

在实际应用场景中,SoundStream 可修改为低时延的设计,支持流式的编解码推理,在智能手机 CPU 上可达到实时的效果。在主观评测中,对于 24kHz 采样率下的音频,3 kbps 低比特率下的 SoundStream 比 12 kbps 的 Opus 和 9.6 kbps 的 EVS(增强语音服务,Enhance Voice Services)效果都更好。另外,SoundStream 的 Encoder 端或者 Decoder 端允许对压缩编码和语音增强进行联合建模,单一模型的实现,不会额外增加时延。
工作概述
- 模型由全卷积 Encoder-Decoder 和残差向量量化(RVQ, Residual Vector Quantizer)模块端到端联合训练得到;
- 模型结合了语音合成和语音增强领域的前沿工作,包括对抗训练和重建损失目标等,能够让模型从量化后的编码结果恢复出高质量的音频;
- 训练时在量化层使用了结构化 dropout,使得单一模型能够在 3kbps 到 18kbps 不同的比特率下有效使用,相比于固定比特率的模型,音频质量的损失几乎可以忽略不计;
- 模型支持将音频压缩编码与音频降噪进行联合建模,达到与级联模型相近的效果。
SoundStream 模型结构
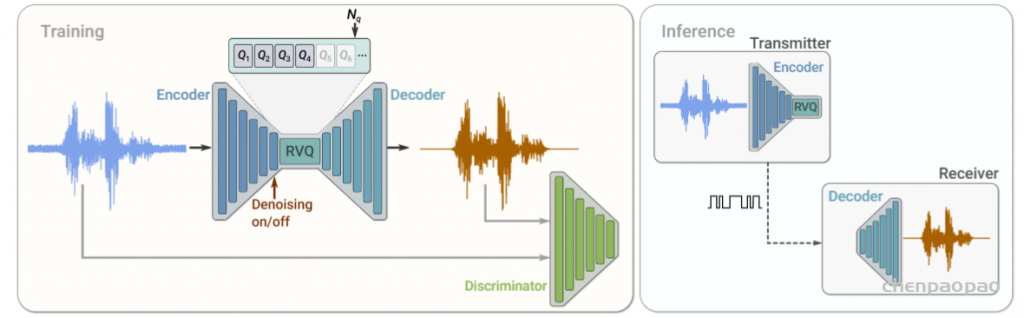
SoundStream 编解码器是全卷积的结构。输入是原始的音频波形,Encoder 将其映射为较低采样率的 embedding 序列,RVQ 残差向量量化器对 embedding 序列进行量化;Decoder 同样是全卷积结构,输入是量化后的 embedding,预测目标是恢复出原始波形。
SoundStream 模型是基于波形重建和对抗训练两个损失函数进行端到端训练的,增加了多个判别器用于区分是解码恢复的音频还是原始音频。需要说明的是,Encoder 和 Decoder 都只使用了因果卷积,不依赖于音频后续采样点的信息,所以模型时延只与编码器的降采样系数有关。具体计算过程为:假设音频的原始采样率是 24 kHz,降采样 320 倍到 75 Hz,那么模型的时延为 1 / 75 ≈ 13.3 ms,因为需要等原始音频输入 320 个新的采样点(320 / 24000 ≈ 13.3 ms)编码器才能输出一个新的 embedding。
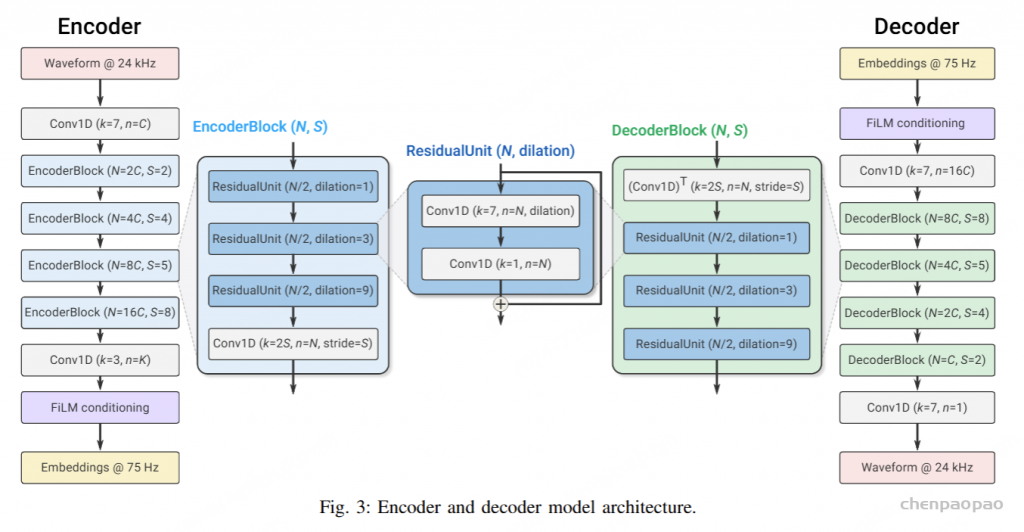
编码器结构
编码器的输入是 24 kHz 原始波形,先进入一层一维卷积,kernel_size 为 7,输出 channel 大小为 C;再经过B个 EncoderBlock 模块,每个模块包含三个 ResidualUnit 残差单元和一层用于降采样的一维卷积。
ResidualUnit
包含两层一维卷积:第一层是膨胀卷积, kernel 大小为 7,输出 channel 为 N,膨胀率为 dilation(用于扩大深层网络的感受野);第二层是输出 channel 为 N,kernel size 为 1 的一维卷积(相当于全连接层)。
EncoderBlock
包含的三个膨胀率分别为 1,3,9 的残差单元,膨胀率越大说明卷积层的感受野越大;三层膨胀卷积之后是一层跳步卷积(strided convolution),stride=S 表示对输入序列进行 S 倍的降采样。
