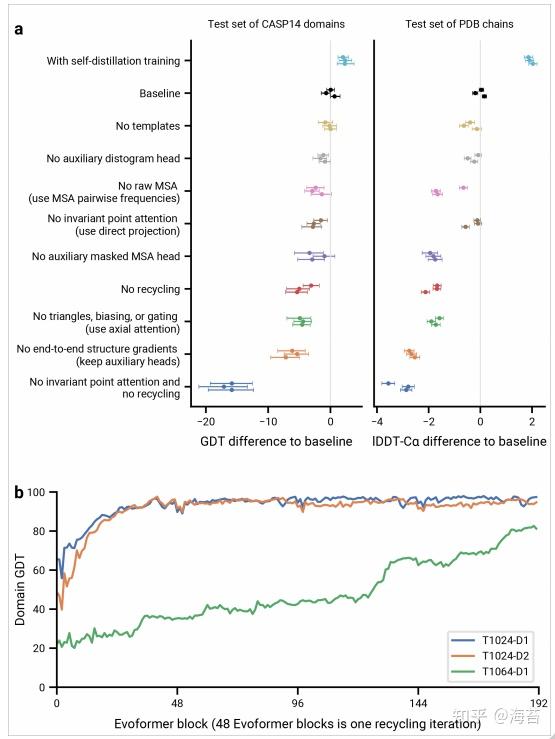
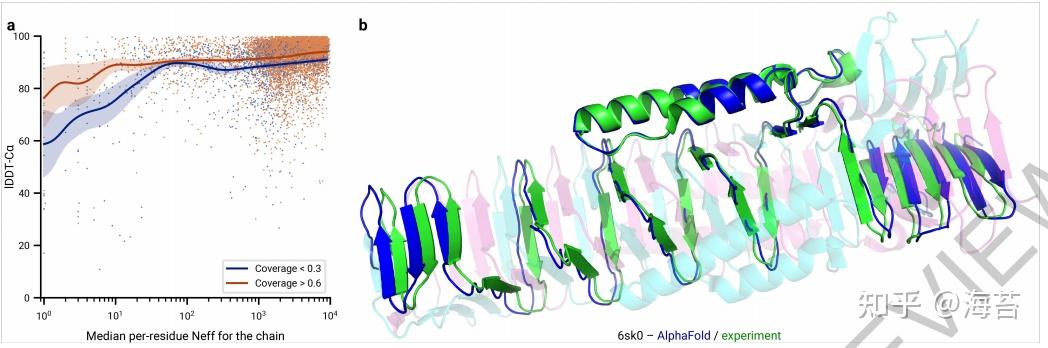
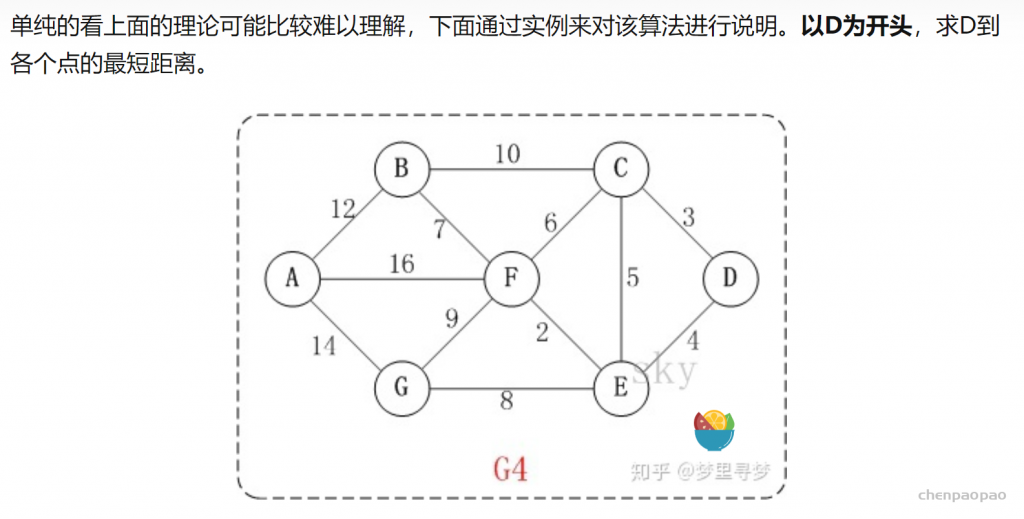
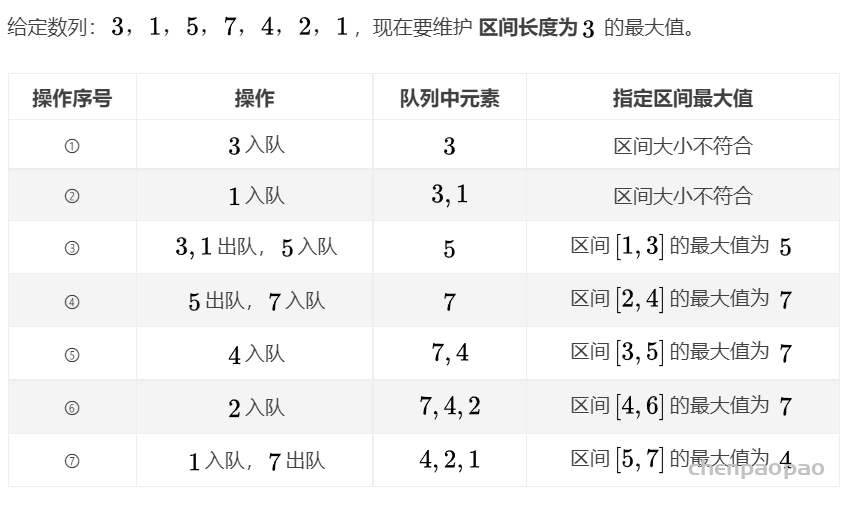
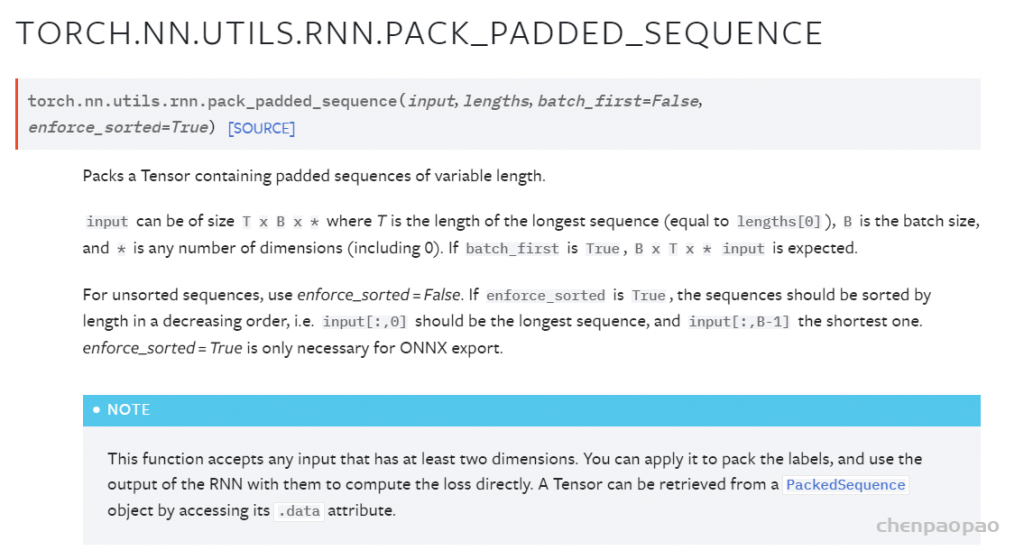
Bellman-ford 算法比dijkstra算法更具普遍性,因为它对边没有要求,可以处理负权边与负权回路。缺点是时间复杂度过高,高达O(VE), V为顶点数,E为边数。
特点:支持有环,负权重,但不能存在负权重环。
其主要思想:对所有的边进行n-1轮松弛操作,因为在一个含有n个顶点的图中,任意两点之间的最短路径最多包含n-1边。换句话说,第1轮在对所有的边进行松弛后,得到的是源点最多经过一条边到达其他顶点的最短距离;第2轮在对所有的边进行松弛后,得到的是源点最多经过两条边到达其他顶点的最短距离;第3轮在对所有的边进行松弛后,得到的是源点最多经过一条边到达其他顶点的最短距离……
Bellman-Ford 算法描述:
- 创建源顶点 v 到图中所有顶点的距离的集合 distSet,为图中的所有顶点指定一个距离值,初始均为 Infinite,源顶点距离为 0;
- 计算最短路径,执行 V – 1 次遍历;
- 对于图中的每条边:如果起点 u 的距离 d 加上边的权值 w 小于终点 v 的距离 d,则更新终点 v 的距离值 d;
- 检测图中是否有负权边形成了环,遍历图中的所有边,计算 u 至 v 的距离,如果对于 v 存在更小的距离,则说明存在环;
for (var i = 0; i < n - 1; i++) {
for (var j = 0; j < m; j++) {//对m条边进行循环
var edge = edges[j];
// 松弛操作
if (distance[edge.to] > distance[edge.from] + edge.weight ){
distance[edge.to] = distance[edge.from] + edge.weight;
}
}
