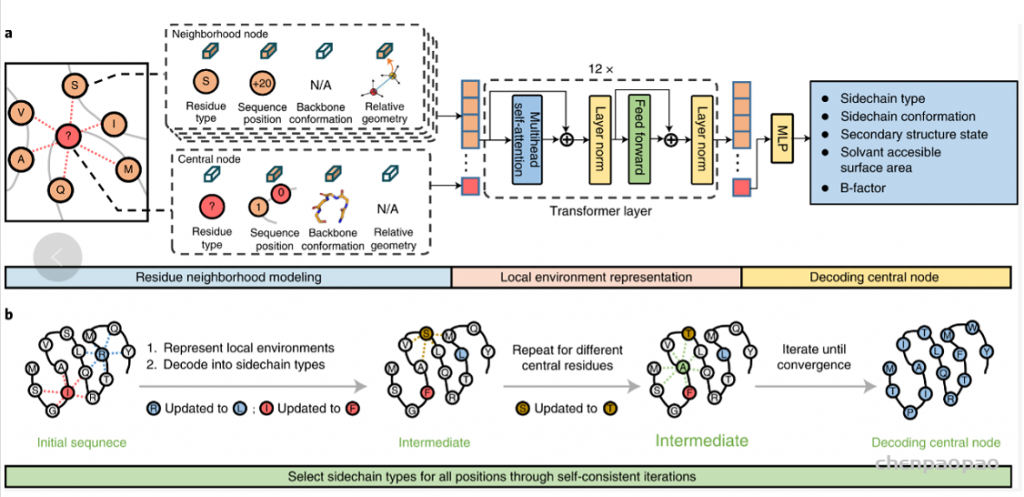
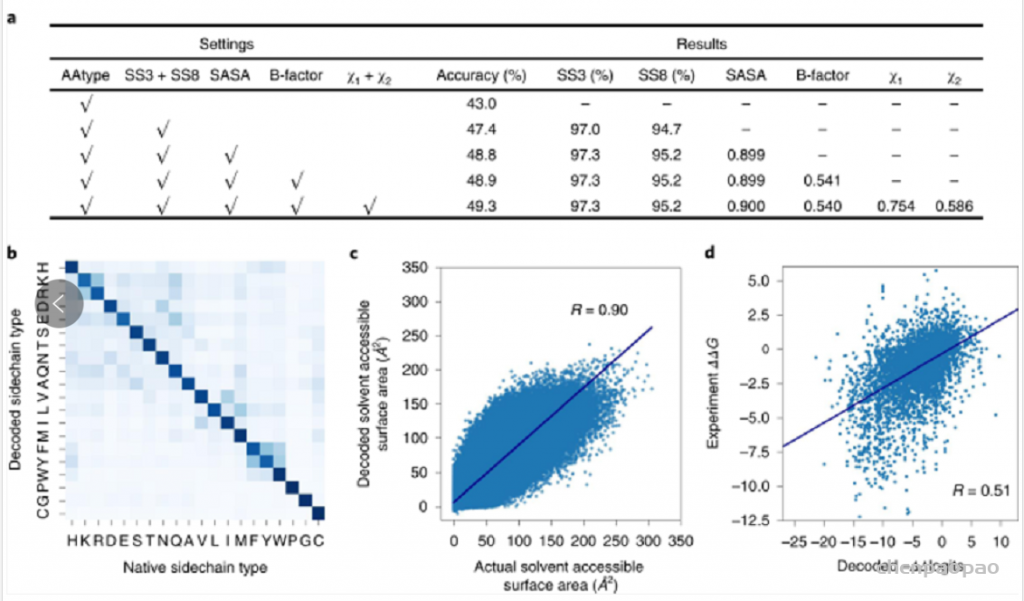
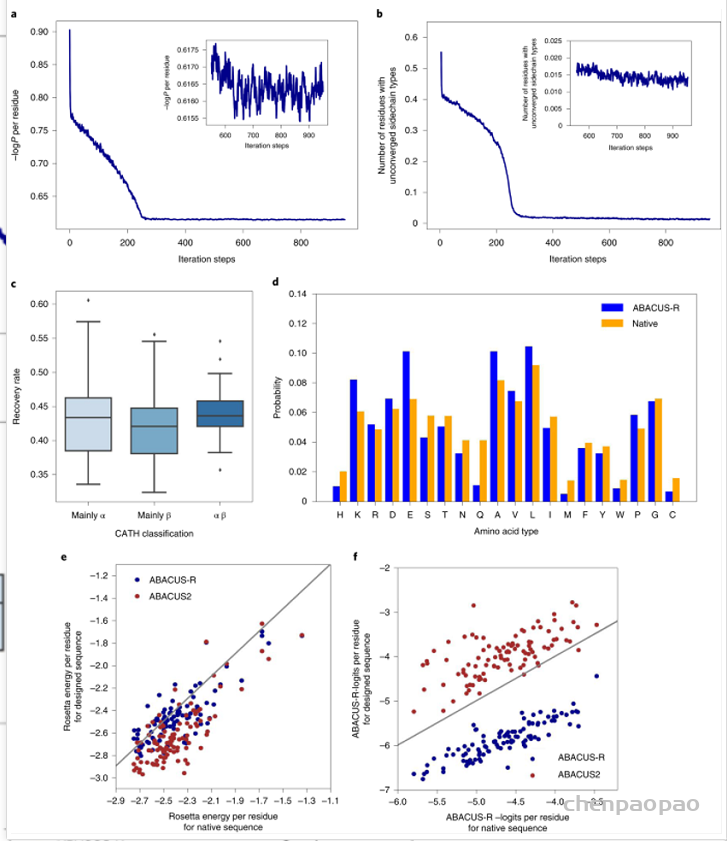
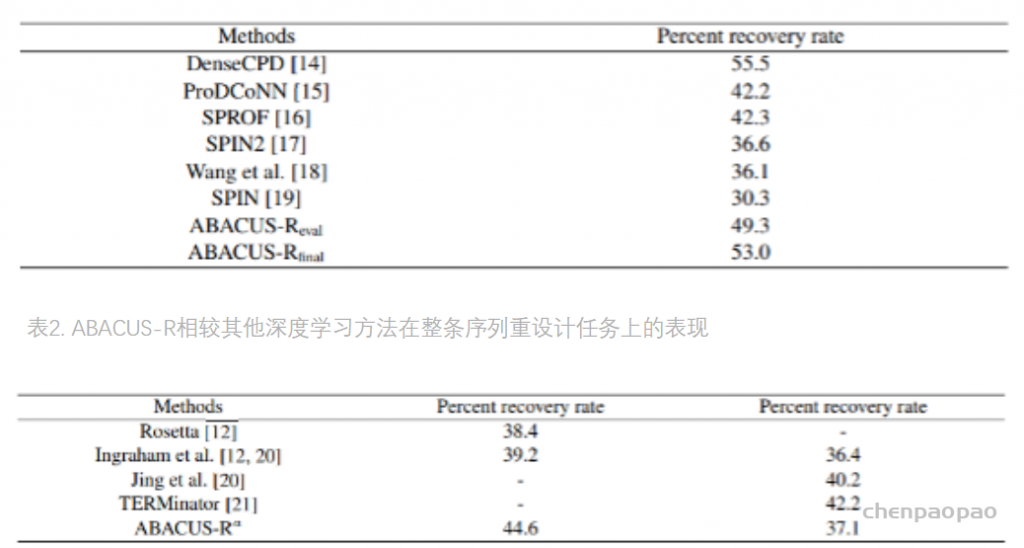
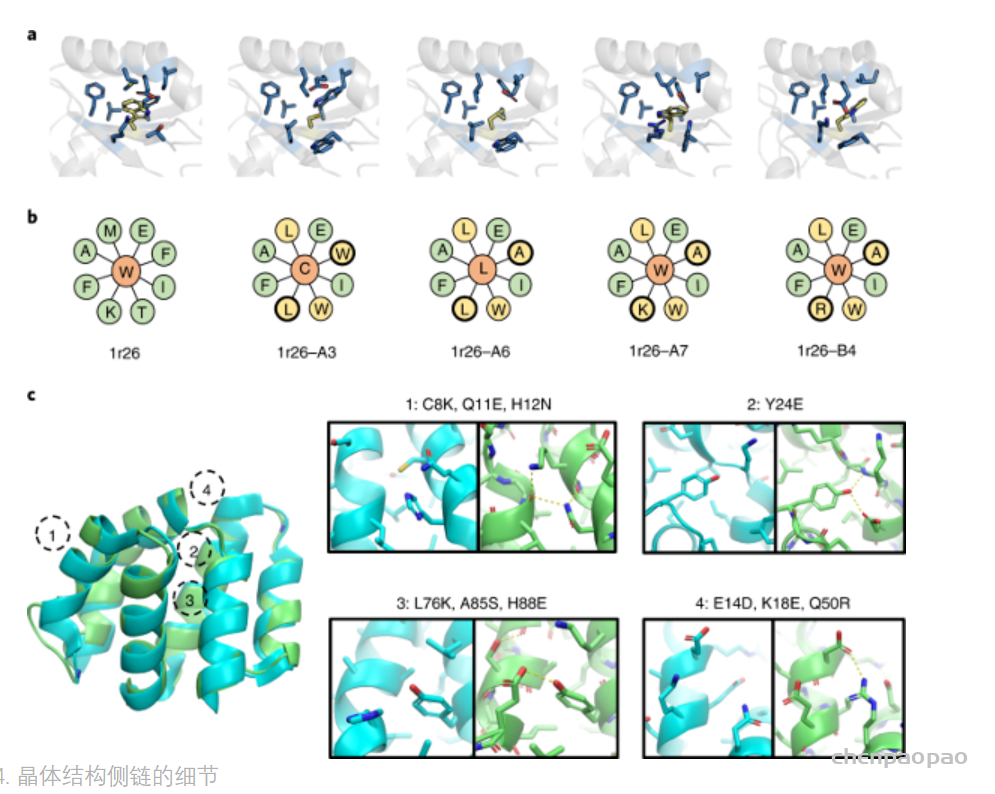
现有的基于蛋白结构的深度学习序列设计方法,虽然在测试的计算指标上取得了很好的成果,但是还鲜有方法经过实验的考验仍然超越传统的能量函数方法。基于这一挑战,中国科学技术大学的刘海燕教授课题组,发展了名为ABACUS-R方法,相关工作名为Rotamer-free protein sequence design based on deep learning and self-consistency,于近期发表在Nature Computational Science上。
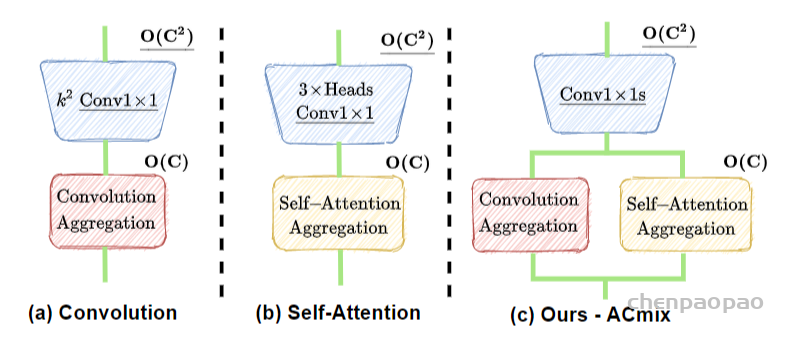
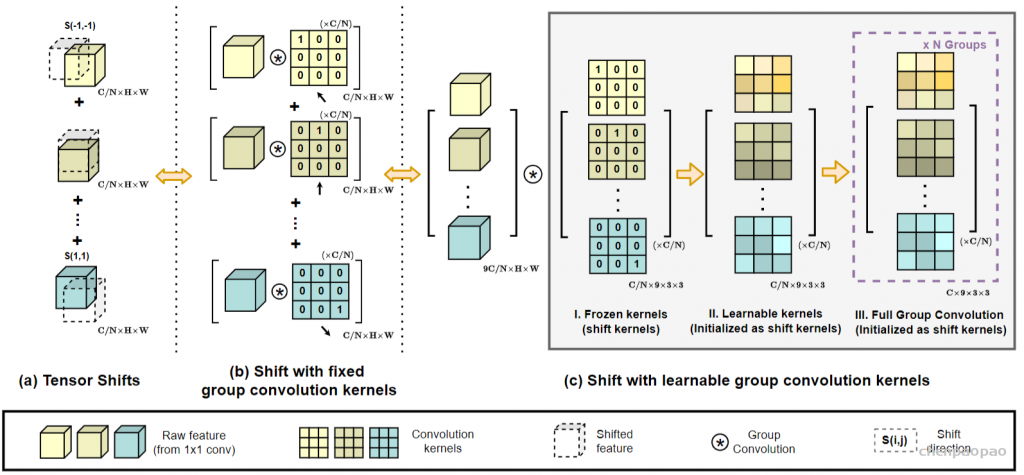
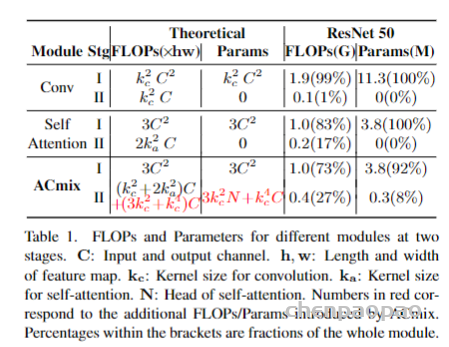
标准卷积可以分为两个部分,第一个阶段为一个特征学习模块,通过执行1 x 1的卷积共享相同的操作将特征投影到更深的空间,第二阶段对应于特征聚合的过程。作为结论,分析表明卷积和自注意力在通过1 x 1的卷积投影输入特征图实际上共享相同的操作,聚合操作是轻量级的,并不需要获取额外的学习参数。卷积和自注意力的示意图如下图所示。
