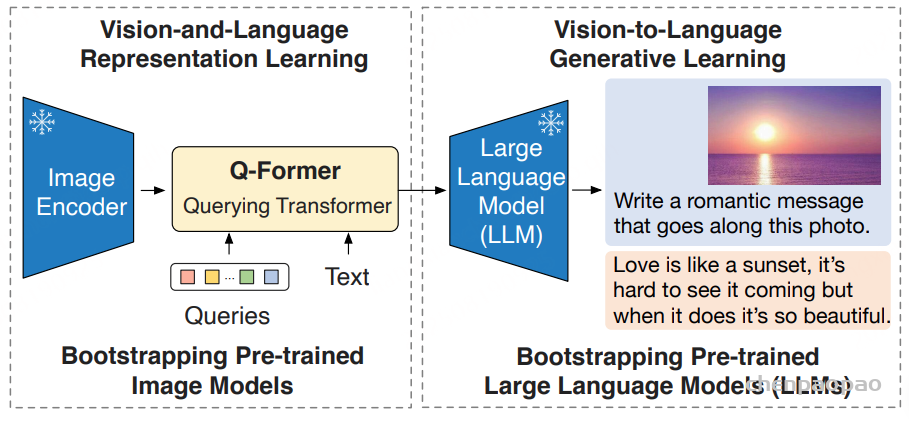
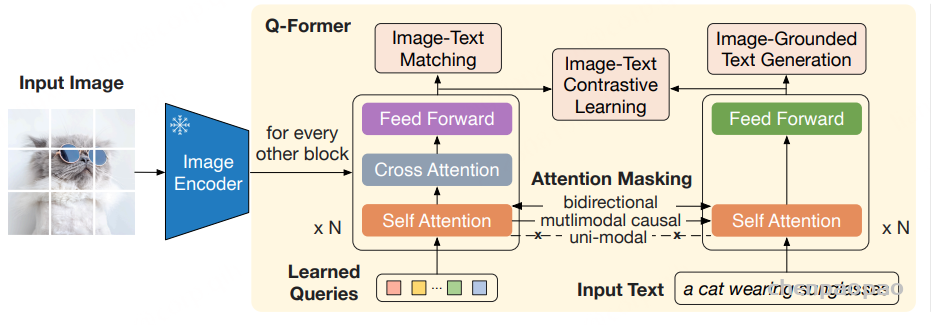
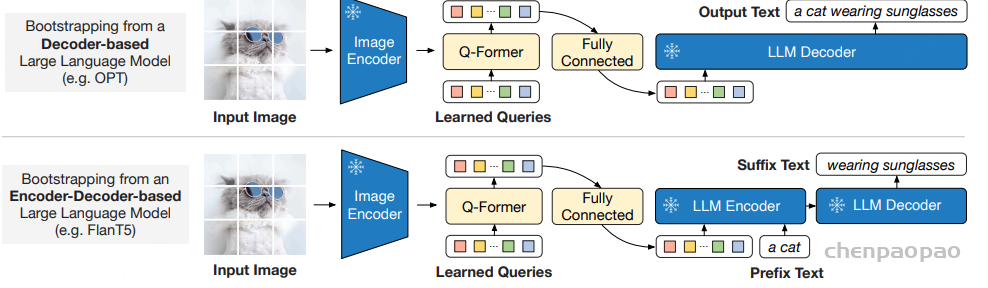
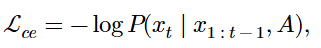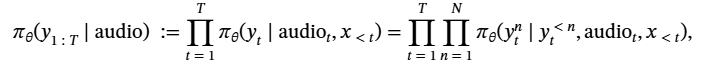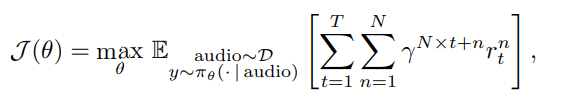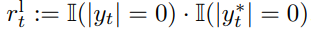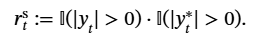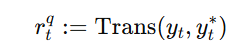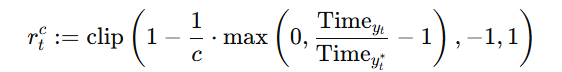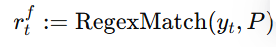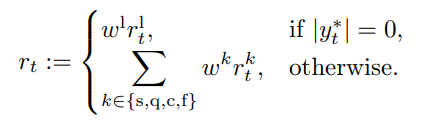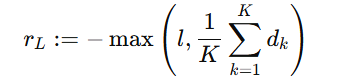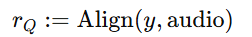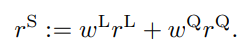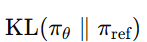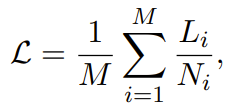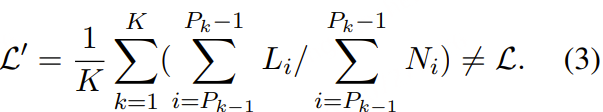论文题目:WenetSpeech-Yue: A Large-scale Cantonese Speech Corpus with Multi-dimensional Annotation
- 论文预印版:https://arxiv.org/abs/2509.03959
- 仓库地址:https://github.com/ASLP-lab/WenetSpeech-Yue
- Demo展示:https://aslp-lab.github.io/WenetSpeech-Yue/
- WenetSpeech-Yue数据集地址:https://huggingface.co/datasets/ASLP-lab/WenetSpeech-Yue
- WSYue-ASR-eval: https://huggingface.co/datasets/ASLP-lab/WSYue-ASR-eval
- WSYue-TTS-eval: https://huggingface.co/datasets/ASLP-lab/WSYue-TTS-eval
- ASR模型地址:https://huggingface.co/ASLP-lab/WSYue-ASR
- TTS模型地址:https://huggingface.co/ASLP-lab/WSYue-TTS
背景动机
语音理解与生成的飞速发展离不开大规模高质量语音数据集的推动。其中,语音识别(ASR)和语音合成(TTS)被公认为最首要的任务。但对于拥有约 8490 万母语使用者的粤语而言,受限于标注资源匮乏,研究进展缓慢,ASR 与 TTS 的表现始终不尽如人意。现有公开的粤语语料库在规模、风格和标注维度上普遍存在不足。例如 Common Voice 和 MDCC 等项目过度依赖人工标注,仅能提供小规模数据;评测集大多局限于短句,缺乏对复杂语言现象的覆盖。同时,这些语料往往只提供语音-文本对齐信息,缺乏说话人属性或声学质量等元数据,极大限制了其在自监督学习、风格建模和多任务训练中的应用,导致主流 ASR 与 TTS 系统在粤语任务上表现欠佳,并在真实场景中泛化能力不足。
