
A Family of High-Quality Versatile Speech Generation Models [字节跳动]
https://bytedancespeech.github.io/seedtts_tech_report/
Seed-TTS,一个大规模的自回归文本到语音(TTS)模型家族,能够生成与人类语音几乎不可区分的语音。Seed-TTS是语音生成的基础模型,具有良好的语音上下文学习能力,在说话人相似度和自然度方面的性能在客观和主观评价上都与真实人类语音相匹配。通过微调,我们在这些指标上获得了更高的主观分数。Seed-TTS提供了对各种语音属性(如情感)的上级可控性,并且能够为现实中的说话者生成高度表达性和多样化的语音。此外,我们提出了一种自蒸馏方法的语音分解,以及强化学习方法,以提高模型的鲁棒性、说话人相似性和可控性。 我们还提出了一个非自回归(NAR)的 Seed TTS模型的变体,命名为 Seed -TTSDiT,它利用了一个完全基于扩散的架构。与以前的基于NAR的TTS系统不同,Seed-TTSDiT不依赖于预先估计的音素持续时间,并且通过端到端处理来执行语音生成。我们证明了这种变体在客观和主观评价中与基于语言模型的变体具有可比性,并展示了其在语音编辑中的有效性。
主要贡献如下:
1、Seed-TTS,这是一系列语音生成模型,能够生成高度表达性的类人语音。我们证明, Seed- TTS实现SOTA的性能在多个评估数据集。在zero-shot speech in-context learning (ICL)设置下,我们表明Seed-TTS能够生成与人类语音难以区分的鲁棒、相似和高度动态的语音。
2、提出了一种新的用于音色解耦的Seed-TTS自蒸馏扩展,并在语音转换任务中验证了SOTA的性能。
3、针对Seed-TTS模型,提出了一种新的基于RL的训练后扩展方法,从整体上提高了模型的性能。
Seed-TTS主要功能:
- 高质量语音生成: Seed-TTS采用了先进的自回归模型和声学声码器技术、能够生成接近人类自然语音的高质量语音。模型在大量数据上进行训练,学习到丰富的语音特征和语言模式,从而能够合成清晰、流畅、自然的语音输出
- 上下文学习: 该模型具备出色的上下文学习能力,可以在理解给定文本的上下文基础上、生成与上下文风格和语义相匹配的语音。无论是连续的对话还是单独的句子,Seed-TTS都能够保持语音的连贯性和一致性。
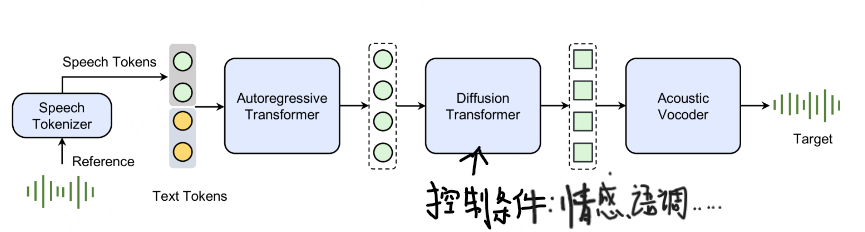
- 情感控制:Seed-TTS能够根据文本内容或额外的情感标签,控制生成语音的情感色彩。用户可以指定语音中应表达的情感,如愤怒、快乐、悲伤或惊讶等,模型会相应地调整语音的音调、强度和节奏,以匹配所选情感 【比如:把情感标签加入text token 或者 作为扩散模型的条件输入】
- 语音属性可控:除了情感,Seed-TTS还允许用户控制其他语音属性,包括语调、节奏和说话风格。用户可以根据应用场景的需求,调整语音使其更正式或非正式 或者更具戏剧化效果【比如:其他语音属性加入text token 或者 作为扩散模型的条件输入】
