
- Github:https://github.com/OpenBMB/MiniCPM-o 【微调和推理代码开源】
- Online Demo US/CN
- MiniCPM-o 2.6 🤗 国内🤖 国外🤖 | MiniCPM-V 2.6 🤗 🤖 | 📄 技术报告 [中文/English]
➤ 项目网站 https://github.com/OpenBMB/MiniCPM-o
➤ 模型权重 https://huggingface.co/openbmb/MiniCPM-o-2_6
https://modelscope.cn/models/OpenBMB/MiniCPM-o-2_6
➤ Demo https://minicpm-omni-webdemo-us.modelbest.cn/
MiniCPM-o 2.6部署教程 详细的部署教程请参考文档。
简介
多模态大模型的蓬勃发展始于视觉和语言,其中开源社区在图像理解能力方面实现了越来越强的性能表现。然而,我们的物理世界本质上是一个并行的连续多模态信息流,而当前大多数多模态大模型缺乏处理这样信息流的能力。最近的 GPT-4o 和 Gemini 2.0 等突破性工作迈出了朝这个目标的第一步,为领域的未来发展建立了雄心勃勃且充满希望的方向。
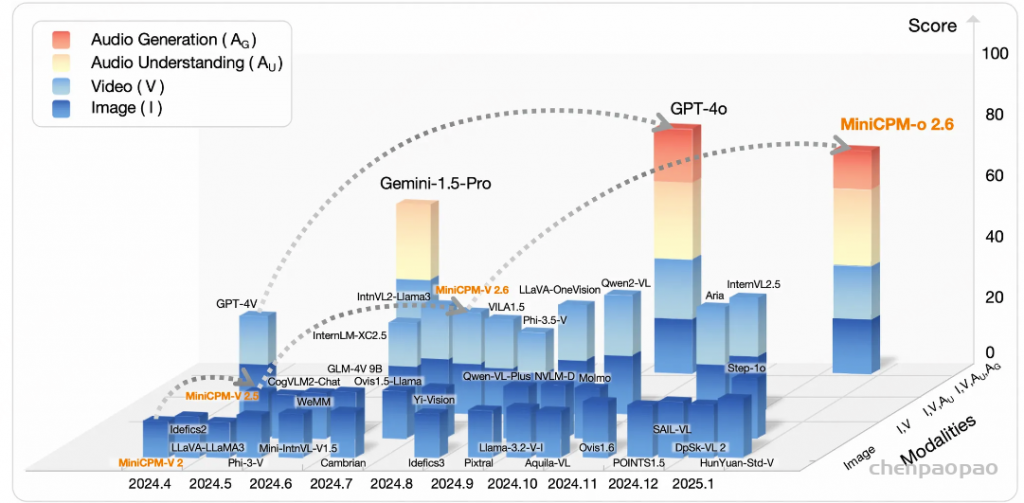
为了促进开源社区的探索,我们推出了 MiniCPM-o 2.6,一个从 MiniCPM-V 系列升级而来的最新性能最佳的端侧多模态大模型。该模型接受图像、视频、文本和音频输入,并以端到端方式生成高质量的文本和语音输出。虽然总参数量仅有 8B,MiniCPM-o 2.6 的视觉、语音和多模态流式能力达到了 GPT-4o-202405 级别,是开源社区中模态支持最丰富、性能最佳的模型之一。其主要特性包括:
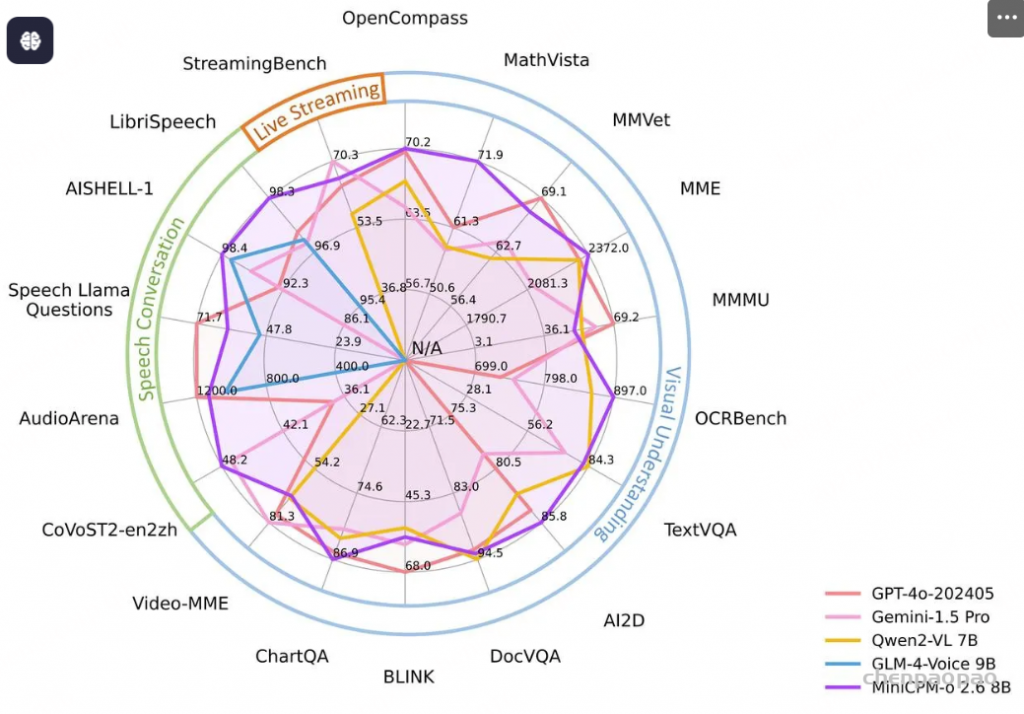
- 领先的视觉能力。 MiniCPM-o 2.6 在 OpenCompass 榜单上(综合 8 个主流多模态评测基准)平均得分 70.2,以 8B 量级的大小在单图理解方面超越了 GPT-4o-202405、Gemini 1.5 Pro 和 Claude 3.5 Sonnet 等主流商用闭源多模态大模型。此外,它的多图和视频理解表现也优于 GPT-4V 和 Claude 3.5 Sonnet,并展现出了优秀的上下文学习能力。
