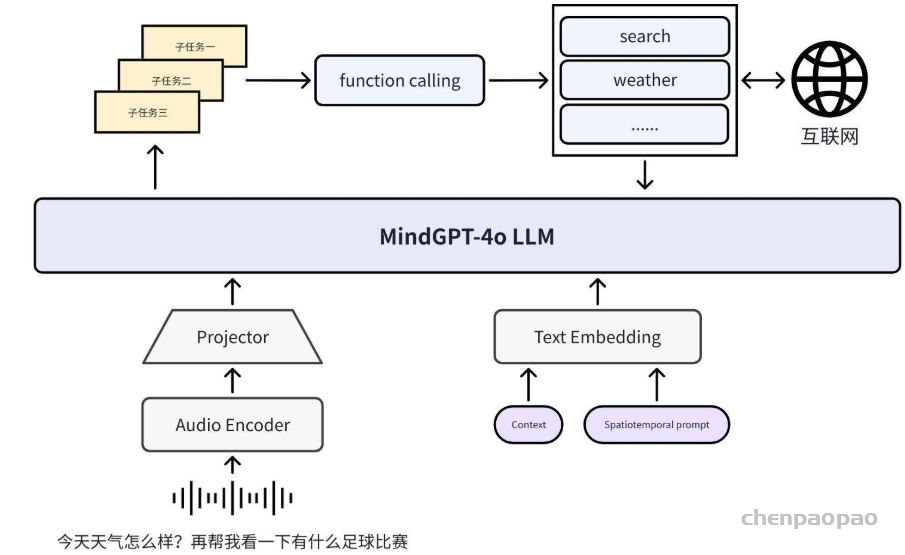
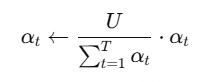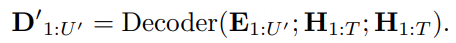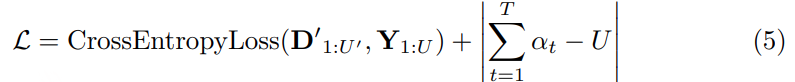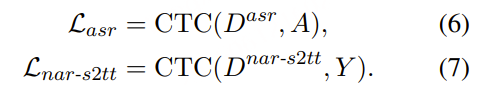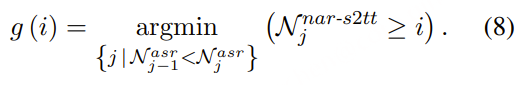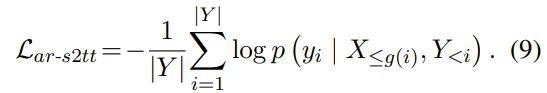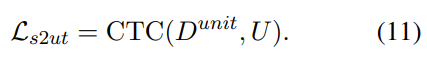- ThinkSound github:https://github.com/FunAudioLLM/ThinkSound
- ThinkSound paper:https://arxiv.org/pdf/2506.21448
- 🌐 English | 简体中文 | 繁體中文 | Español | Français | 日本語
ThinkSound 是一个统一的 Any2Audio 生成框架,通过链式思维(Chain-of-Thought, CoT)推理进行流匹配指导。
基于 PyTorch 的多模态音频生成与编辑实现:可基于视频、文本、音频及其组合,生成或编辑音频,底层由多模态大语言模型(MLLMs)逐步推理驱动。
主要特性:
- Any2Audio:支持任意模态(视频、文本、音频或其组合)生成音频。
- 视频转音频 SOTA:在多个 V2A 基准上取得最新最优结果。
- CoT 驱动推理:基于链式思维推理,实现可组合、可控的音频生成。
- 交互式面向对象编辑:通过点击视觉对象或文本指令,细化或编辑特定声音事件。