2、将self-attention和convolution进行整合
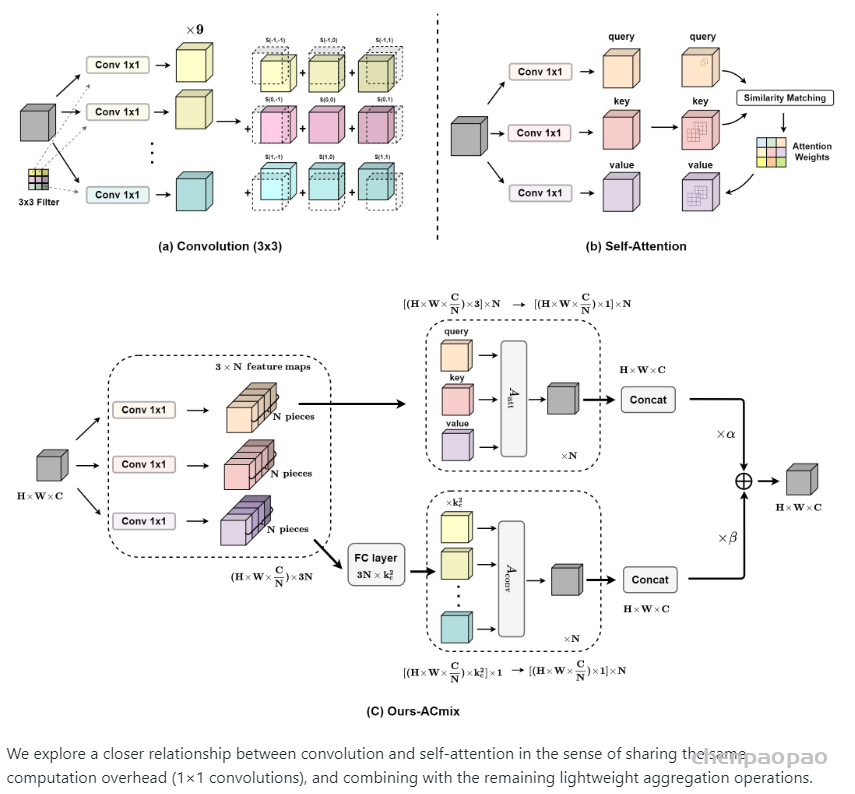
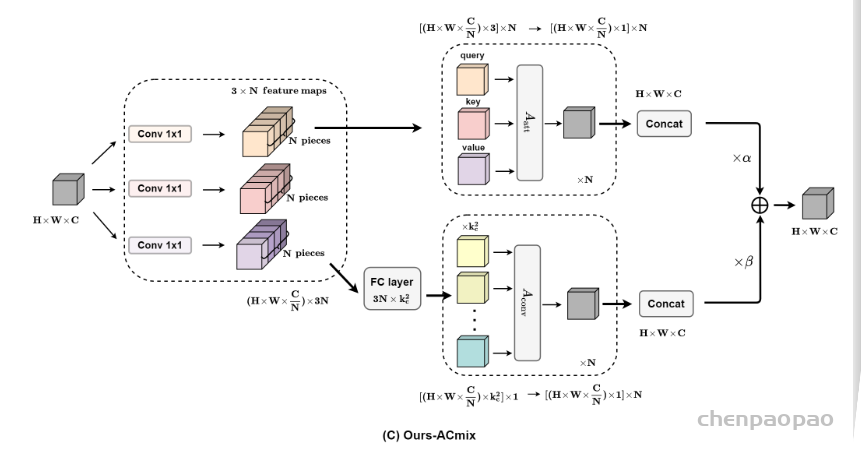
作者根据上述的分析提出ACmix模型,如下图所示:
ACmix模型分为两个阶段,在阶段一,输入特征由三个1 x 1的卷积操作并被reshape成N块,由此获得丰富的3 x N的特征图;在阶段二,对于self-attention,作者将中间特征收集到N组中,每组包含三个部分特征,其中每个1 x 1卷积对应一个。通过移动和聚合生成的特征(用以下公式表达),并像传统方法一样从本地感受野中收集信息。
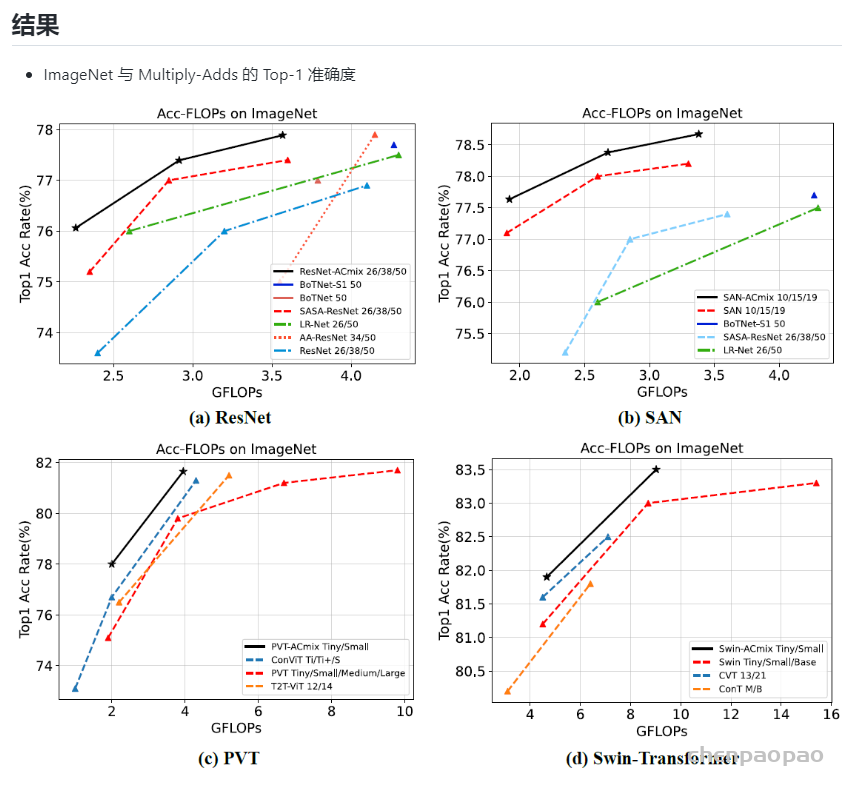
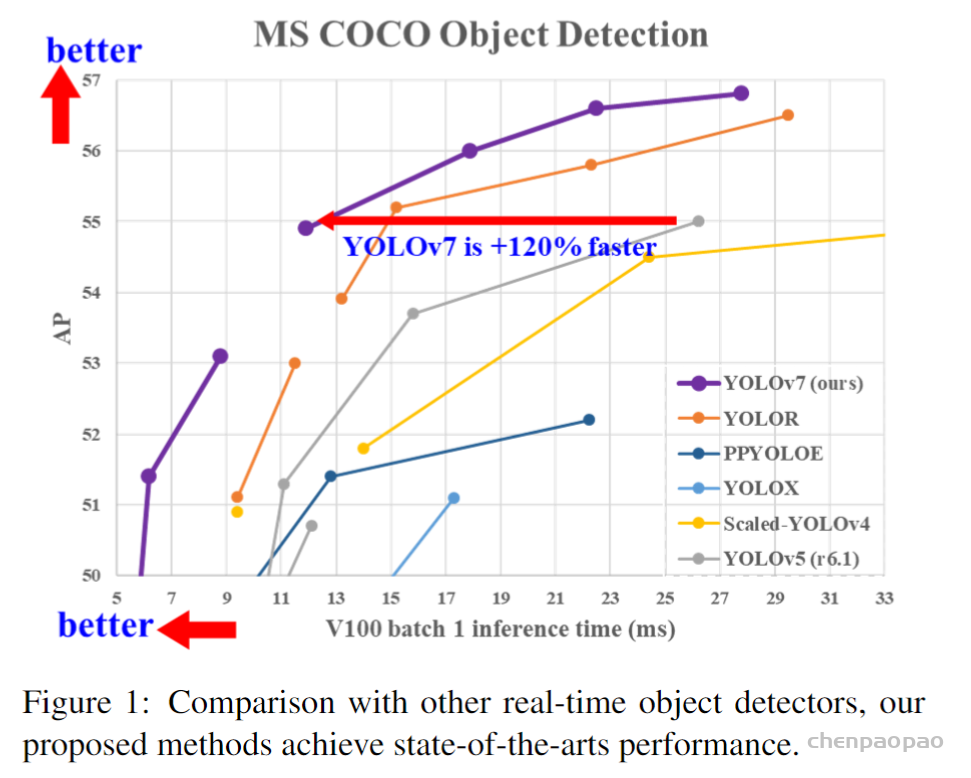
作者为实时探测器提出了“扩展”和“复合缩放”(extend” and “compound scaling”)方法,可以更加高效地利用参数和计算量,同时,作者提出的方法可以有效地减少实时探测器50%的参数,并且具备更快的推理速度和更高的检测精度。(这个其实和YOLOv5或者Scale YOLOv4的baseline使用不同规格分化成几种模型类似,既可以是width和depth的缩放,也可以是module的缩放)
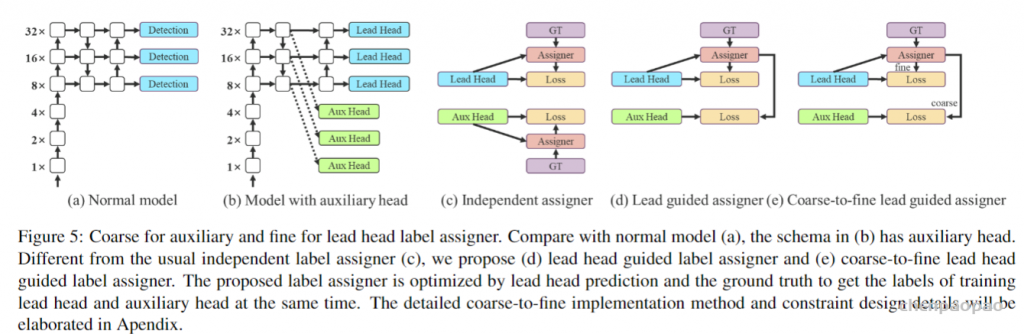