- 零样本学习能力(Zero-shot Learnina):即使没有特定说话者的训练数据,SeedTTS也能够利用其在大量数据上训练得到的泛化能力,生成高质量的语音。此能力使得Seed-TTS能够快速适应新的说话者或语言,而无需额外的训练过程
- 语音编辑:Seed-TTS支持对生成的语音进行编辑,包括内容编辑和说话速度编辑。用户可以根据需要修改语音中的特定部分,或调整语速以适应不同的听众或应用场景。
- 多语种支持:模型设计支持多种语言的文本输入、能够生成相应语言的语音,使得Seed-TTS可以服务于全球化的应用,满足不同语言用户的需求
- 语音分解:Seed-TTS通过自我蒸馏方法实现了语音的属性分解。例如可以将语音的音色与其他属性(如内容和情感)分离,为语音合成提供了更高的灵活性和控制力,允许用户独立地修改和重组语音的不同组成部分。
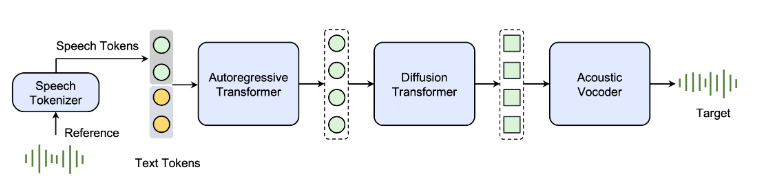
Seed-TTS 是一种基于自回归 Transformer 模型,如图 1 所示。我们的系统由四个主要构建模块组成:语音分词器、分词语言模型、分词扩散模型和声学声码器。我们强调,Seed-TTS 在大量数据上进行训练(数据量级比之前最大的 TTS 系统大得多),以实现强大的泛化能力和新兴能力。
Seed-TTS方法:
Seed-TTS是基于自回归transformer-based(LLaMA:decoder only)的模型,如图1所示。我们的系统由四个主要的构建块:一个语音tokenizer,一个token语言模型,一个token扩散模型,和一个声学声码器。我们强调,Seed-TTS是在大量数据(比以前最大的TTS系统大的数量级)上训练的,以实现强大的泛化和涌现能力。
首先,语音标记器将语音信号转换为一系列语音标记,然后使用类似于 BASE TTS所描述的方法对标记语言模型进行训练。我们研究了连续和离散语音标记器,发现标记器的设计对整个系统的性能至关重要。语言模型是在成对的文本序列和语音标记上训练的。在推理过程中,模型自回归地生成语音标记。请注意,在本技术报告中,我们专注于语音生成任务,因此文本序列的损失是被掩蔽的。这些生成的标记随后由扩散模型处理,以增强声学细节。然后输出通过声学声码器处理,以预测最终的波形。
具体流程如下: 首先语音tokenizer将语音信号转换为语音token序列,在该语音token序列上训练token语言模型,我们研究了连续和离散语音token器,发现 tokenizer 的设计对整个系统的性能至关重要。语言模型在文本和语音token的配对序列上训练。在推理过程中,它自回归地生成语音token。这些生成的令牌,然后用扩散模型进行处理,以增强声学细节。输出被传递到声学声码器以预测最终波形。 声学声码器使用类似于Kumar等人【High-Fidelity Audio Compression with Improved RVQGAN】,并单独进行训练。