- 出色的语音能力。 MiniCPM-o 2.6 支持可配置声音的中英双语实时语音对话。MiniCPM-o 2.6 在语音理解任务(如 ASR 和 STT 等)优于 GPT-4o-realtime,并在语音对话的语义和声学评估中展现了开源社区最佳的语音生成性能。它还支持情绪/语速/风格控制、语音克隆、角色扮演等进阶能力。
- 强大的多模态流式交互能力。 作为一项新功能,MiniCPM-o 2.6 能够接受连续的视频和音频流,并和用户进行实时语音交互。在综合评测基准 StreamingBench 中(包含实时视频理解、全模态视音频理解、多模态上下文理解三大类评测),MiniCPM-o 2.6 取得开源社区最佳水平,并超过了 GPT-4o-202408 和 Claude 3.5 Sonnet。
- 强大的 OCR 能力及其他功能。 MiniCPM-o 2.6 进一步优化了 MiniCPM-V 2.6 的众多视觉理解能力,可以处理任意长宽比的高清图像,像素数可达 180 万(如 1344×1344像素)。在 OCRBench 上取得 25B 以下最佳水平,超过 GPT-4o-202405 等商用闭源模型。基于最新的 RLHF-V、RLAIF-V 和 VisCPM 技术,该模型具备了可信的多模态行为,在 MMHal-Bench 上超过了 GPT-4o 和 Claude 3.5,并支持英语、中文、德语、法语、意大利语、韩语等30多种语言的多模态交互。
- 卓越的效率。 除了对个人用户友好的模型大小,MiniCPM-o 2.6 还表现出最先进的视觉 token 密度(即每个视觉 token 编码的像素数量)。它仅需 640 个 token 即可编码 180 万像素图像,比大多数模型少 75%。这一特性显著优化了模型的推理速度、首 token 延迟、内存占用和功耗。因此,MiniCPM-o 2.6 可以首次支持 iPad 等终端设备上的高效多模态实时流式交互。
我们将介绍 MiniCPM-o 2.6 中所面临的主要挑战及其相应的解决方案。
🤔 如何实现多模态流式交互?
