
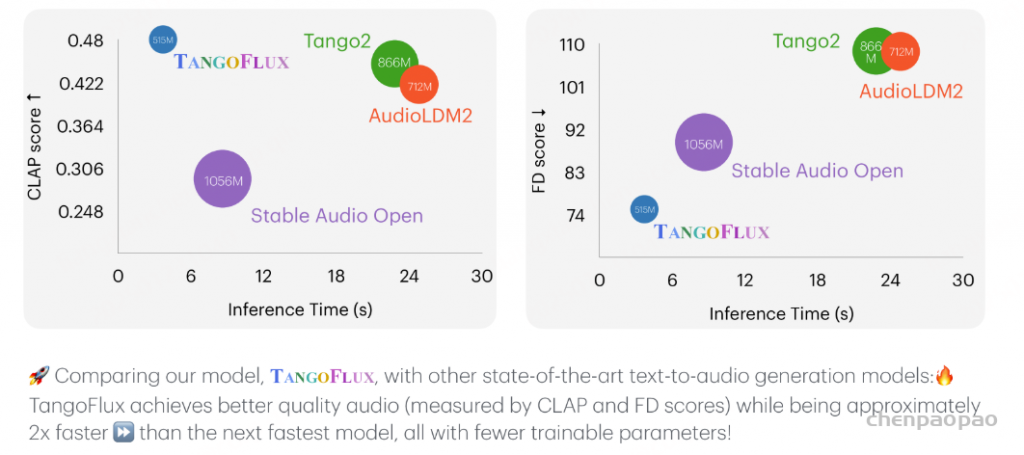
NVIDIA发布了新模型TangoFlux,TangoFlux和Flux采用类似的MMDiT架构,但与Flux不同的是,TangoFlux是用于根据文本来生成与之匹配的音频(Text-to-Audio,TTA)。注意,TTA与文本生成语音(Text-to-Speech,TTS)是两个不同的任务,TTS是根据文本合成口语化的语音,而TTA更复杂,是根据文本内容生成相应的背景音、环境音或者情感表达的音频。TangoFlux模型参数只有515M,能够在单个A40 GPU上仅用3.7秒生成长达30秒的44.1kHz音频,而且效果上实现了SOTA,所以是一个又快又好的TTA模型。目前,TangoFlux的代码和代码均已经开源:
在对齐 TTA(文本到音频)模型时,一个关键挑战在于生成偏好对的困难,因为 TTA 缺乏像大型语言模型(LLMs)那样的结构化机制,例如可验证的奖励或黄金标准答案。为了解决这一问题,我们提出了一种新颖的框架——CLAP 排序偏好优化(CRPO),通过迭代生成和优化偏好数据来增强 TTA 的对齐性能。研究表明,使用 CRPO 生成的音频偏好数据集优于现有的替代方案。借助这一框架,TangoFlux 在客观和主观基准测试中均达到了最先进的性能。
- 代码:https://github.com/declare-lab/TangoFlux
- 模型:https://huggingface.co/declare-lab/TangoFlux
- 技术报告:https://arxiv.org/abs/2412.21037
- HuggingFace demo:https://huggingface.co/spaces/declare-lab/TangoFlux
贡献:
- 引入了 TANGOFLUX,这是一种基于修正流的小型高效 TTA 模型,能够在完全非专有的训练数据上实现最先进的性能。
- 提出了 CRPO,这是一种简单而有效的策略,用于生成音频偏好数据并对修正流进行对齐,其在音频偏好数据集上的表现优于其他方法。
- 公开发布了代码和模型权重,以促进文本到音频生成领域的研究。
方法:
TangoFlux 由 FluxTransformer 块组成,这些块是基于扩散变换器(Diffusion Transformer, DiT,Peebles & Xie,2023)和多模态扩散变换器(Multimodal Diffusion Transformer, MMDiT,Esser 等,2024)的模型,通过文本提示和时长嵌入进行条件化,以生成最高 44.1kHz、时长达 30 秒的音频。TangoFlux 从通过变分自动编码器(VAE,Kingma & Welling,2022)编码的音频潜在表示中学习修正流轨迹。
