传统的上下文偏置 ASR 解决方案中,主要存在两种范式。第一种依赖发音词典,例如基于加权有限状态转换器(WFST)的相关方法。这类系统利用预先定义的发音信息来提升特定术语的识别准确率。第二种范式是将偏置机制直接融入 ASR 模型结构中,通过与 ASR 模型进行联合训练来实现 ,典型代表包括 SeAco-Paraformer。
然而,这两类系统都不利于在支持 prompt 的 ASR 场景中处理偏置词。对于基于 WFST 的系统而言,获取少数语言或方言的发音词典往往十分困难;而端到端的上下文偏置方法通常需要修改 ASR 模型结构并进行联合训练,这在 prompt 支持的大模型范式下缺乏灵活性,难以快速更新和迭代。同时,大模型训练本身需要大量时间和计算资源,成本较高。
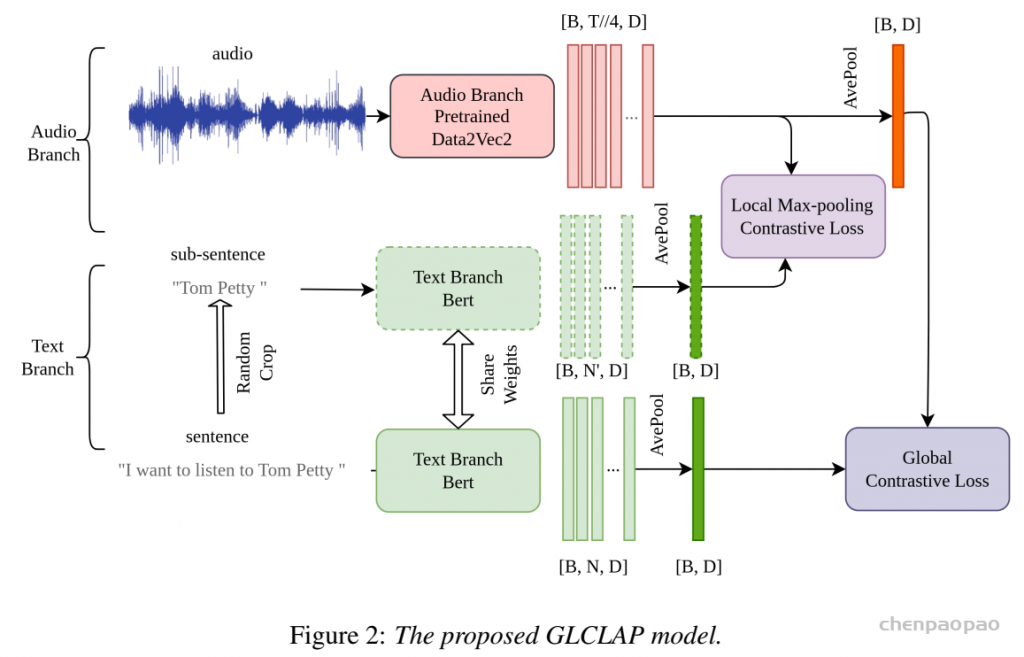
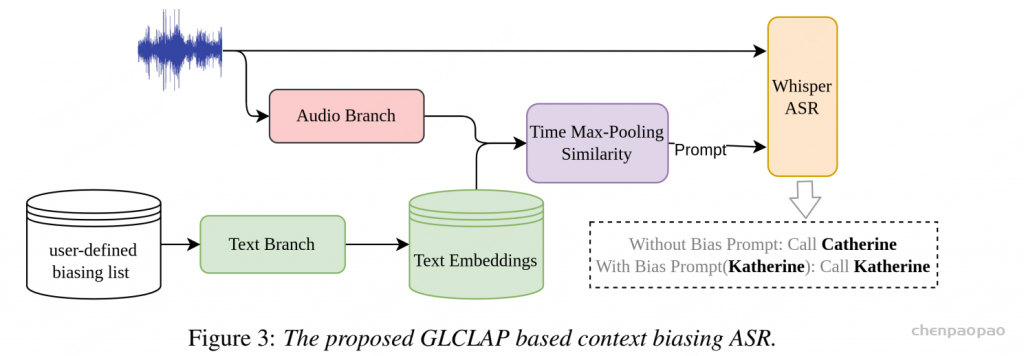
大语言模型(LLMs)中引入的提示机制与检索增强生成(Retrieval-Augmented Generation,RAG)为此提供了重要启示。RAG 通过优化提示来获得期望输出,而无需修改 LLM 的网络结构或进行微调。受这一范式的启发,偏置提示的生成可以作为一个独立模块,与识别过程进行解耦。这样,模型既不需要依赖发音词典,也不必在训练阶段依赖 ASR 模型本身。该方法与当前的大模型框架高度契合,能够利用 RAG 思路实现大规模的上下文偏置增强。
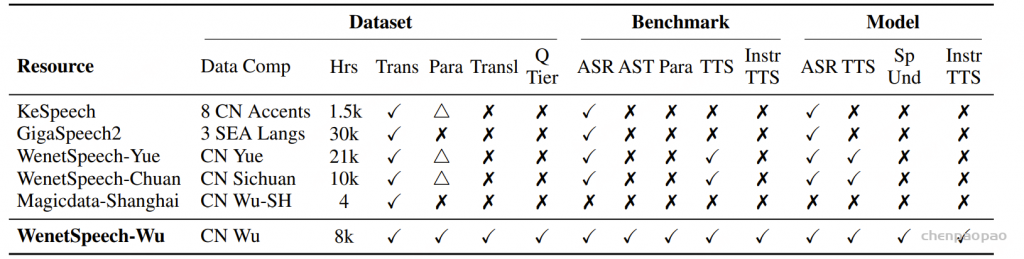
