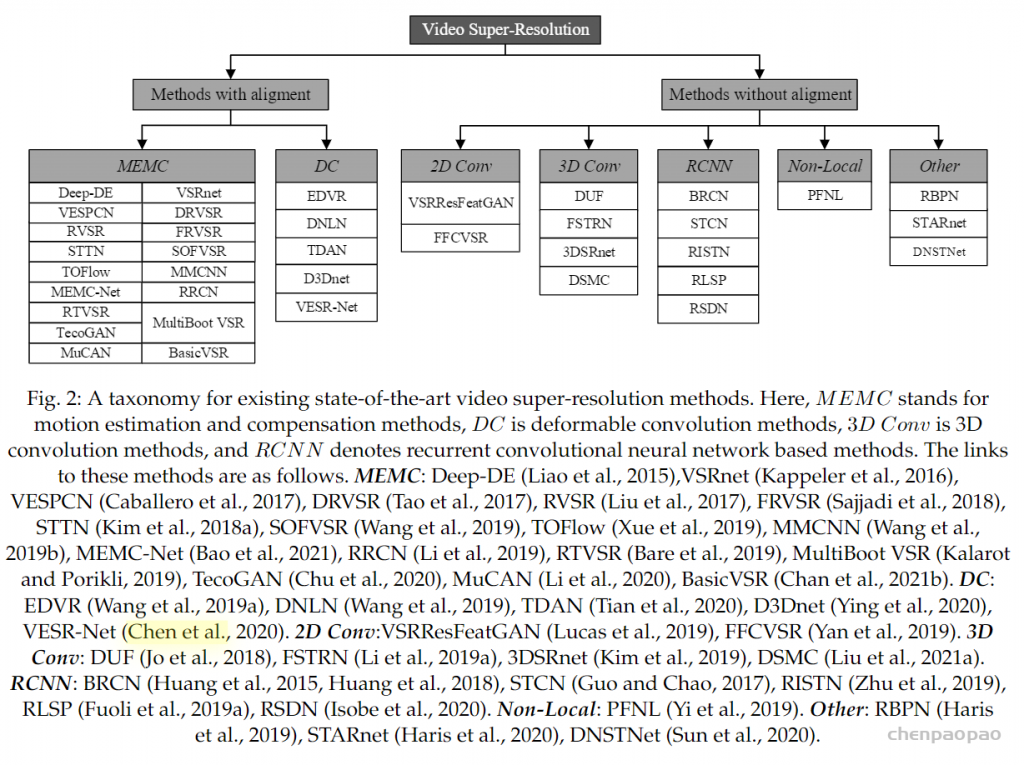
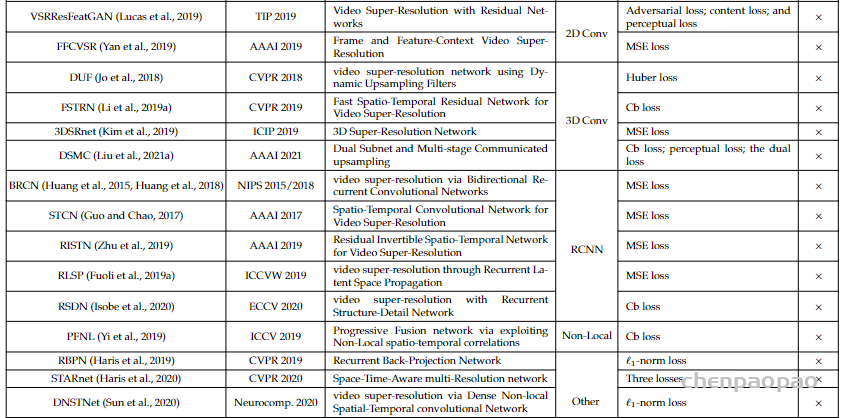
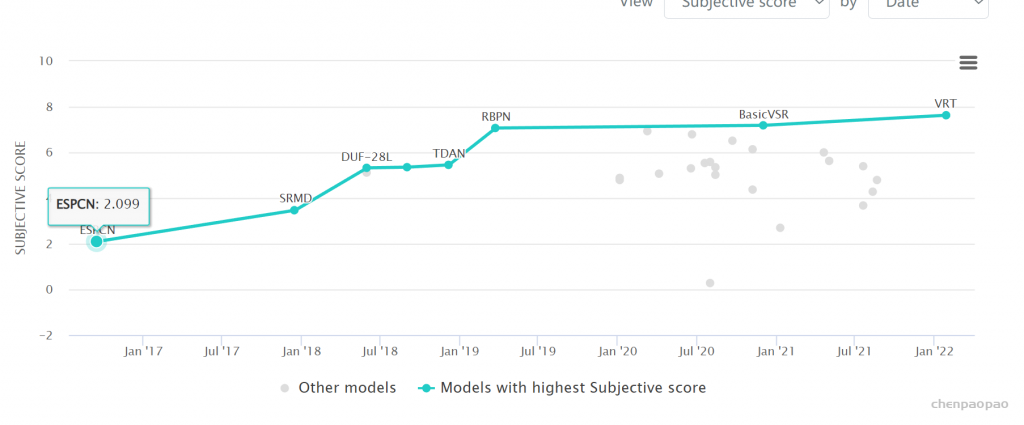
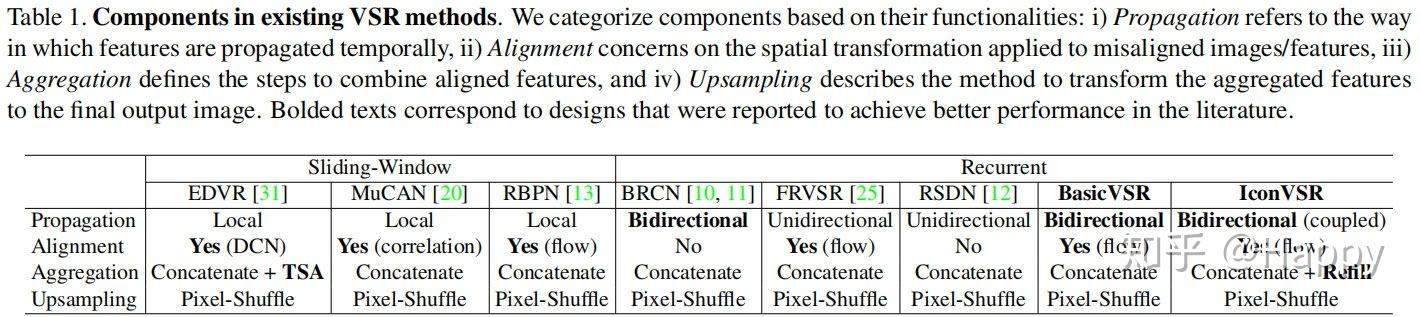
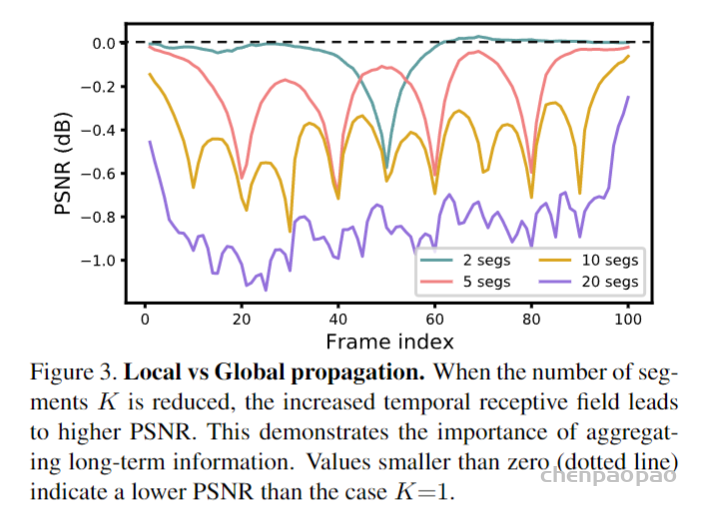
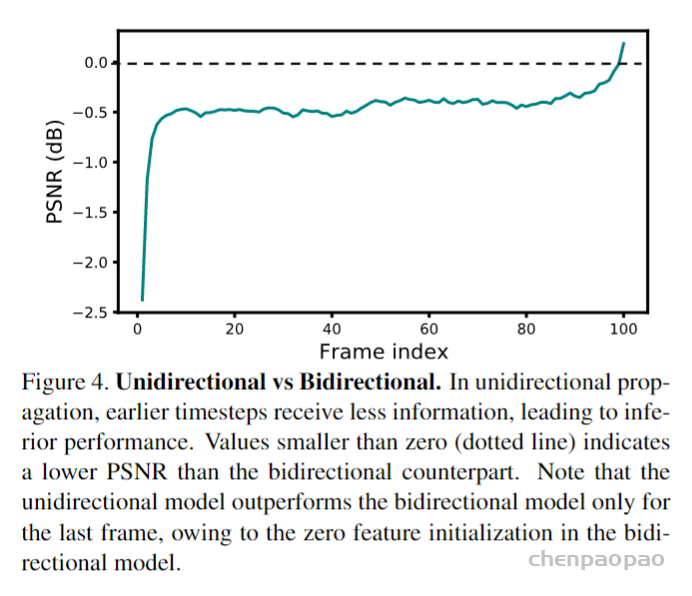
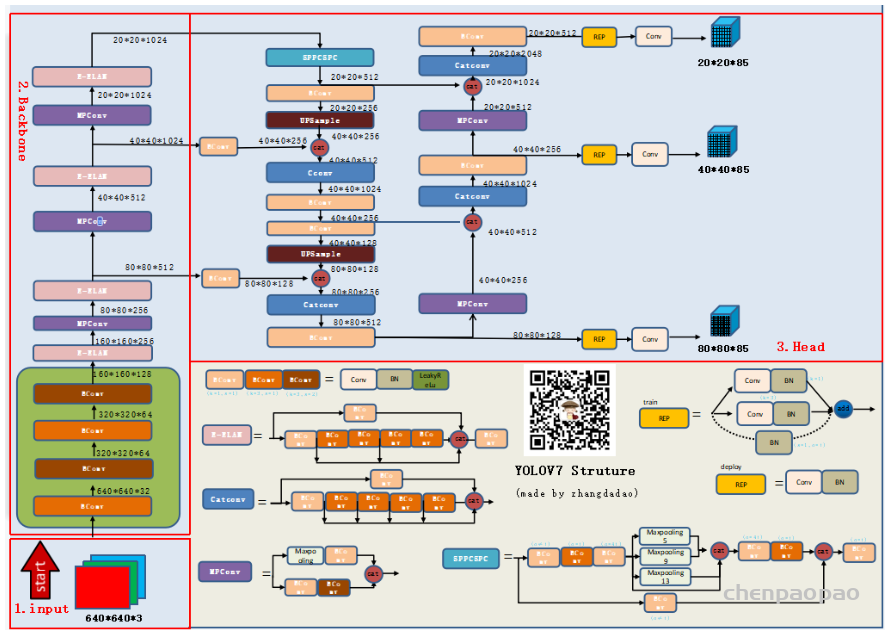