按照上图给出的网络结构示例,共四层 EncoderBlock,降采样倍数分别为 2, 4, 5, 8,相当于整个编码器的整体降采样倍数为 320,对应于输入的 24 kHz 音频,输出帧率为 24000/320 = 75 Hz。此外,每个 EncoderBlock 在输出的 channel 维度上是输入 channel 的 2 倍,四层 EncoderBlock 之后输出的 channel 维度从C扩充至16C。 四层 EncoderBlock 之后是一层 kernel_size 为 3 的一维卷积,输出 channel 维度为 K,即对应于最终 embedding 的维度。
其他细节
为了保证模型的实时性和低时延,模型中用到的所有一维卷积全部采用因果卷积,卷积计算只会用到当前及之前的信息,padding 的操作也只应用于过去的序列。另外,所有的卷积层只使用 ELU 激活函数,不加入任何形式的 normalization 层。
解码器
解码器采用的是和编码器完全对偶的结构。编码器得到的 embedding 经过一维卷积后进入 Bdec个 DecoderBlock 模块。每个 DecoderBlock 先进入一层一维反卷积进行上采样,再经过三层残差单元将输出 channel 减半,三层残差单元的膨胀卷积率仍然是 1, 3, 9 的顺序。 Bdec 层 DecoderBlock 之后是一层输出 channel 为 1 的一维卷积,相当于将当前时刻的输出映射到原始的时域波形上。
残差向量量化器 (RVQ)
SoundStream 整体的编解码器结构比较直观,但论文的关键技术点之一是引入了残差向量量化(RVQ)模块,目的是将 Encoder 输出的 embedding 通过量化层压缩到目标的比特率。
先回顾下 VQ(Vector Quantization):VQ 的目标是学习 N 个向量构成的 codebook,用于对 Encoder 输出的 embedding 进行编码。设 Encoder 输出的 embedding 序列长度为 S,每个 embedding 的维度为 D,使用 VQ 进行编码后,每个 embedding 被重新映射为一个 one-shot 向量,向量中 1 的位置用于表征对应 codebook N 个向量中的哪个,因此量化后对应的序列为 S × N,log2N 作为 one-hot 向量可以用 比特来存储。
普通 VQ 的局限性
计算下 VQ 所需的 codebook 大小:如果目标比特率是 6 kbps,对于 24 kHz 的音频,按照前文图中的 320 倍降采样,每秒对应于 75 个 embedding,每个 embedding 对应的比特数为 6000 / 75 = 80 bit,那么对应的 codebook 大小是 280,这个量级肯定是行不通的,因此普通版本的 VQ 因为 codebook 过大而不适用。
残差 VQ / 多阶段 VQ
为了解决普通 VQ 方法中 codebook 规模过大的问题,SoundStream 采用多阶段 VQ 的方法。RVQ 量化器一共包含Nq层 VQ,基本流程如 Algorithm 1 所示(Qi 表示第 i 层量化层):原始的 Encoder 的输出的 embedding 经过第一层 VQ,可以计算出相应的量化残差,然后第二层 VQ 只针对上一层 VQ 的残差进行量化,以此类推。
值得注意的是,论文将原本的一层 VQ 转换为多层残差 VQ 时,每个 VQ 层的 codebook 大小保持一致,相当于比特率的降低是按照倍数平均分配到每个 VQ 层的。按照前文 24 kHz 音频压缩到 6 kbps 的例子:当使用的 VQ 层共 8 时,每个 VQ 对应的 codebook 大小可以变为 1024,此时就是一个相对可行的 codebook 大小了。
codebook EMA 训练
每个量化器在训练 codebook 的时候,都使用 EMA (Exponential Moving Average,指数移动平均)的更新方式。训练 VQ 的 codebook 使用 EMA 方法由 Aäron van den Oord首次提出。论文 Neural Discrete Representation Learning(https://arxiv.org/abs/1711.00937)提出使用 EMA 指数移动平均的方式训练码本 codebook。
EMA 指数移动平均:每次迭代相当于对之前所有 batch 累计值和当前 batch 新获取的数据值进行加权平均,权重又称为 decay factor,通常选择数值为 0.99 ,使得参数的迭代更新不至于太激进。
假设可以一次性获取训练集对应于 Encoder 的所有输出,设 codebook 上一次迭代后其中某个向量为ei ,那么本次迭代只需求出 Encoder 输出中和 ei 距离最近的向量,取平均值即可作为 ei 本次迭代后的数值。这实际上和 k-means 中聚类中心的迭代方式一样,但这种思想没有办法应用于 mini-batch 级的数据,因为每个 batch 只包含全部训练集的很小一部分,基于 mini-batch 的统计和平均是有偏的,因此需要采用一种随着 mini-batch 的变化在线更新 codebook 的方法。

codebook 初始化及更新
SoundStream 在初始化 codebook 的各个向量时,对第一个 batch 数据 Encoder 输出的 embedding 进行 k-means 聚类,使用聚类中心作为各向量的初始值,使得 codebook 在开始训练时和输入的数据分布保持相近。
如果 codebook 中某个向量在多个 batch(可以对具体的 batch 数进行预设)都没有可用的 embedding 来更新参数,该向量会使用当前 batch 内随机一个 embedding 进行覆盖。这个思想是参考了 JukeBox(https://arxiv.org/pdf/2005.00341.pdf)论文中的做法,是为了让 codebook 中的向量在训练时被及时的使用,因为 codebook 中的向量只用被用到了才能从损失函数得到反馈进行反向传播的参数更新,从而规避 codebook 的无效学习。
灵活的比特率
按照前文的描述,RVQ 的层数和每个 RVQ 的 codebook 大小确定时,音频压缩后的比特率也是固定的,这就要求对不同比特率的应用场景分别训练不同配置的模型。但是 SoundStream 利用了 RVQ 的残差连接的优势,使得所有的 RVQ 层不一定需要全部使用,训练时可以对 RVQ 层进行结构上的 Dropout,从而给出 SoundStream 的另一大优势:很灵活地适配不同的比特率。具体操作方法为:设 RVQ 的层数为 Nq,对于每个训练样本,随机从 1 到 Nq 中选择一个数nq ,对应于不同的比特率,训练阶段只需要经过前 nq个 RVQ 层;推理阶段也可以根据不同比特率的需要,使用相应的前 nq 个 RVQ 模块进行预测。
判别器
SoundStream 为了提高编解码之后音频的合成质量,将语音合成中常用的对抗训练思想引入到模型中,额外增加了两种判别器,用来判别音频是编解码恢复出来的还是真实的音频。
第一种是基于波形的判别器。采用多精度 multi-resolution 的思想,与 MelGAN 和 HiFi-GAN 中的多精度判别器类似,在原始波形、2 倍降采样和 4 倍降采样后的波形上分别进行真假判别。
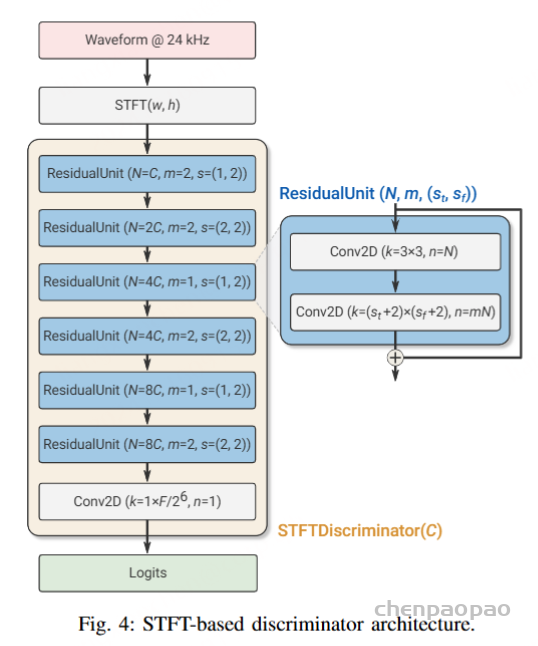
第二种是基于 STFT 的判别器:

训练目标
