

🤗 Hugging Face | 📖 Github | 📑 Technical report
Mini-Omni2: Towards Open-source GPT-4o with Vision, Speech and Duplex Capabilities
Mini-Omni2 是一种全能互动模型。它可以理解图像、音频和文本输入,并与用户进行端到端的语音对话。具有实时语音输出、全方位的多模态理解和说话时与中断机制的灵活交互能力。
✅ 多模态交互:具有理解图像、语音和文本的能力,就像 GPT-4o 一样。
✅ 实时语音转语音对话功能。不需要额外的 ASR 或 TTS 模型,就像 Mini-Omni 一样。
1、为什么不使用 token-in-token-out 范式 :
为了有限数据量的高效训练 ,由于与理解能力相关的挑战,作者选择来自预训练编码器的特征和文本嵌入被连接起来以形成模型的输入。token-in不足以可靠地传达语音输入的内容,训练损失很高。
2、如何实现实时响应:
对文本和音频采用延迟并行输出方法,可以立即响应音频 。
3、如何做到打断对话:
认为当前的全双工训练仍然不够稳定,而基于输入语义信息的中断对于实现稳定和灵活的人机交互至关重要。探索了一种基于命令的中断方法,利用流式令牌作为输入并构建训练数据,使模型能够根据外部语义线索控制其音频输出流
GPT-4o 是一个包罗万象的模型,代表了大型多模态语言模型发展的一个里程碑。它可以理解视觉、听觉和文本模态,直接输出音频,并支持灵活的双工交互。来自开源社区的模型通常实现了 GPT-4o 的一些功能,例如视觉理解和语音聊天。然而,由于多模态数据的复杂性、复杂的模型架构和训练过程,训练包含所有模态的统一模型具有挑战性。 Mini-Omni2是一种视觉音频助手,能够为 visoin 和音频查询提供实时、端到端的语音响应。通过集成预先训练的视觉和听觉编码器,Mini-Omni2 可以在各个模态中保持性能。我们提出了一个三阶段的训练过程来调整模态,允许语言模型在有限的数据集上训练后处理多模态输入和输出。在交互方面,我们引入了基于命令的中断机制,使与用户的交互更加灵活。据我们所知,Mini-Omni2 是 GPT-4o 最接近的复制品之一,它们具有相似的功能形式,我们希望它能为后续研究提供有价值的见解。