- 统一框架:单一基础模型,支持生成、编辑与交互式工作流。
Abstract
ThinkSound 将音频生成与编辑分为三个交互式阶段,均由基于 MLLM 的链式思维(CoT)推理指导:
- 拟音生成(Foley Generation): 从视频生成基础、语义与时序对齐的声景。
- 面向对象的细化: 通过点击或选择视频中的对象区域,对用户指定对象的声音进行细化或添加。
- 定向音频编辑: 使用高级自然语言指令对生成音频进行修改。
在每个阶段,一个多模态大语言模型都会生成与上下文相符的 CoT 推理内容,用以指导统一的音频基础模型。此外,我们还引入了 AudioCoT,一个包含结构化推理标注的综合数据集,用于建立视觉内容、文本描述与声音合成之间的联系。
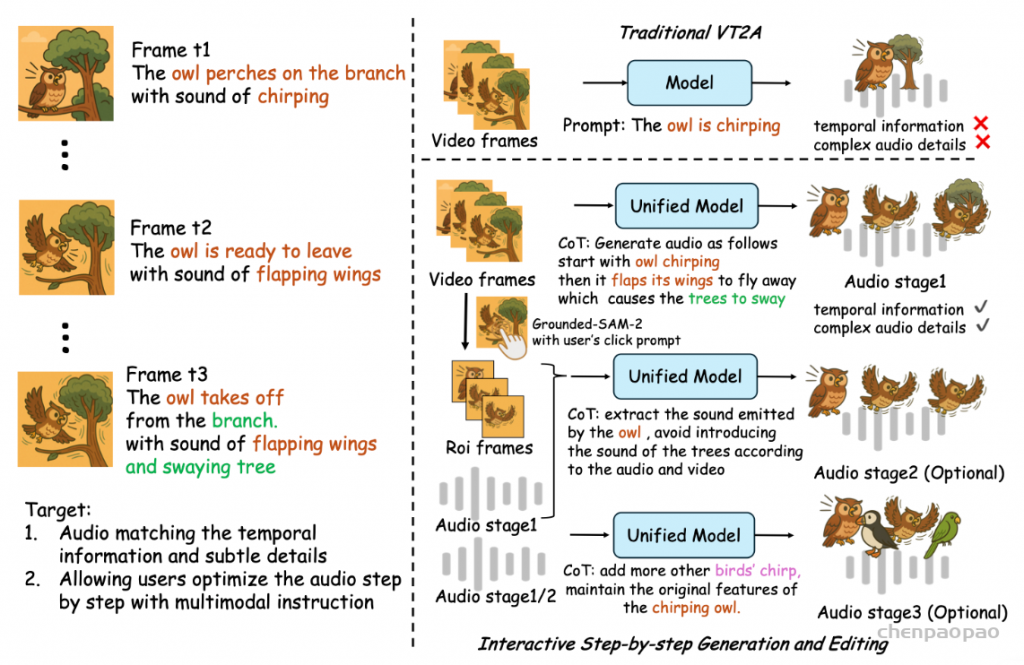
为视频生成真实的声音不仅仅是识别物体,它还需要对复杂的视觉动态和上下文进行推理,比如判断一只猫头鹰是在鸣叫还是在拍打翅膀,识别树枝轻微的摆动,并在一个场景中同步多个声音事件。
ThinkSound——在技术上,提出了三个关键创新:
- a) 对 MLLM 进行 AudioCoT 微调,使其能生成结构化、面向音频的推理链,明确捕捉时间依赖关系、声学属性与复杂音频事件的分解过程;
- b) 设计了一个基于 flow matching 的统一音频基础模型,支持所有三个阶段,能够从任意组合的输入模态(视频、文本、音频)中合成高保真音频。该模型直接受益于 MLLM 提供的细致 CoT 推理,将复杂音频场景分解为可控组件,在保证整体连贯性的同时实现重点声音事件的精确合成;
- c) 引入了一个新颖的基于点击的交互界面,使用户能够选择特定视觉对象进行音频精修,CoT 推理机制将视觉关注转化为语境合理的声音合成过程。
AudioCoT Dataset for CoT-Guided Generation and Editing
