
SNAC: Multi-Scale Neural Audio Codec
Github:https://github.com/hubertsiuzdak/snac
demo:https://hubertsiuzdak.github.io/snac/
语音对话大模型的应用:Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming,使用了snac作为audio decoding
残差矢量量化(RVQ)已成为使用级联 VQ 代码本进行神经音频压缩的标准技术。 本文提出了一种多尺度神经音频编解码器,它是 RVQ 的简单扩展,其中量化器可以在不同的时间分辨率下运行。 通过在可变帧率下应用量化器层次结构,编解码器适应了跨多个时间尺度的音频结构。 正如广泛的客观和主观评估所证明的那样,这将带来更有效的压缩。
SNAC(多尺度神经音频编解码器),是对当前音频残差量化方法的简单扩展,通过在不同的时间分辨率上引入量化来形成音频的多尺度离散表示。
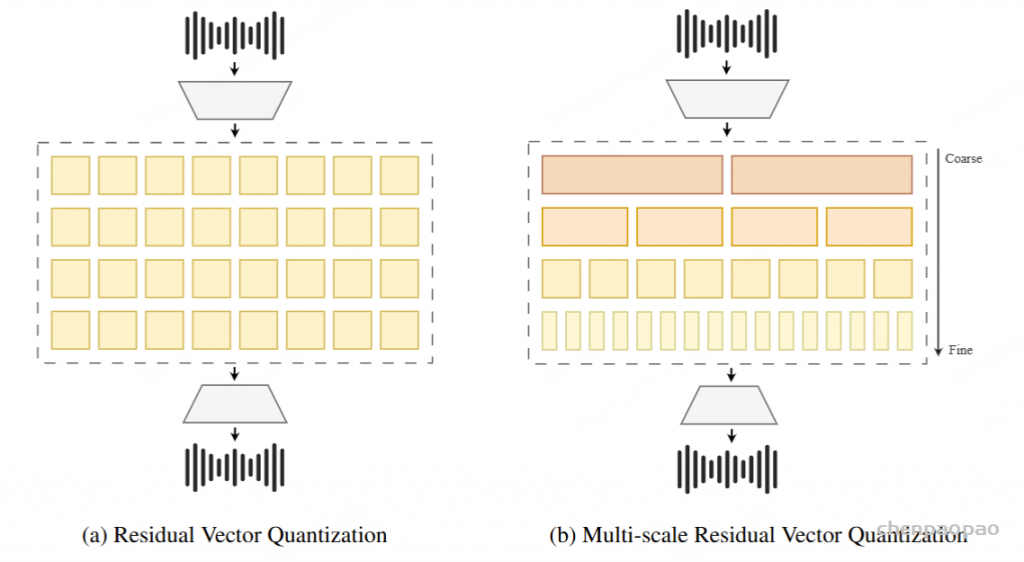

方法:
模型建立在 RVQGAN的基础上,这是一个具有残差向量量化 (RVQ) 瓶颈的编码器-解码器网络。 它使用级联的 Nq 向量量化层,其中每一层将残差 𝐱∈ℝT×C 映射到形状为 T×D 的单热向量序列,其中 T 表示帧数,C 是编码器维度,D 是码字维度。
多尺度残差向量量化
我们的工作通过引入多尺度残差向量量化(如上图所示)扩展了 RVQGAN。 在每次迭代 i 中,将残差下采样 Wi 倍,执行码本查找,然后上采样 Wi 倍以匹配 𝐱 的原始时间分辨率 T。 在实践中,我们使用平均池化进行下采样,并使用最近邻插值进行上采样。
噪声块(Noise Block)
为了引入随机性并增强解码器的表现力,我们在每个上采样层之后添加了一个噪声块。该块通过更新输入来向激活值添加噪声:
x←x+Linear(x)⊙ε
其中 ε∼N(0,1) 是高斯噪声,⊙ 表示逐元素乘法。这种机制允许模型注入与输入相关的噪声。实验发现,噪声块可以改善重建质量,并促进码书(codebook)的更好利用。
深度卷积(Depthwise Convolution)
深度可分离卷积最初被引入是为了在视觉应用中构建更轻量的模型。通过对每个输入通道应用单个滤波器,该方法显著减少了计算量和模型大小。建议在生成器中使用深度卷积,不仅可以减少参数数量,还能稳定训练过程。基于 GAN 的声码器(vocoders)以其训练的不稳定性而闻名,通常在早期训练阶段会出现梯度发散,导致训练不稳定甚至模型崩溃。
局部窗口注意力(Local Windowed Attention)
在我们的模型中,我们在编码器和解码器中最低时间分辨率处引入了单层局部窗口注意力。这样设计的动机是利用注意力机制根据不同输入自适应地关注相关特征。此外,这种机制可以与后续的平均池化互为补充,从而有助于捕获上下文表示。类似地,文献【13】中引入了 LSTM 层,以更有效地建模时间依赖性。
详细网络结构:
一般音频:
编码器和解码器都在最低时间分辨率处包含局部窗口化注意力层。 我们用深度卷积替换了大多数卷积,除了嵌入、输出投影和上采样层。 编码器使用下采样层级联,速率分别为 [2, 3, 8, 8],解码器中相应的上采样层速率为 [8, 8, 3, 2]。 在 RVQ 中,我们使用 [8, 4, 2, 1] 的降采样因子(步长),有效地将 44.1 kHz 的输入信号压缩为四种不同速率的符元序列,分别为 14、29、57 和 115 Hz。 每个码本包含 4096 个条目(12 位),总比特率为 2.6 kbps。 该模型由编码器中的 1600 万个参数和解码器中的 3830 万个参数组成,总共 5450 万个参数。 我们应用相同的架构在 32 kHz 音频上进行训练,导致符元速率分别为 10、21、42 和 83 Hz,总比特率为 1.9 kbps。
语音:
对于语音编解码器,通过调整编码器(以及相应的解码器)中的降采样因子来修改架构,调整后的因子为 [2, 4, 8, 8]。 在残差向量量化中,我们使用 [4, 2, 1] 的步长。 该模型在 24 kHz 音频上进行训练,导致符元速率分别为 12、23 和 47 Hz,有效比特率为每秒 984 比特。 此外,我们减少了卷积通道的数量,导致编码器中有 670 万个参数,解码器中有 1300 万个参数,总共 1980 万个参数。 我们省略了语音编解码器中的局部窗口化注意力层,使架构完全卷积化。
实验:
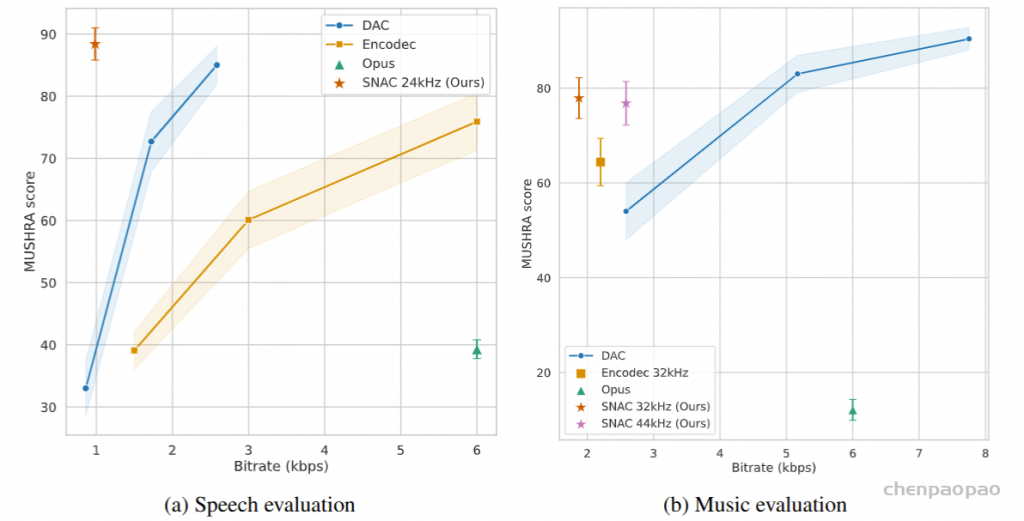
音乐
我们将第 4.1 节中介绍的针对通用音频的两种 SNAC 变体与 MusicGen [28] 中 Encodec [13] 的 32 kHz 检查点以及使用 3、6 或 9 个码本的官方 DAC [2] 检查点进行比较。 我们观察到,SNAC 明显优于其他编解码器,例如在可比较比特率下运行的 Encodec(32 kHz)和 DAC(使用 3 个码本)。 值得注意的是,SNAC 甚至与比特率是其两倍以上的编解码器相竞争。 此外,在 32 kHz 和 44 kHz 下的 SNAC 模型之间感知到的音频质量差异很小,这表明 32 kHz 模型足以完成大多数任务,并提供更低比特率的额外优势。
语音
对于语音,我们将 SNAC 语音模型与 EnCodec(24 kHz 检查点)和 DAC 进行比较,使用不同的码本数量。 在我们的评估中,SNAC 一直优于所有其他编解码器。 值得注意的是,即使在低于 1 kbit/s 的比特率下,SNAC 仍然保持着接近参考信号的音频质量。 这种效率使其在带宽受限的应用中特别有利,在这些应用中,保持语音的清晰度和可懂度至关重要
结论
我们介绍了多尺度神经音频编解码器 (SNAC),它是残差矢量量化的扩展,使用在多个时间分辨率下运行的量化器。 这种多尺度方法适应了音频信号的固有结构,从而实现更高效的压缩。 消融研究证实了我们设计选择的意义。 SNAC 在音乐和语音领域都优于现有的最先进的编解码器,在更低的比特率下提供更高的音频质量,正如广泛的客观和主观评估所证明的那样。 通过开源我们的代码和模型,我们旨在为神经音频压缩研究的进步做出贡献。