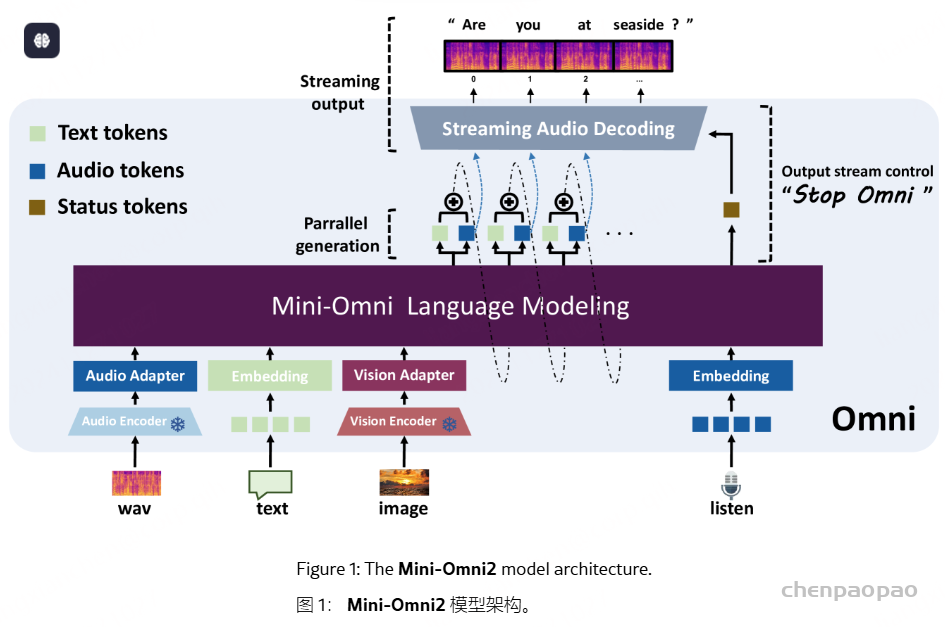
Mini-Omni2 作为 Mini-Omni 的延续,采用单一模型端到端模拟 GPT-4o 的视觉、语音和文本功能,并通过独特的基于命令的中断机制进行增强。与 Mini-Omni 一致,我们保留 Qwen2作为基础模型,利用这种紧凑的架构实现跨三种模态的全面多模态理解和实时流式语音推理。此外,我们使模型能够实时接收外部音频输入,模拟其 “听觉” 感知并根据内容语义控制语音输出流。Mini-Omni2 的模型架构如图 1 所示。作为一个端到端模型,我们通过直接采用经典的预训练视觉编码器 CLIP和语音识别模型 Whisper 的编码器组件来提高数据利用效率并展示 Mini-Omni2 算法的泛化性作为视觉和音频输入的特征提取器。来自预训练编码器的特征和文本嵌入被连接起来以形成模型的输入。由于与理解能力相关的挑战,我们没有采用 token-in-token-out 范式。此外,该模型对文本和音频采用延迟并行输出方法,可以立即响应音频像GPT-4o一样。
在 Mini-Omni2 中,我们提出了一种基于有限数据量的高效训练方法,旨在使模型的训练方法能够辅助其他多模态模型进行模态扩展。因此,我们避免了盲目地以指数方式扩展数据集,而是寻求使用最少的新数据开发一种多模态扩展方法。我们采用了模态扩展、对齐和联合训练的三阶段训练过程。最初,Mini-Omni2 模型使用语音识别和图像标题数据集进行适配器训练,从而拓宽了多模态理解的范围。接下来,Mini-Omni2 接受了跨模态问答任务中的文本输出训练,使基于适配器的输出功能与文本嵌入保持一致,以实现有效的问答。在第三阶段,我们通过结合音频输出和听觉能力(如中断)训练,专注于多模态输出能力。
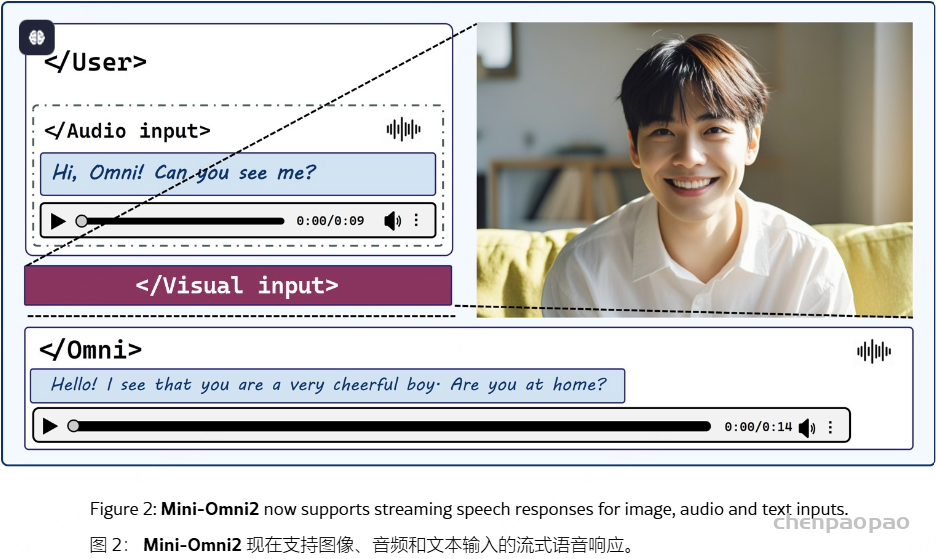
关于模型的语音交互能力,Mini-Omni2 继续使用 SNAC 分词器来确保高质量的语音输出。然而,根据我们的观察,我们认为当前的全双工训练仍然不够稳定。因此,我们认为基于输入语义信息的中断对于实现稳定和灵活的人机交互至关重要。我们使模型能够使用 SNAC 对其接收到的“听觉”波形进行实时编码,生成允许它在每次生成期间控制自己的输出的令牌。作为演示,我们使用短语 “stop omni” 构建数据,使用帧级 irq 和 n-irq 特殊token来控制生成过程。