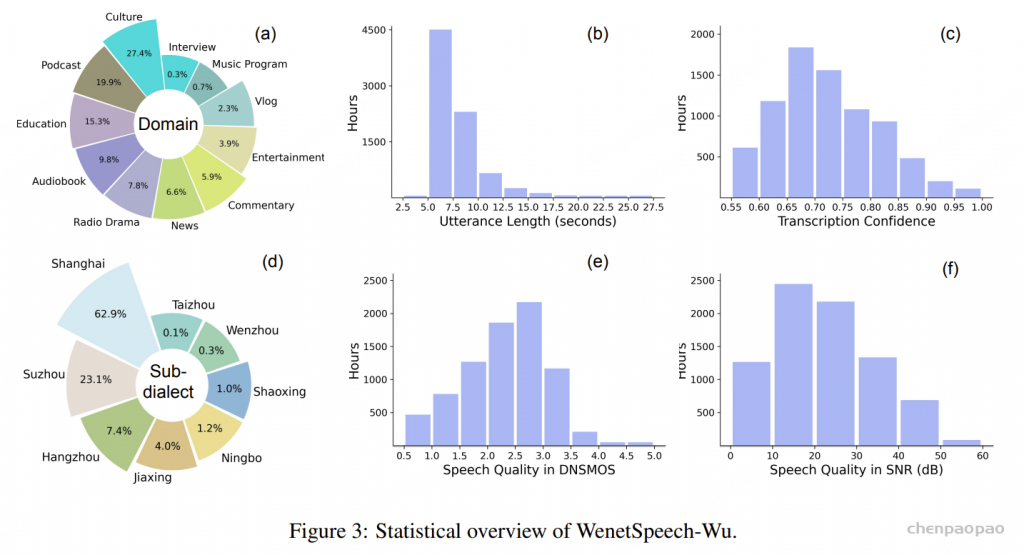
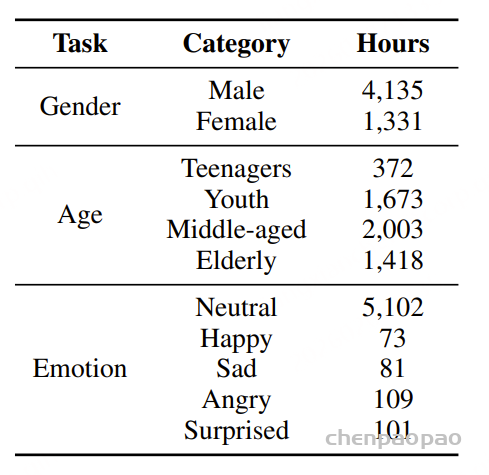
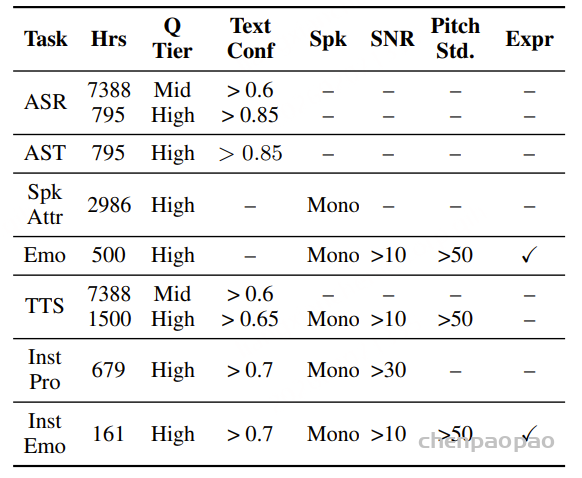
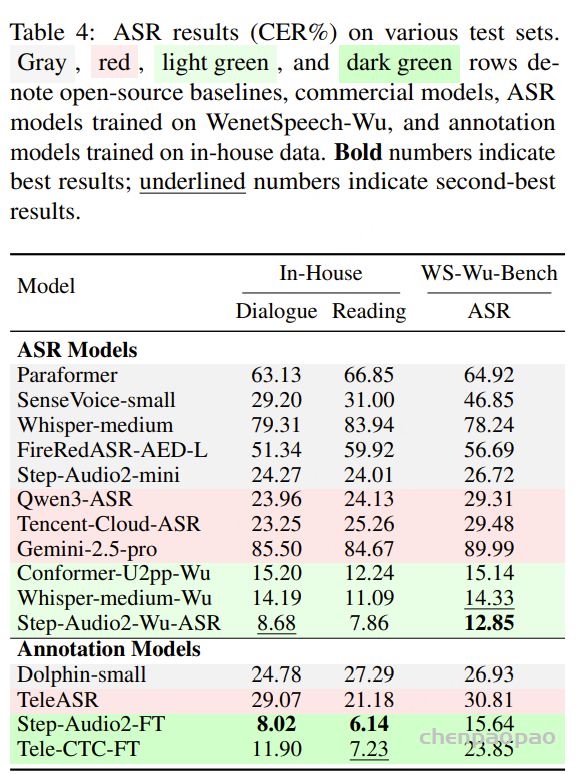
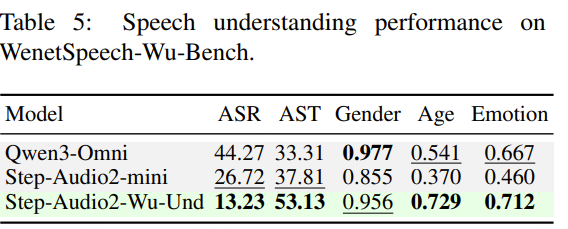
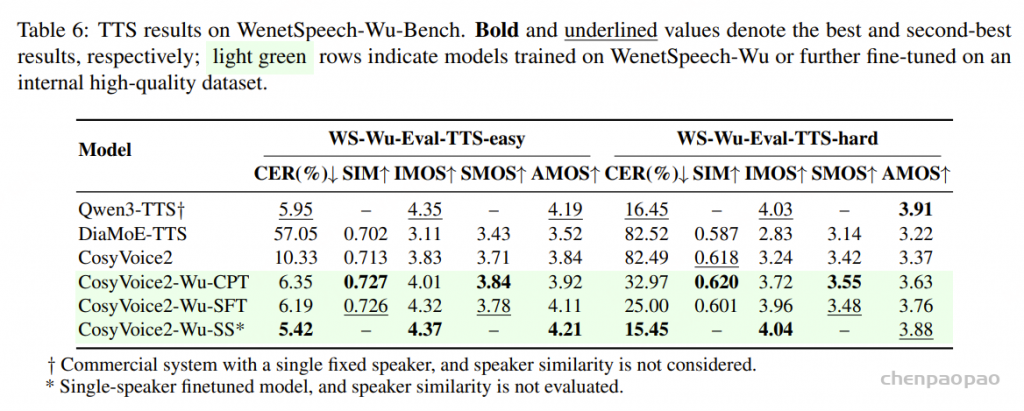
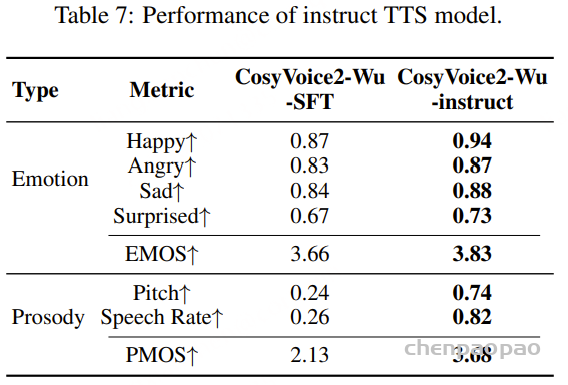
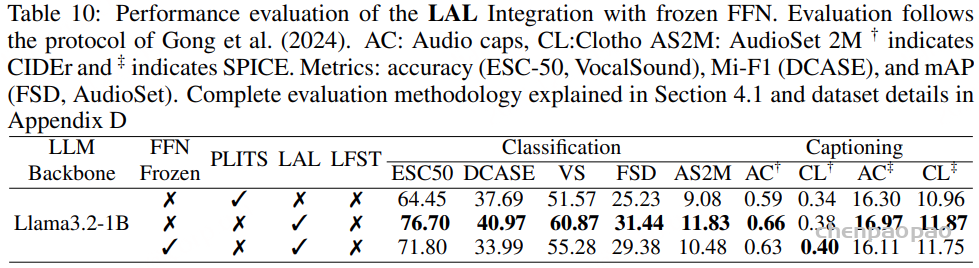
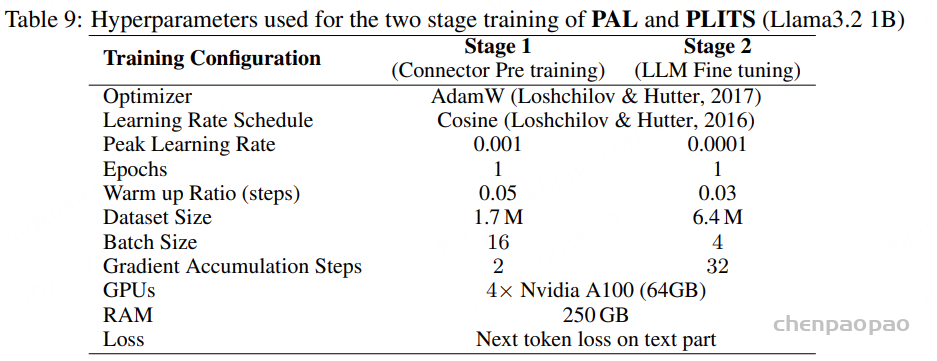
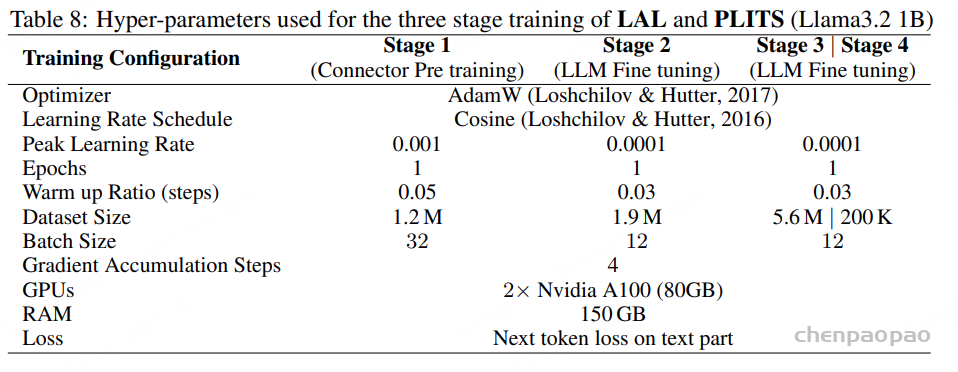
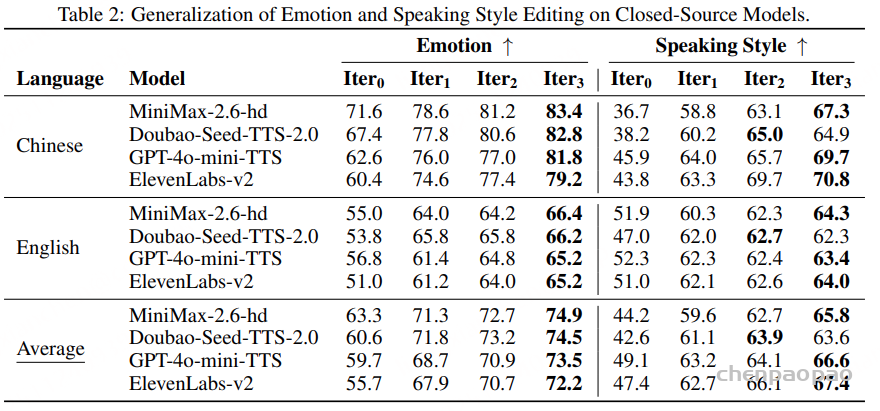
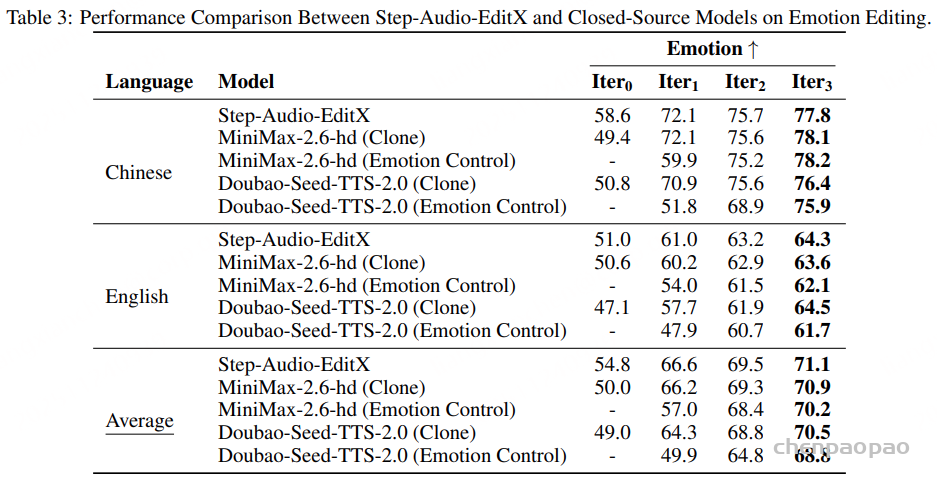
面向任务的数据质量分级:为支持多样化语音任务在实际训练中的不同需求,我们提出了一种与任务特定质量要求相匹配的数据质量分级策略。针对 ASR 和 TTS 任务,我们构建了两个质量等级的数据子集。其中,普通质量子集主要用于大规模预训练,更强调数据覆盖范围和多样性,仅要求中等水平的转写置信度;高质量子集则面向监督微调(SFT),采用更严格的筛选标准,包括更高的转写置信度、更干净的声学环境以及可靠的说话人分离,以提供更稳定、有效的监督信号。