与基于文本的语言模型类似,Seed-TTS经历三个训练阶段:预训练,微调和后训练。预训练阶段的目标是最大限度地提高场景和说话人的覆盖率,同时为通用语音建模建立一个强大的骨干。如前所述,在该阶段,Seed-TTS利用了比先前的语音生成模型大数量级的大量训练数据和模型规模。
微调阶段包括说话人微调和指令微调。说话人微调的重点是提高选定说话人组的表现,而指令微调的目的是提高可控性和交互性。后期训练通过RL进行,从整体上改进了模型。
我们观察到 Seed-TTS 模型相较于之前的模型有两个主要优势。首先,Seed-TTS 在不同场景下(包括如喊叫、哭泣或高度情感化的语音等具有挑战性的情境)展示了出色的语音合成自然度和表现力。在开发过程中,我们在被认为对于以前的 TTS 系统难以或无法处理的情境中对模型进行了严格测试,结果显示其相对于之前的最先进系统具有明显的优势。
其次,Seed-TTS解决了基于语言模型的TTS系统中普遍存在的稳定性问题,这些问题阻碍了它们在现实世界中的部署。稳定性是通过token和模型设计改进、增强的训练和推理策略、数据扩充和训练后强化学习的组合来实现的。因此,Seed-TTS在测试集上实现了显著更好的鲁棒性。
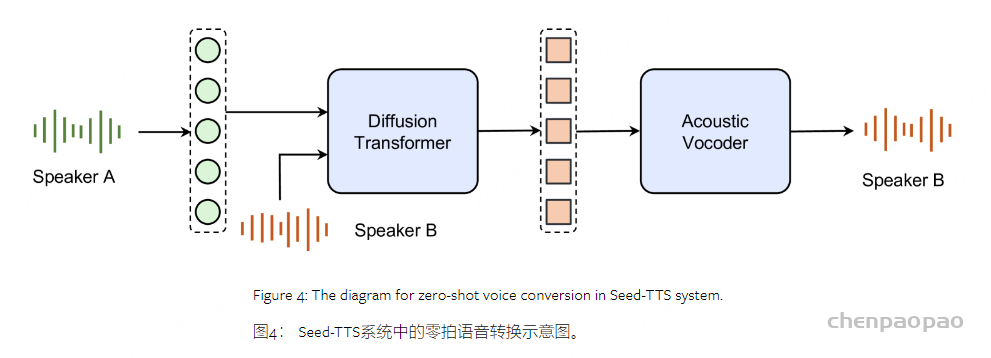
作为语音生成的基础模型,Seed-TTS可以执行各种任务,例如语音ICL【 zero-shot voice continuation】,可控TTS,跨语言TTS,语音转换,音色生成和说话风格转换。
ICL(上下文学习)结果,也称为零样本语音延续。ICL 被定义为生成一个具有与短参考语音片段相同音色和韵律的全新口语表达。这些 ICL 结果是通过使用预训练的 Seed-TTS 模型对音频和文本提示进行延续而获得的。
Experiments
Zero-shot in-context learning
采用了词错误率(WER)和说话人相似度(SIM)指标进行客观评价。我们确保每个样本包含同一说话人说出的一个参考话语和一个目标话语。所提出的Seed-TTS系统用于基于参考语音生成目标文本的语音作为音频提示。通过这种方式,我们可以直接将合成语音与来自真实的人类的地面真实语音进行比较。参考发音的持续时间范围从3到20秒。
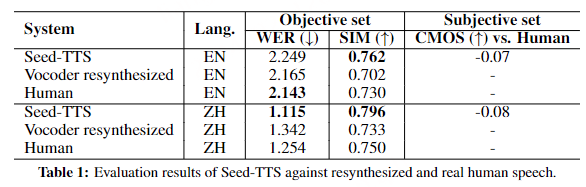
值得注意的是,较低的WER不一定会导致说话者相似性的主观分数提高。我们凭经验观察到,较低的WER通常表明该模型产生更“标准化”的语音,这更容易被ASR系统识别,但以牺牲其他期望的质量为代价。例如,在提示语音包含强口音或高表达力的情况下,从生成的语音获得较低的WER通常指示在模型的输出空间中具有有限变化的较不带口音的语音,这可能听起来不太自然并且当在主观评估中测量时具有降低的说话者相似性。
言语理解评估:
我们通过在生成的语音上训练ASR模型来进一步验证Seed-TTS的生成质量。为此,我们生成了LibriSpeech 960小时训练集的合成版本通过“文本波洗牌”策略,并使用合成语料库从头开始训练ASR模型,然后我们使用该模型在原始LibriSpeech开发和测试集上转录语音。具体地说,我们通过采用训练集中的每个话语作为音频提示来生成训练集中的每个话语的合成版本,以使用来自训练集中的随机采样的文本来合成新句子,同时确保所有话语和文本仅被采样一次。通过这种方式,我们创建了一个合成LibriSpeech训练语料库,该语料库保持与原始语料库相同的总说话者和内容信息,以使用WeNet工具包。我们采用了12层挤压成形器作为ASR编码器和3层双向Transformer作为ASR解码器。ASR基线模型也在原始LibriSpeech训练语料库上训练。所有模型均使用相同的超参数进行训练,例如:每个模型都在LibriSpeech开发和测试集上进行了测试,结果如表2所示。

对于干净集,即,dev_clean和test_clean,使用合成数据训练的模型实现了与使用真实的数据训练的模型非常相似的ASR性能。在有噪声的dev_other和test_other集合上分别观察到1.81%和1.6%的绝对WER下降,我们推测这是由于Seed-TTS在生成过程中倾向于减少背景噪声,从而导致对噪声的鲁棒性降低。这一结果表明,在语音理解模型的开发中使用合成数据的潜力,这进一步推动了语音理解和生成的统一。
说话人相似性分析:
为了验证合成语音中音色的保真度,我们使用与上述相同的混排方法生成了 VoxCeleb1 测试集中的英语语句,并使用基于 WavLM 的说话人验证模型获取了它们的说话人嵌入。我们在图 3 中使用 t-SNE绘制了 25 位说话人真实语音和合成语音的说话人嵌入分布图。
我们观察到,同一说话者的真实语音和合成语音的嵌入可靠地聚集在一起,这表明 Seed-TTS 生成的语音在质量和说话者相似性方面与真实人类语音非常接近。

说话人微调
我们在 Seed-TTS 预训练模型的基础上进行了说话人微调(SFT)。在该实验中,我们选择了 5 位说话者(3 位女性和 2 位男性),每位说话者的语音数据时长在 1 到 10 小时之间。我们使用这些说话者的总计 20 小时的合并数据对 Seed-TTS 进行微调,并引入了一个额外的说话人索引标记,用于在推理时选择目标说话者的音色。对于这些选定的说话者,我们使用 WER(词错误率)和 SIM(相似度)客观指标以及主观 CMOS(主观质量评分)研究,评估了微调模型(Seed-TTS SFT)与基础预训练模型(Seed-TTS ICL)生成的语音效果。对于基础模型,每位说话者使用了随机采样的 20 秒语音片段作为音频提示。说话人微调实验的结果在表 3 中进行了汇报。

通过指令微调实现可控性
为了进一步增强说话人微调模型的可控性,我们尝试集成了额外的指令微调(IFT)。IFT 使模型能够灵活控制生成语音的各个方面,例如表现力、语速、风格、情感等。在本报告中,我们仅以情感控制为示例进行展示。
为了验证情感可控性,我们训练了一个类似于Chen等人的语音情感识别(SER)模型,选择了四个主要情感(即,愤怒、高兴、悲伤和惊讶),并测量了从合成语音预测情绪的准确性。我们为每种情绪生成并评估了100个话语,其中合成文本的主题被设计为与目标情绪相匹配。
结果总结于表4中。我们发现,即使没有一个明确的控制信号, Seed-TTSSFT 仍然获得了中等精度的情绪控制。我们推测这是因为该模型能够根据所提供的文本内容推断出适当的目标情感。当与附加的控制信号结合时,获得了显著提高的精度。

低延迟推理和流处理
TTS模型在实际应用中的部署从多个角度提出了一些实际挑战。例如,在基于聊天的应用中,等待时间和第一分组延迟对于用户体验是必不可少的。在时间和内存上的计算开销对于服务并发性是至关重要的。与传统TTS型号相比,Seed-TTS采用了明显更大的型号尺寸,为部署带来了额外的障碍。为了解决这些挑战,我们采用了各种技术来降低推理成本和延迟。
具体地说,我们解决了模型部署的三个方面。首先,实现了一种因果扩散结构,该结构使流处理能够在扩散模块中进行,并显著降低了处理延迟和首包延迟。 其次,我们采用稠度蒸馏(Song 等人,2023)和改进的流量匹配算法Esser 等人(2024),以降低扩散模型的计算成本。另一方面,我们研究了在语言模型侧减少内存和计算消耗的常用方法。

模型扩展
我们进一步提出了两个扩展的TTS模型,以提高其性能和扩大其适用性。首先,我们介绍了一种自蒸馏的方法,旨在增加音色的可控性。随后,我们提出使用强化学习来全面提高模型的能力。
自蒸馏的语音分解:
语音分解是指将语音分解为各种独立的、分离的属性的过程。该功能允许TTS系统灵活地合成来自不同说话者的具有不同音色、韵律和内容组合的语音,这对于零样本语音转换和因子化零样本TTS等应用至关重要。大多数现有方法通过特征工程特定损失函数或精确的网络架构调整实现属性解耦。然而,将这些方法集成到像Seed-TTS这样的通用语音生成系统中可能具有挑战性。
我们提出了一个自蒸馏方案来实现属性解耦。这种方法的核心原理是创建受控语音对,这些语音对共享大多数信息,但在一个或几个特定的目标属性上有所不同。利用这样的数据对,沿着对模型架构的微小更新,使得Seed-TTS模型能够实现高质量的属性解耦。鉴于Seed-TTS可以为几乎任何说话者生成高质量的零样本生成,生成这些具有不同目标属性的数据对是简单的。在这份报告中,我们特别强调了音色分解的过程和结果。
我们注意到,在Seed-TTS生成过程中,通过在扩散模块中引入说话人扰动,我们能够获得具有相同内容和韵律模式但音色发生变化的合成语音。我们将原始句子和音色改变的句子分别表示为 Sori 和 Salt 。
我们使用这些增强的合成数据对重新训练Seed-TTS系统中的扩散模型。具体地,在训练期间,从 Salt 提取的令牌被用作网络的输入。从 Sori 提取的音色参考也被集成为扩散输入的一部分。 该网络被优化以恢复从 Sori 中提取的声码器嵌入。值得注意的是, Salt 和 Sori 共享相同的内容和韵律,但音色不同。为了恢复 Sori ,网络必须忽略嵌入在来自 Salt 的令牌序列中的音色,并且仅依赖于所提供的音色嵌入。这种方法允许我们使用额外的音色参考来修改音色,同时保留原始内容和韵律。我们发现这种直接的方法使得Seed-TTS系统能够实现高质量的音色解缠结。
通过强化学习的偏好偏向