Mini-Omni2
模型
Mini-Omni2 的模型架构如图 1 所示。除了文本嵌入模块外,Mini-Omni2 还采用了 CLIP 和 Whisper-small 的视觉组件作为视觉和听觉模态的编码器,从而在训练期间实现高效的数据利用,并最大限度地减少了大量的预训练工作。此外,Mini-Omni2 具有实时双工功能,为模型交互提供了更大的灵活性。
视觉编码器 – 我们利用 CLIP 的视觉组件,特别是 ViT-B/32 模型,作为视觉编码器,它将输入的图像转换为长度为 49 的特征序列,用于图像补丁和全局语义特征。Mini-Omni2 将这些连接起来形成长度为 50 的原始特征序列,使用单层 LlamaMLP作为视觉适配器。
Audio Encoder – 在编码器部分,我们使用 Whisper-small 模型作为音频编码器来继续之前的工作。我们选择不对音频输入和输出采用 token-in-token-out 建模方法,原因有两个。(i) 语音识别的语义一致性很强。由 OpenAI 提出的 Whisper 模型经过数千小时的数据集训练,表现出卓越的稳健性。此外,我们出乎意料地发现,尽管没有在任何中国数据集上进行训练,但 Mini-Omni 表现出对中国数据的理解。我们认为,这是因为 Whisper 模型能够自动对齐来自不同语言、语气和噪声级别的音频,这些音频传达了相同的含义,从而使模型能够专注于用户的意图。 (ii) 不稳定的开源音频token。我们观察到一种现象,即 a) Mini-Omni2 的音频损失在训练期间仍然很高,并且 b)音频片段的token可能会根据两端的内容而发生显著变化。我们认为,token不足以可靠地传达语音输入的内容,与 Whisper 等语义特征相比,ASR 的性能不佳就证明了这一点。
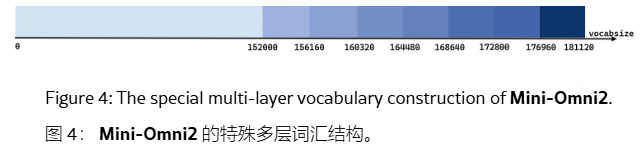
Mini-Omni2 使用 Qwen2-0.5B 基础版本作为其基础语言模型。我们使用 LitPT训练框架移植了基于 Llama 的 Qwen2 模型,采用 0.5B 模型的配置作为基本语言模型。对于图 3 所示的多层码本的并行生成,我们通过添加 7 × 4160 个 sub-LM-head 来扩展 Qwen2 模型的词汇表,如图 4 所示,得出词汇量为 181,120 个。