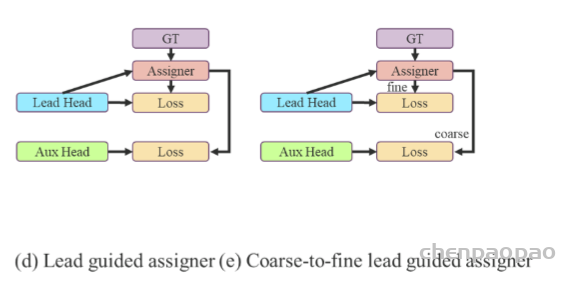
Lead head guided label assigner: 引导头引导“标签分配器”预测结果和ground truth进行计算,并通过优化(在utils/loss.py的SigmoidBin()函数中,传送门:https://github.com/WongKinYiu/yolov7/blob/main/utils/loss.py 生成软标签。这组软标签将作为辅助头和引导头的目标来训练模型。(之前写过一篇博客,【浅谈计算机视觉中的知识蒸馏】]https://zhuanlan.zhihu.com/p/497067556)详细讲过soft label的好处)这样做的目的是使引导头具有较强的学习能力,由此产生的软标签更能代表源数据与目标之间的分布差异和相关性。此外,作者还可以将这种学习看作是一种广义上的余量学习。通过让较浅的辅助头直接学习引导头已经学习到的信息,引导头能更加专注于尚未学习到的残余信息。
Coarse-to-fine lead head guided label assigner: Coarse-to-fine引导头使用到了自身的prediction和ground truth来生成软标签,引导标签进行分配。然而,在这个过程中,作者生成了两组不同的软标签,即粗标签和细标签,其中细标签与引导头在标签分配器上生成的软标签相同,粗标签是通过降低正样本分配的约束,允许更多的网格作为正目标(可以看下FastestDet的label assigner,不单单只把gt中心点所在的网格当成候选目标,还把附近的三个也算进行去,增加正样本候选框的数量)。