人类能够持续感知来自环境的视觉、音频和文本信息流,并以较低延迟生成语音和文本回复,但这对当前的多模态大模型来说是一个重大挑战。
💡 1. 我们将各模态的离线编码/解码器改造为支持在线模式,从而支持流式输入/输出处理。
大多数模态的编码器和解码器都是离线的,大语言模型必须等待完整的视觉/音频输入的编码完成后才能进行处理,用户也必须等待语音完整生成后才能收听。我们在时间维度上将不同模态的输入/输出流分割成小块,并以块为单位进行编码/解码以实现更低的延迟。对于语音生成来说,我们设计了一种新颖的流式注意力策略使解码器能够在接收到第一个文本块时就开始生成音频。
💡 2. 我们提出了一种全模态时分复用机制来处理并行多模态流。
借鉴通信领域的时分复用技术,我们将每个模态的信息流分割成小块(每秒一块),并将同一秒内的所有模态信息组合成一个紧凑的序列单元输入给大语言模型主干。基于这个策略,主干模型可以高效地在线处理多模态信息流。
🤔 如何实现高效的端到端声音、情感、口音和语速可控的语音对话?
大多数传统语音对话模型都是基于 ASR-LLM-TTS 流水线实现的,会丢失大量用户复杂情感和环境声音等细粒度信息。而直接使用大语言模型生成音频 token 的端到端模型在训练和推理过程中都存在计算效率低的问题,且训练时数据效率也较低。
💡 我们基于混合的端到端架构在自然语音上进行了大规模预训练。
我们同时通过连续特征和文本将大语言模型和一个轻量级语音解码器连接起来。大语言模型产生的连续特征确保语音监督信号能够以端到端方式反向传播到全部模型参数,从而支持更高的能力上限。文本连接则提供了强大的语义控制并减少了训练数据需求。为了学习丰富的细粒度语音知识,我们在自然语音数据进行了大规模预训练,然后将模型与用户指令对齐。
端到端全模态架构
我们首先介绍 MiniCPM-o 2.6 的端到端全模态整体架构。该模型基于SigLip-400M、Whisper-medium-300M、ChatTTS-200M 和 Qwen2.5-7B-Instruct,总共有 8B 参数。整体架构如下所示。
端到端语音建模
大多数现有的多模态模型依赖 ASR 和 TTS 工具搭建流水线来理解和生成语音,导致了明显的语音信息损失和比较有限的语音控制能力。我们提出一种混合连接的端到端语音建模架构,在保证模型能力上限的同时具备优秀的训练和推理效率。
音频编码