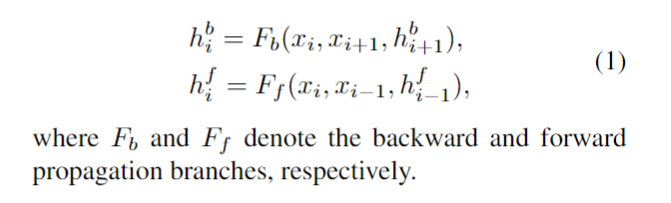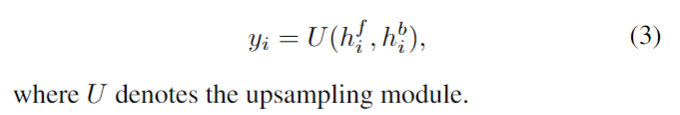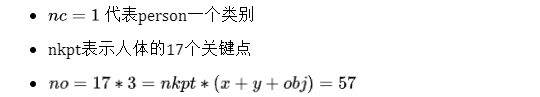Local Propagation: 滑动窗口的方法(比如RBPN,TGA,EDVR)采用局部窗口内的多帧LR图像作为输入并进行中间帧的重建。这种设计方式约束了信息范围,进而影响了模型的性能。下图给出了不同信息范围下的模型性能对比,可以看到:(1)全局信息的利用具有更佳性能;(2) 片段的两端性能差异非常大,说明了长序列累积信息(即全局信息)的重要性。
