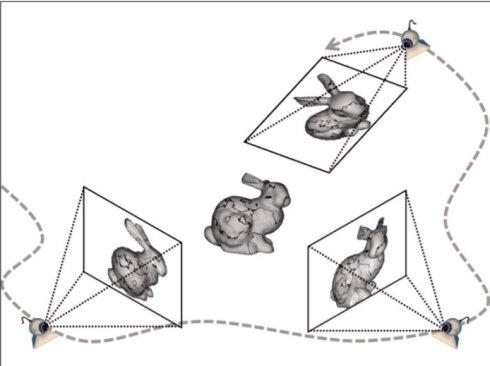
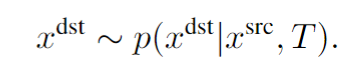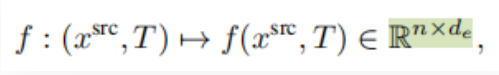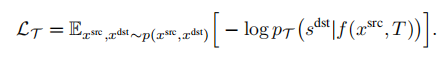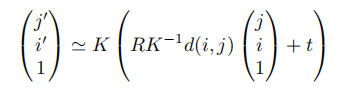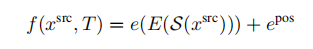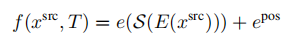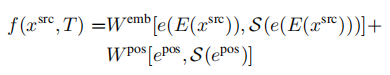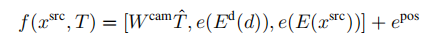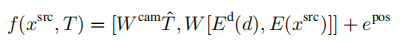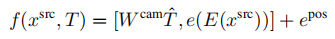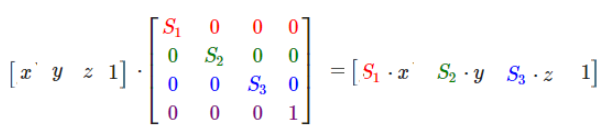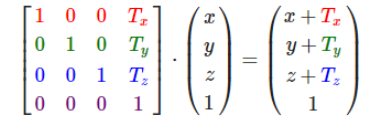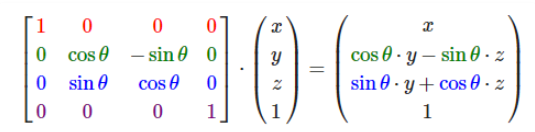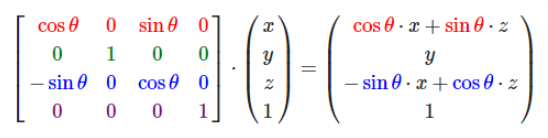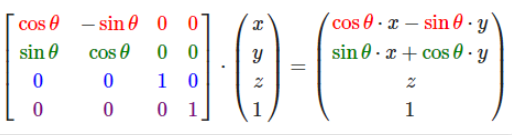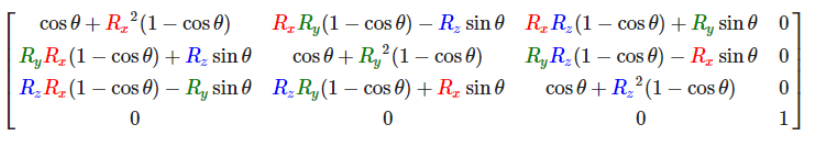[2] N.Snavely, S.M. Seitz, R.Szeliski, “Modeling the World from Internet Photo Collections”, International Journal of Computer Vision, vol.80, no.2, 2008.
[3] Y. Furukawa, J.Ponce, “Accurate, Dense and Robust Multi-view Stereopsis” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009.
