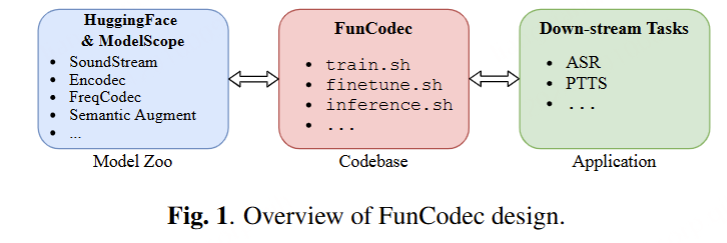
- Demo:funcodec.github.io/
- Github:https://github.com/modelscope/FunCodec/
- Paper:FunCodec: A Fundamental, Reproducible and Integrable Open-source Toolkit for Neural Speech Codec
一个基础的、可重复的和可集成的用于神经语音编解码器的开源工具包
特点:
- FunCodec 再现了最先进的模型,包括 SoundStream、Encodec 等。
- FunCodec 可以很容易地扩展到 下游任务,例如 ASR 和 TTS。
- FunCodec 可以在分布式 GPU 上训练模型, 和批处理模式下的推理。
- FunCodec 原生支持频域、 更适合语音信号。
- FunCode 模型可以通过语义标记进行增强, 例如音素和 Hubert 嵌入。
Available models:
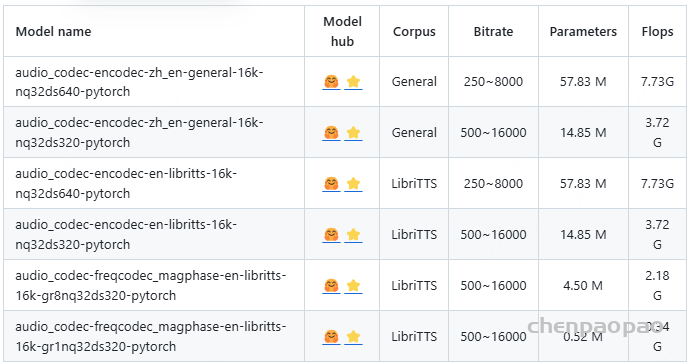
audio_codec-freqcodec_模型特点:频域模型,充分利用语音信号的短时结构,模型参数极少 (0.52M),计算复杂度极低 (0.34G flops),使用结构化 dropout 进行训练,使用单个模型在推理过程中启用各种带宽,将原始语音波形量化为离散标记序列
audio_codec-encodec_模型特点:使用大规模内部数据集进行训练,对许多场景都具有鲁棒性,在低频带宽度下实现更高的编解码器质量,使用结构化 dropout 进行训练,使用单个模型在推理过程中启用各种带宽,将原始语音波形量化为离散标记序列
与 EnCodec 和 SoundStream 相比, 使用以下改进的技术来训练模型,从而提高编解码器质量和 相同带宽下的 ViSQOL 分数:
- 幅值频谱loss用于增强中高频信号
- 结构化 dropout 用于平滑代码空间,并在单个模型中启用各种带宽
- 码字由 k-means 集群而不是随机值初始化
- 码本采用指数移动平均和死码消除机制进行维护,因此码本的利用率很高。