RL已被证明是文本和图像处理中的有效学习范例。我们比较了使用外部奖励模型的RL方法,如近端策略优化和REINFORCE,以及不使用外部奖励模型的RL方法,如DPO。我们的研究结果表明,这两种方法都是有效的。前者允许对特定语音属性进行清晰的控制,而后者受益于更简单的实现。在本报告中,我们展示了前一种方法的有效性。
具体来说,我们使用REINFORCE来微调两个版本,这两个版本基于原始的零触发ICL模型( Seed-TTSICL ),使用不同的奖励函数: Seed-TTSRL-SIM-WER ,使用SIM和WER客观指标作为奖励,以提高说话人相似性和鲁棒性, Seed-TTSRL-SER ,使用SER模型的准确性作为奖励,以提高情感可控性。
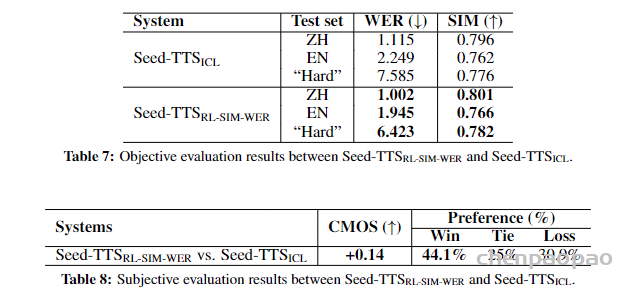
完全基于扩散的语音生成【去除token语言模型】
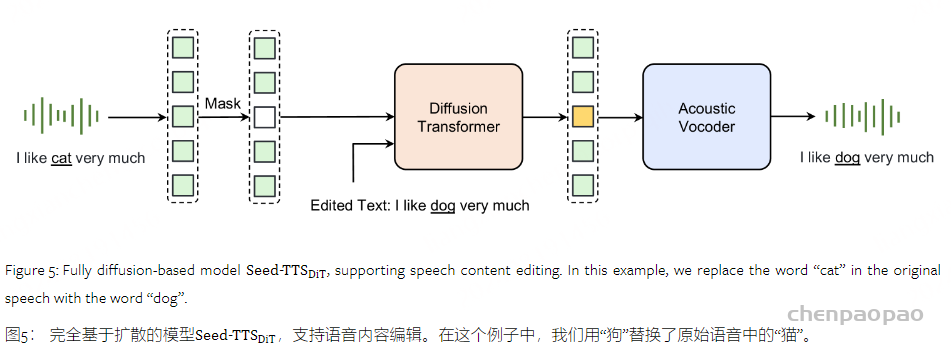
提出了一种仅基于扩散的Seed-TTS模型的变体,表示为 Seed-TTSDiT 。在该变型中,我们去除了扩散模型和声学表征器【acoustic tokenizer】之间的依赖性,使得扩散模型直接将高斯噪声转换成纯粹基于输入文本的声码器的潜在表示。
在我们修改后的 Seed-TTSDiT 设计中,我们直接在扩散模型中采用端到端处理。与估计音素级持续时间相反,该模型预先估计生成的语音的总持续时间。然后优化该模型以估计音频和文本之间的局部对齐。通过这种方式, Seed-TTSDiT 可以动态调整每个音素的持续时间,从而产生高度自然的语音。
我们发现 Seed-TTSDiT 在正确训练时能够预测输入语音的适当总持续时间。然而,不是以这种方式训练,而是选择直接向模型提供总持续时间,这实现了可用于内容编辑和语速编辑的若干附加的期望属性。为此,在训练过程中,扩散模型接收音频提示、目标文本以及一段高斯噪声的片段,所有样本的总时长都相同。模型预测生成语音的潜在表示,保持相同的总时长,然后通过声码器转换成波形。
与采用生成下一个token语言建模的方法相比,纯扩散模型具有更简单的流水线。作为非流模型, Seed-TTSDiT 自然支持内容编辑的应用。在内容编辑任务中,我们屏蔽了一定比例的音频,并使用模型根据每个测试样本提供的文本恢复被屏蔽的部分。
模型应用、局限性和安全性
尽管Seed-TTS具有这些功能,但它仍有一些局限性。虽然观察到了紧急行为,但该模型有时在需要细致入微的情感和上下文理解的场景中存在局限性。此外,尽管使用大量数据进行了训练,但场景覆盖率仍有改进的空间。例如,当前的Seed-TTS模型在唱歌或给出包含背景音乐或过度噪音的提示时表现不佳,通常会产生不一致的背景,例如完全忽略音乐。
考虑到滥用可能会造成有害的社会影响,我们在相关产品中实施了多项安全程序,以防止在该模型的开发和潜在部署过程中发生滥用。例如,我们开发了一种针对语音内容和扬声器音色的多步验证方法,以确保注册音频仅包含授权用户的语音。此外,我们实现了一个多层次的水印方案,这是强制性地包括在创建的内容,如视频背景水印和内容描述中的水印的各个层次。