SoundStream 整体使用 GAN(生成对抗网络)作为训练目标,采用 hinge loss 形式的对抗 loss。对应到 GAN 模型中,整个编解码器作为 Generator 生成器,使用前文所述的两种 Discriminator 判别器:一个 STFT 判别器和三个参数不同的 multi-resolution 判别器。判别器用来区分是解码出的音频还是真实的原始音频,本文采用 hinge loss 形式的损失函数进行真假二分类:
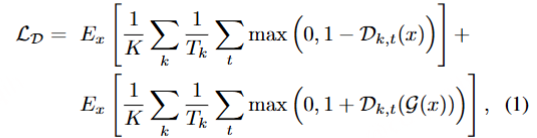

生成器的损失函数是为了让生成器的输出被分类为 1 类别,以达到以假乱真的目标,损失函数形式为:
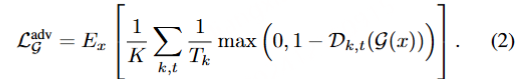
训练目标中还增加了 GAN 中常用的 feature matching 损失函数和多尺度频谱重建的损失函数。feature matching 就是让生成器恢复出的音频和真实的音频,在判别器的中间层上达到相近的分布,用l表示在中间层上进行求和,feature matching 的损失函数为:
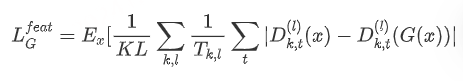
多尺度频谱重建的损失函数形式为:
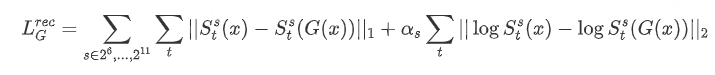

联合压缩与增强
音频压缩(音频编码)和音频的降噪增强通常是两个不同的模块,在传统的音频处理流程中,音频增强模块通常位于音频编码前或者音频解码后,两个模块的时延是累加的。SoundStream 能够同时进行音频的编解码和降噪增强,并且不会增加系统的时延。
SoundStream 除了可以在不同的比特率下工作外,另外的灵活之处在于推理时可以选择降噪和不降噪两种模式。在模型中增加一个条件变量 denoise,denoise 为 false 时任何音频数据都可以拿来训练,denoise 为 true 时必须同时提供音频的原始版和降噪版来训练,因此只有在条件变量 denoise 置为 true 的时候模型才具有降噪的功能。
为了避免模型在 denoise = true 的时候对本来就干净无噪声的音频带来损伤,训练数据中还必须包含一些干净音频,在训练时 denoise = true 或 false 均可,让模型在有噪声/无噪声的条件下都具有效果的保证。
从 SoundStream 的编解码器图例中可以看到一个 FiLM 的模块,表示特征级别的线性调制(Feature-wise Linear Modulation),在编码器中使用时位于 embedding 之前(编码前进行降噪),在解码器中使用时输入是 embedding(编码后进行降噪),论文验证了在图中位置的效果是最好的。

SoundStream 评测
评测准备
评测数据集
评测覆盖多种类型的音频,包括干净和带噪的语音和音乐,都是 24kHz 采样率。干净的语音来自 LibriTTS,带噪的语音是将 LibriTTS 和 freesound 里的噪声叠加,叠加时噪声的增益系数在 -30dB 和 0 dB 之间;音乐数据来源是 MagnaTagATune;论文还采集了真实场景的音频数据集,覆盖了近场、远场(带混响)和背景噪声的音频。相当于共四个测试集,每个测试集是 50 个待测样本。
评测指标
模型最终评测的指标采用前文所述的 MUSHRA 分数,评测人母语均为英语,戴耳机进行评测。但是在模型训练和调参时,留出一个验证集,在上面计算客观指标进行模型评价,可以用 PESQ 和 POLQA 的,本文选择的是开源的 ViSQOL 评测指标。
评测基线