TangoFlux 的训练流程包括三个阶段:预训练、微调和偏好优化。通过 CRPO 对 TangoFlux 进行对齐,CRPO 通过迭代生成新的合成数据并构建偏好对,执行偏好优化。整体训练流程如图 1 所示。
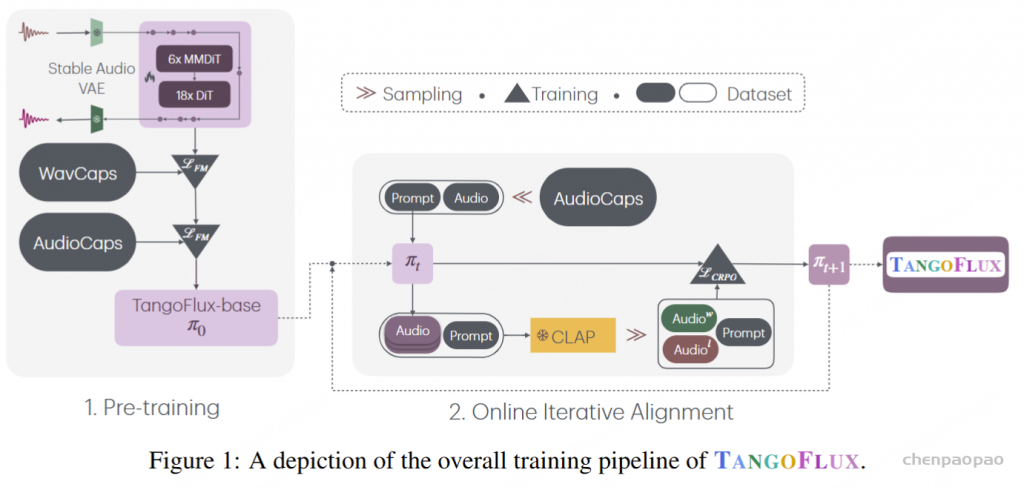
TangoFlux在模型架构上参考了Flux,也是采用混合MMDiT和DiT block的transformer,首先是6层MMDiT block,然后跟着18层DiT block,模型的特征维度是1024,总参数量为515M。类似SD和Flux,这里也是采用了一个音频VAE(来源Stable Audio Open)将音频编码成一定长度的latents,然后用DiT来生成latents。这里的文本编码器采用FLAN-T5,除了文本特征,还用一个小的网络将音频时长编码成一个embedding,并和文本特征拼接在一起,从而实现对生成音频长度的控制。训练也是采用Flow Matching。
音频编码
使用 Stable Audio Open Evans et al. 的 VAE,它能够将 44.1kHz 的立体声音频波形编码为音频潜在表示。给定一个立体声音频 X∈ℝ2×d×sr ,其中 d 是 时长duration 和 sr 是采样率 sampling rate,VAE 编码 X 为潜在表示 Z∈ℝL×C ,其中 L ,C 分别是潜在序列长度和通道大小。VAE 将 latent 表示 Z 解码回原始立体声音频 X 。整个 VAE 在 TangoFlux 训练期间保持冻结。
Model Conditioning
为了实现不同长度音频的可控生成,我们采用了文本调节和持续时间调节。文本调节根据提供的描述控制生成的音频的事件,而持续时间调节指定所需的音频长度,最长可达 30 秒。
文本条件。给定音频的文本描述,我们从预训练的文本编码器FLAN-T5中获取文本编码 ctext
持续时间编码。为了生成可变长度的音频,我们首先使用一个小型神经网络将音频持续时间编码成一个 duration embedding cdur 。这与文本编码 ctext 连接并馈送到 TangoFlux 以控制音频输出的持续时间。
模型架构
采用混合 MMDiT 和 DiT 架构作为 TangoFlux 的主干, 首先是6层MMDiT block,然后跟着18层DiT block,模型的特征维度是1024,总参数量为515M 。
Flow Matching
流匹配(Flow Matching)基于连续归一化流框架。该方法通过学习一个时间相关的向量场,将来自简单先验分布(例如高斯分布)的样本映射到复杂的目标分布,从而生成目标分布的样本。
在 TTA(文本到音频)领域的先前研究中,例如 AudioBox(Vyas 等,2023)和 Voicebox(Le 等,2023),主要采用了 Lipman 等(2023)提出的最优传输条件路径(Optimal Transport conditional path)。然而,我们的方法采用了 修正流(Rectified Flows,Liu 等,2022),这是一种从噪声到目标分布的直线路径,代表了最短路径。
整流流(Rectified Flows)。给定音频样本的潜在表示 x₁ 和服从正态分布 x₀ ∼ N(0, I) 的噪声样本,通过时间步 t ∈ [0, 1] 可以构建训练样本 xₜ。模型通过学习预测速度 vₜ = dxₜ/dt 来引导 xₜ 向 x₁ 演化。尽管存在多种构建传输路径 xₜ 的方法,我们采用了 Liu 等人(2022)提出的整流流(RFs)。该方法在目标分布与噪声分布之间构建直线路径作为前向过程,其定义如公式(1)所示。经验表明,当减少采样步数时,整流流具有更高的采样效率且性能下降更少(Esser 等人,2024)。我们用 θ 表示模型 u 的参数,该模型通过直接回归预测速度 u(xₜ, t; θ) 与真实速度 vₜ 的匹配,其损失函数如公式(2)所示。
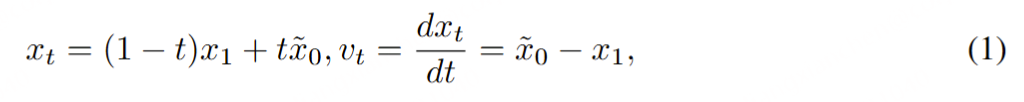
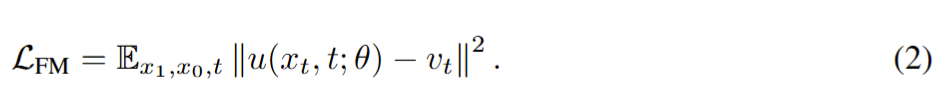
推理。在推理过程中,我们从先验分布 x~0∼𝒩(𝟎,𝐈) 中采样噪声,并使用常微分方程求解器根据模型在每个时间步 t 长预测的速度 vt 来计算 x1 。在此过程中,我们使用 Euler 求解器。
CLAP 排名偏好优化 (CRPO)
CLAP 排名偏好优化 (CRPO) 利用文本-音频联合嵌入模型作为代理奖励模型,根据与输入描述的相似性对生成的音频进行排名,然后构建偏好对。
我们首先设置了一个 Ta ngoFlux 架构的预训练检查点作为要对齐的基础模型,用 π0 表示。此后,CRPO 迭代地将 checkpoint πk≔u(⋅;θk) 对齐到 checkpoint πk+1 中,从 k=0 开始。每个这样的对齐迭代都包括三个步骤:(i) 批量在线数据生成,(ii) 奖励估计和偏好数据集创建,以及 (iii) πk+1 通过直接偏好优化进行微调 πk 。
Main Results

openl3表示 Frechet 距离、 passt KL 表示 KL 散度和 CLAP score 表示对齐。所有推理时间都是在同一个 A40 GPU 上计算的。我们在 #Params 列中报告可训练参数。
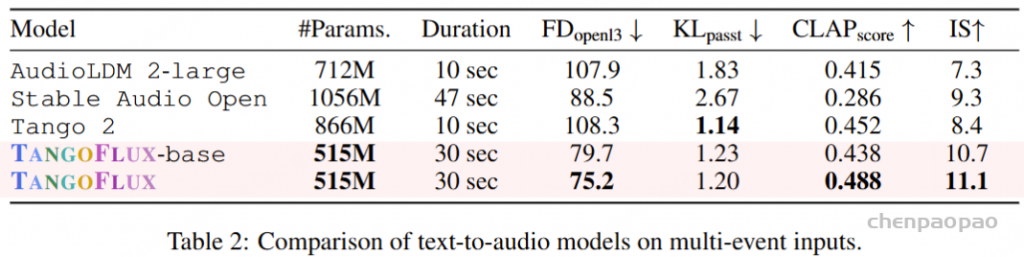
表 1 在客观指标方面将 TangoFlux 与 AudioCaps 上先前的文本到音频生成模型进行了比较。表 2 报告了具有多个事件的提示(即多事件提示)的模型性能。