原因是一个辅助头的学习能力并不需要强大的引导头,为了避免丢失信息,作者将专注于优化样本召回的辅助头。对于引导头的输出,可以从查准率中过滤出高精度值的结果作为最终输出。然而,值得注意的是,如果粗标签的附加权重接近细标签的附加权重,则可能会在最终预测时产生错误的先验结果。
EMA Model:EMA 是一种在mean teacher中使用的技术,作者使用 EMA 模型作为最终的推理模型。
五、实验
5.1 实验环境
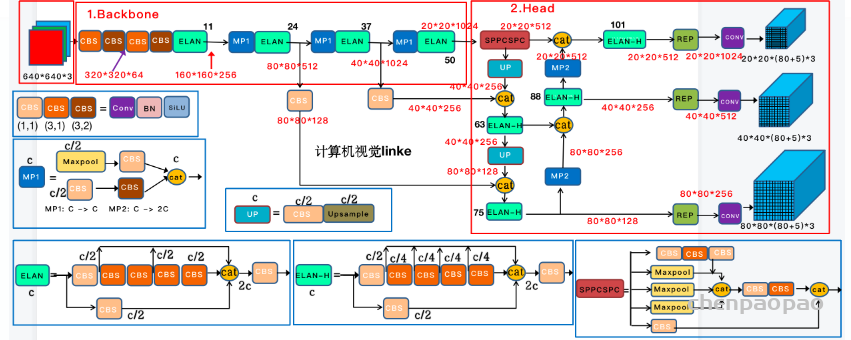
作者为边缘GPU、普通GPU和云GPU设计了三种模型,分别被称为YOLOv7-Tiny、YOLOv7和YOLOv7-W6。同时,还使用基本模型针对不同的服务需求进行缩放,并得到不同大小的模型。对于YOLOv7,可进行颈部缩放(module scale),并使用所提出的复合缩放方法对整个模型的深度和宽度进行缩放(depth and width scale),此方式获得了YOLOv7-X。对于YOLOv7-W6,使用提出的缩放方法得到了YOLOv7-E6和YOLOv7-D6。此外,在YOLOv7-E6使用了提出的E-ELAN,从而完成了YOLOv7-E6E。由于YOLOv7-tincy是一个面向边缘GPU架构的模型,因此它将使用ReLU作为激活函数。作为对于其他模型,使用SiLU作为激活函数。
AP % AP at IoU=0.50:0.05:0.95 (primary challenge metric)