为解决上述问题,西北工业大学音频语音与语言处理研究组(ASLP@NPU)联合中国电信人工智能研究院、希尔贝壳、香港科技大学和Wenet开源社区,提出了 WenetSpeech-Pipe ——一个面向语音理解与生成、支持多维度标注的大规模语音语料构建一体化流程。该流程包含六个模块:音频采集、说话人属性标注、语音质量标注、自动语音识别、文本后处理与识别结果投票,能够生成丰富且高质量的标注。基于该流程,构建并发布了 WenetSpeech-Yue ——首个大规模粤语多维标注语音语料库,涵盖 21800 小时、10 大领域的粤语语音数据,并包含 ASR 转录、文本置信度、说话人身份、年龄、性别、语音质量评分等多种标注信息。同时,我们还发布了 WSYue-eval,这是一个全面的粤语评测基准,包含两个部分:WSYue-ASR-eval(人工标注集,用于评测短句/长句、粤英转换及多样声学条件下的 ASR 性能),以及 WSYue-TTS-eval(基础与覆盖子集,用于标准测试与泛化能力测试)。实验结果表明,基于 WenetSpeech-Yue 训练的模型在粤语 ASR 与 TTS 任务中表现优异,性能超越最先进(SOTA)的系统,并与商业系统相媲美,凸显了该数据集与流程的重要价值。
WenetSpeech-Pipe
WenetSpeech-Pipe 框架如图 所示,由六个模块组成:(A) 音频采集,(B) 说话人属性标注,(C) 语音质量标注,(D) 自动语音识别,(E) 文本后处理,以及 (F) 识别结果投票。
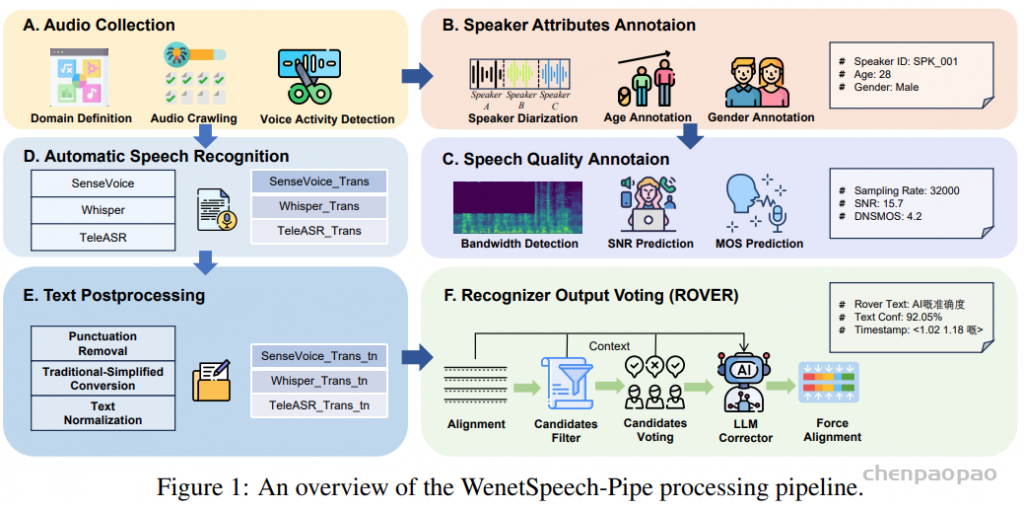
音频采集: WenetSpeech-Pipe 首先从多个领域(如故事、影视、评论、Vlog、美食、娱乐、新闻和教育)大规模采集真实语音数据。由于原始录音多为几十分钟至数小时的长音频,不适合直接用于模型训练或对齐,因此系统通过语音活动检测(VAD)自动切分为短音频片段,从而生成可用于转写和质量评估的语句级数据,为后续处理奠定基础。
说话人属性标注:为了丰富数据集,使其具备多说话人建模和风格感知合成所需的说话人级别元数据,WenetSpeech-Pipe 引入了 说话人属性标注阶段。首先,利用 pyannote 工具包 进行说话人分离,为同一录音中的短片段分配局部说话人标签,实现录音内的说话人区分。
其次,利用 Vox-Profile对每个片段的说话人进行年龄和性别估计,从而生成说话人属性注释。该流程最终得到带有说话人身份、年龄和性别信息的语句级片段,形成多维度的元数据,有助于监督建模和可控风格的语音建模
语音质量标注:WenetSpeech-Pipe 在语音质量评估阶段结合三种方法:Brouhaha 计算信噪比、DNSMOS 预测主观质量分、带宽检测分析频谱特性,从而为每个片段生成包含 SNR、MOS 与频谱参考的结构化质量标注,支撑高保真语音建模。
ps:关于 Brouhaha: multi-task training for voice activity detection, speech-to-noise ratio, and C50 room acoustics estimation: 代码:https://github.com/marianne-m/brouhaha-vad 给定一个音频片段,Brouhaha 可以提取:语音/非语音片段,语音噪声比 (SNR),C50,测量环境混响程度。 DNSMOS:基于多阶段自我学习(multi-stage self-teaching) 的无参考感知客观指标:DNSMOS,用来评估噪声抑制模型的语音质量。基于 CNN;输入为语音频谱;训练以人类主观评分为目标,采用自我学习提升性能.