对于对标注噪声和语义歧义更为敏感的任务,例如吴语到普通话的自动语音翻译、说话人属性预测、语音情感识别、语音合成以及指令控制语音合成,我们采用了更为严格的数据筛选标准,包括单说话人录音、高 MOS 评分、较高信噪比、音高标准差约束,以及经过一致性验证的标注结果,具体标准如表3所示。
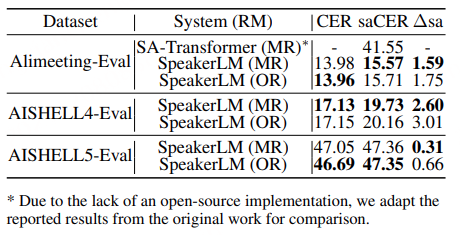
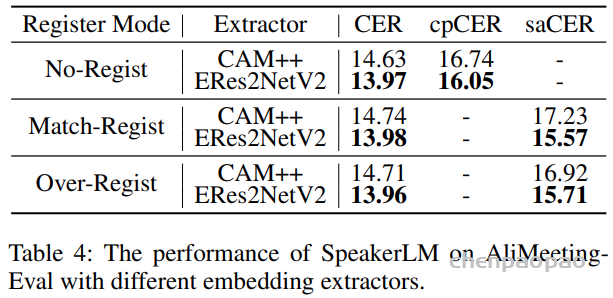
Match-Regist vs Over-Regist:两者的CER、cpCER差不多,但Over-Regist的∆sa更高(比如AliMeeting-Eval上,Match-Regist的∆sa=1.59%,Over-Regist=1.75%)——说明多余的注册信息会轻微影响说话人归属,但整体影响不大,模型能过滤冗余。
多余说话人数量对saCER的影响:
随着 Nov 的增加,并未观察到明显的性能退化。这反映出 SpeakerLM 对冗余说话人身份具有良好的鲁棒性,并且在推理过程中能够聚焦于与任务相关的说话人表征。
SD+ASR+LLM 的 LLM Prompt: You are a helpful assistant. In the speaker diarization transcript below, some words are potentially misplaced. Please correct those words and move them