APIoU=.50 % AP at IoU=0.50 (PASCAL VOC metric)
APIoU=.75 % AP at IoU=0.75 (strict metric)
AP Across Scales:
APsmall % AP for small objects: area < 322
APmedium % AP for medium objects: 322 < area < 962
APlarge % AP for large objects: area > 962
Average Recall (AR):
ARmax=1 % AR given 1 detection per image
ARmax=10 % AR given 10 detections per image
ARmax=100 % AR given 100 detections per image
AR Across Scales:
ARsmall % AR for small objects: area < 322
ARmedium % AR for medium objects: 322 < area < 962
ARlarge % AR for large objects: area > 962
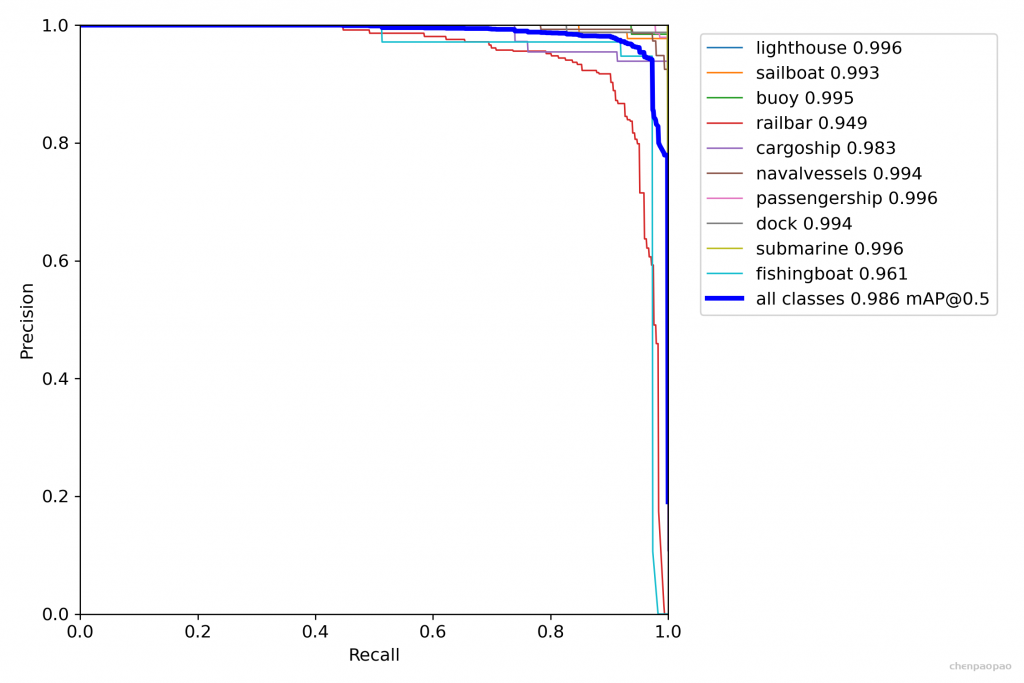
1)除非另有说明,否则AP和AR在多个交汇点(IoU)值上取平均值。具体来说,我们使用10个IoU阈值0.50:0.05:0.95。这是对传统的一个突破,其中AP是在一个单一的0.50的IoU上计算的(这对应于我们的度量APIoU=.50 )。超过均值的IoUs能让探测器更好定位(Averaging over IoUs rewards detectors with better localization.)。