自动语音识别:单一 ASR 系统通常会因架构限制、训练数据不足或领域不匹配而表现出系统性偏差和错误模式。为了缓解这些问题并提升转写可靠性,WenetSpeech-Pipe 采用 多系统集成识别 方法,结合不同的识别范式。具体来说,每个音频片段会被 独立输入到三个高性能粤语 ASR 系统:开源模型 SenseVoice、Whisper,以及商用系统 TeleASR。这些系统在架构、训练数据和优化目标上各不相同,因此能够形成互补的错误分布和多样的语言假设。最终输出为每条语句的三份并行转写,作为后续融合与优化的基础输入。
文本后处理:WenetSpeech-Pipe 通过文本后处理统一多系统转写结果:使用 OpenCC 繁转简,去除符号与标签,规范数字和日期格式,并在中英文间加空格。这样生成的规范化转写确保 ROVER 融合时不会受表层差异干扰。
- 使用 OpenCC 将繁体字统一转换为简体字;
- 去除所有标点和特殊符号;
- 基于规则重写统一数字与日期表达;
- 在粤语与英语单词之间插入空格,便于双语建模。
经过上述步骤,系统获得了跨三套 ASR 的标准化转写,作为 ROVER 模块的鲁棒输入,避免表层差异干扰语音与词汇层面对齐。

为了确保不同 ASR 系统之间的转写格式一致,我们提出了一个集成的文本后处理框架,包含四个关键操作:
- 标点去除:通过正则表达式匹配,删除符号类字符;
- 繁转简:利用 OpenCC 库实现繁体到简体的转换;
- 文本规范化:使用 an2cn 工具进行数字的标准化转换;
- 合理分词:借助 Pangu 工具实现恰当的词间空格。
这四个步骤共同作用,能够在不同 ASR 系统输出存在差异的情况下,保证生成标准化的文本格式。