to the right speaker. Directly show the corrected transcript without explaining what changes were made or why you made those changes. (你是一名有帮助的助手。下面的说话人分离转录中,某些词语可能被错误地分配到说话人。请纠正这些词语并将其移动到正确的说话人处。直接展示修正后的转录,不要解释修改内容或理由。)
2. SpeakerLM-ASR : 在 SpeakerLM 的第一阶段训练中,我们使用纯 ASR 数据来增强模型的 ASR 性能。该模型被称为 SpeakerLM-ASR。使用的 LLM prompt 如下:
SpeakerLM-ASR 的 LLM Prompt: You are a helpful assistant. Transcribe the speech. <start>path to the input speech<end> (你是一名有帮助的助手。请进行语音转写。<start>输入语音的路径<end>)
You are a helpful assistant. Transcribe by roles. <start>path to the multi-speaker speech<end> (你是一名有帮助的助手。请按角色进行转写。<start>多说话人语音的路径<end>)
Match-Regist(匹配注册)
You are a helpful assistant. Registered Speaker Embeddings: Mike<start>path to the embedding of Mike<end>; Lucy<start>path to the embedding of Lucy<end>; Jack<start>path to the embedding of Jack<end>; Transcribe by roles. <start>path to the multi-speaker speech<end> (你是一名有帮助的助手。已注册的说话人嵌入如下: MikeMike 的嵌入路径; LucyLucy 的嵌入路径; JackJack 的嵌入路径; 请按角色进行转写。多说话人语音的路径 (说话人顺序没有特定要求。))
Over-Regist(过度注册)
You are a helpful assistant. Registered Speaker Embeddings: Mike<start>path to the embedding of Mike<end>; Lucy<start>path to the embedding of Lucy<end>; Jack<start>path to the embedding of Jack<end>; Andy<start>path to the embedding of Andy<end>; Rose<start>path to the embedding of Rose<end>; Frank<start>path to the embedding of Frank<end>; Transcribe by roles. <start>path to the multi-speaker speech<end> (注:在此情况下,Andy、Rose 和 Frank 是来自其他会话的过度注册说话人。说话人顺序没有特定要求。)
(1) 在转录文本生成过程中同时纠正错误;一般需要训练额外的模块,使 ASR 模型具备上下文偏置能力,或者利用上下文信息来纠正 ASR 模型中的命名实体错误。 这些方法需要对ASR系统进行修改,使其具备纠错能力,因此这些方法很难应用于第三方 ASR 系统。
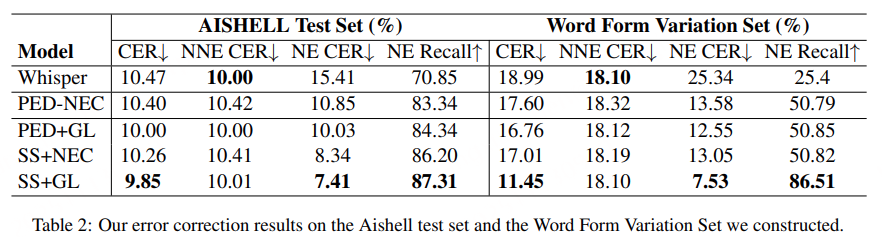
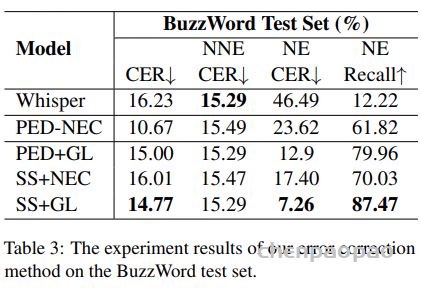
(2) 在转录文本生成后纠正错误,即后编辑错误。不需要对 ASR 系统进行任何修改,因此后编辑 NEC 方法更具适用性。其中最常见的是PED-NEC(基于语音编辑距离的方法),当 ASR 转录文本中实体和相关错误文本的词形相似时,我们可以通过遍历实体数据存储轻松定位错误,但PED-NEC有个大毛病——如果错的文本和真实实体“长得太不一样”,就彻底歇菜。比如:
“大语言模型”被ASR转成“大原模型”,俩词字面差挺多;
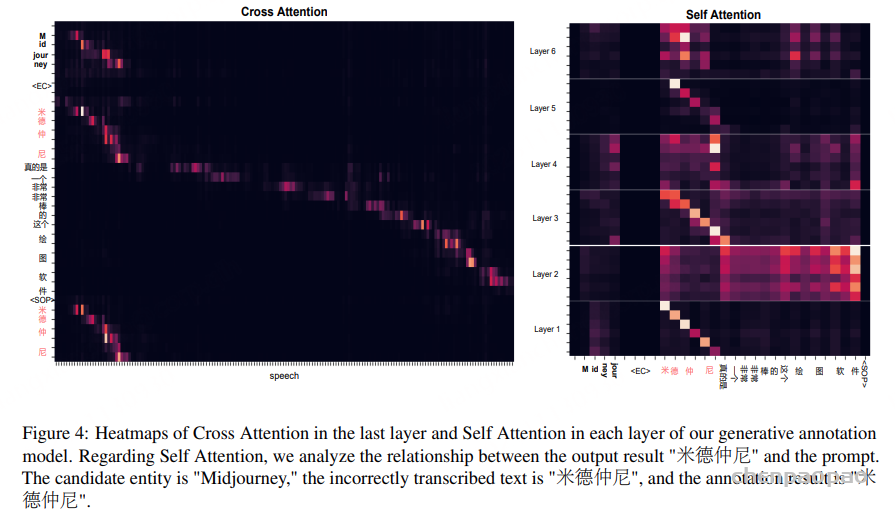
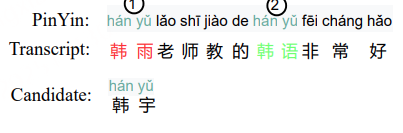
“Midjourney”转成“米德仲尼”(英文变中文音译);
“灵耀X”转成“01X”(汉字变数字);