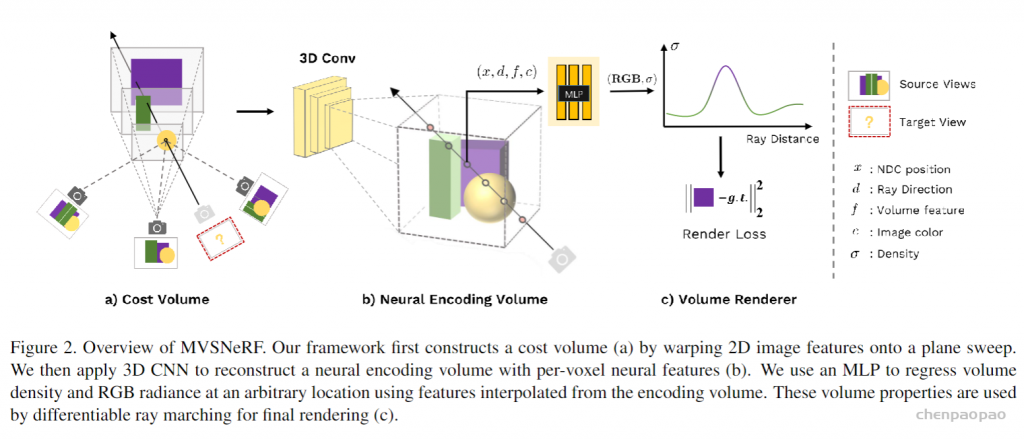
提出了一种新的神经渲染方法neural rendering approach MVSNeRF,它可以有效地重建用于视图合成的神经辐射场。与先前关于神经辐射场的工作不同,这些工作考虑对密集捕获的图像进行逐场景优化,我们提出了一种通用的深度神经网络,该网络可以通过快速网络推理仅从三个附近的输入视图重建辐射场。我们的方法利用平面扫描成本体plane-swept cost volumes(广泛用于多视图立体multi-view stereo)进行几何感知场景推理,并将其与基于物理的体渲染相结合进行神经辐射场重建。我们在DTU数据集中的真实对象上训练我们的网络,并在三个不同的数据集上测试它以评估它的有效性和可推广性generalizability我们的方法可以跨场景(甚至室内场景,完全不同于我们的对象训练场景)进行推广generalize across scenes,并仅使用三幅输入图像生成逼真的视图合成结果,明显优于目前的广义辐射场重建generalizable radiance field reconstruction工作。此外,如果捕捉到密集图像dense images are captured,我们估计的辐射场表示可以容易地微调easily fine-tuned;这导致快速的逐场景重建fast per-scene reconstruction,比NeRF具有更高的渲染质量和更少的优化时间。
我们利用最近在深度多视图立体(MVS)deep multi- view stereo (MVS)上的成功[50,18,10]。这一系列工作可以通过对成本体积应用3D卷积applying 3D convolutions on cost volumes来训练用于3D重建任务的可概括的神经网络。与[50]类似,我们通过将来自附近输入视图的2D图像特征(由2D CNN推断)扭曲warping到参考视图的平截头体中的扫描平面上sweeping planes in the reference view’s frustrum,在输入参考视图处构建成本体。不像MVS方法[50,10]仅在这样的成本体积上进行深度推断depth inference,我们的网络推理关于场景几何形状和外观reasons about both scene geometry and appearance,并输出神经辐射场(见图2),实现视图合成。具体来说,利用3D CNN,我们重建(从成本体)神经场景编码体neural scene encoding volume,其由 编码关于局部场景几何形状和外观的信息的每个体素神经特征per-voxel neural features 组成。然后,我们利用多层感知器(MLP)在编码体积encoding volume内使用三线性插值神经特征tri-inearly interpolated neural features来解码任意连续位置处的体积密度volume density和辐射度radiance。本质上,编码体是辐射场的局部神经表示;一旦估计,该体积可以直接用于(丢弃3D CNN)通过可微分射线行进differentiable ray marching(如在[34]中)的最终渲染。