识别结果投票:虽然文本后处理统一了转写表层形式,但在词汇选择、分词和音素表示上仍存在差异。为了得到统一且高精度的参考转写,WenetSpeech-Pipe 采用了 ROVER (Recognizer Output Voting Error Reduction) 框架 ,通过多系统投票提升转写精度。
在实现上,标准 ROVER 流水线被扩展以更好地适应粤语:
- 使用动态规划对三套系统的转写结果进行对齐;
- 引入候选过滤模块,计算某系统输出与其余两套平均转写的编辑距离,若超过阈值则剔除该系统结果;
- 在每个对齐位置,选择最常出现的词,并将整体投票频率作为语句级置信度;
- 并行引入 基于拼音的投票,结合字符级投票,保证音素一致性。
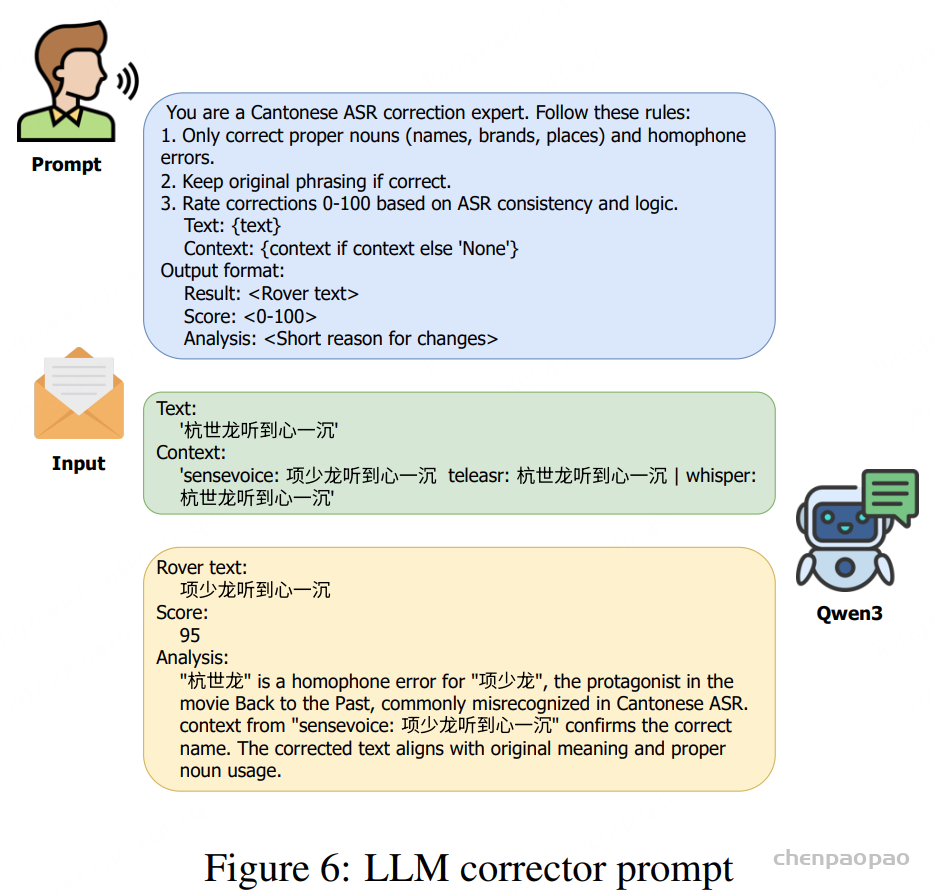
为进一步提高转写准确率,系统引入 大语言模型 Qwen3-4B,在共识输出的基础上进行最小化的上下文感知修正,仅在语法、用词或命名实体方面做必要调整,保持口语内容的完整性。
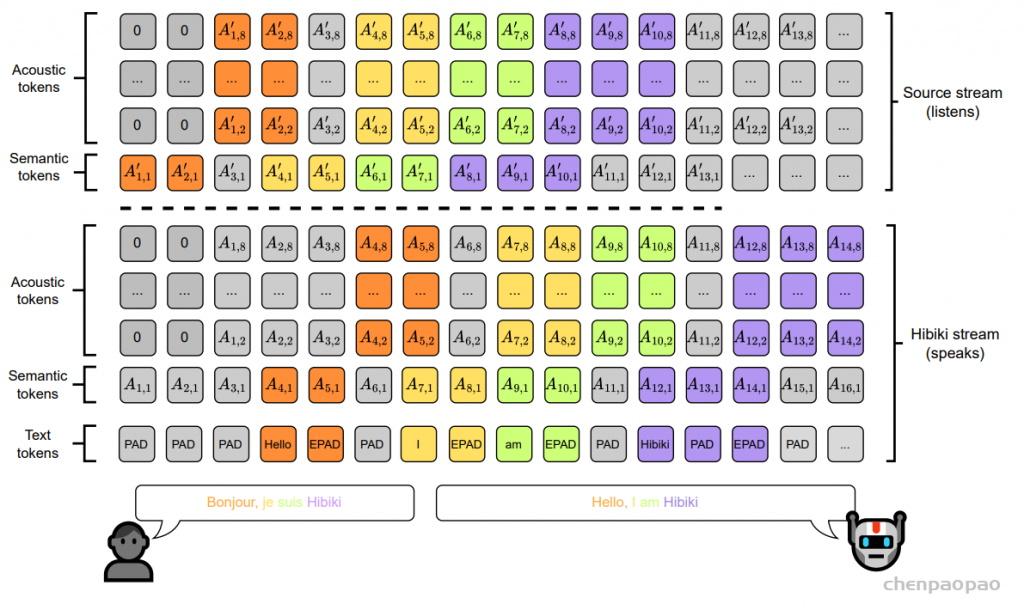
字级别时间戳对齐:最后,使用预训练声学模型在字符级别上强制对齐修正后的转写与原始音频,从而获得精确的逐字符时间戳,支持更精细的语音处理和下游任务。
Meta Data Example:
将所有音频的元数据以标准化的 JSON 格式进行存储。核心字段包括:
- utt_id(每个音频片段的唯一标识符)、
- rover_result(来自三个 ASR 转写结果的 ROVER 融合结果)、
- confidence(文本转写的置信度分数)、
- jyutping_confidence(粤语拼音转写的置信度分数)、
- duration(音频时长)。
说话人属性(Speaker attributes)包含参数:speaker_id、性别(gender)和年龄(age)。音频质量评估指标包括专业测量项:采样率(sample_rate)、DNSMOS 和 SNR。时间戳信息(timestamp)精确记录了起始时间(start)和结束时间(end)。此外,在 meta_info 字段下还扩展了更多元数据,包括:program(节目名称)、region(地理信息)、link(原始内容链接)、以及 domain(领域分类)。

WenetSpeech-Yue
数据集分布
元数据:所有元数据存储在单一 JSON 文件中,字段包括音频路径、时长、文本置信度、说话人身份、信噪比(SNR)、DNSMOS 分数、年龄、性别以及字符级时间戳。这些字段具有可扩展性,未来可进一步加入新的标签。
领域分布:WenetSpeech-Yue 的语料来源大致涵盖十个领域:故事、娱乐、戏剧、文化、Vlog、评论、教育、播客、新闻及其他,具体分布如图2所示。
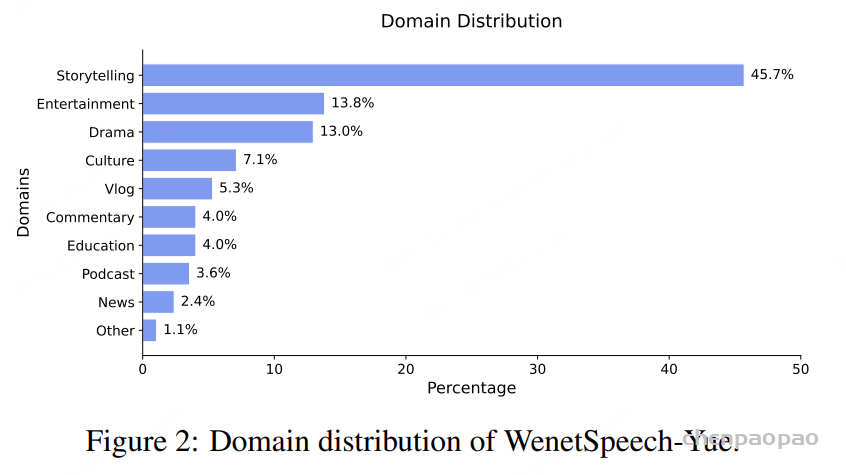
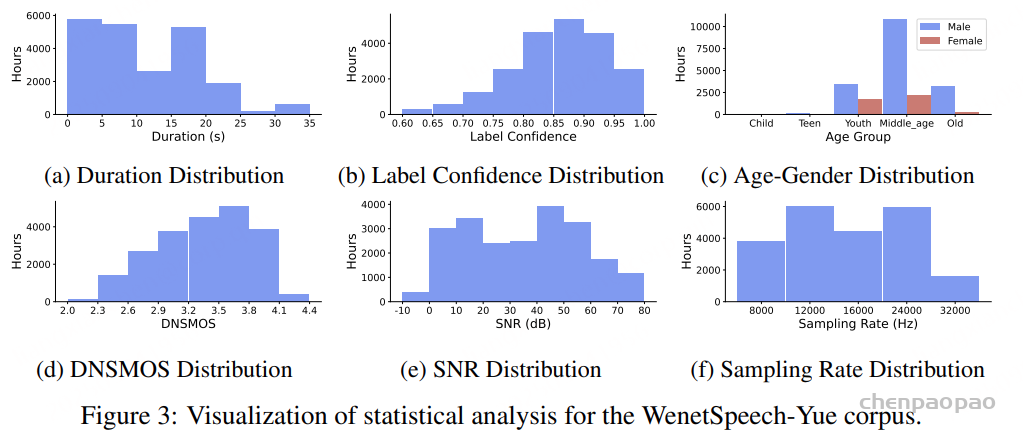
时长分布:整个语料库共包含 21,800 小时音频,既包括长录音也包括短片段,切分后平均时长为 11.40 秒。
置信度:我们仅保留文本置信度高于 0.6 的标注,并根据confidence区间划分为三类:强标注(confidence> 0.9,6,771.43 小时)、中等标注(0.8 ~ 0.9,10,615.02 小时)和弱标注(0.6 ~ 0.8,4,488.13 小时)。