“ChatGPT”转成“Check GPT”(拼写差一截)。
这时候PED-NEC没法定位错词,自然就纠正不了,这就是论文要解决的核心问题。
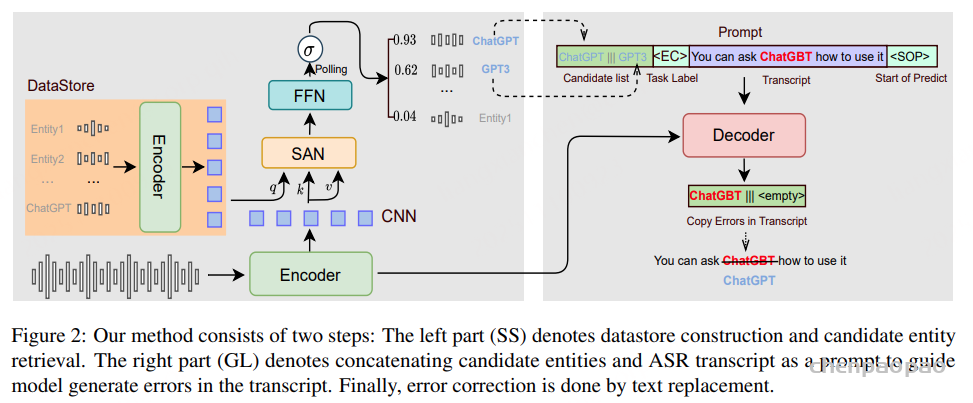
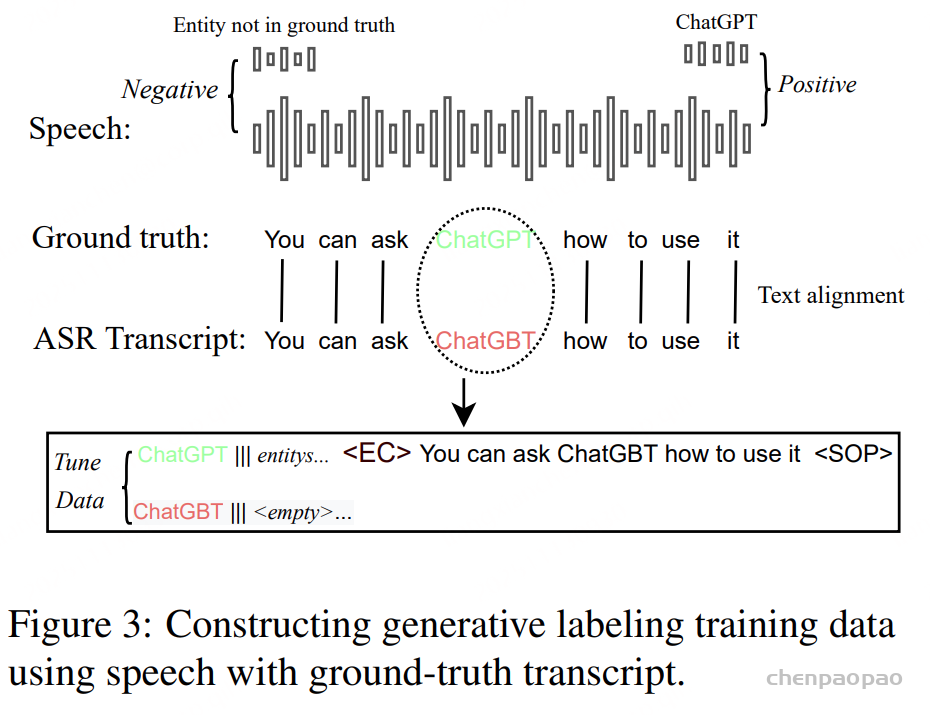
为了解决上述问题,创新性地提出了一种基于生成式方法的 NEC(命名实体校正) 方法,用于在转录文本中自动标注待纠正片段。具体来说,利用语音声学特征、候选命名实体以及 ASR 转录结果,生成(标注)出转录文本中需要被纠正的词语,并据此进行修正。该基于错误标注的 NEC 方法能够在识别出待纠正文本后,实现端到端的文本纠错,无需考虑词形变化,因此相比以往基于规则的替换方法具有更高的优越性。
将 TTS 生成的音频输入到编码器,并将编码器最后一层的输出作为实体 xi 的语音表示。为了提高检索准确率并降低内存占用,我们在编码器的末尾添加了一个CNN层
数据存储存储键值(表示实体)对:
Entity Retrieval:用户的输入音频片段 s 输入到编码器中,并从编码器最后一层的输出中得到它的表示 s’:
引入自注意力网络(SAN)和前馈网络(FFN)来计算数据存储区 s 包含候选实体 xi′ 的概率 pi :
最后应用平均池化,获取最终的分类:
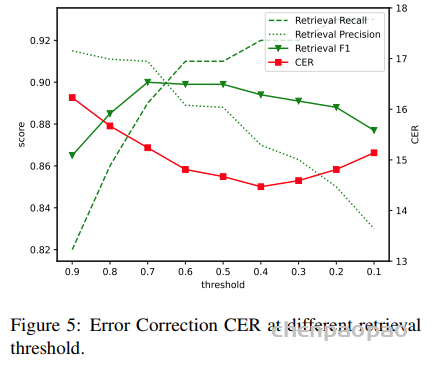
判断数据存储中是否存在语音片段中的实体。如果概率 pi 高于我们设定的阈值,则选择前 K 个候选实体进行进一步校正。