Opus 是传统的音频编解码方法,支持 4kHz ~ 24 kHz 的采样率和 6 kbps ~ 510 kbps 的比特率,在 Youtube 流媒体上都在使用。另外 EVS (增强语音服务) 也是一种新编解码方法,支持 4kHz ~ 20 kHz 的采样率和 5.9 kbps ~ 128 kbps 的比特率。Google 还提出了基于自回归模型的 Lyra 编解码器,可以在 3 kbps 的低比特率下使用。本文将以上三种方法作为基线。
实验结果
不同比特率下的结果
其中 scalable 的 SoundStream 代表一个支持多比特率的模型,不带 scalable 的模型表示给当前比特率专门训练的模型,可以看出模型是否 scalable 差别不大,尤其是高比特率下几乎无差别。相同比特率下,SoundStream 碾压其他三个基线模型。
不同类型音频的结果
SoundStream @ 3kbps 相当于 EVS @ 9.6kbps 和 Opus@12kbps,SoundStream@6kbps 相当于 Opus @ 16kbps 和 EVS @ 13.2kbps,SoundStream @ 12kbps 超过了 Opus @ 20kbps 和 EVS @ 16.4kbps。普遍性地,编解码后恢复的音频,MUSHRA 分数上:干净语音 > 真实场景音频 > 带噪语音 > 音乐。
消融实验
神经网络编码器的重要性
如果将编码器部分修改为普通的 fbank 特征(类似于一代 Lyra),再训练 RVQ 和解码器模块,此时的客观指标 ViSQOL 从 3.96 降低至 3.33;但是如果增加了神经网络结构的编码器,3 kbps 比特率下的 ViSQOL 也有 3.76,说明编码器采用神经网络结构是非常有必要的。
模型参数量大小的影响
从实验结果可以看出,建议使用相对轻量级的编码器和参数量更多的解码器。
VQ 参数配置的影响
假设共 Nq个量化器,每个量化器的 codebook 大小为 N,那么每帧 embedding 编码后需要 NqlogN比特来存储,比特率和 NqlogN 正相关。表格中给出了相同比特率下的不同参数配置,可以看出量化器层数不必太多,每层的 codebook 大小更大时,模型的效果会更好;但同时也能看出,80 层深层的 1-bit 量化器,也能够达到较好的效果,验证了 RVQ 深层网络的有效性。

模型的时延计算
前文说明过,模型的时延主要取决于编码器的降采样倍数,降采样倍数越大,时延越大。表格中给出了详细的对比结果,能够看出,降采样倍数越大,时延越大,但同时模型需要的量化层数明显降低,编解码器的实时率会随之提高(因为每个 embedding 对应的真实时间更长),因此在实际场景中需要在时延和实时性之间进行 trade-off。
联合的音频降噪和压缩
该评测将联合降噪压缩与分别的降噪和压缩进行对比。降噪和压缩分开时,压缩采用 SoundStream 模型,降噪采用 SEANet 模型,关于降噪和压缩模型的使用顺序,分别使用先降噪(编码前)后压缩、先压缩后降噪(解码后)两种策略。评测数据集使用的是 24kHz 的 VCTK,没有被用于 SoundStream 和 SEANet 的训练。分别在0,5,10,15 dB 四个配置下评测:
联合的压缩和降噪略差于其他两种实验配置,其他两种实验表明顺序带来的影响相差不大。SoundStream 的优势在于一个模型两种功能,简约而且省算力,并且和分开的两个模型在最终结果上相差不大。
参考文献/链接