语音质量:我们评估了语料的音质:DNSMOS 分数范围为 2.0–4.4,SNR 范围为 -5–80 dB,采样率分布为 8,000–32,000 Hz。为确保生成式任务的可用性,我们过滤后仅保留 DNSMOS > 2.5 且 SNR > 25 dB 的样本,共得到约 12,000 小时高质量语音,可用于 TTS、声码器或语音转换等任务。
说话人属性:语料库在性别与年龄上分布不均,以男性为主,尤其集中在中年群体(50.6%),而女性在各年龄段中比例相对较低。
WSYue-eval
为应对粤语的语言特性,我们提出 WSYue-eval,一个同时涵盖 ASR 与 TTS 的综合评测基准,用于全面检验模型在粤语处理上的表现。
ASR 评测集(WSYue-ASR-eval):该测试集经过多轮人工标注,包含转写、情感、年龄、性别等信息,并划分为 短语音(0–10 秒,9.46 小时,2861 位说话人)和 长语音(10–30 秒,1.97 小时,838 位说话人)两个子集,覆盖粤英转换及多领域场景。
TTS 评测集(WSYue-TTS-eval):该基准专为零样本粤语 TTS 设计,包含两个子集:
- Base:1000 条来自 CommonVoice 的提示-文本对,用于测试日常场景;
- Coverage:由于 CommonVoice 主要包含日常对话数据,其对不同领域和语言现象的覆盖范围有限。为了解决这个问题, Coverage 子集由人工与 LLM 生成文本组成,覆盖日常、新闻、娱乐、诗歌等多领域,并包含多音字、变调、语码转换、专名、数字等复杂语言现象。
模型训练策略:
模型均采用两阶段训练策略:初始阶段使用混合的中高置信度标签实现快速收敛,之后在高置信度标签上进行微调,以最大限度地提高转录准确率。这种设置既降低了训练成本,又直接反映了数据集的质量影响。