损失:对于同时生成的音频和文本标记,负对数似然损失可以表示为公式 :
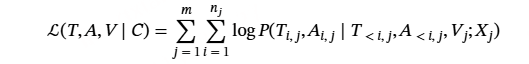
多模态标记 – 混合输入 – 图 3 说明了模型一些主要任务的输入和输出标记建模。由于该模型包含多个 LM 头,因此它以自回归方式生成多个序列。因此,该模型还将多个序列作为输入。输入序列可以包含从最少一种模态到最多三种模态的混合输入。
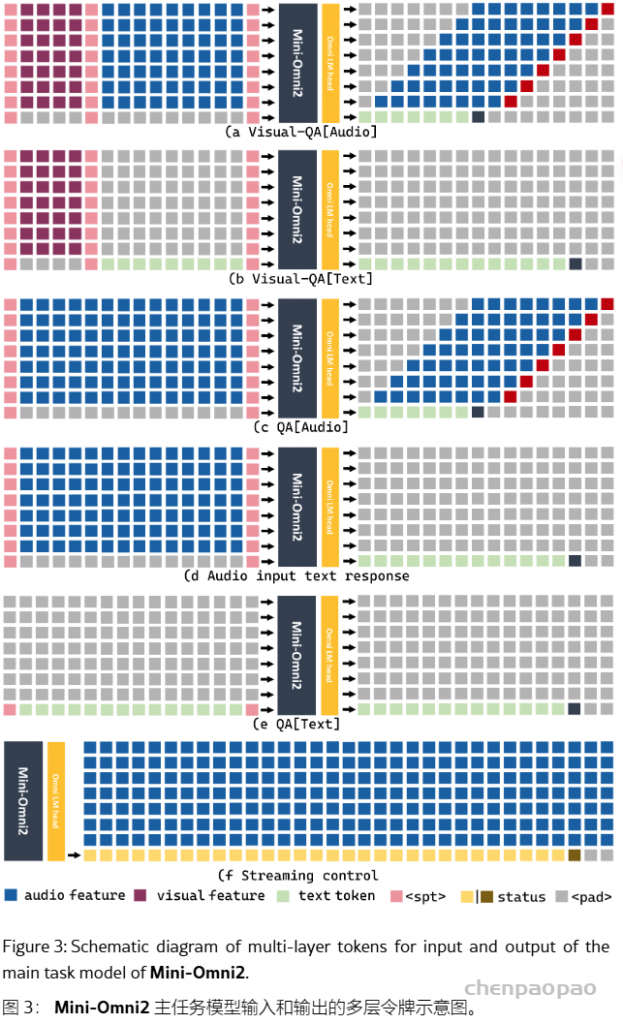
- 视觉 – [音频|文本] 输入。实验表明,当自回归任务与语义信息相连接时,Transformer 架构更容易训练并产生更自然的反应。因此,如图 3 (a) 所示,我们首先放置视觉适配器处理的视觉特征,然后是音频适配器处理的 Whisper 特征。最后,在需要自回归生成响应的位置,我们为响应放置一个特殊的 token。总长度约为 50(CLIP 特征长度)+ La (Whisper 特征长度)。
- 单模态输入 单模态输入可以由视觉、语音或文本输入组成。我们将视觉和音频模态的特征放在第 1 层到第 7 层。将复制这些特征,以便在所有图层要素之间进行平均时增强其突出性。值得注意的是,当仅输入单个模态的特征而不受特殊标记的控制时,默认任务是图像字幕、语音到文本的问答和文本到文本的问答。
文本-音频并联解码。在 Mini-Omni2 中,我们基本上保留了 Mini-Omni 的输出策略,采用 Text-Instruct Delay Parallel Decoding 算法来增强音频生成。这种方法利用文本-音频并行解码来同时生成音频和文本令牌,并利用文本到语音合成进行实时输出。我们继续 MusicGen 引入的并行生成方法,使用 SNAC 作为音频编码器,它由七个互补的令牌层组成。在一个步骤中,我们生成了 8 个标记,包括文本,同时在层之间保持一步延迟。此外,我们还采用了一种 Batch 方法,该方法涉及两个样本:一个需要文本和音频响应,另一个需要仅文本响应。通过丢弃第一个样本中的文本标记并将第二个样本的输出嵌入到第一个样本中,我们有效地将模型的基于文本的功能转移到音频任务中,从而以最小的资源开销显著提高推理能力。