Multimodal Data Sources
AudioCoT 数据集包含视频-音频和音频-文本对。对于视频-音频数据,我们利用 VGGSound 和 AudioSet中精选的非语音子集,以确保广泛覆盖现实世界的视听事件。对于音频-文本数据,我们聚合了来自 AudioSet-SL 、Freesound 、AudioCaps和 BBC Sound Effects数据对,从而构建了一个用于训练多模态模型的多样化且具有代表性的语料库。
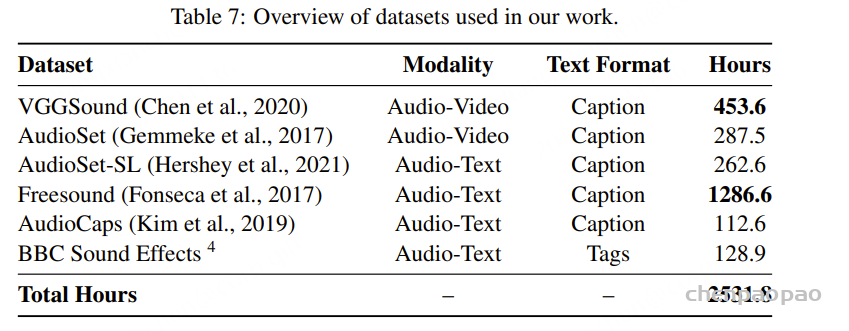
首先移除静默的音频-视频片段,仅保留含有效内容的素材。针对AudioSet子集,根据标签信息进一步剔除了含有人声的片段,以专注于非语音音频。随后将所有音视频片段统一分割为9.1秒的固定时长,舍弃较短片段以保证数据 uniformity(统一性)。为实现数据平衡,保持音乐与音效样本的比例约为1:1,确保两类别的均衡表征。
自动化 CoT 生成流程:

第一阶段:基础拟音思维链生成
- 视频-音频对处理:
- 使用VideoLLaMA2通过差异化提示策略提取视频的时序与语义信息
- 结合Qwen2-Audio生成音频描述
- 将视频描述与音频描述通过GPT-4.1-nano整合为完整思维链
- 纯音频-文本对处理:
采用简化流程(无需VideoLLA2),直接生成音频描述后与现有文本标注整合
该阶段生成的思维链能捕捉内容条件与对应音频元素的复杂关联,确保两类数据共同促进音频生成推理的全面理解
第二阶段:交互式对象中心思维链生成
为实现对象聚焦的音频生成,开发基于Grounded SAM2的ROI提取框架:
- 对象定位:以音频描述为提示,生成潜在发声物体的边界框
- 时序追踪:跨视频帧持续跟踪坐标变化
- 语义增强:VideoLLA2为每个ROI片段提供详细语义描述