我们首先使用 Whisper 编码音频输入,然后进一步压缩其特征表示来减小后续的计算开销。默认情况下,Whisper 编码器会为每秒音频生成 50 个 token。受 LLaVA-UHD 的启发,我们在将音频 token 输入到大语言模型主干之前会进一步压缩音频 token,以提高 token 信息密度和计算效率。实验结果表明从 50 token/秒压缩到 25 token/秒时,造成的信息损失几乎可以忽略,并可提高近一倍的计算效率。
语音解码
为了实现对语音输出的精细控制,我们首先从大语言模型主干中获得连续特征作为 speech embedding,然后通过大语言模型继续生成文本。speech embedding 和生成的文本同时会输入给解码器作为生成语音梅尔谱的控制条件。MiniCPM-o 2.6 使用了初始化自 ChatTTS 的轻量级自回归语音解码器来联合建模输入的 speech embedding、文本和输出的音频 token。
语音到语音架构
我们直接通过编码后的音频特征(不使用 ASR)将音频编码器与大语言模型连接起来。大语言模型和语音解码器则以混合方式连接:(1)speech embedding 连续特征控制语音、情感、口音及其他细粒度语音特征。在训练过程中,来自语音解码器的梯度会反向传播到包含大语言模型主干和音频编码器的整个模型参数。模型通过端到端方式训练,没有使用任何中间损失和监督。(2)我们还将来自大语言模型的文本输入到语音解码器,来提供更好的语义控制和训练数据效率。
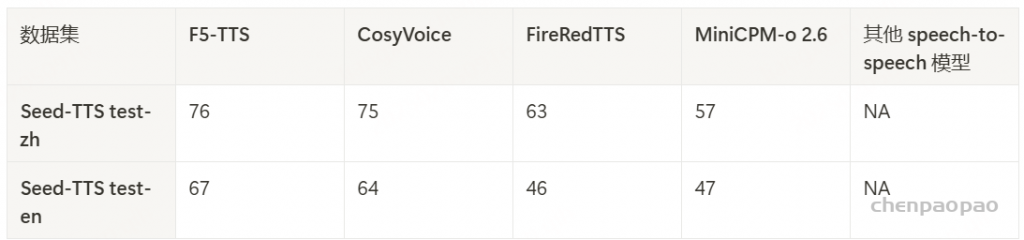
得益于端到端的架构设计,MiniCPM-o 2.6 成为首个支持端到端语音克隆的通用语音对话模型。我们发现 MiniCPM-o 2.6 在语音克隆任务中可以达到与一些专业 TTS 工具相近的性能。
端到端视觉理解
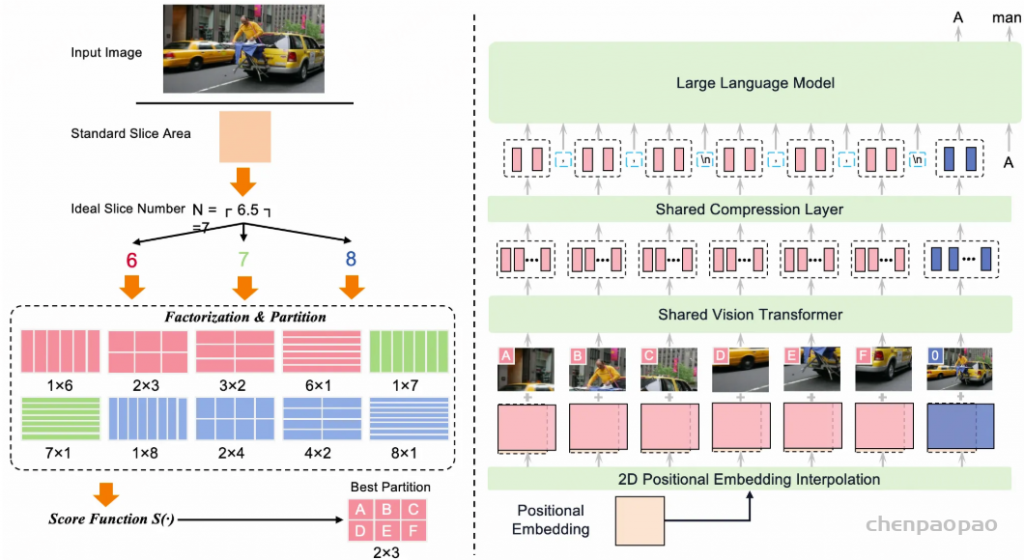
MiniCPM-o 2.6 采用 LLaVA-UHD 的自适应视觉编码方案以实现高清视觉理解,支持处理最高 180 万像素(例如 1344×1344)的任意长宽比图像。具体而言,我们先将图像划分为多个切片,使得每个切片在分辨率和长宽比方面接近 ViT 的预训练设置。为了提高计算效率,我们支持每张图像最多 9 个切片。然后我们将每个切片及原始完整图像输入给 SigLIP 以获取视觉特征。最后,我们应用 perceiver resampler 将每个图像切片的特征序列压缩为 64 个视觉 token。更多细节参见 LLaVA-UHD 和MiniCPM-V 原始论文。
全模态流式机制