2)AP是所有类别的平均值。传统上,这被称为“平均精确度”(mAP,mean average precision)。我们没有区分AP和mAP(同样是AR和mAR),并假定从上下文中可以清楚地看出差异。
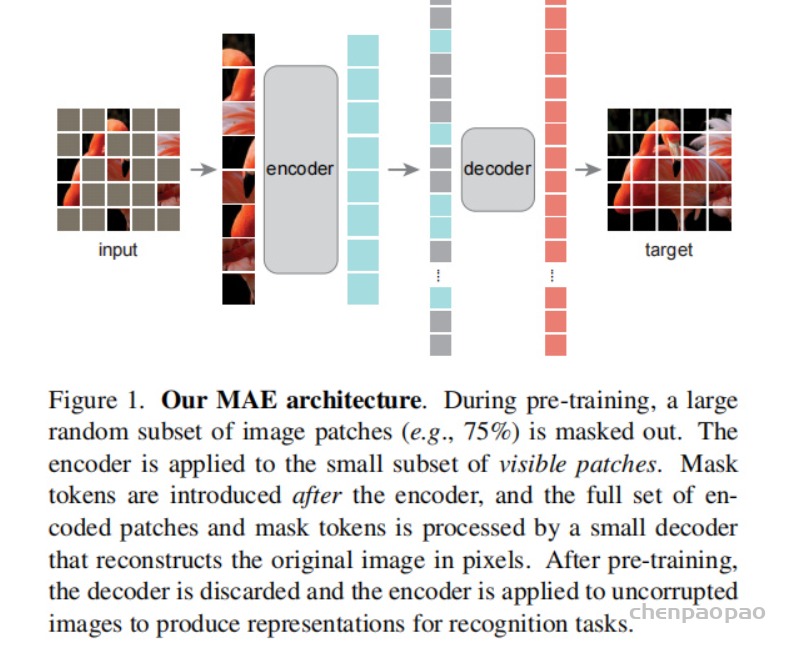
MAE Encoder MAE中的编码器是一种ViT,但仅作用于可见的未被Mask的块。类似于标准ViT,该编码器通过线性投影于位置嵌入对块进行编码,然后通过一系列Transformer模块进行处理。然而,由于该编解码仅在较小子集块(比如25%)进行处理,且未用到掩码Token信息。这就使得我们可以训练一个非常大的编码器 。
MAE Decoder MAE解码器的输入包含:(1) 编码器的输出;(2) 掩码token。正如Figure1所示,每个掩码Token共享的可学习向量,它用于指示待预测遗失块。此时,我们对所有token添加位置嵌入信息。解码器同样包含一系列Transformer模块。
Efficient Self-supervised Vision Pretraining with Local Masked Reconstruction,比MAE快3.1倍,比BEiT快5.3倍!KAUST&南洋理工提出基于局部mask重建的高效自监督视觉预训练方法LoMaR,同时提高训练精度和效率!
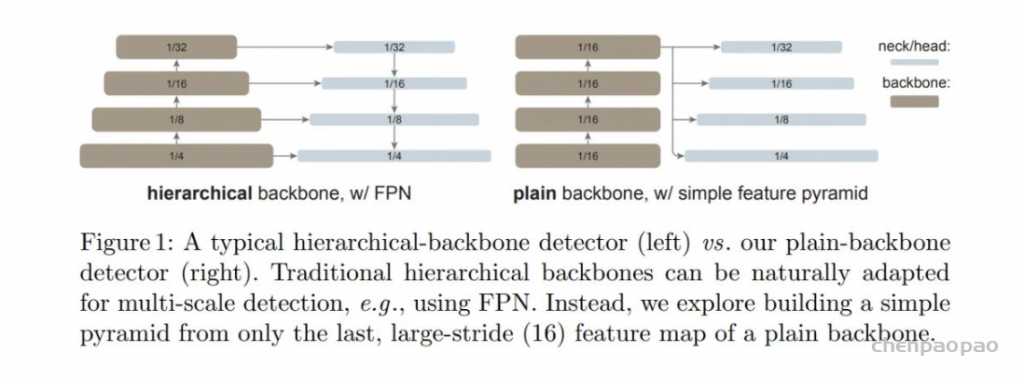
在过去的一年里,视觉 Transformer(ViT)已经成为视觉识别的强大支柱。与典型的 ConvNets 不同,最初的 ViT 是一种简单的、非层次化的架构,始终保持单一尺度的特征图。它的「极简」追求在应用于目标检测时遇到了挑战,例如,我们如何通过上游预训练的简单主干来处理下游任务中的多尺度对象?简单 ViT 用于高分辨率图像检测是否效率太低?放弃这种追求的一个解决方案是在主干中重新引入分层设计。这种解决方案,例如 Swin Transformer 和其他网络,可以继承基于 ConvNet 的检测器设计,并已取得成功。
在这项工作中,何恺明等研究者追求的是一个不同的方向:探索仅使用普通、非分层主干的目标检测器。如果这一方向取得成功,仅使用原始 ViT 主干进行目标检测将成为可能。在这一方向上,预训练设计将与微调需求解耦,上游与下游任务的独立性将保持,就像基于 ConvNet 的研究一样。这一方向也在一定程度上遵循了 ViT 的理念,即在追求通用特征的过程中减少归纳偏置。由于非局部自注意力计算可以学习平移等变特征,它们也可以从某种形式的监督或自我监督预训练中学习尺度等变特征。
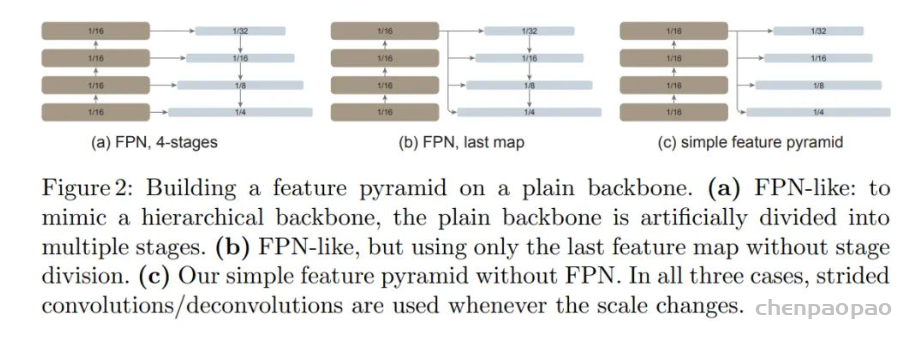