- 复杂操作处理:
- 建立分层推理结构,合并目标视频CoT 与参考视频的思维链CoT 以构建全局上下文
- 结合ROI特定生成信息,通过GPT-4.1-nano生成连贯的操作逻辑
第三阶段:基于指令的音频编辑思维链生成
针对指令引导的音频编辑任务,基于四类核心(扩展、修复、添加和移除)分析并整合来自第一阶段的 CoT 信息。这些操作涵盖从扩展序列到删除不需要的片段的各种场景。GPT-4.1-nano 处理这些整合的信息,生成特定于指令的 CoT 推理链,同时执行相应的音频操作,创建(指令-CoT、输入音频、输出音频)三元组,用于模型训练和评估。
ThinkSound
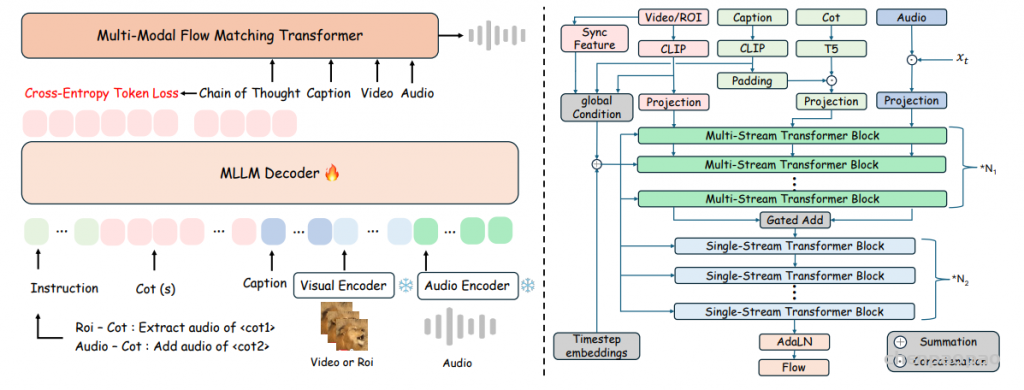
Overview
ThinkSound 引入了一个新颖的分步式交互式音频生成和编辑框架,该框架由 CoT 推理引导。我们的方法将复杂的 V2A 任务分解为三个直观的阶段:(1) 基础拟音生成,创建语义和时间匹配的音景;(2) 通过用户点击进行基于区域的交互式细化;以及 (3) 基于高级指令的定向音频编辑。在每个阶段,MLLM 都会生成 CoT 推理,引导统一的音频基础模型制作和细化音轨。
使用多模态 LLM 进行 CoT 推理
为了实现分步式、情境感知的音频生成,我们利用 VideoLLaMA2 作为核心多模态推理引擎。VideoLLaMA2 之所以被选中,是因为其在融合视频、文本和音频模态方面拥有领先的能力,而其先进的时空建模对于捕捉视觉事件与其对应听觉表现之间的微妙相互作用至关重要。
通过AudioCoT数据集对VideoLLA2进行微调,使其适配音频推理领域。该数据集包含专为视听任务定制的丰富标注推理链,通过微调过程使模型具备三大核心能力:
(1)音频中心化理解能力
- 声学特性推断(如材料属性、空间混响等)