阶段 1 在混合置信度数据集上训练,已经能够取得非常具有竞争力的粤语 ASR 性能,而阶段 2 在高置信度数据上进行微调,则在 WSYue-ASR-eval 的两个测试集上都带来了显著提升。这些观察结果验证了高置信度标签是性能提升的主要驱动力。我们认为保留置信度信息至关重要,因为它能够支持灵活的训练策略:高置信度子集可用于主导微调,而低置信度片段经过谨慎利用,则可以在半监督或领域自适应场景下提高模型的鲁棒性。
模型效果:
ASR任务:
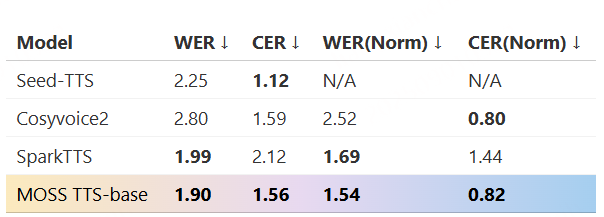
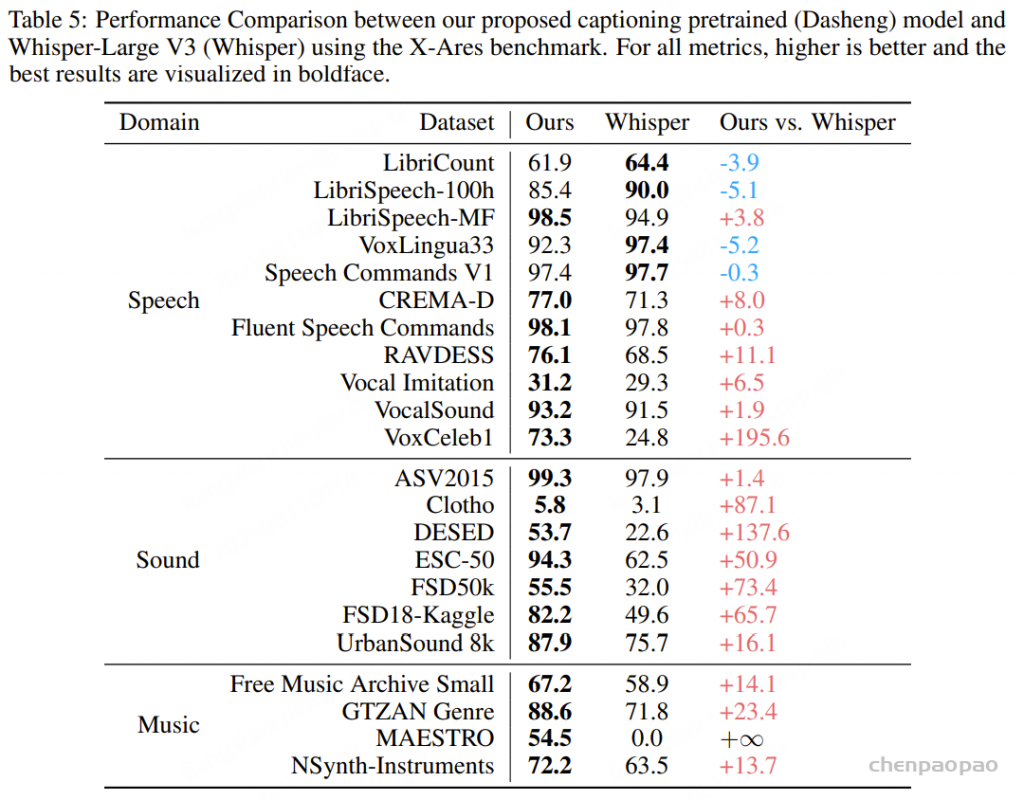
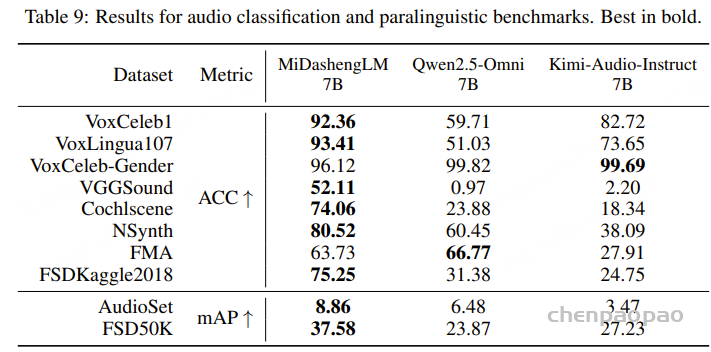
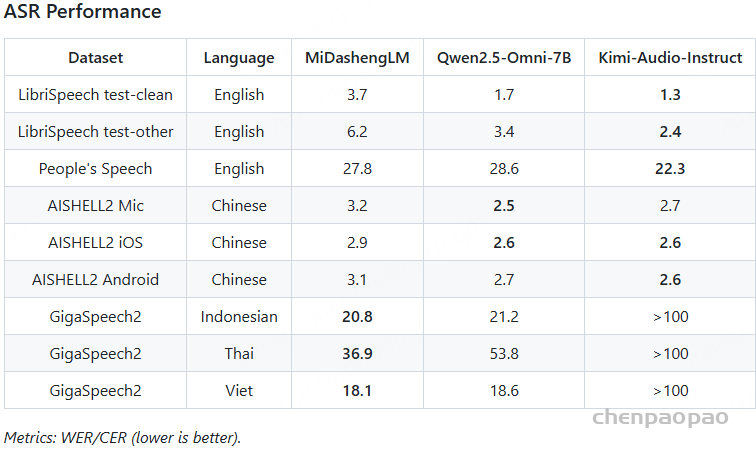
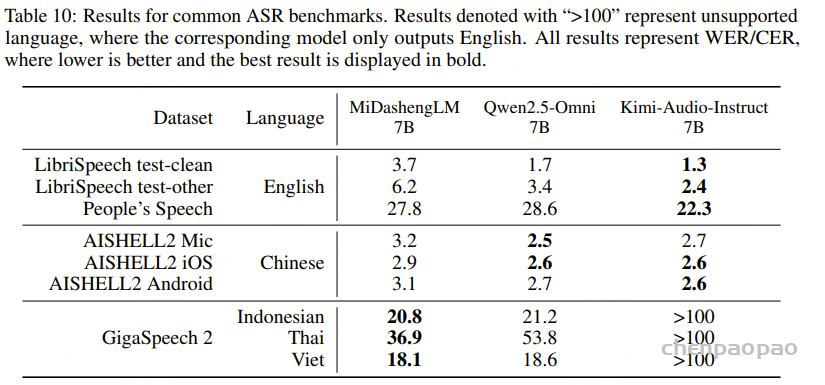
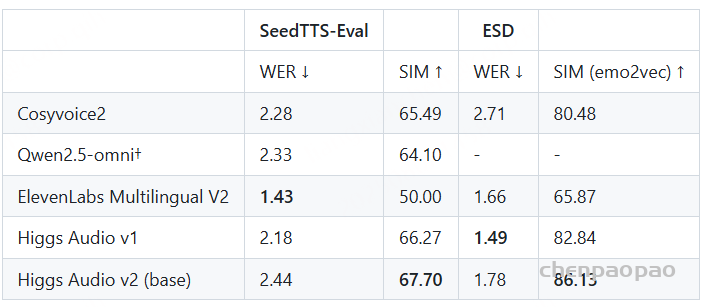
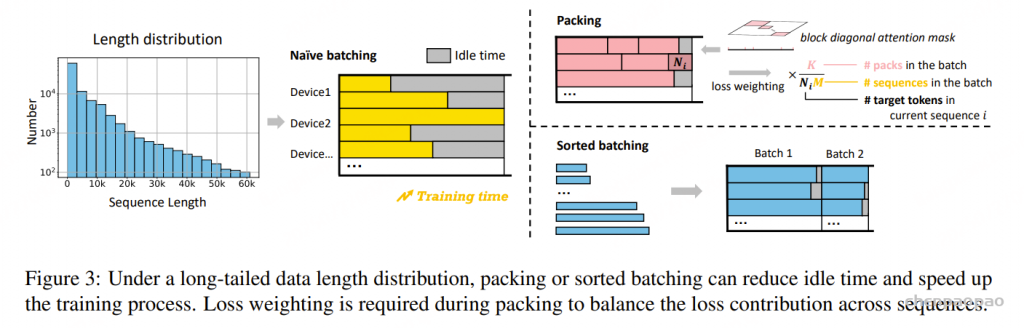
采用混合错误率(MER)作为评测指标,其中中文按字级、英文按词级计算错误,用于比较基于 WenetSpeech-Yue 训练的模型与各类基线模型的表现。表1的实验结果显示:
- 在所有模型规模(small、medium、w/ LLM)下,我们的模型在大多数评测集上表现最佳;
- 在小规模模型中,SenseVoice-small-Yue 和 U2pp-Conformer-Yue 均表现优异,其中 SenseVoice-small-Yue 尽管规模较小,却超过了所有基线模型,说明该语料库能显著提升低容量模型的效率;