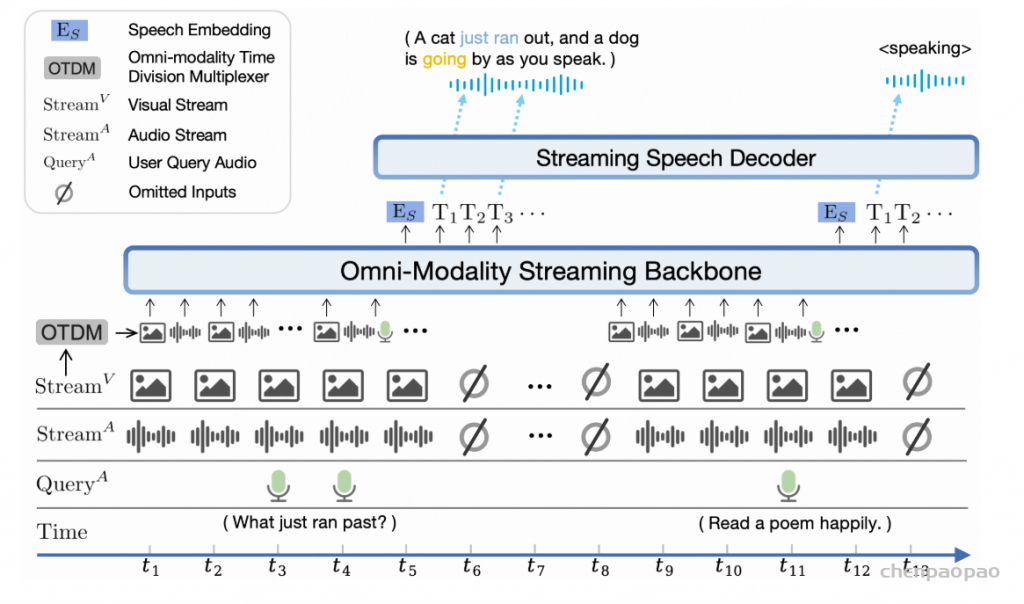
本章我们介绍 MiniCPM-o 2.6 的全模态流式机制,包括:(1)改造语音编码器和解码器以支持在线流式处理,(2)使大语言模型主干能够处理并行的多模态流信息。
流式音频编码
大多数现有模型只能在整个音频输入信号完整后才开始进行音频编码,从而引入了显著的延迟。为了解决这个问题,我们将输入音频分割成多个片段,每个片段是表示一秒钟的音频的固定数量音频 token。在音频编码过程中,每个片段都采用因果注意力机制进行编码,仅关注自身及之前的片段,从而满足在线流式编码的需求,同时与离线整体编码相比保持了最小的信息损失。
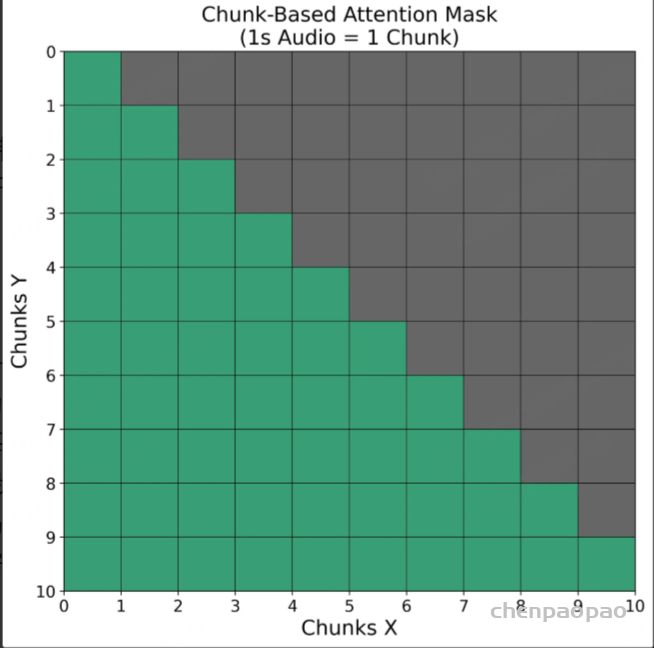
流式语音解码
大多数语音生成模型要求在开始生成音频之前,所有文本 token 都已经完整就位,如图 A 所示。虽然这种方式在离线任务中表现良好,但无法满足流式场景的需求。对于流式模型而言,我们需要在部分文本生成时就开始生成(和播放)相应音频。
为了实现流式语音生成,我们每次输入固定数量的文本 token(一个大小为 n 的片段),而解码器立即输出固定数量的音频 token(一个大小为 m 的片段)。这个过程会对下一个文本 token 和音频 token 片段重复进行,以此类推。值得注意的是,文本片段与其对应音频片段之间的并不是精确对齐的。因此在实际应用中,我们为文本 token 片段的大小保留了更大的空余以避免意外情况。
为了实现上述流式策略并尽可能减小对当前最佳语音解码器的改动,我们主要引入了两个改变:
- 为文本预留前 N 个位置: 我们使用语音解码器上下文中的前 N 个位置来放置 speech embedding 和生成中的文本。
- 引入流式因果注意力掩码: 每个新生成的音频片段只能关注到已经生成的前几个文本 token 片段和其之前的所有音频 token。
在图 A-E 中,我们展示了每当引入新文本 token 和音频 token 时,注意力掩码是如何一步一步变化的。通过控制文本和音频 token 之间的片段注意力掩码,我们使得音频能以流式方式生成和播放。
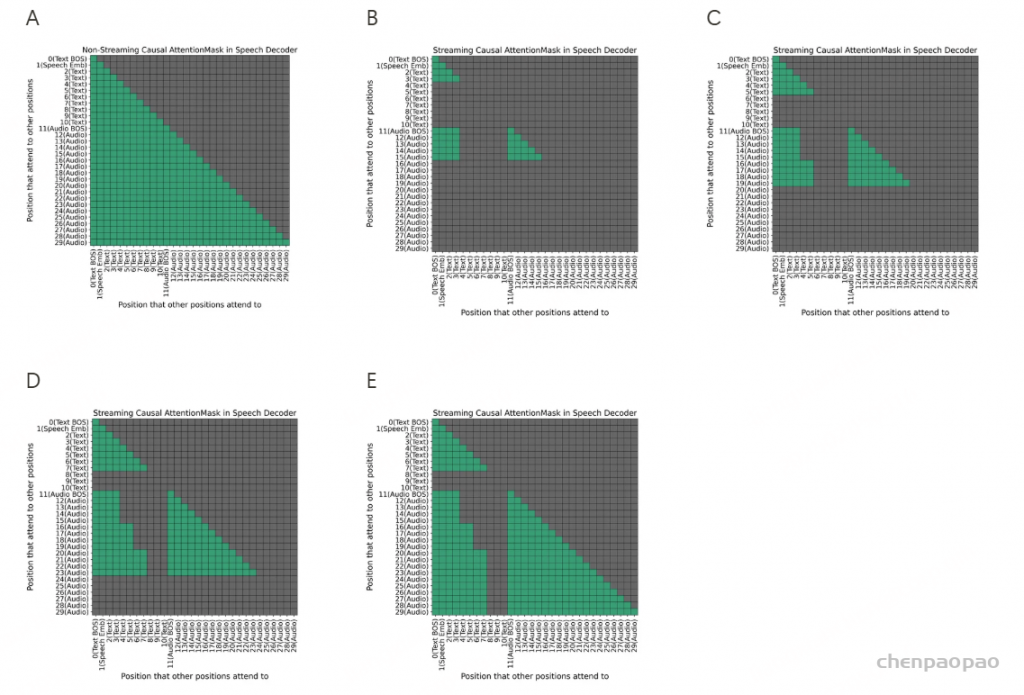
- (文本和音频生成的开始) 在图 B 中,大语言模型主干生成 speech embedding 和前 n 个文本 token(此处 n=2)。然后,我们将 <Text BOS>(1 个位置)、speech embedding(1个位置)和文本 token(n个位置)输入到语音解码器中(总共输入了 2+n 个位置),基于此,模型可以生成最多 m 个音频 token(此处 m=4),但仅关注前 2+n 个位置以及所有之前的音频 token 位置。