}其中, n为顶点的个数,m为边的个数,edges数组储存了所有边,distance数组是源点到所有点的距离估计值,循环结束后就是最小值。
算法过程:首先初始化,对所有的节点V来说,所有的边E进行松弛操作,再然后循环遍历每条边,如果d[v] > d[u] + w(u,v),表示有一个负权重的环路存在。
最后如果没有负权重环路,那么d[v] 是最小路径值。
python 实现:
def bellman_ford(graph, source):
dist = {}
p = {}
max = 10000
for v in graph:
dist[v] = max #赋值为负无穷完成初始化
p[v] = None
dist[source] = 0
for i in range(len( graph ) - 1):
for u in graph:
for v in graph[u]:
if dist[v] > graph[u][v] + dist[u]:
dist[v] = graph[u][v] + dist[u]
p[v] = u #完成松弛操作,p为前驱节点
for u in graph:
for v in graph[u]:
if dist[v] > dist[u] + graph[u][v]:
return None, None #判断是否存在环路
return dist, p
def test():
graph = {
'a': {'b': -1, 'c': 4},
'b': {'c': 2, 'd': 3, 'e': 2},
'c': {},
'd': {'b': 3, 'c': 5},
'e': {'d': -3}
}
dist, p = bellman_ford(graph, 'a')
print(dist)
print(p)
def testfail():
graph = {
'a': {'b': -1, 'c': 4},
'b': {'c': 2, 'd': 3, 'e': 2},
'c': {'d': -5},
'd': {'b': 3},
'e': {'d': -3}
}
dist, p = bellman_ford(graph, 'a')
print(dist)
print(p)
test()
testfail()