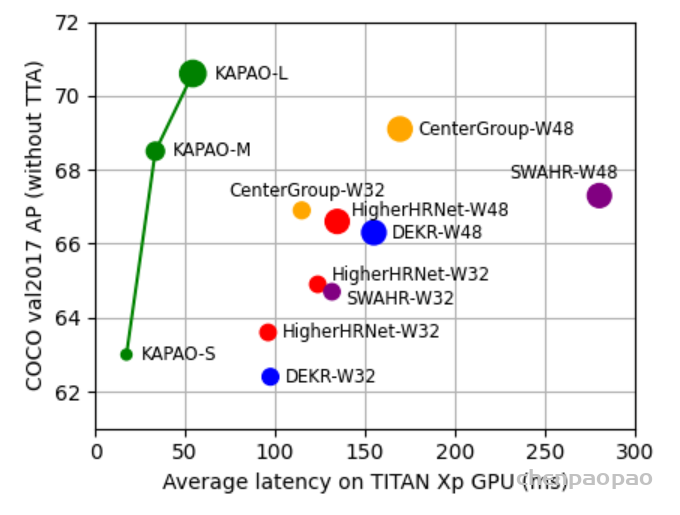
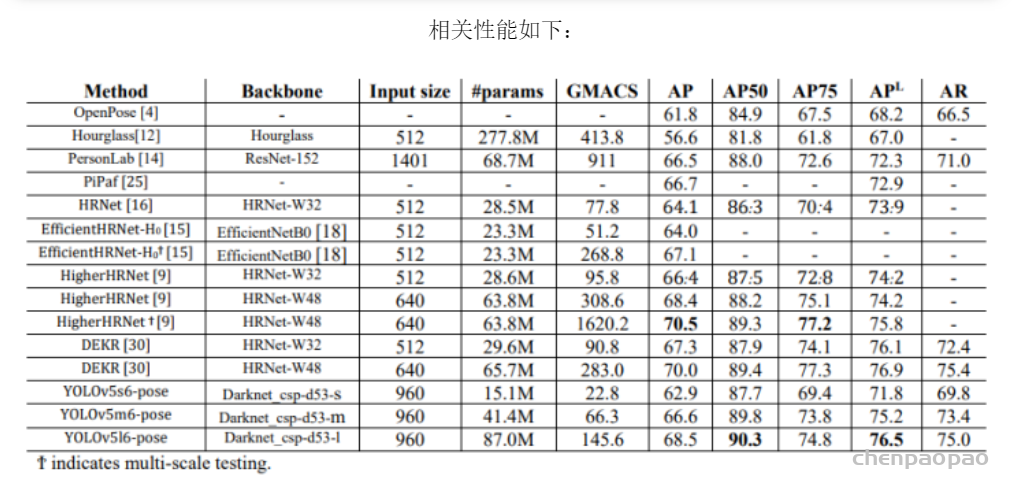
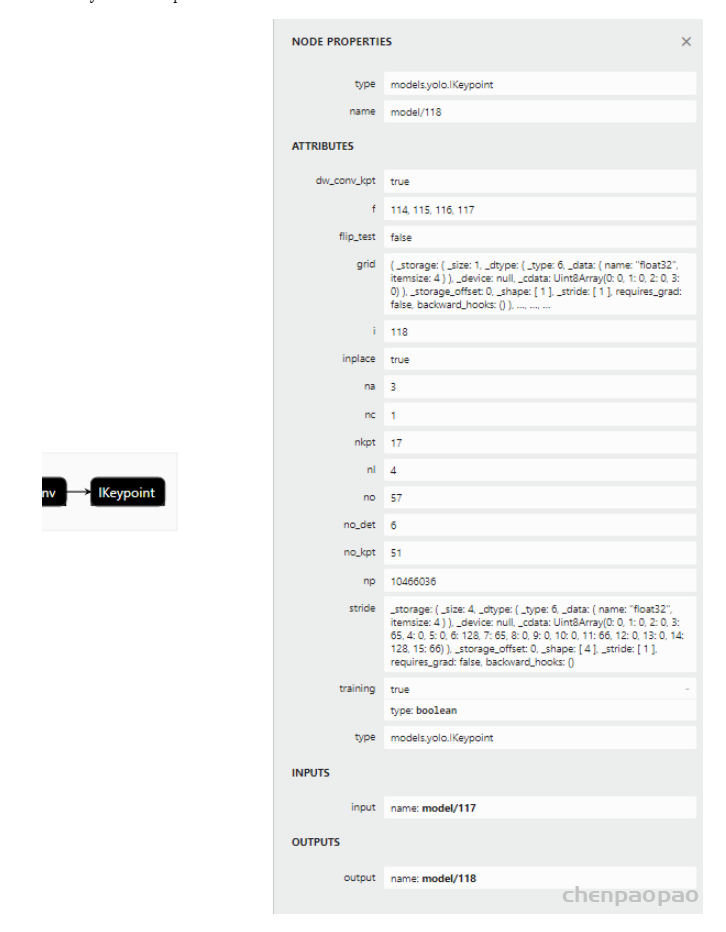
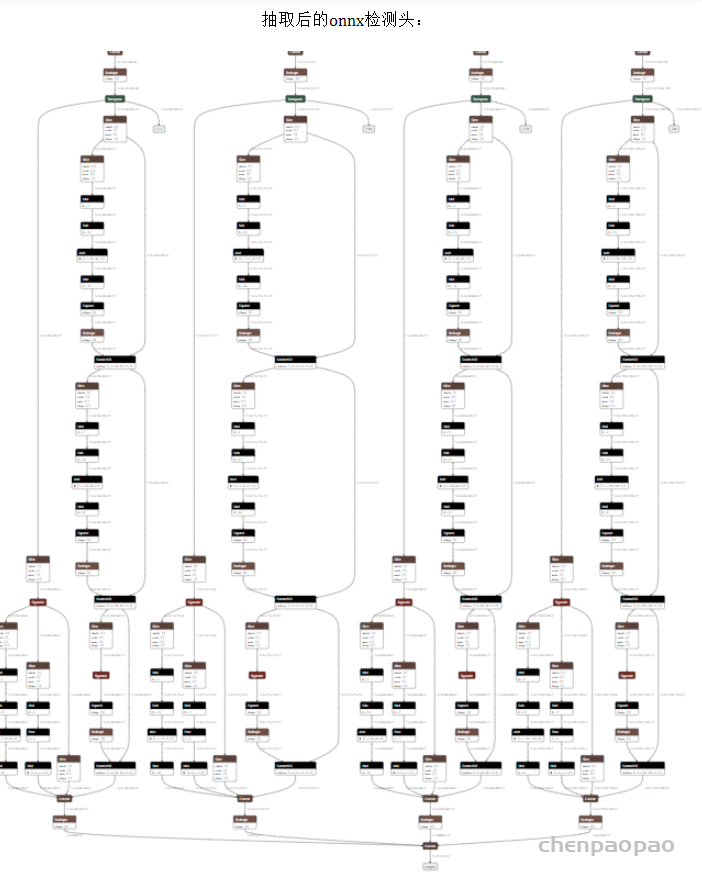
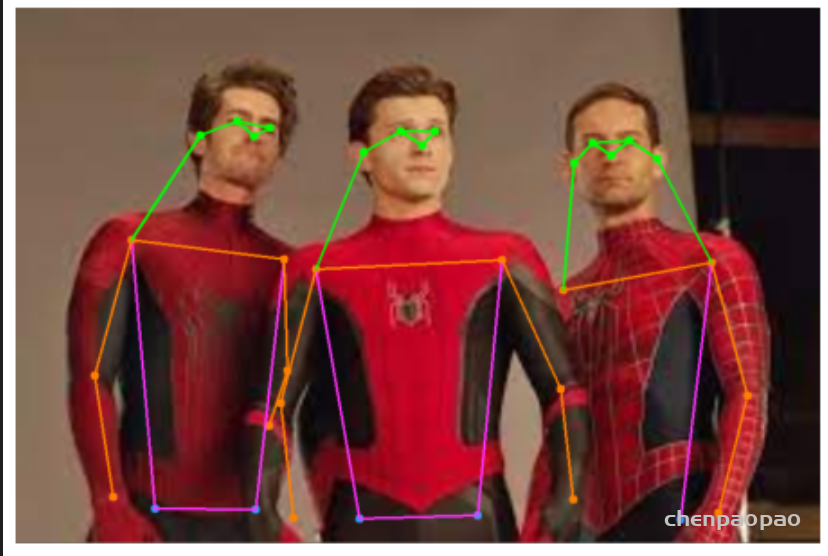
去年11月,滑铁卢大学率先提出了 KaPao:Rethinking Keypoint Representations: Modeling