- (步骤 1 的重复) 在图 C 中,大语言模型生成下一段 n 个文本 token。我们将这些新文本 token 输入到语音解码器中。然后,解码器生成下一段 m 个音频 token。
- (文本生成结束) 在图 D 中,大语言模型完成所有文本 token 的生成,产生了最后的 k 个文本 token(k<=n,此处 k=2)。剩余的 k 个文本 token 被输入到语音解码器中。然后,语音解码器生成下一个m个音频 token。
- (音频生成结束) 在图 E 中,语音解码器继续生成音频 token,直到生成 <Audio EOS> token。
这里的 N、n 和 m 是超参数。在实际应用中,我们使用 N=300、n=10、m=50,以实现性能与推理速度之间的平衡。
流式视觉理解
我们将视频流表示为以 1 帧每秒(1 fps)的帧序列。我们每秒钟从输入的视觉流中采样一帧,并使用自适应高分辨率编码策略对其进行编码,然后将编码后的特征输入给大语言模型主干。
为了在效率和性能之间取得平衡,我们设计了一种简单的混合分辨率策略。具体而言,我们只对用户请求结束时的最后一帧进行高分辨率编码(例如 1344 x 896),而其他帧则使用中等分辨率(例如 448 x 448)。
全模态时分复用
为了实现对不同模态的时间对齐的流式理解,我们提出了一种全模态时分复用机制。如整体框架图所示,我们首先使用共享的时间线对齐来自多个模态的信息流。受到通信领域时分复用技术的启发,我们将每个模态的流分成小块(每秒一块),并将同一秒块内的所有模态信息聚集成一个紧凑的序列单元。大语言模型则按时间顺序处理这些多模态序列单元。
需要注意的是,MiniCPM-o 2.6 可以独立于用户提问持续感知多模态输入流,这与现有的多模态流式模型只在用户提问期间获取单帧或少数几帧图像信息是不同的。通过这种方式,MiniCPM-o 2.6 能够处理需要时序记忆和推理的任务(例如,“球在哪个杯子里?”、“我刚才擦掉了哪些字?”)并原生支持多轮流式对话。
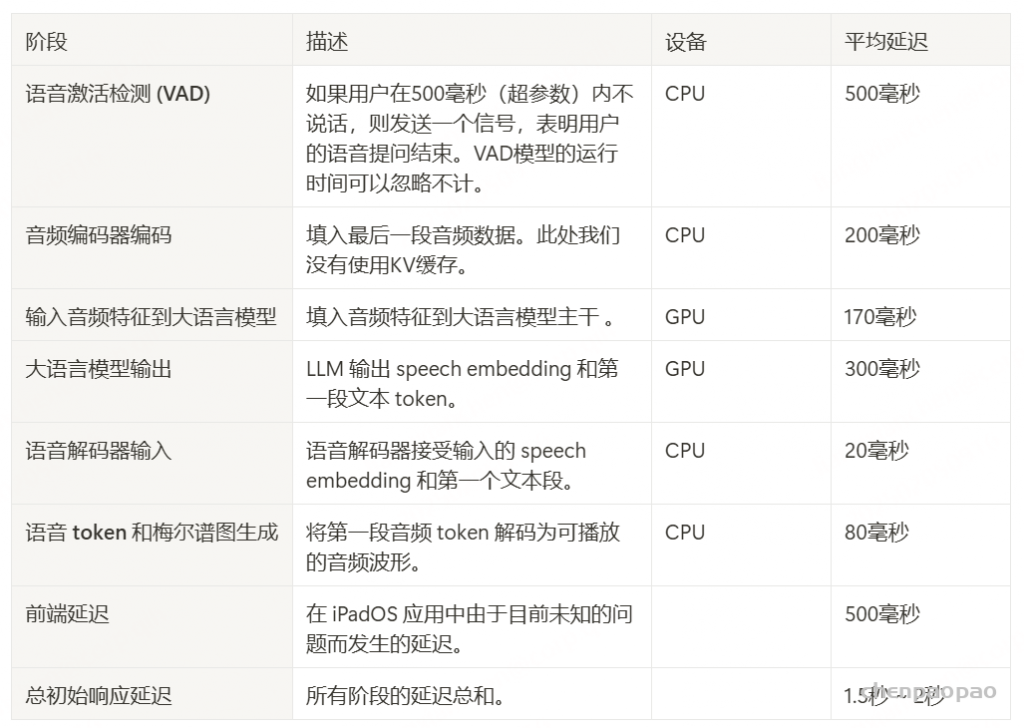
延迟分析
