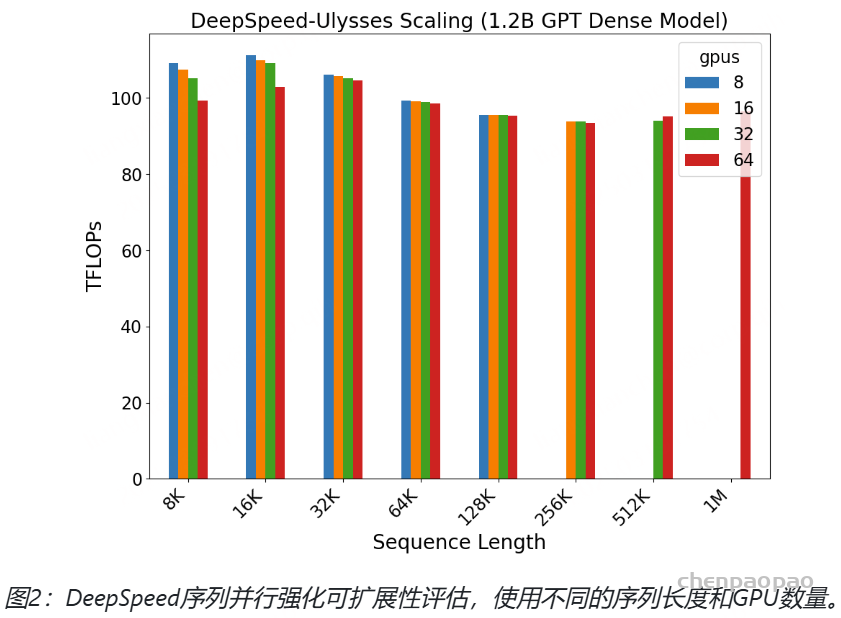
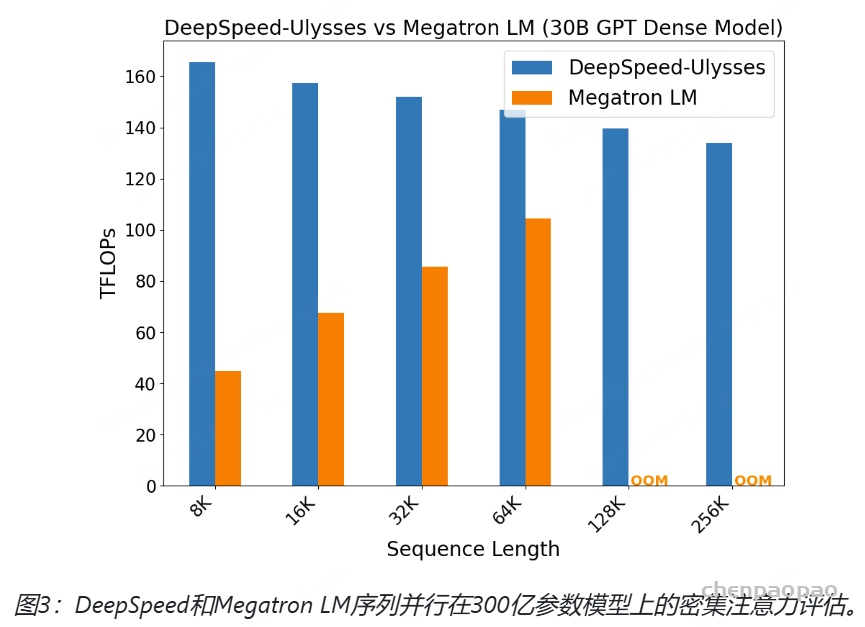
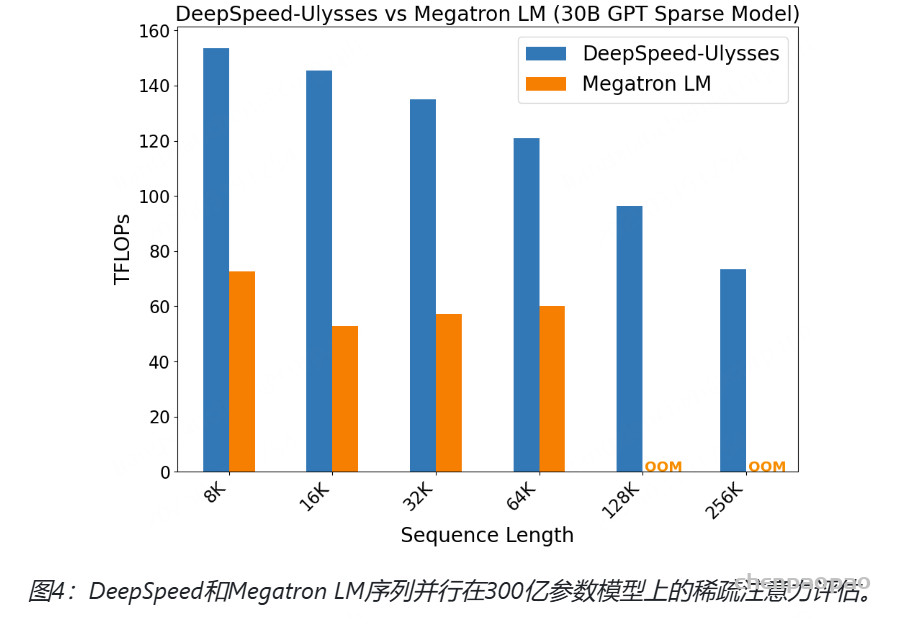
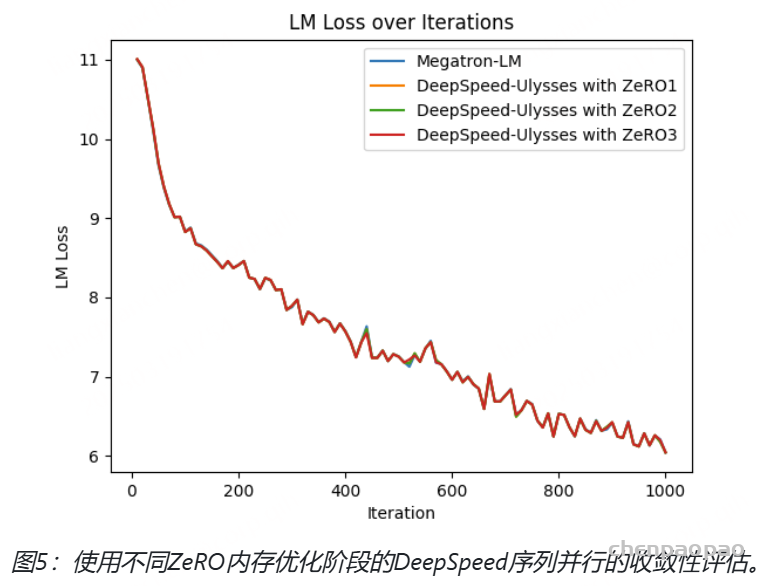
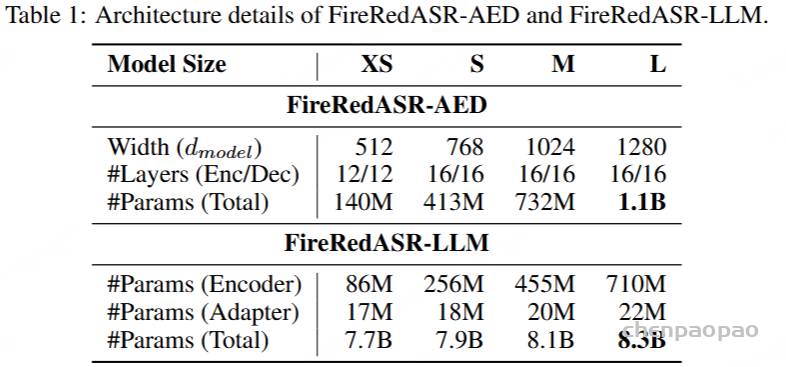
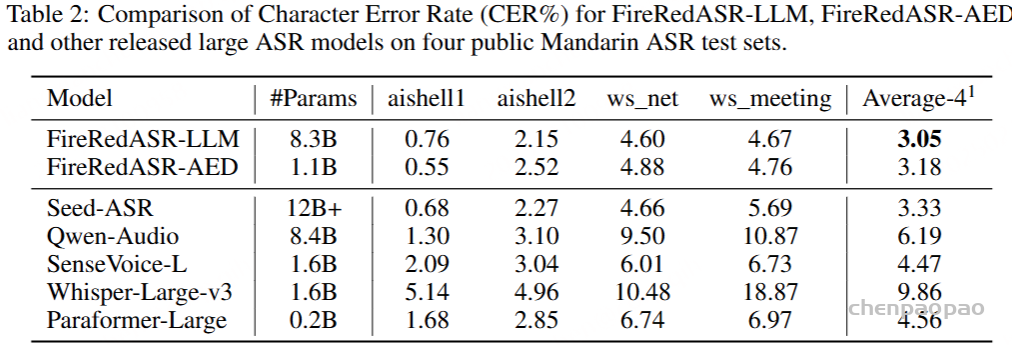
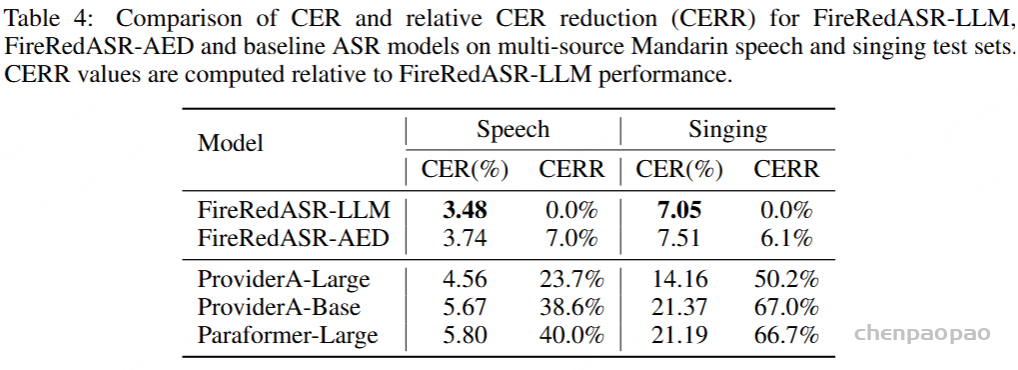
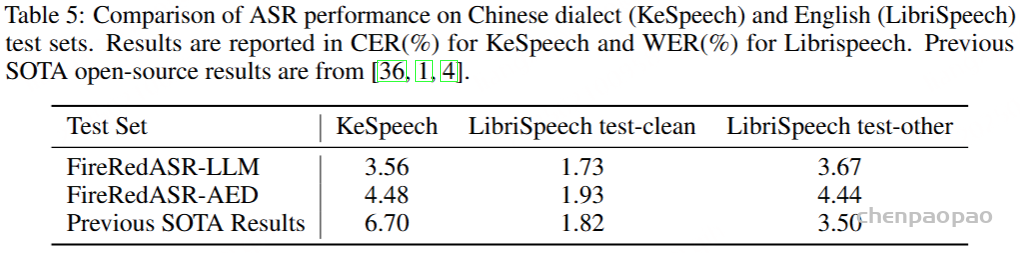
- github: https://github.com/baichuan-inc/Baichuan-Audio/
- Baichuan-Audio 🤗 | Baichuan-Audio-Base 🤗 | 技术报告 📖
- OpenAudioBench 🤗 | 训练数据 🤗 (Coming Soon)
Baichuan-Auido 是Baichuan最新的端到端训练的语音交互大模型,无缝集成了音频理解和生成功能,支持高质量可控的中英双语实时对话。
- Baichuan-Audio-Base: 为促进语音大模型发展,我们开源了使用高质量海量数据训练的端到端语音基座模型。该模型未经SFT指令微调,可塑性强。
- Baichuan-Audio: 接受文本、音频作为输入,并生成高质量文本和语音输出,能够在保持预训练 LLM 智商能力下实现无缝的高质量语音交互,和用户进行实时语音对话。
Introduction
Baichuan-Audio,这是一款为实时语音交互设计的端到端音频大语言模型。与 Moshi 和 GLM-4-Voice [输出 文本+speech token,speech token 接入cosyvoice解码器合成音频 ] 类似,Baichuan-Audio 扩展了预训练的大语言模型(LLM),以支持端到端的音频输入和输出。该模型通过集成 Baichuan-Audio-Tokenizer 和流匹配解码器来实现上述功能,前者将音频信号离散化为音频标记,后者则将音频标记解码为语音波形。
Baichuan-Audio-Tokenizer 的运行帧率为 12.5 Hz,并采用多码本离散化技术,以保留语义和声学信息,从而支持 LLM 中语音模态的有效建模。Baichuan-Audio 还引入了独立的音频头(audio head),以提升模型处理和捕捉音频特征的能力。
我们在包含约 1000 亿个标记的音频-文本数据上进行了大规模预训练。基于包含 88.7 万小时的大型音频语料库,我们采用了交错数据处理方法,以在 LLM 框架内实现高效的知识迁移。
贡献:
- 统一且卓越的语音能力:我们设计了一个 8 层 RVQ 音频分词器(Baichuan-Audio-Tokenizer),在 12.5 Hz 帧率下实现了对语义和声学信息的最佳平衡,支持高质量、可控的中英文双语实时对话。
- 端到端语音交互:Baichuan-Audio 能够处理文本和音频输入,并生成高质量的文本和语音输出,支持无缝的高质量语音交互,同时保持智能响应能力。
- 开源支持:我们已开源训练数据和基础模型,为语音交互领域的研究与创新提供了宝贵的资源与工具。
模型

该模型结构围绕三大核心组件构建:Baichuan-Audio分词器、音频大语言模型(audio LLM),以及音频解码器。
处理流程从音频分词器开始,它通过捕捉语义与声学信息,将原始音频输入转化为离散的token。这一步是通过 Whisper编码器 与 残差矢量量化(RVQ)技术相结合实现的。
随后,音频LLM以交替方式生成对齐的文本与音频token,并借助一个特殊的token实现文本与音频模态间的无缝切换。接下来,这些音频token将由一个独立的音频head进一步处理。
最后,模型通过一个基于Flow-Matching的方法的音频解码器,从这些token中重建出高质量的Mel谱图,再通过 声码器(vocoder)将其转换为音频波形。
Audio Tokenization
当前音频分词器面临的主要挑战,在于如何在捕捉语音信号中的语义信息与声学信息之间取得最佳平衡。相较于像 HuBERT 这样的自监督学习方法,Baichuan-Omni 与 Qwen-Audio 这类模型在捕捉语义特征方面提供了更直接的路径。【ASR任务】
与此同时,像 Encodec和 SpeechTokenizer这样的音频分词器则在完整重建音频特征方面表现尤为出色。【音频重建任务】
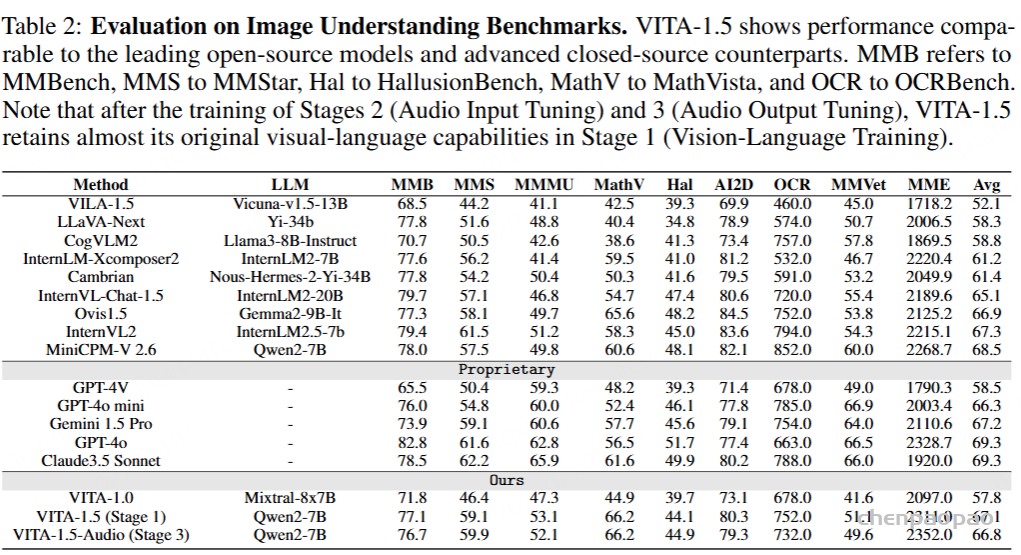
为了结合这两类方法的优点,提出了 Baichuan-Audio-Tokenizer:一个基于 残差矢量量化(RVQ) 和 多目标训练【重建音频任务以及ASR任务】 的音频分词器,如图2所示。Baichuan-Audio-Tokenizer 保留了来自 Baichuan-Omni 的音频编码器和语言模型组件,并在编码器之后新增了一个 音频解码器结构,用于重建输入的 Mel 频谱图。该音频分词器采用多目标优化方法进行训练,从而能够有效捕捉输入语音中的语义信息与声学信息。

Baichuan-Audio-Tokenizer 采用了每秒 12.5 个 token 的帧率设计。高层次的音频特征首先通过 Whisper Large 编码器从 Mel 频谱图(Mel spectrogram) 中提取,随后通过一个 残差卷积网络 进行 4× 下采样,以获得低帧率的音频特征。
由于 Whisper 编码器输出的音频特征是高维的,在量化过程中需尽可能减少信息损失,因此我们使用了 8 层残差矢量量化(RVQ)。我们设计了逐层递减的码本大小,依次为:{8K, 4K, 2K, 1K, 1K, 1K, 1K, 1K}。
音频解码器采用与 Whisper 编码器完全对称的结构,通过一个 反卷积模块(deconvolution module) 对输入进行 4× 上采样。之后,序列经过一系列 Transformer 层,并进一步进行 2× 上采样,最终得到每秒 100 个 token 的粗略 Mel 频谱表示。设计了一个 精细化网络,以提升 Mel 频谱重建的精度,最终获得高质量的精细 Mel 频谱特征。
在音频重建损失函数的设计中,我们,采用 L2 损失与 L1 损失的组合 作为重建损失。其形式定义如下:

为提升音频重建的质量,我们引入了一种 多尺度 Mel 频谱损失(multiscale Mel loss) 方法,使用了两种不同的 hop length(帧移) 和 window size(窗长)。该方法有效缓解了在从解码器输出转换为 Mel 频谱过程中,由于降维和下采样插值所导致的信息损失。通过在多个尺度上进行优化,该方法能够保留更多细粒度的音频特征,从而提升重建的保真度和训练的稳定性。
对于预训练的语言模型(LLM),其目标是在音频理解任务中最大化文本输出的 softmax 概率。为了确保语义对齐,我们在训练过程中保持预训练语言模型参数不更新(冻结),仅最大化其在音频理解任务中预测文本的 softmax 概率。这种做法有助于保持音频分词器与文本LLM之间的语义对齐关系。
在选择 LLM 的规模时,我们观察到,在音频理解模型的训练过程中,不同规模的 LLM 对于 ASR(自动语音识别)指标的影响很小。因此,我们最终选用了一个拥有 15亿参数(1.5B) 的预训练 LLM 进行持续训练。这个规模的模型与音频解码器在训练过程中表现出良好的匹配性,两者的梯度范数差距较小,有助于提升整体训练的稳定性。
在量化模块的训练中,我们采用了 指数移动平均(EMA) 策略来更新码本,并使用 直通估计器(STE, Straight-Through Estimator) 来反向传播梯度至编码器。此外,我们还使用了 向量量化承诺损失(VQ commitment loss),以确保编码器的输出能够紧密对齐至码本中的条目。
VQ 承诺损失定义如下:
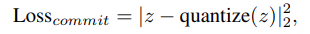
总损失是多尺度重建损失、文本音频对齐损失(对于LLM)和 VQ 承诺损失的加权组合:

训练数据。 除了自动语音识别 (ASR)、音频查询回答 (AQA) 和语音到文本翻译 (S2TT) 等传统任务外,我们还将一定比例的音频文本交错数据纳入训练过程。此策略旨在增强 VQ 模块对复杂上下文场景进行建模的能力。具体来说,训练数据集包括 135k 小时的 ASR 数据、11k 小时的 AQA 数据、9k 小时的 S2TT 翻译数据和 52k 小时的音频文本交错数据。
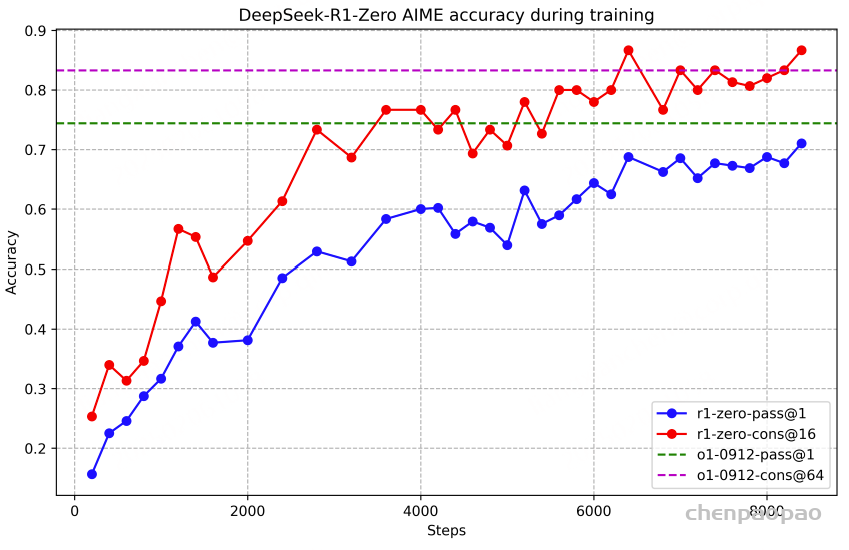
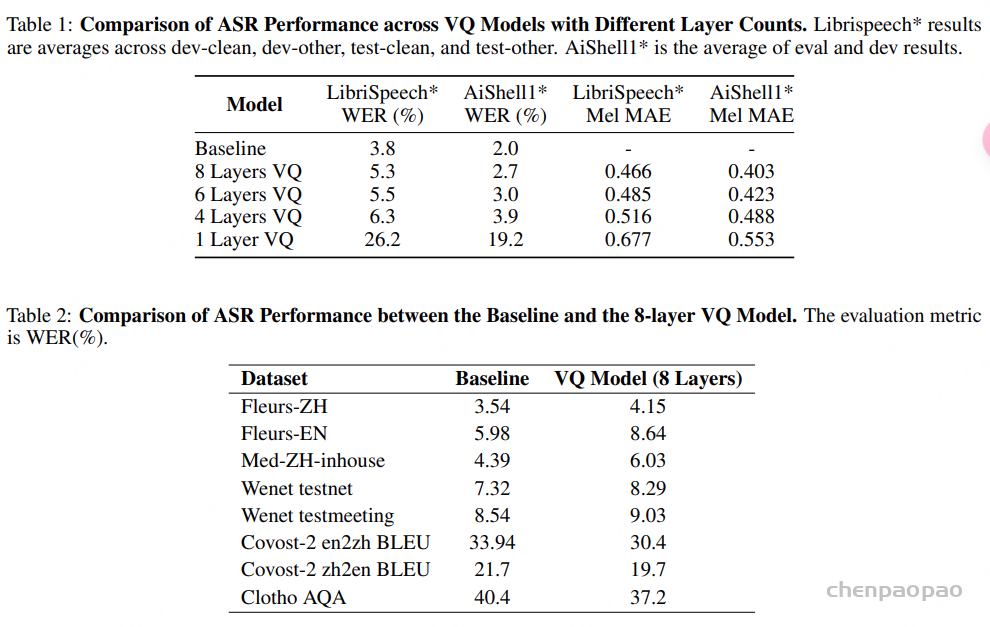
Evaluation of Baichuan-Audio-Tokenizer. 我们使用相同的数据和基础模型训练了音频理解模型的非 VQ 版本作为基线。对于 VQ 和非 VQ 模型,LLM 的参数在训练期间保持冻结,以确保公平比较并隔离 VQ 机制对整体性能的影响。从表 1 中,我们可以看到 8 层 vq 更接近基线,并且语义内容损失最少。如表 2 所示,8 层 VQ 模型和基线在多个数据集上的 ASR 结果表明,训练后的 8 层 VQ 模型实现了具有竞争力的性能。
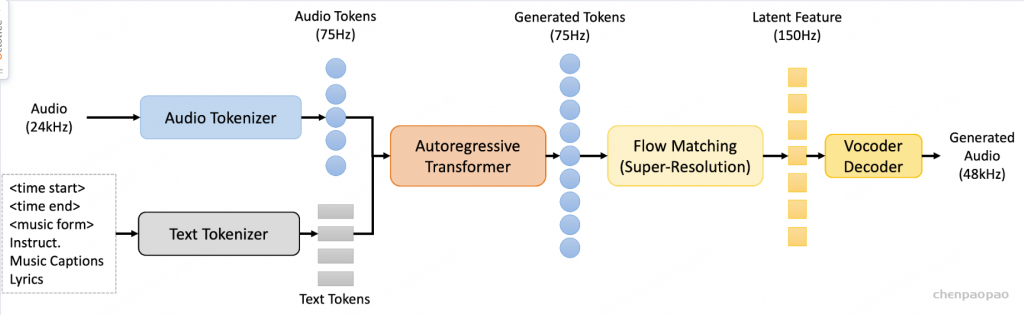
基于流匹配的音频解码器
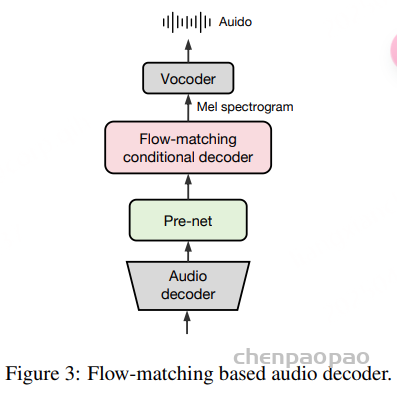
为了提升合成音频的质量与保真度,我们对音频解码模块进行了增强,引入了 Flow-Matching 模型,在 24 kHz 采样率的音频数据上训练,用于生成目标 Mel 频谱图。该 Flow-Matching 解码器 包括两个主要部分:Pre-Net 和 条件解码器(Conditional Decoder),如图 3 所示。
Pre-Net 负责将中间表示映射为供声码器(vocoder)使用的先验分布,结构上由一个 多层感知机(MLP) 和一个 12 层 Transformer 组成:MLP 将输入的 1280维、50 Hz 的音频特征压缩投影至 512维;接着,Transformer 对其进行精细建模;最后通过一个线性层转换为 80维的 Mel 频谱图。
条件解码器(Flow-Matching Conditional Decoder)。该部分采用基于 U-Net 的结构,并结合 OT-CFM(Optimal Transport Conditional Flow Matching) 方法进行训练,灵感来源于 Matcha-TTS 和 CosyVoice 。
U-Net 结构包括:一个下采样模块、一个上采样模块,以及 12 个中间模块,每个模块由一个 ResNet1D 层 和一个 Transformer 层(256维)组成。最终,再通过一个线性层将特征投影为 80维 Mel 频谱图。
需要注意的是,由于模型已通过重建损失编码了声学信息(如说话人音色),因此 不需要额外的说话人嵌入(speaker embeddings)。生成的 Mel 频谱图将通过 HiFi-GAN 声码器转换为音频波形。
训练细节: 流匹配模型在约 27 万小时的音频上进行了训练,包括普通话、英语、各种方言和多语言数据。使用集成 ASR 和 MOS 过滤来改善数据质量。在训练期间,AudioEncoder、VQ 层和 AudioDecoder 是固定的,而流匹配 Pre-Net 和解码器则在 Pre-Net 中添加了先验损失进行训练。
重建性能评估:

Audio LLM
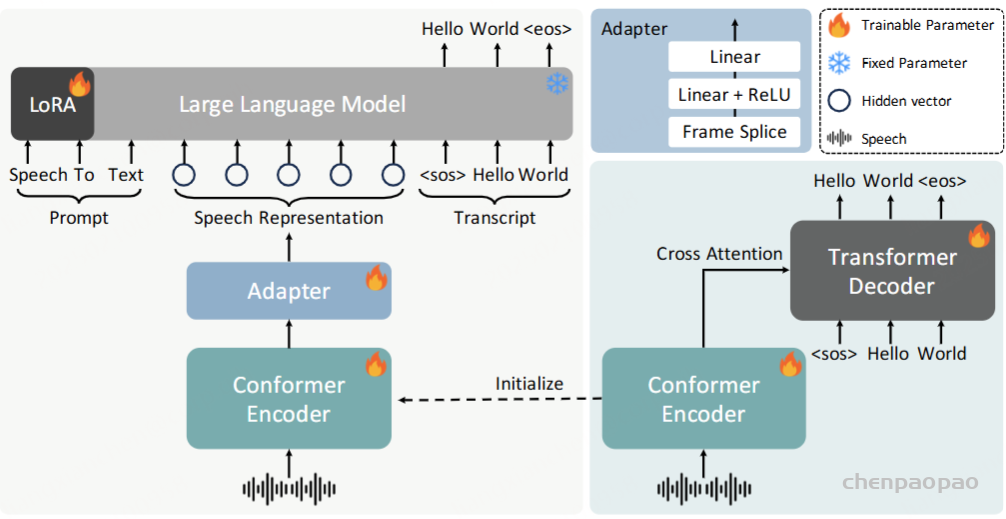
Baichuan-Audio 通过整合新推出的 Baichuan-Audio-Tokenizer(包括音频嵌入层和独立的音频头)扩展了预训练的 LLM。具体来说,来自 Baichuan-Audio-Tokenizer 的音频标记首先通过音频嵌入层转换为音频嵌入。音频 LLM 交替生成对齐的文本标记和音频标记,并通过特殊标记实现文本和音频之间的模态切换。生成的音频标记由独立的音频头处理,该头由 3 层深度转换器和 8 个分类头组成。最后,音频嵌入通过音频编码器(例如基于流匹配的音频编码器和声码器)以重建音频波形。
音频嵌入。 首先,将 8 个离散音频标记通过相应数量的嵌入层相加以获得音频嵌入。由于包含一个额外的特殊标记来表示音频标记生成的结束,因此每个嵌入层的输入维度都比相应码本的大小大一。
音频头。生成的音频标记使用独立的音频头进行处理,该音频头由 3 层深度转换器和 8 个分类头组成。深度转换器的深度为 8,可预测 8 个码本的音频嵌入。最后,分类头用于获取与音频标记相对应的每个码本的逻辑值。
与纯文本大模型相比,语音语言模型(speech language models) 往往在生成语义连贯的输出方面存在困难。研究 [36] 指出,这一问题主要源于语音中引入了 时长信息(duration) 和 副语言信息(paralinguistic information),例如语调、语气等。
为了解决这一问题,我们在预训练阶段引入了两种类型的交错数据(interleaved data):音频-文本交错数据(INTLV, Audio-Text Interleaved)、文本到语音交错数据(ITTS, Interleaved Text-to-Speech)
这两种数据设计有助于提升模型的音频理解与生成能力。
