Zero-Shot TTS目前有不少工作用了MEL谱作为中间特征,然后在梅尔谱的基础上,或是用VQ提供离散token,或是用CNN来提取连续latent。对于MEL+latents的工作,有:AudioLDM 1&2、StyleTTS 1&2。我们来简单看看是它们是怎么做的。
AudioLDM 1&2
AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
[Paper on ArXiv][Code on GitHub][Hugging Face Space]
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
[Paper on ArXiv][Code on GitHub][HuggingFace Demo][Discord Community]
AudioLDM 1&2使用的语音latents是一致的,均通过MEL+VAE获得。既然是连续的latents,使用扩散模型来建模也合情合理。解码过程也相当简单:VAE decoder获得梅尔谱,然后用声码器转换为音频波形。该系列工作的核心创新点是利用多模态模型统一了扩散模型条件输入侧的信息:AudioLDM 1用CLAP统一了文本模态和音频模态,用单模态的音频数据就能完成模型的训练;AudioLDM 2则包含了图像、文本、转录文本等更多模态,模型泛用性也更强,既能做语音合成,也能做音乐生成、音频事件生成。
StyleTTS 1&2
StyleTTS: A Style-Based Generative Model for Natural and Diverse Text-to-Speech Synthesis
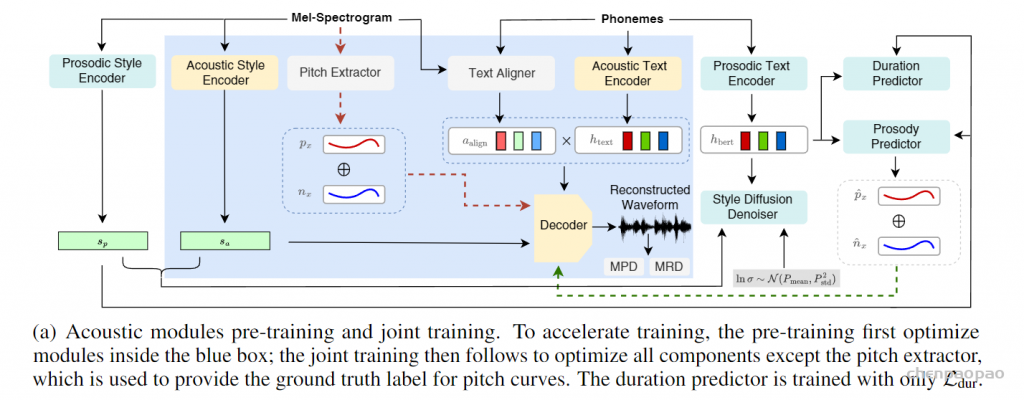
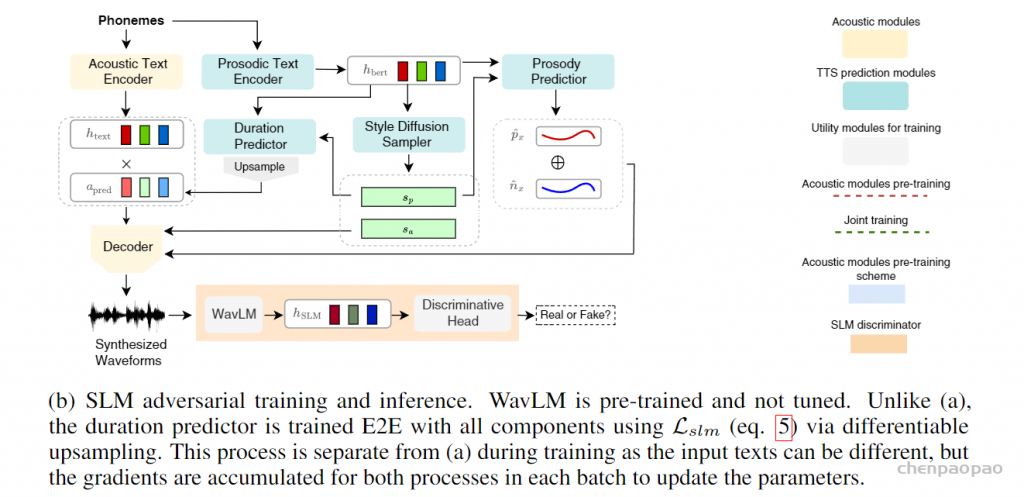
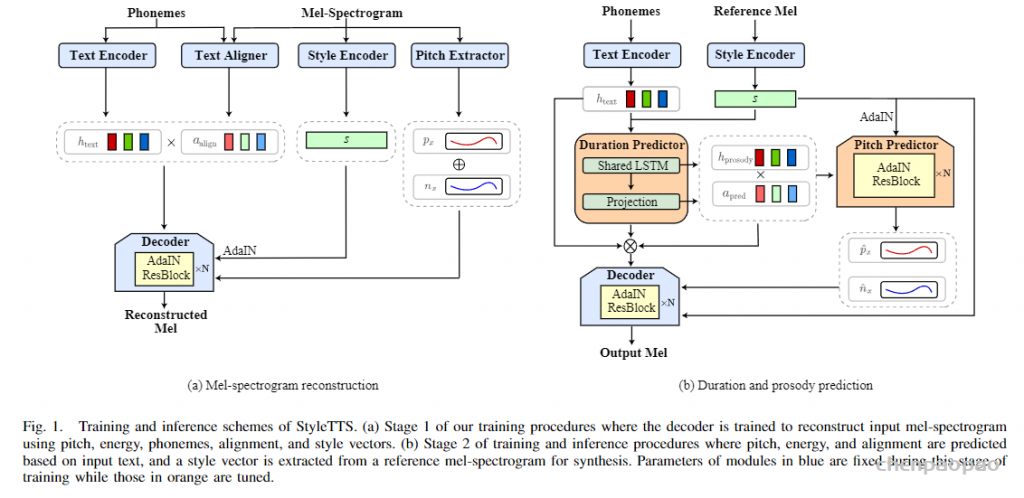
StyleTTS系列的模型一众zero-shot TTS模型显得比较老派,整体结构基本上沿袭了非自回归的FastSpeech 2,不同之处在于增加了基于参考音频抽取的风格信息。说是风格,其实跟megatts的音色很像。StyleTTS 2的工作则将风格进一步拆分成声学风格和韵律风格。训练时的风格信息由音频提供,推断时的风格信息则由扩散模型提供。StyleTTS 2通过一个扩散模型桥接了文本韵律和语音风格之间的联系,摆脱推断时对参考音频的依赖。不用参考音频其实对产品的意义还挺大的,要都用现实世界中真人尤其是名人的声音作为参考音频,那这势必会引起版权纠纷。这种纠纷在国内国外都有相关的事件。最近寡姐投诉OpenAI的事件就是一例。
在 StyleTTS 中,我们提出了“全局风格迁移”(GST),这是一个在Tacotron(最先进的端到端语音合成系统)中联合训练的嵌入库。嵌入在没有明确标签的情况下进行训练,但学会了对大范围的声学表现力进行建模。商品及服务税会带来一系列丰富的重要结果。它们生成的软可解释“标签”可用于以新颖的方式控制合成,例如改变速度和说话风格 – 独立于文本内容。它们还可用于风格转换,在整个长格式文本语料库中复制单个音频剪辑的说话风格。当对嘈杂的、未标记的发现数据进行训练时,GST 学会分解噪声和说话人身份,为高度可扩展但强大的语音合成提供了一条途径。
StyleTTS 2的不同之处在于,通过扩散模型将风格建模为潜在随机变量,以生成最适合文本的风格,而无需参考语音,实现高效的潜在扩散,同时受益于扩散模型提供的多样化语音合成。 此外采用大型预训练SLM(如WavLM)作为鉴别器,并使用新颖的可微分持续时间建模进行端到端训练,从而提高了语音自然度。