- 声音传播建模
- 视听对应关系推理(包括音频事件间的时序与因果关系,例如”脚步声先于开门声,随后出现对话声”)
(2)结构化思维链分解能力
将复杂音频生成/编辑任务拆解为明确可执行的步骤序列
(3)多模态指令跟随能力
可靠地解析并执行跨模态的多样化生成/编辑指令
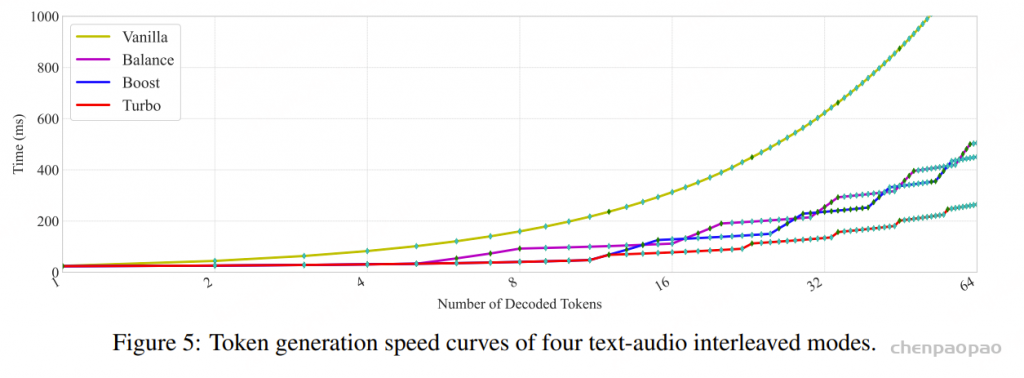
如图3所示,微调目标采用标准的下一个token预测交叉熵损失。通过这种针对性适配,VideoLLA2被转化为专用音频推理模块,能够生成上下文精确的思维链指令,驱动ThinkSound流程的每个阶段。
CoT 引导的统一音频基础模型
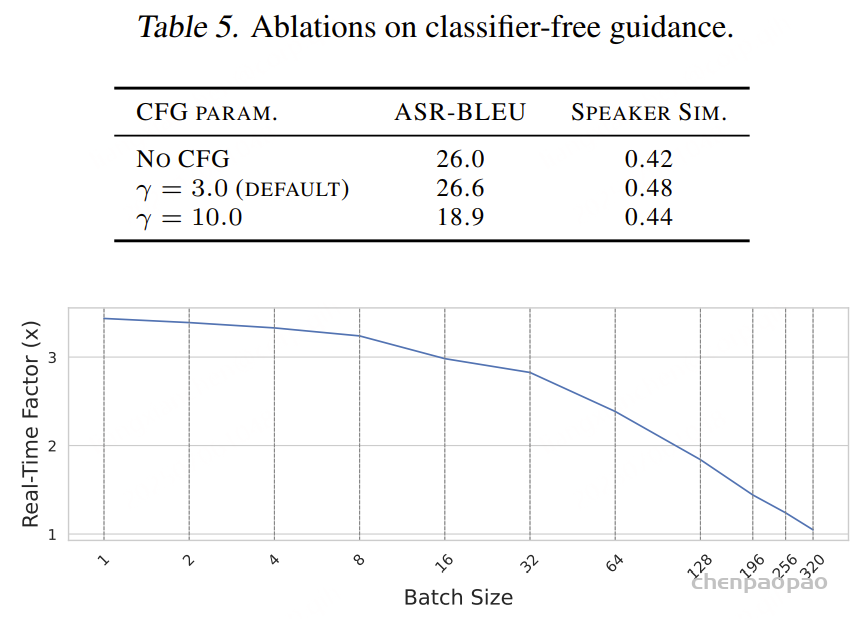
ThinkSound 的核心是我们统一的音频基础模型,它能将 CoT 推理无缝转换为高质量音频,具体细节见图 3 右侧部分。使用预训练的 VAE将音频编码为潜在表示,并采用条件流匹配对模型进行训练,其中速度场预测以多模态上下文为条件,包括视觉内容、CoT 推理、文本描述和音频上下文。为了支持任意组合的输入模态,我们在训练过程中引入了无分类器引导的随机丢弃方法。通过以概率 p_drop 随机丢弃不同模态的组合,使模型在推理阶段能够处理任意输入配置——这对于我们的交互式框架至关重要。我们还结合了策略性音频上下文遮蔽,以支持音频修补和扩展等高级编辑操作。
在文本处理方面,我们采用了双通道编码策略:MetaCLIP对视觉字幕进行编码,提供场景级上下文;而 T5-v1-xl则处理结构化的 CoT 推理,以捕捉详细的时间和因果关系。这两种互补的表示被有效融合,MetaCLIP 的特征作为全局条件信号,而 T5 的输出则支持基于推理的精细控制。
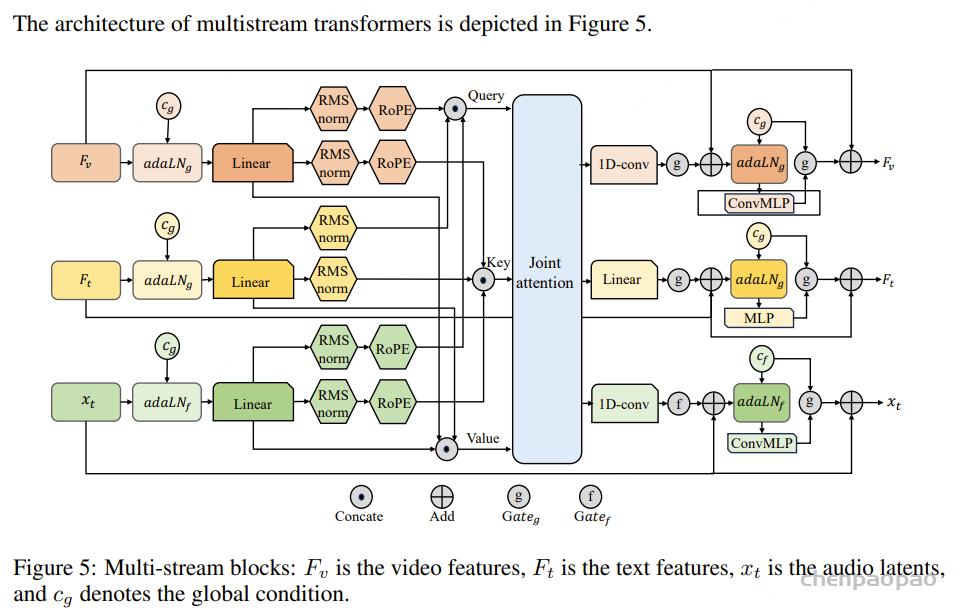