训练策略
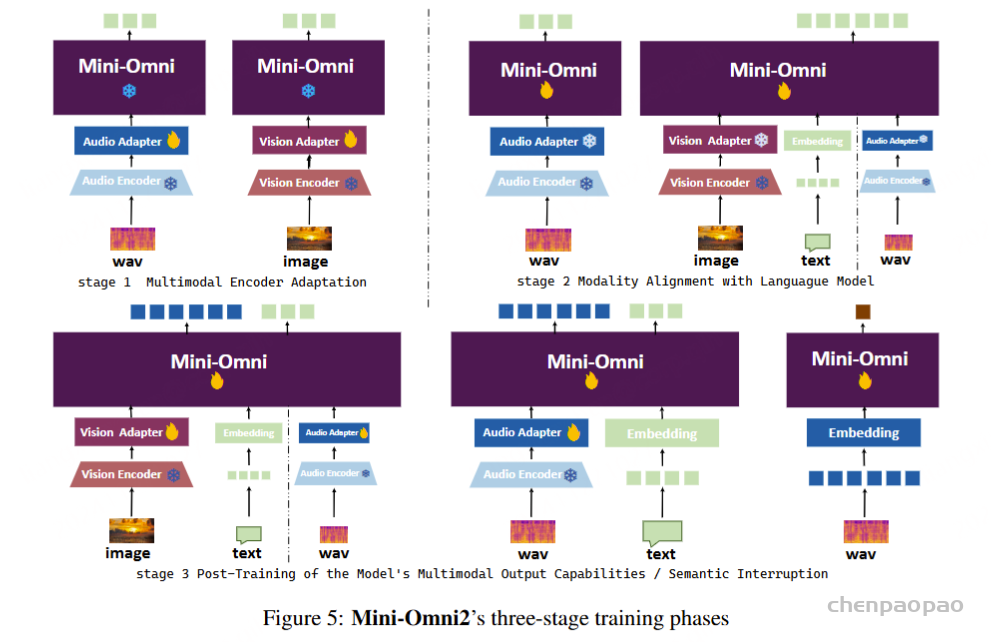
Mini-Omni2 的整个训练过程如图 5 所示。培训过程分为三个阶段,每个阶段采用多任务培训。在图中,除了阶段 1 之外,还合并了一个基础文本到文本任务,但未明确描述。我们将整个训练过程分为三个阶段:
- 多模态编码器适应 在第一阶段,我们采用快速、小规模的训练,只关注连接语言模型和编码器的线性层的权重。阶段 1 的目标是确保模型接收的多模态特征与模型嵌入层中表示的文本标记的特征非常相似。我们认为这种方法有两个主要优点:1. 它允许模型在随后的训练中专注于特定模态问答中的逻辑推理。2. 它最大限度地减少了语言模型核心中的参数变化,否则这些变化会因适应其他模态而导致。
- 模态对齐 在第 2 阶段,模型训练的主要任务是将基于文本输入的问答能力转移到基于图像和音频的问答能力。在此步骤中,在阶段 1 中训练的适配器被暂时冻结,语言模型的权重参与训练。在此阶段,所有任务都不涉及音频响应。对于基于图像和基于音频的 QA 等任务,仅生成基于文本的响应来建立模型的基本逻辑功能。语音输出只是这种逻辑能力在不同模态中的延伸。
- 训练后 在第 3 阶段,模型的任务是扩展输出模态以包括音频响应生成。如图 5 所示,该模型将针对第 1 阶段和第 2 阶段的所有任务进行训练,并为所有问答任务提供音频令牌输出。此外,该模型将学习中断机制。
双工交互
实时对话模型需要具有双工功能,以实现更灵活的交互。但是,这种中断机制不应该是一个简单的基于 VAD(语音活动检测)的机制,而是一个可以确定用户是否打算中断模型的系统。此外,模型的能力应该非常健壮,能够处理各种外部情况(例如,噪音、其他对话和不相关的声音)。我们通过基于命令的任务来探索此功能,当用户说出 “Stop Omni” 时,模型将立即停止说话。此外,这种方法可以通过开发更符合上下文的中断数据集,自然地扩展为包含更复杂的语义中断机制。
背景噪声选择:(1) 我们随机使用了来自 Libri-tts 数据集的各种语音识别样本作为原始人类噪声数据样本。(2) 我们使用了来自 MUSAN数据集的样本,其中包括音乐、人声、白噪声和城市噪声。
语义中断构造:我们将 “Stop Omni” 与随机的语音音色合成,随后与噪声混合。具体的数据构造方法将在下一节中介绍。