在推理阶段,离散音频 token 会被送入 LLM,模型随后以交替的方式生成对齐的 文本 token 和 音频 token。我们引入了特殊 token,用于在文本与音频模态间切换。这种强制对齐策略(forced alignment approach)确保了模型会优先生成连贯完整的文本内容,再生成对应的音频 token,从而有效引导音频 token 的生成,缓解语义退化问题。
Pre-training details:
数据: 交错数据由交替的文本和音频模态组成,并用标点符号分隔以促进跨模态知识传输。交错对齐的生成数据由完全对齐的文本和音频内容组成,旨在增强模型在文本监督下生成音频标记的能力。音频-文本配对数据(例如,ASR 和 TTS 数据)提高了基本语音任务的性能。另一方面,纯音频数据增强了独立处理音频模态的能力。交错数据收集流程如图 4 所示,分为爬取数据和合成数据两种,共获取了 14.2 万小时的 ITTS 数据和 39.3 万小时的 INTLV 数据。交错数据采用LLM进行切分,即根据文本内容中的标点符号或自然停顿进行自然切分。对于合成数据的切分文本数据,我们还采用了大型语言模型进行文本归一化 。在预训练过程中,我们排除了音频文本交错数据中音频片段的损失计算,这一设计选择与 GLM-4-Voice 不同。 在当前约 50B 的训练音频数据规模下进行的经验观察表明,计算 INTLV 数据中音频片段的损失会导致性能下降。这一决定的合理性还在于音频和文本之间固有的模态冲突,以及推理过程中不需要文本到音频的延续。因此,我们省略了 INTLV 数据中音频片段的损失计算。对于 ITTS 数据,除了初始文本片段外,还计算了音频和文本片段的损失,以增强模型在文本引导音频生成方面的能力。

两阶段训练策略。 为了解决语音特征与文本特征的不同特征可能导致的LLM中原始文本知识的潜在破坏,我们提出了一种两阶段训练策略来缓解模态之间的训练冲突。在第一阶段,LLM的参数保持不变,只允许更新音频嵌入层和音频头的参数。在第二阶段,除文本嵌入层和 LM 头的参数外,所有参数都可训练。
监督微调细节
监督微调阶段旨在增强模型在一系列任务中遵循复杂指令的能力。音频 SFT 数据来自大量文本指令。使用基于指令类型、多样性和整体质量的过滤策略选择高质量指令。使用 10,000 种不同语音音调的精选数据集合成音频指令。在自然对话停顿处生成和分割相应的文本响应,然后使用指定的语音音调转换为音频。这些数据集涵盖多项任务,包含大约 242k 个音频数据对。