Error Correction:通过上述实体检索方法获得若干候选实体,用符号“|||”连接实体,然后用引号将实体字符串与 ASR 转录文本连接起来。实体+转录文本字符串用作提示,引导纠错模型在转录文本中生成与候选实体具有相似语音特征的错误实体。该过程实际上是一种生成式标注方法,因为纠错模型会在原始 ASR 转录文本中输出一个或多个单词。

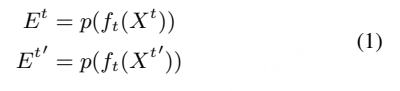

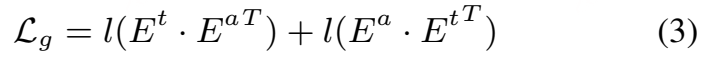
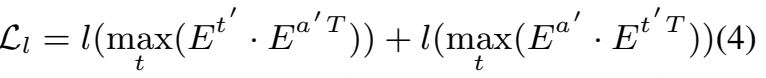





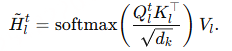
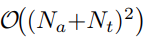
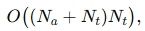




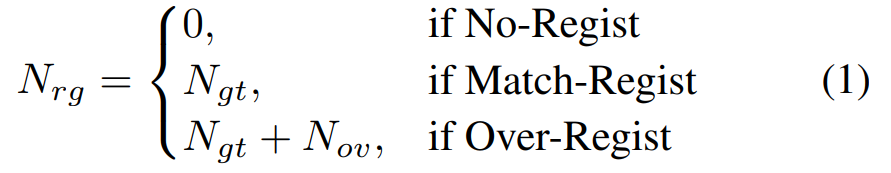









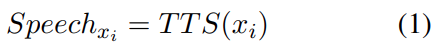
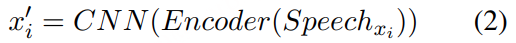
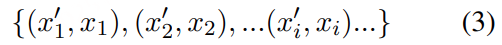
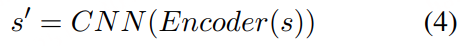
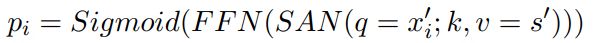


{kind=link}