
同步 LLMs 作为全双工对话代理
https://syncllm.cs.washington.edu/
尽管对语音对话代理进行建模有着广泛的兴趣,但大多数方法本质上都是 “半双工” 的 —— 仅限于回合制交互,响应需要用户明确提示或隐式跟踪中断或静音事件。相比之下,人类对话是“全双工”的,允许以快速和动态的轮流、重叠语音和反向通道的形式实现丰富的同步性。从技术上讲,使用 LLMs在于将同步建模为预训练的 LLMs 没有“时间”感。为了弥合这一差距,我们提出了用于全双工口语对话建模的同步 LLMs。我们设计了一种新颖的机制,将时间信息集成到 Llama3-8b 中,以便它们与现实世界的时钟同步运行。我们还介绍了一个训练方法,该方法使用从文本对话数据生成的 212k 小时的合成口语对话数据来创建一个模型,该模型仅使用 2k 小时的真实口语对话数据即可生成有意义且自然的口语对话。同步 LLMs 在保持自然性的同时,在对话意义方面优于最先进的。最后,我们通过模拟在不同数据集上训练的两个代理之间的交互,同时考虑高达 240 毫秒的 Internet 规模延迟,展示了该模型参与全双工对话的能力。
Latency tolerant interaction
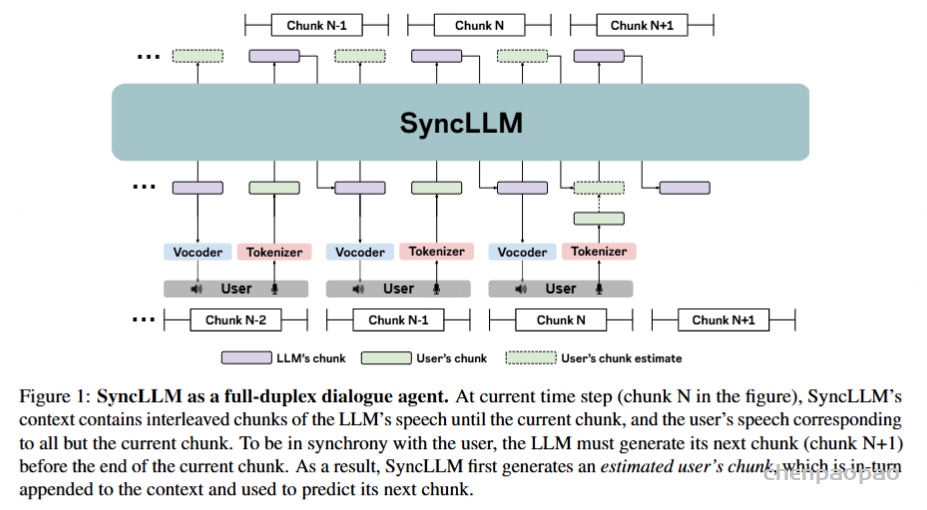
SyncLLM 是一种仅限自回归解码器的 transformer 模型,可以用作全双工对话代理。在下图中,在当前时间步(图中的 chunk N),SyncLLM 的上下文包含 LLM 的语音到当前 chunk 的交错块,以及对应于除当前 chunk 之外的所有 chunk 的用户语音。为了与用户同步,LLM 必须在当前 chunk 结束之前生成其下一个 chunk (chunk N+1)。因此,SyncLLM 首先生成估计用户的 chunk,该 chunk 又附加到上下文并用于预测其下一个 chunk。
SyncLLM 经过训练,可以预测对应于对话两侧的语音单元的交错块,如图 2 所示。1. 在每个时间步长中,模型预测与对话一侧的固定持续时间(称为模型的块大小)相对应的语音单位,然后是与对话的用户一侧相对应的语音单位。通过这种方法,该模型能够生成与真实时钟同步的两个语音流。这允许我们的方法对所有对话线索进行建模,例如反向通道、重叠、中断等。
Training
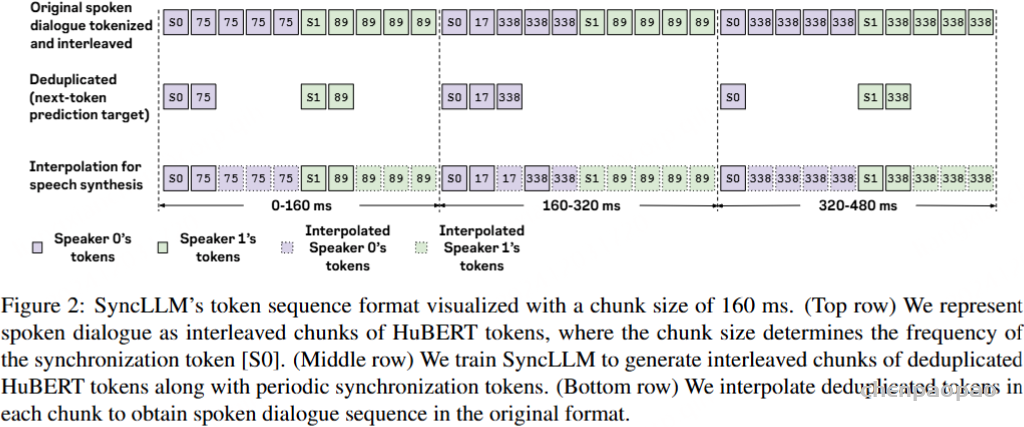
SyncLLM 使用简单的 next-token 预测目标进行训练,其中全双工口语对话的格式如下。(顶行)我们将语音对话表示为 HuBERT 令牌的交错块,其中块大小决定了同步令牌 [S0] 的频率。(中间行)我们训练 SyncLLM 生成去重 HuBERT 令牌的交错块以及定期同步令牌。(底行)我们在每个块中插入去重的标记,以获得原始格式的语音对话序列。
如果我们可以将两个令牌流中的一个替换为与真实用户相对应的令牌流,那么经过训练的模型可以用于全双工语音交互。在图 .1,紫色框对应于每个时间块中 LLM 侧对话的标记序列,绿色框对应于对话的用户侧。我们通过丢弃 LLM 用户语音交互。
HuBERT 令牌 :使用 HuBERT 来表示语音。我们使用 Nguyen 等 人的分词化参数,分词采样率为 25 Hz,每 40 毫秒音频产生一个分词,词汇量为 501。为了模拟两个说话人 0 和 1 之间的对话,我们定义了两个特殊的标记 [S0] 和 [S1],称为说话人标签,分别指定每个说话人的标记序列的开始。我们将对话表示为两个并行的语音流,每个说话人一个,交错,如上图 的顶行所示。对于每个流,我们嵌入一个周期性的 speaker 标签,其时间段等于模型的块大小。