Keypoints and Poses as Objects for Multi-Person Human Pose Estimation,基于YOLOv5进行关键点检测,该文章目前已被ECCV 2022接收,该算法所取得的性能如下:
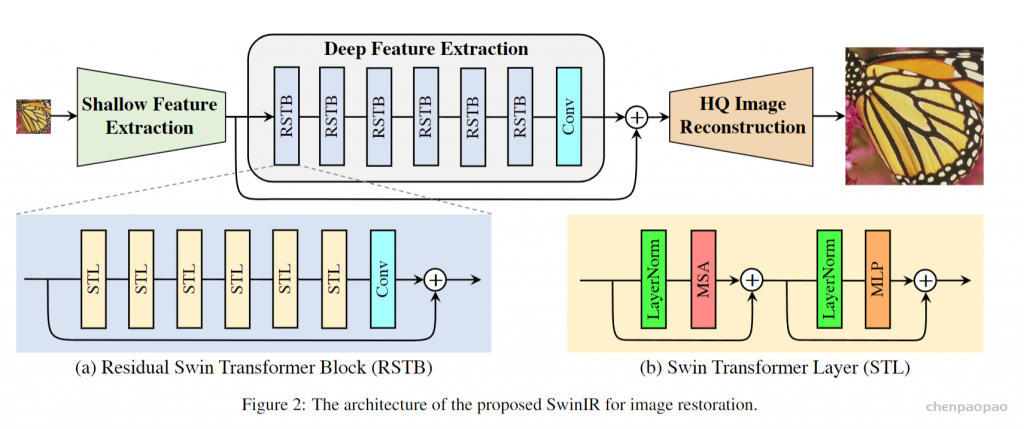
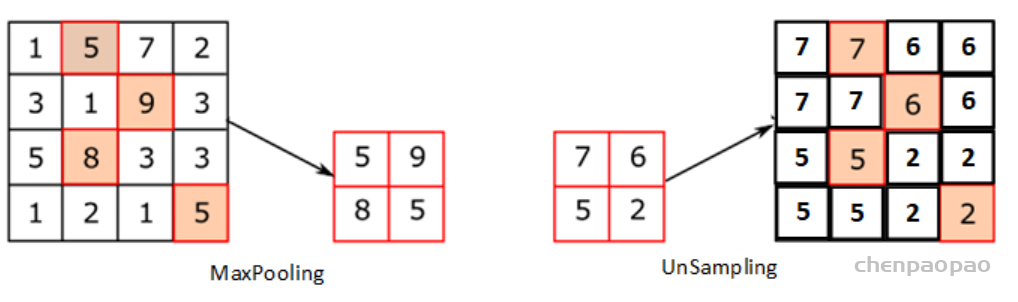
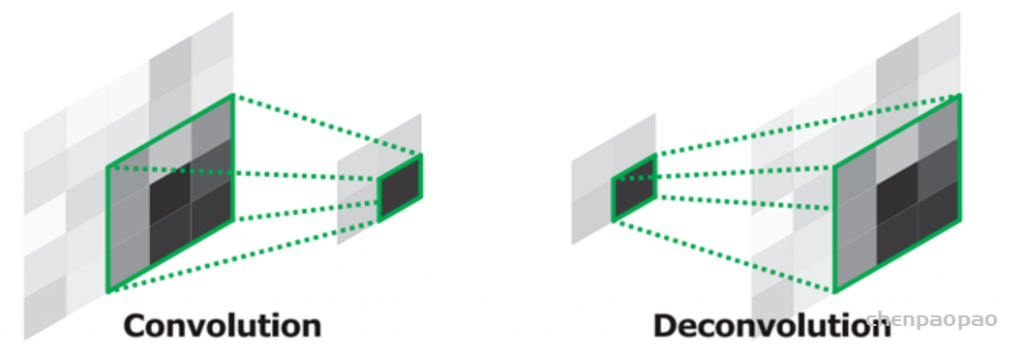
自从全卷积网络(Fully Convolutional Networks, FCN)和UNet提出以来,主流的改进思路是围绕着编解码结构来进行的。