研究者表示,在这项研究中,他们的目标不是开发新的组件,而是通过最小的调整克服上述挑战。具体来说,他们的检测器仅从一个普通 ViT 主干的最后一个特征图构建一个简单的特征金字塔(如图 1 所示)。这一方案放弃了 FPN 设计和分层主干的要求。为了有效地从高分辨率图像中提取特征,他们的检测器使用简单的非重叠窗口注意力(没有 shifting)。他们使用少量的跨窗口块来传播信息,这些块可以是全局注意力或卷积。这些调整只在微调过程中进行,不会改变预训练。



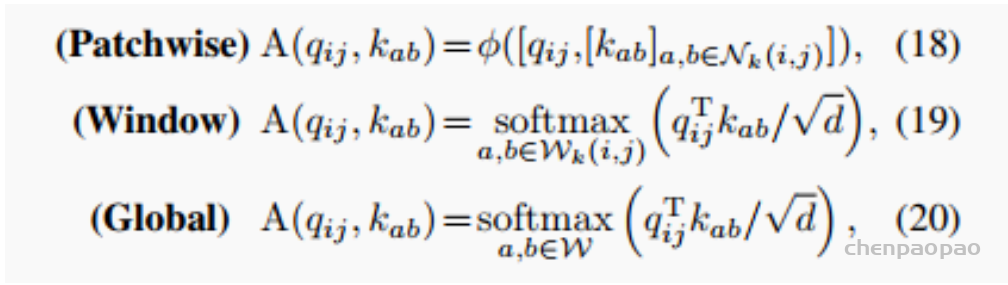
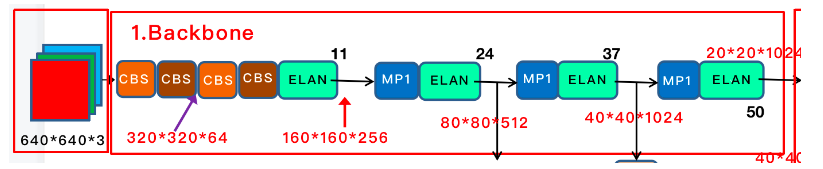
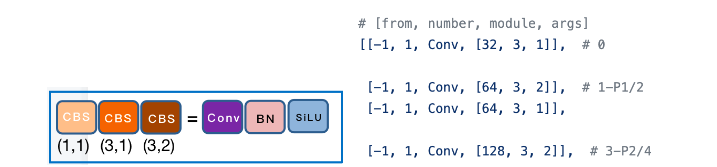
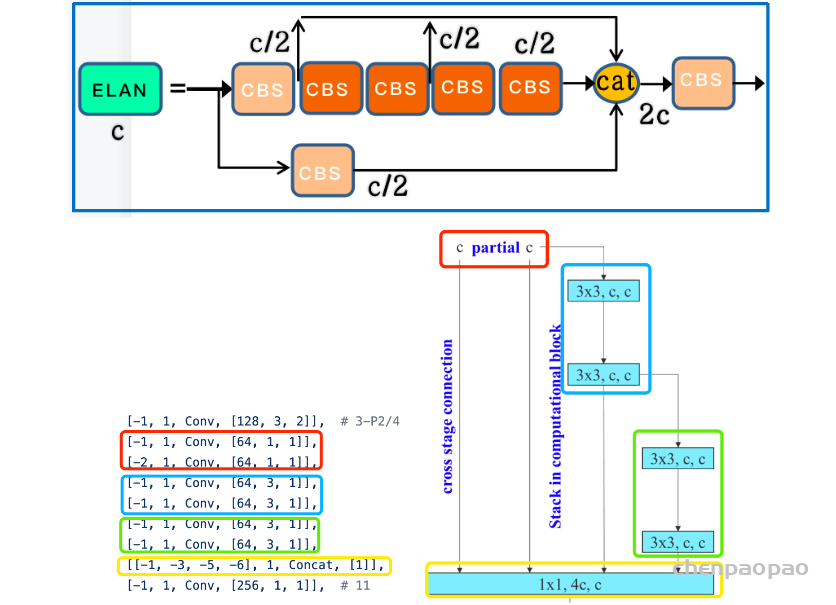
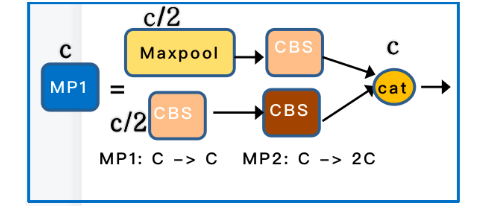

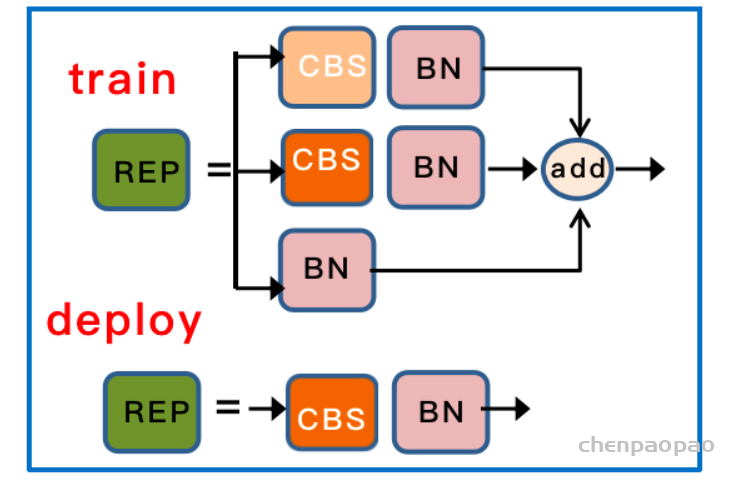
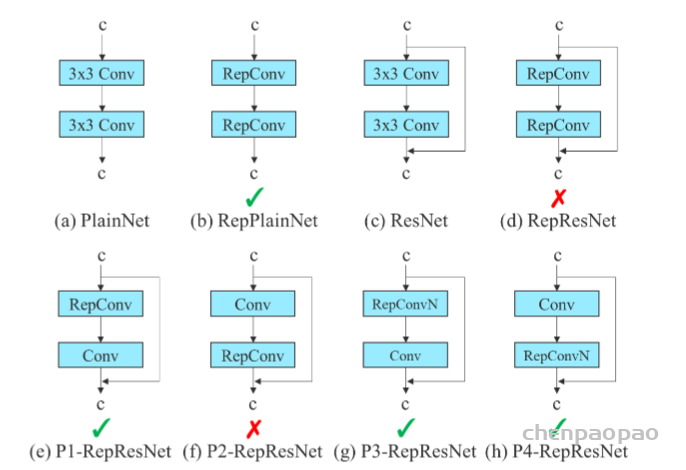




![图3 Rep算子的融合过程[4]](https://p0.meituan.net/travelcube/9f7878c7872787f9b8706b28e5e7c611237315.png)