// boFirst.cpp : Defines the exported functions for the DLL.
#include "pch.h" // use stdafx.h in Visual Studio 2017 and earlier
#include <utility>
#include <limits.h>
#include "boFirst.h"
# include <iostream>
int bo_add(int a, int b)
{
int c;
c = a + b;
return c;
}
float bo_shape_vol(boShape bs)
{
float volume = bs.width * bs.height * bs.depth;
std::cout << bs.shape << "volume is " << volume << std::endl;
return volume;
}
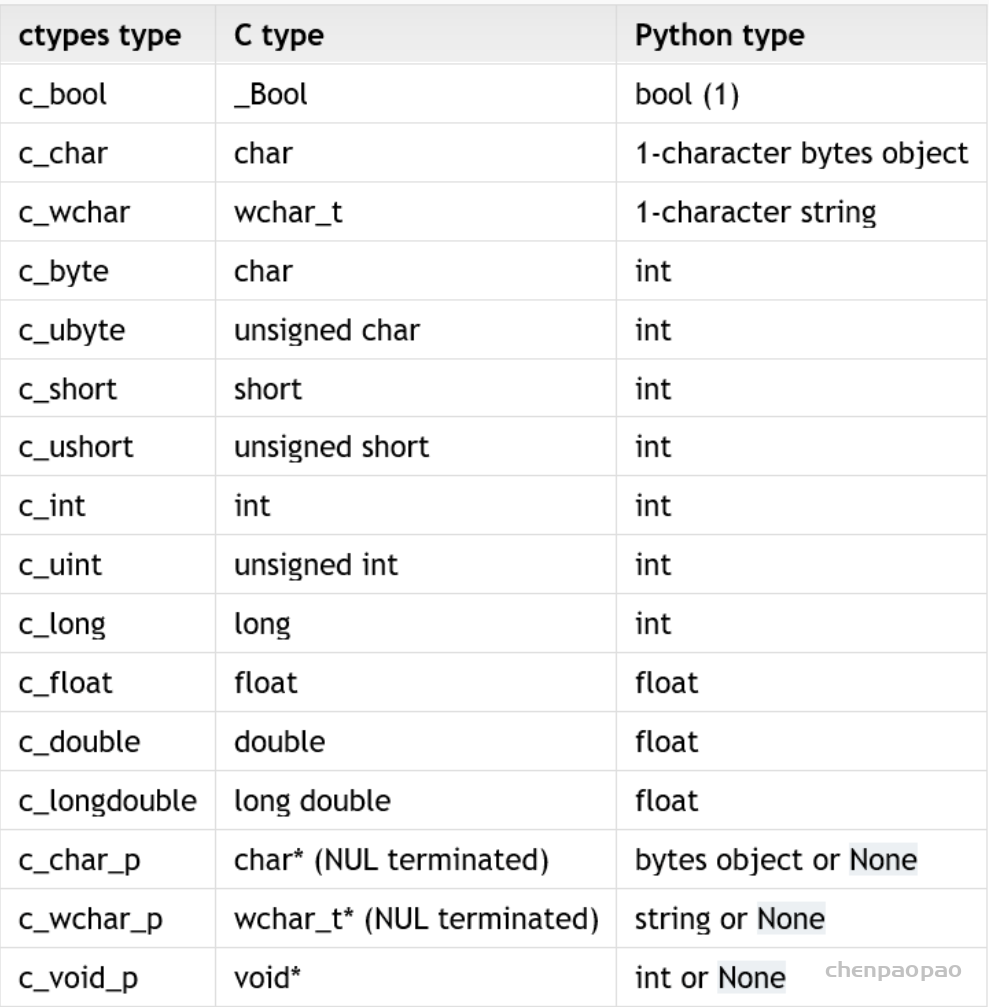
def find_example_ctypes(required):
'''
Finds and loads example shared object of the required major
'''
# Importing ``ctypes`` should be in scope of this function to prevent failure
from ctypes import util, cdll
so_name = util.find_library('example.dll')
if so_name is None:
raise ExampleImportError('EXAMPLE shared object not found.')
example = cdll.LoadLibrary(so_name)
require_version(example.example_version(), required)
return example
Geometry-Free View Synthesis: Transformers and no 3D Priors
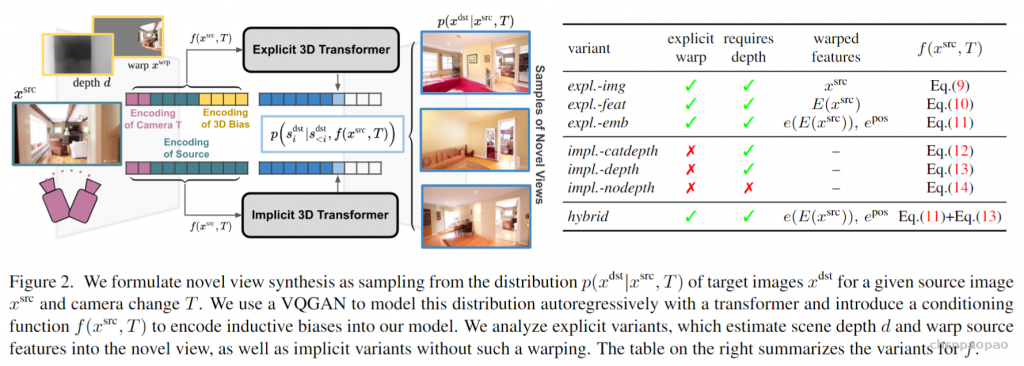
引入一种基于 transformers 的概率方法,用于从具有大视角变化的单一源图像中进行新视图合成。作者对transformers 的各种显式和隐式 3D 感应偏置进行比较,结果表明,在架构中显式使用 3D 变换对其性能没有帮助。此外,即使没有深度信息作为输入,模型也能学会在其内部表示中推断深度。这两种隐式 transformer 方法在视觉质量和保真度上都比目前的技术状态有显着的改进。