重复数据删除。HuBERT 令牌的固定时间段对于在全双工对话中对时间进行建模很有用。然而,原始 HuBERT 序列由大量重复的标记组成,主要是由话语内和话语之间的沉默引起的。每个唯一标记的重复次数表示标记所表示的声学单元的持续时间。然而,语义内容可以通过在删除重复标记序列时仅考虑唯一标记来建模。重复的标记序列会对最终口语对话模型的语义能力产生不利影响 ,因为如上图 所示,与去重序列相比,它们每个标记的语义内容比去重后的序列低约50%。
插值。虽然去重的标记序列有利于自回归建模,但要生成适合语音合成的标记序列,我们需要原始格式的周期性 HuBERT 标记。由于 speaker 标签 [S0] 维护了计时信息,因此我们知道每个块中去重后删除的令牌数量。我们使用它来插入已删除重复数据的令牌,以匹配每个块中的预期令牌数量。例如,在 Fig.2,则说话人 0 的流在去重后只有一个 Token。但是由于在这种情况下,块大小为 160 毫秒,因此每个块将包含 160/40 = 4 个令牌。所以如图 3 日的第三行所示。2 中,我们重复 deed token 三次以重建 chunk。如果一个块有多个去重的令牌,如图 2 中的第二个 token。2,我们以相等的数量重复每个 Token。我们注意到这种方法可能会导致错误,因为原始 chunk 可能不遵循这种启发式方法。我们观察到,即使数据块大小为 240 毫秒,其影响也是难以察觉的,这可能是因为每个标记的预测持续时间的误差受到数据块大小的上限。此外,在具有更多新词元的 chunk 中,误差会更小。
采用三阶段训练,训练数据:
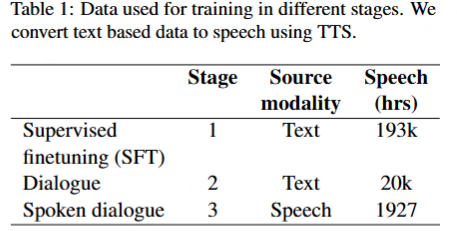
第 1 阶段:具有合成语音数据的回合制口语对话模型。 鉴于口语对话数据有限,我们从大规模文本对话数据集中生成合成语音数据。 我们使用监督式微调 (SFT) 数据集作为我们的源文本对话数据集。我们使用 Bark TTS AI (2023) 模型生成文本对话数据集的口语版本,其中包含 10 个说话人预设。
第 2 阶段:假设没有重叠的全双工对话。回合制语音对话是无重叠的全双工对话的特例。基于这一观察结果,我们可以将合成的语音对话数据视为全双工语音对话数据,其中轮到一个说话人时,另一个说话人完全沉默。在这个阶段,我们从文本对话数据创建合成的口语对话数据,与上一阶段类似,但有一个主要区别:从对话的每个回合中,我们生成一个对应于一个说话者的语音话语和对应于另一个说话者的等长沉默。然后,我们以图 2 第二行所示的格式对并行语音对话数据进行标记。2. 这样,我们可以进一步利用文本对话数据来帮助我们的模型学习图 1 中的标记序列格式。2. 此微调阶段对话语中的计时进行建模。该模型还无法学习轮流提示,例如反向信道或两个说话人之间的重叠。
第 3 阶段:使用真实世界的口语对话数据进行建模。最后,我们对模型进行微调,从现实世界的口语对话数据中学习轮流线索。我们使用 Fisher Cieri et al. (2004) 的数据集,其中包含 2000 小时的口语对话,其中对话中每个说话者的语音都被分成独立的音频通道。我们将数据集分别以 98:1:1 的比例分为 train、val 和 test split。对话中的每个音频声道都单独标记化,并以上一阶段使用的全双工对话格式交错。在此阶段,除了学习话语中的计时外,该模型还学习有效的轮流对话线索,例如在轮流和反向通道之间准确分配停顿。