但又一些改进在当时看来却不是那么“主流”,其中有一些是针对如何提升网络的全局信息提取能力来进行改进的。FCN提出之后,一些学者认为FCN忽略了图像作为整张图的全局信息,因而在一些应用场景下不能有效利用图像的语义上下文信息。图像全局信息除了增加对图像的整体理解之外,还有助于模型对局部图像块的判断,此前一种主流的方法是将概率图模型融入到CNN训练中,用于捕捉图像像素的上下文信息,比如说给模型加条件随机场(Conditional Random Field,CRF),但这种方式会使得模型难以训练并且变得低效。
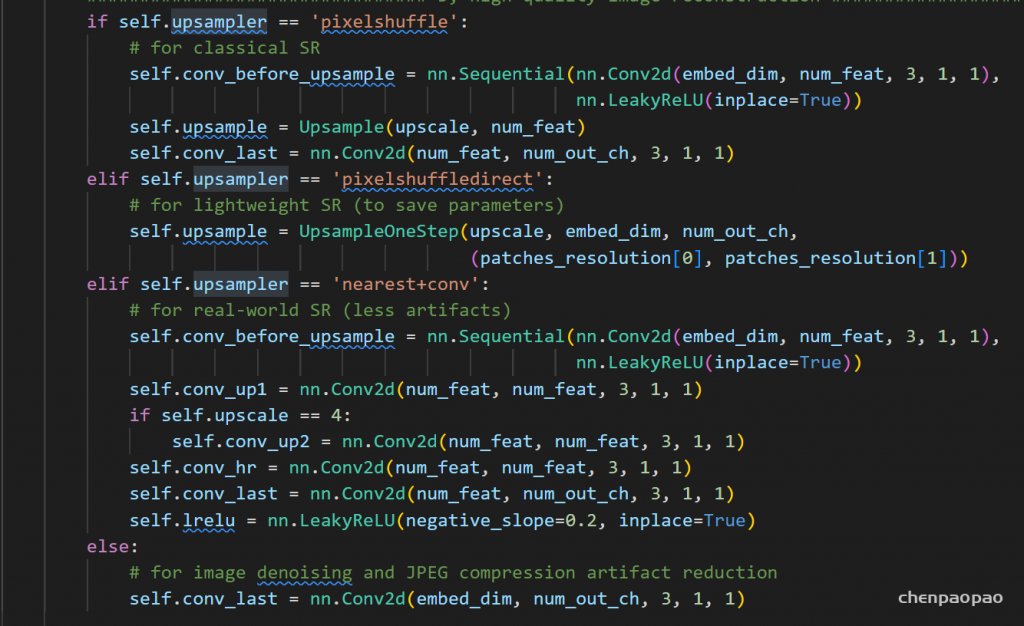
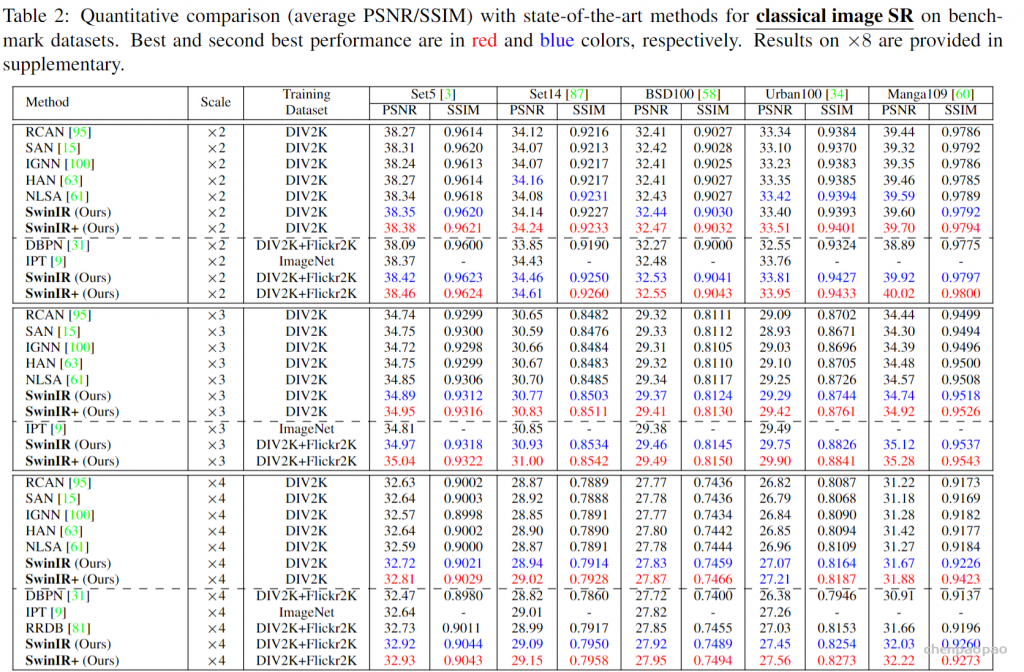
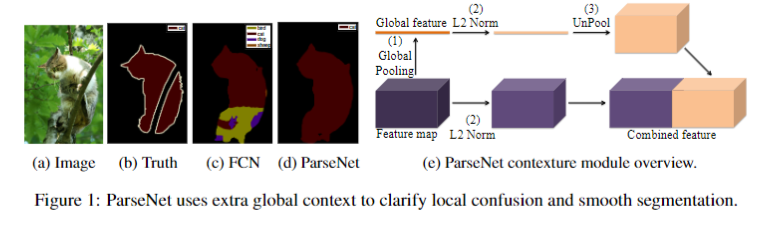
针对如何高效利用图像的全局信息问题,相关研究在FCN结构的基础上提出了ParseNet,一种高效的端到端的语义分割网络,旨在利用全局信息来指导局部信息判断,并且引入太多的额外计算开销。提出ParseNet的论文为ParseNet: Looking Wider to See Better,发表于2015年,是在FCN基础上基于上下文视角的一个改进设计。