我们改进的 MM-DiT 架构基于多模态生成建模领域的最新进展,包含三大关键组件:(1)采用混合型 Transformer 主干网络,在模态专用与共享处理之间交替进行。多流 Transformer 块为每个模态维护独立参数,同时共享注意力机制,从而高效处理多样输入,同时兼顾跨模态学习。(2)设计了自适应融合模块,通过门控机制对视频特征进行上采样并与音频潜变量融合。这不仅能够突出显著的视觉线索、抑制无关信息,还确保视频信息直接参与后续的单流 Transformer 块。通过将视频整合到音频潜变量空间,模型可以更好地捕捉细微视觉细节及其对声景的微妙影响,实现比仅依赖音频潜变量更丰富的跨模态推理。(3)通过对字幕和视频的 CLIP 特征进行均值池化,实现全局条件控制,并借鉴 MMAudio,引入同步特征以提升音视频时间对齐效果。最终得到的全局条件被添加到时间步嵌入中,并通过自适应层归一化(AdaLN)注入多流与单流块。
逐步 CoT 引导的音频生成和编辑
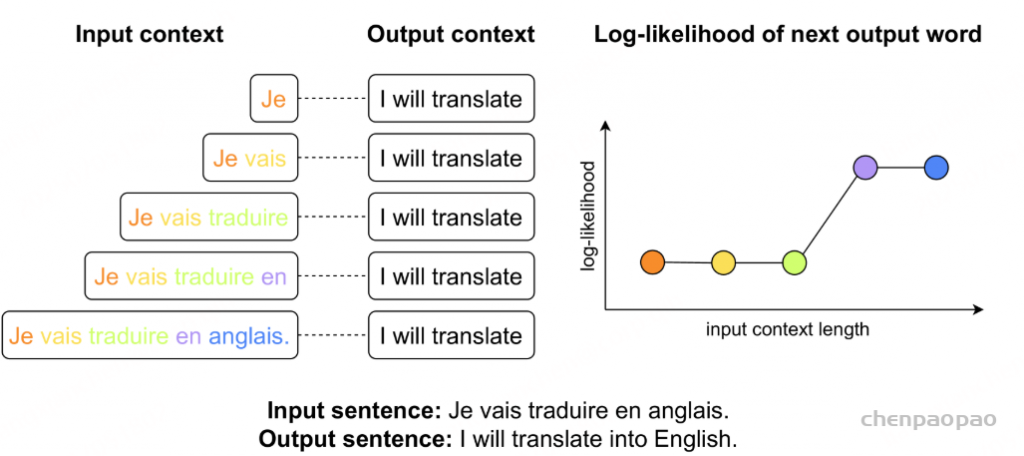
通过支持输入模式与 CoT 的灵活组合,ThinkSound 支持将音频生成分解为图 1 所示的三个直观阶段。该三阶段流程通过直观的交互式工作流程,实现了逐步精细化、高度定制化的音频生成,CoT 推理在每个步骤中将用户意图与音频合成连接起来。
阶段 1:基于 CoT 的拟音生成
在第一阶段,系统分析整段视频以识别声学要素及其关系。经过微调的 MLLM 生成详细的 CoT 推理,明确识别主要声事件、环境元素、声学属性以及它们的时间依赖关系——确定物体何时发声及声音间的相互作用。这种结构化推理指导音频基础模型生成高保真音频,精准匹配视觉场景的语义内容与时间动态。借助 CoT 推理将复杂音频场景拆解为显式声源,模型能够生成多样且连贯的声景,捕捉微妙视觉线索与运动动态,实现逼真的音频合成。