- 在不带 LLM 的组别中,U2pp-Conformer-Yue、Whisper-medium-Yue 和 SenseVoice-small-Yue 均优于大规模基线模型;
- 在带 LLM 的组别中,U2pp-Conformer-LLM-Yue 始终达到当前最先进水平。
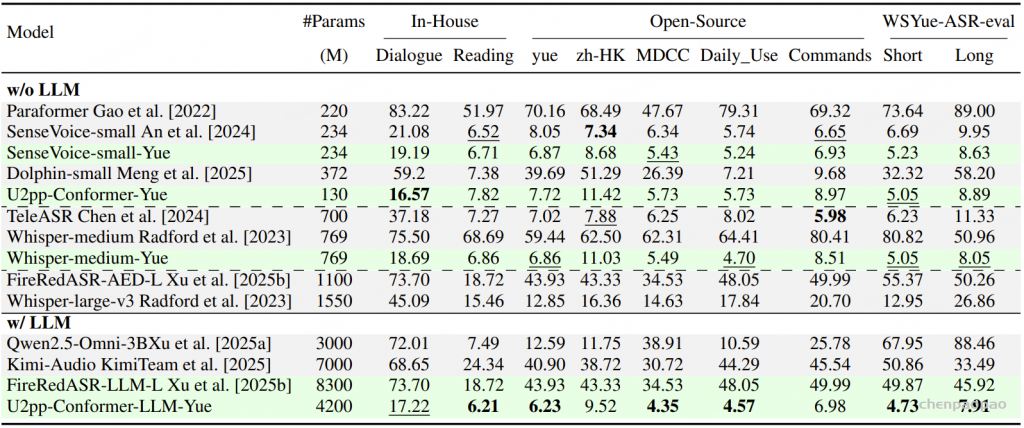
总体来看,WenetSpeech-Yue 不仅显著提升了整体性能,还能充分释放不同规模模型的潜力,验证了其在传统 ASR 和 LLM 增强型 ASR 中的广泛价值。
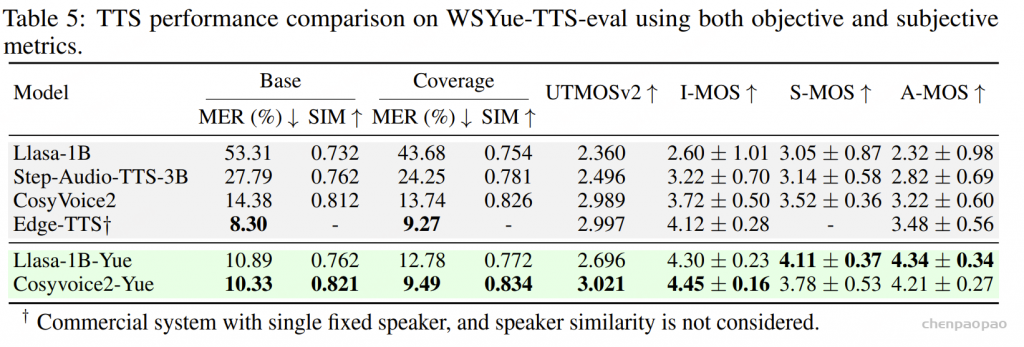
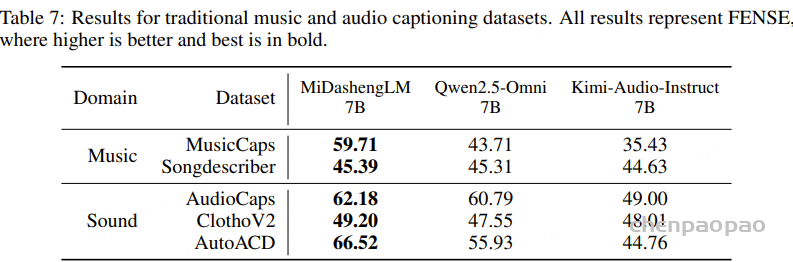
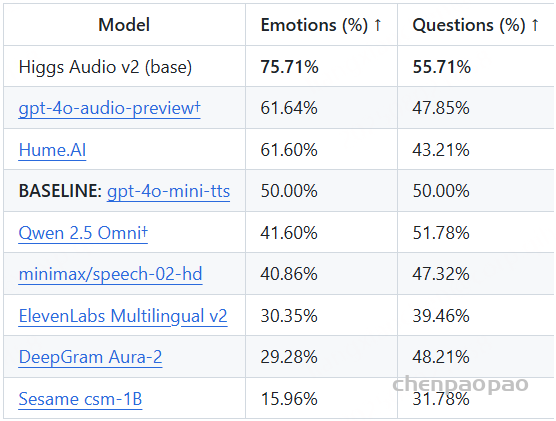
TTS任务:
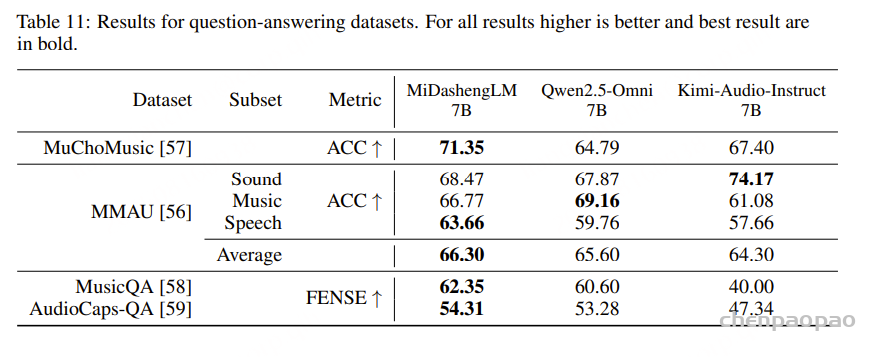
表2的实验结果表明,基于 WenetSpeech-Yue 微调的 Llasa-1B-Yue 和 CosyVoice2-Yue 在客观和主观指标上均显著优于各自的预训练基线:CosyVoice2-Yue 在 MER 和自然度(UTMOSv2)上表现最佳,并取得最高的可懂度(I-MOS),而 Llasa-1B-Yue 则在说话人相似度(S-MOS)和口音自然度(A-MOS)方面领先,体现了更自然的韵律与风格。整体上,两种模型在多维度上均大幅提升了粤语 TTS 的质量,验证了 WenetSpeech-Yue 在推动粤语语音合成方面的有效性。