在语义分割中,上下文信息对于提升模型表现非常关键,在仅有局部信息情况下,像素的分类判断有时候会变得模棱两可。尽管理论上深层卷积层的会有非常大的感受野,但在实际中有效感受野却小很多,不足以捕捉图像的全局信息。ParseNet通过全局平均池化的方法在FCN基础上直接获取上下文信息,图1为ParseNet的上下文提取模块,具体地,使用全局平均池化对上下文特征图进行池化后得到全局特征,然后对全局特征进行L2规范化处理,再对规范化后的特征图反池化后与局部特征图进行融合,这样的一个简单结构对于语义分割质量的提升的巨大的。如图2所示,ParseNet能够关注到图像中的全局信息,保证图像分割的完整性。
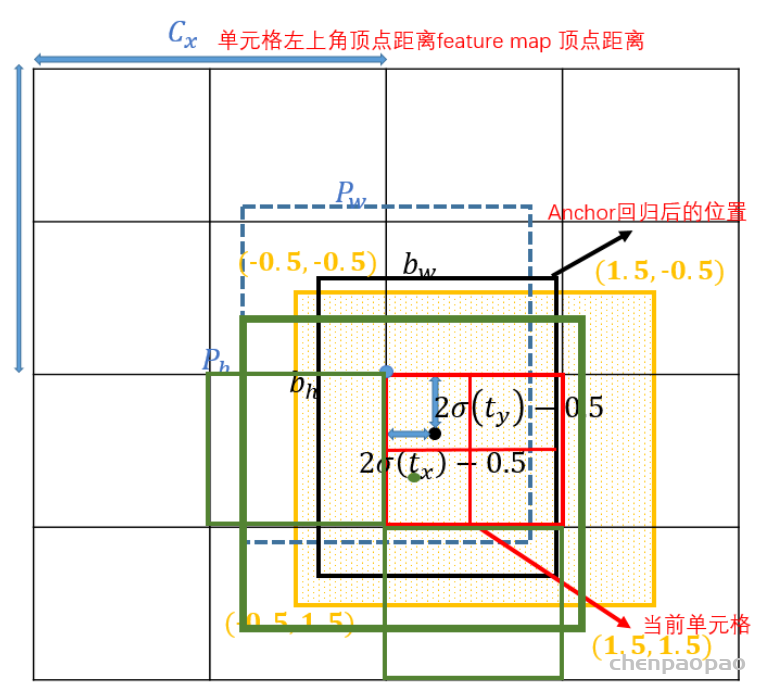
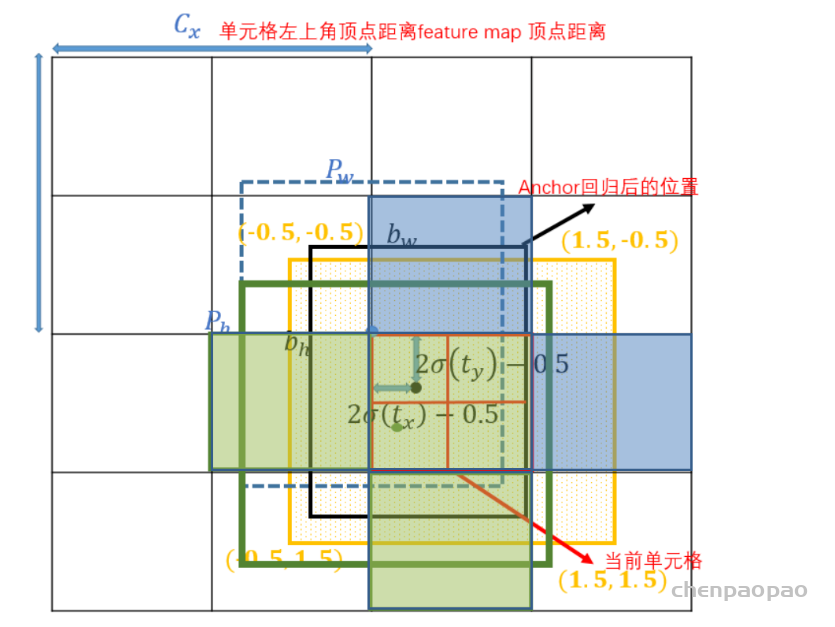
Yolov5基于anchor based,在开始训练前,会基于训练集中gt(ground truth 框),通过k-means聚类算法,先验获得9个从小到大排列的anchor框。先将每个gt与9个anchor匹配(以前是IOU匹配,Yolov5中变成shape匹配,计算gt与9个anchor的长宽比,如果长宽比小于设定阈值,说明该gt和对应的anchor匹配),