结合上述数据,该模型将接收到包含各种噪音中的 “Stop Omni” 短语的长序列数据。该模型将实时生成两种类型的状态 token:irq 和 n-irq,分别代表用户打断和不打断的意图。在推理过程中,当模型输出 irq token 时,它会停止生成过程并开始监听新的 question。对于此任务,我们使用token作为输入来增强模型的实时处理能力。
训练:
Mini-Omni2 模型在 8 个 A100 GPU 上完成了所有训练步骤。在适配器训练阶段,学习率从 2e-5 到 1e-3 不等,而训练语言模型使用的学习率在 2e-6 和 2e-4 之间。最后的微调是在 2e-6 到 2e-5 的学习率范围内进行的。采用了余弦调度器,具有 1500 个预热步骤,全局批处理大小为 192。使用完整数据集对每个阶段进行一个 epoch 的训练。前面介绍了视觉和音频编码器的规模,使用的语言模型是 Qwen2-0.5B 基本模型。所有型号适配器均使用中间尺寸为 4,864 的 Llama-MLP。
数据集:
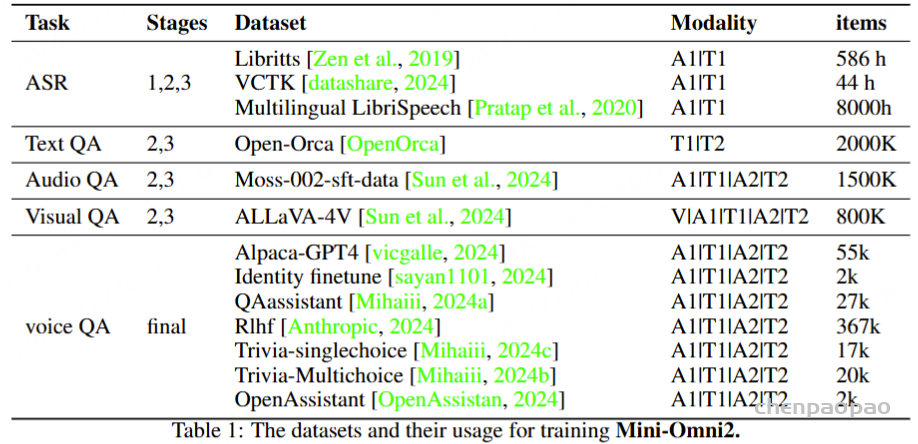
语音对话数据合成:
Spoken Dialogue Data:使用语音识别数据集作为随机语音音色库。为了确保训练的稳健性,从该数据集中随机选择一个样本作为输入所有口语对话数据的语音提示,并采用 CosyVoice进行零镜头语音合成。对于所有问答数据的输出,使用来自内部 TTS 系统的相同语音音色。
中断数据:首先,对噪声数据进行流式编码和解码,以模拟模型的实时流式输入。然后,提取噪声数据的随机段。在此段落的末尾,插入一个 “Stop Omni” 乐句,以与对话数据相同的方式使用随机语音音色生成。最后,在此段的末尾附加一个 0-10 秒的额外“尾巴”。在标注方面,尾部之前的所有数据都标记为 “n-irq”,而尾部段被标记为 “irq”,表示模型应该被打断。
结果:

改进空间:
以下几个方面值得探索和改进:
1. 模型和数据大小的缩放。Mini-Omni2 的目标是用有限的资源训练小模型,我们相信更多的数据和计算可以大大增强其能力。
2. 改进音频输出的风格控制和多样性(情感、自然度、音色、口音和歌唱)。
3. 更丰富的语义中断机制。