我们提供了纯音频模式下首次响应延迟的具体拆解分析。首次响应延迟指从用户请求结束到模型语音开始播放的延迟。作为参考,GPT-4o 在纯语音模式下的初始响应延迟约为 1.8 秒。MiniCPM-o 2.6 在iPad Pro(M4 芯片)上的初始响应延迟分解如下表所示:
多模态系统提示词
社区在使用文本提示词方面已经积累了丰富的经验,一个好的系统提示可以定义模型的角色、增强其准确性、优化细节表现和令模型聚焦重点。
生成语音回复的端到端全模态模型则面临新的挑战。模型输出的音频特征——如声音、语调、口音和其他细微特征至关重要,但无法仅通过文本传达。为了应对这一挑战,我们提出了多模态系统提示词的概念,允许用户通过声学特征控制模型的声音使其与用户意图相符。
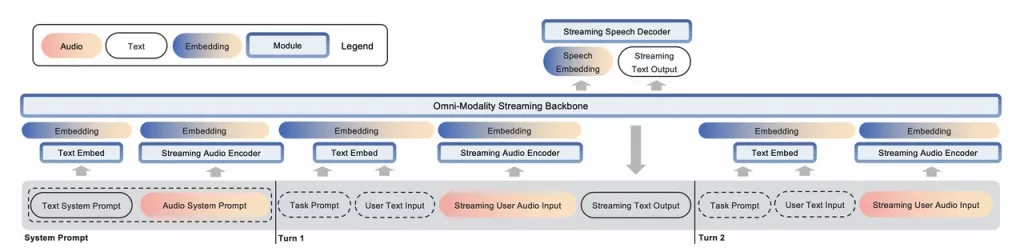
具体来说,多模态系统提示词包括传统的文本系统提示词和用于确定模型声音的音频部分。这一设计使得用户在推理时可以灵活配置声音。用户可以通过提供一段语音样例作为音频系统提示,来完成端到端的声音克隆;还可以通过将音频系统提示留空,基于语言描述要求模型创建一种新声音(例如 “请使用低沉有磁性的声音和我说话”)。
模型训练
MiniCPM-o 2.6 采用多阶段训练以逐步学习新模态的知识,从而避免模态冲突并将各种模态能力整合到一个模型中。整体的训练阶段可以分为预训练、指令微调和偏好对齐阶段。
预训练
我们首先分别对视觉和音频进行预训练以学习每种模态,然后进行全模态预训练以对齐这些模态。
视觉预训练。 我们利用大规模图像-文本对来对齐视觉和语言模块。在此阶段,我们仅更新视觉编码模块,让模型具备基本的图像理解和 OCR 能力。然后,我们在图文交替数据上训练视觉编码器和大语言模型,使模型具备多图理解和多模态上下文学习能力。
音频预训练。 我们使用音频-文本对数据来训练连接部分的权重,以实现音频模态和主干的对齐。为了学习丰富的细粒度语音知识,我们在自然语音数据上进行大规模端到端的预训练,然后根据用户指令对模型进行对齐。
全模态预训练。 在这一阶段,我们结合来自大规模网络视频的视频和音频流,使用 OTDM 机制使模型能够从不同模态中获取和对齐丰富的知识。
全模态指令微调
该阶段使用高质量的多模态数据进行监督微调,包括视觉问答、语音理解、语音生成和多模态流式视频(带音频)理解数据。我们对模型进行全参数微调以统一模型的视觉能力、语音理解和生成能力,以及流式多模态能力,同时增强模型的指令遵循能力。
偏好对齐