为了确保合成音频的质量,自动语音识别 (ASR) 被应用于生成的音频文件。将 ASR 输出与原始文本进行比较以验证质量。此过程可创建高质量的端到端对话数据集。有错误的合成音频文件将添加到文本转语音 (TTS) 数据集,而有 ASR 错误的案例将合并到 ASR 训练数据集中。这种合并具有挑战性的示例的迭代方法可增强 TTS 和 ASR 的性能。
需要特别注意处理文本转音频导致原始文本响应不适合作为音频回复的情况。此问题是由于文本和音频之间的语调、速度和表达方式的差异而产生的。某些文本内容在转换为音频时可能无法传达预期含义或引入歧义。因此,在生成过程中仔细检查和调整此类情况至关重要。这可确保合成数据准确反映现实世界的语音交互场景,从而提高数据可靠性并提高模型的实际适用性。
Experiment
综合智力测评
基于语音的对话模型面临的一大挑战是,与纯文本对话模型相比,其性能往往会下降。为了评估语音模型的“智能”,我们以文本到文本的建模能力为基准,评估预训练的语音到文本模型的性能。评估数据集包括两种类型:故事延续能力和常识推理能力。

Performance in ASR/TTS Tasks


Performance in Audio Understanding Tasks
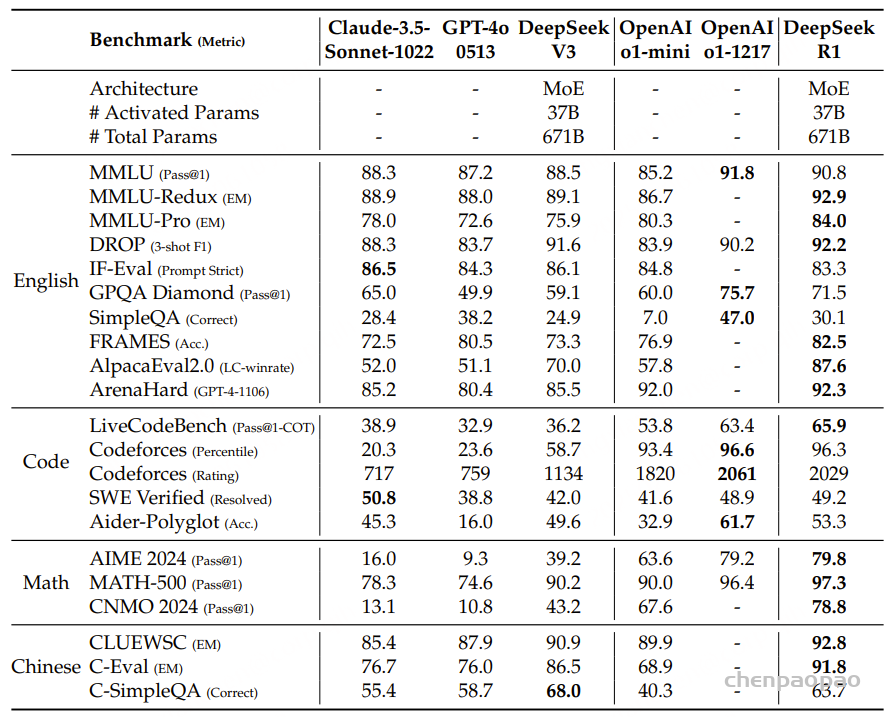
模型在音频理解基准测试中表现优异,超越了最新的开源模型。
两种不同的设置:1)非级联方式的语音到语音生成(表示为 S → S),其中输入是音频,输出是交错的文本和音频。然后合并输出文本并用于评估。2)语音到文本生成(表示为 S → T,其中输入是音频,输出是文本,用于评估。

总结
Baichuan-Audio,这是一种专为音频设计的端到端大型语言模型,集成了语音理解和生成功能。该模型通过预训练的 ASR 模型对 12.5 Hz 的语音信号进行多码本离散化,从而保留了语音标记中的语义和声学信息。此外,还专门设计了一个独立的音频头来高效处理这些标记。为了平衡音频建模和语言能力保留,采用了交错数据的两阶段预训练策略。所提出的框架通过文本引导的对齐语音生成来支持语音交互,从而进一步保留了模型的基础认知能力。