- Lyra v1: Kleijn, W. Bastiaan, et al. “Generative Speech Coding with Predictive Variance Regularization.” arXiv preprint arXiv:2102.09660 (2021).
- AudioLM: Borsos, Zalán, et al. “Audiolm: a language modeling approach to audio generation.” arXiv preprint arXiv:2209.03143 (2022).
- MusicLM: Agostinelli, Andrea, et al. “MusicLM: Generating Music From Text.” arXiv preprint arXiv:2301.11325 (2023).
- EMA 训练 codebook 1: Van Den Oord, Aaron, and Oriol Vinyals. “Neural discrete representation learning.” Advances in neural information processing systems 30 (2017).
- EMA 训练 codebook 2: Razavi, Ali, Aaron Van den Oord, and Oriol Vinyals. “Generating diverse high-fidelity images with vq-vae-2.” Advances in neural information processing systems 32 (2019).
- Jukebox: Dhariwal, Prafulla, et al. “Jukebox: A generative model for music.” arXiv preprint arXiv:2005.00341 (2020).
- FiLM: Perez, Ethan, et al. “Film: Visual reasoning with a general conditioning layer.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 32. No. 1. 2018.
- ViSQOL 指标: Chinen, Michael, et al. “ViSQOL v3: An open source production ready objective speech and audio metric.” 2020 twelfth international conference on quality of multimedia experience (QoMEX). IEEE, 2020.
- 官方博客: https://opensource.googleblog.com/2022/09/lyra-v2-a-better-faster-and-more-versatile-speech-codec.html
- 示例音频: https://google-research.github.io/seanet/soundstream/examples
- 官方开源: https://github.com/google/lyra
- 非官方实现(PyTorch)Lucidrains: https://github.com/lucidrains/audiolm-pytorch/blob/main/audiolm_pytorch/soundstream.py
- 非官方实现(Pytorch)wesbz: https://github.com/wesbz/SoundStream