潜在空间中的概率视图合成: 为了学习上式中分布,需要捕获源视图和目标视图之间的远程交互的模型,以隐式地表示几何变换。由于基于相似的模型已经被证明直接在像素空间中建模图像时,在像素的短程交互上花费了太多的容量,我们遵循VQGAN并采用了两个阶段训练。第一阶段执行反向(对抗性)引导的离散表示学习(VQGAN),获得一个抽象的潜在空间,已被证明非常适合有效地训练生成式transformer。 建模条件图像模型: VQGAN包括一个编码器E,解码器G和一个离散表征zi(dz)的codebook Z。训练后的VQGAN允许编码任意x(HxWx3)到离散隐空间E(x)(h x w x dz)。以栅格扫描的顺序展开,这个潜在的表示形式对应于一个序列s(h x w x dz),可以等价地表示为一个整数序列,索引已学习的码本。按照通常的名称,我们将序列元素称为“tokens”。一个嵌入函数g=g(s) (hw x de)将每个tokens映射到transformer的嵌入空间中,并添加了可学习的位置编码。类似地,为了编码输入视图xsrc和照相机转换T,两者都由一个函数f映射到嵌入空间中:
隐式几何变换:接下来,我们描述我们用来分析的隐式变量,transformer能否同样好地处理所有位置,是否需要在模型中内置一个显式的几何转换。我们使用与显式变体相同的符号。 (4)第一个变体impl.-catdepth为transformer提供了显式变体中使用的所有相同组件:相机参数K、R、t、估计深度d和源图像xsrc。相机参数被拉平并连接到T^,通过Wcam(de x 1)映射到嵌入空间。深度和源图像被VQGAN编码器Ed和E编码来获得
与其他变体相比,这个序列大约长32倍,这是计算成本的两倍。 (5)因此,我们还包括了一个impl.-depth变体,它连接了深度和源图像的离散代码,并用一个矩阵W(de x 2dz)映射它们到嵌入空间以避免序列长度增加:
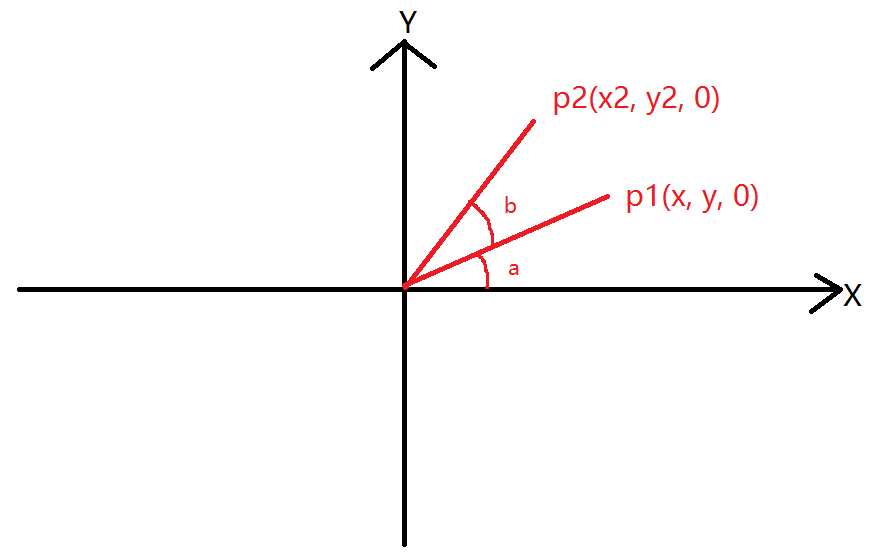
在图形学中,在做平移,旋转和缩放时,经常会用到矩阵,有缩放矩阵、平移矩阵和旋转矩阵。在三维空间中,变换矩阵都是一个四维矩阵,每一行分别表示x, y, z, w。
1. 缩放矩阵(scale)
上面的公式,左边的第一个操作数(四维矩阵)就是一个缩放矩阵,s1表示x轴的缩放倍数,s2表示y轴的缩放倍数,s3表示z轴的缩放倍数。第二个操作数表示空间中(x, y, z)点, w分量在缩放矩阵中没有用到,我们将其设为1。由右边的结果,可以看出(x, y, z)点经过缩放矩阵变换后,x、y、z分量都各自缩放了s(s1、s2、s3)倍。需要注意的是矩阵的乘法不具有交换律,这里点是用一维列矩阵表示的,作为矩阵乘法的右操作数。如果将其转换到乘法的左边,那么点应该用一维行矩阵表示: