插值。具体而言,作者首先基于PSNR方法训练的得到的网络G_PSNR,然后再用基于GAN的网络G_GAN进行finetune。
然后,对这两个网络相应的网络参数进行插值得到一个插值后的网络G_INTERP:
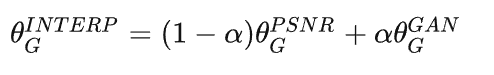
这样就可以通过 α 值来调整效果
训练细节
训练细节
放大倍数:4,mini-batch:16
通过Matlab的bicubic函数对HR图像进行降采样得到LR图像。
HR patch大小:128×128(实验发现使用大的patch时,训练一个深层网络效果会更好,因为一个增大的感受域会帮助模型捕捉更具有语义的信息)
训练过程:
1.训练一个基于PSNR指标的模型(L1 Loss)
初始化学习率:2×1e-4
每200000个mini-batch学习率除以2
2.以1中训练的模型作为生成器的初始化
λ=5×10−3,η=0.01,β=0.2 (残差scaling系数)
初始学习率:1e-4,并在50k,100k,200k,300k迭代后减半。
一个基于像素损失函数进行优化的预训练模型会帮助基于GAN的模型生成更符合视觉的结果,原因如下:1.可以避免生成器不希望的局部最优;2.再预训练以后,判别器所得到的输入图像的质量是相对较好的,而不是完全初始化的图像,这样会使判别器更关注到纹理的判别。
优化器:Adam( β1=0.9,β2=0.999 );交替更新生成器和判别器,直到收敛。
生成器的设置:1.16层(基本的残差结构) 2.23层(RDDB)
数据集:DIV2K,Flickr2K,OST;(有丰富纹理信息的数据集会是模型产生更自然的结果)

经过实验以后,作者得出结论:
1.去掉BN:并没有降低网络的性能,而且节省了计算资源和内存占用。而且发现当网络变深变复杂时,带BN层的模型更倾向于产生影响视觉效果的伪影。
2.使用激活前的特征:得到 的图像的亮度更准确,而且可以产生更尖锐的边缘和更丰富的细节。
3.RaGAN:产生更尖锐的边缘和更丰富的细节。
4.RDDB:更加提升恢复得到的纹理(因为深度模型具有强大的表示能力来捕获语义信息),而且可以去除噪声。
网络插值实验
为了平衡视觉效果和PSNR等性能指标,作者对网络插值参数 α 的取值进行了实验,结果如下:

总结
文章提出的ESRGAN在SRGAN的基础上做出了改进,包括去除BN层,基本结构换成RDDB,改进GAN中判别器的判别目标,以及使用激活前的特征构成感知域损失函数,实验证明这些改进对提升输出图像的视觉效果都有作用。此外,作者也使用了一些技巧来提升网络的性能,包括对残差信息的scaling,以及更小的初始化。最后,作者使用了一种网络插值的方法来平衡输出图像的视觉效果和PSNR等指标值。