阶段 2:交互式对象聚焦音频生成
第二阶段引入交互框架,让用户通过关注特定视觉元素来优化初步声景。借助简单的点击界面,用户可以选择感兴趣的物体进行音频强化。不同于第一阶段的整体生成方式,此阶段采用基于目标区域(ROI)的局部细化,利用分割出的目标区域指导定向音频合成。经过微调的 MLLM 针对所选 ROI 生成专门的 CoT 推理,关注该物体在全局背景下的声学特性。模型在这些结构化推理引导下生成物体专属声音,与第一阶段生成的音轨自然融合。值得注意的是,此阶段的基础模型将已有音频上下文作为附加条件信号纳入考虑。
阶段 3:基于指令的音频编辑
在最后阶段,用户可通过高层次的编辑指令来优化音质或修改特定元素。MLLM 将自然语言指令转译为具体的音频处理操作,利用 CoT 推理综合视觉内容和当前音频状态。基础模型在此推理及现有音频上下文条件下执行定向修改,同时保持整体连贯性。通过自然语言控制,非专业用户也可以完成复杂的音频操作,包括添加声音、移除声音、音频修补以及音频延展。
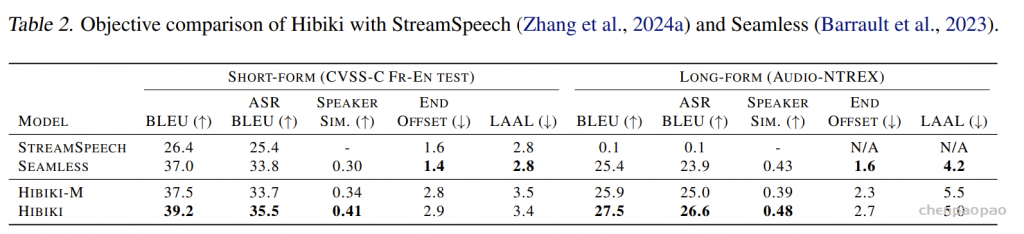
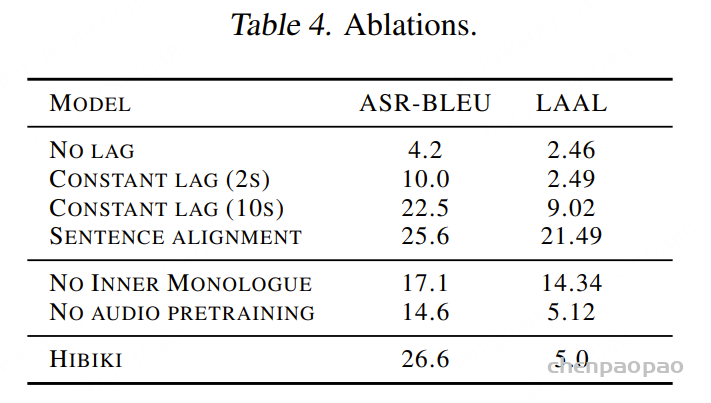
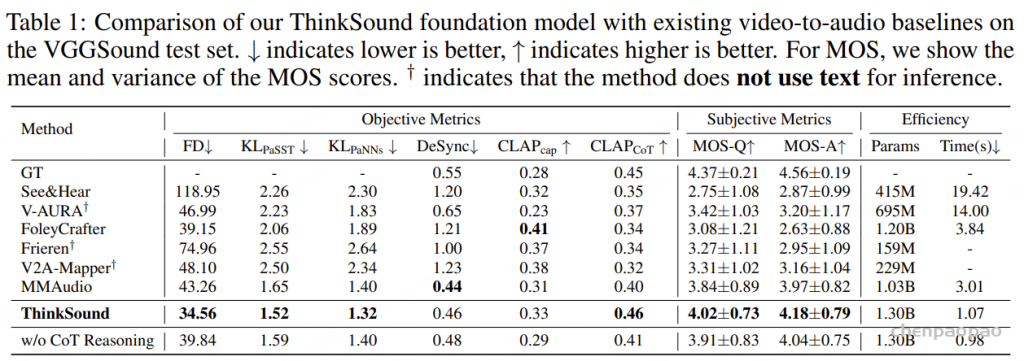
Results
虽然目前的 MLLM 模型能够很好地理解和推理语义信息,但它们在理解视频的精确时间和空间信息方面仍然存在局限性。例如,在定位声音事件的精确时间戳时,MLLM 模型经常无法提供准确的结果或给出错误的结果。此外,目前用于音频生成的开源视音频数据集在多样性和覆盖范围方面存在局限性,可能缺少稀有或特定文化的声音事件。未来,我们将继续探索更加多样化和全面的数据集,以提升模型的性能。此外,我们还将探索更有效的方法来提升生成音频的时间和空间对齐效果。