最后,MiniCPM-o 2.6 采用 RLAIF-V 技术以进一步提高模型的可信度和综合能力。在这个阶段,模型使用分而治之的策略对不同的回复进行评分以构建偏好数据集,并进行直接偏好优化训练(DPO)。同时,我们还特别将相比图像幻觉更常见的视频幻觉比例降低了63%。我们也使用了 MMPR 等开源偏好数据集来多样化训练数据。
评测
我们充分评估了 MiniCPM-o 2.6 的视觉理解、语音对话和多模态流式交互能力。实验结果表明,该模型在视觉、语音和多模态流式交互能力上的整体表现与 GPT-4o-202405 相当。
MiniCPM-o 2.6 的 iPad Pro 实机演示和 web demo 演示样例:
局限性
- 可能不稳定的语音输出。 多模态系统提示词使得更灵活的语音控制和许多有趣的功能成为可能,但也给语音输出的稳定性带来了更多挑战。传统的语音对话模型通过全参数记忆单一输出声音,与之相比,MiniCPM-o 2.6 需要从多模态系统提示词中提取和复制声音。受到该问题影响,语音生成结果可能会存在背景噪音和无意义声音等。
- 长语音生成。MiniCPM-o 2.6 原生支持最长 45 秒的单次语音生成,我们通过滑动窗口技术来支持生成更长的语音。模型训练与滑动窗口推理之间的差距可能导致长语音生成过程中的不稳定现象。
- 多模态流式交互能力。 作为一项实验性能力,模型的多模态流式交互能力在感知、理解和推理能力上仍然有限。我们期待社区的共同努力构建更优秀和可靠的性能效果。
- 网页 demo 高延迟。 用户在使用托管在海外服务器上的网页 demo 时可能会遇到异常的高延迟情况。我们建议在本地部署 demo(例如 4090 GPU 可以流畅运行)或使用合适的网络连接。
参考文献
- MiniCPM-V: A GPT-4V Level MLLM on Your Phone. 2024.
- RLHF-V: Towards Trustworthy MLLMs via Behavior Alignment from Fine-grained Correctional Human Feedback. CVPR 2024.
- RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness. 2024.
- LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images. ECCV 2024.
- Large Multilingual Models Pivot Zero-Shot Multimodal Learning across Languages. ICLR 2024.