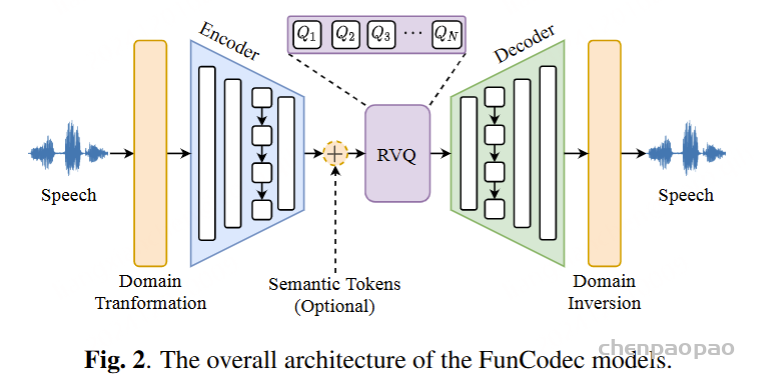
模型组成:
- FunCodec 模型由五个模块组成:域转换模块、编码器、RVQ 模块、解码器和域反转模块。
- 域变换:将信号转换为时域、短时频域、幅度-角度域或幅度-相位域。
- 编码器:将信号编码为具有堆叠卷积层和 LSTM 层的紧凑表示。
- 语义token(可选):使用语义标记增强编码器输出以增强内容信息,此模型中未使用。
- RVQ:使用级联向量量化器将表示量化为离散标记的并行序列。
- Decoder:将量化的 embedding 解码到与 inputs 相同的不同信号域中。
- Domain Inversion:重新合成来自不同域的可感知波形。
Results
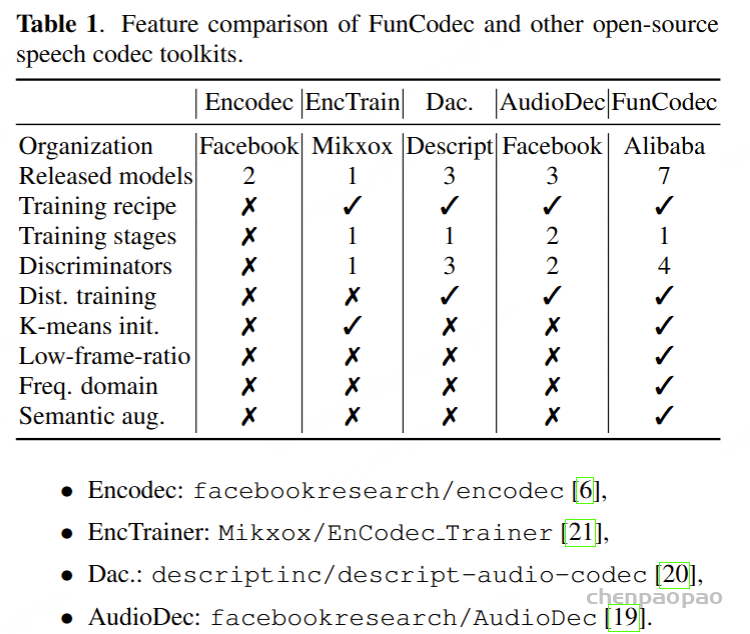
相比其他开源的音频编解码训练框架:
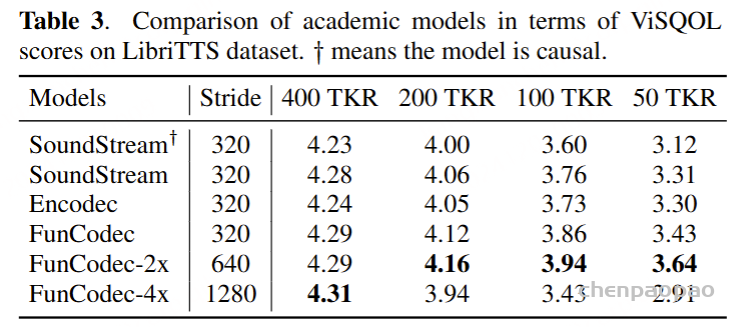
1. Comparison of academic models in terms of ViSQOL scores on LibriTTS dataset. † means the model is causal.
2. Comparison between FunCodec and other toolkits under (a) lower and (b) higher token rate. LS denotes Librispeech test sets. While Librispeech and gigaspeech are English corpora, aishell and Wenet are Mandarin corpora.

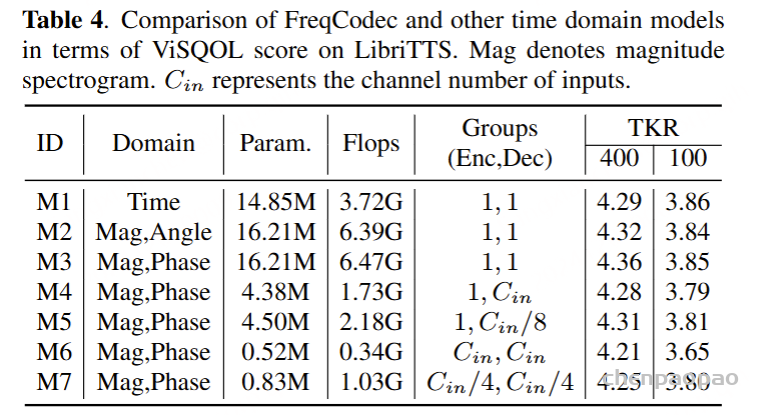
3. Comparison of FreqCodec and other time domain models in terms of ViSQOL score on LibriTTS. Mag denotes magnitude spectrogram. C_in represents the channel number of inputs.